
Prorise
这是我的博客,分享技术与生活的点点滴滴
Claude Code 工作流:BMAD-METHODS - AI编程下的规范之王
Claude Code 工作流:BMAD-METHODS - AI编程下的规范之王
Prorise第一章. BMAD 的本质:为什么需要它
本章将揭示 “氛围编程” 的致命缺陷,并解释 BMAD 如何通过 “规范驱动” 和 “人在回路” 两大支柱解决这些问题。
注:更详细的关于 BMAD 的方法论说明请跳转至:
1.1. 氛围编程的三大死穴
我们先从一个真实场景开始。
假设你正在用 AI 助手开发一个电商系统,对话进行到第 50 轮时,你突然发现:刚才让 AI 生成的订单服务代码,和 20 轮之前设计的用户服务完全不兼容。API 接口对不上,数据库字段也对不上。更糟糕的是,你已经记不清当时为什么要那样设计了。
这就是 氛围编程凭感觉与 AI 对话式编程,缺乏结构化规划 的典型困境。它有三个致命问题:
死穴一:上下文衰减
AI 对话的上下文窗口是有限的。即使是 Gemini 这样的长上下文模型,当对话超过 100 轮后,早期的关键决策也会被 “遗忘”。你会发现 AI 开始自相矛盾:
- 第 10 轮说用 REST API
- 第 80 轮突然建议改成 GraphQL
- 第 120 轮又回到 REST,但参数结构完全变了
更可怕的是,你自己也会忘记。三个月后回来维护代码,你会盯着屏幕问自己:“当初为什么要这么写?”
死穴二:幻觉累积
AI 在没有约束的情况下,会 “创造性地” 编造不存在的 API、配置项、甚至整个框架。举个例子:
1 | // AI 生成的代码 |
你兴高采烈地复制粘贴,运行后发现 @awesome/auth-kit 这个包压根不存在。回到对话里追问,AI 会一本正经地道歉,然后给你另一个同样不存在的方案。
在氛围编程中,这种幻觉会像滚雪球一样累积。因为没有 “规范文档” 作为事实基准,AI 每次回答都是基于概率模型的即兴发挥。
死穴三:架构漂移
没有预先规划的项目,架构会随着对话的进行而 “漂移”。最初你想做一个简单的 CRUD 应用,聊着聊着变成了微服务架构,再聊着聊着又加上了事件溯源和 CQRS。
这不是说这些技术不好,而是 决策缺乏一致性。你会发现:
- 用户模块用了 RESTful 风格
- 订单模块突然变成 RPC 调用
- 支付模块又引入了消息队列
整个系统像一个缝合怪,每个部分都能跑,但拼在一起就是灾难。
1.2. BMAD 的核心思想:规范驱动 + 人在回路
BMAD 的设计哲学可以用一句话概括:先把规则写清楚,再让 AI 按规则干活。
它通过两个核心机制解决氛围编程的问题:
规范驱动:工件即真相
在 BMAD 中,所有的关键决策都必须固化为 工件持久化的文档或代码,作为后续开发的事实依据。这些工件包括:
| 工件类型 | 作用 | 生命周期 |
|---|---|---|
| 项目简介 (Project Brief) | 定义项目目标和边界 | 整个项目 |
| PRD (产品需求文档) | 详细描述功能需求 | 整个项目 |
| 架构文档 (Architecture Doc) | 规定技术栈和系统设计 | 整个项目 |
| 故事 (Story) | 单个可交付的功能单元 | 单次迭代 |
这些工件不是摆设,而是 AI 的行动指南。当你让 Dev 代理实现一个功能时,它必须严格遵循 PRD 和架构文档中的约定。如果 PRD 里说用 PostgreSQL,Dev 就不能擅自改成 MongoDB。
这就解决了 “幻觉累积” 的问题。因为 AI 不再是凭空想象,而是基于已经确认的文档进行推理。
人在回路:检查点机制
BMAD 不是让 AI 完全自主工作,而是在关键节点设置 人工检查点。整个流程分为四个阶段:

注意那两个虚线箭头,它们代表 必须由人来决定是否继续。具体来说:
检查点 1:Planning → Solutioning
在这个阶段,PO (Product Owner) 代理会生成一份检查清单,验证 PRD 和架构文档是否一致。例如:
- PRD 里提到的 “用户角色管理”,架构文档里有没有对应的数据表设计?
- 架构文档选择了 Redis 做缓存,PRD 里有没有说明缓存失效策略?
这份清单生成后,你必须人工审查。如果发现不一致,回到 Planning 阶段修正文档,而不是带着问题进入开发。
检查点 2:每个 Story 的 Review 阶段
当 Dev 代理完成一个故事的开发后,QA 代理会进行代码审查。审查报告会明确指出:
- 哪些地方符合规范
- 哪些地方需要改进
- 是否可以合并到主分支
这个决定权在你手上。如果 QA 发现了严重问题(比如缺少事务处理),你可以要求 Dev 返工,而不是 “先合并再说”。
这种机制确保了 质量门槛。每个阶段的输出都经过验证,不会把问题遗留到下一个阶段。
1.3. 适用场景判断树
BMAD 不是银弹,它有明确的适用边界。我们用一个决策树来说明:
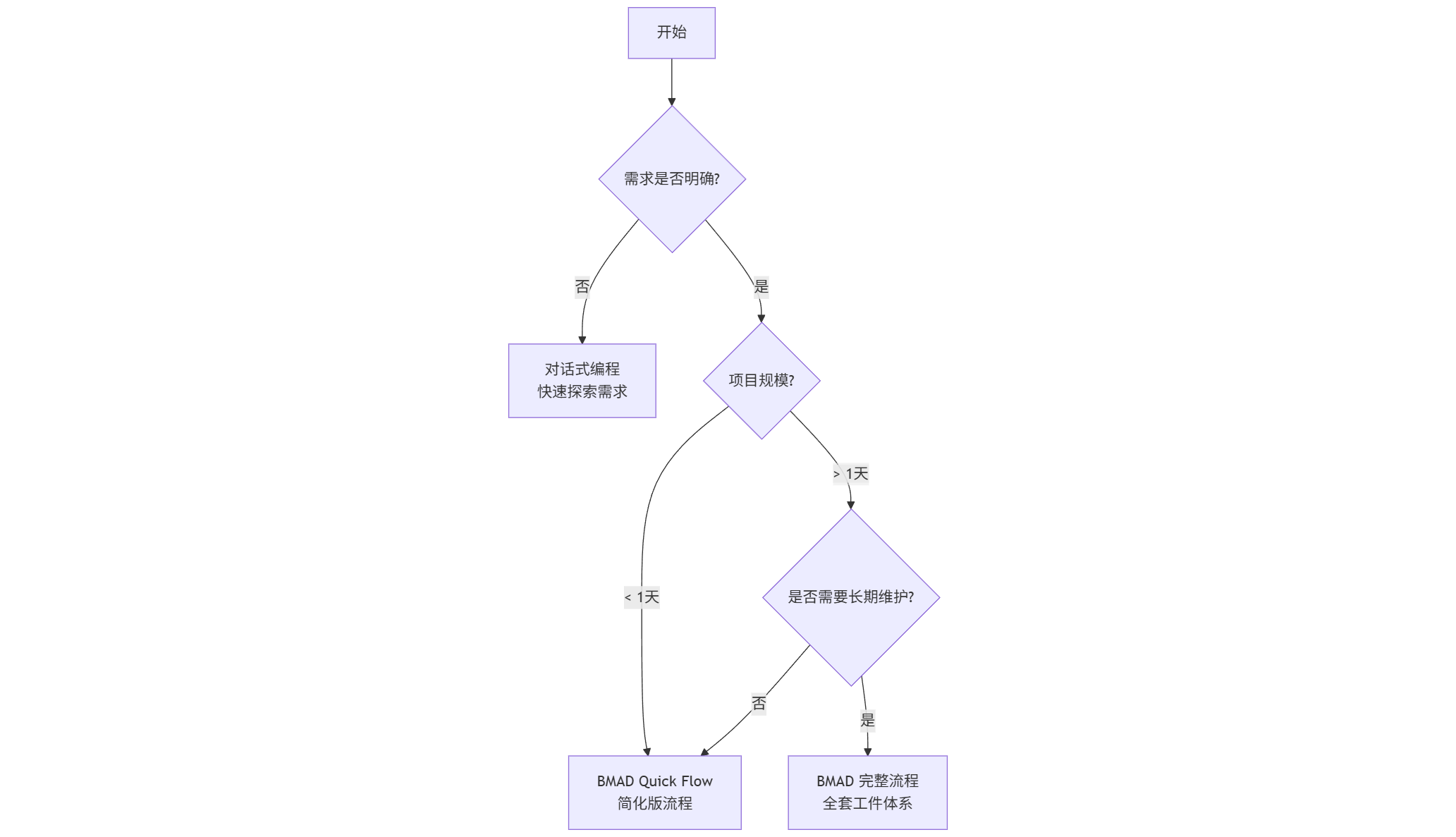
我们逐个解释每个分支:
分支 1:需求不明确 → 对话式编程
如果你还在探索 “到底要做什么”,BMAD 反而会拖慢节奏。这时候应该用对话式编程快速试错:
- 写几个原型验证想法
- 和 AI 讨论不同的技术方案
- 频繁推翻重来
等需求逐渐清晰后,再切换到 BMAD 进行正式开发。
分支 2:小项目(< 1 天)→ Quick Flow
对于简单的功能(比如给现有系统加一个导出 Excel 的接口),完整的 BMAD 流程过于重量级。这时可以用简化版:
- 直接写一个简单的 Story(跳过 PRD)
- 用 Dev 代理实现
- 用 QA 代理快速审查
这样既保留了 “规范驱动” 的核心思想,又不会陷入文档泥潭。
分支 3:大项目 + 长期维护 → 完整流程
如果你的项目满足以下任一条件,强烈建议用完整的 BMAD 流程:
- 开发周期超过 1 周
- 涉及多个模块或服务
- 需要多人协作(即使是 “你 + AI” 的协作)
- 三个月后还要继续迭代
这种情况下,前期在文档上多花的时间,会在后期以 “减少返工” 的形式百倍偿还。
1.4. 本章总结与决策速查
让我们回顾一下核心要点:
氛围编程的三大死穴
- 上下文衰减:对话越长,早期决策越容易被遗忘
- 幻觉累积:AI 会编造不存在的 API 和配置
- 架构漂移:缺乏规划导致系统变成缝合怪
BMAD 的两大支柱
- 规范驱动:用工件(PRD、架构文档、Story)固化决策
- 人在回路:在关键节点设置人工检查点
决策速查表
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 探索性编程 | 对话式 | 需求未定,频繁试错 |
| 临时脚本 | 对话式 | 一次性任务,无需维护 |
| 小功能增强 | BMAD Quick | 保留规范,简化流程 |
| 新产品开发 | BMAD 完整 | 需要长期维护和迭代 |
| 遗留系统改造 | BMAD 完整 | 风险高,需要严格规划 |
自检问题
在开始一个项目前,问自己三个问题:
- 三个月后,我还能看懂这些代码吗?(如果答案是 “不确定”,用 BMAD)
- 这个项目会不会有第二个人参与?(如果是,用 BMAD)
- 我能接受推倒重来的成本吗?(如果不能,用 BMAD)
第二章. BMAD 角色体系:21 个代理的分工逻辑
本章将拆解 BMAD 的目录结构和角色分工,理解为什么需要 21 个代理,以及它们如何通过工件传递信息。
2.1. 先看看 BMAD 装了什么
在理解角色之前,我们先把 BMAD 的仓库拉下来看看。它以一个 Github 仓库 的形式存在,安装后会在你的项目里生成一个 .bmad 目录。
安装和初始化
1 | npx bmad-method@alpha install |
安装程序会启动一个交互式配置向导。这个过程会问你一系列问题,我们逐个解释:
问题 1:安装目录
1 | ? Installation directory: C:\Users\YourName\Desktop\BMAD |
这个没什么好说的,选一个你想放项目的地方。
问题 2:选择开发工具
1 | ? Select tools to configure: |
必须按空格键选中,然后按回车确认。只是高亮不算选中。
这里选择你用的 IDE。我们的教程以 Claude Code 为例,但其他 IDE 的流程本质上是一样的。
问题 3:配置语言和输出
1 | ? What shall the agents call you? Prorise |
这里有个关键点:对话语言和文档语言可以分开设置。
- 对话语言:AI 用什么语言跟你交流
- 文档语言:PRD、架构文档等工件用什么语言输出
我选了中文,因为 PRD 和架构文档用中文写更自然。但如果你的团队是国际化的,可以选英文。
问题 4:选择模块
1 | ? Select modules to install: |
这里有三个模块:
| 模块 | 全称 | 作用 |
|---|---|---|
| BMM | BMad Method | 完整的敏捷开发流程,包含 21 个 Agent 和 50+ 工作流 |
| BMB | BMad Builder | 用来创建自定义 Agent 和工作流 |
| CIS | Creative Innovation Suite | 创新和头脑风暴工具 |
第一次使用建议只选 BMM,因为想先体验标准流程。等熟悉了再用 BMB 定制自己的 Agent。
问题 5:是否启用 TTS
1 | ? Claude Code supports TTS (Text-to-Speech). Would you like to enable it? No |
这个功能可以让 AI 用语音跟你对话。我选了 No,因为这部分我们不需要,没必要下载额外依赖。
安装完成后,会看到:
1 | ✨ BMAD is ready to use! |
2.2. 目录结构:核心文件在哪里
安装完后,项目里会多两个目录:
1 | 📂 BMAD/ |
_bmad 目录:三个模块的分工
这个目录包含三个模块:
1 | _bmad/ |
我们逐个拆解。
core 模块:基础能力层
1 | core/ |
这里的 bmad-master 是总控 Agent,负责协调其他所有 Agent。它就像一个项目经理,知道什么时候该叫哪个 Agent 出来干活。
tasks 目录里是可复用的任务定义。比如 review-adversarial-general.xml 定义了 对抗性审查让一个 AI 挑战另一个 AI 的输出,找出逻辑漏洞和潜在问题 的逻辑:让一个 AI 挑战另一个 AI 的输出,找出问题。
这解决了什么问题?防止 AI 自嗨。如果只有一个 AI 生成代码,它可能会觉得自己写得很完美。但如果有另一个 AI 专门挑刺,就能发现很多隐藏的问题。
bmm 模块:21 个角色的定义
1 | bmm/ |
这里才是真正的 21 个角色和 50+ 工作流。
打开 agents/analyst.md,你会看到需求分析师的完整定义:
1 | # Business Analyst |
每个 Agent 的定义包含三个部分:
- 职责边界:这个 Agent 负责什么,不负责什么
- 工作方式:这个 Agent 怎么思考问题
- 输出规范:这个 Agent 产出什么格式的工件
这解决了什么问题?防止角色越界。如果没有明确的职责定义,Analyst 可能会开始讨论技术实现,Architect 可能会开始质疑需求合理性。但有了这些定义,每个 Agent 只关注自己的领域。
workflows 目录:四阶段的具体流程
这个目录是 BMAD 的核心。我们重点看四个阶段的目录结构。
1-analysis 阶段:
1 | 1-analysis/ |
每个工作流都拆成了多个步骤。比如 create-product-brief 有 6 个步骤:初始化 → 愿景 → 用户 → 指标 → 范围 → 完成。
为什么要拆这么细?因为大脑一次只能处理 7±2 个信息块。如果一次性问你 20 个问题,你会懵。但如果分成 6 个步骤,每个步骤问 3-4 个问题,你就能清晰地回答。
2-plan-workflows 阶段:
1 | 2-plan-workflows/ |
PRD 工作流有三种模式:
| 模式 | 步骤数 | 适用场景 |
|---|---|---|
| 创建模式 (steps-c) | 12 | 从零开始写 PRD |
| 编辑模式 (steps-e) | 4 | 修改现有 PRD |
| 验证模式 (steps-v) | 13 | 检查 PRD 质量 |
这解决了什么问题?防止文档质量参差不齐。如果没有验证模式,你可能会写出一份 “看起来很完整,但实际上漏洞百出” 的 PRD。但有了 13 个验证步骤,每个步骤检查一个维度(完整性、一致性、可测试性等),就能确保 PRD 的质量。
3-solutioning 阶段:
1 | 3-solutioning/ |
这个阶段的关键是 check-implementation-readiness。它会检查:
- PRD 和架构文档是否一致?
