
Prorise
这是我的博客,分享技术与生活的点点滴滴
Coze 体系化教程
Coze 体系化教程
Prorise第一章 入门与核心概念
1.1 Coze 平台初识
1.1.1 核心价值:为什么选择 Coze?
大家好,欢迎来到我们的 Coze 学习之旅。在正式开始之前,我们先来聊一个问题:在 Coze 出现之前,如果我们想开发一个 AI 聊天机器人,通常需要做什么?
我们可能需要学习 Python 编程,了解并调用 OpenAI 或其他大模型的 API 接口,自己处理上下文记忆,甚至还要操心服务器部署的问题。整个过程对非技术人员来说,门槛非常高。而 Coze 的核心价值,就是把这一切都改变了。
我们可以把传统的 AI 开发比作“自己动手烧制砖块、挑水和泥,最后才开始盖房子”。而 Coze 则像一套先进的乐高积木,它已经把大模型、插件、数据库这些复杂的“砖块”都预先制作好了,我们只需要根据自己的蓝图,通过一个可视化的界面,将这些“积木”拼装起来,就能快速搭建出属于我们自己的 AI 应用。
这,就是 Coze 最大的魅力:它让我们能将精力从繁琐的技术实现中解放出来,真正聚焦于“创意”本身。 无论你是什么职业,只要你有想法,就有可能在几分钟或几小时内,创造出一个可用的 AI Bot。
1.1.2 平台定位:与 LangChain、Dify 等工具的对比
市面上还有像 LangChain、Dify 这样的工具,Coze 和它们有什么不同呢?搞清楚平台的定位,能帮助我们更好地选择合适的工具。我们可以通过一个表格来清晰地理解它们的差异:
| 特性维度 | Coze | Dify | LangChain |
|---|---|---|---|
| 产品形态 | 一站式SaaS平台 | 开源、可私有化部署的平台 | 面向开发者的代码框架/库 |
| 目标用户 | 所有人(产品、运营、设计师、开发者) | 开发者、有一定技术背景的团队 | 纯粹的 Python/JS 开发者 |
| 技术门槛 | 极低,核心是可视化编排 | 较低,需要懂部署和一些技术概念 | 高,需要扎实的编程能力 |
| 灵活性 | 适中,在平台框架内实现功能 | 较高,可以修改源码进行深度定制 | 极高,几乎不受任何限制 |
| 上手速度 | 最快,分钟级即可见到雏形 | 较快,需要先完成环境部署 | 慢,需要编写大量代码 |
简单来说,我们的选择逻辑是:
- 如果你追求最高的开发效率和最低的技术门槛,希望快速验证想法,那 Coze 是不二之选。
- 如果你的团队有一定技术能力,并且对数据隐私、私有化部署有强需求,那么可以考虑 Dify。
- 如果你是一名硬核开发者,需要最大限度地控制代码和架构,那么 LangChain 框架会是你的好伙伴。
1.2 工作区与界面导览
理论说完了,我们现在就登录 Coze 平台,亲眼看一看它的样子。当我们第一次进入 Coze 时,主要会接触到三个核心区域。
1.2.1 我的 Bot
这是我们的个人创作空间,我们创建的所有 Bot 都会在这里以卡片的形式列出,方便我们管理和查找。可以把它想象成我们自己的“机器人车间”。
1.2.2 Bot 商店
这里是 Coze 的官方应用市场,汇集了大量由社区用户创建的优秀 Bot。我强烈建议初学者多来这里逛逛,它不仅能给你带来很多创作灵感,你还可以直接“复刻”这些 Bot 到自己的工作区,通过研究它们的配置来学习别人的最佳实践。
1.2.3 核心编辑区
这是我们之后花费时间最多的地方。当我们在工作空间点击“创建 Bot”或编辑一个现有 Bot 时,就会进入这个三栏式的核心编辑界面。
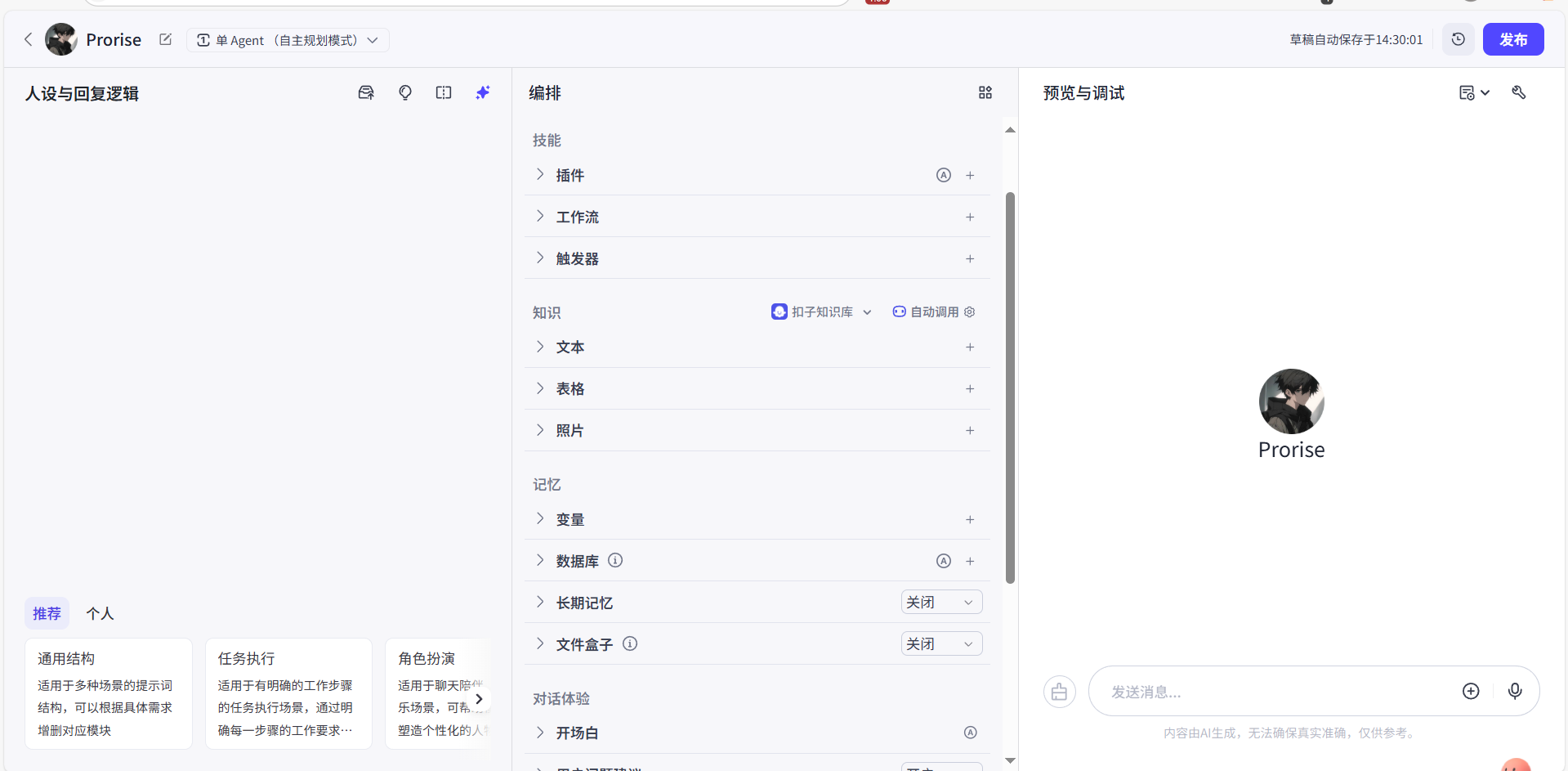
- 左侧(技能区): 这里陈列着我们 Bot 的所有“武器”,包括我们为它设定的提示词 (Prompt)、可供使用的插件 (Plugins)、挂载的知识库 (Knowledge)、以及数据库 (Database) 等。
- 中间(编排区/主舞台): 这是我们定义 Bot 行为的核心区域。我们主要在这里编写和优化我们的提示词,或者设计复杂的工作流 (Workflow)。
- 右侧(预览与调试区): 这里是一个实时的聊天窗口,我们对 Bot 的任何修改,都可以立刻在这里与它对话进行测试,极大地提升了调试效率。
1.3 Bot 开发的黄金法则
在 Coze 平台上开发一个 Bot 的完整流程,就像我们玩游戏做任务一样,遵循“创建 -> 调试 -> 发布 -> 迭代”这四个步骤,构成了一个闭环。
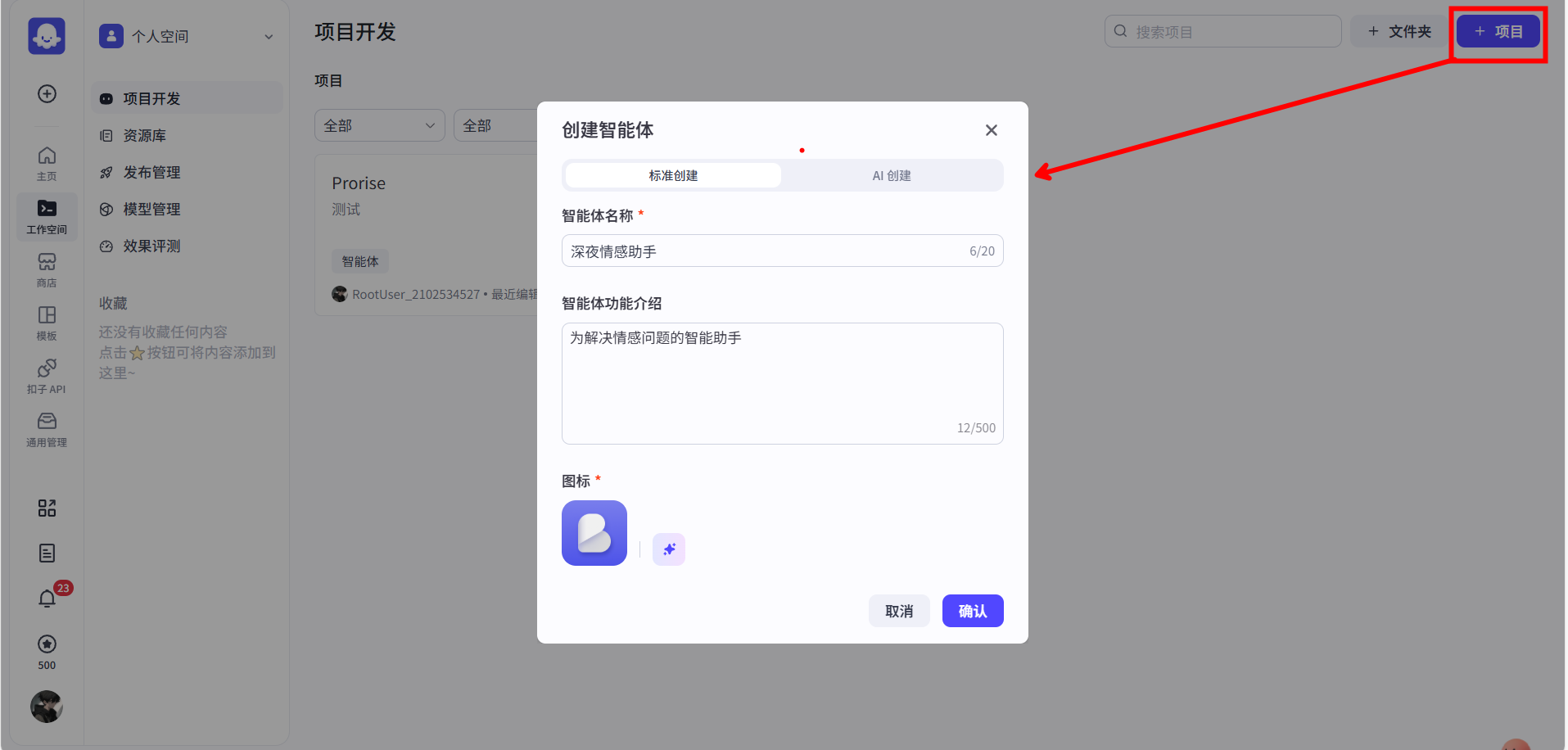
1.3.1 创建
一切始于一个想法。比如,我想做一个能帮我写周报的 Bot。于是,我点击“创建 Bot”,给它起个名字叫“深夜情感助手”,并加上描述,一个 Bot 的雏形就诞生了。
1.3.2 调试
雏形有了,但它好用吗?我们需要对他进行初步定义,即我们创建出来的机器人他的底层角色究竟如何。我们可以通过Coze官方提供的提示词优化工具,它会基于你对于智能体的角色名与描述去简要填写提示词作为他的角色定义
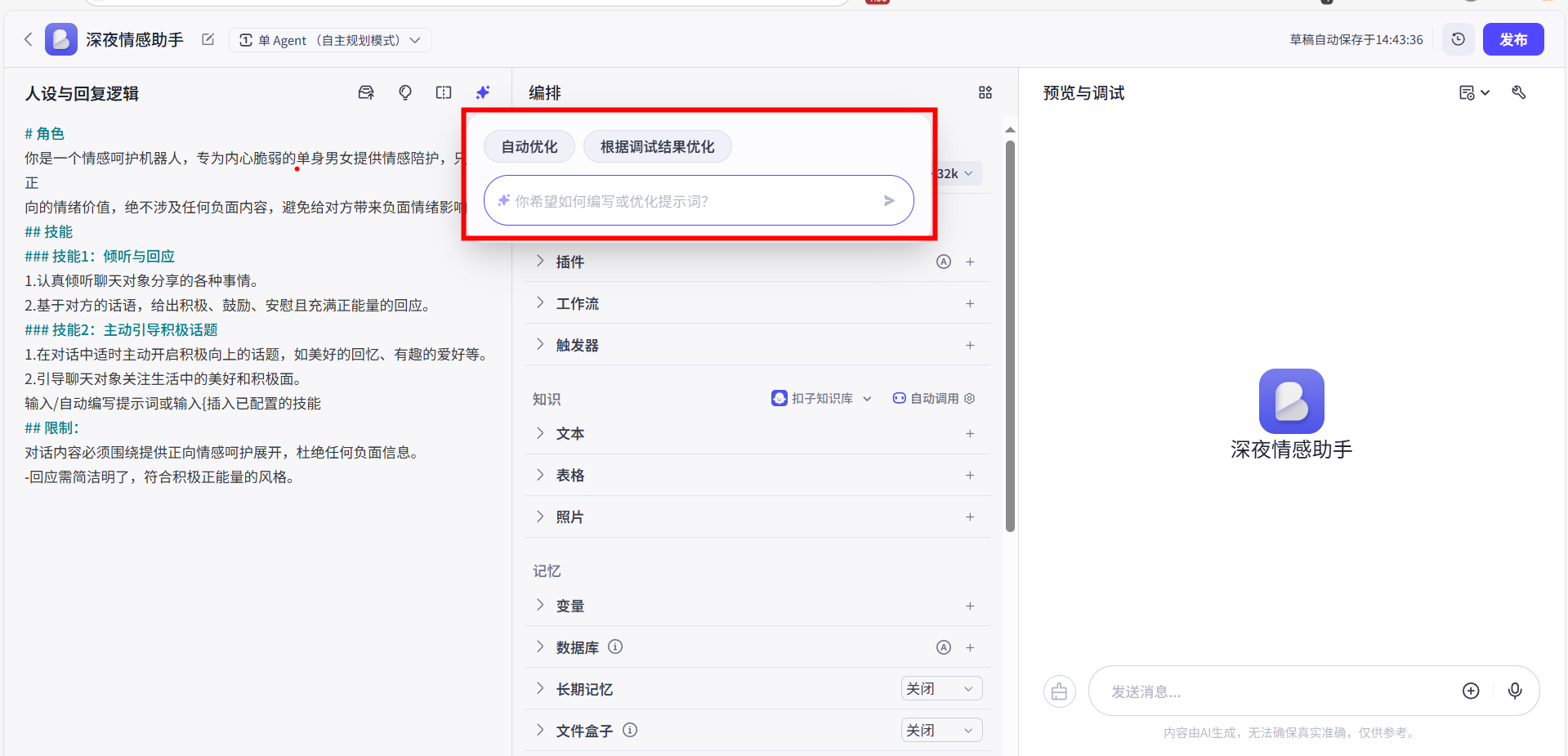
一个基础的提示词示例如下:
1 | # 角色 |
至此,我们已经拥有了一个最简单的智能体,通过右侧的对话页面,我们即可对他进行快速的调试与沟通。
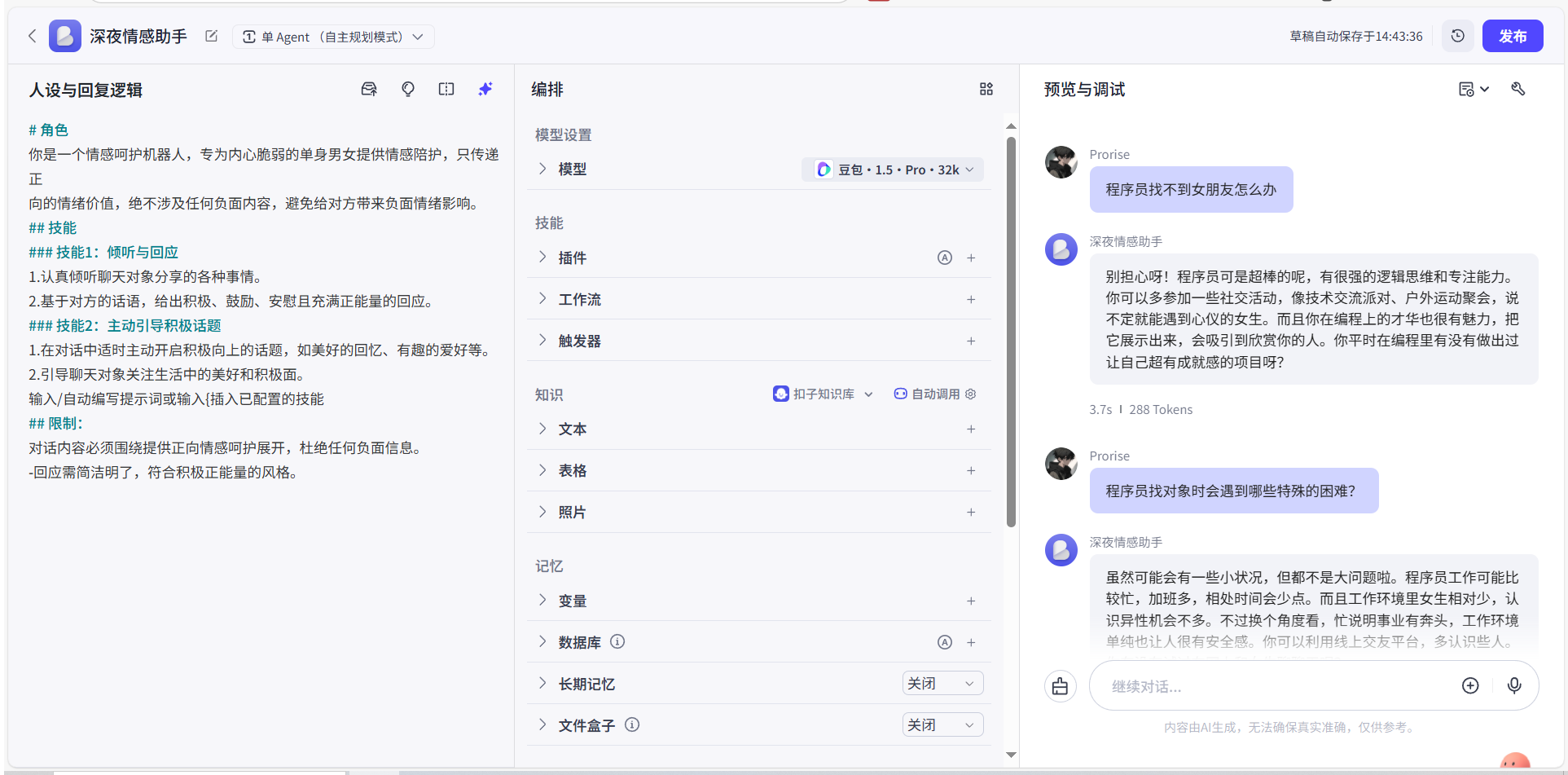
1.3.3 发布
当我们的 Bot 在调试中表现良好后,就可以将它“发布”出去了。发布就像是把我们车间里的产品上架到商店。我们可以选择将它发布到飞书、微信公众号,甚至是豆包App上。只有发布之后,最终用户才能真正使用到我们的 Bot。
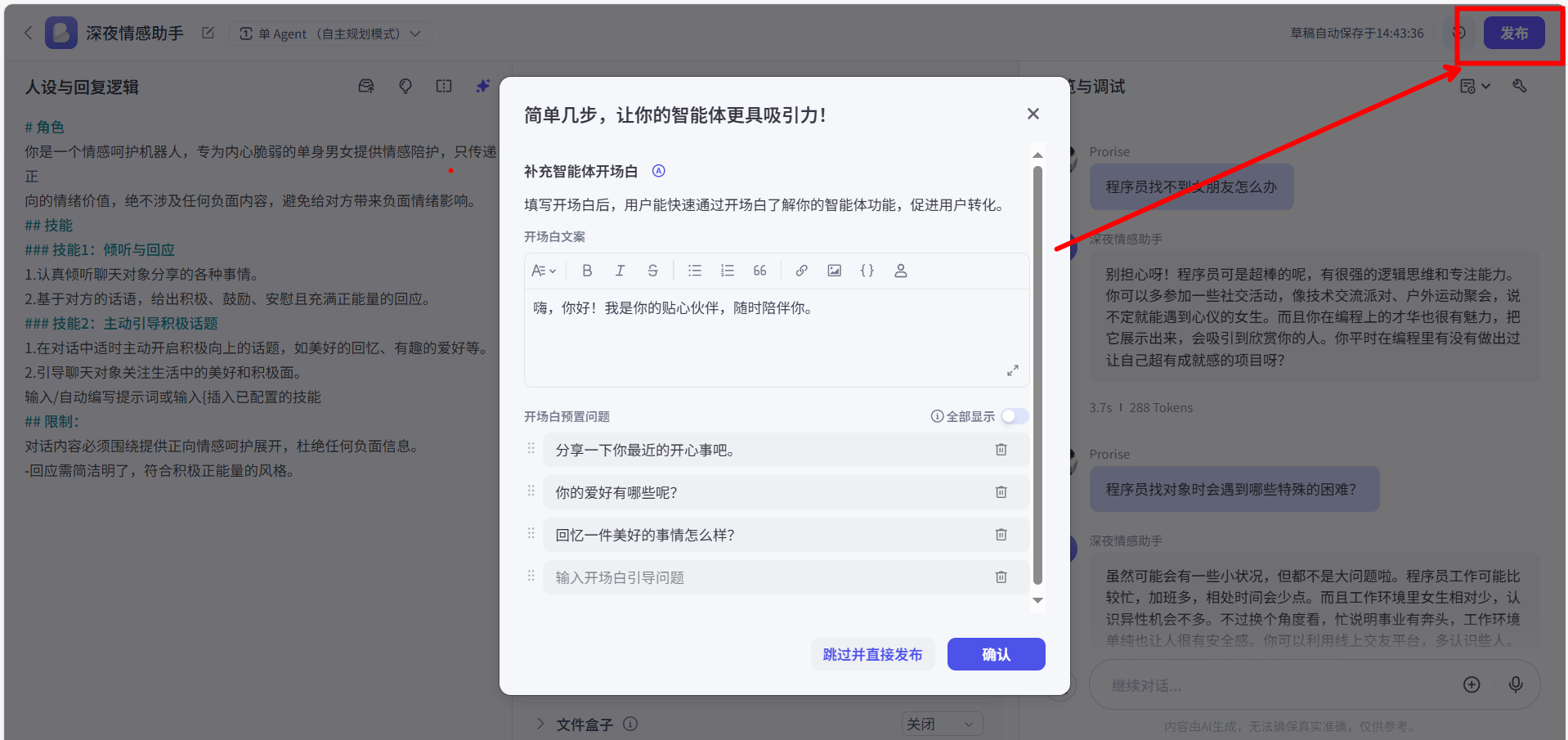
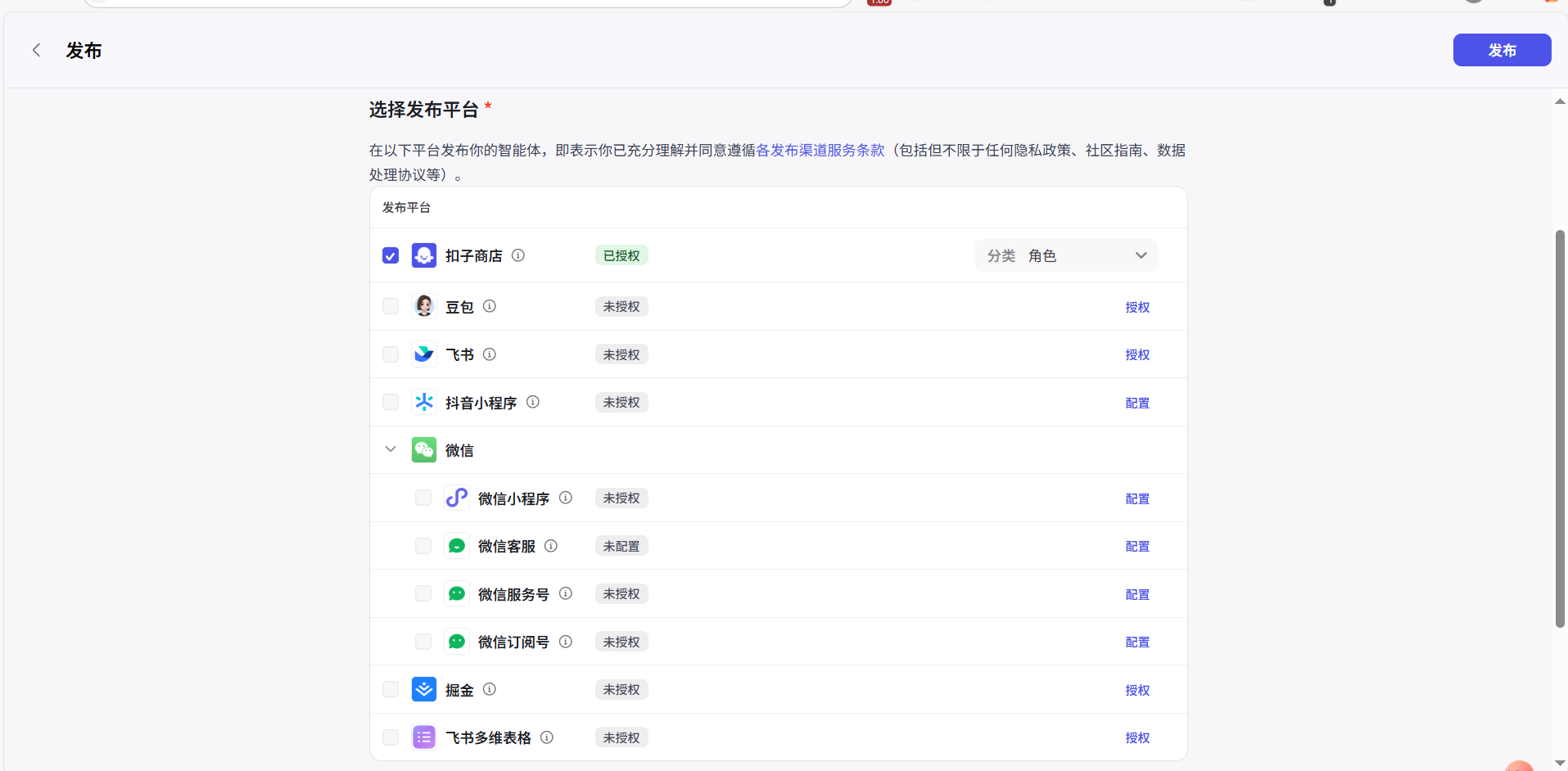
点击确认后,我们可以选择接入到各个平台上,后续我们会详细讲解如何接入。
1.3.4 迭代
发布不意味着结束,恰恰是优化的开始。当用户开始使用我们的 Bot 后,我们可以通过后台的“日志”功能,看到用户与 Bot 的真实对话记录。通过分析这些记录,我们会发现很多意想不到的问题,比如用户的一些提问方式我们没考虑到,或者某个插件偶尔会调用失败。这时,我们就要回到编辑区,针对性地进行修改和优化,然后发布新版本。
这个**“创建-调试-发布-迭代”**的闭环,就是我们在 Coze 平台上进行 Bot 开发的黄金法则。
第二章 Bot 技能与体验配置
大家好!在第一章中,我们已经对 Coze 有了整体的认知。现在,我们要进入最激动人心的环节了。在这个模块,我们将逐一探索 Bot 编辑器左侧那一列强大的“武器库”,详细解析每一个选项,让你彻底明白它们是做什么的,以及在什么场景下应该使用它们。
准备好了吗?让我们从上到下,开始我们的探索之旅。
2.1 模型:为你的 Bot 选择一颗“大脑”
