
Prorise
这是我的博客,分享技术与生活的点点滴滴
第十六章. GitHub Actions 入门:让代码审查在云端自动发生
第十六章. GitHub Actions 入门:让代码审查在云端自动发生
Prorise第十六章. GitHub Actions 入门:让代码审查在云端自动发生
在前面的章节中,我们搭建了基于 Husky 的本地代码质量门禁系统,通过 Git Hooks 在每次提交前自动执行 ESLint、Prettier 和类型检查。这套机制在单人开发时运作良好,但当项目进入团队协作阶段,你会发现本地门禁存在致命缺陷:任何开发者都可以通过 --no-verify 参数轻松绕过检查,将未经审核的代码推送到远程仓库。
本章将带你进入持续集成(CI)的世界。你将学会使用 GitHub Actions 在云端构建自动化工作流,让每一次代码推送都必须经过严格的质量检查。我们不仅会学习如何编写工作流配置文件,更会深入理解其背后的运行机制、触发器设计、矩阵测试、缓存优化等核心概念。到本章结束时,你将拥有一个完整的云端质量检查流水线,能够并发测试多个 Node 版本、自动生成测试报告,并在检测到问题时阻止代码合并。
本章假设你已完成第 12-15 章的学习,熟悉 ESLint、TypeScript、Monorepo 等工具的基础配置。如果你跳过了这些章节,建议先返回补充相关知识。
必备基础:
- Git 基本操作(分支管理、推送拉取)
- npm 脚本与依赖管理
- YAML 语法基础
- 第 12 章的 ESLint 配置经验
推荐但非必须:
- Linux 基础命令行操作
- 第 15 章的 Monorepo 架构知识
- Docker 容器基础概念
学习时长估算: 完整跟随本章实践需要 4-6 小时,建议分两次完成。第一次专注于基础工作流的创建与调试,第二次深入矩阵策略与缓存优化。
16.1. 为什么你的团队需要云端 CI:一个真实的协作灾难
16.1.1. 场景重现:Husky 被绕过后的代码污染事件
让我回忆一个真实的项目灾难。那是一个由五人团队维护的电商后台系统,我们在项目中配置了完整的 Husky + lint-staged 门禁,所有提交都必须通过 ESLint 检查。某个周五下午,团队成员小李需要紧急修复一个生产环境的 Bug,但他的代码中存在几处 ESLint 错误。
由于时间紧迫,他使用了这个命令:
1 | git commit -m "fix: 紧急修复支付接口" --no-verify |
这段代码成功绕过了 Husky 的 pre-commit 钩子,直接推送到了主分支。更糟糕的是,这次提交还引入了一个隐藏的类型错误 undefined is not a function,在周末无人值守时触发了大量用户投诉。
问题代码示例
1 | // 小李修改的代码 |
当我们周一复盘时发现,如果有云端 CI 系统,这段代码根本无法合并到主分支。这次事故直接导致了我们决定引入 GitHub Actions。
16.1.2. 本地门禁的三大先天缺陷
缺陷一:可绕过性
任何开发者都可以通过 --no-verify、删除 .husky 目录、甚至卸载 Husky 依赖来跳过检查。本地门禁的强制性完全依赖开发者自觉。
缺陷二:环境差异性
不同开发者的本地环境千差万别:Node 版本不同、操作系统不同、甚至 npm 的镜像源都可能不同。代码在 A 的机器上通过检查,到 B 那里可能直接报错。
缺陷三:配置漂移
当团队成员克隆仓库后,如果忘记执行 npm install 或手动运行 husky install,本地钩子根本不会生效。这种 “半激活” 状态很难被及时发现。
16.1.3. CI/CD 工具选型:为什么 GitHub Actions 是 2024 年的最优解
在众多 CI/CD 工具中(Jenkins、Travis CI、CircleCI、GitLab CI 等),GitHub Actions 具有以下独特优势:
GitHub Actions 与 GitHub 仓库原生集成,无需注册第三方服务或配置 Webhook。只需在仓库中创建 YAML 文件即可启用。
公开仓库享有无限制的免费运行时长,私有仓库每月提供 2000 分钟免费额度(足够中小型项目使用)。
GitHub Marketplace 拥有超过 18000 个可复用的 Actions,覆盖代码检查、测试、部署等各个环节。
内置矩阵策略可轻松实现跨平台、跨版本的并发测试,这在 Jenkins 等传统工具中需要复杂的插件配置。
16.1.4. 本章实战预告:你将亲手搭建的三层防护网
本章将通过递进式的实战案例,帮你构建一个完整的质量保障体系:
第一层防护:基础代码检查工作流
第二层防护:多环境矩阵测试
第三层防护:集成 Monorepo 的并发任务
完成这三层防护后,你的仓库将具备企业级项目的质量保障能力。
16.2. 第一个工作流:10 分钟完成自动化 CI
本节目标:亲手搭建第一个 GitHub Actions 工作流,推送代码后自动运行 ESLint 检查。
16.2.1. 准备项目(复用第 12 章配置)
如果你已经完成第 12 章的 ESLint 配置,并保留了实战搭建好的项目可以直接跳到 16.2.2
如果没有,可以跳转 12.5 节
在 src/App.tsx 中故意写一段会触发 ESLint 警告的代码:
1 | import { useState } from "react" |
验证本地能运行:
1 | pnpm run lint |
16.2.2. 创建工作流配置
第一步:创建配置文件
1 | mkdir -p .github/workflows |
第二步:复制以下配置到 lint.yml
1 | name: Code Quality Check |
16.2.3. 推送代码并查看结果
第一步:提交并推送
1 | git init |
第二步:在 GitHub 查看运行状态
推送完成后,访问:
1 | https://github.com/<你的用户名>/<仓库名>/actions |
你会看到工作流正在运行(黄色圆圈),点击进去可以查看实时日志。
第三步:观察结果
- ✅ 如果 ESLint 检查通过:状态变为绿色对勾,工作流成功
- ❌ 如果有代码问题:状态变为红色叉号,展开 “运行 ESLint 检查” 步骤可以看到具体错误
16.2.4. 故意制造一个错误(测试 CI 拦截)
修改 src/App.tsx,添加一行 console.log:
1 | import { useState } from "react" |
再次推送:
1 | git add . |
此时 Actions 会显示失败,错误信息类似:
1 | src/App.tsx |
修复后再次推送,删除 console.log 那行:
1 | git add . |
这次应该显示绿色对勾,检查通过!