- 所有 Epic 都有对应的技术方案吗?
- 技术栈能满足非功能需求吗?
- 有没有遗漏的依赖或风险?
只有通过这 6 个检查,才能进入开发阶段。这就是我们在第一章提到的 “人在回路” 检查点。
4-implementation 阶段:
1 | 4-implementation/ |
这个阶段的工作流是循环的:规划 → 开发 → 评审 → 回顾 → 下一个迭代。
bmad-quick-flow:
1 | bmad-quick-flow/ |
Quick Flow 是完整流程的简化版。它只有两个工作流:
- quick-spec:4 步生成技术规格说明
- quick-dev:6 步完成开发(包含自检和对抗性审查)
注意 quick-dev 的第 5 步是 “对抗性审查”。即使是简化版,也保留了质量检查机制。
testarch 目录:
1 | testarch/ |
这个目录包含 35 个测试知识文档,涵盖 TDD、契约测试、性能测试等各种测试模式。
为什么需要这么多测试文档?因为测试是最容易被忽略的环节。很多开发者写完代码就觉得完成了,但实际上没有测试的代码是不可靠的。BMAD 通过提供完整的测试知识库,确保每个 Story 都有对应的测试策略。
_config 目录:配置和清单
1 | _config/ |
这些 .customize.yaml 文件是用来定制 Agent 行为的。打开 bmm-dev.customize.yaml,你会看到:
1 | agent: |
你可以修改这些配置,让 Dev Agent 使用你喜欢的代码风格。
各种 manifest 文件记录了系统里有哪些 Agent、工作流、任务。打开 agent-manifest.csv:
1 | id,name,module,path,enabled |
这个清单的作用是 让系统知道有哪些 Agent 可用。当你输入 *agent pm 时,系统会查这个清单,找到 bmm-pm 对应的定义文件,然后加载它。
_bmad-output 目录:工件的归宿
1 | _bmad-output/ |
这个目录一开始是空的。当你跑完工作流后,所有生成的文档、代码、测试报告都会存在这里。
比如跑完 PRD 工作流后:
1 | _bmad-output/ |
跑完架构设计后:
1 | _bmad-output/ |
注意文件名都带了日期。这是因为 工件是有版本的。如果你三个月后修改了 PRD,会生成一个新的文件 prd-20250415.md,而不是覆盖旧文件。这样你可以随时对比不同版本的差异。
2.3. 四个阶段在做什么
现在我们知道了 BMAD 的目录结构,接下来理解四个阶段的分工逻辑。
Analysis:把模糊想法变成清晰问题
这个阶段的目标是:把 “我想要个用户管理” 变成 “需要哪些字段、权限、接口”。
为什么需要这个阶段
因为大部分需求一开始都是模糊的。
产品说 “我想要个用户管理”,但他没说:
- 用户有哪些字段?姓名、邮箱、手机号?
- 用户有哪些权限?管理员、普通用户、访客?
- 用户怎么登录?账号密码、手机验证码、第三方登录?
如果直接开始写代码,这些问题会在实现过程中不断冒出来。每次冒出来,都要停下来讨论,然后改代码。
Analysis 阶段就是把这些问题提前问清楚。
这个阶段产出什么
一个 产品简报包含背景、目标、约束、风险、成功标准的需求分析文档,包含:
- 背景:为什么要做这个功能
- 目标:这个功能要解决什么问题
- 约束:有哪些限制条件(时间、预算、技术栈)
- 风险:可能遇到哪些问题
- 成功标准:怎么判断这个功能做成功了
对比:有 Analysis vs 没有 Analysis
没有 Analysis 的情况:
1 | 你:帮我写个用户管理模块 |
改了 5 次,每次都要重新生成代码。
有 Analysis 的情况:
1 | Analyst:这个用户管理模块,需要支持哪些功能? |
一次性把需求问清楚,后面不用反复改。
Planning:拆任务表和里程碑
这个阶段的目标是:把需求拆成 10 个可执行的任务,排好优先级。
为什么需要这个阶段
因为一个大需求直接开始写,很容易失控。
“用户管理模块” 听起来很简单,但实际上包含:
- 用户表设计
- 注册接口
- 登录接口
- 权限校验
- 角色管理
- 第三方登录
- 用户列表
- 用户详情
- 用户编辑
- 用户删除
如果不拆任务,你会在这 10 个功能之间跳来跳去,最后哪个都没做完。
Planning 阶段就是把大需求拆成小任务,一个一个做。
这个阶段产出什么
两个工件:
- PRD 文档:详细描述每个功能的用户故事和验收标准
- Epic 和 Story 列表:把 PRD 拆分成可执行的开发任务
PRD 的核心是 验收标准。它用可验证的条件定义 “什么叫做完了”:
1 | ## Story: 用户登录 |
注意每一条都是 可测试的。QA 代理在审查代码时,会逐条检查这些标准是否满足。
Solutioning:定技术方案和架构
这个阶段的目标是:定技术栈、画架构图、定接口规范。
为什么需要这个阶段
因为同一个需求,可以有多种实现方式。
“用户管理模块” 可以用:
- 技术栈:Node.js + Express + MySQL,或者 Python + Django + PostgreSQL
- 架构:单体应用,或者微服务
- 认证方式:JWT,或者 Session
如果不提前定方案,开发过程中会不断纠结 “用哪个更好”。
Solutioning 阶段就是把技术方案定下来,后面不用纠结。
这个阶段产出什么
两个工件:
- 架构文档:描述系统的整体架构、技术栈、关键设计决策
- 接口契约:定义所有接口的请求和响应格式(OpenAPI 格式)
架构文档的核心是 约束而非自由。它不是告诉 Dev “你可以用任何数据库”,而是明确规定 “必须用 PostgreSQL,且所有表必须有 created_at 和 updated_at 字段”。
Implementation:写代码和测试
这个阶段的目标是:按任务写代码,每个任务一个 Story。
为什么用 Story 而不是直接修改文件
因为 Story 是可追溯的。
一个 Story 包含:
- 变更说明:为什么要改
- 影响范围:改了哪些文件
- 代码 diff:具体改动
- 测试用例:如何验证
如果直接修改文件,三个月后你不记得为什么这么改。但如果用 Story,你可以随时查看这个 Story 的变更说明。
这个阶段产出什么
每个任务产出一个 Story 文档:
1 | # Story 1.1: 用户注册接口 |
2.4. 角色切换的黄金法则
BMAD 的一个核心原则是:一次只用一个代理,且必须在新的干净对话中启动。
什么是角色污染?
假设你在同一个对话中先用 SM 创建了一个 Story,然后直接让 Dev 实现。这时候会发生什么?
AI 的上下文中既有 SM 的 “规划思维”,又有 Dev 的 “实现思维”。结果就是 Dev 可能会:
- 擅自修改 Story 的验收标准(因为它觉得 “这样实现更简单”)
- 偏离架构文档的约束(因为它 “忘记” 了架构师的规定)
这就是角色污染。两个角色的职责混在一起,导致输出质量下降。
正确的切换方式
步骤 1:完成当前角色的任务
在 SM 对话中,创建完 Story 后,把内容保存到项目目录:
1 | docs/stories/story-1.1.md |
步骤 2:开启新的干净对话
关闭当前对话,打开一个全新的对话窗口。
步骤 3:激活新角色
在新对话中输入:
1 | *agent dev |
这时 Dev 代理会读取 docs/stories/story-1.1.md 文件,基于这份文档开始工作。它的上下文中 只有 Story 的内容,没有 SM 的思考过程。
为什么要这么麻烦?
因为这确保了 职责的单一性。每个代理只关注自己的任务:
- SM 只负责拆分 Story,不关心怎么实现
- Dev 只负责实现功能,不关心为什么要这样拆分
- QA 只负责审查质量,不关心实现细节
这种分离带来了两个好处:
- 输出质量更高:每个代理都能专注于自己的领域,不会被其他角色的思维干扰
- 可追溯性更强:每个阶段的输出都有独立的文档,三个月后回来看,能清楚地知道 “当时为什么这么做”
2.5. 本章总结与角色速查表
让我们回顾一下核心要点:
BMAD 的目录结构
| 目录 | 作用 | 关键文件 |
|---|---|---|
| core/ | 基础能力层 | bmad-master.md, 对抗性审查任务 |
| bmm/ | 21 个角色和 50+ 工作流 | 各个 Agent 定义,四阶段工作流 |
| _config/ | 配置和清单 | Agent 定制文件,manifest 清单 |
| _bmad-output/ | 工件输出 | PRD、架构文档、Story 等 |
四个阶段的分工
| 阶段 | 目标 | 输出工件 |
|---|---|---|
| Analysis | 把模糊想法变成清晰问题 | 产品简报 (Product Brief) |
| Planning | 拆任务表和里程碑 | PRD + Epic/Story 列表 |
| Solutioning | 定技术方案和架构拆解 Story | 架构文档 + 接口契约 |
| Implementation | 写代码和测试 | Story 文档 + 代码 |
角色切换检查清单
在切换角色前,问自己三个问题:
如果三个问题的答案都是 “是”,才能切换到下一个角色。
第三章. BMAD 四阶段工作流:从需求到上线
本章将深入四个阶段的具体操作步骤,理解每个阶段的关键决策点和工件传递机制。核心思想:每个阶段都是下一个阶段的 “地基”,地基不牢,地动山摇。
🗺️ BMAD 方法论概览
| 阶段 | 核心内容 | 典型交付物 |
|---|---|---|
| Phase 1 - 分析 | 市场研究、需求分析、产品定义 | 产品简介、PRD、竞品分析 |
| Phase 2 - 架构 | 技术架构、系统设计 | 架构文档、技术选型 |
| Phase 3 - 实施 | Epic/Story 拆分、开发 | 功能规格、代码 |
| Phase 4 - 测试/发布 | 质量保证、部署 | 测试计划、发布 |
3.1. Analysis 阶段:把模糊想法变成可执行需求
这个阶段的目标是 回答三个问题:我们要做什么?为什么要做?怎么判断做成功了?
启动 Analyst 代理
在 Claude Code 中打开一个新对话,输入:
1 | *agent analyst |
或者简写:
1 | *analyst |
系统会加载 _bmad/bmm/agents/analyst.md 文件,激活需求分析师角色(Mary)。这时你会看到:
1 | 📊 Business Analyst (Mary) 已激活 |
注意:代理激活后会立即加载 _bmad/bmm/config.yaml 配置文件,读取项目名称、输出文件夹、用户名、沟通语言等设置。
WS(Workflow Status)
一个轻量级状态追踪工具,专门用来回答一个关键问题:
“我现在该做什么?” 🎯
🔍 它具体做什么?
- 读取状态文件 — 它会查找 bmm-workflow-status.yaml 文件,里面记录了项目的整个工作流程进度
- 展示当前状态 — 告诉你:
- 项目类型和级别
- 已完成的工作流
- 待处理的工作流
- 可选的工作流 - 指引下一步 — 明确指出:
- 下一个该做的工作流是什么
- 应该调用哪个代理 来执行
- 具体的命令是什么 - 管理进度 — 允许你:
- 标记工作流为「已完成」
- 跳过某些工作流
- 查看完整的状态文件
想象一下,你正在做一个大型项目,涉及需求分析、架构设计、测试等多个阶段… WS 就像一个进度灯塔 ,随时告诉你现在在哪里、下一步要去哪里!
