
Prorise
这是我的博客,分享技术与生活的点点滴滴
2026 最完整 AI 编程方法论:全面理解BMAD-METHOD一套可落地的AI敏捷开发工程方法
2026 最完整 AI 编程方法论:全面理解BMAD-METHOD一套可落地的AI敏捷开发工程方法
Prorise我的 AI 编程项目为什么总是烂尾
去年 10 月,我用 Claude 开发了一个 SaaS 项目。
前三天进展神速。我在对话框里描述需求,AI 吐出代码,复制粘贴,刷新浏览器,功能就跑起来了。那种感觉就像是拥有了一个 24 小时待命的全栈工程师。
到第 7 天,项目代码突破 3000 行。我开始发现 AI 变 “笨” 了。它会忘记我在第 2 天定义的数据库字段,会把已经废弃的接口重新写回来,甚至开始编造一些根本不存在的函数。
到第 15 天,我每天花 6 小时在 “哄” AI。修复一个 Bug 会引入三个新 Bug,对话记录长到需要滚动 5 分钟才能翻到开头。最后我放弃了,删掉整个项目重新开始。
这不是 AI 能力的问题,是我的方法出了问题。
对话式编程的三大死亡陷阱
陷阱一:上下文的稀释效应
很多人迷信 “长窗口”。他们觉得 Claude 的 200k token 窗口足够大,可以把整个项目塞进去,AI 就能完美理解。
这是个巨大的误区。
Token 数量不等于注意力。就像你手里拿着一本 1000 页的书,你确实 “拥有” 了这本书,但你此刻的注意力只能聚焦在其中一页。
在随性编程中,你的对话会混合各种信息:
- “我要加个登录功能”(需求)
- “用 Tailwind CSS”(技术偏好)
- “刚才那个报错了”(Bug 反馈)
- “你怎么这么笨”(情绪发泄)
当对话进行到第 50 轮,AI 需要在数万字的废话中寻找你最初定义的 “接口规范”。这时候,它的注意力已经被稀释到无法工作。
我做过一个简单测试:
- 前 20 轮对话,AI 的代码准确率在 85% 以上
- 50 轮对话后,准确率下降到 60%
- 100 轮对话后,准确率不到 30%
这不是 AI 变笨了,是信息密度崩塌了。
陷阱二:易失性记忆与幻觉
对话是流式的,本质上是易失的。
你在对话框里敲定的决策,如果没有被固化下来,就只是一串临时的 Token。两天后,当你开启新的对话窗口(因为上一个太卡了),之前的所有约束条件瞬间归零。
你不得不重新告诉 AI:“记得吗,我们用的是 PostgreSQL,不是 MySQL。”
但更可怕的是幻觉。
当上下文缺失时,AI 会用 “概率预测” 来填补空白。它会自信地编造一个并不存在的函数,或者引用一个你从未定义的变量。在没有约束的情况下,AI 的创造力就变成了破坏力。