16.3. 物理架构解剖:Workflow 文件背后的运行机制
16.3.1. 五层架构的自底向上理解
GitHub Actions 的架构可以抽象为五层金字塔结构:
1 | Workflow(工作流) |
各层职责详解
Runner(最底层):物理执行环境,可以是 GitHub 托管的虚拟机,也可以是你自己部署的 Self-hosted Runner。
Steps(步骤层):最小执行单元,可以是 Shell 命令或预定义的 Action。
Jobs(作业层):步骤的逻辑分组,默认并发执行,可以通过 needs 定义依赖关系。
Event(触发层):定义何时启动工作流,如 push、pull_request、schedule 等。
Workflow(顶层):完整的自动化流程定义,对应一个 YAML 文件。
16.3.2. Runner 的真实身份:虚拟机还是容器?
这是初学者常见的困惑。GitHub 提供的 Runner 是完整的虚拟机,而非 Docker 容器。以 ubuntu-latest 为例,它实际是一个运行 Ubuntu 22.04 的虚拟机,预装了以下软件:
你可以在工作流中运行任何 Linux 命令,包括安装软件包、修改系统配置等。每次工作流运行时,都会分配一个全新的虚拟机,执行完成后立即销毁,确保环境隔离。
16.3.3. 为什么文件必须放在 .github/workflows/
这是 GitHub Actions 的硬性约定(Convention over Configuration)。当你推送代码到仓库时,GitHub 服务器会:
- 扫描仓库根目录的
.github/workflows/目录 - 解析其中所有
.yml和.yaml文件 - 根据文件中的
on配置判断是否需要触发 - 如果触发条件满足,将工作流加入执行队列
如果你把配置文件放在其他位置(如 ci/lint.yml),GitHub 根本不会识别它。
16.3.4. 实验:查看 Runner 的硬件配置和预装软件
创建一个新工作流 .github/workflows/inspect.yml:
1 | name: Inspect Runner |
推送后,在 Actions 面板点击 “Inspect Runner” → “Run workflow” → “Run workflow” 按钮手动触发。查看日志输出,你会看到类似信息:
1 | === 操作系统 === |
知识点:GitHub 免费提供的 Runner 配置为 2 核 CPU、16GB 内存、14GB SSD,对于大多数前端项目的 CI 任务已经足够。
16.4. 触发器深度剖析:工作流何时启动
触发器(Trigger)决定了工作流在什么时机被激活。这个看似简单的配置背后,实际上涉及 GitHub 的事件系统架构。
16.4.1. GitHub 事件系统的工作原理
当你在 GitHub 上执行任何操作(推送代码、创建 PR、发布 Release 等),GitHub 会生成对应的 事件对象。这个事件对象包含了操作的完整上下文信息,比如:
- 谁触发的(actor)
- 在哪个分支上(ref)
- 改动了哪些文件(changed files)
- 提交消息是什么(commit message)
Actions 系统会监听这些事件,当事件类型与工作流配置的 on 字段匹配时,就会启动对应的工作流。
关键理解:触发器不是轮询机制,而是事件驱动。GitHub 内部使用发布-订阅模式,工作流相当于订阅了特定类型的事件。
16.4.2. push 事件的深层机制
最常见的 push 事件看起来很简单:
1 | on: |
但这背后发生了什么?
第一步:事件生成
当你执行 git push origin main 时,GitHub 服务器接收到推送请求后,会:
- 更新 ref(引用指针)
- 生成一个
push事件对象 - 将这个事件发布到事件总线
第二步:过滤匹配
事件总线会遍历仓库中所有的工作流文件,检查每个工作流的触发条件:
- 事件类型是否匹配(这里是
push) - 分支过滤是否匹配(是否是
main分支) - 路径过滤是否匹配(如果配置了
paths)
第三步:工作流入队
匹配成功的工作流会被加入执行队列,等待分配 Runner。
为什么要限制分支?