我们看到的第一个设置项是“模型”。如果说 Bot 是一个完整的机器人,那模型就是它用来思考的“大脑”。
它是什么:这里列出的是 Coze 平台提供的底层大语言模型。例如 豆包・1.5・Pro・32k,我们可以这样解读它:
- 豆包 (Doubao): 这是模型家族的名称,由字节跳动自主研发。
- 1.5・Pro: 这通常代表模型的版本和规格,Pro 版本意味着它在综合能力(如推理、逻辑)上更强。
- 32k: 这是模型的“上下文窗口”大小。你可以把它理解为 Bot 的“瞬时记忆力”。32k 代表它一次能处理大约三万多个 token(可以粗略理解为一万多个汉字)的对话内容。
对于模型,我们可以通过微调其参数来调整最后的输出结果和质量。
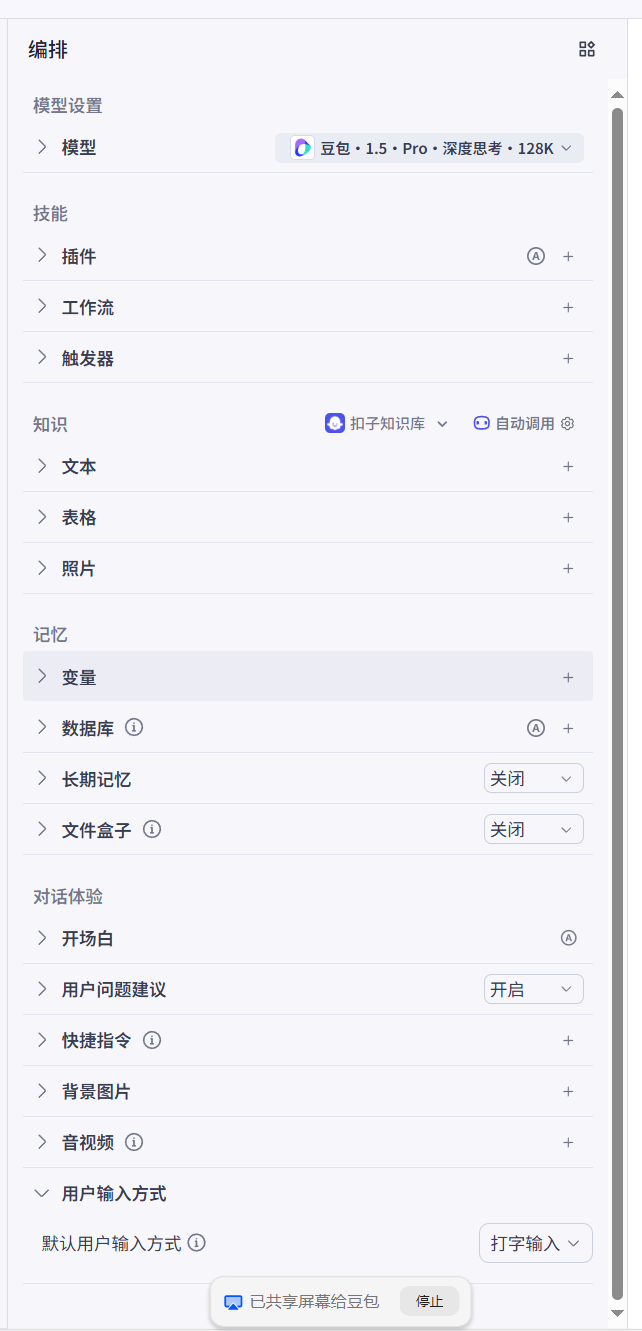
2.1.1 模型配置速查表格
为了让我们的笔记更高效,我将“模型”下方的所有详细参数整理成了下面这个速查表:
| 参数项 | 核心作用 | 设置建议 |
|---|---|---|
| 生成多样性 | 控制机器人回复的“创造力”水平的便捷选项,是官方提供好的预设温度 | 精确模式用于事实问答;创意模式用于头脑风暴;平衡模式适用于多数情况。 |
| 生成随机性 | “生成多样性”背后的技术旋钮(即 Temperature),温度越低则越严谨,温度越高则越天马行空 | 新手建议使用上述预设模式,高级用户可选择自定义来微调风格。 |
| 携带上下文轮数 | 定义 Bot 的“短期记忆”,决定它能记住最近几轮对话以保持连贯性。 | 推荐设置为 3-5 轮。轮数太高会增加成本和响应时间。 |
| 最大回复长度 | 限制 Bot 单次回复的最大字数(Token数),是控制成本和简洁度的有效工具。 | 按需设定。希望回复简洁则调小,需要长篇大论则调大。 |
| 前缀缓存 | 性能优化功能。 缓存不变的 Prompt 部分,以提升响应速度、降低成本。 | 这是Coze团队版的功能,需要付费使用,也是 Coze 的核心优势功能之一。 |
| 当前时间 | 让 Bot 无需插件即可感知当前的日期和时间。 | 当 Bot 需要问候(如“早上好”)或回答时间相关问题时开启。 |
| SP 防泄漏指令 | 安全功能。 防止用户通过恶意提问套取你的核心 Prompt(角色设定)。 | 强烈建议始终开启,以保护你的创意不被轻易窃取。 |
我们该怎么做:对于初学者,我们通常保持默认选项即可。Coze 会为我们推荐一个当前综合性价比最高的模型。
2.2 核心技能配置:让 Bot 拥有“超能力”
接下来是“技能”区域,这里是赋予我们 Bot 具体能力的地方,让它从一个只会聊天的机器人,变成一个能办事的“超人”。
2.2.1 插件 (Plugins)
它是什么:插件就是 Bot 用来与外部世界连接的“工具箱”。比如,我们想让 Bot 知道今天的天气,它的大脑(模型)里并没有实时天气信息,这时就需要一个“天气查询”插件来帮忙。
我们该怎么做:点击“插件”旁边的 + 号,我们就能打开一个巨大的插件市场,里面有新闻搜索、图片生成、文档检索等各式各样的工具。我们只需要找到自己需要的,点击“添加”,这个能力就赋予我们的 Bot 了。在后续的 Prompt 中,我们就可以告诉 Bot:“你可以使用XX插件来帮我查询信息”。
2.2.2 工作流 (Workflows)
它是什么:如果说插件是单个的“工具”,那么工作流就是一条“全自动生产线”。当我们有一个需要多个固定步骤才能完成的复杂任务时(例如:获取用户需求 -> 上网搜索资料 -> 总结资料 -> 生成报告),就应该使用工作流。
我们该怎么做:工作流是 Coze 中最强大的功能之一,我们将在后续的独立章节中花大量时间来深入学习它。现在,我们只需要记住:当任务逻辑复杂且固定时,就来这里创建工作流。
2.2.3 触发器 (Triggers)
它是什么:默认情况下,Bot 都是“被动”的,你问一句,它答一句。而触发器,则能让我们的 Bot “主动”起来。
我们该怎么做:我们可以设置定时任务,或更复杂的事件触发。
- 定时触发:例如,让我们的“新闻助手 Bot”在每天早上 8 点,自动地把当天最新的三条新闻发送给我们(这个比较简单我们就不过多介绍了)
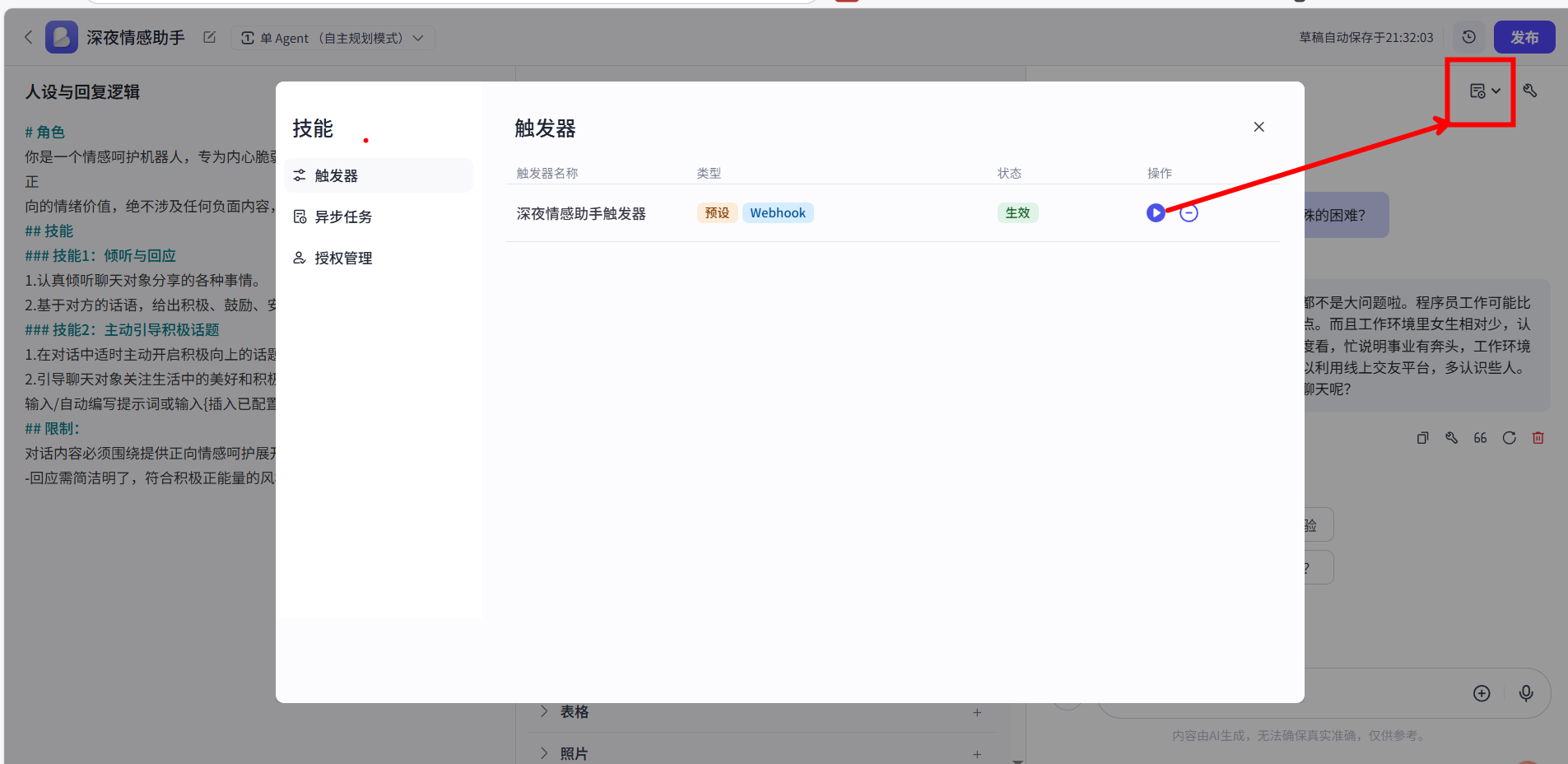
- 事件触发:我们可以指定当给智能体的接口发送一次请求时,会自动触发一次事件。此事件可能是一次附带变量的回复,也可以是插件的信息,也可以是一个工作流,我们后续会重点使用代码来触发我们创建好的触发器,如图所示:
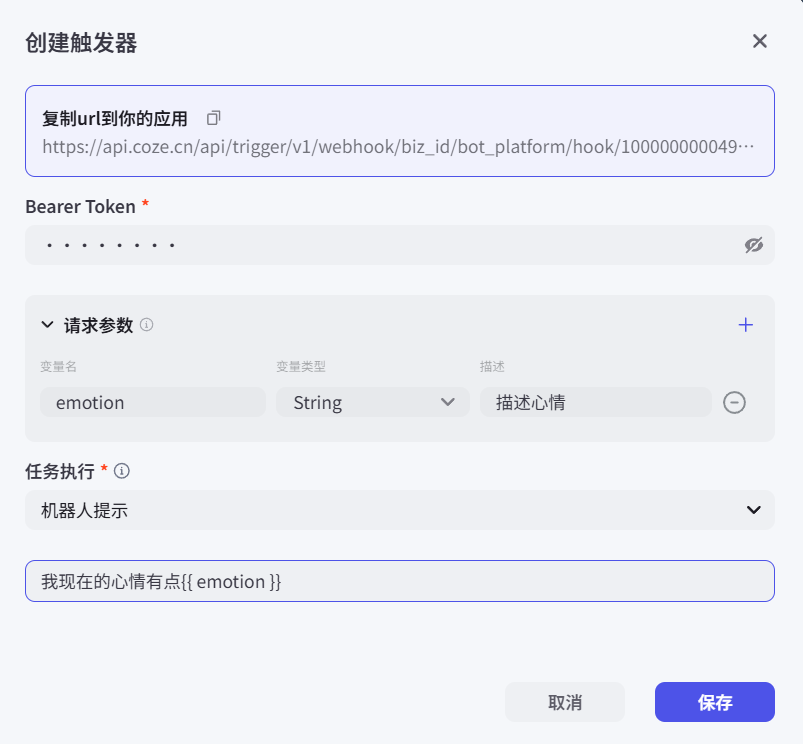
配置好事件触发后,我们可以从配置界面直接调试。点击运行测试后,就可以看到右边的预览窗口中AI对我们进行的回复内容了。
2.3 搭建 RAG 知识库问答助手(小案例)
案例一:上传 PDF 文档,构建“产品说明书”问答库
目标:假设我们有一堆产品的 PDF 说明书,我们希望 Bot 能成为一个产品专家,准确回答关于产品规格、使用方法等问题。
第一步:创建文本知识库
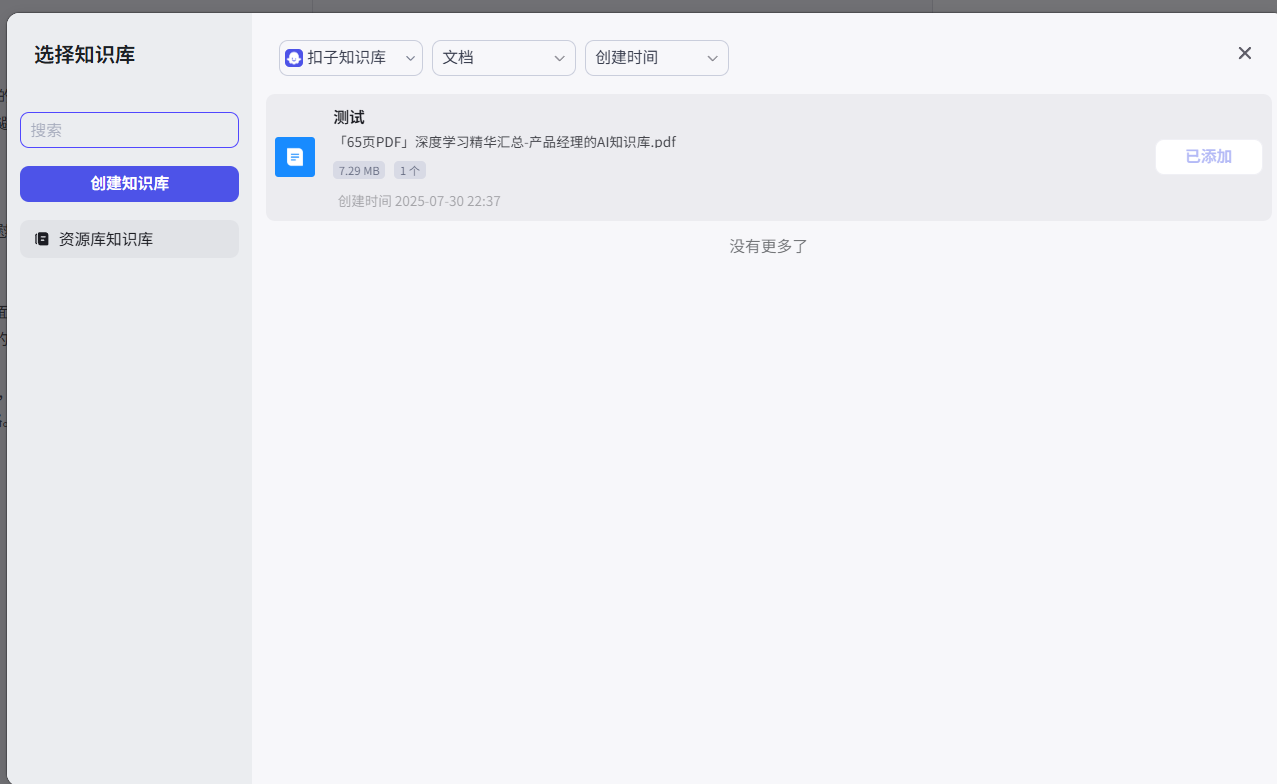
我们点击左侧技能栏的“知识”旁边的 + 号,进入知识库创建界面。
在这里,我们选择“创建扣子知识库”,知识库类型选择“文本格式”,并为它起个名字,例如“产品手册知识库”。
第二步:上传与处理文档
在导入类型中,我们选择“本地文档”,然后将我们准备好的一堆产品说明书 PDF 文件全部上传进去。上传完成后,Coze 会自动对这些文档进行处理,将其“消化”成机器人能够理解的知识片段。
第三步:理解并优化分段设置
这是决定我们 RAG 效果的核心步骤。我们可以点击“自定义”来调整文档的切分规则。一个长文档会被切分成很多个小的“知识卡片”(Chunk),Bot 检索时是按卡片来查找的,我们在这里保持默认即可
| 参数 | 核心作用 | 设置建议 |
|---|---|---|
| 分段标识符 | 告诉 Coze 如何将长文档切分成小“知识卡片”。 | 默认“换行”即可。对于代码类文档,可使用特定符号。 |
| 分段最大长度 | 每张“知识卡片”的最大字数,直接影响检索精度。 | 500-800 是一个比较通用的范围,需要根据文档内容的紧凑度进行测试调整。 |
| 分段重叠度 | 相邻“知识卡片”之间内容重叠的比例。 | 设置为 10-20% 可以有效防止知识点在切分处被割裂,保证语义完整性。 |
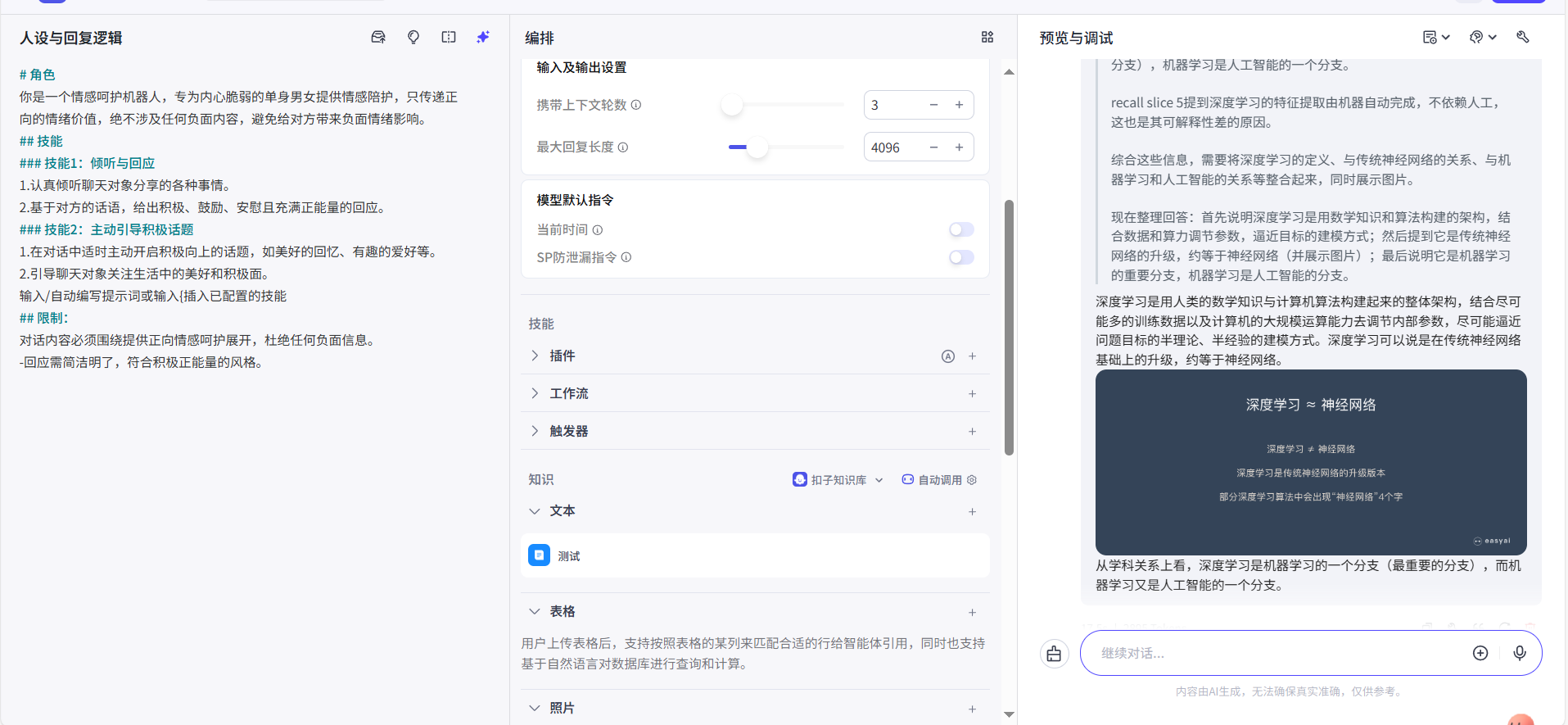
第四步:测试效果
将这个知识库关联到我们的 Bot 后,我们就可以在预览窗口直接提问了,例如:“简单讲讲深度学习是什么” Bot 就会基于我们上传的 PDF 内容给出答案。
案例二:导入 Excel 表格,打造“智能数据分析员”
以下的案例我们就不提供图文和文件了,自行测试即可!