头脑风暴:挖掘真实需求
第一步是进行头脑风暴。在 Analyst 代理的菜单中,选择 [BP] 或输入 BP(支持模糊匹配)。
Analyst 会启动 _bmad/core/workflows/brainstorming/workflow.md 工作流,开始引导式头脑风暴:
1 | 让我们开始头脑风暴会话。我会使用多种创意技巧来帮助你探索想法。 |
Analyst 的提问方式:它不问 “你想要什么功能”,而是问 “你遇到了什么问题”。
这解决了什么问题?防止需求蔓延。如果直接问 “你想要什么功能”,产品经理会列出 20 个功能。但如果问 “你遇到了什么问题”,他会聚焦在核心痛点上。
假设你回答:
1 | 我想做一个用户权限管理系统,因为当前权限分配太随意,没有审计记录。 |
Analyst 会继续追问:
1 | 很好!让我们深入挖掘一下: |
这个过程会持续多轮对话,Analyst 会使用不同的创意技巧(从 brain-methods.csv 中加载),确保探索足够深入。
研究:市场与竞品分析
头脑风暴后,如果需要更深入的研究,可以选择 [RS] 启动研究流程:
1 | [RS] 引导式研究 |
Analyst 会启动 _bmad/bmm/workflows/1-analysis/research/workflow.md,引导你进行:
- 市场研究:目标市场规模、趋势、机会
- 竞品分析:主要竞争对手的功能对比
- 技术研究:实现方案的技术可行性
研究结果会保存到 {output_folder}/analysis/research-{date}.md。
创建产品简报
头脑风暴和研究结束后,选择 [PB] 创建产品简报:
1 | [PB] 创建产品简报 |
Analyst 会启动 _bmad/bmm/workflows/1-analysis/create-product-brief/workflow.md 工作流。这个工作流使用 step-file 架构,逐步执行:
步骤 1:初始化
1 | 我将创建一份产品简报,包含以下部分: |
步骤 2-N:逐步构建
工作流会按顺序加载 steps/step-01-init.md、step-02-xxx.md 等文件,每个步骤:
- 读取完整的步骤文件
- 按顺序执行所有指令
- 等待用户输入(如果有菜单)
- 更新文档的 frontmatter 中的
stepsCompleted数组 - 加载下一个步骤文件
关键规则:
- 🛑 绝不 同时加载多个步骤文件
- 📖 总是 在行动前完整读取步骤文件
- 🚫 绝不 跳过步骤或优化顺序
- 💾 总是 在完成步骤后更新 frontmatter
所有步骤完成后,Analyst 会生成一份产品简报:
1 | --- |
这份文档会自动保存到 {output_folder}/planning/product-brief-{date}.md(路径由 config.yaml 中的 planning_artifacts 配置决定)。
派对模式 (Party Mode) 是什么
想象一下——一场多位专家代理齐聚一堂的头脑风暴盛宴!这是一个多代理协作讨论模式,让所有已安装的 BMAD 专家代理们参与进来,各自发挥专长,进行自然流畅的集体对话!
🤖 它如何运作?
- 集结专家团队 — 派对模式会加载所有 BMAD 代理的名单(比如 Mary 是商业分析师,还有产品经理、架构师、开发者、用户体验设计师等各路专家)
- 智能匹配参与 — 根据你提出的话题或问题,系统会智能选择 2-3 位最相关的专家来参与讨论,确保多角度观点的碰撞!
- 角色扮演对话 — 每个代理都会保持自己独特的性格和专业风格,互相引用、补充、甚至辩论,就像真人团队会议一样生动!
- 协作解决问题 — 代理之间可以互相提问、建立共识、深化见解,最终为你提供全面、多维度的分析!
从业务分析的角度看,这就像把跨职能团队的专家们聚集在一张桌子旁——战略分析师、产品人、技术大牛、设计达人齐上阵!不同视角的碰撞往往能发现单一视角无法察觉的机会和风险!🔍✨
3.2. Planning 阶段:PRD 与架构文档的双保险
这个阶段的目标是 把需求翻译成两份文档:PRD(给开发看的功能清单)和架构文档(给开发看的技术约束)。
启动 PM 代理
关闭 Analyst 对话,开启一个新对话,输入:
1 | *agent pm |
或者简写:
1 | *pm |
系统会加载 _bmad/bmm/agents/pm.md 文件,激活产品经理角色(John)。
1 | 📋 主菜单 |
创建 PRD
在 PM 代理的菜单中,选择 [CP] 创建 PRD:
1 | [CP] 创建产品需求文档(PRD) |
PM 会启动 _bmad/bmm/workflows/2-plan-workflows/prd/workflow.md 工作流。这个工作流是 三模态 的:
| 模式 | 触发方式 | 适用场景 |
|---|---|---|
| 创建模式 | create prd 或 -c | 从零开始写 PRD |
| 验证模式 | validate prd 或 -v | 检查现有 PRD 质量 |
| 编辑模式 | edit prd 或 -e | 修改现有 PRD |
如果模式不明确,PM 会询问:
1 | PRD 工作流 - 选择模式: |
创建模式流程:
PM 会按顺序执行 steps-c/step-01-init.md 等步骤文件,引导你:
- 发现输入文档:自动查找产品简报、项目上下文等
- 定义愿景:用一句话描述项目成功后的改变
- 识别用户:主要用户和次要用户
- 拆分 Epic:将需求组织成大的功能模块
- 编写用户故事:为每个 Epic 编写详细的用户故事
- 定义验收标准:每个故事的可测试标准
- 设置优先级:P0/P1/P2 划分
- 定义非功能需求:性能、安全、可用性等
关键步骤示例:
步骤 5:编写用户故事
1 | 让我们为 Epic 1 编写用户故事: |
注意每个 Story 都遵循固定格式:作为 [角色],我需要 [功能],以便 [目标]。
步骤 8:定义非功能需求
1 | 现在让我们定义非功能需求(NFR): |
所有步骤完成后,PM 会生成完整的 PRD,保存到 {planning_artifacts}/prd.md。
验证 PRD 质量
PRD 生成后,不要急着进入下一步。选择 [VP] 运行验证模式:
1 | [VP] 验证产品需求文档(PRD) |
PM 会启动验证流程(steps-v/step-v-01-discovery.md),进行 13 项验证:
- 完整性:所有 Epic 都有对应的 Story 吗?
- 一致性:Story 之间有没有矛盾?
- 可测试性:验收标准是否可验证?
- 优先级:P0/P1/P2 的划分是否合理?
- 可追溯性:每个 Story 是否都能追溯到产品简报?
验证报告会指出问题:
1 | ## 验证报告 |
根据报告修正 PRD,直到所有验证项都通过。
启动 Architect 代理
PRD 验证通过后,关闭 PM 对话,开启新对话:
1 | *agent architect |
或者简写:
1 | *architect |
系统会加载 _bmad/bmm/agents/architect.md 文件,激活架构师角色(Winston)。
1 | 请选择菜单项: |
创建架构文档
在 Architect 代理的菜单中,选择 [CA]:
1 | [CA] 创建架构文档 |
Architect 会启动 _bmad/bmm/workflows/3-solutioning/create-architecture/workflow.md 工作流,这个工作流有多个步骤:
步骤 1:发现输入文档
1 | 我将基于 PRD 创建架构文档。让我先查找相关文档... |
步骤 2-N:逐步设计
工作流会引导你完成:
- 技术栈选择:语言、框架、数据库等
- 系统架构:整体架构图和组件划分
- 数据模型:实体关系和表结构
- API 规范:所有接口的请求/响应格式
- 编码规范:命名约定、错误处理、日志等
- 部署架构:部署方式和基础设施
关键步骤示例:
步骤 2:选择技术栈
1 | 根据需求,我建议以下技术栈: |
这里的关键是 每个选择都要有理由。不是 “我们用 PostgreSQL”,而是 “我们用 PostgreSQL,因为它支持 JSONB,适合存储审计日志的复杂结构”。
步骤 4:设计数据模型
1 | 让我们设计核心数据模型: |
步骤 6:定义 API 规范
1 | 让我们定义 API 规范: |
所有步骤完成后,Architect 会生成完整的架构文档,保存到 {planning_artifacts}/architecture.md。
Planning 阶段的检查清单
在进入下一个阶段前,确认以下问题:
- [ ] PRD 是否通过了验证?
- [ ] 架构文档是否明确了技术栈?
- [ ] 数据模型是否支持所有 Story?
- [ ] API 规范是否完整(包含所有接口)?
- [ ] 编码规范是否明确(命名、错误处理、日志)?
3.3. Solutioning 阶段:Epic 与 Story 的创建
这个阶段的目标是 把 PRD 和架构文档转换成可执行的 Epic 和 Story 文件
在开发尤其是 Agile/敏捷开发 和 Scrum(阶段性冲刺) 中,Epic(史诗) 是一个项目管理术语,而不是一种代码语法
Story 全称是 User Story(用户故事)。它是 Agile 开发中 最小的需求描述单位。
什么叫“故事”而不是“功能”?因为它是 从用户的视角 来描述需求的,而不是从技术的视角。它强调的是 价值。
作为一个 <角色>, 我想要 <执行某个动作>, 以便于 <获得某种价值/解决某个问题>。
| 概念 | 形象比喻 | 关注点 | 典型周期 |
|---|---|---|---|
| Epic | 整部电影 | 宏观愿景、大模块 | 1~3 个月 |
| Story | 电影里的一个场景 | 用户能感知到的功能 | 2~5 天 |
| Task | 摄像机架设/灯光调试 | 具体的执行步骤 | 几小时~1 天 |
| Scrum | 整个剧组的拍摄日程表 | 流程、节奏、协作 | 持续进行 |
创建 Epic 和 Story
继续使用 PM 代理(或重新激活),选择 [ES]:
1 | [ES] 从 PRD 创建 Epic 和用户故事(架构完成后必需) |
PM 会启动 _bmad/bmm/workflows/3-solutioning/create-epics-and-stories/workflow.md 工作流。
步骤 1:验证前置条件
工作流首先检查:
1 | 正在验证前置条件... |
步骤 2-N:逐步创建
工作流会:
- 提取 Epic:从 PRD 中识别所有 Epic
- 创建 Epic 文件:为每个 Epic 生成详细文档
- 提取 Story:从 PRD 中识别所有用户故事
- 创建 Story 条目:将 Story 组织到对应的 Epic 中
- 添加 BDD 场景:为每个 Story 编写 Given-When-Then 场景
- 添加技术任务:为每个 Story 拆分技术实现任务
最终生成的文件结构:
1 | {planning_artifacts}/ |
每个 Epic 文件包含:
1 | # Epic 1: 角色管理 |
实现就绪检查
Epic 和 Story 创建完成后,运行实现就绪检查。可以选择 PM 代理的 [IR] 或 Architect 代理的 [IR]:
给予 PM 【IR】 功能是因为我们在拆分 epic 的时候是 PM 视角拆分的,他可以继续延续上下文进行审查
1 | [IR] 实现就绪审查 |
PM 或 Architect 会启动 _bmad/bmm/workflows/3-solutioning/check-implementation-readiness/workflow.md 工作流,进行 6 项检查:
检查 1:文档一致性
1 | 检查 PRD 和架构文档是否一致... |
检查 2:Story 完整性
1 | 检查 Story 是否完整... |
检查 3:依赖关系
1 | 检查 Story 之间的依赖关系... |
检查 4:技术风险
1 | 识别技术风险... |
检查 5:资源评估
1 | 评估开发资源... |
检查 6:生成检查报告
1 | ## 实现就绪检查报告 |
根据报告修正问题,直到所有检查项都通过。
Solutioning 阶段的检查清单
在进入下一个阶段前,确认以下问题:
- [ ] Epic 和 Story 文件是否已创建?
- [ ] 所有 Story 是否都有完整的验收标准和技术任务?
- [ ] Story 之间的依赖关系是否清晰?
- [ ] 技术风险是否已识别并有应对方案?
- [ ] 实现就绪检查是否通过?
3.4. Implementation 阶段:故事驱动的开发循环
这个阶段的目标是 按 Story 写代码,每个 Story 一个完整的开发-审查循环。
启动 SM 代理
关闭 PM/Architect 对话,开启新对话:
1 | *agent sm |
或者简写:
1 | *sm |
系统会加载 _bmad/bmm/agents/sm.md 文件,激活 Scrum Master 角色(Bob)。
Sprint 规划
首先,选择 [SP] 生成或更新 sprint 状态文件:
1 | [SP] 生成或重新生成 sprint-status.yaml(Epic+Story 创建后必需) |
SM 会启动 _bmad/bmm/workflows/4-implementation/sprint-planning/workflow.yaml 工作流,从 Epic 文件中提取所有 Story,生成 {implementation_artifacts}/sprint-status.yaml:
1 | project_name: "用户权限管理系统" |
这个文件会跟踪所有 Story 的状态:draft → approved → in_progress → review → done。
创建 Story 文件
选择 [CS] 创建下一个 Story 文件:
1 | [CS] 创建 Story(准备 Story 用于开发) |
SM 会启动 _bmad/bmm/workflows/4-implementation/create-story/workflow.yaml 工作流:
- 读取 sprint-status.yaml:找到下一个待开发的 Story
- 加载相关文档:PRD、架构文档、Epic 文件
- 创建 Story 文件:生成详细的 Story 文件,包含:
- Story 描述和验收标准
- BDD 场景
- 技术任务和子任务
- 相关文档引用
- 实现指南
生成的 Story 文件示例:
1 | --- |
Story 文件会保存到 {implementation_artifacts}/{story_key}.md。
启动 Dev 代理
Story 文件创建完成后,关闭 SM 对话,开启新对话:
1 | *agent dev |
或者简写:
1 | *dev |
系统会加载 _bmad/bmm/agents/dev.md 文件,激活开发者角色(Amelia)。
开发 Story
在 Dev 代理的菜单中,选择 [DS]:
1 | [DS] 执行 Dev Story 工作流(完整的 BMM 路径,包含 sprint-status) |
Dev 会启动 _bmad/bmm/workflows/4-implementation/dev-story/workflow.yaml 工作流:
- 读取 Story 文件:加载完整的 Story 文件和相关文档
- 按顺序执行任务:严格按照 Story 文件中的任务顺序执行
- 遵循 TDD 原则:每个任务先写测试,再写实现
- 更新 Story 状态:完成任务后更新 Story 文件中的复选框
关键规则:
- 🛑 绝不 跳过任务或重新排序
- 📖 总是 先读取完整的 Story 文件
- ✅ 总是 先写测试,再写实现
- 💾 总是 完成任务后更新 Story 文件
- 🚫 绝不 在测试失败时继续下一个任务
开发过程示例:
1 | 正在加载 Story 1.1... |
代码审查
Story 开发完成后,选择 [CR] 进行代码审查:
1 | [CR] 执行彻底的代码审查(强烈推荐,使用新上下文和不同 LLM) |
Dev 会启动 _bmad/bmm/workflows/4-implementation/code-review/workflow.yaml 工作流。这个工作流是 对抗性的,会:
- 挑战一切:代码质量、测试覆盖、架构合规、安全性、性能
- 找出问题:每个 Story 必须找出 3-10 个具体问题
- 提供修复建议:可以自动修复(需用户批准)
审查报告示例:
1 | ## 代码审查报告:Story 1.1 |
根据报告修正问题,然后重新提交审查。
循环继续
Story 1.1 完成后,回到 SM 对话:
1 | [CS] 创建 Story |
SM 会根据 sprint-status.yaml 和依赖关系,推荐下一个 Story:
1 | Story 1.1 已完成 ✓ |
重复 SM → Dev → CR 的循环,直到所有 Story 完成。
Implementation 阶段的检查清单
每个 Story 完成后,确认以下问题:
- [ ] 所有验收标准是否已满足?