如果不限制分支,所有推送都会触发工作流。在一个有 10 个开发者的团队中,每人每天推送 5 次,就是 50 次触发。如果每次工作流运行 3 分钟,那就是 150 分钟的计算时间。对于免费账户(每月 2000 分钟),这意味着 4 天就会用完配额。
正确的思维模式:把触发器当作 “质量门禁的部署位置”。主分支需要严格检查,开发分支可以只在 PR 阶段检查,个人分支完全不需要 CI。
16.4.3. pull_request 事件的特殊性
pull_request 事件比 push 更复杂,因为它涉及两个分支的交互:
1 | on: |
opened vs synchronize 的本质区别:
opened:PR 刚创建时触发,此时 GitHub 会合并源分支和目标分支生成一个 临时合并提交synchronize:PR 有新提交推送时触发,会重新生成临时合并提交
为什么需要临时合并提交?因为你需要测试的不是源分支本身,而是 “源分支合并到目标分支后” 的状态。假设:
- 你在
feature分支修改了文件 A - 别人在
main分支修改了文件 B,且文件 B 依赖文件 A 的旧版本 - 如果只测试
feature分支,测试会通过 - 但合并到
main后,文件 B 会因为依赖版本不匹配而失败
这就是为什么 PR 检查要在临时合并提交上运行。
实际场景对比:
假设你的工作流配置是:
1 | on: |
时间线:
- 10:00 - 你创建 PR → 触发
opened事件,工作流启动 - 10:05 - 你发现有 Bug,推送新提交 → 触发
synchronize事件,工作流再次启动 - 10:10 - 你又推送一次修复 → 再次触发
synchronize - 10:15 - 你关闭 PR(因为方案不对)
- 10:20 - 你重新打开 PR → 触发
reopened事件
如果你只配置了 [opened],那么步骤 2、3、5 都不会触发检查,这可能导致带 Bug 的代码被合并。
16.4.4. schedule 定时任务的 Cron 陷阱
定时任务使用 Cron 表达式:
1 | on: |
Cron 表达式的 5 个字段:
1 | ┌───────────── 分钟 (0 - 59) |
常见错误:
1 | # ❌ 错误:想表达"每小时",但写成了"每分钟" |
更隐蔽的陷阱:GitHub Actions 的定时任务不保证精确触发。官方文档说:
定时任务最多可能延迟 15 分钟,在高负载时段可能更久。
这意味着如果你配置 0 2 * * *,实际触发时间可能是 2:00、2:05、甚至 2:15。如果你的业务依赖精确时间(比如每天 2 点抓取数据,2 点 10 分数据源就会变化),那就有问题了。
解决方案:在工作流中加入时间校验:
1 | jobs: |
16.4.5. 路径过滤的底层逻辑
路径过滤用于控制 “只有特定文件改动时才触发”:
1 | on: |
过滤算法:
GitHub 会将本次推送涉及的所有文件路径与 paths 配置进行模式匹配:
- 获取本次提交改动的文件列表(git diff)
- 遍历每个文件路径,检查是否匹配
paths中的任何一个模式 - 如果有任何一个文件匹配,触发工作流
- 如果配置了排除模式(
!开头),匹配的文件会被移除
实际案例分析:
假设你的 Monorepo 结构是:
1 | repo/ |
你希望 ui 包改动时运行前端测试,api 包改动时运行后端测试。
错误配置:
1 | # ❌ 这个配置有问题,如果在加入共享包的情况下! |
问题在于:如果你同时修改了 packages/ui 和 packages/api,只会触发 UI 的工作流,API 的改动不会被检查。
正确配置:
1 | # ui-workflow.yml |
这样修改共享包时,两个工作流都会触发,确保不会遗漏检查。
16.4.6. workflow_dispatch:手动触发与交互式调试
前几种触发器(如 push 代码、定时任务)都是自动发生的,但实际开发中,我们经常需要“按需执行”。比如:紧急回滚线上版本、手动触发一次数据清洗,或者只是想单纯地测试一下脚本逻辑。
workflow_dispatch 就是 GitHub Actions 提供的 “手动启动按钮”。
配置它的核心在于 inputs(输入参数)。这相当于给你的脚本编写了一个简易的 Web 表单。当你配置好后,GitHub 的 Actions 界面会出现一个 “Run workflow” 的按钮,点击它会弹出一个侧边栏让你填写参数。
来看一个标准的配置示例:
1 | on: |
这里有两个 非常隐蔽但至关重要 的底层机制,新手极其容易踩坑:
首先是 “先有鸡还是先有蛋”的 UI 加载问题。很多初学者在开发分支写好了上面这个配置,去网页上看却找不到按钮。这是因为 GitHub 必须要先读取到 YAML 文件,才能渲染出那个按钮和表单。默认情况下,GitHub 只读取默认分支(通常是 main)的文件来生成 UI。所以,如果你第一次引入这个触发器,必须先把文件合并到主分支,按钮才会出现。
其次是 参数类型的“字符串陷阱”。虽然我们在 YAML 里定义 enable_debug 是 boolean(布尔值),在 UI 上它也是个复选框。但是,当数据传递给 Shell 环境时,所有类型都会被强行转换成字符串。
如果你写 if [ ${{ inputs.enable_debug }} ],在 Bash 中字符串 “false” 也是非空值,会被判定为真!正确的做法 是必须把它当做字符串进行比较:if [ "${{ inputs.enable_debug }}" == "true" ]。
动手实操:体验你的第一个手动工作流
光看不练假把式。请打开你的 GitHub 仓库,跟随以下 4 步,亲手体验一下“上帝视角”控制工作流的感觉。
第一步:创建文件
在你的仓库根目录下,创建文件 .github/workflows/manual-demo.yml。
第二步:填入代码
复制以下代码并保存。这段代码模拟了一个“手动部署”的场景:
1 | name: manual-demo |
第三步:推送并合并
将这个文件推送到你的 默认分支(main 或 master)。注意:如果不推送到默认分支,你在 Actions 页面是看不到按钮的!
