Prorise
这是我的博客,分享技术与生活的点点滴滴
第四章 数据库交互
第四章 数据库交互
Prorise第四章 数据库交互
欢迎来到模块四!在本章中,我们将从零开始,亲手打造一个极具实用价值的工具——“AI 产品需求与迭代管理 Bot”。这个 Bot 将成为我们团队的智能助手,帮助我们管理从创意到上线的整个产品需求流程。
我们将在这个项目中,深度实践 Coze 最核心的数据库交互能力。让我们开始吧!
4.1 项目启动:创建我们的智能体
在搭建复杂的数据库和工作流之前,我们首先需要一个“载体”,也就是我们的 Bot 本身。
第一步:创建新 Bot
我们回到 Coze 的工作空间,点击“创建 Bot”按钮。为我们的 Bot 起一个清晰的名字,例如:需求池小助手,并可以为它添加一个合适的图标和描述,如“一个帮助 AI 产品团队管理需求的智能助手”。第二步:设定初始角色 (快速复习)
我们知道,一个好的 Bot 始于一个清晰的角色设定。虽然我们的需求池小助手主要依赖工作流执行任务,但一个明确的 Prompt 能够让它在与我们交互时,表现得更专业、更稳定。我们为它设定一个简单的初始 Prompt:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37# 角色
你是一个专为AI产品团队打造的、高度智能的“需求池管理助手”。你的核心能力是理解产品经理、设计师等角色的日常语言,并将其转化为对“需求池”数据库的精确操作或调用专门的工作流。