- [ ] 代码是否通过代码审查?
- [ ] 测试覆盖率是否达标(> 80%)?
- [ ] Story 文件中的任务是否全部完成?
- [ ] Story 状态是否已更新为 Done?
- [ ] sprint-status.yaml 是否已更新?
3.5. 本章总结与完整工作流速查
让我们把四个阶段的操作流程完整串联起来,并给出每个环节的最佳实践建议。****
完整工作流图谱
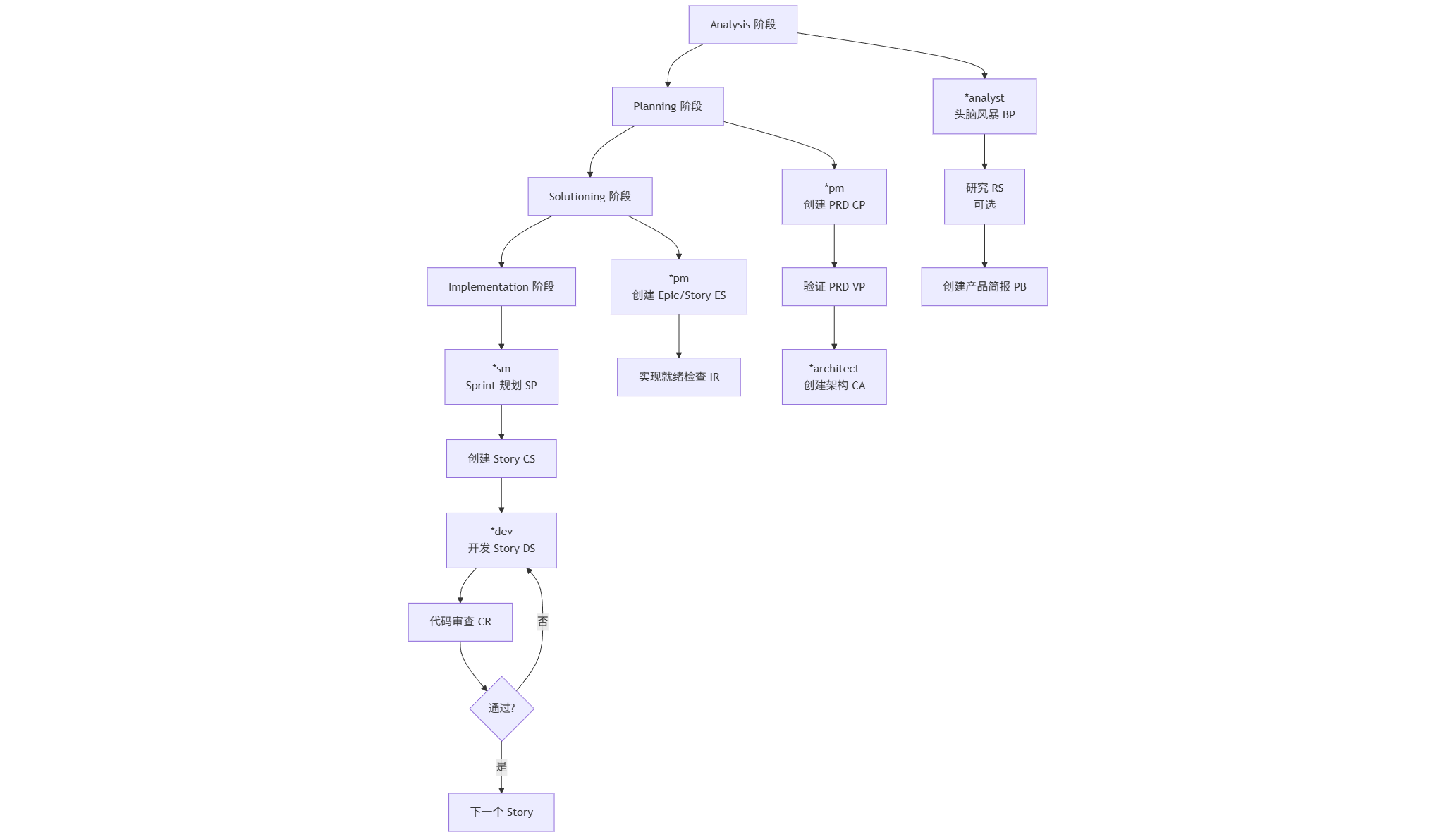
阶段一:Analysis(分析阶段)
目标:把模糊想法变成清晰的产品简报
操作流程:
| 步骤 | 命令 | 说明 | 输出工件 |
|---|---|---|---|
| 1. 激活代理 | *analyst 或 *agent analyst | 激活需求分析师 Mary | - |
| 2. 检查状态 | WS | 查看当前工作流状态(可选) | - |
| 3. 头脑风暴 | BP | 引导式头脑风暴会话 | 头脑风暴记录 |
| 4. 深入研究 | RS | 市场/竞品/技术研究(可选) | 研究报告 |
| 5. 创建简报 | PB | 创建产品简报(6 个步骤) | product-brief-{date}.md |
| 6. 派对模式 | PM | 多代理协作讨论(可选) | - |
关键检查点:
- [ ] 产品简报是否明确了 “为什么要做”?
- [ ] 目标用户是否清晰且完整?
- [ ] 成功指标是否可量化?
- [ ] 范围边界是否明确(包含什么,不包含什么)?
- [ ] 约束条件(时间、预算、技术)是否已识别?
推荐模型:
| 模型 | 推荐理由 | 适用场景 |
|---|---|---|
| Gemini ⭐ | 超大上下文窗口,适合处理大量研究资料;思考模式适合深度分析 | 头脑风暴、研究、产品简报创建 |
| Claude | 理解能力强,擅长结构化输出 | 产品简报创建、派对模式 |
| GPT | 平衡性好,响应速度快 | 头脑风暴、快速迭代 |
为什么推荐 Gemini:Analysis 阶段需要处理大量信息(市场研究、竞品分析、用户访谈),Gemini 的超大上下文窗口可以一次性加载所有资料,避免信息丢失。Thinking 模式能进行深度推理,挖掘隐藏需求。
阶段二:Planning(规划阶段)
目标:把产品简报翻译成 PRD 和架构文档
操作流程:
Part 1:创建 PRD
| 步骤 | 命令 | 说明 | 输出工件 |
|---|---|---|---|
| 1. 激活 PM | *pm 或 *agent pm | 激活产品经理 John | - |
| 2. 检查状态 | WS | 查看当前工作流状态 | - |
| 3. 创建 PRD | CP | 创建模式(12 个步骤) | prd.md |
| 4. 验证 PRD | VP | 验证模式(13 项检查) | 验证报告 |
| 5. 编辑 PRD | EP | 根据验证报告修正(可选) | 更新后的 prd.md |
Part 2:创建架构文档
| 步骤 | 命令 | 说明 | 输出工件 |
|---|---|---|---|
| 1. 激活 Architect | *architect 或 *agent architect | 激活架构师 Winston | - |
| 2. 创建架构 | CA | 创建架构文档(8 个步骤) | architecture.md |
关键检查点:
- [ ] PRD 是否通过了 13 项验证?
- [ ] 所有 Epic 都有对应的 Story 吗?
- [ ] 所有 Story 都有验收标准吗?
- [ ] 非功能需求(NFR)是否明确?
- [ ] 架构文档是否明确了技术栈?
- [ ] 数据模型是否支持所有 Story?
- [ ] API 规范是否完整?
- [ ] 编码规范是否明确?
推荐模型:
| 模型 | 推荐理由 | 适用场景 |
|---|---|---|
| Claude ⭐ | 结构化输出能力最强,擅长编写规范文档;对细节把控严格 | PRD 创建、PRD 验证、架构文档创建 |
| GPT | 平衡性好,适合快速迭代 | PRD 编辑、小幅修正 |
为什么推荐 Claude:Planning 阶段需要输出高质量的结构化文档,Claude 在这方面表现最佳。它能严格遵循模板格式,输出的 PRD 和架构文档条理清晰、逻辑严密。验证模式需要挑刺能力,Claude 的批判性思维更强,而 Gemini1 的幻觉率高,对于这一类需要严苛保证标准的题材,Claude 往往更能发挥出优点
阶段三:Solutioning(方案阶段)
目标:把 PRD 和架构文档转换成可执行的 Epic 和 Story
操作流程:
| 步骤 | 命令 | 说明 | 输出工件 |
|---|---|---|---|
| 1. 激活 PM | *pm | 继续使用 PM 代理 | - |
| 2. 创建 Epic/Story | ES | 从 PRD 提取并创建(4 个步骤) | epics.md + Story 文件 |
| 3. 实现就绪检查 | IR | 6 项检查(可用 PM 或 Architect) | 就绪检查报告 |
关键检查点:
- [ ] 所有 Epic 都有对应的 Story 吗?
- [ ] 所有 Story 都有完整的验收标准吗?
- [ ] 所有 Story 都有技术任务拆分吗?
- [ ] 所有 Story 都有 BDD 场景吗?
- [ ] Story 之间的依赖关系是否清晰?
- [ ] 技术风险是否已识别并有应对方案?
- [ ] PRD 和架构文档是否一致?
推荐模型:
| 模型 | 推荐理由 | 适用场景 |
|---|---|---|
| Claude 3.5 Sonnet ⭐ | 擅长任务拆解和依赖分析;对抗性审查能力强 | Epic/Story 创建、实现就绪检查 |
| Gemini 2.0 Flash Thinking | 思考深度好,适合风险识别 | 实现就绪检查、技术风险评估 |
为什么推荐 Claude:Solutioning 阶段需要精细的任务拆解能力,Claude 能准确识别 Story 之间的依赖关系,避免遗漏。实现就绪检查需要对抗性思维,Claude 的批判性更强,能发现潜在问题。
阶段四:Implementation(实现阶段)
目标:按 Story 写代码,每个 Story 一个完整的开发-审查循环
操作流程:
Part 1:Sprint 规划(SM)
| 步骤 | 命令 | 说明 | 输出工件 |
|---|---|---|---|
| 1. 激活 SM | *sm 或 *agent sm | 激活 Scrum Master Bob | - |
| 2. Sprint 规划 | SP | 生成 sprint-status.yaml | sprint-status.yaml |
| 3. 创建 Story | CS | 创建下一个 Story 文件 | {story_key}.md |
Part 2:开发 Story(Dev)
| 步骤 | 命令 | 说明 | 输出工件 |
|---|---|---|---|
| 1. 激活 Dev | *dev 或 *agent dev | 激活开发者 Amelia | - |
| 2. 开发 Story | DS | 按任务顺序开发(TDD) | 代码 + 测试 |
| 3. 代码审查 | CR | 对抗性审查(强烈推荐) | 审查报告 |
| 4. 修正问题 | 根据审查报告修正 | 重新提交审查 | 修正后的代码 |
Part 3:循环继续
重复 SM → Dev → CR 的循环,直到所有 Story 完成。
关键检查点:
- [ ] sprint-status.yaml 是否已生成?
- [ ] Story 文件是否包含完整的技术任务?
- [ ] 是否严格按照任务顺序开发?
- [ ] 是否遵循 TDD 原则(先写测试)?
- [ ] 所有验收标准是否已满足?
- [ ] 代码是否通过审查?
- [ ] 测试覆盖率是否达标(> 80%)?
- [ ] Story 状态是否已更新为 Done?