第四步:触发运行
- 打开该仓库的 GitHub 页面,点击顶部的 Actions 标签。
- 在左侧列表中点击 “手动触发演示” (Manual Trigger Demo)。
- 在右侧你会看到 Run workflow 按钮,点击它。
- 在弹出的表单中:
- 修改“操作人昵称”。
- 勾选“确认立即部署?”。
- 点击绿色的 Run workflow 按钮。
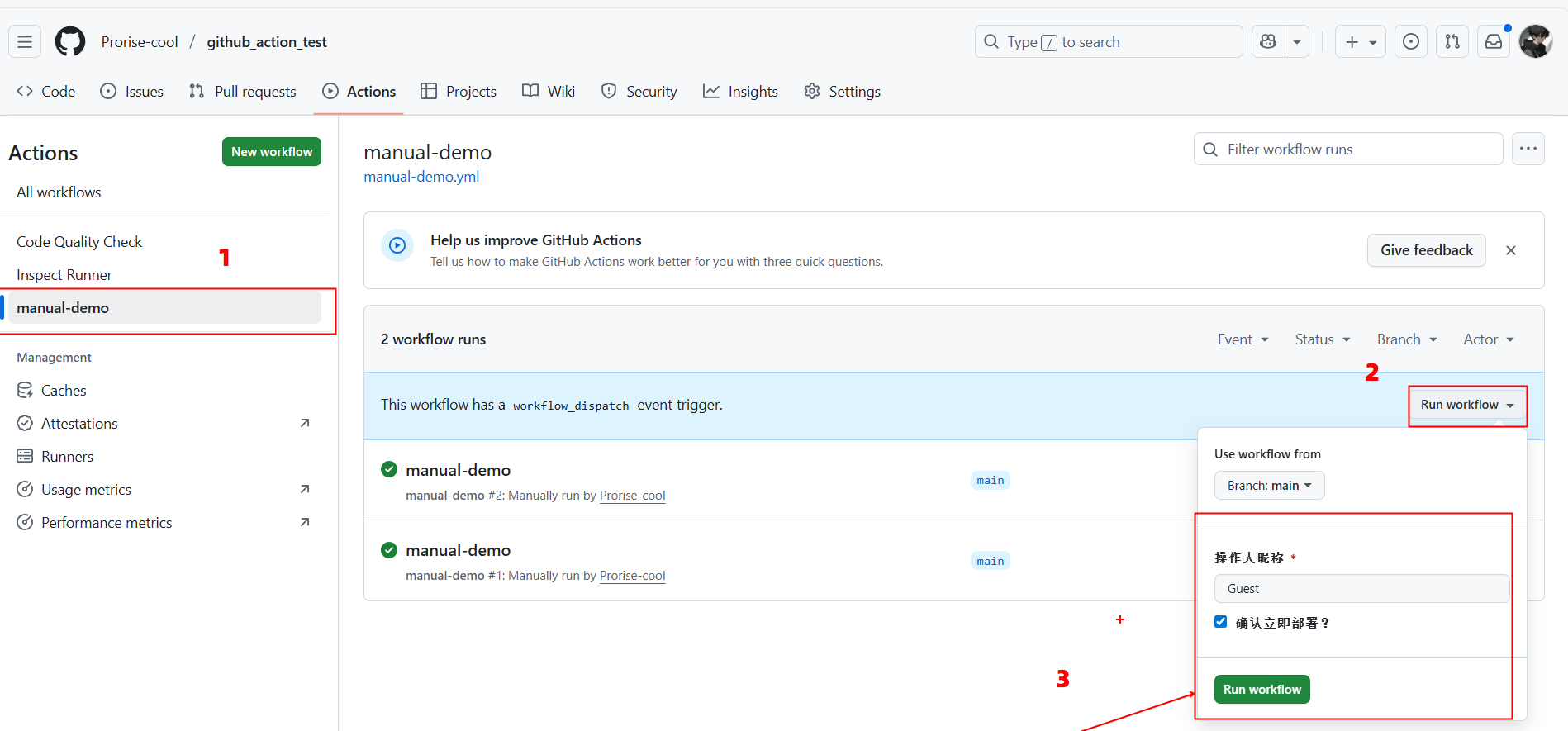
查看结果:等待几秒钟,点击新产生的工作流运行记录。在 模拟部署逻辑 这一步中,你应该能看到它成功输出了 “✅ 收到指令,正在开始部署…”。
通过这个实操,你就掌握了将脚本转化为可视化工具的核心能力。
进阶玩法:从 UI 点击到 API 自动化
掌握了 UI 操作只是第一步,workflow_dispatch 真正的杀手锏在于它 暴露了一个标准的 REST API 接口。这意味着你的 GitHub 仓库不仅仅是存代码的地方,它变成了一个可以通过网络请求调用的“服务器”。
想象一下,你不再需要打开 GitHub 网页,而是在公司内部的 Slack 或飞书里输入 /deploy,或者在你的运维管理后台点击一个按钮,就能触发这个工作流。这一切的底层,都是通过发送一个 HTTP POST 请求 实现的。
让我们用终端(Terminal)来模拟这个过程。你需要准备两样东西:
- 你的 Personal Access Token (PAT)(在 GitHub 设置 -> Developer settings -> Tokens 里生成,需要勾选
workflow权限)。 - 刚才那个工作流的文件名:
manual-demo.yml。
打开你的终端,替换下面命令中的 <你的Token>、<用户名> 和 <仓库名>,然后执行:
1 | curl -X POST \ |
命令解析:
- URL:注意路径里的
.yml文件名,这就像是 API 的 endpoint(端点)。 - ref:必填项,告诉 GitHub 你要在哪个分支上运行(通常是 main)。
- inputs:这里就是刚才我们在 UI 表单里填的内容,现在变成了 JSON 数据。注意看,我们把
username改成了API-Robot,把confirm_deploy设置为"true"。
执行成功后,终端通常不会返回任何内容(HTTP 204 No Content),这代表请求已成功发送。
现在回到 GitHub Actions 页面刷新,你会发现一个新的工作流正在运行。点进去看日志,你会发现它打印出了:“👋 Hello, API-Robot!”。
这带来的思维转变是巨大的:你刚刚完成的不仅仅是一个脚本的触发,而是实现了一种 基础设施即代码(IaC)的远程调用。这意味着你可以把任何复杂的运维任务(数据库备份、CDN 刷新、环境销毁)封装在 GitHub 内部,然后通过简单的 API 向外界提供服务。这就是现代运维中 ChatOps(聊天驱动运维)的核心基石。
16.5. Jobs 与 Steps:构建执行链的正确姿势
16.5.1. Job 的并发模型与资源隔离
工作流中的 Jobs 默认是 并发执行 的,但这个 “并发” 不是在同一台机器上多线程运行,而是每个 Job 分配到 不同的 Runner(虚拟机) 上独立执行。
物理模型:
1 | GitHub Actions Orchestrator |
每个 Runner 是一个全新的虚拟机环境,运行时互不干扰。这意味着:
- Job A 安装的依赖,Job B 无法访问
- 如果 Job A 执行了
npm install,Job B 仍然需要重新安装依赖。 - 文件系统完全隔离
Job A 生成的文件(如构建产物),Job B 无法直接读取。需要通过 Artifacts 传递。 - 环境变量不共享
Job A 设置的环境变量,Job B 看不到。需要通过 Outputs 传递。
为什么要这样设计?