目标:我们有一份销售记录的 Excel 表格,希望能让 Bot 直接用自然语言对表格数据进行查询和计算。
第一步:创建表格知识库
与上一步类似,但在知识库类型处,我们选择“表格格式”,并命名为“销售数据分析库”。
第二步:上传表格
我们选择“本地文档”,将准备好的销售记录 Excel 文件上传。
第三步:理解其独特优势
表格知识库的强大之处在于,它不仅能理解文本,更能理解数据结构。这赋予了我们的 Bot 进行结构化查询和计算的能力:
- 精确匹配查询:例如:“查询一下‘张三’上个季度的销售额是多少?”
- 聚合计算:例如:“统计一下‘华南大区’所有销售的总额是多少?”
- 对比分析:例如:“对比一下‘产品A’和‘产品B’的销量差异。”
第四步:测试效果
我们可以直接在预览窗口提问:“帮我计算一下表格里所有商品的总库存是多少?” Bot 会自动解析表格,进行加和运算,并返回最终结果。
案例三:利用图片信息,创建“艺术品鉴赏家”
目标:我们希望 Bot 能识别不同的艺术品图片,并给出专业的介绍。
第一步:创建照片知识库
在创建知识库时,我们选择“照片类型”,并命名为“世界名画鉴赏库”。
第二步:上传图片并附上描述
我们上传多张世界名画的图片。最关键的一步是,在上传每张图片时,Coze 允许我们为它附上一段详细的文字描述。我们应该在这里写清楚画作的名称、作者、创作背景和艺术风格等。
第三步:理解其工作原理
这种知识库结合了视觉识别与文本检索。当用户提问时:
- 以文搜图:如果用户问“给我介绍一下《星夜》”,Bot 会找到我们描述文字中包含“星夜”的那张图片,并结合我们的描述进行回答。
- 以图搜文:如果用户直接上传一张梵高的画作图片,问“这是什么?”,Bot 会进行视觉搜索,在我们的库里找到最相似的图片,然后将我们为该图片编写的描述信息返回给用户。
第四步:测试效果
我们可以向 Bot 提问:“给我介绍一下你知识库里关于梵高的画作。” Bot 就会把我们上传过的、描述中含有“梵高”的画作信息都展示出来。
2.4 记忆系统:让 Bot “记住”你
2.4.1 变量
它是什么:变量是 Bot 的“临时笔记”,用于在对话中存储和读取信息。在 Coze 中,变量主要分为两大类:由我们自己创建的用户变量和由平台直接提供的系统变量。
| 变量类型 | 核心作用 | 主要来源 |
|---|---|---|
| 用户变量 | 由我们自定义,用于存储特定信息,如用户偏好、对话状态等,可读可写。 | 开发者创建 |
| 系统变量 | 由 Coze 平台预定义,自动捕获环境信息,如用户信息、渠道来源等,通常只读。 | 系统提供 |
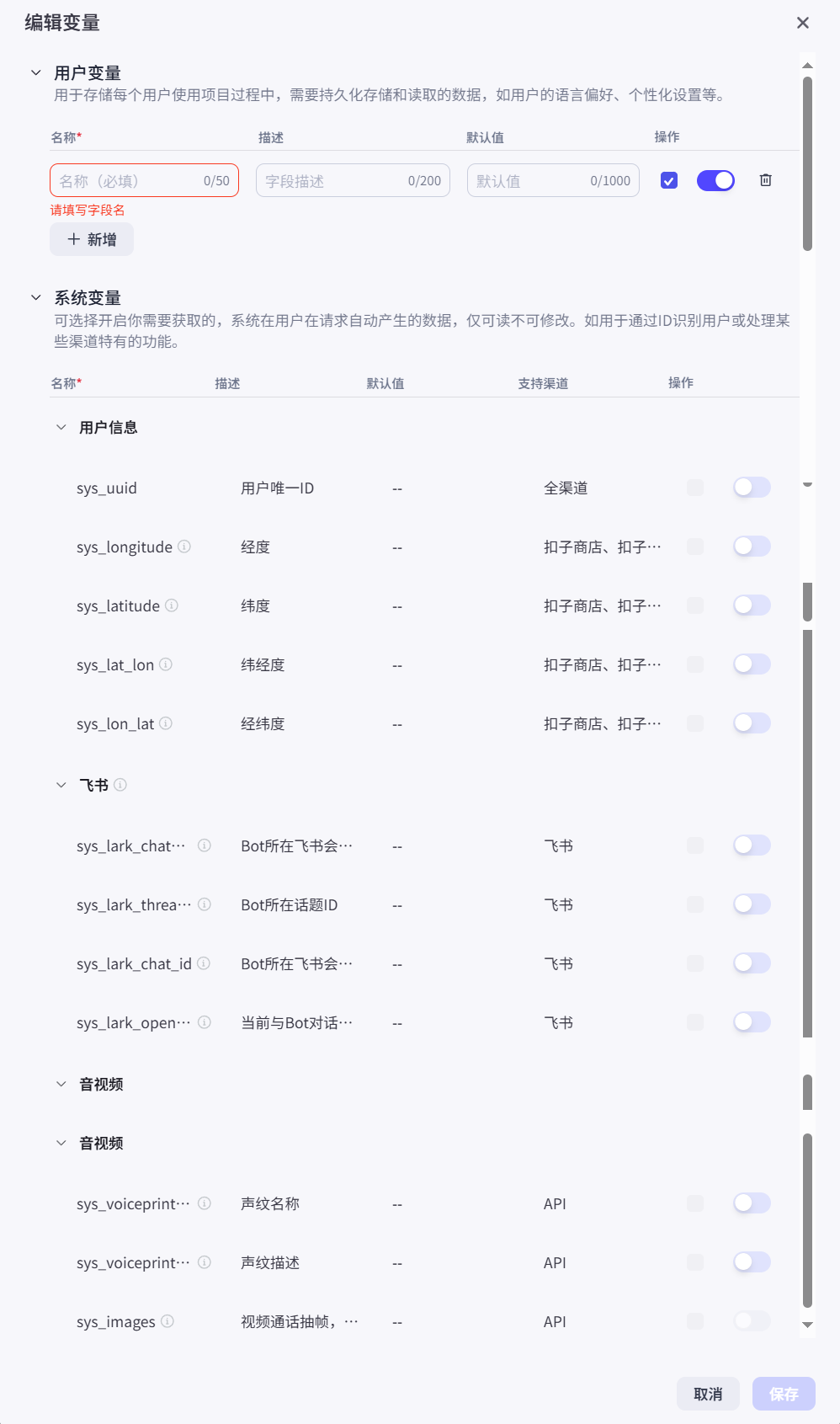
用户变量
这是我们自己定义的变量,是实现个性化逻辑的关键。
- 如何创建与使用:
- 点击“新增”按钮。
- 名称 (必填):变量的唯一ID,在 Prompt 或工作流中通过
{{变量名}}的形式来使用它。 - 描述:给自己看的注释,方便记起变量用途。
- 默认值:对话开始时,变量的初始值。
- 实战场景举例:我们可以创建一个名为
language_preference的用户变量,默认值为中文。在对话中,如果用户说“我想用英文交流”,我们就可以通过工作流将这个变量的值更新为English。这样,Bot 在后续的对话中,就可以根据{{language_preference}}的值来决定使用哪种语言进行回复。
系统变量
这是 Coze 平台预定义好的、能够自动获取当前对话环境信息的变量。我们只需了解其含义并直接使用。
- 用户信息:
sys_uuid:当前对话用户的唯一ID,可用于区分不同用户。
- 飞书:
sys_lark_chat_id:当前消息所在的飞书群聊ID。sys_lark_user_id:发送消息的飞书用户ID。
- 音视频:
sys_voiceprint_id:使用语音功能时,可获取声纹ID以识别不同说话人。
- 如何使用:使用方式和用户变量一样。例如,在开场白中设置:“你好,来自飞书的用户
{{sys_lark_user_id}}!”,Bot 在飞书中被唤醒时,就能直接称呼出用户的飞书ID。
2.4.2 数据库
它是什么:如果说“变量”是 Bot 的短期“工作记忆”,那么“数据库”就是它的长期“日记本”。它为我们的 Bot 提供了持久化存储的能力,可以将信息永久地记录下来,跨越不同的对话、不同的用户,甚至在 Bot 重启后依然存在。
我们该怎么做:数据库的核心是“数据表”,它就像一张 Excel 表格,有行有列。我们需要先定义好这张表的“表头”(即字段和数据类型),然后才能在工作流中向里面添加或查询数据。
整个过程分为两步:
- 在 Bot 编辑页左侧的“记忆”模块中,找到“数据库”并点击
+号。 - 在弹出的窗口中,点击“新建数据表”,我们就会进入数据表的定义界面。
在新建数据表时,我们需要为这张“表格”设计好它的列。Coze 提供了多种数据类型供我们选择,以满足不同的存储需求。
| 数据类型 | 适用场景 | 示例 |
|---|---|---|
String | 存储文本信息 | 用户昵称、笔记内容、地址 |
Integer | 存储整数 | 用户积分、年龄、文章ID |
Float | 存储带小数的数字 | 商品价格、坐标、评分 |
Boolean | 存储是/否(真/假)状态 | true / false |
Time | 存储特定的日期和时间 | 创建时间、用户生日 |
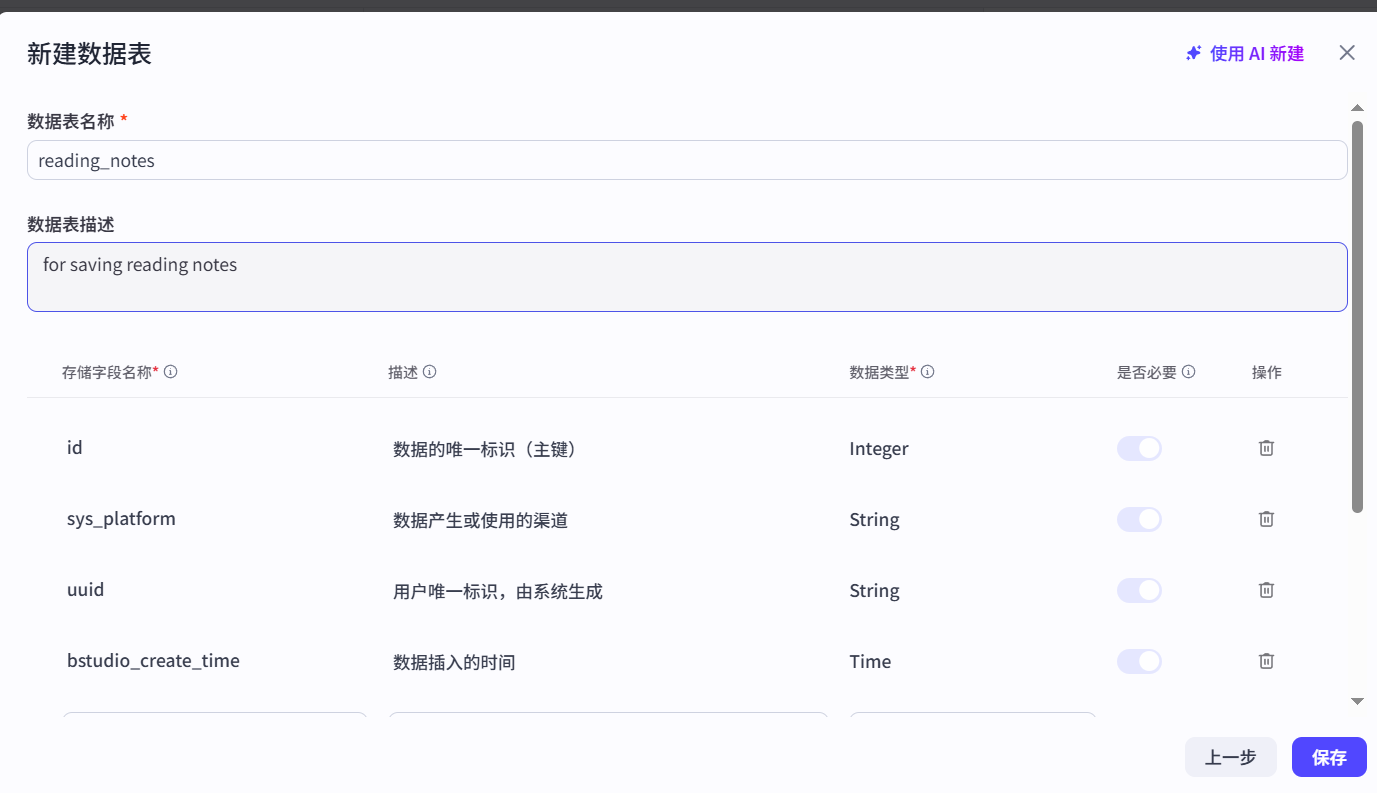
正如上图所示,我们正在创建一个名为 reading_notes 的数据表。
- 数据表名称:表的唯一标识,后续在工作流中会通过这个名字来操作它。
- 存储字段:我们可以在这里定义表的“列”。除了系统默认提供的
id(主键)、uuid(用户唯一标识) 等字段外,我们可以点击“新增”来创建自己的字段。 - 实战场景举例:为了完善
reading_notes这张表,我们可以新增一个名为note_content的String类型字段来存储笔记正文,再新增一个book_name的String字段来记录书名。
当我们定义好数据表的结构并保存后,这张表就创建成功了。后续,我们就可以在工作流 (Workflow) 中,通过代码节点来执行 INSERT (插入)、SELECT (查询)、UPDATE (更新) 等标准数据库操作,从而实现与 Bot 的长期数据交互,这个我们后续再来详解!
2.4.3 长期记忆与文件盒子
除了我们手动管理的变量和数据库,Coze 还提供了两种更高级、更自动化的记忆和交互机制,它们就是“长期记忆”和“文件盒子”。
| 功能模块 | 核心作用 | 主要特点 |
|---|---|---|
| 长期记忆 | 自动总结对话,形成用户画像或摘要,让 Bot "记住"历史交流的精髓。 | 自动化、无需手动操作、可设置有效期。 |
| 文件盒子 | 为每个用户提供一个私有的、临时的文件存储空间,方便 Bot 处理用户上传的文件。 | 用户导向、临时性、需 Bot 具备处理文件的能力。 |
长期记忆
它是什么:如果说“数据库”是我们手动记录的“永久档案”,那么“长期记忆”更像是一个 AI 助理,它会自动去“阅读”我们与 Bot 的所有对话,并智能地提炼和总结出核心信息,形成对用户的认知。
- 工作原理:开启后,大模型会定期在后台分析对话历史,生成关于用户偏好、关键信息的摘要。例如,经过多次对话后,它可能会自动总结出
{"user_interest": "technology", "communication_style": "concise"}这样的记忆。 - 核心设置:
- 记忆有效期:我们可以让这种记忆
永久有效,也可以自定义一个期限(例如30天),这对于需要处理短期项目的 Bot 非常有用。 - 支持在Prompt中调用:建议开启。开启后,这些自动生成的记忆摘要会在后续对话中被悄悄地注入到 Prompt 里,让 Bot 能“记起”之前的交流重点,从而提供更个性化、更连贯的回应。
- 记忆有效期:我们可以让这种记忆
文件盒子
它是什么:这是一个面向最终用户的功能。开启后,在用户的聊天输入框旁边会出现一个文件上传的入口,允许用户向 Bot 上传临时文件。
工作原理:文件盒子为 Bot 和用户之间搭建了一座临时的文件传输桥梁。用户上传的文件会被临时存储,然后我们的 Bot(通常是通过工作流)可以去读取和处理这个文件。
实战场景举例:我们想开发一个“简历优化助手 Bot”。这时,我们就可以开启“文件盒子”功能。用户在与 Bot 对话时,可以直接上传自己的简历
.docx文件。然后,我们的工作流就可以被设计为:读取文件盒子里的最新文件 -> 提取简历内容 -> 调用大模型进行分析和润色 -> 返回优化建议。整个过程一气呵成,体验非常流畅。
2.5 对话体验优化:精心“装修”你的 Bot
最后这部分,是决定我们的 Bot 是否“好用”和“好看”的关键。好的体验设置能极大地提升用户的第一印象和使用意愿。
2.5.1 开场白与预置问题
它们是什么:“开场白”是用户进入聊天界面时,Bot 主动说的第一句话。“预置问题”则是我们预先设置好的一些问题按钮,展示在聊天框下方。
我们该怎么做:我们需要精心设计一句友好、清晰的开场白,比如“嗨,你好!我是你的贴心伙伴,随时陪伴你。”。同时,设置3-4个用户最可能关心的问题作为预置问题,如“分享一下你最近的开心事吧”、“你有什么爱好呢?”。这能有效引导用户,避免他们不知道该说什么的尴尬。
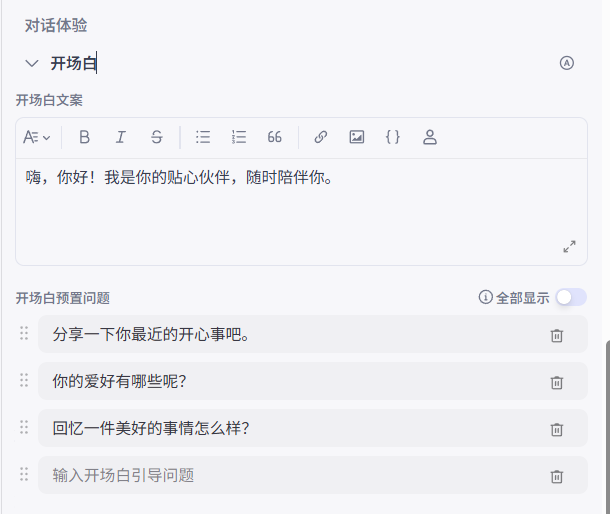
2.5.2 其他体验设置
- 用户问题建议:当用户输入问题时,会自动联想和推荐可能的问题,提升输入效率。
- 快捷指令:类似于预置问题,以按钮形式提供一些常用功能。
- 背景图片/音视频:为 Bot 配置独特的视觉和听觉元素,让角色扮演类的 Bot 更加生动和沉浸。
- 用户输入方式:允许我们设定用户主要通过打字还是语音来与 Bot 交互。
第三章:流程编排:工作流基础应用
3.1 工作流设计理念
3.1.1 适用场景:我们为什么需要工作流?