推荐模型:
| 模型 | 推荐理由 | 适用场景 |
|---|---|---|
| Claude 后端 ⭐ | 代码质量最高,遵循规范能力强;代码审查最严格 | Story 开发、代码审查 |
| Gemini 前端 ⭐ | 思考深度好,适合复杂逻辑;上下文大,适合大型代码库 | 复杂 Story 开发、架构级重构 |
| GPT(审查) ⭐ | 思考链强大,往往能找到更准确的系统漏洞 | 系统复杂对抗 |
为什么推荐 Claude + Gemini 双模型:
- Claude:代码质量最高,严格遵循架构文档和编码规范。代码审查时批判性最强,能发现细微问题。适合 80% 的常规 Story。
- Gemini Thinking:思考深度更好,适合复杂的算法逻辑、性能优化、架构级重构。超大上下文适合处理大型代码库。适合 20% 的复杂 Story。
双模型协作策略:
- 常规 Story:用 Claude 开发 + Claude 审查
- 复杂 Story:用 Gemini Thinking 开发 + Claude 审查
- 架构级重构:用 Gemini Thinking 开发 + Gemini Thinking 审查
角色切换的黄金法则
规则 1:必须在新对话中切换角色
❌ 错误做法:
1 | 你:*analyst |
✅ 正确做法:
1 | 对话 1: |
为什么:防止角色污染。同一对话中切换角色,AI 的上下文会混杂两个角色的思维方式,导致输出质量下降。
规则 2:必须保存工件后再切换
❌ 错误做法:
1 | Analyst:我已经完成头脑风暴... |
✅ 正确做法:
1 | Analyst:我已经完成头脑风暴... |
为什么:工件是阶段之间的信息传递媒介。如果不保存工件,下一个阶段的代理无法获取前一个阶段的输出。
规则 3:必须通过检查点才能进入下一阶段
❌ 错误做法:
1 | PM:PRD 已创建 |
✅ 正确做法:
1 | PM:PRD 已创建 |
为什么:每个检查点都是质量门槛。跳过检查点,问题会累积到后期,导致大量返工。
规则 4:必须使用正确的菜单命令
❌ 错误做法:
1 | 你:请执行 _bmad/bmm/workflows/2-plan-workflows/prd/workflow.md |
✅ 正确做法:
1 | 你:*pm |
为什么:菜单命令会自动处理前置条件检查、文件路径解析、配置加载等。直接调用工作流文件可能导致路径错误或配置缺失。
常见错误与纠正
| 错误 | 后果 | 正确做法 | 检测方法 |
|---|---|---|---|
| 跳过 Analysis 直接写 PRD | 需求不清晰,后期频繁返工 | 必须先用 Analyst 明确需求 | PRD 中出现大量 “待定” 或 “可选” |
| PRD 未验证就进入开发 | 文档质量差,开发时发现问题 | 必须运行 VP 验证 PRD | 开发时频繁回头修改 PRD |
| 不创建架构文档直接开发 | 技术选型混乱,代码风格不一致 | 必须用 Architect 创建架构文档 | 代码中出现多种技术栈混用 |
| 跳过实现就绪检查 | Story 不完整,依赖关系混乱 | 必须运行 IR 检查 | 开发时发现 Story 缺少关键信息 |
| 不创建 Story 文件直接开发 | 任务不清晰,容易遗漏 | 必须用 SM 创建 Story 文件 | 开发时不知道该做什么 |
| 跳过代码审查直接合并 | 代码质量无保障 | 必须通过 CR 审查 | 上线后出现大量 Bug |
| 不更新 sprint-status.yaml | Story 状态混乱,进度不可追踪 | SM 会自动更新,但需确认 | 不知道哪些 Story 已完成 |
| 在同一对话中切换角色 | 角色污染,输出质量下降 | 必须在新对话中切换 | 代理开始做不属于它的事 |
自检清单
每个阶段结束时,问自己:
Analysis 阶段:
- [ ] 产品简报是否已保存到
{planning_artifacts}/product-brief-{date}.md? - [ ] 产品简报是否明确了目标用户、核心问题、成功指标?
- [ ] 是否进行了必要的研究(市场/竞品/技术)?
Planning 阶段:
- [ ] PRD 是否已保存到
{planning_artifacts}/prd.md? - [ ] PRD 是否通过了
VP验证(13 项检查)? - [ ] 架构文档是否已保存到
{planning_artifacts}/architecture.md? - [ ] 架构文档是否明确了技术栈、数据模型、API 规范、编码规范?
Solutioning 阶段:
- [ ] Epic 和 Story 是否已保存到
{planning_artifacts}/epics.md? - [ ] 所有 Story 是否都有验收标准、BDD 场景、技术任务?
- [ ] 是否通过了
IR实现就绪检查(6 项检查)?
Implementation 阶段:
- [ ] sprint-status.yaml 是否已生成?
- [ ] 每个 Story 是否都有独立的 Story 文件?
- [ ] 每个 Story 是否都通过了代码审查?
- [ ] 测试覆盖率是否达标(> 80%)?
- [ ] sprint-status.yaml 中的 Story 状态是否已更新为 Done?
快速命令速查表
| 代理 | 激活命令 | 常用菜单命令 | 说明 |
|---|---|---|---|
| Analyst | *analyst | BP 头脑风暴RS 研究PB 产品简报 | 需求分析 |
| PM | *pm | CP 创建 PRDVP 验证 PRDEP 编辑 PRDES 创建 Epic/StoryIR 实现就绪检查 | 产品管理 |
| Architect | *architect | CA 创建架构IR 实现就绪检查 | 架构设计 |
| SM | *sm | SP Sprint 规划CS 创建 Story | 迭代管理 |
| Dev | *dev | DS 开发 StoryCR 代码审查 | 开发实现 |
通用命令:
WS:查看工作流状态(所有代理通用)PM:启动派对模式(所有代理通用)MH:重新显示菜单(所有代理通用)DA:解除代理(所有代理通用)
最后的建议
1. 不要急于求成
BMAD 的价值在于 减少返工,而不是 加快初始速度。前期在文档上多花的时间,会在后期以 “避免返工” 的形式百倍偿还,一个模型可能跑的比较旧,我们在后续的篇章中会推出更强大的公族流,并行执行多个模型进行工作,互相获取上下文并行工作…
2. 严格遵循流程
不要跳过任何检查点。每个检查点都是质量门槛,跳过一个,问题就会累积到下一个阶段。
3. 善用派对模式
当你对某个决策不确定时,启动派对模式(PM),让多个代理从不同角度讨论。这能避免单一视角的盲点。
4. 定期回顾工件
每完成一个阶段,回头看看之前的工件(产品简报、PRD、架构文档)。如果发现不一致,立即修正,不要拖到后期。
5. 记录技术债务
代码审查时发现的 “重构建议”,即使暂时不修复,也要记录到技术债务清单中。定期回顾和偿还技术债务。
第四章. BMAD 灵活工作流:现有项目与快速开发
本章将深入讲解 BMAD 在不同场景下的灵活应用。核心思想:不是所有项目都需要完整的四阶段流程,BMAD 提供了多种工作流模式,让你根据项目状态选择最合适的路径。
4.1. 场景识别:你的项目属于哪种类型?
在开始之前,先问自己三个问题:
- 项目状态:这是新项目还是已有代码库?
- 变更规模:你要做的是小功能还是大重构?
- 文档完整度:现有项目有没有完整的文档?
根据答案,BMAD 提供了三种主要工作流:
| 工作流类型 | 适用场景 | 特点 |
|---|---|---|
| BMAD Method(完整流程) | 大型新功能、系统重构、从零开始 | 完整的四阶段:Analysis → Planning → Solutioning → Implementation |
| Quick Flow(快速流程) | 小功能、快速迭代、已有明确需求 | 两步走:Tech Spec → Quick Dev |
| 独立阶段启动 | 项目进行中、只缺某个阶段 | 可以单独启动任意阶段的工作流 |
不管是新项目还是老项目,功能规模才是决定工作流的关键因素。
4.2. Quick Flow:小功能的快速通道
Quick Flow 是 BMAD 为 小功能快速开发 设计的精简流程。它跳过了完整的 Analysis 和 Planning 阶段,直接从技术规格开始。
什么时候用 Quick Flow?
我们先看一个对比表:
| 判断维度 | Quick Flow | BMAD Method |
|---|---|---|
| Story 数量 | 1-5 个 | 10+ 个 |
| 需求明确度 | 已经明确 | 需要讨论 |
| 架构影响 | 不涉及架构变更 | 涉及架构变更 |
| 时间压力 | 紧迫 | 充裕 |
| 团队协作 | 单人或小团队 | 多团队协作 |
✅ 适合的场景:
- 在现有系统中添加小功能(比如给用户表加一个字段)
- 需求已经明确,不需要深入分析(比如产品经理已经给了详细的原型)
- 时间紧迫,需要快速交付(比如修复线上 Bug)
- 功能相对独立,不涉及系统架构变更(比如添加一个导出 Excel 的接口)
❌ 不适合的场景:
- 需要多轮需求讨论的大型功能(比如重构整个权限系统)
- 涉及系统架构变更(比如从单体应用拆分成微服务)
- 需要多团队协作(比如前后端分离的大型功能)
- 有复杂的非功能需求(比如性能优化、安全加固)
Quick Flow 的两步走
Quick Flow 只有两个核心步骤:
步骤 1:Tech Spec(技术规格)
这一步的目标是 把需求翻译成可执行的技术任务。
Tech Spec 不是 PRD,它更关注 “怎么做” 而不是 “为什么做”。一份合格的 Tech Spec 必须包含:
- 验收标准:用 Given-When-Then 格式描述
- 技术任务:明确的文件路径和操作步骤
- 依赖关系:任务之间的先后顺序
- 现有代码模式参考:确保新代码与现有代码风格一致
步骤 2:Quick Dev(快速开发)
这一步的目标是 严格按照 Tech Spec 实现代码。
Quick Dev 的关键特点是 自包含。也就是说,即使你换一个全新的 AI 对话,只要加载 Tech Spec 文件,AI 就能继续实现,不需要读取之前的对话历史。
这解决了什么问题?防止上下文污染。如果在同一个对话中既做规划又做实现,AI 的思维会混乱。但如果用 Tech Spec 作为中间工件,规划和实现就完全分离了。
Quick Flow 的核心代理
Quick Flow 使用一个专门的代理:Quick Flow Solo Dev快速流程专家,负责从技术规格到代码实现的全流程(Barry)。
激活命令:
1 | *quick-flow-solo-dev |
Barry 的菜单只有 5 个核心命令:
| 命令 | 作用 | 何时使用 |
|---|---|---|
[TS] | 架构技术规格 | 第一步,必须先创建 Tech Spec |
[QD] | 快速开发实现 | 第二步,基于 Tech Spec 实现代码 |
[CR] | 代码审查 | 第三步,强烈推荐,使用新上下文审查 |
[WS] | 检查工作流状态 | 随时可用,了解当前进度 |
[PM] | 派对模式 | 可选,多代理协作讨论 |
Tech Spec 的关键要素
一份好的 Tech Spec 必须是 可操作的。什么叫可操作?就是一个从未接触过这个项目的开发者,拿到 Tech Spec 后,能直接开始写代码,不需要问任何问题。
我们用一个反例来说明:
❌ 不可操作的 Tech Spec:
1 | ## 任务 1:创建角色管理功能 |
这个 Tech Spec 有什么问题?
- 没有明确文件路径:开发者不知道代码应该写在哪里
- 没有具体操作:开发者不知道应该创建哪些类、方法
- 没有参考模式:开发者不知道应该遵循什么代码风格
✅ 可操作的 Tech Spec:
1 | ## 任务 1:创建 Role 实体 |
这个 Tech Spec 的优点:
- 文件路径明确:开发者知道要创建
src/models/Role.ts - 操作具体:开发者知道要创建哪些字段、添加哪些装饰器
- 有参考模式:开发者知道应该参考
User.ts的写法
Quick Dev 的执行原则
Quick Dev 在实现代码时,必须遵循三个原则:
原则 1:严格按任务顺序执行
Tech Spec 中的任务是有依赖关系的。比如:
- 任务 1:创建 Role 实体
- 任务 2:实现 RoleService(依赖任务 1)
- 任务 3:创建 API 路由(依赖任务 2)
如果跳过任务 1 直接做任务 2,代码会报错(因为 Role 实体还不存在)。
原则 2:遵循 TDD 原则
每个任务都应该先写测试,再写实现。这确保了代码的可测试性。
原则 3:保持代码风格一致
新代码必须与现有代码风格一致。这就是为什么 Tech Spec 中要包含 “现有代码模式参考”。
Quick Flow 的对抗性审查
Quick Dev 完成后,会进行 对抗性审查。这是 Quick Flow 的一个关键特点。
什么叫对抗性审查?就是让 AI 扮演一个 挑刺的角色,专门找代码的问题。
对抗性审查的规则是:必须找出 3-10 个问题。如果找不出问题,说明审查不够严格,需要重新审查。
这解决了什么问题?防止 AI 自嗨。如果只有一个 AI 生成代码,它可能会觉得自己写得很完美。但如果有另一个 AI 专门挑刺,就能发现很多隐藏的问题。
4.3. 现有项目:棕地项目的处理
大多数情况下,你面对的不是新项目,而是 已有代码库(棕地项目已有代码库的项目,相对于从零开始的绿地项目)。BMAD 提供了专门的工作流来处理这种情况。
棕地项目的三大挑战
挑战 1:缺少文档
很多老项目没有文档,或者文档已经过时。AI 不知道现有代码的架构模式、编码规范、技术栈。
挑战 2:代码风格不一致
老项目可能经过多人维护,代码风格不一致。AI 不知道应该遵循哪种风格。
挑战 3:依赖关系复杂