假设 Job A 和 Job B 共享同一个 Runner,如果 Job A 意外修改了系统配置(比如全局安装了某个包),可能会影响 Job B 的执行结果,导致不可复现的错误。
独立的 Runner 保证了每个 Job 的执行环境都是 幂等 的,即多次执行结果一致。
16.5.2. needs 关键字的依赖链构建
当 Job 之间存在依赖关系时,使用 needs 构建执行顺序:
1 | jobs: |
执行时间线:
1 | 0s ───> build 启动 |
总耗时 20 秒。
如果没有 needs(全部并发):
1 | 0s ───> build 启动 |
总耗时仍是 20 秒(取决于最慢的 Job),但 deploy 可能在 build 还没完成时就开始执行,导致错误。
依赖链的失败传播:
如果 build 失败,test 和 deploy 会被自动跳过(状态显示为 skipped)。这避免了在基础任务失败时浪费计算资源。
16.5.3. Job Outputs:跨 Job 传递数据
Jobs 之间传递数据不仅仅是简单的“赋值”,它涉及了从 Runner 内部到 GitHub 控制平面的 三层穿透。如果不理解这个数据流向,很容易配置失败。
核心逻辑图解:
数据必须穿过三道“门”才能到达下一个 Job:
- Step 门:脚本计算出结果,写入系统文件
$GITHUB_OUTPUT。 - Job 门:在 Job 层级显式声明“我要公开暴露这个 Step 的数据”。
- Needs 门:下一个 Job 通过
needs抓取上一个 Job 公开的数据。
代码实操与深度注释:
第一步:生产者(Build Job)—— 数据如何“流”出来
1 | jobs: |
第二步:消费者(Deploy Job)—— 数据如何“流”进去
1 | deploy: |
为什么不用环境变量?
你可能会问:“为什么不能直接设一个全局 ENV 变量大家一起用?”
因为 Job 经常运行在 不同的物理机 上。build 可能跑在机器 A,deploy 跑在机器 B。机器 A 的内存变量,机器 B 根本看不见。所以必须通过 $GITHUB_OUTPUT 把数据上传到 GitHub 的服务器(控制平面),然后机器 B 启动时,再从 GitHub 服务器把这个数据拉下来。
16.5.4. Step 的两种形态对比
Step 可以是 Shell 命令或 Action 调用,两者有本质区别:
形态一:Shell 命令
1 | steps: |
这会在 Runner 上直接执行 Shell 命令,等价于你在本地终端执行。默认使用 bash(Linux/macOS)或 powershell(Windows)。
形态二:Action 调用
1 | steps: |
这会执行一个预定义的 Action(本质是一段 JavaScript 代码或 Docker 容器)。
对比分析:
| 维度 | Shell 命令 | Action |
|---|---|---|
| 执行环境 | Runner 的 Shell | Node.js 运行时 或 Docker |
| 参数传递 | 通过环境变量 | 通过 with 字段 |
| 错误处理 | 依赖退出码 | 可以有复杂的错误处理逻辑 |
| 复用性 | 低(需要复制粘贴) | 高(可以发布到 Marketplace) |
| 适用场景 | 简单操作(1-3 行命令) | 复杂逻辑(需要条件判断、循环等) |
何时用 Shell,何时用 Action?
规则:如果操作可以用 1-3 行 Shell 命令完成,直接用 run。如果需要:
- 复杂的参数验证
- 跨平台兼容性处理
- 与 GitHub API 交互
- 生成格式化的日志输出
那就应该用或创建一个 Action。
16.5.5. 实战案例:代码质量检查流水线
现在我们构建一个真实的质量检查工作流,并 逐行分析 每个配置的作用。
1 | name: Code Quality |
分析:
on.pull_request.branches: [main]:只检查目标分支为main的 PRpaths配置:只有代码或依赖变更时才触发,避免文档修改也跑 CI,注意了,如果在后续测试记得是修改 src 下的代码,否则 action 是不会触发的!
1 | jobs: |
分析:
fetch-depth: 0:获取完整 Git 历史,而不是默认的浅克隆(只获取最新提交)- 为什么需要完整历史?某些工具(如 ESLint 的增量检查)需要对比历史提交
1 | - name: 设置 Node.js |
分析:
cache: 'npm':自动缓存~/.npm目录,加速依赖安装- 原理:第一次运行时,
setup-node会在安装依赖后将~/.npm打包上传;后续运行时,如果package-lock.json的 hash 值没变,就直接解压缓存
1 | - name: 安装依赖 |
分析:
- 为什么用
npm ci而不是npm install?npm ci会删除node_modules后全新安装,确保环境干净npm install会尝试复用已有的包,可能导致版本不一致- CI 环境应该追求可复现性,所以用
ci
1 | - name: 运行 ESLint |
分析:
- 为什么用
npx而不是npm run lint?npx直接执行node_modules/.bin/eslint,更明确npm run lint依赖package.json中的 scripts 配置,增加了一层间接性- 在 CI 中推荐显式命令,减少隐式依赖
1 | - name: 检查 TypeScript 类型 |
分析:
if: hashFiles('tsconfig.json') != '':只有项目中存在 TypeScript 配置时才执行hashFiles()函数返回文件的 hash 值,如果文件不存在返回空字符串- 这样同一个工作流可以兼容 JS 和 TS 项目
16.5.6. continue-on-error 的使用时机
某些步骤的失败不应该中断整个工作流,比如:
1 | steps: |
原理:
continue-on-error: true:即使这个步骤失败(退出码非 0),后续步骤仍然执行if: always():无论前面步骤成功与否都执行steps.test.outcome:获取步骤的执行结果(success、failure、skipped)
使用场景:
- 测试失败但仍需要生成报告
- 可选的性能检查(失败时发出警告但不阻断流程)
- 多环境测试中某个环境失败不影响其他环境
16.6. 上下文对象:让工作流感知运行环境
16.6.1. 上下文对象的本质
上下文(Context)是 GitHub Actions 在运行时注入的一组 只读对象,包含了当前执行环境的所有信息。
可以类比为:
- 前端框架中的全局状态(如 Vuex 的 state)
- 后端框架中的请求上下文(如 Express 的 req 对象)
在工作流中通过 ${{ context.property }} 语法访问,比如 ${{ github.ref }}。
为什么需要上下文对象?