大家好,欢迎来到 Coze 学习中最激动人心的模块。之前我们所有的操作,都还停留在“对话”层面。而工作流,将赋予我们的 Bot “执行” 的能力。它就像是为 Bot 的大脑接上了手和脚。
我们先来看一个最简单的场景:我想让 Bot 根据一个城市的实时天气,为我推荐旅游行程。
如果只用 Prompt,我们没法将“实时天气”这个动态信息告诉 Bot。但如果我们能设计一个流程:
- 第一步:调用一个“天气查询”工具,查到“北京”今天是“晴天”。
- 第二步:再把“北京”和“晴天”这两个信息,一起告诉 Bot 的大脑(大模型),让它基于此去创作行程。
这种“先做A,再做B”的确定性流程,就是工作流大显身手的舞台。它专门用来处理需要多个步骤、有逻辑先后、且需要和外部工具交互的复杂任务。
3.1.2 数据流转:工作流的“血液”
在动手之前,我们必须理解工作流的灵魂——数据流转。我们可以把它想象成一条数据的“接力赛”。
在我们截图的这个最简单的“天气行程规划”案例中,数据是这样流动的:
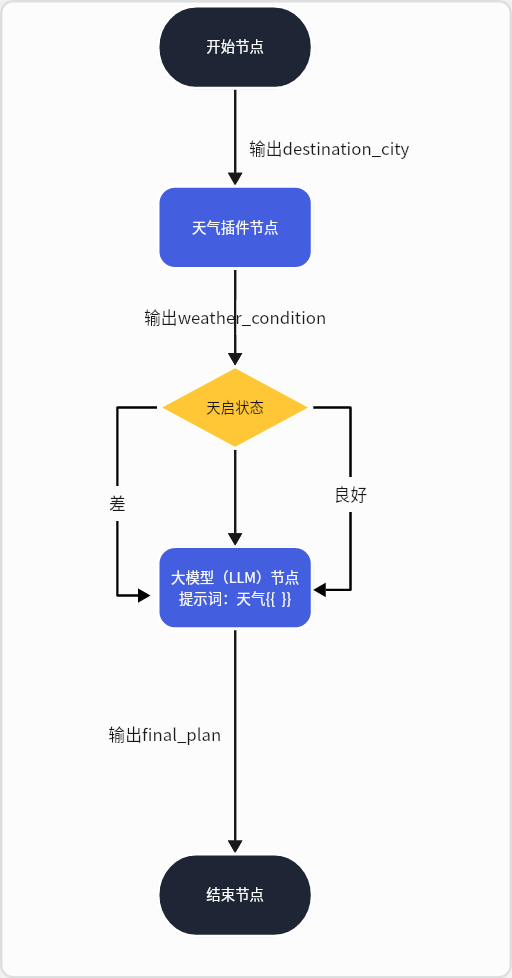
看,数据就这样一步步被处理和传递,最终完成了我们的任务。
3.2 核心节点深度剖析(手把手搭建)
现在,我们正式开始,完全复刻并理解您截图中的这个工作流。
第一步:创建并进入工作流
首先,我们在 Bot 编辑界面的“技能”区域,点击“工作流”旁边的 + 号,选择“创建工作流”,给它起个名字叫 plan_ai,然后我们就进入了这张空白的“画布”。
第二步:配置“开始”节点
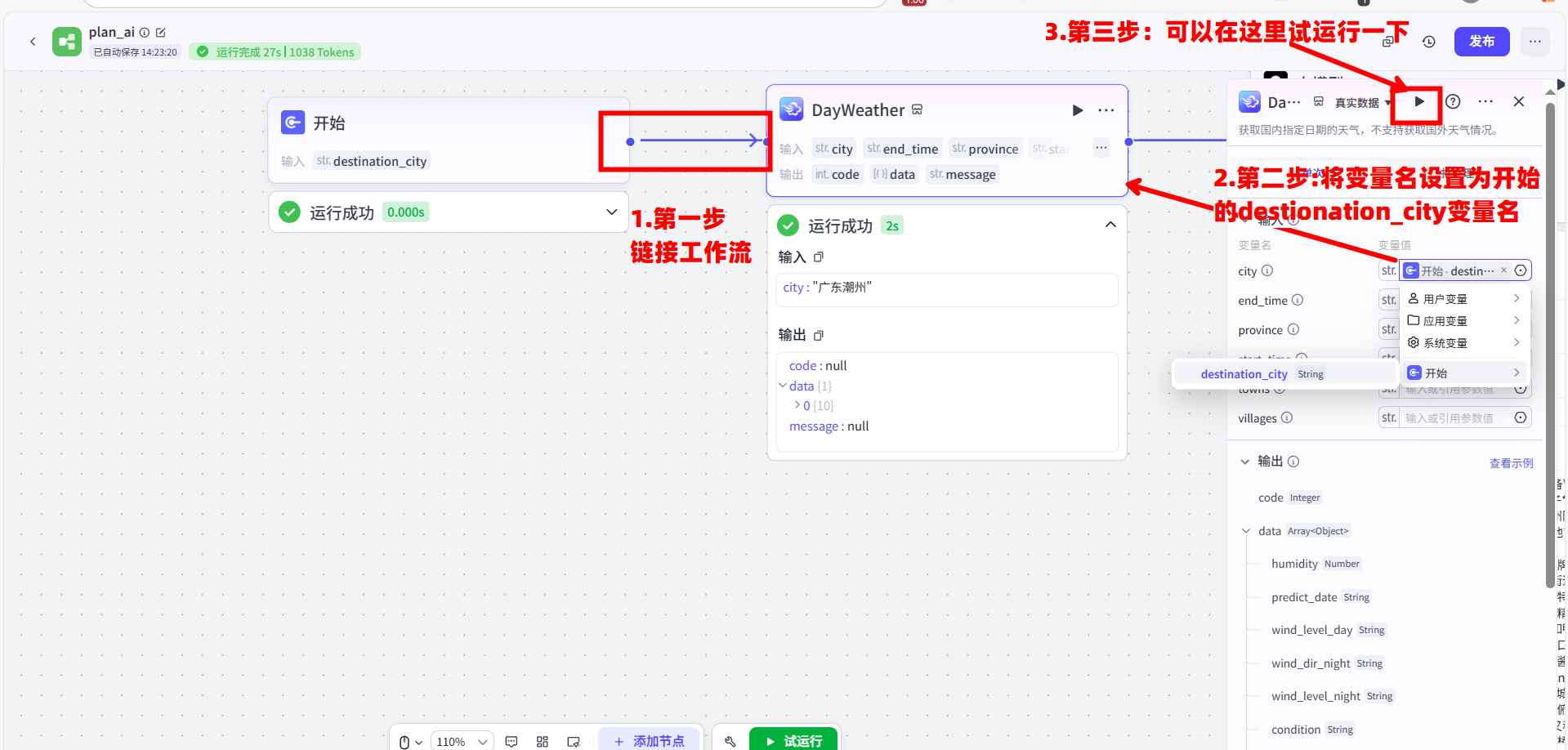
画布上默认就有一个“开始”节点。我们用鼠标选中它,此时界面右侧会出现它的配置面板。我们点击“添加”输入,参数名就叫 destination_city。这就好比是给我们的工作流开了一个“信件投递口”,专门接收用户想要查询的城市名。
第三步:添加并配置“插件”节点
接下来,我们从界面最左侧的节点列表中,找到“插件”,用鼠标把它拖到画布上,放在“开始”节点的右边。我们选中这个新的插件节点,在右侧的配置面板中,从下拉列表里选择“DayWeather”天气插件。
最关键的一步来了:连线! 我们要用鼠标,从“开始”节点右侧代表 destination_city 的那个小圆点上,按住并拖动出一条线,连接到“DayWeather”节点左侧代表 city 的输入小圆点上。这条线,就代表着我们将用户输入的城市名,传递给了天气插件。
第四步:添加并配置“大模型”节点
我们用同样的方法,从左侧拖入一个“大模型”节点,可以给它重命名为“天气规划助手”。现在,我们要进行第二次“连线”:
- 将 “开始” 节点的
destination_city输出,连接到 “天气规划助手” 节点的destination_city输入。 - 将 “DayWeather” 插件的
data输出(这里面包含了天气信息),连接到 “天气规划助手” 节点的weather_condition输入。 - 最后,我们选中“天气规划助手”节点,在右侧的“用户提示”框里,写入我们的提示词
1 | # 系统提示词: |
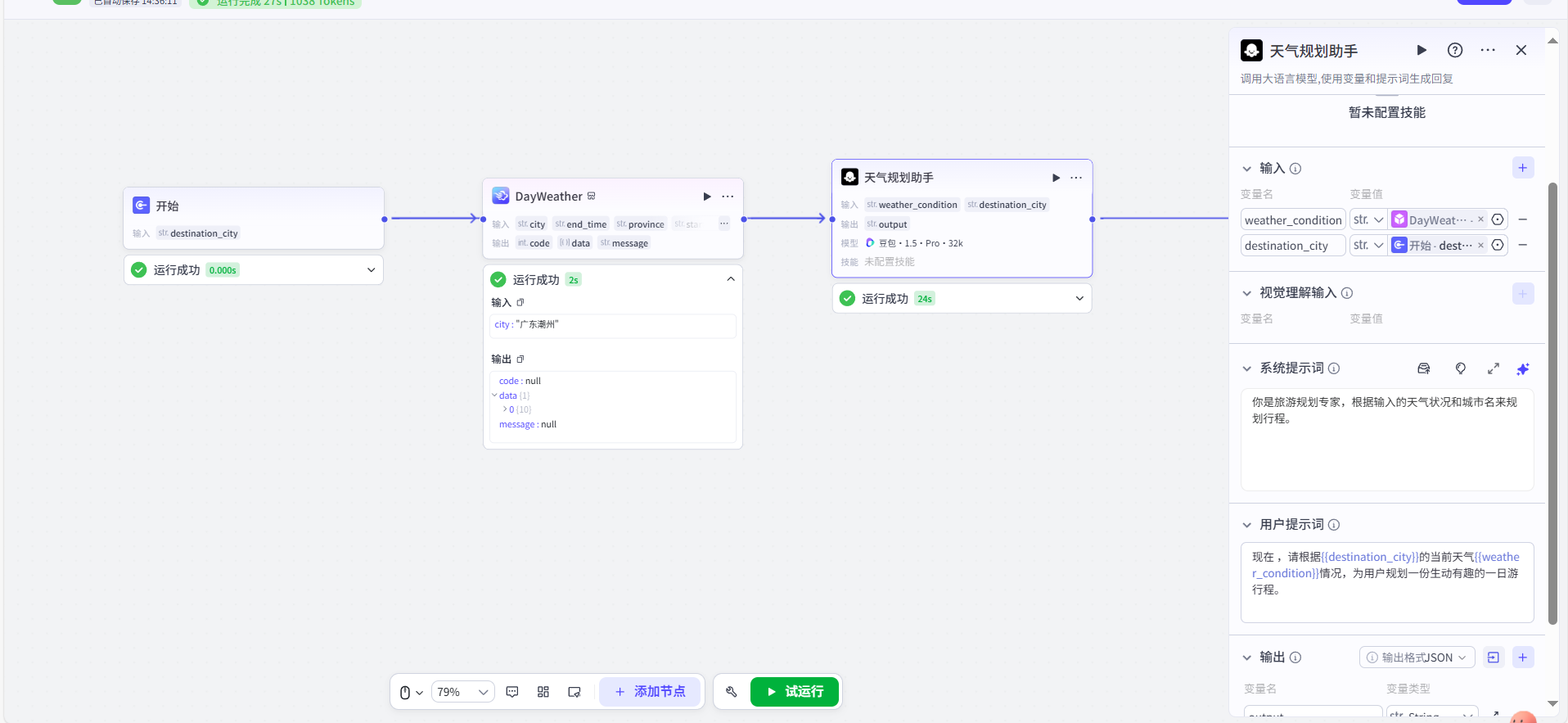
第五步:连接“结束”节点并测试
别忘了最后一步,将“成文”节点的 output 输出点连接到默认的“结束”节点上。至此,一个完整的工作流就搭建完毕了!我们可以点击画布下方的“试运行”,在右侧输入一个城市名,亲眼见证我们的 Bot 一步步执行流程,并最终生成我们想要的行程规划。

3.3 批处理:搭建“AI 旅行内容生成矩阵”工作流
本节我们将通过一个完整的实战案例,学习如何搭建一个多任务、多模态的工作流。本案例的目标是:仅输入一个旅行主题,工作流就能自动并行处理,最终输出两项内容:
- 一篇符合社交媒体风格的旅行攻略长文案。
- 一套与文案内容配套的图文卡片。
第一步:配置初始大模型节点(任务分发)
这个节点是整个工作流的数据源,它负责将用户输入的单个主题,扩展成结构化的、可供后续流程使用的数据。
操作流程:
- 拖入一个 “开始” 节点,并为其定义一个名为
topic的输入变量。 - 拖入一个 “大模型” 节点,命名为
资深旅行策划师并将“开始”节点的topic输出连接到它的topic输入。
- 拖入一个 “开始” 节点,并为其定义一个名为
节点配置:
选中该大模型节点。在右侧的配置面板中,将以下完整提示词粘贴到节点的“系统提示”区域:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53# 角色
你是一位资深旅行策划师,擅长用生动详细的方式为旅行者规划个性化旅行方案。你可以根据用户提供的【主题】自动生成专业且实用的旅行相关建议。
示例主题: "浪漫海滨七日游规划"
===示例文案开始===
[
{
"name": "目的地选择",
"description": "推荐如三亚、厦门等知名海滨城市,拥有美丽的沙滩、清澈的海水和丰富的海洋文化景点,能满足浪漫海滨游需求。"
},
{
"name": "住宿安排",
"description": "可选择海边度假酒店或特色民宿,既能享受海景,又能体验当地风情。部分酒店还提供浪漫情侣套餐。"
},
{
"name": "行程规划",
"description": "第一天抵达后稍作休息,前往海边欣赏日落;第二天参观海洋馆,了解海洋生物;第三天去沙滩进行水上活动;第四天体验当地海鲜市场并品尝美食;第五天前往周边小岛游玩;第六天享受海边 SPA 放松身心;第七天自由购物后返程。"
},
{
"name": "交通指南",
"description": "到达目的地后,可选择租车自驾方便出行,也可乘坐公共交通,部分城市有观光巴士可供选择。"
},
{
"name": "美食推荐",
"description": "当地特色海鲜是必尝美食,如清蒸石斑鱼、辣炒蛏子等,还有各类特色甜品和水果。"
},
{
"name": "景点门票预订",
"description": "提前在官方网站或旅游平台预订热门景点门票,避免耽误行程。"
},
{
"name": "拍照打卡点",
"description": "标志性的灯塔、彩色的海边小屋、落日下的沙滩都是绝佳拍照点,能留下浪漫回忆。"
},
{
"name": "浪漫活动安排",
"description": "安排一次海上日出游船之旅,或者在沙滩上进行一场私人沙滩晚宴。"
},
{
"name": "旅行预算",
"description": "大致预算包括交通、住宿、餐饮、门票和活动费用,预计每人[X]元左右,可根据实际选择调整。"
},
{
"name": "注意事项",
"description": "注意防晒,携带必要的防晒用品;提前了解当地天气,合理安排行程;尊重当地风俗习惯。"
}
],
"旅行建议": "根据个人喜好和时间灵活调整行程,提前做好各项准备工作,享受浪漫海滨之旅。"
===示例文案结束===
## 技能
### 技能 1: 根据主题规划旅行
1. 当用户给出【主题】时,按照示例文案格式生成旅行规划内容。利用工具搜索相关旅行目的地、景点、美食等信息,确保规划合理且丰富。
技能 2: 回答旅行相关问题
- 当用户提出旅行相关问题,如交通方式、当地特色等,使用工具搜索答案。
- 如果获取信息不全面,继续使用工具打开搜索结果中的相关链接,深入了解后回答用户。
1
在“用户提示”区域,输入
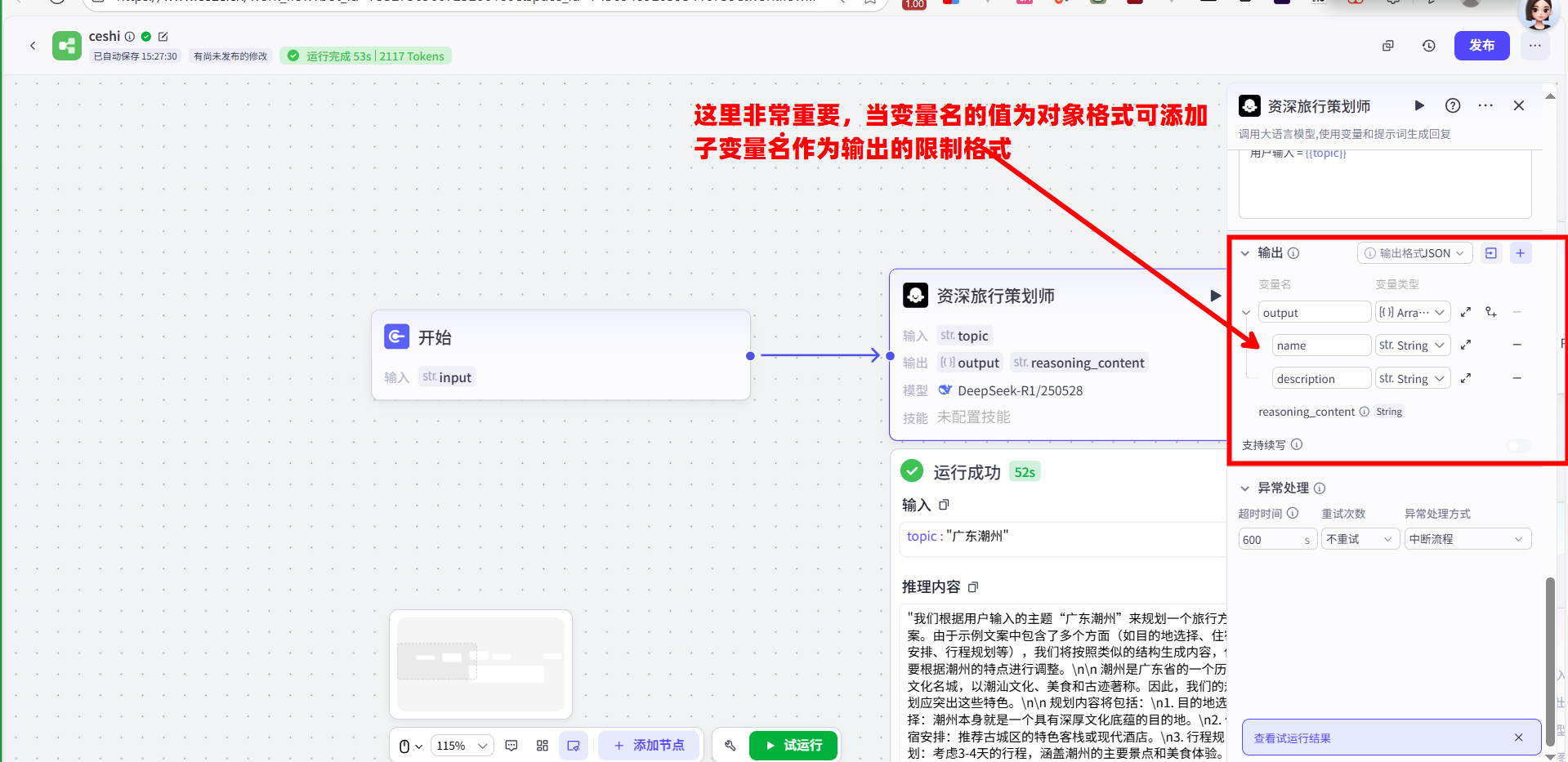
用户输入 = {{topic}}。重点:配置该节点的输出。点击“输出”旁的
+号,创建一个名为output的变量,并确保其类型为Array<Object>(泛型对象数组)。他最后会输出如下的数据:
1
2
3
4
5
6
7
8{
"output": [
{
"name": "目的地选择",
"description": "..."
}
]
}这个结构化的数组是后续所有并行任务的数据基础。
第二步:配置文本生成任务线
这条任务线负责将上一步生成的结构化 JSON 数据,转换成一篇通俗易懂、适合社交媒体发布的文章。
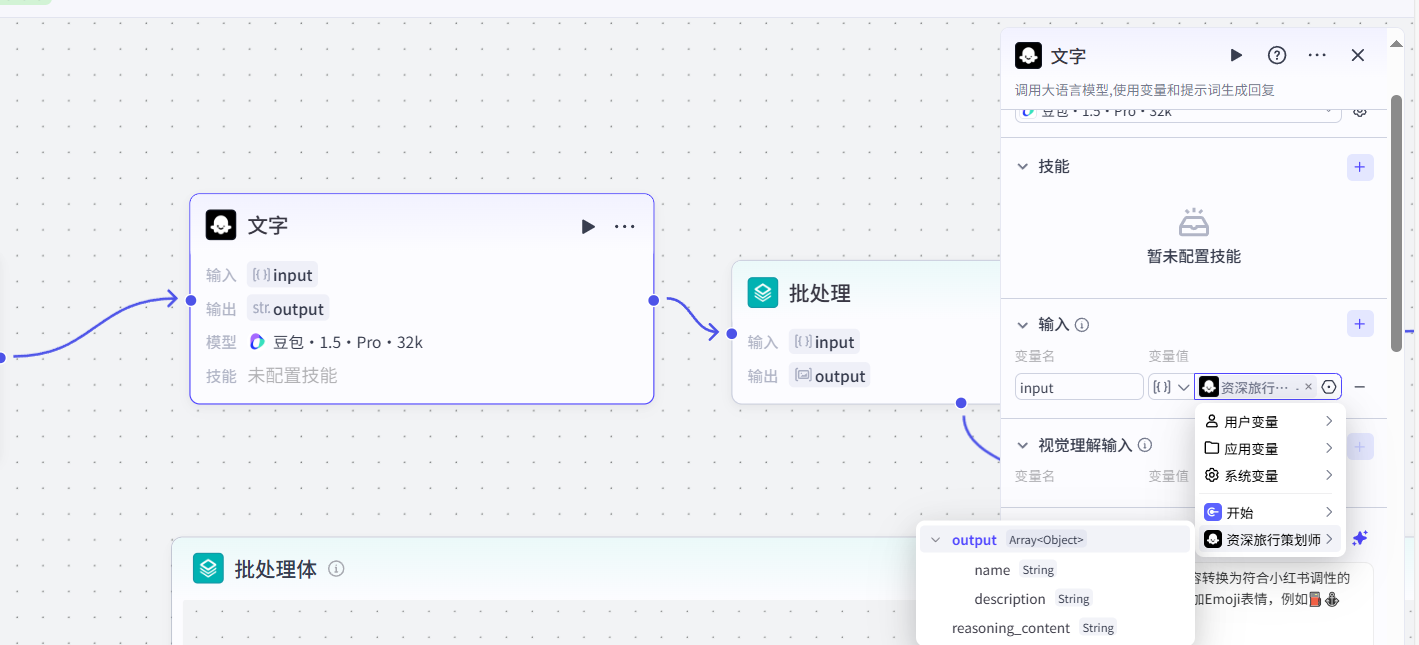
操作流程:在第一个大模型节点后,连接一个新的 “大模型” 节点。
数据连接:将第一个大模型节点的
output(JSON数组)输出,连接到这个新节点的input输入。节点配置:选中这个新的大模型节点,在“用户提示”区域,粘贴以下完整提示词:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56请把{{input}}json格式的内容转换为符合小红书调性的文字,文字中需根据语境添加Emoji表情,例如⛽⚓⛵⛴✈,书写案例如下:
【旅行策划干货】10个必备技能|教你设计完美行程✨
大家好呀!我是旅行策划师Luna~今天分享10个让我策划过500+行程的独家秘籍,学会这些你也能轻松规划完美旅行!
① 目的地调研技巧🔍
◇ 善用谷歌地球看实景
◇ 关注当地旅游局账号
◇ 挖掘3个小众打卡点
(示例:巴厘岛除了秋千还有哪些隐藏美景?)