老项目的模块之间可能有复杂的依赖关系。AI 不知道修改一个模块会影响哪些其他模块。
Document Project:棕地项目的第一步
如果你的项目缺少文档,第一步是 文档化现有项目。
BMAD 提供了一个专门的工作流:Document Project。这个工作流会:
- 扫描代码库:识别技术栈、架构模式、编码规范
- 分析依赖关系:找出模块之间的依赖关系
- 生成文档:创建项目概览、源代码树、架构模式文档
- 生成 project-context.md:这是 AI 代理理解项目的关键文件
激活 Analyst 代理,选择 [DP]:
1 | *analyst |
Document Project 的两种模式
| 模式 | 适用场景 | 扫描范围 |
|---|---|---|
| Full Scan(全扫描) | 首次文档化、大型项目 | 扫描整个代码库 |
| Deep Dive(深度分析) | 特定功能重构、模块迁移 | 聚焦特定模块 |
Full Scan 适合第一次接触项目,或者项目规模较大。它会扫描整个代码库,生成完整的项目文档。
Deep Dive 适合已经熟悉项目,只需要深入分析某个模块。比如你要重构用户模块,可以用 Deep Dive 聚焦分析用户模块的代码。
project-context.md:AI 代理的项目手册
Document Project 最重要的输出是 project-context.md。这个文件包含:
- 技术栈:后端、前端、数据库、工具链
- 编码规范:文件命名、类命名、错误处理、日志
- 架构模式:数据访问模式、API 风格、认证方式
- 关键约定:必须遵守的规则(比如所有数据库操作必须使用事务)
这个文件会被所有 AI 代理自动加载。当 Dev 代理实现代码时,它会参考这个文件,确保新代码与现有代码风格一致。
这解决了什么问题?防止代码风格混乱。如果没有 project-context.md,AI 可能会用自己的风格写代码,导致新代码与老代码格格不入。
棕地项目的工作流选择
文档化完成后,根据功能规模选择工作流:
场景 1:添加小功能(1-5 Story)
使用 Quick Flow:
1 | *quick-flow-solo-dev |
Quick Flow 会自动加载 project-context.md,确保新代码与现有代码风格一致。
场景 2:添加大功能(10+ Story)
使用 BMAD Method 完整流程:
1 | *pm |
注意这里的架构文档不是从零设计,而是 基于现有架构扩展。Architect 会读取 project-context.md,在现有架构的基础上设计新功能的架构。
4.4. 独立阶段启动:项目进行中的灵活应对
有时候项目已经进行到一半,你只需要补充某个阶段的文档。BMAD 允许你 独立启动任意阶段,不需要从头开始。
Workflow Status:项目进度的 GPS
任何代理都可以使用 [WS] 命令检查当前项目状态:
1 | [WS] 获取工作流状态或初始化工作流 |
这个命令会:
- 扫描项目目录:查找已有的工件(PRD、架构文档、Epic 文件等)
- 分析完成度:判断每个阶段是否完成
- 给出建议:告诉你下一步应该做什么
这解决了什么问题?防止重复劳动。如果你不知道项目当前状态,可能会重复创建已有的文档。但如果用 [WS] 检查状态,就能避免这个问题。
独立启动的典型场景
场景 1:有 PRD 但没有架构文档
1 | *architect |
Architect 会读取 PRD,基于 PRD 的需求设计架构。
场景 2:有 PRD 和架构文档,但没有 Epic 和 Story
1 | *pm |
PM 会读取 PRD 和架构文档,拆分成可执行的 Epic 和 Story。
场景 3:有 Epic 和 Story,但没有 sprint-status.yaml
1 | *sm |
SM 会读取 Epic 文件,生成 sprint-status.yaml,用于跟踪 Story 的状态。
场景 4:直接开始开发
如果所有文档都齐全,可以直接进入开发:
1 | *sm |
独立启动的关键原则
原则 1:检查前置条件
每个阶段都有前置条件。比如创建 Epic 和 Story 需要先有 PRD 和架构文档。如果前置条件不满足,工作流会报错。
原则 2:保持工件一致性
如果你修改了 PRD,需要重新生成 Epic 和 Story。否则 Epic 和 Story 会与 PRD 不一致。
原则 3:使用 WS 检查状态
在独立启动任何阶段前,先用 [WS] 检查状态,确保你知道项目当前的完成度。
4.5. 工作流路径选择指南
BMAD 提供了多种工作流路径,根据项目类型自动选择。我们用一个决策表来总结:
| 项目类型 | 有无文档 | 功能规模 | 推荐工作流 | 关键步骤 |
|---|---|---|---|---|
| 新项目 | - | 大功能(10+ Story) | Greenfield 完整流程 | Analysis → Planning → Solutioning → Implementation |
| 新项目 | - | 小功能(1-5 Story) | Quick Flow | Tech Spec → Quick Dev |
| 现有项目 | 无文档 | 大功能 | Brownfield 完整流程 | Document Project → Analysis → Planning → Solutioning → Implementation |
| 现有项目 | 无文档 | 小功能 | Quick Flow | Document Project → Tech Spec → Quick Dev |
| 现有项目 | 有文档 | 大功能 | Brownfield 完整流程 | Analysis → Planning → Solutioning → Implementation |
| 现有项目 | 有文档 | 小功能 | Quick Flow | Tech Spec → Quick Dev |
| 项目进行中 | 部分文档 | - | 独立阶段启动 | WS 检查状态 → 补充缺失阶段 |
Greenfield 路径(从零开始)
适用于全新项目,完整流程:
1 | Phase 1: Analysis(可选) |
关键点:Phase 1 是可选的。如果需求已经明确,可以跳过 Analysis,直接从 Planning 开始。
Brownfield 路径(现有项目)
适用于已有代码库的项目:
1 | Phase 0: Documentation(如果缺少文档) |
关键点:Phase 0 是 Brownfield 特有的。如果项目缺少文档,必须先文档化,否则 AI 不知道现有代码的架构模式。
Quick Flow 路径(快速开发)
适用于小功能快速迭代:
1 | Step 1: Tech Spec |
关键点:Quick Flow 只有 3 个步骤,但 Code Review 是强烈推荐的。不要因为追求速度而跳过审查。
4.6. 本章总结与最佳实践
工作流选择的核心原则
原则 1:规模优先
功能规模是决定工作流的第一要素。不管是新项目还是老项目,小功能用 Quick Flow,大功能用完整流程。
原则 2:文档先行
现有项目如果缺少文档,必须先文档化。不要急于开发,否则新代码会与老代码风格不一致。
原则 3:灵活应对
项目进行中可以随时补充缺失的阶段。不需要从头开始,用 [WS] 检查状态,然后独立启动需要的阶段。
原则 4:质量门槛
不管用哪种工作流,代码审查都是必须的。不要因为追求速度而跳过审查。
最佳实践清单
开始任何任务前:
- [ ] 用
[WS]检查项目状态 - [ ] 判断功能规模(Story 数量)
- [ ] 确认项目是否有文档
- [ ] 根据上述三点选择工作流
使用 Quick Flow 时:
- [ ] 确保需求已经明确
- [ ] 确保功能不涉及架构变更
- [ ] Tech Spec 必须包含文件路径和具体操作
- [ ] 必须进行对抗性审查
- [ ] 推荐使用新对话进行代码审查
使用完整流程时:
- [ ] 不要跳过任何阶段
- [ ] 每个阶段结束后检查工件是否完整
- [ ] PRD 必须通过验证
- [ ] 实现就绪检查必须通过
- [ ] 每个 Story 必须通过代码审查
处理现有项目时:
- [ ] 如果缺少文档,先运行 Document Project
- [ ] 确保 project-context.md 存在且完整
- [ ] 新代码必须与现有代码风格一致
- [ ] 修改现有代码前,先理解依赖关系
常见错误与纠正
| 错误 | 后果 | 正确做法 | 检测方法 |
|---|---|---|---|
| 小功能也用完整流程 | 浪费时间,过度设计 | 使用 Quick Flow | 如果 Story 数量 < 5,用 Quick Flow |
| 现有项目不文档化就开发 | AI 不理解现有代码模式 | 先运行 Document Project | 检查是否存在 project-context.md |
| 不检查状态就启动工作流 | 重复创建已有文档 | 先用 [WS] 检查状态 | 每次开始前先检查 |
| 跳过代码审查 | 代码质量无保障 | 使用 [CR] 进行审查 | 每个 Story 完成后必须审查 |
| Tech Spec 不够具体 | Dev 不知道怎么实现 | 包含文件路径和具体操作 | 检查 Tech Spec 是否可操作 |
| 不更新 project-context.md | 新代码与老代码风格不一致 | 架构变更后更新文档 | 定期检查文档是否过时 |
我们用一个表格来对比不同工作流的效率:
| 维度 | Quick Flow | BMAD Method | 独立阶段启动 |
|---|---|---|---|
| 启动时间 | 10 分钟 | 1-2 小时 | 5-30 分钟 |
| 文档完整度 | 低(只有 Tech Spec) | 高(PRD + 架构 + Epic) | 中(补充缺失部分) |
| 适合规模 | 1-5 Story | 10+ Story | 视情况而定 |
| 返工风险 | 中(需求不清晰时) | 低(需求充分讨论) | 低(基于已有文档) |
| 学习曲线 | 低(只需掌握 2 个命令) | 高(需掌握完整流程) | 中(需理解阶段关系) |
| 团队协作 | 适合单人 | 适合多人 | 视情况而定 |
关键洞察:Quick Flow 不是 BMAD Method 的简化版,而是 针对不同场景的优化版。它们各有适用场景,不存在谁优谁劣。
工作流组合策略
在实际项目中,你可能会 组合使用 多种工作流:
策略 1:先 Quick Flow,后完整流程
适用场景:需求不明确,需要快速验证
流程:
- 用 Quick Flow 快速实现 MVP(最小可行产品)
- 验证需求后,用完整流程重构和扩展
策略 2:先完整流程,后 Quick Flow
适用场景:大功能开发完成后,需要快速修复 Bug 或添加小功能
流程:
- 用完整流程开发核心功能
- 后续的小功能和 Bug 修复用 Quick Flow
策略 3:混合使用
适用场景:大型项目,不同模块规模不同
流程:
- 核心模块用完整流程
- 辅助模块用 Quick Flow
- 独立阶段启动用于补充文档
关键点:不要教条地使用某一种工作流。根据实际情况灵活选择,甚至可以在同一个项目中混合使用。
第五章. 模块扩展:BMB 与 CIS 的进阶用法
前面几章,我们一直把 BMAD 当成一套面向软件开发的四阶段工作流。从这一章开始,你会看到:BMAD 其实装了三个模块——核心的 BMM(开发方法),再加上 BMB(Builder)和 CIS(创意套件)。它们分别解决三个问题:怎么把需求变成代码、怎么设计属于你自己的 AI 代理、怎么产生更好的点子和方案。
5.1. 三个模块的分工逻辑
在安装 BMAD 时,你可能注意到了模块选择界面:
1 | ? Select modules to install: |
这三个模块不是互相替代的关系,而是 互补的关系。我们用一个表格来说明:
| 模块 | 全称 | 核心功能 | 解决什么问题 |
|---|---|---|---|
| BMM | BMad Method | 四阶段开发流程 | 怎么把需求变成代码 |
| BMB | BMad Builder | 创建自定义代理和工作流 | 怎么设计属于你的 AI 代理 |
| CIS | Creative Innovation Suite | 创意和策略工具 | 怎么产生更好的点子和方案 |
三个模块的协作关系
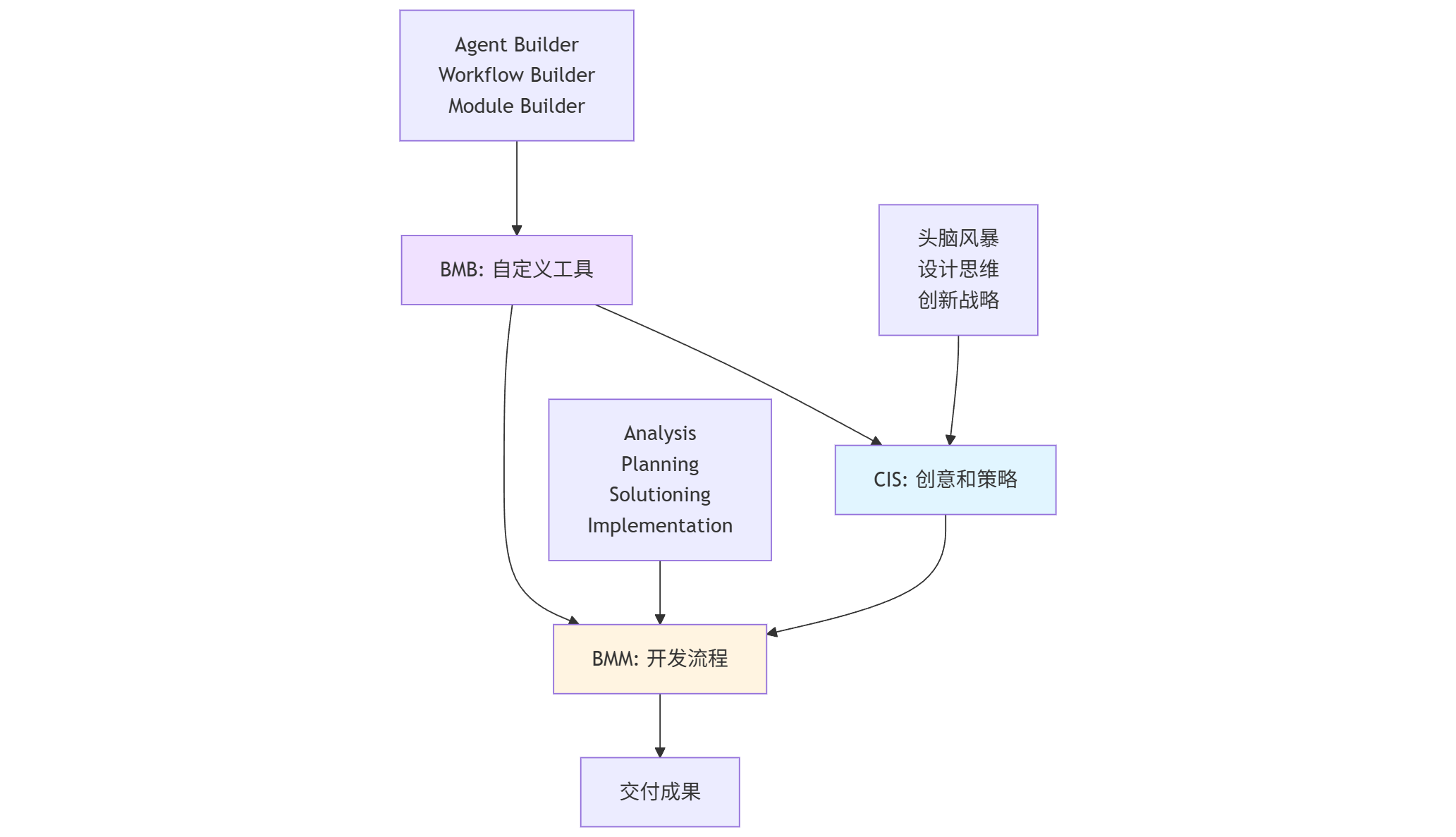
这个图的核心逻辑是:
- CIS 为 BMM 提供高质量输入:用头脑风暴、设计思维等方法,产生更好的需求和方案
- BMM 把创意落实成代码:用四阶段流程,把需求变成可交付的产品
- BMB 把经验固化成工具:当你发现某个流程经常重复,用 BMB 把它固化成自定义代理或工作流
安装后的目录结构
安装完成后,_bmad/ 目录的结构是:
1 | _bmad/ |
注意每个模块都有自己的 agents/、workflows/ 和 data/ 目录。这意味着:
- BMM 的代理(Analyst、PM、Architect 等)只负责开发流程
- BMB 的代理(Agent Builder、Workflow Builder 等)只负责创建工具
- CIS 的代理(Brainstorming Coach、Design Thinking Coach 等)只负责创意和策略
它们各司其职,不会互相干扰。
5.2. BMB:给创作者用的工具工厂
BMB 是干什么的?
BMB 的全称是 BMad Builder,它的目标是:让你能够创建属于自己的 BMAD 组件。
什么叫 “BMAD 组件”?包括三类:
- Agent(代理):比如 “教育产品专家”、“内部工具架构师”
- Workflow(工作流):比如 “课程大纲设计流程”、“内部需求 intake 流程”
- Module(模块):一整套代理 + 工作流 + 配置,打包成一个独立模块
为什么需要 BMB?