因为工作流需要根据 运行时信息 做决策。比如:
- 根据分支名决定部署环境(main → 生产,develop → 测试)
- 根据触发者决定是否执行敏感操作(只允许 admin 触发部署)
- 根据提交消息决定是否跳过 CI(提交消息包含
[skip ci])
16.6.2. 最重要的 5 个上下文对象
1. github 上下文
包含仓库、分支、提交、触发者等信息:
1 | steps: |
实际输出:
1 | 仓库: owner/repo |
常用属性:
github.ref:完整的引用路径(refs/heads/main、refs/tags/v1.0.0)github.ref_name:简短的引用名(main、v1.0.0)github.sha:触发工作流的提交 SHA(完整 40 位)github.event_name:触发事件类型(push、pull_request等)
2. env 上下文
访问环境变量:
1 | env: |
3. secrets 上下文
访问加密的密钥:
1 | steps: |
安全机制:
- Secrets 在日志中会被自动替换为
*** - 无法通过表达式打印 Secrets 的值(
${{ secrets.MY_SECRET }}会被过滤)
4. runner 上下文
获取 Runner 的系统信息:
1 | steps: |
5. needs 上下文
访问依赖 Job 的输出:
1 | jobs: |
16.6.3. 表达式与函数
上下文对象支持一些内置函数:
条件判断函数:
1 | steps: |
字符串操作函数:
1 | steps: |
文件检测函数:
1 | steps: |
hashFiles() 的工作原理:
- 参数支持 glob 模式(如
**/*.json) - 返回所有匹配文件内容的 SHA-256 hash
- 如果没有文件匹配,返回空字符串
JSON 序列化:
1 | steps: |
这会输出完整的 github 上下文对象,方便调试。
16.7. 环境变量的三层作用域
16.7.1. 作用域的物理意义
环境变量在 GitHub Actions 中分为三个层级:
1 | Workflow 级别(全局) |
层级的物理映射:
- Workflow 级别 → 写入 Runner 的全局环境配置文件
- Job 级别 → 在 Job 启动时注入到 Shell 环境
- Step 级别 → 只在当前 Step 的进程环境中生效
16.7.2. 优先级规则:就近原则
当多层定义同名变量时,内层覆盖外层:
1 | env: |
为什么要分层?
- 复用性:Workflow 级别的变量可以被所有 Job 共享,避免重复定义
- 灵活性:Job 级别可以覆盖全局配置,适应特殊需求
- 隔离性:Step 级别的变量不会污染其他 Step
16.7.3. 实战:统一管理依赖版本
一个实际项目可能有多个 Job,每个都需要相同的 Node 版本:
❌ 糟糕的写法(硬编码):
1 | jobs: |
问题:升级 Node 版本时需要改 3 处。
✅ 推荐写法(环境变量):
1 | env: |
升级时只需修改一处。
16.7.4. Secrets 的安全传递机制:避免“裸奔”
Secrets(机密信息)是 GitHub 仓库中最敏感的数据。很多新手知道要用 Secrets,但往往在使用方式上犯了 “把钥匙插在门上” 的错误。
当你写 ${{ secrets.MY_TOKEN }} 时,GitHub Actions 的后端会在工作流启动前,将这个变量替换为实际的密钥值。
但是! 这种替换发生在 YAML 解析阶段,而不是 Shell 执行阶段。这就引出了最大的安全隐患。
❌ 极其危险的写法:
1 | steps: |
发生了什么?
- GitHub 将
${{ secrets.API_TOKEN }}替换为abcd-1234。 - 实际发送给 Runner 执行的命令变成了:
./deploy.sh --token abcd-1234。 - 安全漏洞:在 Linux 系统中,任何用户只要运行
ps aux(查看进程列表命令),就能看到所有正在运行的命令及其 完整参数。 - 如果此时有恶意脚本在同一台机器上运行(或者日志采集工具不够智能),你的密钥就直接 明文暴露 在了系统进程列表中。
✅ 安全的写法:
1 | steps: |
为什么这样就安全了?