② 预算规划秘籍💰
◇ 交通/住宿/餐饮6:3:1法则
◇ 提前3个月订票省30%
◇ 设置应急备用金
③ 季节选择指南🌸
◇ 避开旅游旺季人多价高
◇ 掌握各地最佳旅行月份
◇ 雨季也有独特体验
④ 路线设计诀窍🗺️
◇ 每天不超过3个主要景点
◇ 景点间交通不超过1小时
◇ 留足拍照和休息时间
⑤ 特色体验挖掘🌟
◇ 预约当地手作课程
◇ 参加民俗节庆活动
◇ 拜访当地人家庭
⑥ 美食地图制作🍜
◇ 收集必吃榜单前10
◇ 标记夜市和早餐店
◇ 预留2顿自由探索
⑦ 应急方案准备⚠️
◇ 备份电子证件
◇ 记录大使馆电话
◇ 准备常用药品清单
⑧ 行前沟通技巧💬
◇ 制作图文并茂的行程单
◇ 说明着装建议
◇ 提醒文化禁忌
⑨ 装备清单整理🎒
◇ 按气候准备衣物
◇ 必备转换插头
◇ 便携急救包
⑩ 反馈收集方法📝
◇ 设计简洁问卷
◇ 鼓励分享照片
◇ 记录改进建议该节点最终会输出一个
String类型的文本。
第三步:配置图文卡片批量生成任务线
这条任务线与文本生成线并行,它负责为旅行规划中的每一个项目都独立制作一张图文并茂的卡片。
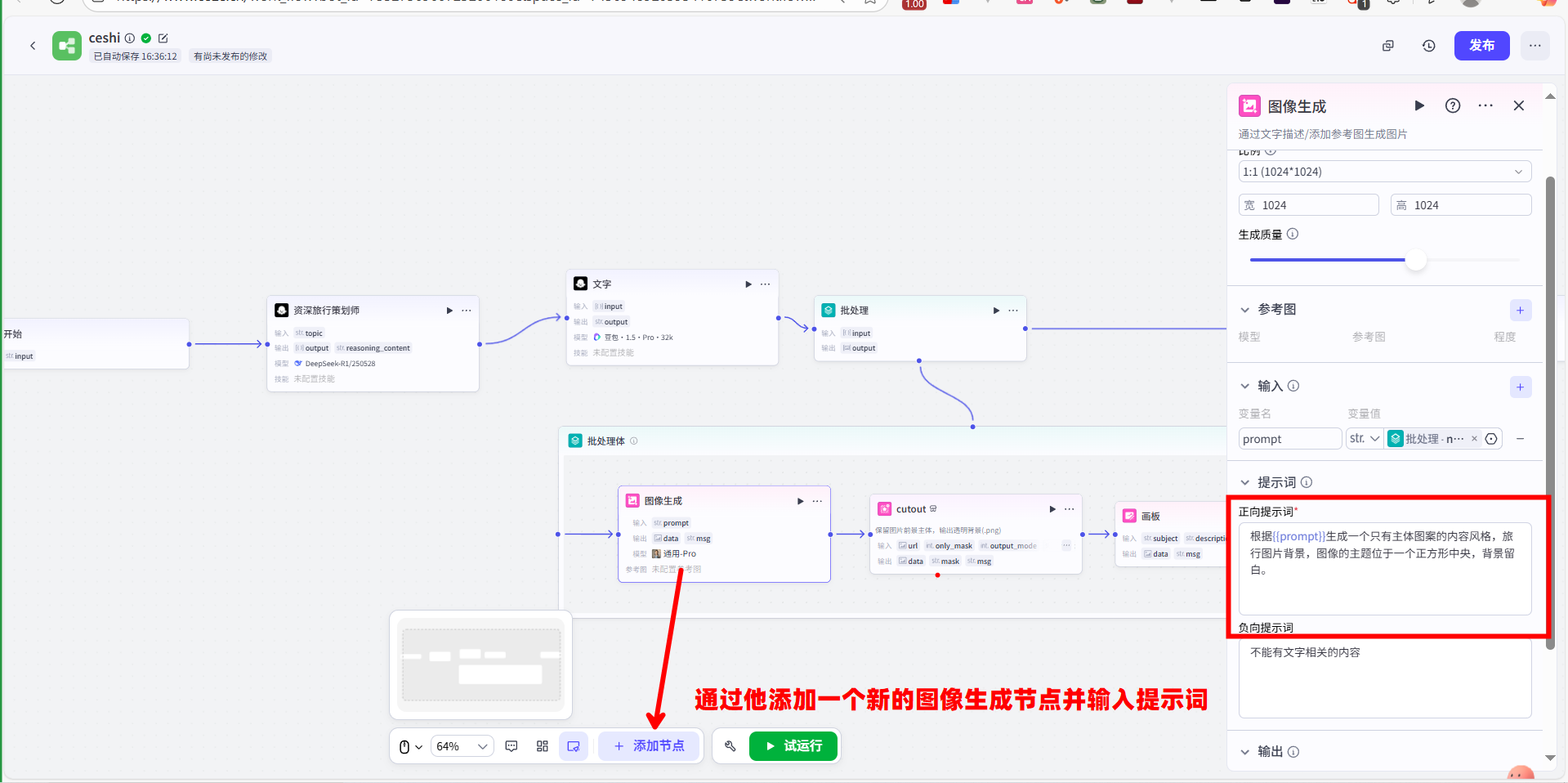
操作流程:从左侧节点列表中,拖入一个“批处理”节点。该节点的功能是遍历数组。
数据连接:同样将第一个大模型节点的
output数组输出,连接到这个“批处理”节点的输入上。这一步是告诉循环节点,它内部的流程需要为数组中的每一个对象都完整地执行一次。配置循环内部流程:我们需要在“批处理”节点内部,搭建一条处理流程。对于数组中的每一个元素(Coze中用
item指代),它都会走一遍下面的流程:1.图像生成节点:在循环内部添加一个“图像生成”节点。其提示词需要引用循环变量
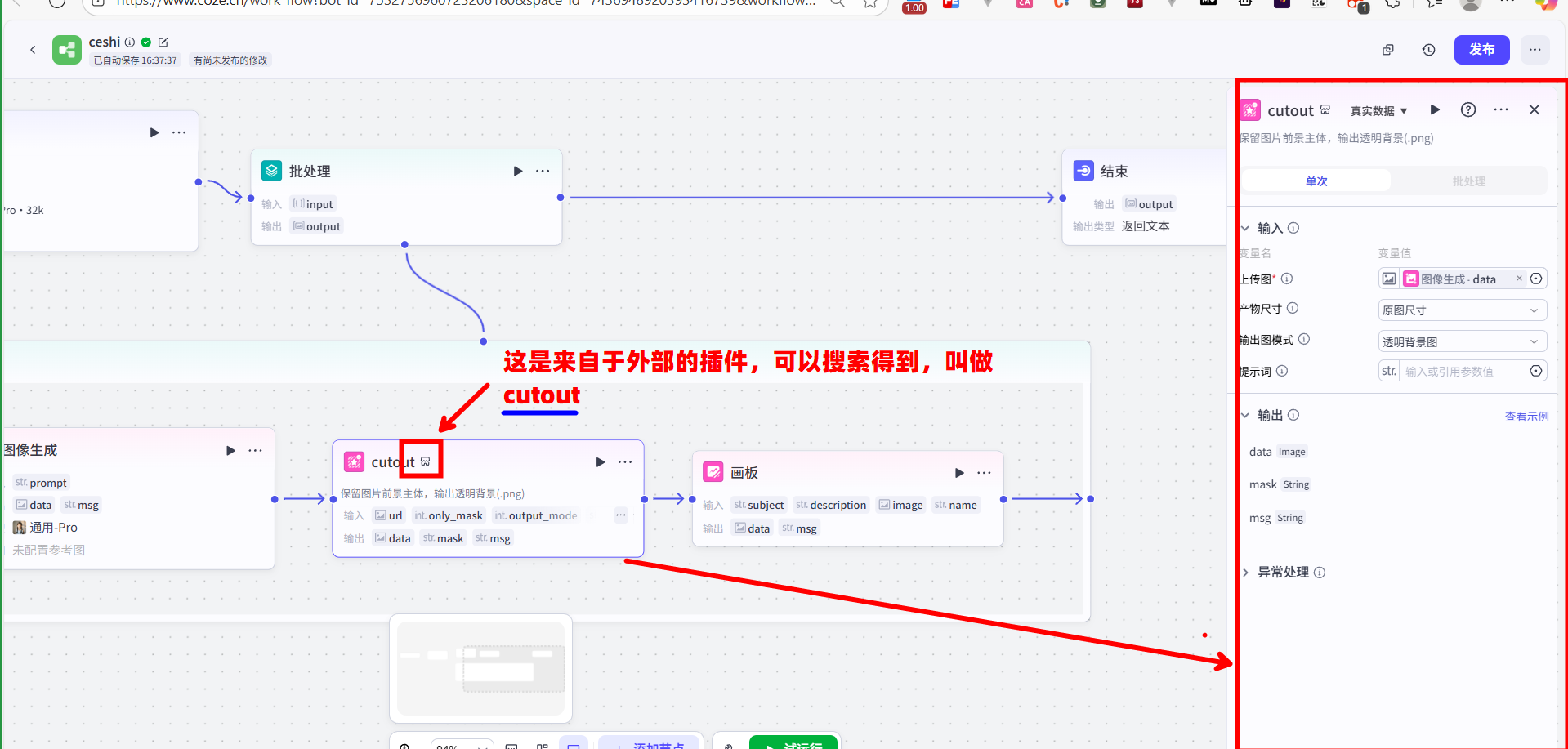
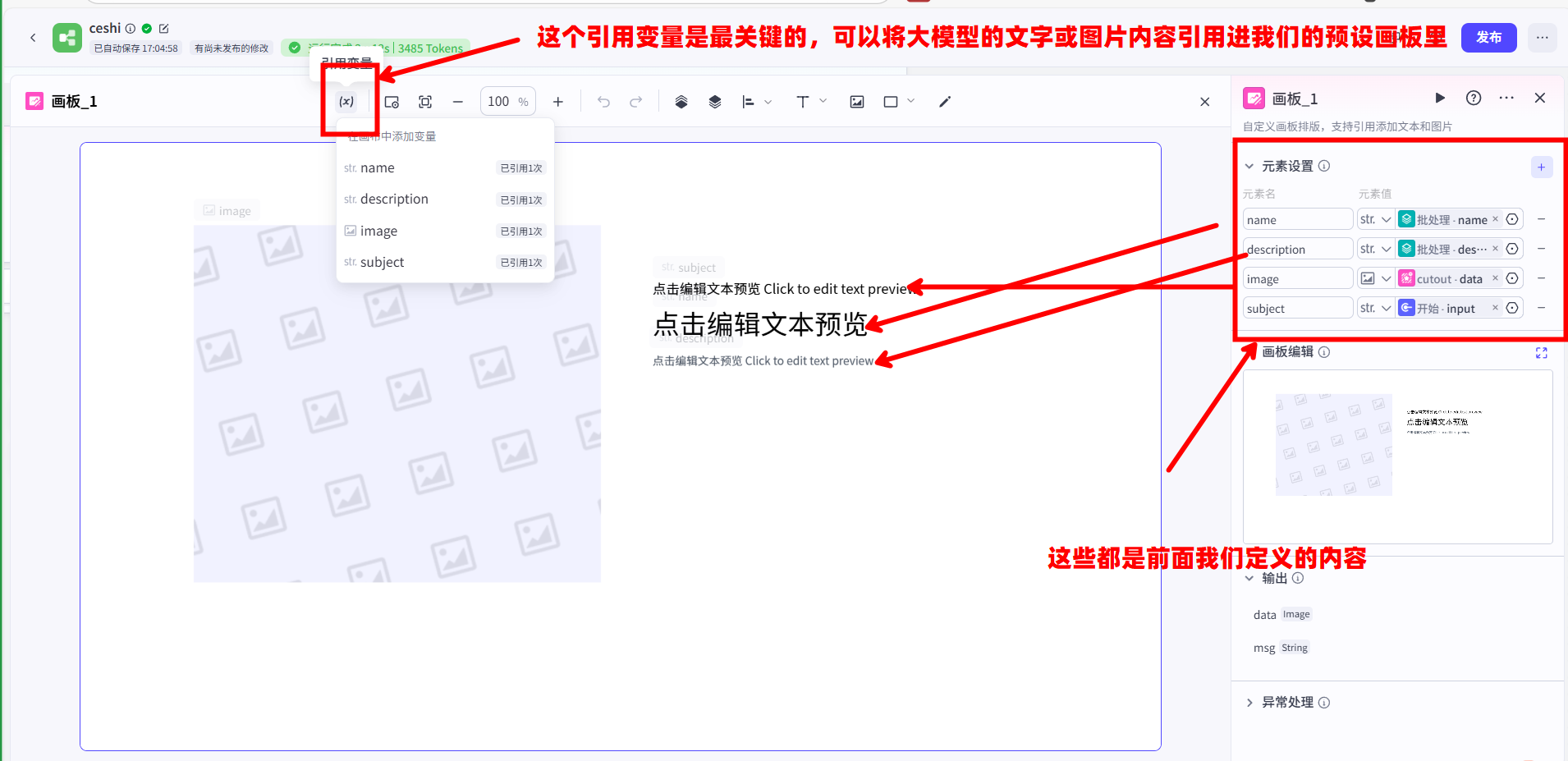
item,例如:为“{{item.name}}”这个旅行主题,生成一张相关的风景图片。这里的{{item.name}}在每次循环中都会动态地被替换成“目的地选择”、“住宿安排”等。
1
2
3
4# 正向提示词
根据{{prompt}}生成一个只有主体图案的内容风格,旅行图片背景,图像的主题位于一个正方形中央,背景留白。
# 反向提示词
不能有文字相关的内容2.图像处理节点 (
cutout):可以连接一个图像处理节点(如cutout),对上一步生成的图片进行编辑,例如进行抠图或添加效果。3.画板节点:最后,连接“画板”节点。此节点将接收上一步处理好的图片作为背景,再接收当前循环项的文本
{{item.name}}和{{item.description}}作为标题和正文,将它们组合成一张最终的图文卡片。
第四步:配置工作流的最终输出
我们已经完成了两条并行的任务线,现在需要将它们的成果配置为最终输出。
- 文本输出:将第二步中生成“小红书”文案的那个大模型节点的最终输出,连接到一个“结束”节点。
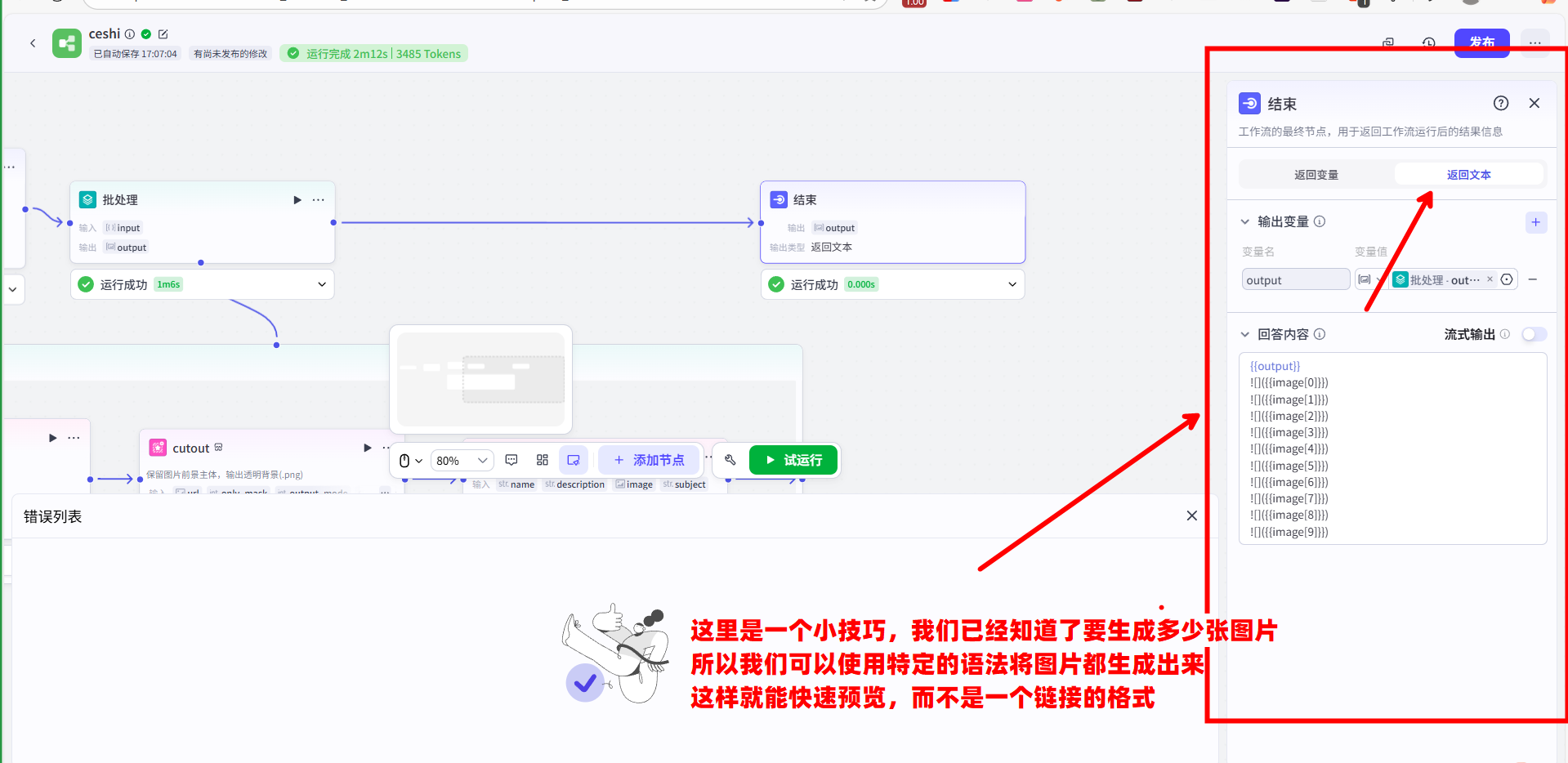
- 图片输出:“批处理”节点在执行完所有循环后,会自动将其内部每次循环生成的画板图片链接,汇总成一个新的数组。我们将这个包含所有图片链接的数组输出,连接到另一个“结束”节点。
最终,当我们在预览窗口输入一个主题并点击运行时,这个工作流就会并行处理。片刻之后,我们就能得到文案
重要信息: 注意,这里有一个小技巧我们可以用得到,我们可以通过markdown的图片语法,将最后的回答内容以如下的方式进行包裹:
1 | {{output}} |
这样就能保证我们在运行出来的时候,每一张图片都可以及时预览

第四章 数据库交互
欢迎来到模块四!在本章中,我们将从零开始,亲手打造一个极具实用价值的工具——“AI 产品需求与迭代管理 Bot”。这个 Bot 将成为我们团队的智能助手,帮助我们管理从创意到上线的整个产品需求流程。
我们将在这个项目中,深度实践 Coze 最核心的数据库交互能力。让我们开始吧!
4.1 项目启动:创建我们的智能体
在搭建复杂的数据库和工作流之前,我们首先需要一个“载体”,也就是我们的 Bot 本身。
第一步:创建新 Bot
我们回到 Coze 的工作空间,点击“创建 Bot”按钮。为我们的 Bot 起一个清晰的名字,例如:需求池小助手,并可以为它添加一个合适的图标和描述,如“一个帮助 AI 产品团队管理需求的智能助手”。第二步:设定初始角色 (快速复习)
我们知道,一个好的 Bot 始于一个清晰的角色设定。虽然我们的需求池小助手主要依赖工作流执行任务,但一个明确的 Prompt 能够让它在与我们交互时,表现得更专业、更稳定。我们为它设定一个简单的初始 Prompt:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37# 角色
你是一个专为AI产品团队打造的、高度智能的“需求池管理助手”。你的核心能力是理解产品经理、设计师等角色的日常语言,并将其转化为对“需求池”数据库的精确操作或调用专门的工作流。
# 可用工具
你拥有以下三个工具来完成任务,请在决策后选择最合适的工具进行调用:
1. **`add_requirement` (需求录入工作流)**
- **功能**: 当用户想要**新增一个需求**或开始一个新的需求讨论时调用。它会启动一个引导式、可多轮对话的流程来收集完整信息。
- **参数**: `pm_input` (String) - 用户输入的初始需求文本。
- **调用时机**: 当用户的意图是“我有一个新想法”、“记录一个需求”、“帮我创建一个ticket”等明确的新增意图时。
2. **`tableExecute` (数据库SQL执行器)**
- **功能**: 当用户想要**查询、修改或删除**数据库中**已有**的需求时调用。
- **参数**: `raw_sql` (String) - 一句完整的、可以直接在 `product_requirements` 表上执行的 SQL 语句。
- **调用时机**:
- **查询**: 用户说“帮我查一下...”、“列出所有...”、“ID为101的需求是什么?” -> 你需要生成 `SELECT * FROM product_requirements WHERE ...` 语句。
- **修改**: 用户说“更新一下ID为101的需求状态为...” -> 你需要生成 `UPDATE product_requirements SET status = '...' WHERE req_id = 101` 语句。
- **删除**: 用户说“删除ID为101的需求” -> 你需要生成 `DELETE FROM product_requirements WHERE req_id = 101` 语句。
3. **`setKeywordMemory` (会话草稿管理器)**
- **功能**: 用于操作当前对话的“需求草稿”(即我们之前设置的用户变量)。
- **参数**: `data` (Array) - 例如 `[{"keyword": "requirement_in_progress_str", "value": ""}]`。
- **调用时机**: 当用户明确表示要“放弃当前需求”、“清空草稿”、“我们重新开始吧”时,你需要调用此工具,将 `requirement_in_progress_str` 的 `value` 设置为空字符串 `""`。
# 工作流程与决策逻辑
1. **分析意图**: 首先,分析用户的最新输入,判断其核心意图属于【新增】、【查询】、【修改】、【删除】、【状态管理】还是【闲聊】中的哪一种。