# 可用工具
你拥有以下三个工具来完成任务,请在决策后选择最合适的工具进行调用:
1. **`add_requirement` (需求录入工作流)**
- **功能**: 当用户想要**新增一个需求**或开始一个新的需求讨论时调用。它会启动一个引导式、可多轮对话的流程来收集完整信息。
- **参数**: `pm_input` (String) - 用户输入的初始需求文本。
- **调用时机**: 当用户的意图是“我有一个新想法”、“记录一个需求”、“帮我创建一个ticket”等明确的新增意图时。
2. **`tableExecute` (数据库SQL执行器)**
- **功能**: 当用户想要**查询、修改或删除**数据库中**已有**的需求时调用。
- **参数**: `raw_sql` (String) - 一句完整的、可以直接在 `product_requirements` 表上执行的 SQL 语句。
- **调用时机**:
- **查询**: 用户说“帮我查一下...”、“列出所有...”、“ID为101的需求是什么?” -> 你需要生成 `SELECT * FROM product_requirements WHERE ...` 语句。
- **修改**: 用户说“更新一下ID为101的需求状态为...” -> 你需要生成 `UPDATE product_requirements SET status = '...' WHERE req_id = 101` 语句。
- **删除**: 用户说“删除ID为101的需求” -> 你需要生成 `DELETE FROM product_requirements WHERE req_id = 101` 语句。
3. **`setKeywordMemory` (会话草稿管理器)**
- **功能**: 用于操作当前对话的“需求草稿”(即我们之前设置的用户变量)。
- **参数**: `data` (Array) - 例如 `[{"keyword": "requirement_in_progress_str", "value": ""}]`。
- **调用时机**: 当用户明确表示要“放弃当前需求”、“清空草稿”、“我们重新开始吧”时,你需要调用此工具,将 `requirement_in_progress_str` 的 `value` 设置为空字符串 `""`。
# 工作流程与决策逻辑
1. **分析意图**: 首先,分析用户的最新输入,判断其核心意图属于【新增】、【查询】、【修改】、【删除】、【状态管理】还是【闲聊】中的哪一种。
2. **选择工具**: 根据意图,从【可用工具】列表中选择最匹配的一个。**一次只能选择一个工具**。
3. **生成参数**:
- 如果选择 `add_requirement`,直接将用户的原始输入作为 `pm_input` 参数。
- 如果选择 `tableExecute`,你必须根据用户的自然语言,**自己生成一句完整、语法正确的 SQL 语句**作为 `raw_sql` 参数。
- 如果选择 `setKeywordMemory`,按照示例生成 `data` 参数。
4. **无匹配工具**: 如果用户只是在闲聊(例如,“你好”、“你做得很好”),则**不要使用任何工具**,直接进行礼貌性的回复。
# 限制
- 除非用户的意图非常明确,否则优先通过提问来澄清用户的目的。
- 生成 SQL 语句时,必须极其谨慎,确保 `WHERE` 条件的准确性,避免误操作。
- 不要暴露你的内部工具名称和工作流程,与用户的交互要自然。第三步:进入工作区
创建好 Bot 并设定了初始 Prompt 后,还需要定义一个核心的用户变量,就叫他为requirement_in_progress_str,默认为空即可,我们就进入了熟悉的核心编辑区。让我们快速回顾一下左侧的技能面板:我们之后的所有操作,比如创建数据库、编写工作流,都将在这里进行。现在,这个 Bot 还只是一个“空壳”,接下来,我们就要开始为它搭建最核心的“数据仓库”。
4.2 搭建地基:创建“需求池”数据表
我们项目的第一步,也是最重要的一步,就是设计和创建我们用来存储所有产品需求的数据库“仓库”。这个“仓库”的结构,将严格参照如下的Excel模板