- 机制:环境变量属于进程的 私有内存空间。
- 隔离:运行
ps命令只能看到./deploy.sh --token $DEPLOY_TOKEN(或是展开后的变量名,取决于 Shell,但通常不会在进程树中展开值),或者脚本内部直接读取$DEPLOY_TOKEN。外部进程无法窥探到变量的具体值。
GitHub 有一个自动脱敏机制:当 Runner 启动时,它会把所有的 Secrets 值注册为 “Mask”(掩码)。
在日志输出流中,只要遇到和 Secrets 完全一样的字符串,GitHub 就会自动把它替换成 ***。
1 | steps: |
日志显示:
我的密码是: ***
注意:不要依赖脱敏机制!如果你把 Secret Base64 编码后打印出来,GitHub 是识别不出来的(因为字符串变了),从而导致泄漏。
16.8. 矩阵策略:一次配置测试多种环境
16.8.1. 问题引入:跨平台测试的困境
假设你的 Node.js 库需要支持:
- 3 个 Node 版本:16、18、20
- 3 个操作系统:Ubuntu、Windows、macOS
传统做法需要手写 9 个 Job(3×3 组合),配置文件会非常冗长。矩阵策略可以将 9 个 Job 的配置压缩为一个。
16.8.2. 矩阵的数学本质:笛卡尔积
矩阵策略本质上是对配置参数做 笛卡尔积 运算:
1 | os = [ubuntu, windows, macos] |
每个组合对应一个并发的 Job 实例。
配置语法:
1 | strategy: |
这会生成 9 个 Job,并发执行。
16.8.3. include 与 exclude 的组合艺术
排除特定组合(某些组合不需要测试):
1 | strategy: |
这会生成 7 个 Job(9 - 2)。
添加特殊组合(在笛卡尔积基础上追加):
1 | strategy: |
这会生成 4 个 Job:
- ubuntu + Node 18
- ubuntu + Node 20
- ubuntu + Node 16(带 experimental 标记)
- windows + Node 20
include 的额外属性 可以在步骤中引用:
1 | steps: |
16.8.4. fail-fast 的流控机制
默认情况下,如果矩阵中任何一个 Job 失败,其他 Job 会立即取消(fail-fast 模式)。
关闭 fail-fast:
1 | strategy: |
使用场景对比:
| 场景 | fail-fast 设置 | 原因 |
|---|---|---|
| 单元测试 | false | 需要看到所有平台的测试结果 |
| 构建发布 | true(默认) | 一个平台失败就没必要继续 |
| 性能基准测试 | false | 需要收集所有环境的数据 |
16.8.5. 实战:Monorepo 的多包并发测试
假设你的 Monorepo 有 3 个包:ui、utils、cli,需要在 2 个 Node 版本上分别测试。
1 | name: Monorepo Test Matrix |
执行效果:
- 生成 6 个并发 Job(3 个包 × 2 个版本)
- 每个 Job 只测试一个包的一个版本
- 失败不会影响其他 Job(
fail-fast: false) - 为每个组合单独上传覆盖率报告(通过 flags 区分)
为什么这样设计?
如果按传统方式(一个 Job 测试所有包),当某个包失败时,后续包的测试就被跳过了。而矩阵策略让每个包独立运行,互不影响。
16.9. 缓存策略:让构建从 5 分钟降到 30 秒
16.9.1. 缓存的性能对比实验
先看一个没有缓存的工作流:
1 | jobs: |
时间分布(假设项目有 200 个依赖):
- 检出代码:10s
- 设置 Node:5s
- 安装依赖:180s ⬅️ 性能瓶颈
- 构建:20s
- 总计:215s(3 分 35 秒)
现在启用缓存:
1 | - uses: actions/setup-node@v4 |
第二次运行的时间分布:
- 检出代码:10s
- 设置 Node:5s
- 恢复缓存:15s ⬅️ 从远程下载缓存
- 安装依赖:10s ⬅️ 只安装缓存中没有的包
- 构建:20s
- 总计:60s(1 分钟)
性能提升:72%(从 215s 降到 60s)
16.9.2. 缓存的工作原理深度解析
缓存机制分为三个阶段:
阶段一:缓存键生成
1 | - uses: actions/cache@v3 |
key 的组成:
runner.os:操作系统(Linux、Windows、macOS)hashFiles('**/package-lock.json'):所有package-lock.json文件的 SHA-256 hash
为什么要用 hash?
假设你的 package-lock.json 内容是:
1 | { |
hash 值可能是:a1b2c3d4...
当你添加一个新依赖后,内容变成:
1 | { |
hash 值变成:e5f6g7h8...
两个 hash 不同,说明依赖变了,需要重新安装。
阶段二:缓存命中检测
GitHub 会在缓存服务器中查找是否存在 key 为 Linux-npm-a1b2c3d4... 的缓存:
- 如果存在:下载并解压到
~/.npm - 如果不存在:跳过恢复,正常执行后续步骤
阶段三:缓存保存
当 Job 成功完成时,GitHub 会:
- 将
~/.npm目录打包(tar.gz) - 上传到缓存服务器
- 关联到 key
Linux-npm-a1b2c3d4...
下次运行时,如果 package-lock.json 没变,就能命中这个缓存。
16.9.3. restore-keys 的降级策略
如果 package-lock.json 有微小变化,hash 值会完全不同,导致缓存完全失效。这时可以用 restore-keys 提供降级方案:
1 | - uses: actions/cache@v3 |
匹配逻辑:
- 先尝试精确匹配
Linux-npm-a1b2c3d4... - 如果失败,尝试前缀匹配
Linux-npm-(任何以此开头的缓存) - 如果还失败,尝试
Linux-(任何 Linux 平台的缓存)
实际效果:
假设缓存服务器中有:
Linux-npm-a1b2c3d4...(旧版本的缓存)Linux-npm-e5f6g7h8...(当前版本的精确缓存)
如果当前 hash 是 e5f6g7h8...,会精确命中第二个缓存。
如果当前 hash 是全新的 x9y8z7w6...,会降级匹配第二个缓存(Linux-npm- 前缀),虽然不完全匹配,但能加速部分依赖的安装。
16.9.4. 缓存失效的三种场景
场景一:依赖文件变更
1 | 旧的 package-lock.json → hash: a1b2c3d4 |
缓存键不同,失效。
场景二:缓存过期
GitHub 的缓存策略:
- 单个缓存最大 10GB
- 仓库总缓存最大 10GB
- 超过 7 天未访问的缓存会被自动删除
场景三:手动清除
在仓库的 Actions → Caches 页面可以手动删除缓存。
何时需要手动清除?