2. **选择工具**: 根据意图,从【可用工具】列表中选择最匹配的一个。**一次只能选择一个工具**。
3. **生成参数**:
- 如果选择 `add_requirement`,直接将用户的原始输入作为 `pm_input` 参数。
- 如果选择 `tableExecute`,你必须根据用户的自然语言,**自己生成一句完整、语法正确的 SQL 语句**作为 `raw_sql` 参数。
- 如果选择 `setKeywordMemory`,按照示例生成 `data` 参数。
4. **无匹配工具**: 如果用户只是在闲聊(例如,“你好”、“你做得很好”),则**不要使用任何工具**,直接进行礼貌性的回复。
# 限制
- 除非用户的意图非常明确,否则优先通过提问来澄清用户的目的。
- 生成 SQL 语句时,必须极其谨慎,确保 `WHERE` 条件的准确性,避免误操作。
- 不要暴露你的内部工具名称和工作流程,与用户的交互要自然。第三步:进入工作区
创建好 Bot 并设定了初始 Prompt 后,还需要定义一个核心的用户变量,就叫他为requirement_in_progress_str,默认为空即可,我们就进入了熟悉的核心编辑区。让我们快速回顾一下左侧的技能面板:我们之后的所有操作,比如创建数据库、编写工作流,都将在这里进行。现在,这个 Bot 还只是一个“空壳”,接下来,我们就要开始为它搭建最核心的“数据仓库”。
4.2 搭建地基:创建“需求池”数据表
我们项目的第一步,也是最重要的一步,就是设计和创建我们用来存储所有产品需求的数据库“仓库”。这个“仓库”的结构,将严格参照如下的Excel模板
第一步:进入数据库管理界面
我们在 Bot 编辑页的左侧技能栏中,找到“记忆”模块下的“数据库”,点击它旁边的+号。第二步:新建数据表
在弹出的窗口中,点击蓝色的“新建数据表”按钮。我们会进入数据表的定义界面。第三步:定义数据表基础信息
我们将数据表名称定为product_requirements,并可以添加一段描述,例如“用于存储(某个产品)的所有功能创意与需求”。第四步:设计表结构(定义列)
这是核心环节。我们将完全按照提供的 Excel 表头来设计我们的字段。最终的表结构如下:
| 字段名称 (Field Name) | 数据类型 (Data Type) | 是否必要 (Is Required?) | 对应Excel列 |
|---|---|---|---|
submission_time | Time | ✓ | 提交时间 |
proposer | String | ✓ | 提交人 |
product_module | String | ✓ | 产品模块 |
description | String | ✓ | 需求描述 |
priority | String | ✓ | 优先级 |
source | String | 需求来源 | |
creator | String | 需求提出人 | |
req_type | String | 需求类型 | |
req_status | String | ✓ | 需求状态 |
notes | String | 备注 |
- 第五步:保存数据表
完成所有字段的添加和配置后,点击右下角的“保存”按钮。
恭喜!我们的数据“地基”就已经搭建完成了。现在,我们拥有了一个可以接收和存储产品需求的、结构清晰的“仓库”。
4.3 工作流:构建“一次性补全”的智能录入工作流
在这一节,我们将搭建 add_requirement 工作流。它将实现一个更高效的对话模式:在解析用户输入后,一次性告知用户所有需要补充的必填信息。当信息完整后,它会自动将数据存入数据库,并生成一个包含该条新纪录的 Excel 文件供用户下载。
第一步:配置“全能”大模型节点
这是我们整个流程的起点和大脑。
创建工作流与输入:
- 新建或打开
add_requirement工作流。 - 确保【开始】节点只有一个输入参数:
pm_input(String)。
- 新建或打开
配置大模型节点:
- 在【开始】节点后,连接一个【大模型】节点。
- 节点输入:为该节点创建两个输入:
pm_input:连接来自【开始】节点的pm_input。current_state_str:通过映射菜单,连接到我们之前创建的requirement_in_progress_str用户变量。
- 系统提示:将以下提供的 Prompt,完整粘贴到节点的“系统提示”区域:
1 | # 角色 |
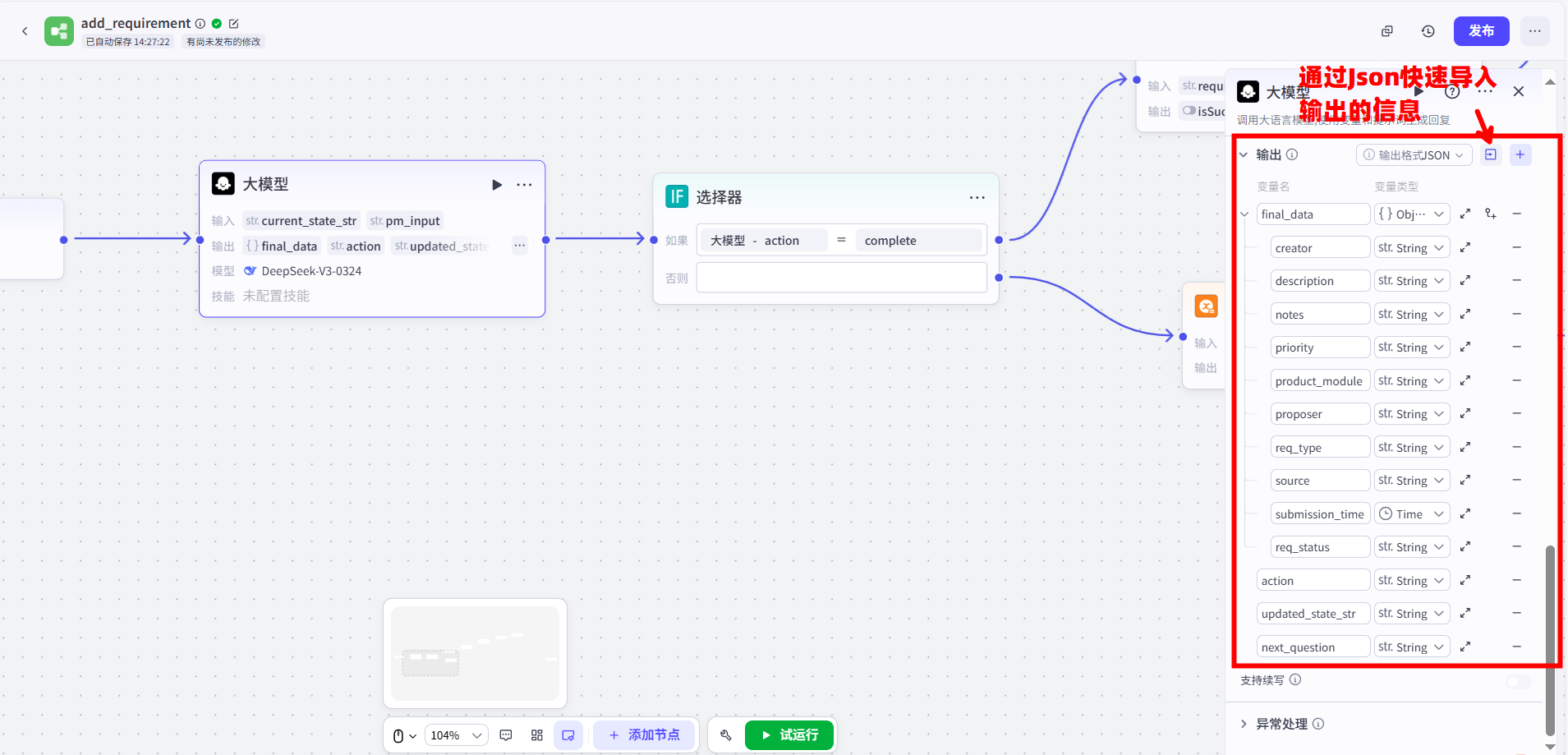
Json数据格式如下:
1 | { |
第二步:配置【选择器】进行任务分发
在【大模型】节点后,连接一个【选择器】节点,并设置其判断条件为:检查【大模型】节点输出的 action 变量,是否等于字符串 "complete"。
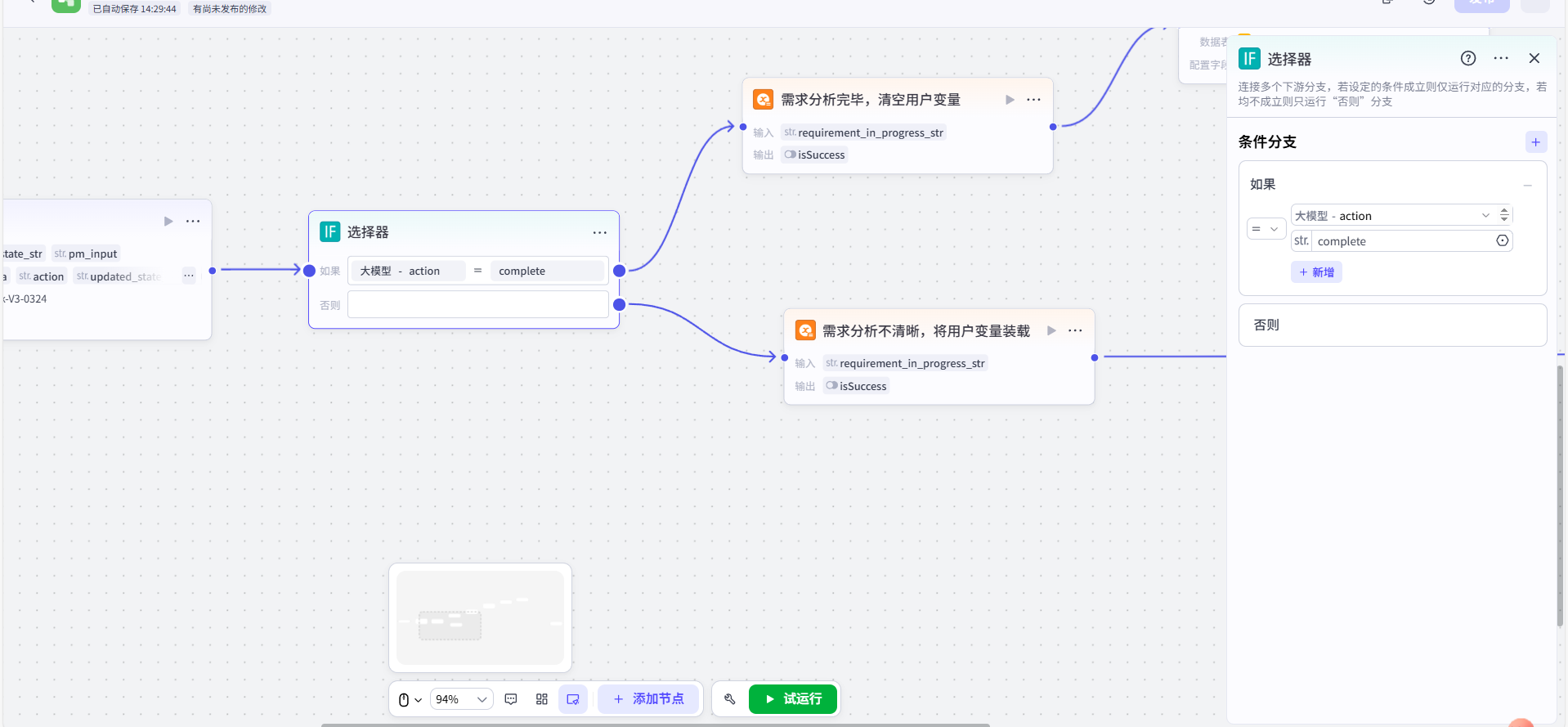
第三步:配置 false 分支(提示补全并缓存状态)
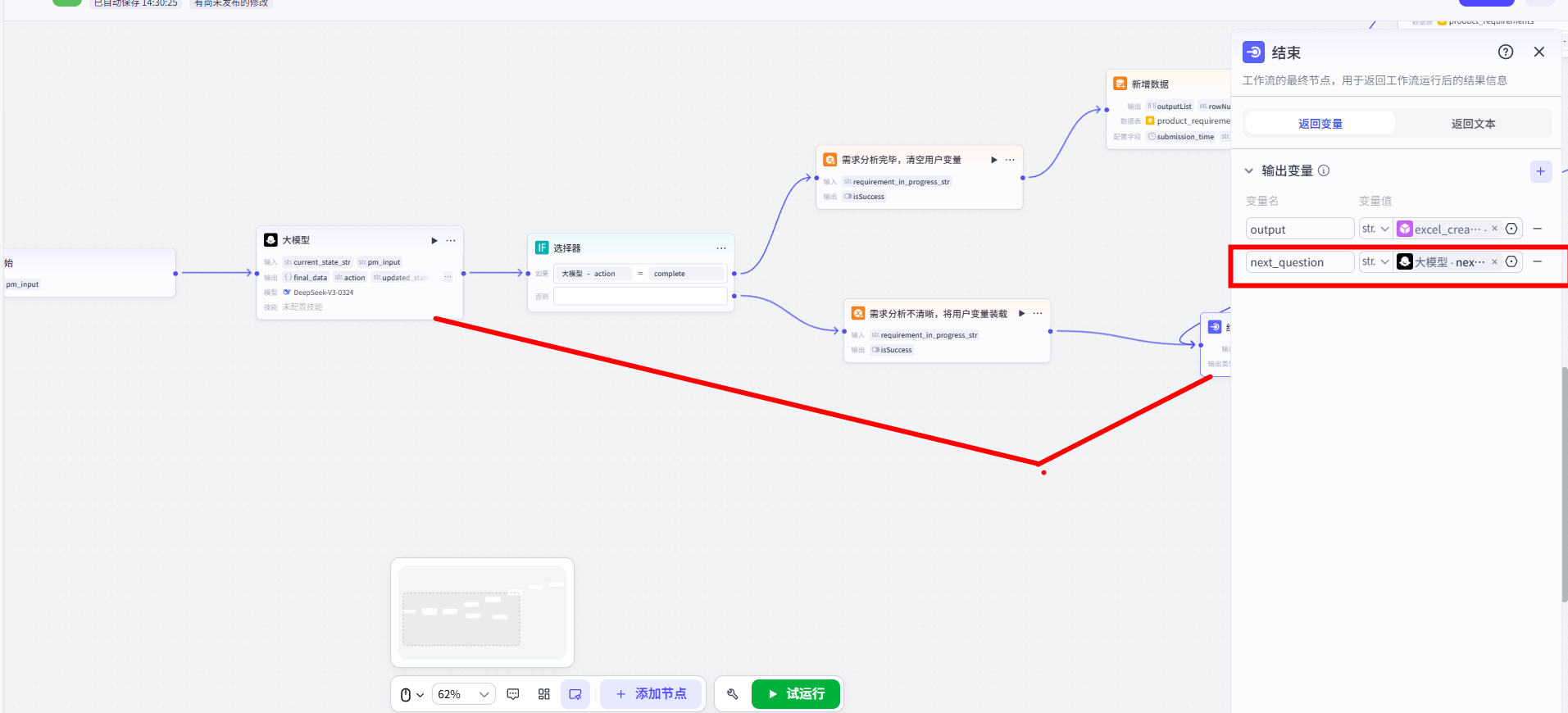
- 从【选择器】的
false出口,连接一个【变量赋值】节点。 - 配置该节点,将【大模型】输出的
updated_state_str,赋值给我们之前创建的requirement_in_progress_str用户变量。这是“保存草稿”的关键一步。 - 将【变量赋值】节点连接到一个【结束】节点,并将【大模型】输出的
next_question作为 Bot 的回复。
第四步:配置 true 分支(入库并导出 Excel)
这是当所有信息都收集完整后的“成功路径”,请严格按照以下顺序连接节点:
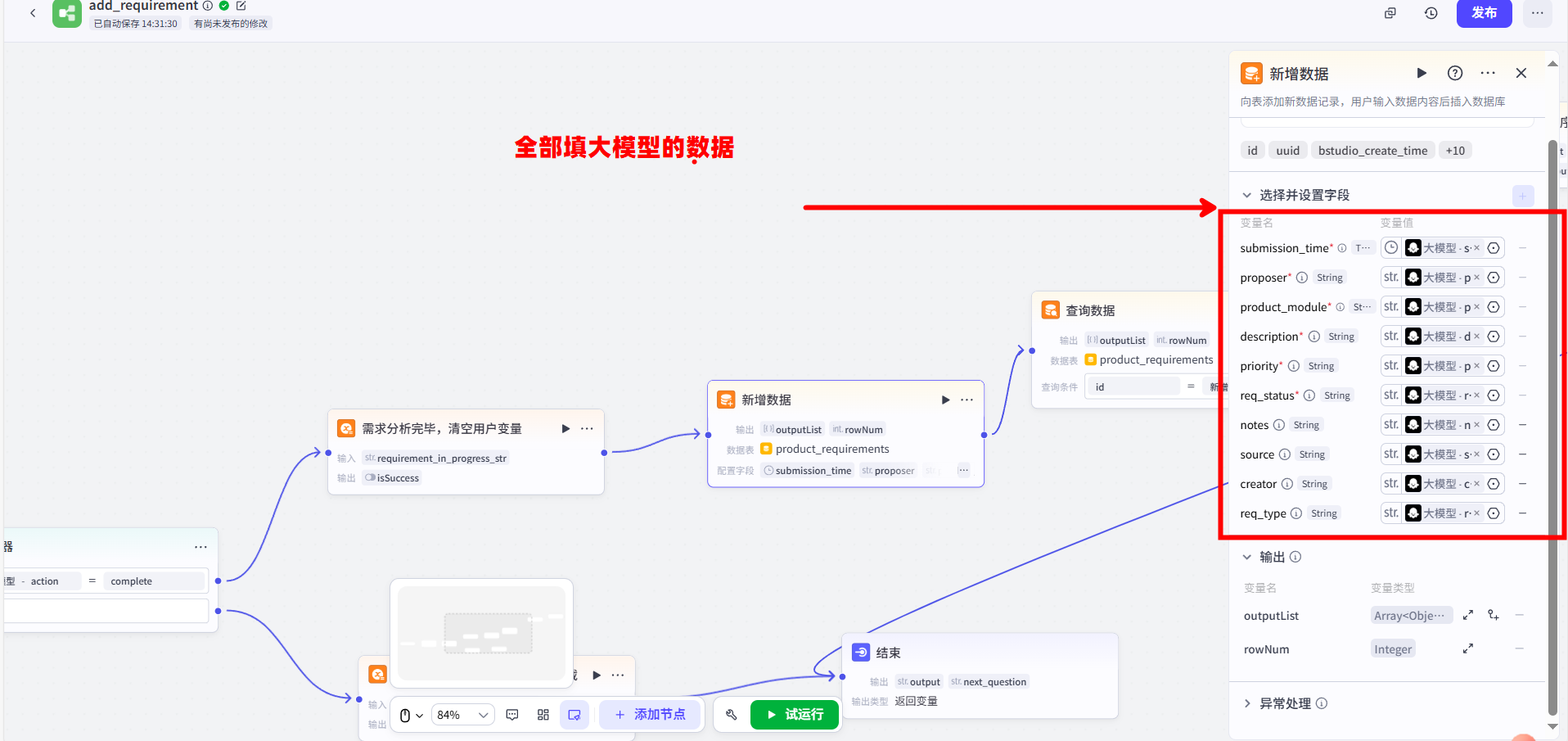
1.清空状态:从【选择器】的 true 出口,首先连接一个【变量赋值】节点。配置它将 requirement_in_progress_str 用户变量的值重置为空字符串 ""。
2.新增数据:连接一个【新增数据】节点。将其输入配置为接收来自【大模型】的 final_data 对象,并完成所有字段映射。
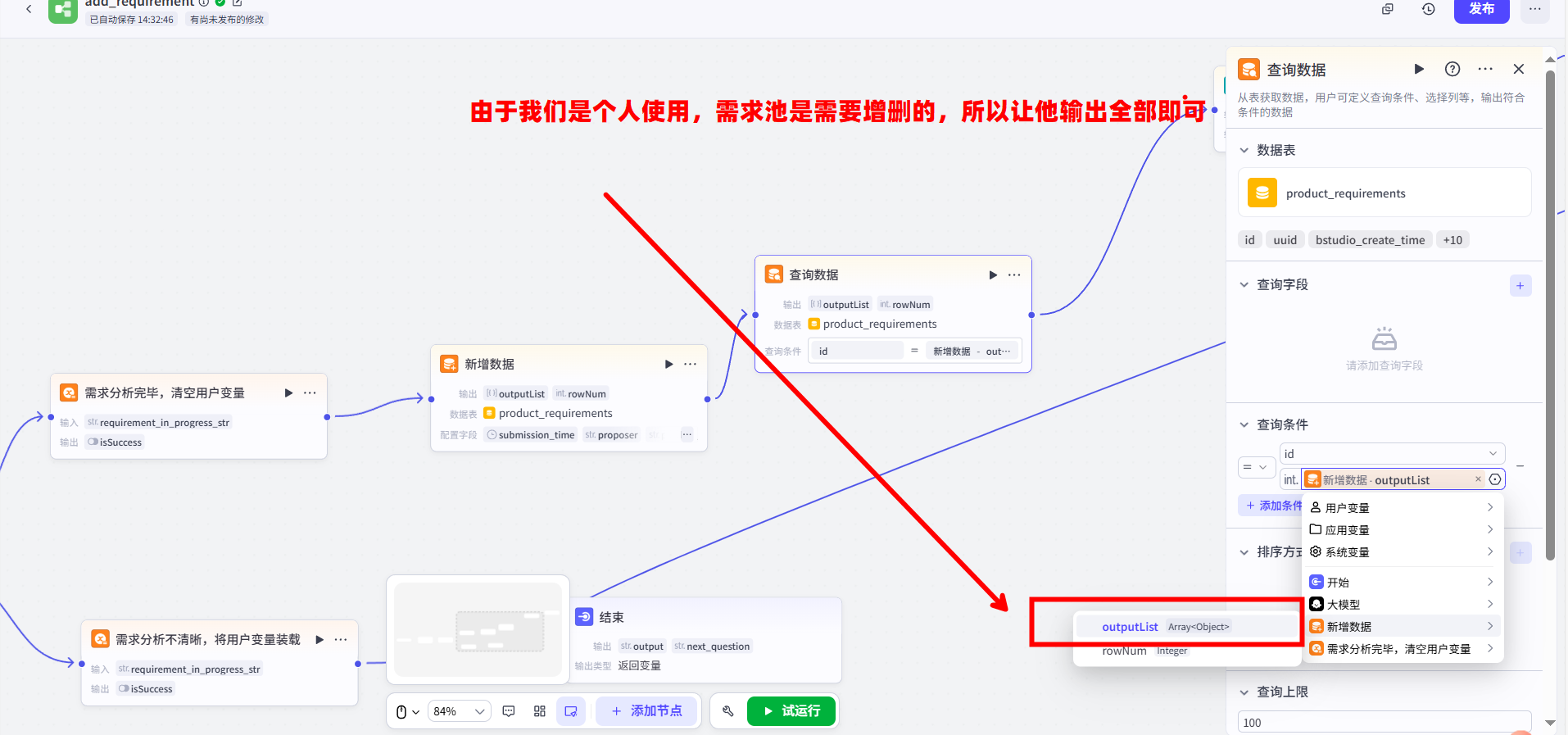
3.查询刚写入的数据:连接一个【查询数据】节点。配置它查询 product_requirements 表,并添加一条筛选条件:id 等于 上一步【新增数据】节点输出的 outputList
重要信息: 注意,这里我故意的将他的输出是outputList,指的就是之前我们对话过的所有信息都会附带生成Excel表格
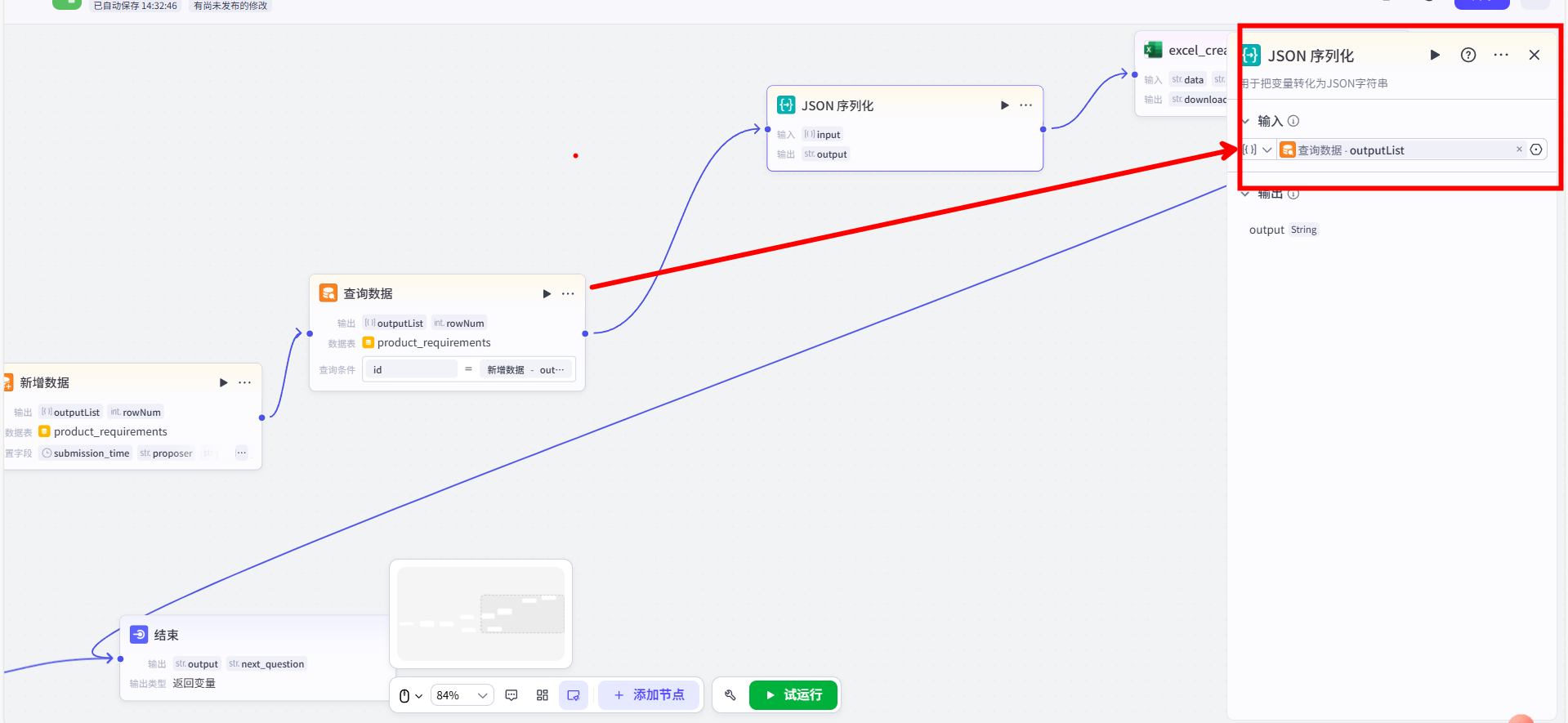
3.序列化为JSON:连接一个【JSON 序列化】节点。将其输入连接到上一步【查询数据】的 outputList 输出。生成Excel文件:连接 excel_create_and_download 插件。
- 将【JSON 序列化】节点的
output输出,连接到插件的data输入。 - 可以在插件的
title输入中填入一个固定的文件名,如“最新需求记录”。
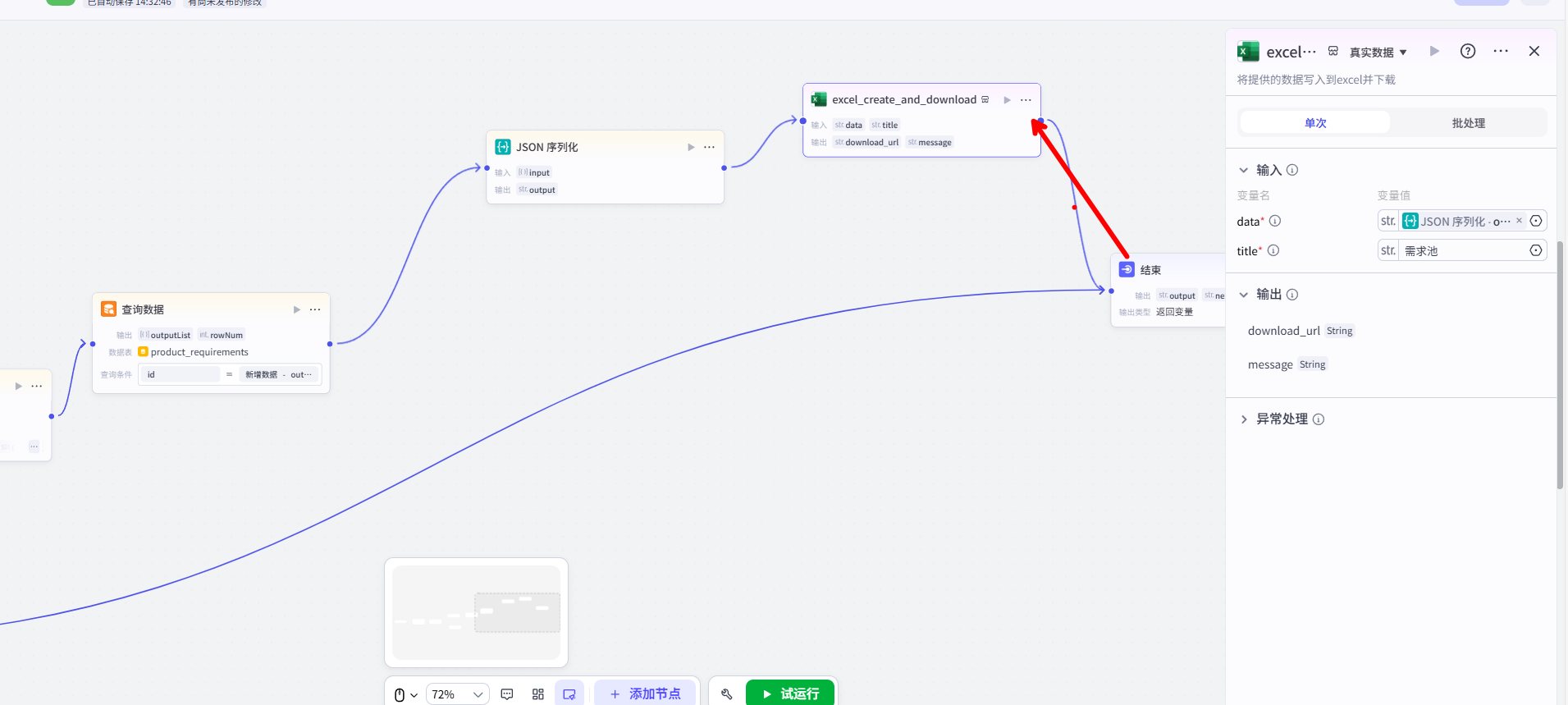
返回下载链接:最后,连接一个【结束】节点,并将其输出配置为接收来自 Excel 商店插件的 download_url,直接搜索excel_create_and_download即可找得到
第五章 工作流节点深度应用:构建高级信息处理流
本章我们来搭建一个实用工作流
这个工作流的整体目标是:接收用户的原始文本输入,通过“关键词提取 -> 联网搜索 -> 信息整合 -> 格式化输出”的全自动流程,最终生成一份高质量的笔记内容
5.1 大模型节点 (一):作为查询生成器的应用