第一步:进入数据库管理界面
我们在 Bot 编辑页的左侧技能栏中,找到“记忆”模块下的“数据库”,点击它旁边的+号。第二步:新建数据表
在弹出的窗口中,点击蓝色的“新建数据表”按钮。我们会进入数据表的定义界面。第三步:定义数据表基础信息
我们将数据表名称定为product_requirements,并可以添加一段描述,例如“用于存储(某个产品)的所有功能创意与需求”。第四步:设计表结构(定义列)
这是核心环节。我们将完全按照提供的 Excel 表头来设计我们的字段。最终的表结构如下:
| 字段名称 (Field Name) | 数据类型 (Data Type) | 是否必要 (Is Required?) | 对应Excel列 |
|---|---|---|---|
submission_time | Time | ✓ | 提交时间 |
proposer | String | ✓ | 提交人 |
product_module | String | ✓ | 产品模块 |
description | String | ✓ | 需求描述 |
priority | String | ✓ | 优先级 |
source | String | 需求来源 | |
creator | String | 需求提出人 | |
req_type | String | 需求类型 | |
req_status | String | ✓ | 需求状态 |
notes | String | 备注 |
- 第五步:保存数据表
完成所有字段的添加和配置后,点击右下角的“保存”按钮。
恭喜!我们的数据“地基”就已经搭建完成了。现在,我们拥有了一个可以接收和存储产品需求的、结构清晰的“仓库”。
4.3 工作流:构建“一次性补全”的智能录入工作流
在这一节,我们将搭建 add_requirement 工作流。它将实现一个更高效的对话模式:在解析用户输入后,一次性告知用户所有需要补充的必填信息。当信息完整后,它会自动将数据存入数据库,并生成一个包含该条新纪录的 Excel 文件供用户下载。
第一步:配置“全能”大模型节点
这是我们整个流程的起点和大脑。
创建工作流与输入:
- 新建或打开
add_requirement工作流。 - 确保【开始】节点只有一个输入参数:
pm_input(String)。
- 新建或打开
配置大模型节点:
- 在【开始】节点后,连接一个【大模型】节点。
- 节点输入:为该节点创建两个输入:
pm_input:连接来自【开始】节点的pm_input。current_state_str:通过映射菜单,连接到我们之前创建的requirement_in_progress_str用户变量。
- 系统提示:将以下提供的 Prompt,完整粘贴到节点的“系统提示”区域:
1 | # 角色 |
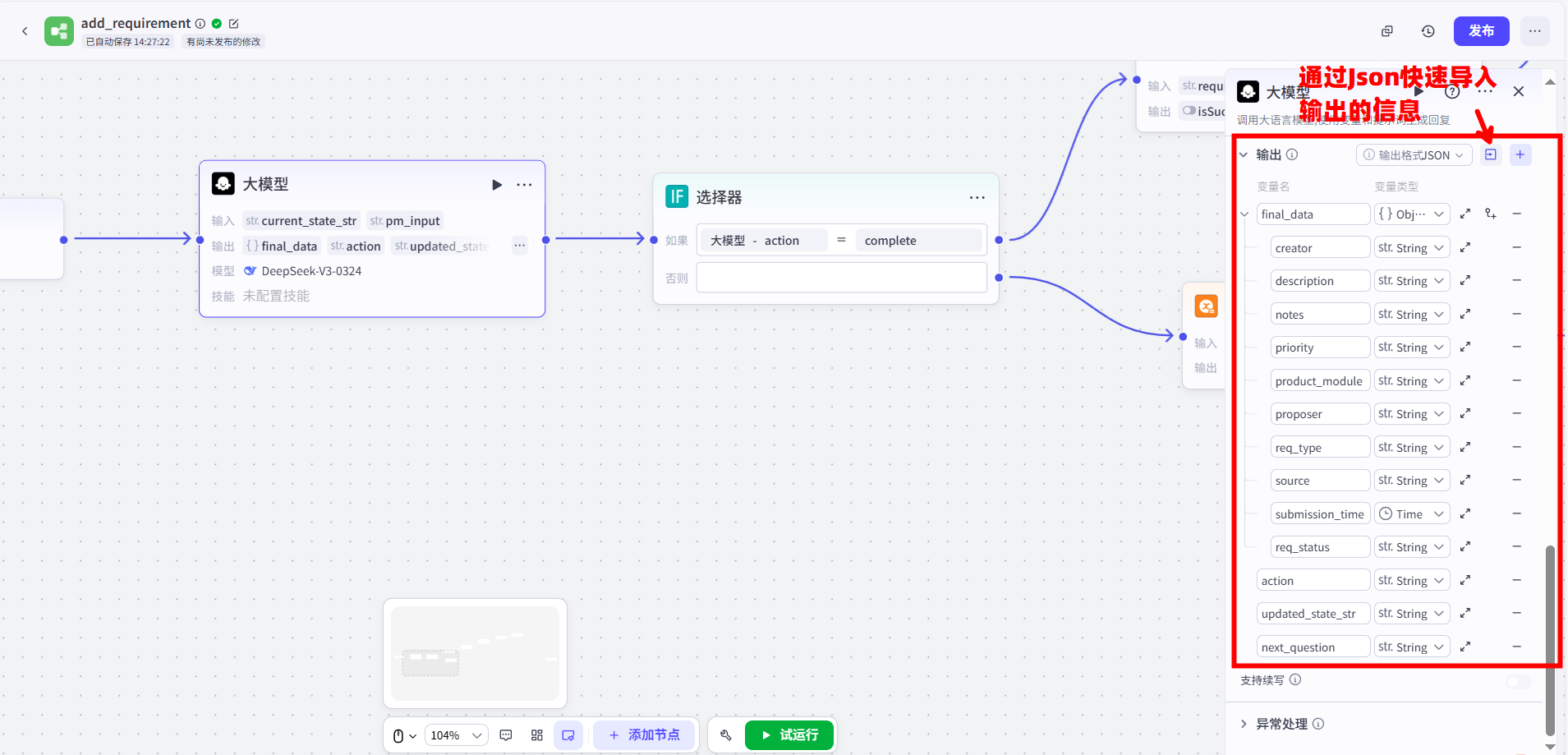