前面几章,我们一直在用 BMM 自带的代理:Analyst、PM、Architect、Dev、QA。但这些代理是 通用的,它们不了解你的特定领域。
举个例子:
场景 1:教育行业
如果你在做教育产品,BMM 的 PM 代理能帮你写 PRD,但它不知道:
- 教学设计的 ADDIE 模型
- 布鲁姆认知层次
- 学习路径设计的最佳实践
你需要一个 “教育产品专家” 代理,它懂这些领域知识。
场景 2:内部工具开发
如果你在做公司内部工具,BMM 的 Architect 代理能帮你设计架构,但它不知道:
- 你们公司的技术栈规范
- 内部系统的集成方式
- 权限管理的特殊要求
你需要一个 “内部工具架构师” 代理,它懂你们公司的规范。
BMB 就是用来创建这些自定义代理的工具。
BMB 的三个 Builder 代理
BMB 提供了三个 Builder 代理,分别用于创建不同类型的组件:
| Builder 代理 | 用途 | 激活命令 |
|---|---|---|
| Agent Builder | 创建自定义代理 | *agent agent-builder |
| Workflow Builder | 创建自定义工作流 | *agent workflow-builder |
| Module Builder | 创建自定义模块 | *agent module-builder |
Agent Builder:创建自定义代理
Agent Builder 的工作流路径是:_bmad/bmb/workflows/agent/workflow.md
它有三种模式:
| 模式 | 用途 | 步骤目录 |
|---|---|---|
| Create(创建) | 从零开始创建新代理 | steps-c/ |
| Edit(编辑) | 修改现有代理 | steps-e/ |
| Validate(验证) | 检查代理设计是否合理 | steps-v/ |
Create 模式的关键步骤
我们重点看 Create 模式,它包含以下步骤:
步骤 1:头脑风暴
1 | 让我们先理解一下这个代理要解决的问题: |
这一步的目标是 明确代理的定位。不要急于设计,先把 “为什么需要这个代理” 说清楚。
步骤 2:类型与元数据
1 | 现在让我们定义代理的基本信息: |
这一步定义代理的 身份信息。
步骤 3:Persona 设计
1 | 让我们设计代理的人格: |
这一步定义代理的 性格和价值观。
步骤 4:菜单和命令
1 | 让我们设计代理的菜单: |
这一步定义代理的 功能菜单。
步骤 5:激活逻辑
1 | 代理启动时需要加载哪些文件? |
这一步定义代理的 启动行为。
步骤 6:生成代理文件
所有步骤完成后,Agent Builder 会生成一个完整的代理文件:
1 | --- |
这个文件会保存到 _bmad/custom/agents/education-product-expert.md。
自定义代理的使用
创建完成后,你可以像使用 BMM 代理一样使用它:
1 | *agent education-product-expert |
系统会加载你创建的代理文件,激活 “教育产品专家” 代理。
Workflow Builder:创建自定义工作流
Workflow Builder 的工作流路径是:_bmad/bmb/workflows/workflow/workflow.md
它也有三种模式:Create、Edit、Validate。
Create 模式的关键步骤
步骤 1:定义工作流目标
1 | 让我们先理解这个工作流要做什么: |
步骤 2:设计步骤文件
1 | 让我们把工作流拆分成步骤: |
步骤 3:定义步骤内容
1 | 让我们为每个步骤定义内容: |
步骤 4:生成工作流文件
Workflow Builder 会生成:
- workflow.md:工作流的主文件
- steps/ 目录:所有步骤文件
- data/ 目录(可选):工作流需要的数据文件
生成的文件会保存到 _bmad/custom/workflows/your-workflow/。
Module Builder:创建自定义模块
Module Builder 的目标是:打包一整套代理 + 工作流 + 配置,形成一个独立模块。
什么时候需要创建模块?
场景 1:为特定领域创建完整工具集
例如,你想为 “教学设计” 创建一个完整的 BMAD 模块:
- 代理:课程设计师、测评专家、运营策划
- 工作流:课程结构设计、作业设计、考试出题、教学复盘
- 数据:教学设计模板、评估标准、案例库
场景 2:为团队创建内部工具集
例如,你想为公司内部创建一个 “内部工具开发” 模块:
- 代理:内部系统 PO、权限设计顾问、数据接口协调人
- 工作流:内部需求 intake 流程、系统间集成设计流、变更影响分析流
- 数据:公司技术栈规范、内部系统清单、权限模板
Module Builder 的工作流
Module Builder 会引导你:
- 定义模块元数据:名称、描述、版本
- 选择包含的代理:哪些代理属于这个模块
- 选择包含的工作流:哪些工作流属于这个模块
- 配置模块依赖:这个模块依赖哪些其他模块
- 生成安装脚本:如何安装和卸载这个模块
最终生成的模块结构:
1 | _bmad/your-module/ |
5.3. CIS:为 BMM 和 BMB 提供高质量创意燃料
CIS 模块的定位
CIS 的全称是 Creative Innovation Suite(创意创新套件)。它的目标不是写代码,而是:帮你想清楚做什么、为什么、从哪些角度想。
CIS 包含五类工作流:
| 工作流类型 | 核心目标 | 适用场景 |
|---|---|---|
| Brainstorming | 创意发散 | 需要大量点子时 |
| Design Thinking | 以用户为中心 | 需要深入理解用户时 |
| Innovation Strategy | 商业模式创新 | 需要战略级思考时 |
| Problem Solving | 系统性问题解决 | 需要拆解复杂问题时 |
| Storytelling | 故事化表达 | 需要讲好故事时 |
CIS 的五个代理
在 _bmad/cis/agents/ 目录下,有五个代理:
| 代理 | 激活命令 | 用途 |
|---|---|---|
| Brainstorming Coach | *brainstorming-coach | 引导头脑风暴 |
| Design Thinking Coach | *design-thinking-coach | 引导设计思维 |
| Innovation Strategist | *innovation-strategist | 引导创新战略 |
| Creative Problem Solver | *creative-problem-solver | 引导问题解决 |
| Storyteller | *storyteller | 引导故事创作 |
Brainstorming:真正专业的创意发散
Brainstorming Coach 的工作流路径是:_bmad/cis/workflows/brainstorming/workflow.yaml
它的核心特点是:使用 36+ 种创意技巧,轮换引导你产出点子。
创意技巧库
在 _bmad/cis/workflows/brainstorming/data/design-methods.csv 文件中,包含 36 种创意技巧,分为 7 大类别:
| 类别 | 适用场景 |
|---|---|
| Collaborative(协作式) | 团队头脑风暴 |
| Structured(结构化) | 需要系统性思考 |
| Wild(疯狂式) | 需要打破常规 |
| Introspective(内省式) | 个人深度思考 |
| Analytical(分析式) | 需要理性分析 |
| Empathetic(共情式) | 需要理解用户 |
| Provocative(挑衅式) | 需要突破思维定式 |
Brainstorming 的工作流程
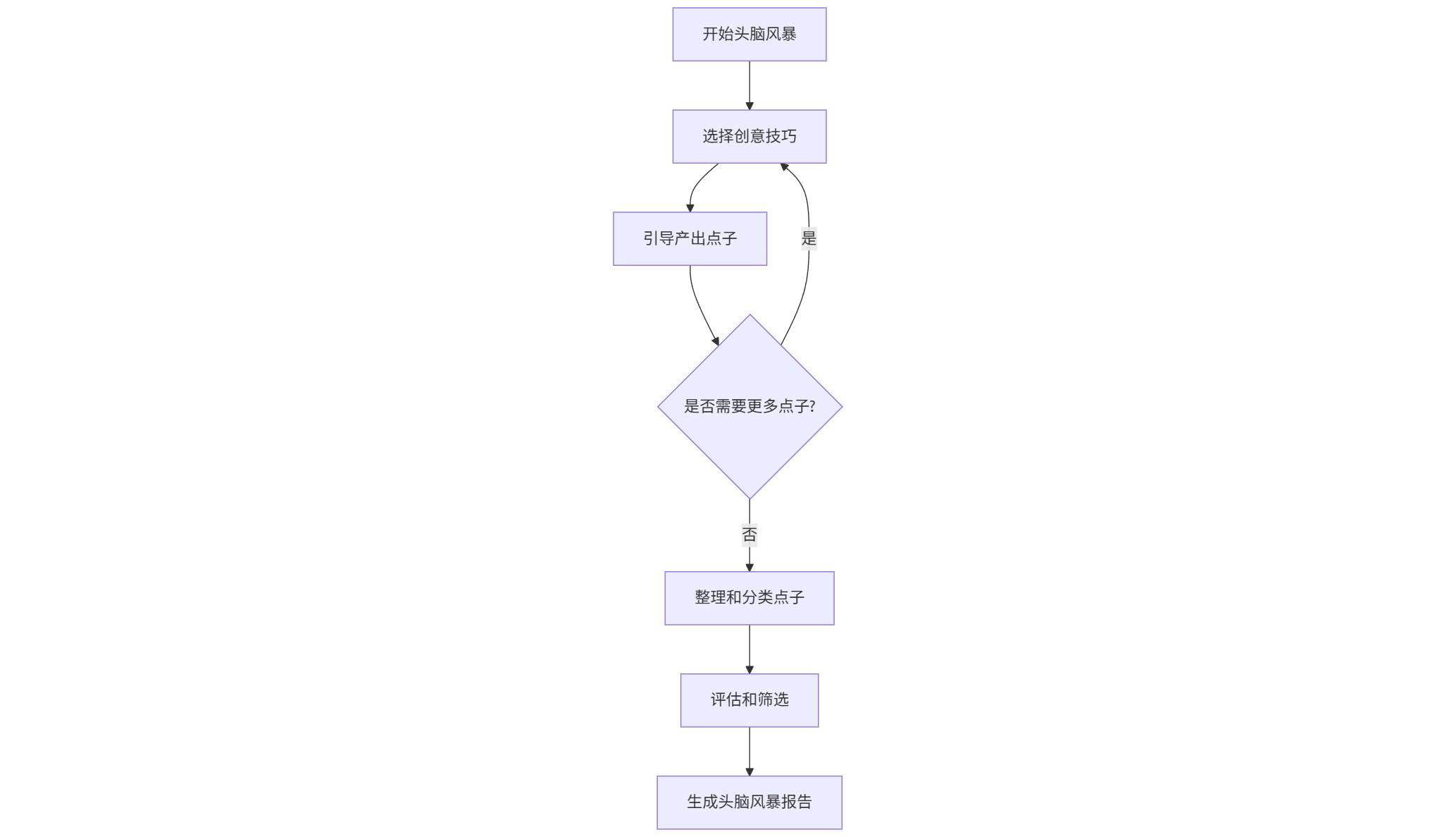
关键特点:
- 技巧轮换:不会一直用同一种技巧,而是根据场景切换
- 引导式提问:通过提问引导你产出,而不是 AI 自己写
- 结构化输出:最终生成一份结构化的头脑风暴报告
适用时机
在 BMM 的 Analysis 阶段之前:
1 | *brainstorming-coach |
为 BMB 的 Module 设计提供创意素材:
1 | *brainstorming-coach |
Design Thinking:做真正的以用户为中心
Design Thinking Coach 的工作流路径是:_bmad/cis/workflows/design-thinking/workflow.yaml
它遵循设计思维的五个阶段:
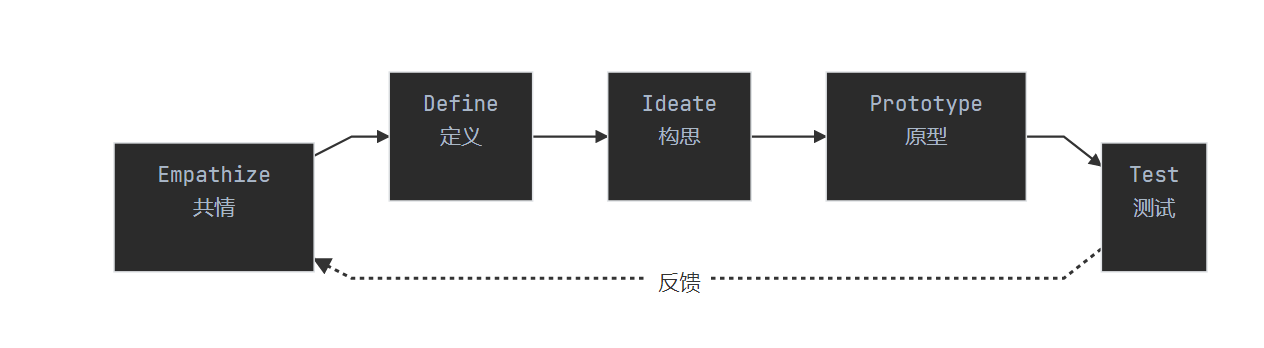
五个阶段的关键活动
| 阶段 | 关键活动 | 输出 |
|---|---|---|
| Empathize | 用户访谈、观察、同理心地图 | 用户洞察 |
| Define | 问题陈述、用户旅程、痛点地图 | 问题定义 |
| Ideate | 头脑风暴、How Might We、SCAMPER | 解决方案列表 |
| Prototype | 草图、线框图、原型 | 可测试的原型 |
| Test | 用户测试、反馈收集、迭代 | 验证结果 |
适用时机
在写 PRD 之前,先跑一轮设计思维:
1 | *design-thinking-coach |
输出可以直接喂给 Analyst 或 PM,作为产品简报 / PRD 的原料。
Innovation Strategy:上到商业模式那一层
Innovation Strategist 的工作流路径是:_bmad/cis/workflows/innovation-strategy/workflow.yaml
它的目标不是设计一个小功``能,而是:思考产品 / 平台未来 6-12 个月的演化方向。
内置框架
| 框架 | 用途 | 适用场景 |
|---|---|---|
| Jobs-to-be-Done | 理解用户真正要完成的任务 | 产品定位 |
| Blue Ocean Strategy | 找到无竞争的市场空间 | 市场策略 |
| Value Chain Analysis | 分析价值链的优化空间 | 业务模式 |
| Business Model Canvas | 设计商业模式 | 战略规划 |
适用时机
不是在做一个小功能,而是在考虑:
- 这个产品未来 6-12 个月的演化方向
- 要不要砍掉某块功能 / 打开新市场
- 如何建立竞争壁垒
这类输出,可以和 BMM 的 产品简报 + PRD 形成上下游关系。
Problem Solving:系统化拆解复杂问题