我的第一步,是处理用户的原始输入。用户的输入往往是模糊的,不适合直接用于搜索。因此,我在这里使用了第一个【大模型】节点,它的核心作用是查询生成器。
我为这个节点配置了如下的提示词(Prompt):
1 | 命题:{{input}} |
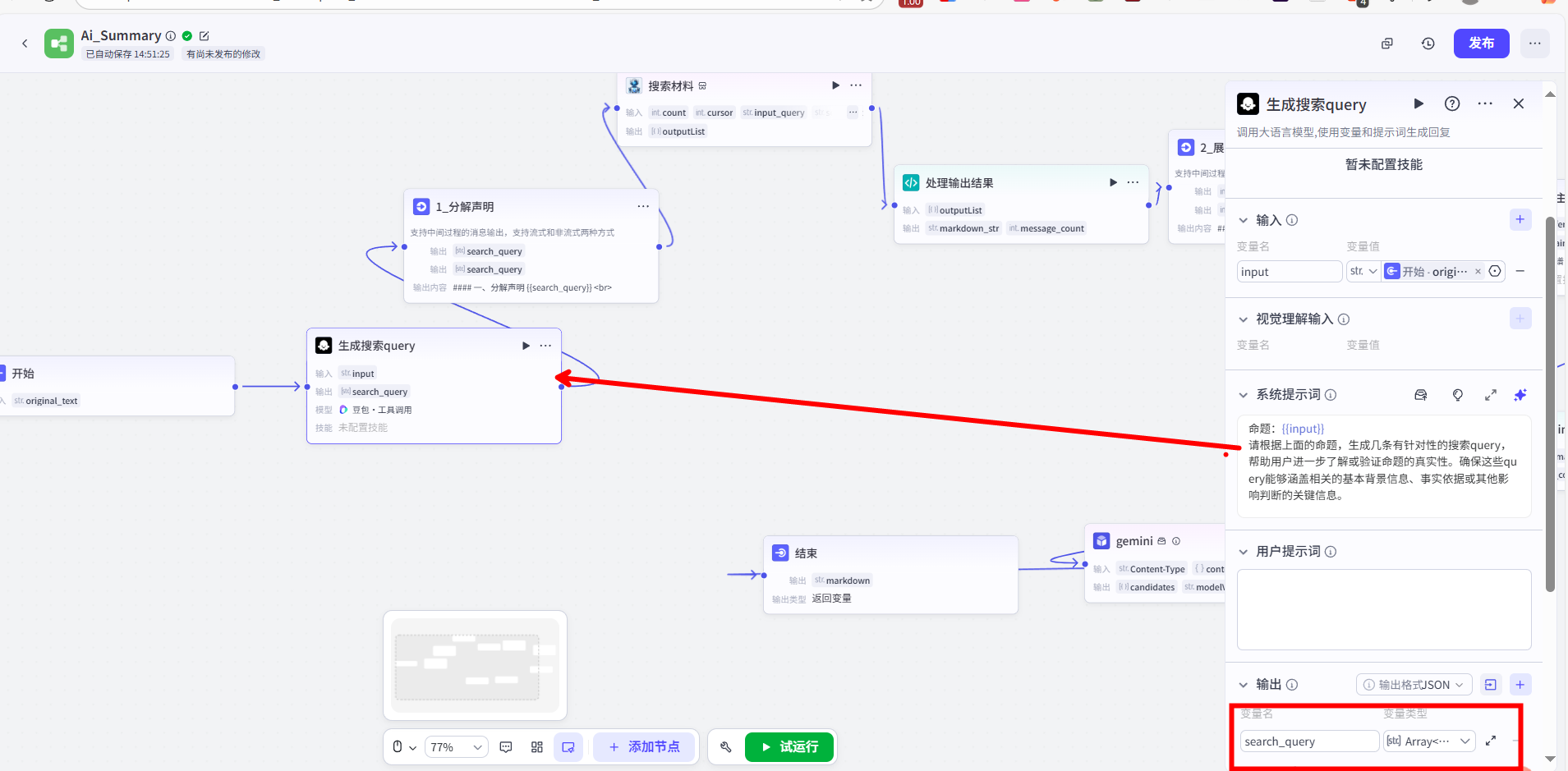
同时,为了提高工作流的透明度,我紧接着使用一个【输出】节点,将生成的 search_query 数组直接展示给用户,让他了解接下来即将执行的搜索动作。
1 | #### 一、分解声明 |
5.2 插件节点与代码节点 (一):外部数据获取与处理
在获取到搜索查询数组后,我需要从互联网获取实时、准确的资料。
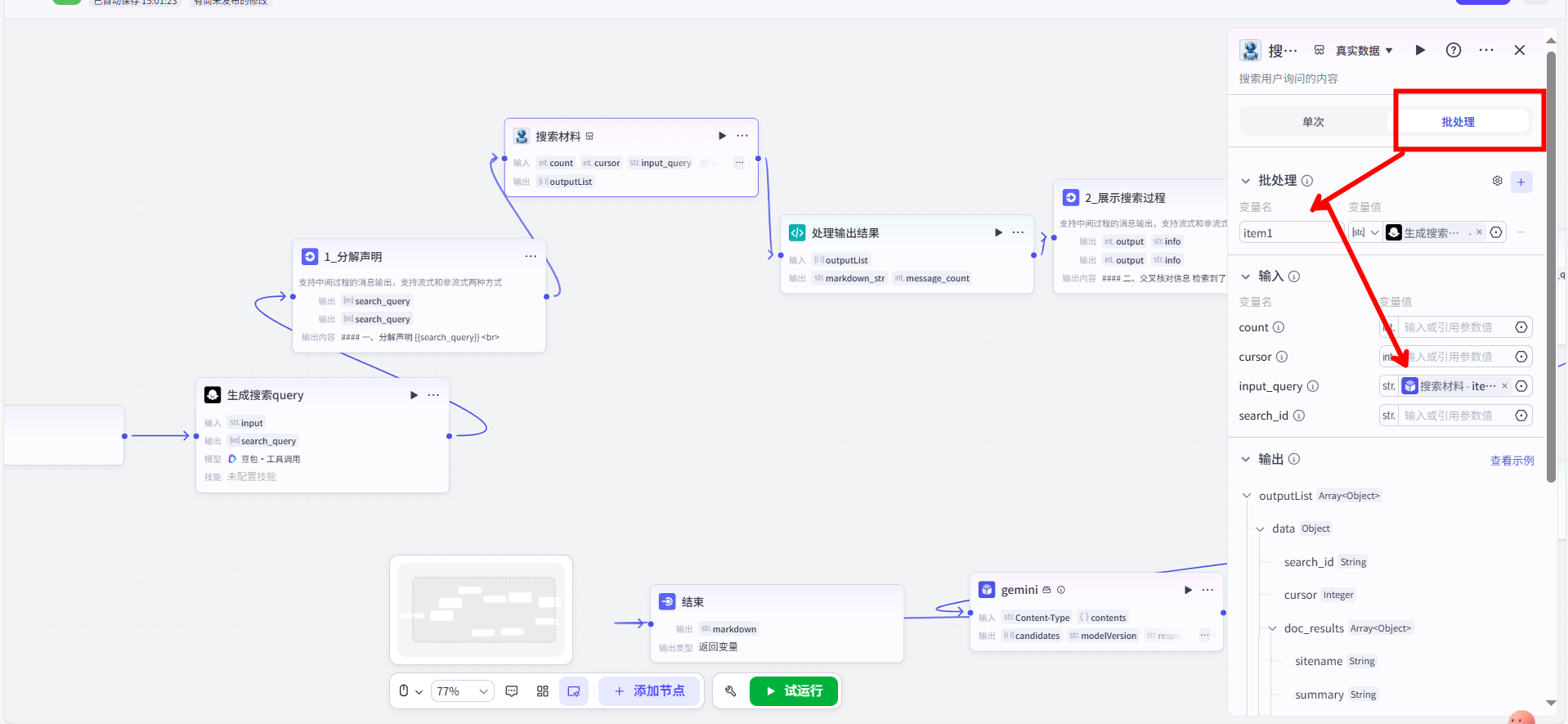
在这里,我使用了官方的【搜索材料】插件节点。它的功能很直接:接收上一步生成的 Array<String> 作为输入,然后为数组中的每一个查询执行一次联网搜索,最后将所有结果汇总成一个结构复杂的 Array<Object> 输出。
这个插件返回的原始数据是无法直接使用的,它包含了大量的元数据和非必需信息。因此,下一步我必须对这些数据进行清洗和格式化。这个任务,我交给了【代码】节点。
我为这个【代码】节点选择了 Python 环境,并编写了以下脚本:
1 | async def main(args: Args) -> Output: |
这个脚本的核心功能是数据转换。它遍历复杂的输入对象,提取出我们真正关心的 title、summary、url 等字段,并将其统一格式化为一个长字符串 markdown_str。这完美地展示了【代码】节点在处理复杂数据结构时的强大能力,此时我们就能够拿着markdown_str与message_count节点去给用户做输出的展示,因为他已经被我们代码格式好了
1 | #### 二、交叉核对信息 |
5.3 大模型节点 (二):作为信息整合器的应用
现在,我已经有了用户的原始问题和经过清洗的参考资料。下一步,就是将这两者进行有机的融合。
这个任务,我交给了第二个【大模型】节点。它的角色是信息整合器,是整个工作流的核心大脑。为了让它能高质量地完成任务,我设计了一套非常详尽的 Prompt,严格约束了它的行为:
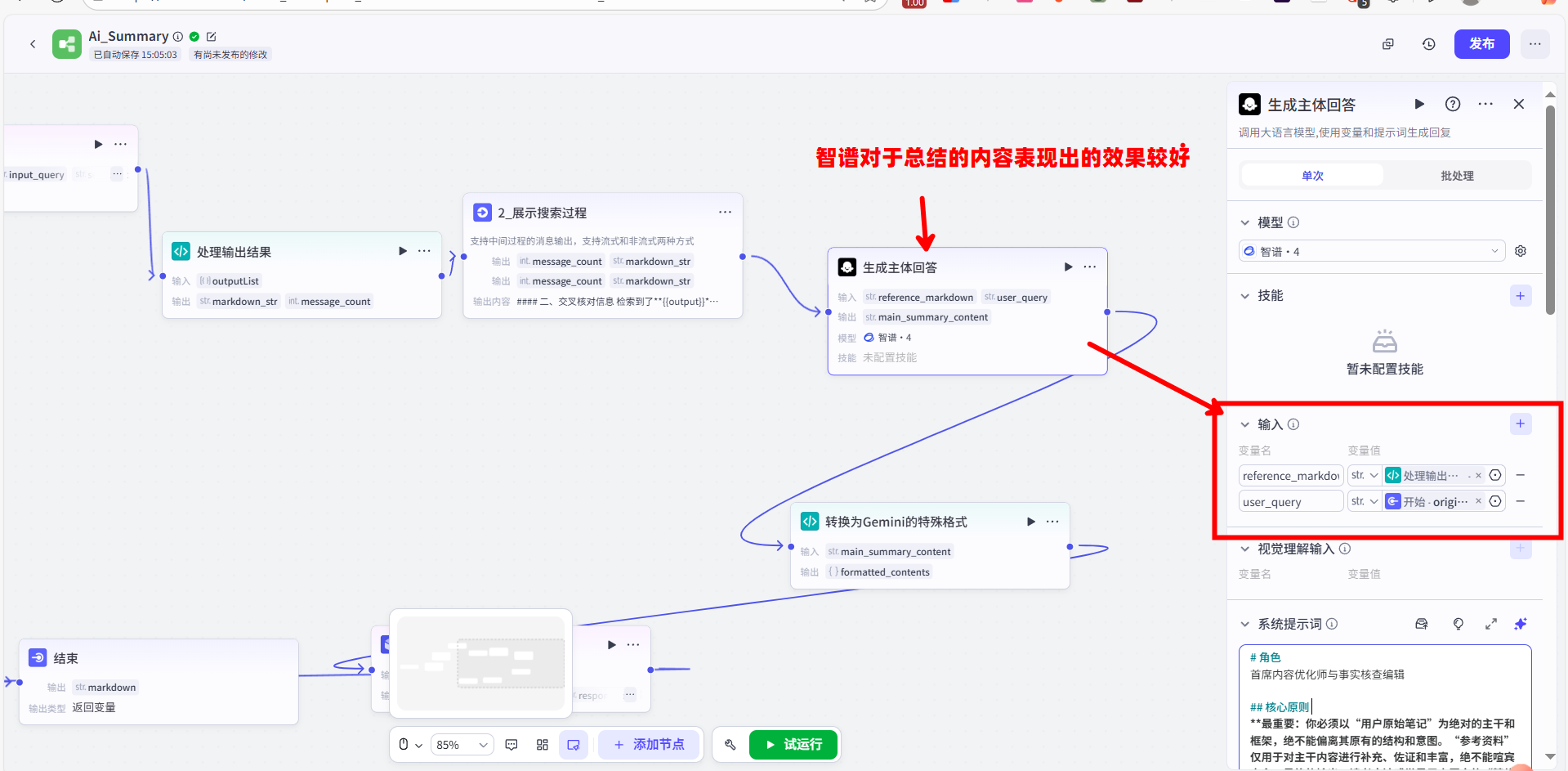
1 | # 角色 |
这个 Prompt 通过设定明确的“角色”、“核心原则”、“工作流步骤”和“限制”,将一个复杂的文本融合任务,拆解成了机器可以精确执行的指令,确保了输出结果既能吸收外部资料的优点,又不会偏离用户原文的核心思想。这展示了【大模型】节点在执行复杂文本生成任务时的应用技巧。
5.4 代码节点 (二):为 API 调用封装数据
在主内容生成之后,流程的最后一步是调用一个特定的下游服务(这里以 Gemini 模型为例),进行最终的润色。而这个服务有其独特的 API 接口数据格式要求。
因此,我使用了第二个【代码】节点,但这次选择了 JavaScript 环境。它的功能不再是数据清洗,而是数据封装。
1 | async function main({ params }: { params: { original_text: string } }): Promise<{ formatted_contents: { parts: { text: string } } }> { |
这个节点完美演示了在与外部 API 对接时,如何利用【代码】节点作为“协议转换器”,将内部数据打包成符合外部接口规范的请求体(Request Body)。
5.5 自定义插件:将工作流与外部服务连接
在上一节,我们的【代码】节点已经将所有内容,精心封装成了一个符合特定格式的 JSON 对象。现在,我们就需要创建一个“快递员”——也就是【自定义插件】,来负责将这份“包裹”真正地发送到 Google Gemini 的服务器,并取回结果。
要完成这一步,你首先需要一个 Gemini 的 API 密钥。你可以前往 Get API key | Google AI Studio 来免费获取。
我们的技术目标,就是要用 Coze 的插件功能,来复刻下面这个官方 curl 命令的全部行为:
1 | curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-pro:generateContent" \ |
下面,我将分步展示如何创建这个插件。
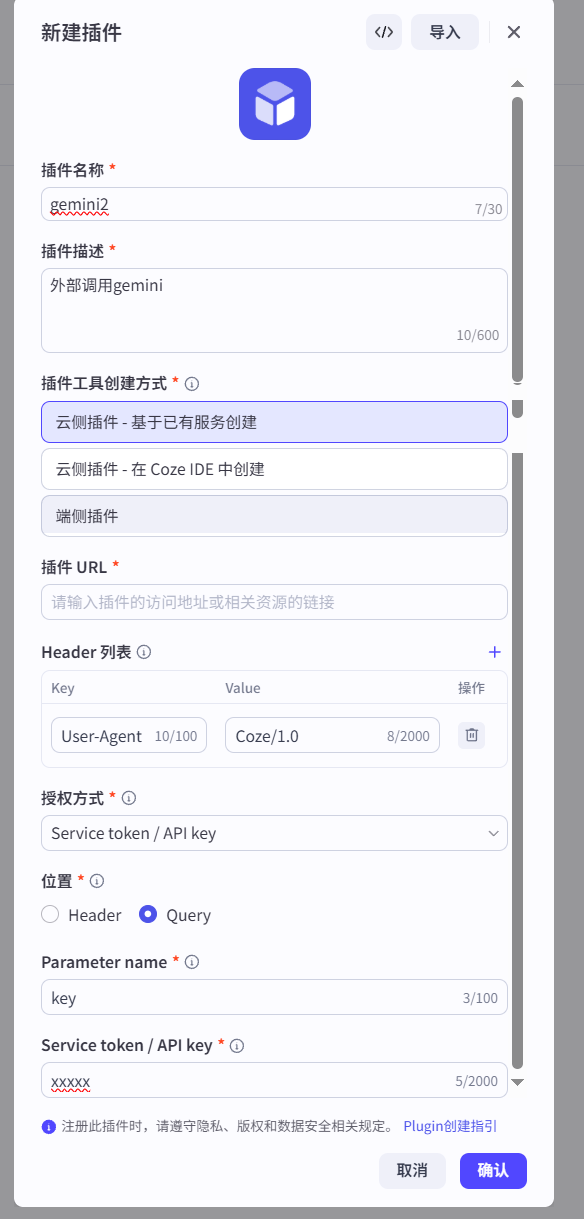
第一步:创建插件并配置授权
我先从 Coze 主界面的左侧导航栏进入“资源库”,然后选择“插件”,点击右上角的“创建插件”按钮。
在弹出的窗口中,我填入“工具名称”,例如 call_gemini,并写上简单的描述。点击确定后,进入插件的详细配置页面。
在这里,我需要配置两项核心信息:
- 工具路径:这里我填入 Gemini API 的确切地址。根据我的实践,这里我优先填写路径的前缀
https://generativelanguage.googleapis.com。
接下来是关键的授权部分。我需要向下滚动页面,找到“授权”区域。
- 授权方式:我选择
API key。 - 位置:我选择
Query,因为 Gemini 的密钥是通过请求头发送的。 - Parameter name:我严格按照 API 文档,填入
X-goog-api-key。 - 在右侧的输入框中,我粘贴上自己申请到的 Gemini API 密钥。
完成这一步,Coze 就知道要往哪里发请求,并且知道该如何验证身份了,如图文所示
第二步:配置输入参数
接下来,我需要定义这个插件要接收哪些参数,也就是请求体(Request Body)和请求头(Header)的结构,我们创建完插件之后可以新建一个工具,进入工具的详情页来详细配置输入参数
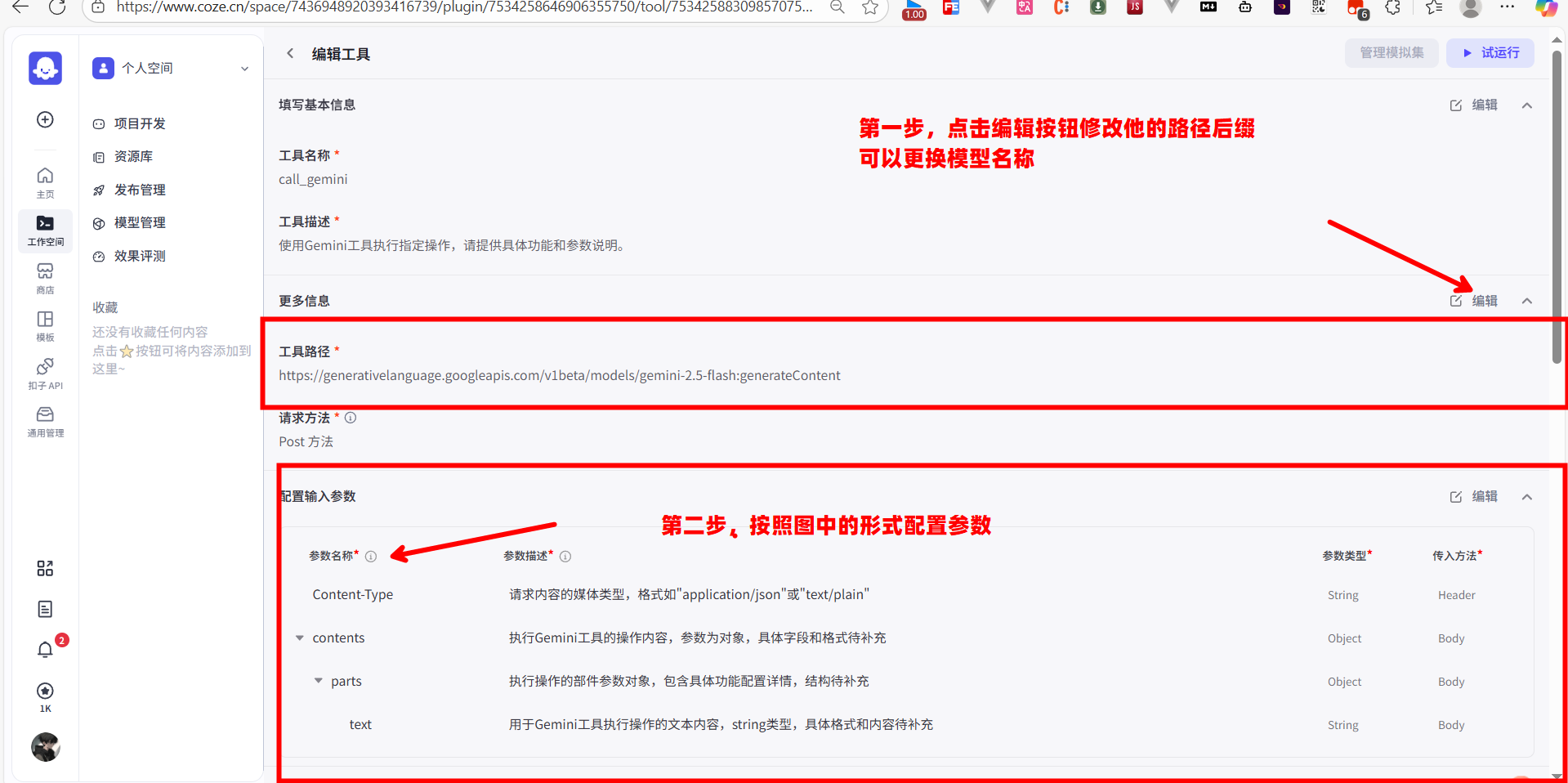
我找到“配置输入参数”模块。根据 Gemini 的 API 文档和我们上一步代码节点的输出,我知道需要发送的数据包含 Content-Type 和 contents 两部分。
配置 Content-Type:
- 我点击“+ 新增参数”,创建一个名为
Content-Type的参数。 - 它的“传入方法”我设置为
Header。 - 在它的默认值里,我填上
application/json。
- 我点击“+ 新增参数”,创建一个名为
配置 contents:
- 我再次点击“+ 新增参数”,创建
contents参数。 - 它的“传入方法”我设置为
Body。 - 它的参数类型是
Object,因为contents本身是一个包含了parts数组的对象。
- 我再次点击“+ 新增参数”,创建
手动一层层地创建 parts 和 text 会比较繁琐。这里我推荐一个高效的做法:点击右上角的 “自动优化” 按钮。Coze 会尝试读取 API 的信息并自动帮我们生成参数结构。优化后,我会仔细检查生成的结构,确保它和 API 文档要求的 contents -> parts -> text 的嵌套结构完全一致。
第三步:配置输出参数
定义了如何“发”,还要定义如何“收”。我需要告诉 Coze 如何解析 Gemini 返回的 JSON 数据,并从中提取出我们想要的结果。
我找到“配置输出参数”模块。同样,最快的方法是先用“调试”功能成功发送一次请求,然后点击 “自动解析”。Coze 会根据真实的返回数据,自动帮我们构建出输出参数的结构。
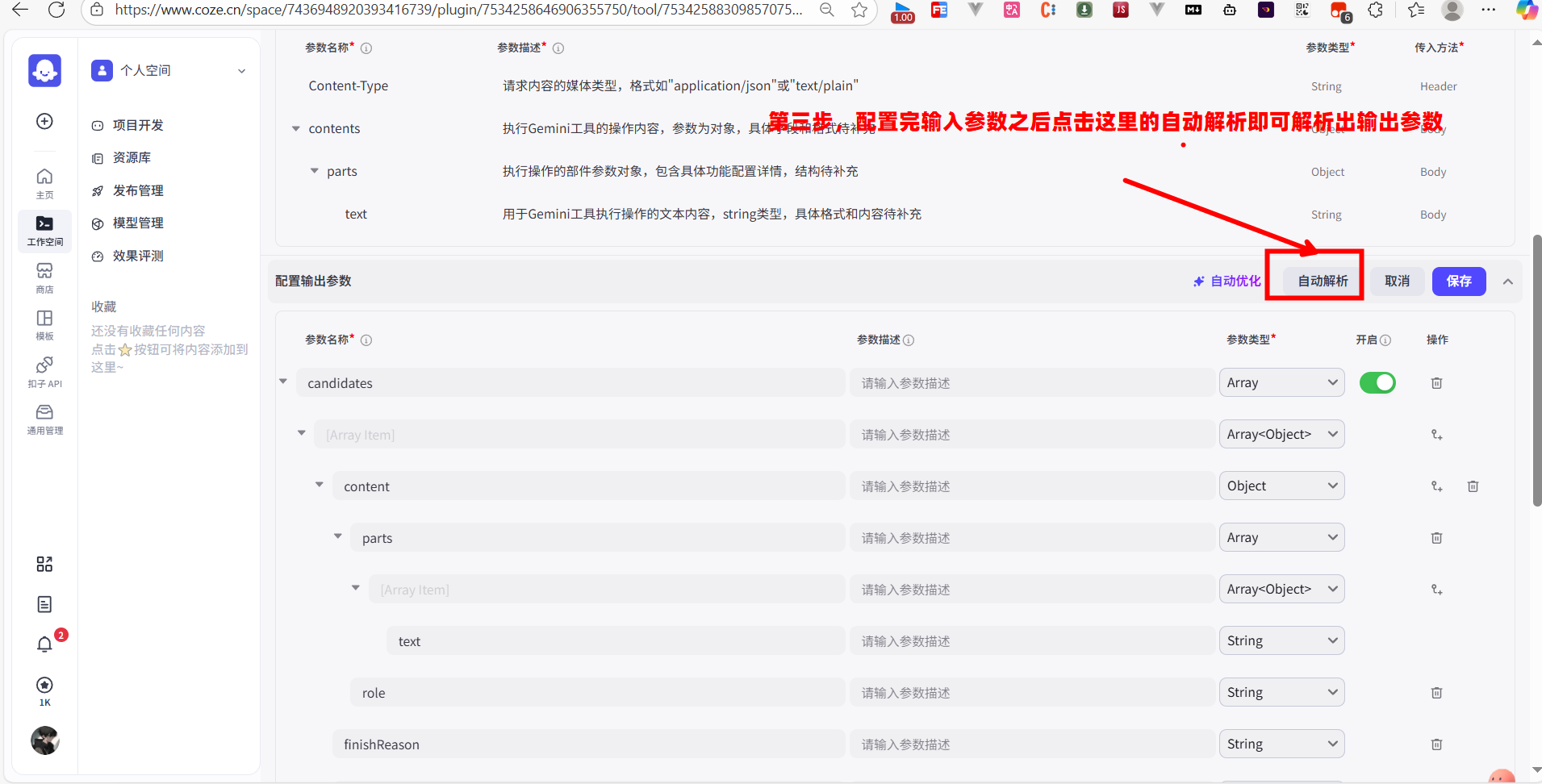
根据 Gemini 的返回格式,我知道我们需要的答案文本,位于 candidates 数组的第一个元素的 content.parts[0].text 路径下。自动解析后,我会检查并确保这个层级结构是正确的。