我遇到过最离谱的一次:AI 告诉我调用 getUserProfile() 函数,但这个函数根本不存在。我花了 2 小时才发现,它是根据 “常见命名习惯” 推测出来的。
陷阱三:熵增的不可逆性
物理学有个概念叫 “熵”,指的是系统的混乱度。热力学第二定律说:封闭系统的熵只会增加,不会减少。
对话式编程就是一个典型的熵增系统。
每一次需求变更,每一次 Bug 修复,都会在对话中引入新的变量和约束。这些信息像灰尘一样堆积,最终让整个系统陷入不可逆的混乱。
你无法通过 “继续对话” 来降低熵。就像你无法通过搅拌让咖啡和牛奶重新分离。
BMAD 的三大哲学支柱
BMAD 方法论的核心,是用结构对抗混乱。
它不是教你如何写 Prompt,而是教你如何管理 AI 的认知。它通过三个维度的重构,将 AI 从 “聊天机器人” 变成了 “数字生产线”。
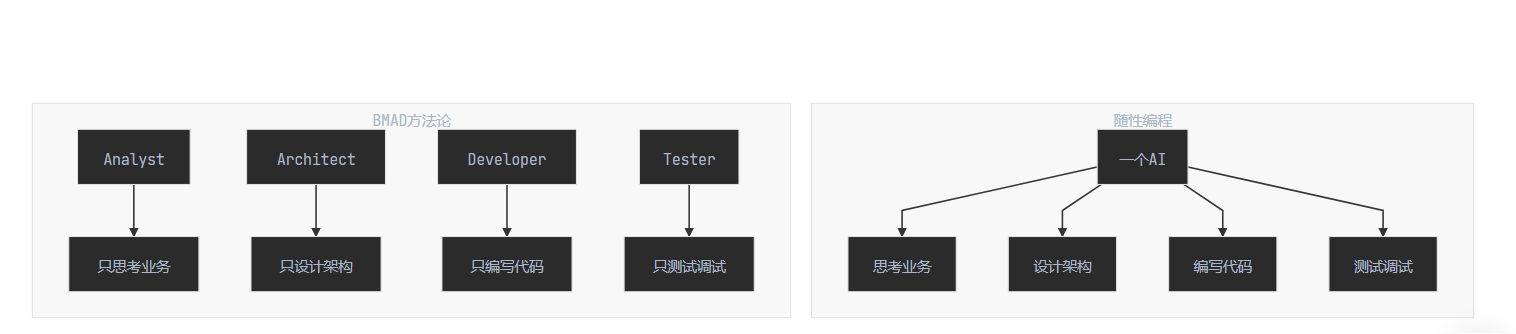
支柱一:角色的原子化分离
在传统的小作坊里,一个工匠既要画图纸,又要搬砖,还要搞装修。在 AI 编程中,如果你只用一个对话窗口,其实就是把 AI 当作这个 “全能工匠”。
这违反了软件工程的基本原则:关注点分离。
BMAD 强制引入了多个专门的角色。每个角色只负责一个极其狭窄的领域:
- Analyst:只负责问 “为什么”。它极其挑剔,专注于挖掘业务逻辑漏洞,完全不关心代码怎么写。
- Architect:只负责定 “怎么做”。它关注技术栈选型、接口定义、数据结构,不关心业务价值,也不关心代码缩进。
- Developer:只负责 “执行”。它是一个无情的代码生成机器,不需要思考架构是否合理,只负责把任务变成代码。
为什么要这么做?
因为当你限定了角色的 “视界”,AI 的幻觉率会大幅下降。让一个专注于写 Java 代码的 AI 去思考产品商业模式,它一定会胡说八道。但如果你只让它写一个符合接口契约的类,它就是世界顶级的专家。
角色分离的本质:
| 维度 | 全能 AI(随性编程) | 专业 AI(BMAD) |
|---|---|---|
| 认知负荷 | 需要同时思考业务+架构+代码 | 每次只专注一个维度 |
| 幻觉率 | 高(跨领域推理容易出错) | 低(限定领域内的专家) |
| 可维护性 | 低(决策散落在对话中) | 高(决策固化在工件中) |
| 纠错成本 | 高(需要重新对话) | 低(修改对应工件即可) |
角色分离,本质上是对 AI 上下文的物理隔离。每一个角色只能看到它需要的信息,从而保持了认知的纯净。
支柱二:工件驱动的持久化记忆
这是 BMAD 最反直觉的设计。
在敏捷开发流行了二十年后,我们习惯了 “重沟通、轻文档”。但 BMAD 却突然掉头,要求我们在写第一行代码前,必须生成大量的文档:产品简报、PRD、架构设计图、接口定义文件、任务清单。
这是在开历史倒车吗?