Creative Problem Solver 的工作流路径是:_bmad/cis/workflows/problem-solving/workflow.yaml
它的目标是:用系统化方法拆解复杂问题,找到根因和解法。
方法库
| 方法 | 用途 | 适用场景 |
|---|---|---|
| TRIZ | 创新性问题解决 | 技术难题 |
| Theory of Constraints | 找到系统瓶颈 | 流程优化 |
| Systems Thinking | 理解系统动态 | 复杂系统 |
| Root Cause Analysis | 找到问题根因 | 故障分析 |
| Five Whys | 深挖问题本质 | 快速分析 |
工作流程

适用时机
不是写一个新功能,而是:
- 现有系统经常出问题
- 性能、稳定性、协作、流程某处一直痛
产出的 “根因 → 解法” 可以转成:
- BMM 的 Epic / Story
- BMB 的 新 Workflow 设计
Storytelling:把一切讲成一个好故事
Storyteller 的工作流路径是:_bmad/cis/workflows/storytelling/workflow.yaml
它的目标是:把复杂的技术、产品、项目讲成一个引人入胜的故事。
故事模型库
在 _bmad/cis/workflows/storytelling/data/story-models.csv 文件中,包含 25 套故事模型:
| 模型 | 用途 | 适用场景 |
|---|---|---|
| Hero’s Journey | 经典英雄之旅 | 产品发布、项目复盘 |
| Three-Act Structure | 三幕剧结构 | 演讲、Pitch |
| Story Brand | 品牌故事框架 | 营销、宣传 |
| Problem-Solution-Benefit | 问题-解决方案-收益 | 技术分享 |
适用时机
你想:
- 给团队讲清楚这个项目的 “英雄之旅”
- 把复杂的架构改变解释给非技术听众
- 做一个 “项目复盘故事”
输出可以用于:
- Pitch deck
- PRD 封面
- 内部分享会
- 项目复盘报告
5.4. 三个模块的协作模式
现在我们知道了三个模块各自的功能,接下来看它们如何协作。
模式 1:CIS → BMM(创意到实现)
这是最常见的协作模式:用 CIS 产生高质量创意,然后用 BMM 落实成代码。

具体流程:
步骤 1:用 CIS 挖掘创意和需求
1 | *brainstorming-coach |
步骤 2:用 BMM 落实成规格
1 | *analyst |
步骤 3:用 BMM 实现代码
1 | *sm |
模式 2:BMM → BMB(经验到工具)
这是另一个常见模式:当你发现某个流程经常重复,用 BMB 把它固化成工具。

具体流程:
步骤 1:在 BMM 中发现重复模式
假设你发现,每次做 “课程大纲设计” 时,都要经历相同的步骤:
- 理解学习目标
- 拆分知识点
- 设计学习路径
- 设计评估方案
步骤 2:用 BMB 固化成工作流
1 | *agent workflow-builder |
Workflow Builder 会引导你:
- 定义工作流的输入和输出
- 拆分成步骤文件
- 为每个步骤定义内容
步骤 3:用 BMB 创建专属代理
1 | *agent agent-builder |
Agent Builder 会引导你:
- 定义代理的角色和专业领域
- 设计代理的菜单(包含 “课程大纲设计” 工作流)
- 配置代理的启动行为
步骤 4:下次直接使用
1 | *agent course-designer |
现在你有了一个专门的 “课程设计师” 代理,它内置了 “课程大纲设计” 工作流。
模式 3:CIS → BMB(创意到工具)
这是一个高级模式:用 CIS 产生创意,然后用 BMB 把创意固化成工具。

具体流程:
步骤 1:用 CIS 识别新领域
1 | *innovation-strategist |
步骤 2:用 BMB 创建新模块
1 | *agent module-builder |
Module Builder 会引导你:
- 定义模块的目标和范围
- 设计模块需要的代理(课程设计师、测评专家、运营策划)
- 设计模块需要的工作流(课程结构设计、作业设计、考试出题)
步骤 3:用 BMB 创建代理和工作流
1 | *agent agent-builder |
步骤 4:新模块可用
现在你有了一个完整的 “在线教育 BMAD” 模块,包含:
- 3 个专属代理
- 5 个专属工作流
- 完整的配置和文档
模式 4:完整循环(CIS → BMM → BMB)
这是最完整的协作模式:从创意到实现,再到工具化。
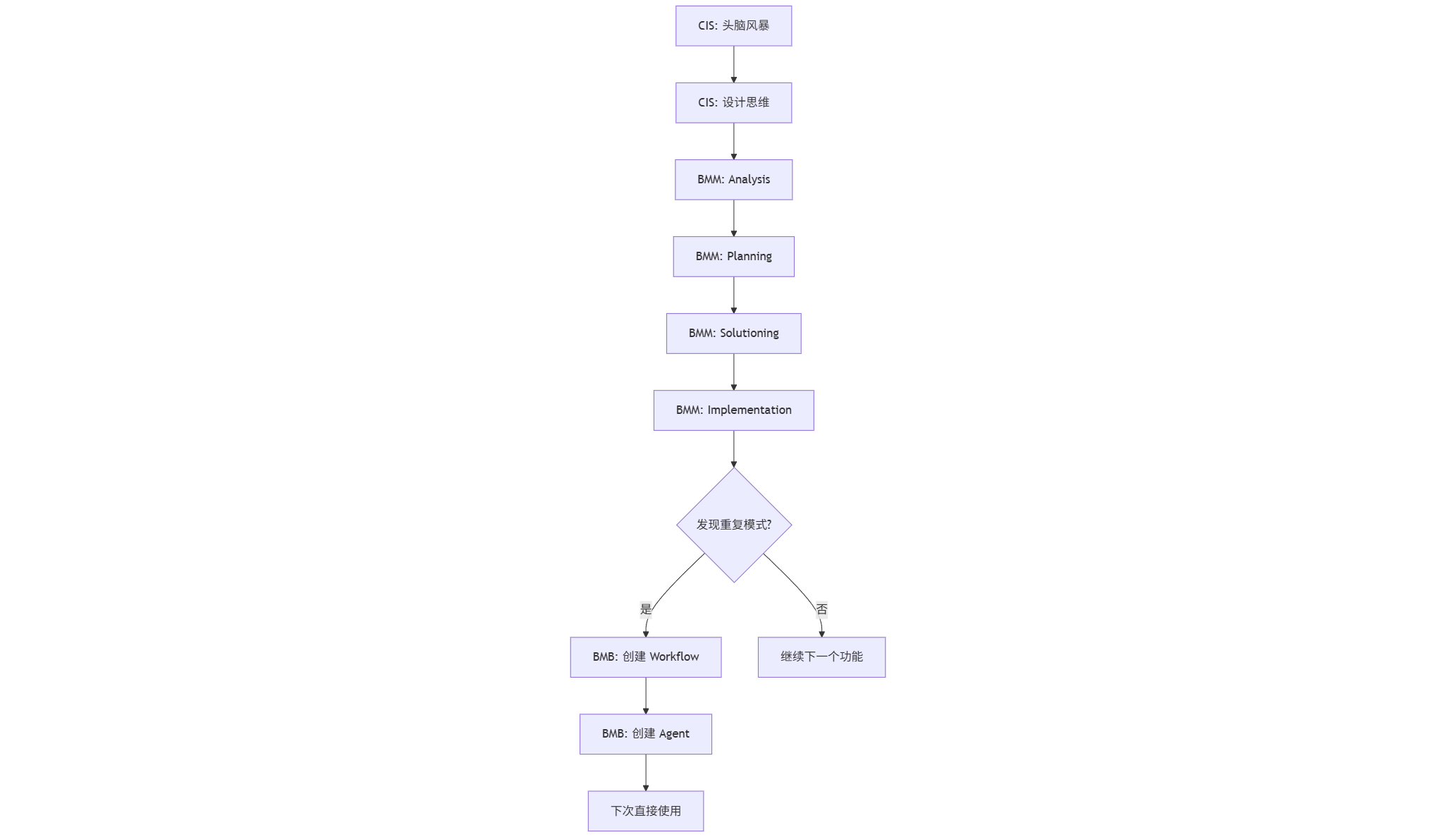
具体流程:
第一轮:用 CIS + BMM 完成第一个项目
1 | # CIS 阶段 |
第二轮:发现重复模式,用 BMB 固化
1 | # 发现:每次做课程设计都要经历相同步骤 |
第三轮:直接使用固化的工具
1 | *agent course-designer |
5.5. 实战案例:为教育产品创建自定义模块
让我们通过一个完整案例,看看如何用三个模块协作。
案例背景
你在做在线教育产品,发现 BMM 的通用代理不够用。你需要:
- 一个懂教学设计的 “课程设计师” 代理
- 一个懂评估的 “测评专家” 代理
- 一套 “课程大纲设计” 工作流
步骤 1:用 CIS 明确需求
首先,用 Brainstorming Coach 挖掘需求:
1 | *brainstorming-coach |
Brainstorming Coach 会引导你:
1 | 让我们用 SCAMPER 技巧来思考: |
经过头脑风暴,你明确了:
- 需要一个 “课程设计师” 代理,它懂 ADDIE 模型、布鲁姆认知层次
- 需要一个 “课程大纲设计” 工作流,包含 5 个步骤
- 需要一个 “测评专家” 代理,它懂评估设计
步骤 2:用 BMB 创建模块
激活 Module Builder:
1 | *agent module-builder |
Module Builder 会引导你:
1 | 让我们创建一个新模块: |
Module Builder 会生成模块结构:
1 | _bmad/education-design/ |
步骤 3:用 BMB 创建代理
激活 Agent Builder,创建 “课程设计师” 代理:
1 | *agent agent-builder |
Agent Builder 会引导你完成 Persona 设计:
1 | 让我们设计 "课程设计师" 代理: |
Agent Builder 会生成 course-designer.md 文件。
步骤 4:用 BMB 创建工作流
激活 Workflow Builder,创建 “课程大纲设计” 工作流:
1 | *agent workflow-builder |
Workflow Builder 会引导你拆分步骤:
1 | 让我们设计 "课程大纲设计" 工作流: |
Workflow Builder 会生成完整的工作流文件。
步骤 5:使用自定义模块
现在你可以使用自定义的 “教育设计模块”:
1 | *agent course-designer |
Course Designer 会启动 “课程大纲设计” 工作流,引导你完成 6 个步骤,最终生成一份专业的课程大纲。
这个案例的关键点
- CIS 提供创意输入:用头脑风暴明确需求
- BMB 固化成工具:用 Module Builder、Agent Builder、Workflow Builder 创建自定义模块
- 模块可复用:下次做课程设计时,直接使用 Course Designer 代理
5.6. 本章总结与最佳实践
三个模块的定位总结
| 模块 | 核心价值 | 何时使用 |
|---|---|---|
| BMM | 稳定地把需求变成代码 | 开发任何软件功能 |
| CIS | 产生高质量的创意和方案 | 需求不明确、需要创新时 |
| BMB | 把经验固化成可复用工具 | 发现重复模式、需要定制时 |
协作模式总结
| 模式 | 流程 | 适用场景 |
|---|---|---|
| CIS → BMM | 创意 → 实现 | 新项目、新功能 |
| BMM → BMB | 经验 → 工具 | 发现重复模式 |
| CIS → BMB | 创意 → 工具 | 进入新领域 |
| CIS → BMM → BMB | 创意 → 实现 → 工具 | 完整循环 |
最佳实践
实践 1:不要急于定制
不要一开始就用 BMB 创建自定义代理。先用 BMM 的通用代理完成几个项目,发现真正的重复模式后,再用 BMB 固化。
实践 2:CIS 不是可选的
很多人觉得 CIS 是 “可选” 的,只有 BMM 是 “必需” 的。但实际上,CIS 决定了你做什么,BMM 决定了你怎么做。如果 “做什么” 不对,“怎么做” 再好也没用。
实践 3:模块化思维
当你用 BMB 创建自定义工具时,要有 模块化思维。不要把所有东西都塞进一个代理或工作流,而是:
- 一个代理只负责一个角色
- 一个工作流只负责一个流程
- 一个模块只负责一个领域
实践 4:文档先行
在用 BMB 创建自定义工具前,先写文档:
- 这个代理 / 工作流要解决什么问题?
- 典型使用场景是什么?
- 输入和输出是什么?
文档写清楚了,创建工具就很简单。
实践 5:版本控制
如果你用 BMB 创建了自定义模块,建议将整个 _bmad/ 目录纳入版本控制。这样:
- 团队成员可以共享自定义工具
- 工具的修改可以追溯
- 可以回滚到之前的版本
常见错误与纠正
| 错误 | 后果 | 正确做法 |
|---|---|---|
| 一开始就用 BMB 定制 | 过度设计,浪费时间 | 先用 BMM 完成几个项目,发现模式后再定制 |
| 跳过 CIS 直接用 BMM | 需求不清晰,频繁返工 | 用 CIS 先把 “做什么” 想清楚 |
| 把所有功能塞进一个代理 | 代理职责不清,难以维护 | 一个代理只负责一个角色 |
| 不写文档就创建工具 | 工具难以理解和使用 | 先写文档,再创建工具 |
| 自定义工具不纳入版本控制 | 团队无法共享,修改无法追溯 | 将 _bmad/ 目录纳入 Git |
自检清单
在使用三个模块前,问自己:
关于 BMM:
- [ ] 我是否需要完整的四阶段流程?
- [ ] 还是只需要 Quick Flow?
- [ ] 现有的代理是否够用?
关于 CIS:
- [ ] 需求是否已经明确?
- [ ] 是否需要头脑风暴或设计思维?
- [ ] 是否需要战略级思考?
关于 BMB:
- [ ] 是否发现了重复模式?
- [ ] 现有代理是否无法满足需求?
- [ ] 是否需要为特定领域创建工具?