Json数据格式如下:
1 | { |
第二步:配置【选择器】进行任务分发
在【大模型】节点后,连接一个【选择器】节点,并设置其判断条件为:检查【大模型】节点输出的 action 变量,是否等于字符串 "complete"。
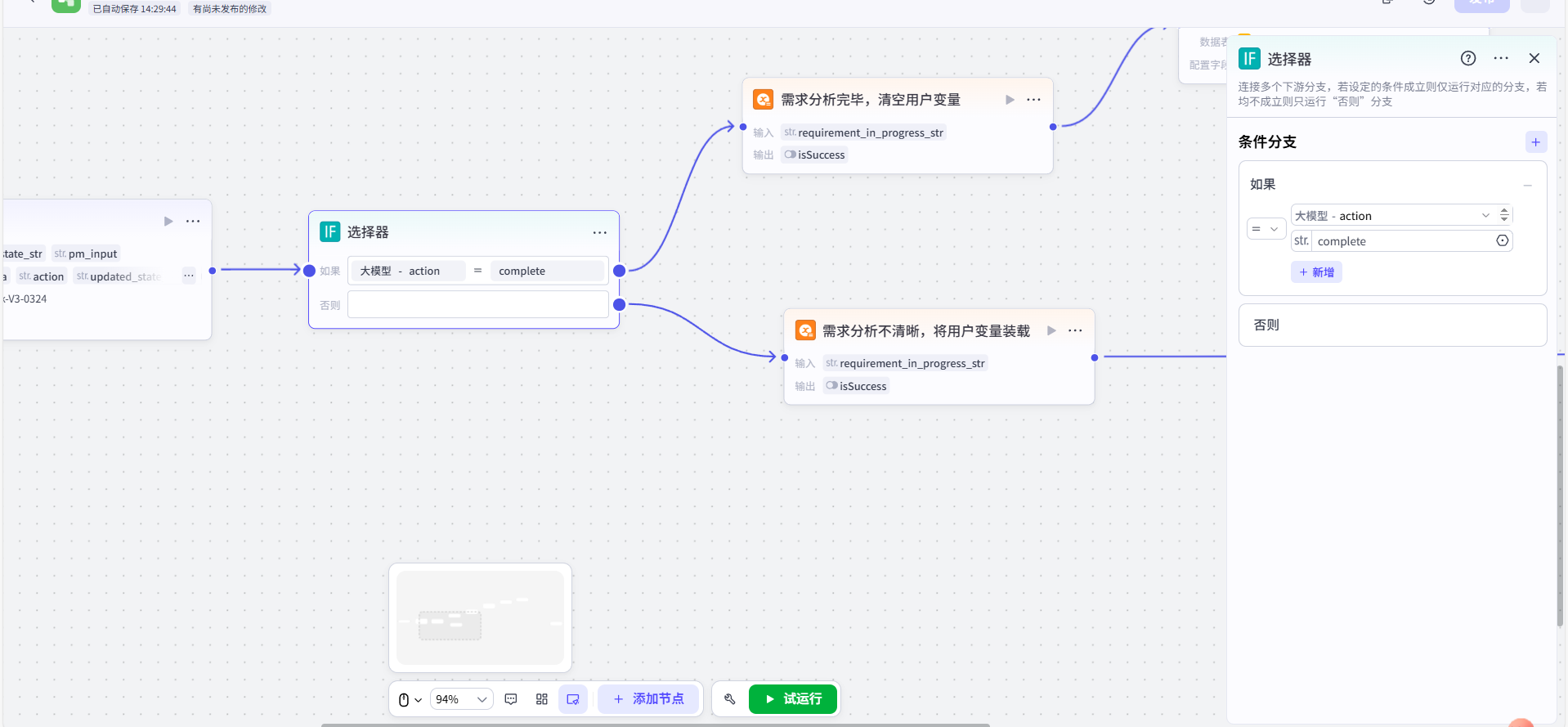
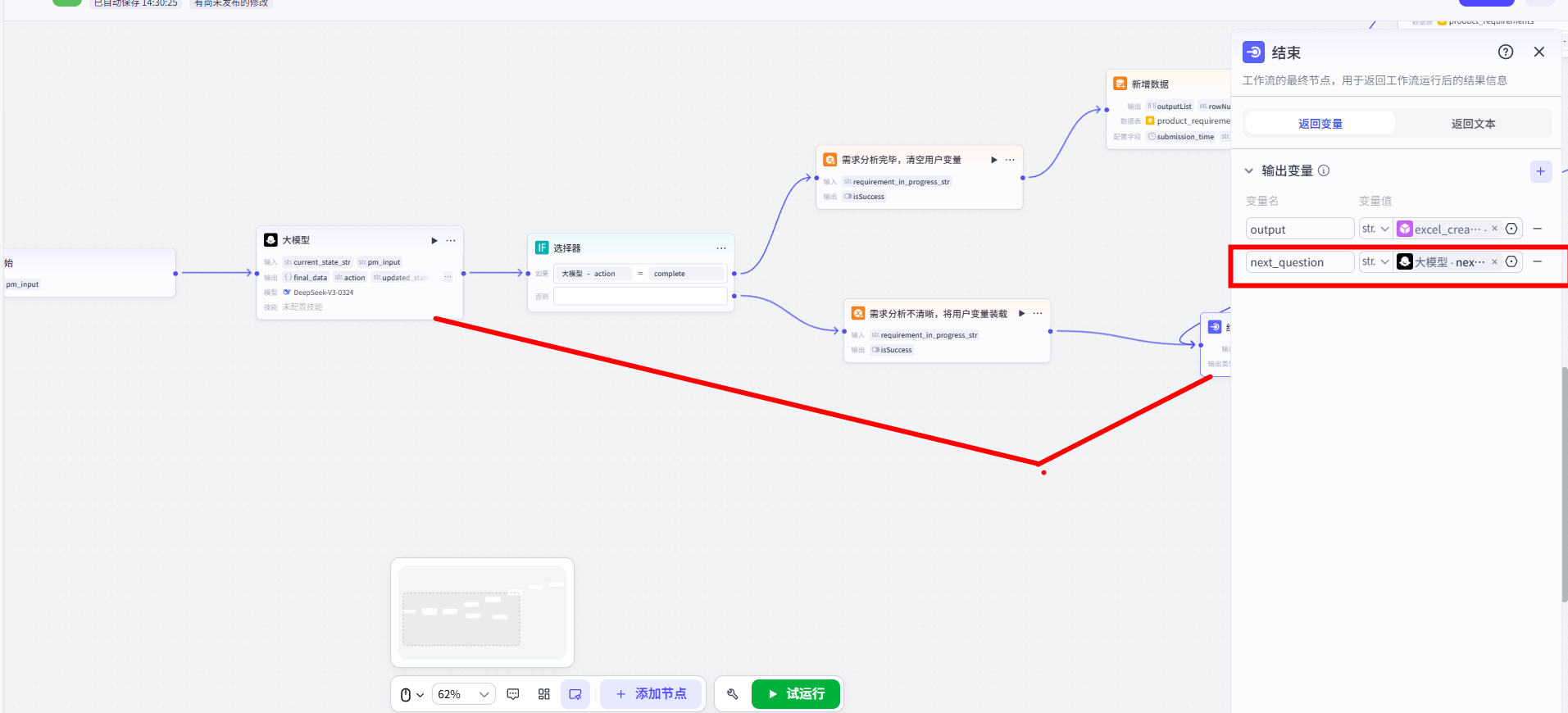
第三步:配置 false 分支(提示补全并缓存状态)
- 从【选择器】的
false出口,连接一个【变量赋值】节点。 - 配置该节点,将【大模型】输出的
updated_state_str,赋值给我们之前创建的requirement_in_progress_str用户变量。这是“保存草稿”的关键一步。 - 将【变量赋值】节点连接到一个【结束】节点,并将【大模型】输出的
next_question作为 Bot 的回复。
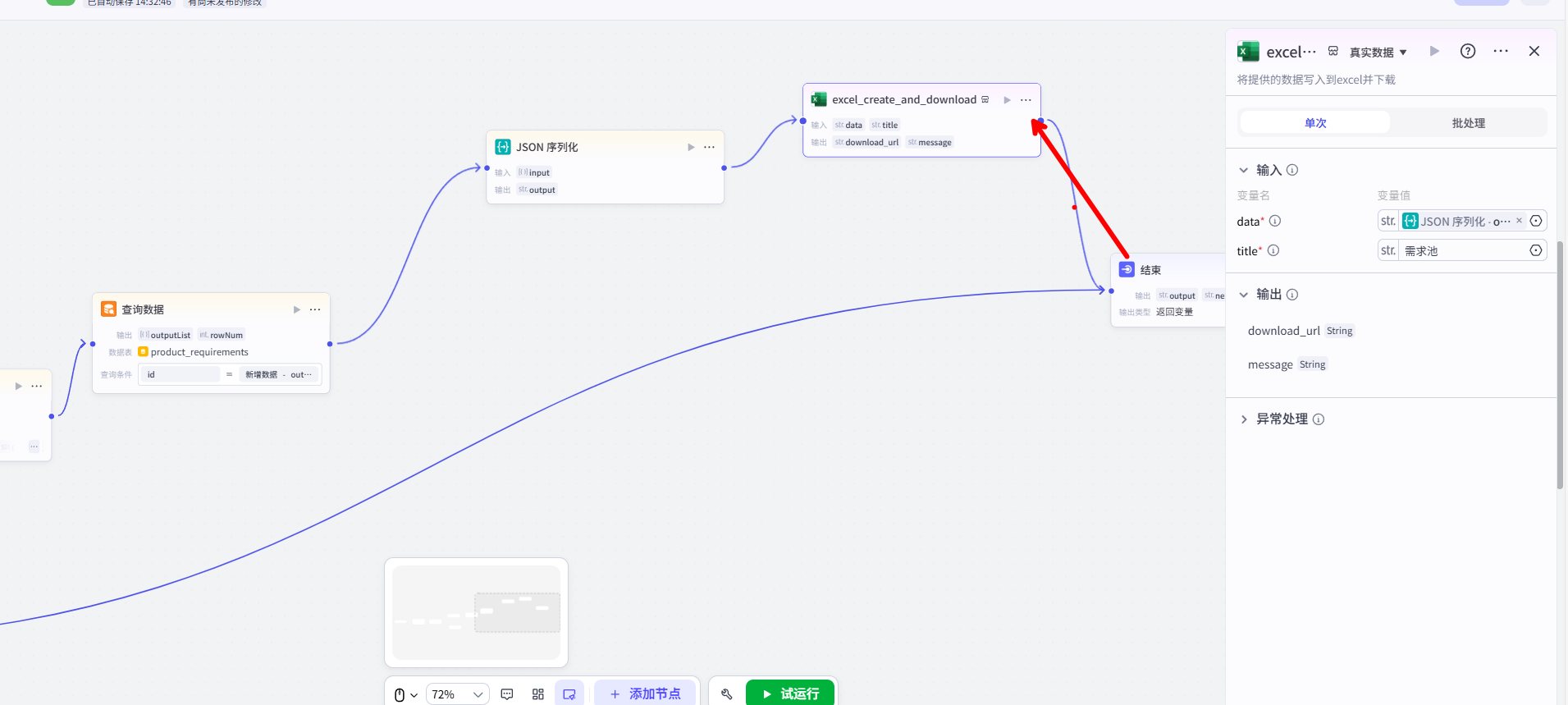
第四步:配置 true 分支(入库并导出 Excel)
这是当所有信息都收集完整后的“成功路径”,请严格按照以下顺序连接节点:
1.清空状态:从【选择器】的 true 出口,首先连接一个【变量赋值】节点。配置它将 requirement_in_progress_str 用户变量的值重置为空字符串 ""。