- 缓存数据损坏(比如某个包安装失败后被缓存)
- 想测试完全干净的环境
- 更换了包管理器(从 npm 切换到 pnpm)
16.9.5. Setup Actions 的内置缓存
除了手动使用 actions/cache,很多 setup 类 Action 内置了缓存功能:
Node.js 缓存:
1 | - uses: actions/setup-node@v4 |
等价于:
1 | - uses: actions/cache@v3 |
Python 缓存:
1 | - uses: actions/setup-python@v4 |
Go 缓存:
1 | - uses: actions/setup-go@v4 |
为什么推荐用内置缓存?
- 更简洁(一行配置)
- 自动处理路径和缓存键
- 跨平台兼容性更好
16.9.6. Turborepo 的远程缓存终极优化
对于使用 Turborepo 的 Monorepo,可以启用远程缓存(Remote Cache):
1 | jobs: |
远程缓存的优势:
传统缓存:只缓存依赖(node_modules)远程缓存:缓存构建产物(dist、build)
实际效果:
假设你的 Monorepo 有 10 个包:
传统方式:
1 | 安装依赖(30s)→ 构建包1(10s)→ 构建包2(10s)→ ... → 构建包10(10s) |
启用远程缓存后(第二次运行):
1 | 安装依赖(10s,命中依赖缓存)→ 检测到所有包都有缓存 → 直接使用缓存产物 |
性能提升:90%
16.10. Actions 复用的三种形态
16.10.1. 为什么需要 Actions 复用
在多个工作流中出现重复步骤时,比如:
1 | # workflow-1.yml |
这种重复有三个问题:
- 维护成本高:修改 Node 版本需要改多处
- 容易不一致:可能某个工作流忘记更新配置
- 配置冗长:相同的步骤重复多次
解决方案就是创建可复用的 Action。
16.10.2. Marketplace Actions:站在巨人的肩膀
GitHub Marketplace 提供了丰富的第三方 Actions,涵盖:
- 代码检查(ESLint、SonarQube)
- 测试报告(Jest、Playwright)
- 部署工具(AWS、Azure、Vercel)
- 通知服务(Slack、Discord、Email)
使用建议:
版本锁定
1
2
3
4
5# ❌ 不推荐
- uses: actions/checkout@latest
# ✅ 推荐
- uses: actions/checkout@v4原因:
latest可能引入破坏性更新,导致工作流突然失败。安全审查
使用第三方 Action 前,检查:- 星标数(> 1000 为佳)
- 更新频率(最近 6 个月有更新)
- 是否由可信组织维护(如 GitHub 官方)
- 源码审查
对于敏感操作(如部署),查看 Action 的源码,确认没有恶意行为。
16.10.3. Composite Actions:抽取你自己的重复步骤
创建一个自定义 Action,封装 “设置 Node 环境 + 安装依赖” 的逻辑。
第一步:创建 Action 配置文件
在仓库根目录创建 .github/actions/setup-node-env/action.yml:
1 | name: 'Setup Node Environment' |
关键点解析:
using: 'composite':声明这是一个组合 Actioninputs:定义可传递的参数shell: bash:必须显式指定(Composite Action 的限制)
第二步:在工作流中调用
1 | name: Code Quality Check |
优势:
- 所有工作流共享同一套环境配置
- 修改版本号只需改一处(Action 的默认值)
- 可以添加额外的环境检查逻辑
16.10.4. 带输出的 Composite Action
除了输入参数,Action 还可以返回输出:
1 | # .github/actions/get-version/action.yml |
调用时:
1 | name: Code Quality Check |
16.10.5. Docker Container Actions 的适用场景
当 Composite Action 无法满足需求时(比如需要特殊的系统环境、编译工具),可以使用 Docker Container Action。
场景示例:你需要一个基于 Go 语言的自定义 Linter,但不想在每个工作流中安装 Go 环境。
第一步:创建 Action 配置
.github/actions/go-linter/action.yml:
1 | name: 'Go Custom Linter' |
第二步:创建 Dockerfile
.github/actions/go-linter/Dockerfile:
1 | FROM golang:1.21-alpine |
第三步:编写入口脚本
.github/actions/go-linter/entrypoint.sh:
1 |
|
调用:
1 | jobs: |
优劣对比:
| 维度 | Composite Action | Docker Container Action |
|---|---|---|
| 启动速度 | 快(几秒) | 慢(需要构建镜像,可能 1-2 分钟) |
| 环境隔离 | 依赖 Runner 环境 | 完全隔离 |
| 跨平台 | 依赖 Shell 兼容性 | 只支持 Linux Runner |
| 适用场景 | 简单脚本组合 | 需要特殊环境的复杂工具 |
16.11. 本章总结与能力清单
通过本章的学习,你应该掌握了:
触发器机制
理解 GitHub 事件系统的发布-订阅模型,知道如何使用push、pull_request、schedule、workflow_dispatch等触发器,以及路径过滤的工作原理。Jobs 与 Steps 的执行模型
理解 Jobs 的并发本质和资源隔离机制,掌握使用needs构建依赖链,知道如何通过 Outputs 跨 Job 传递数据。上下文对象系统
知道github、env、secrets、runner、needs等上下文对象的作用,能够使用表达式和内置函数做条件判断。环境变量的三层作用域
理解 Workflow、Job、Step 三个层级的优先级规则,知道如何统一管理配置和传递敏感信息。矩阵策略的数学原理
理解笛卡尔积的生成机制,掌握include、exclude、fail-fast的使用场景。缓存的工作原理
理解缓存键的生成、命中检测、降级策略,知道如何使用actions/cache和 setup Actions 的内置缓存。Actions 的三种复用形态
知道何时使用 Marketplace Actions、Composite Actions、Docker Container Actions,能够创建自己的可复用 Action。