不,这是 AI 时代的必然。
对于人类,文档是负担;对于 AI,文档是 “外挂大脑”。
在 BMAD 流程中,每一个阶段的产出,都不是对话记录,而是一个物理存在的文件(Artifact):
- Analyst 的产出是
.md格式的需求文档 - Architect 的产出是
.yaml格式的接口定义 - Scrum Master 的产出是
.csv格式的任务列表
这些工件具有持久性和唯一真理性。
当 Developer 开始写代码时,它不需要去翻阅几百轮的聊天记录,它只需要读取 Architect 生成的那个架构文档。文档成为了连接不同 Agent 的无损数据总线。
对话 vs 工件的本质差异:
| 特性 | 对话记录 | 结构化工件 |
|---|---|---|
| 持久性 | 易失(窗口关闭即消失) | 永久(文件系统保存) |
| 可检索性 | 低(需要遍历全文) | 高(结构化查询) |
| 唯一真理性 | 无(多次对话可能矛盾) | 有(单一文件为准) |
| 版本管理 | 不可能 | 可以(Git 追踪) |
| AI 理解成本 | 高(需要理解上下文) | 低(直接读取结构) |

这种模式解决了 “失忆” 问题。无论你的开发周期拖多久,只要文档还在,项目的 “状态” 就被完美保存了。你是通过修改文档来控制项目,而不是通过记忆来控制项目。
支柱三:确定性的状态机
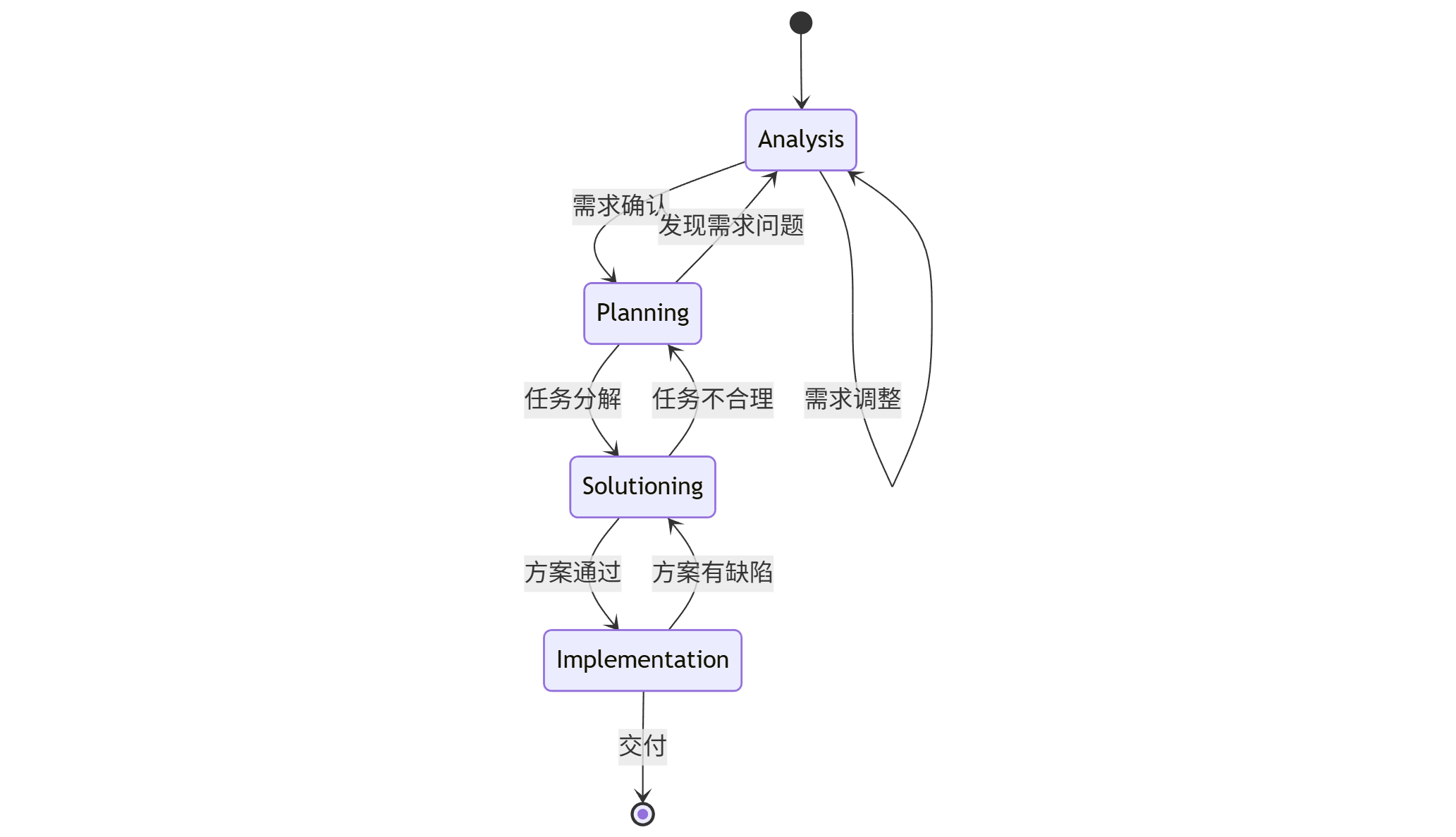
随性编程是线性的,像一条没有尽头的河流。而 BMAD 将开发过程变成了一个有限状态机。
它将开发划分为四个有着严格边界的阶段:
- Analysis(分析)
- Planning(规划)
- Solutioning(方案)
- Implementation(实现)
这不仅仅是流程的划分,更是纠错成本的控制。
在随性编程中,需求变更是灾难性的。你写了一半代码,突然想改数据库结构,往往意味着前面的代码要全部推翻,AI 也会因此陷入逻辑混乱。
而在 BMAD 中,如果需求变了,你只需要回退到 Analysis 阶段,修改需求文档。然后重新运行 Planning 和 Solutioning 的工作流,生成新的任务清单和架构文档。代码阶段(Implementation)甚至还没有开始。
线性流程 vs 状态机:
| 维度 | 线性流程(随性编程) | 状态机(BMAD) |
|---|---|---|
| 需求变更成本 | 极高(推翻所有代码) | 低(回退到 Analysis 阶段) |
| 错误传播 | 会扩散到所有后续环节 | 被限制在当前阶段 |
| 可回溯性 | 不可能(对话已消失) | 完全可以(工件有版本) |
| 并行开发 | 不可能(依赖对话上下文) | 可以(不同角色独立工作) |