2.新增数据:连接一个【新增数据】节点。将其输入配置为接收来自【大模型】的 final_data 对象,并完成所有字段映射。
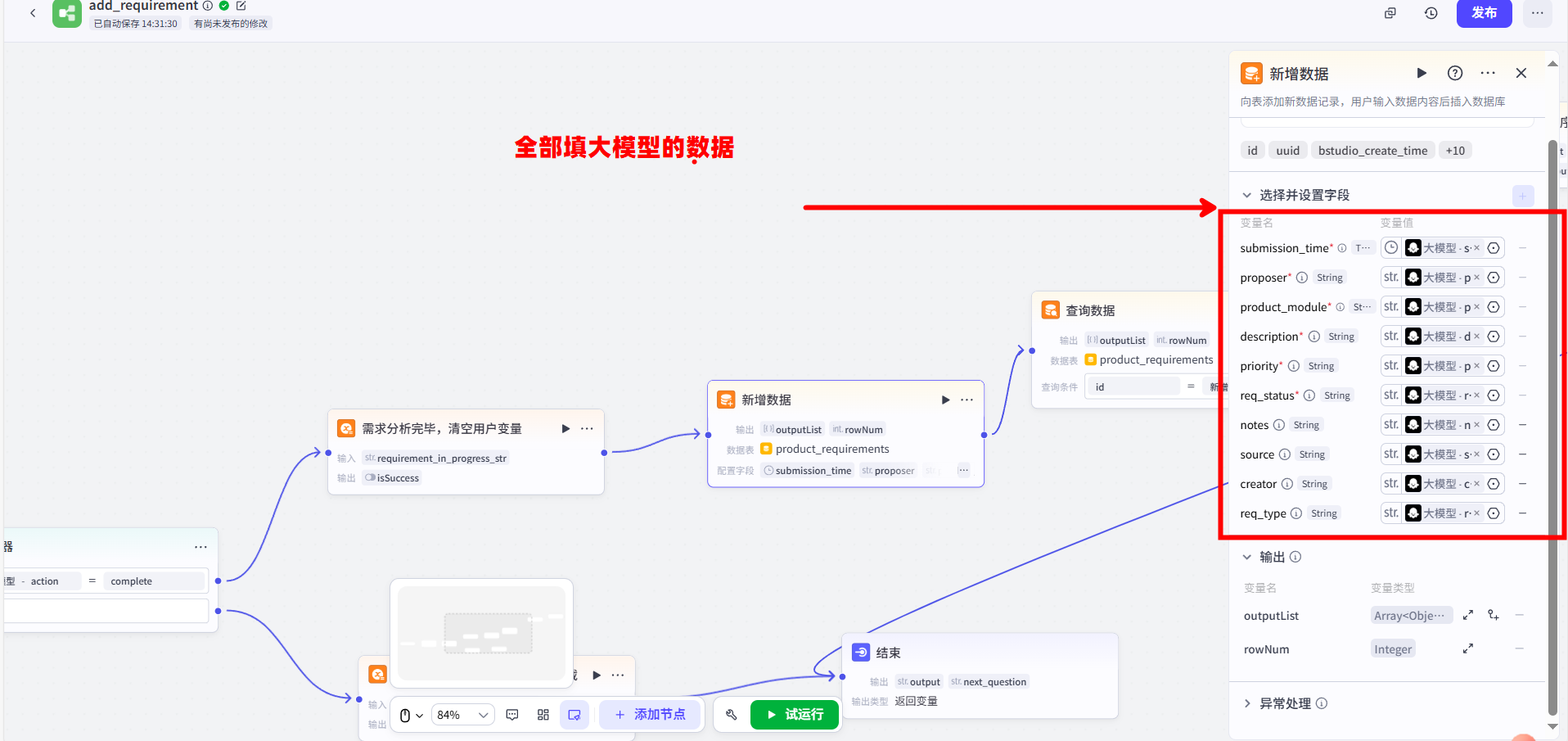
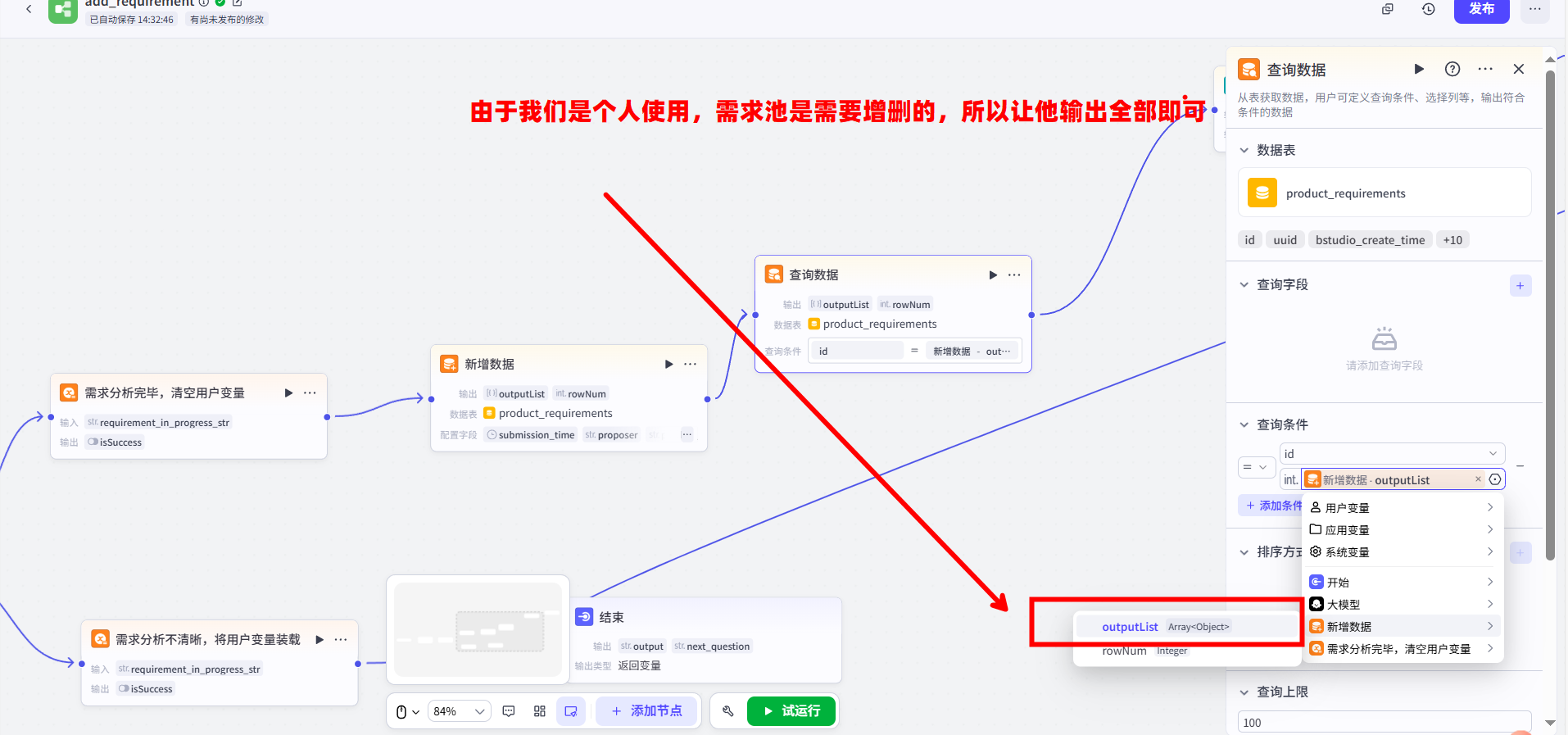
3.查询刚写入的数据:连接一个【查询数据】节点。配置它查询 product_requirements 表,并添加一条筛选条件:id 等于 上一步【新增数据】节点输出的 outputList
重要信息: 注意,这里我故意的将他的输出是outputList,指的就是之前我们对话过的所有信息都会附带生成Excel表格
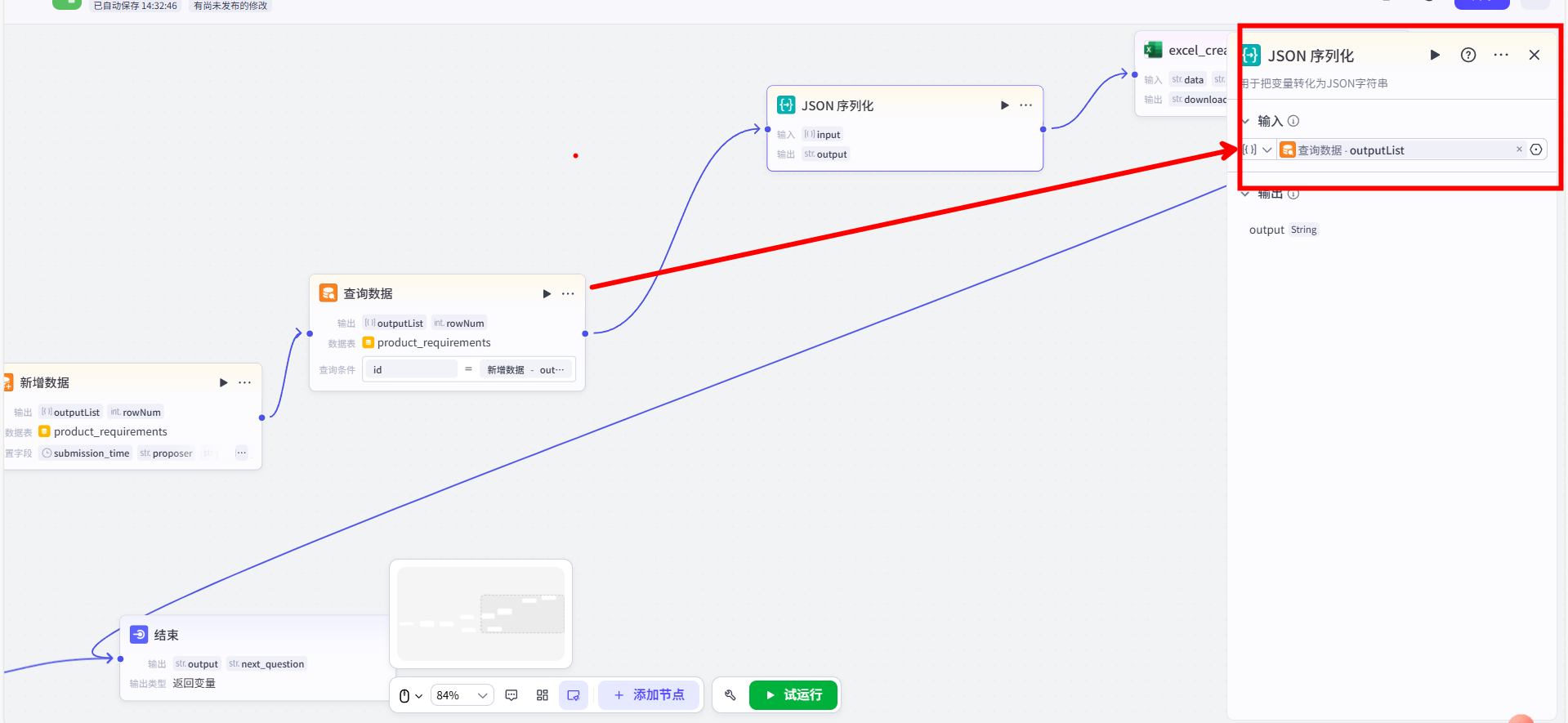
3.序列化为JSON:连接一个【JSON 序列化】节点。将其输入连接到上一步【查询数据】的 outputList 输出。生成Excel文件:连接 excel_create_and_download 插件。
- 将【JSON 序列化】节点的
output输出,连接到插件的data输入。 - 可以在插件的
title输入中填入一个固定的文件名,如“最新需求记录”。
返回下载链接:最后,连接一个【结束】节点,并将其输出配置为接收来自 Excel 商店插件的 download_url,直接搜索excel_create_and_download即可找得到