这种 “分层治理” 的思想,让你可以在极低的成本下进行高频的试错。你可以在写代码前,让 AI 自己把逻辑跑通十遍,把所有矛盾都在文档层面解决掉。
重新定义 “人” 的位置
如果 AI 负责分析、设计、排期、写代码甚至测试,那么作为人类的我们,究竟还剩下什么?
BMAD 方法论极其残酷地剥夺了人类 “写代码” 的快感,但也赋予了人类更高的权力。
从 Coder 进化为 Reviewer
在 BMAD 体系下,你不再是那个逐行敲击键盘的程序员。你的核心工作变成了 Review(审查):
- 你审查 Analyst 写的需求是否符合你的初衷
- 你审查 Architect 选的技术栈是否过于激进
- 你审查 Developer 提交的 Patch 是否引入了安全隐患
你成为了一个把关人。这其实比写代码更难。写代码时,你只需要关注细节;审查时,你需要具备全局视野。你需要懂产品,懂架构,懂代码规范,才能驾驭这群 AI 员工。
唯一的 “意图源”
AI 可以生成无限的方案,但它无法决定 “要不要做”。
在 BMAD 的每一个关键节点,系统都会停下来等待人类的确认。这种 Human-in-the-loop(人在回路)的设计,是为了确保 AI 的发散思维最终收敛到人类的真实意图上。
你是这个数字团队的 CEO。你不需要知道怎么砌墙(写函数),但你必须知道这堵墙砌在客厅还是卧室(架构决策)。
对抗性审查:给 AI 找个对手
BMAD 甚至引入了 “对抗性审查” 的概念。既然人类也会疲惫,也会看漏眼,那就让另一个 AI 来充当 “魔鬼代言人”。
一个 AI 写完代码后,系统会启动另一个设定为 “极其挑剔的安全专家” 的 AI 来攻击这段代码,寻找漏洞和逻辑死角。
这不仅解放了人类,更将代码质量提升到了一个人类难以企及的细致程度。
一人公司的终极形态
BMAD 并不是一个简单的开源脚本,它是一场关于软件工程的工业化革命。
在手工业时代,一个鞋匠需要掌握量脚、选皮、裁剪、缝合的所有技能。效率低下,且难以复制。
在工业时代,流水线诞生了。每个人只负责一个环节,通过传送带传递半成品。效率暴增,质量标准化。
现在的 AI 编程,正处于从 “手工业” 向 “流水线” 转型的关键时刻。
大多数人还在沾沾自喜于 “我用 AI 写出了个小工具”,这依然是手工业者的思维。而真正想要依靠 AI 构建商业壁垒、运营 “一人公司” 的开发者,必须拥抱 BMAD 这样的流水线思维。
这套方法论确实会让起步变得 “慢” 一些。你需要配置环境,需要定义角色,需要看着 AI 像老学究一样写文档。但这种 “慢”,是为了后期的 “快”。
当你面对一个拥有 50 个接口、涉及微服务架构、需要长期维护的复杂系统时,你会感谢 BMAD 带来的那种坚如磐石的确定性。
AI 不再是一个陪你聊天的玩具,它是你麾下那支纪律严明、不知疲倦的工程军团。而你需要做的,就是掌握这套指挥军团的兵法。