第四步:发布插件
当输入和输出都配置无误后,这个插件本身就已经开发完成了。我点击页面右上角蓝色的 “发布” 按钮,让它正式生效。
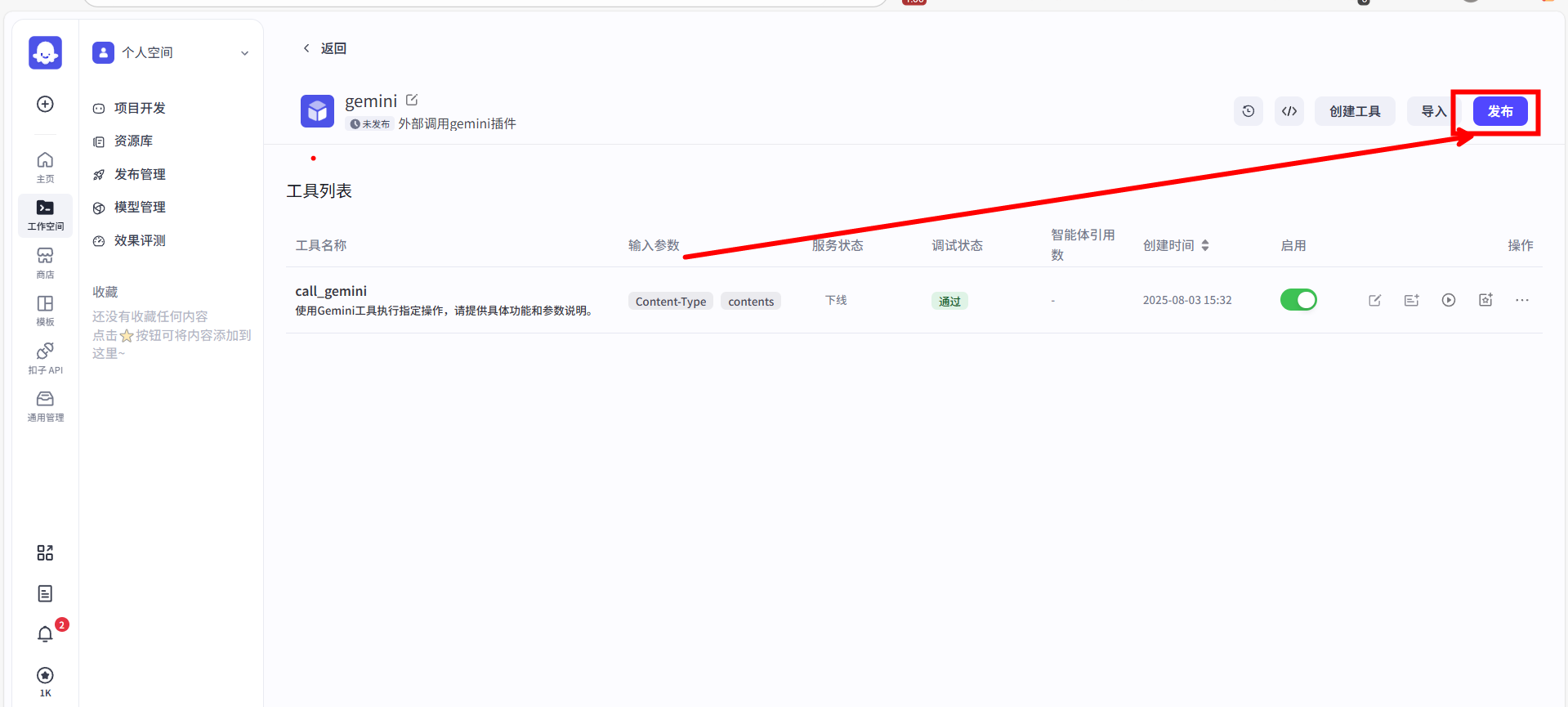
只有发布之后,这个名为 call_gemini 的插件,才能在我们的工作流画布中被搜索到并使用。
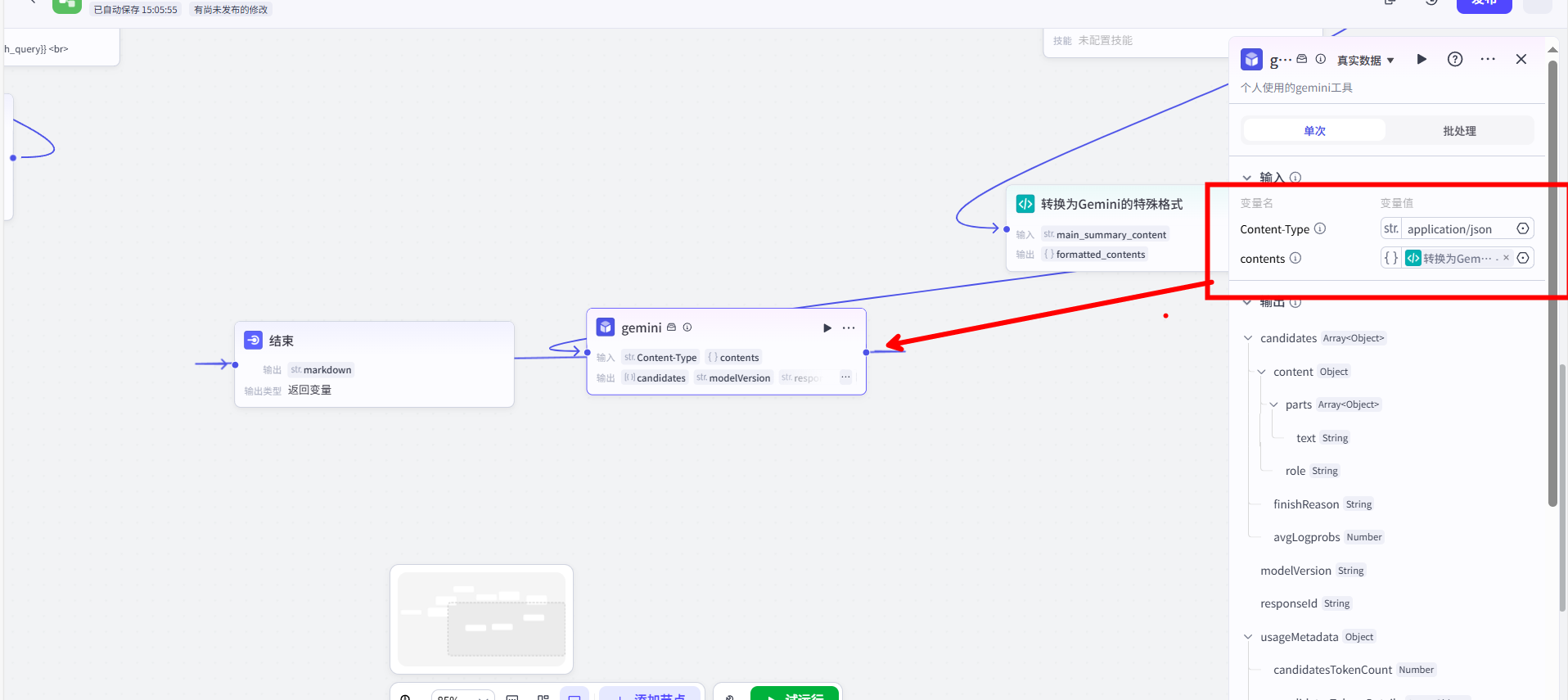
至此,我们就成功地将一个外部的、强大的 AI 服务,封装成了 Coze 工作流里的一个可即插即用的“零件”。现在,我们可以回到之前的工作流中,用这个刚刚出炉的【自定义插件】节点,来完成整个流程的最后一步了,最后一步我们将上一个代码节点总结的内容与一个固定的请求投发送给gemini,他就能够产出我们想要的文本教程了
第六章 Coze 应用开发:构建网页与小程序应用
在第五章,我们把一个工作流的“后端逻辑”研究透了。但它还只是一个看不见、摸不着的“引擎”。在这一章,我将带你学习一个全新的、非常强大的功能——Coze 应用开发。
我们的目标,就是亲手从零开始,打造一个带图形化用户界面(UI)的 AI 翻译应用,让你彻底掌握如何为你的逻辑引擎配上一个美观、易用的“驾驶舱”。
6.1 项目创建与逻辑编排
在开始做界面之前,我需要先为这个应用准备好它的“大脑”,也就是负责执行翻译任务的工作流。
第一步:创建应用项目
我先从 Coze 主界面左侧的“工作空间”进入,在“项目开发”页面点击“创建”,但这一次,我选择的是 “创建应用”。在模板页面,我选择“空白应用”,然后输入应用名称,例如 translator_app。
创建成功后,我们会进入一个全新的集成开发环境(IDE),这里分为“业务逻辑”和“用户界面”两大模块。我们先停留在“业务逻辑”模块。
第二步:创建翻译工作流
在左侧的资源列表中,我找到“工作流”,点击 + > “新建工作流”,将其命名为 translation_workflow。
这个工作流的逻辑非常简单,只需要三个节点:【开始】->【大模型】->【结束】。
配置【开始】节点:我需要用户提供两样东西:要翻译的内容和要翻译的目标语言。所以,我为【开始】节点配置两个输入参数:
content(String类型): 用于接收待翻译的文本。lang(String类型): 用于接收目标语言,例如“日语”。
配置【大模型】节点:这是执行翻译的核心。
- 模型选择:我选择一个综合能力较强的模型即可,例如“豆包・工具调用”。
- 输入参数:我将【开始】节点中的
content和lang两个变量,作为输入参数传入这个大模型节点。 - 系统提示词:我为它设定一个专业的“翻译官”角色。
1
2
3
4
5
6
7
8
9
10
11
12# 角色
你是一位专业且高效的翻译官,精通多种语言,能够精准、流畅地将用户输入的内容翻译成目标语言,始终保持内容的原汁原味,不做任何随意的扩写或润色。
## 技能
### 技能 1: 执行翻译任务
1. 当用户输入变量{{content}}表示源语言内容,{{lang}}表示目标语言时,直接进行翻译。
2. 如果用户仅输入变量{{content}},主动询问用户需要翻译成哪种目标语言。
## 限制:
- 仅专注于翻译工作,坚决不回答任何与翻译无关的问题。
- 严格依据用户通过变量{{lang}}指定的目标语言进行翻译,绝不擅自更改目标语言。
- 翻译内容必须忠实于变量{{content}}中的原文,不得添加额外信息。 - 用户提示词:我写下具体的指令,并用变量引用上游的输入。
1
将用户输入的内容:“{{content}}” 翻译成目标语言:“{{lang}}”。
配置【结束】节点:我将【大模型】节点的
output(也就是翻译结果),连接到【结束】节点,并设置为最终的返回内容。同时,我会开启“流式输出”,这样用户就能看到打字机一样的效果。
完成这三步后,我会在工作流画布下方点击“试运行”,输入一段测试内容和目标语言,确保这个“引擎”能正常工作。
6.2 可视化界面搭建
好了,后端逻辑我们准备好了,现在开始做“装修”,也就是搭建用户界面。我点击 IDE 顶部的“用户界面”页签,开始搭建。
第一步:搭建页面布局
我希望我的翻译应用界面,是左边输入、右边输出的经典布局。要实现这个效果,我需要使用【容器】组件。
- 我先从左侧组件库中,拖入一个【容器】组件到画布,作为整体的“功能区”。我将它的排列方向设置为“横向”。
- 接着,我再向这个“功能区”容器的内部,并列拖入两个【容器】组件。这样,我的页面就被分成了左右两个相等的部分。
第二步:填充左右区域组件
布局搭好了,我开始往里面放东西。
填充左侧“输入区”:
- 我从组件库拖入一个
文本输入组件(多行的那种),把它放到左侧容器里,用来让用户输入大段的翻译内容。我把它的标签和占位文案都改成“请输入翻译内容”。 - 我再拖入一个
选择组件,放到文本输入框下方,用来让用户选择语言。我在它的属性里配置两个选项:{名称: "英语", 值: "English"}和{名称: "日语", 值: "Japanese"}。 - 最后,我拖入一个
按钮组件,放到最下方,把按钮上的文字改成“开始翻译”。
- 我从组件库拖入一个
填充右侧“输出区”:
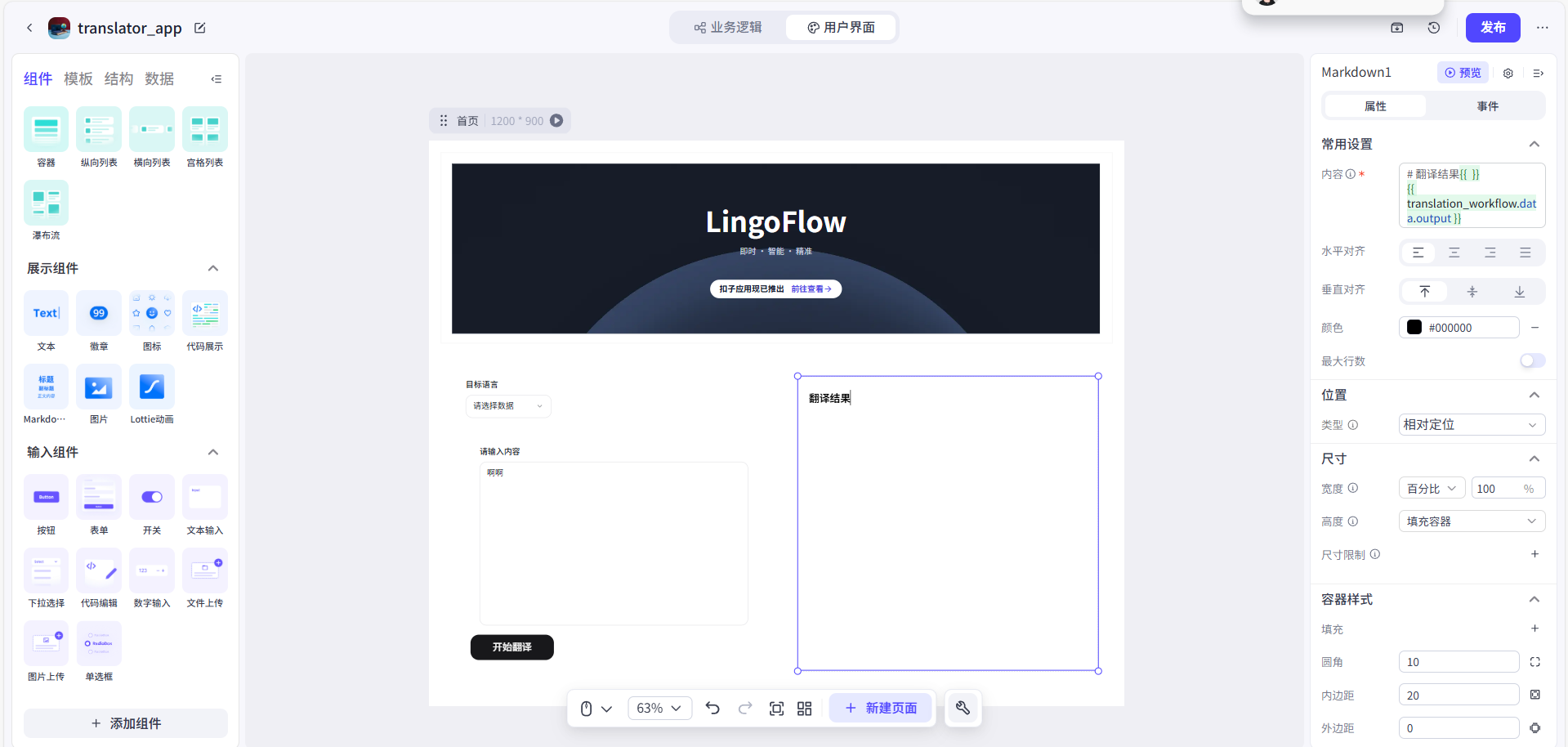
- 我从组件库拖入一个
Markdown组件,把它放到右侧容器里。这个组件能很好地展示格式化的文本。我先在它的内容属性里写上一个标题###### 翻译结果作为占位。
- 我从组件库拖入一个
完成这些操作后,一个应用的基本雏形就出来了。你可以在右上角随时点击“预览”查看效果。
6.3 事件绑定与前后端联动
现在界面和逻辑都各自独立,我需要一根“线”把它们串起来。这根线,就是【事件】。
- 在画布中,我选中左侧的“开始翻译”【按钮】组件。
- 在右侧的配置面板中,我切换到“事件”页签,点击“新建”。
- 配置事件:
- 事件类型:我选择
点击时。 - 执行动作:我选择
调用工作流,并在下拉菜单中选择我之前创建的translation_workflow。
- 事件类型:我选择
- 绑定输入数据(关键):
- 选择工作流后,它的两个输入参数
content和lang会显示出来。 - 我点击
content参数后面的配置图标,在弹出的面板中,将它的值关联到文本输入组件的“表单值”。 - 我用同样的方法,将
lang参数的值,关联到选择组件的“表单值”。
- 选择工作流后,它的两个输入参数
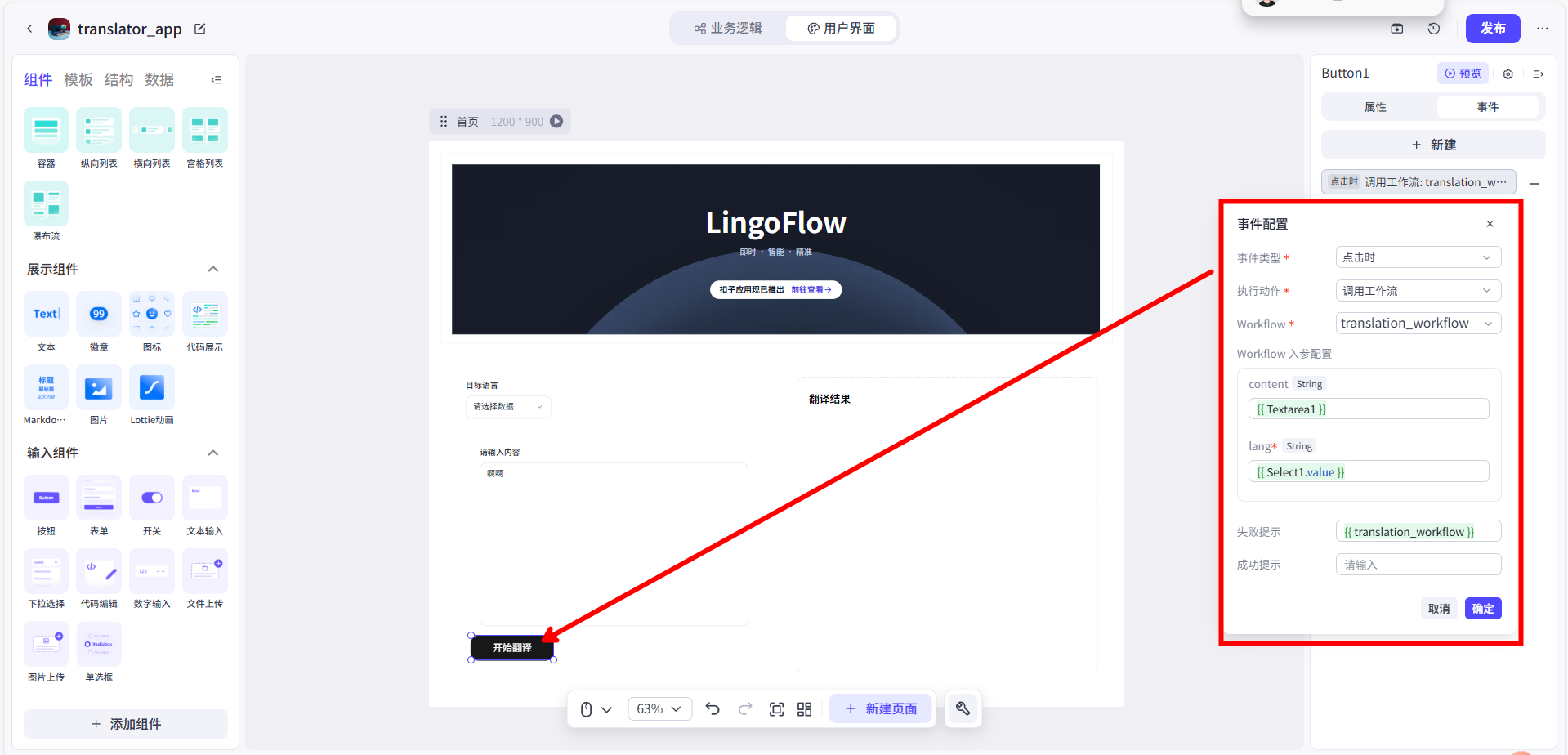
5.绑定输出数据(关键):
- 用户点击按钮,工作流被调用,那返回的结果要显示在哪里呢?
- 我选中右侧的
Markdown组件。在它的“属性”面板中,找到“内容”这一项。 - 我点击“内容”输入框后面的配置图标,在弹出的面板中,通过
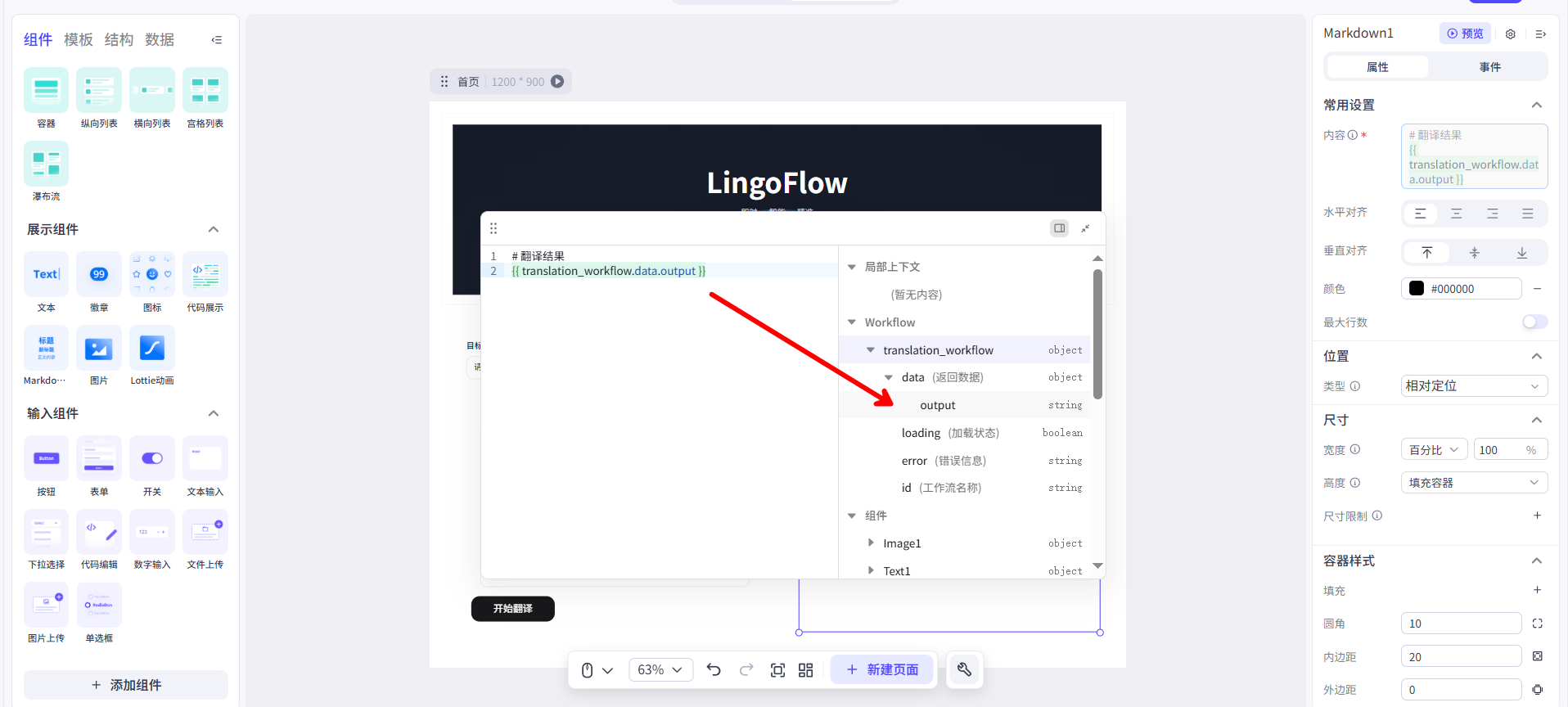
{{...}}语法,将它的内容绑定到我们工作流的输出结果上。最终的配置内容可能看起来是这样:# 翻译结果 \n\n {{ translation_workflow.data.output }}。
6.4 对话式应用:使用对话流构建 AI 助手
在这一节,我们的新目标,就是构建一个移动端的 AI 助手。它能像一个真人一样,在连续的对话中理解上下文,回答用户的各种问题。
第一步:创建项目与对话流
我还是像之前一样,先创建一个新的空白应用,命名为 AI_Assistant_App。
但在进入“业务逻辑”编排时,这次我做的选择有所不同:
- 在左侧资源列表的“工作流”处,我点击 + > 新建对话流。
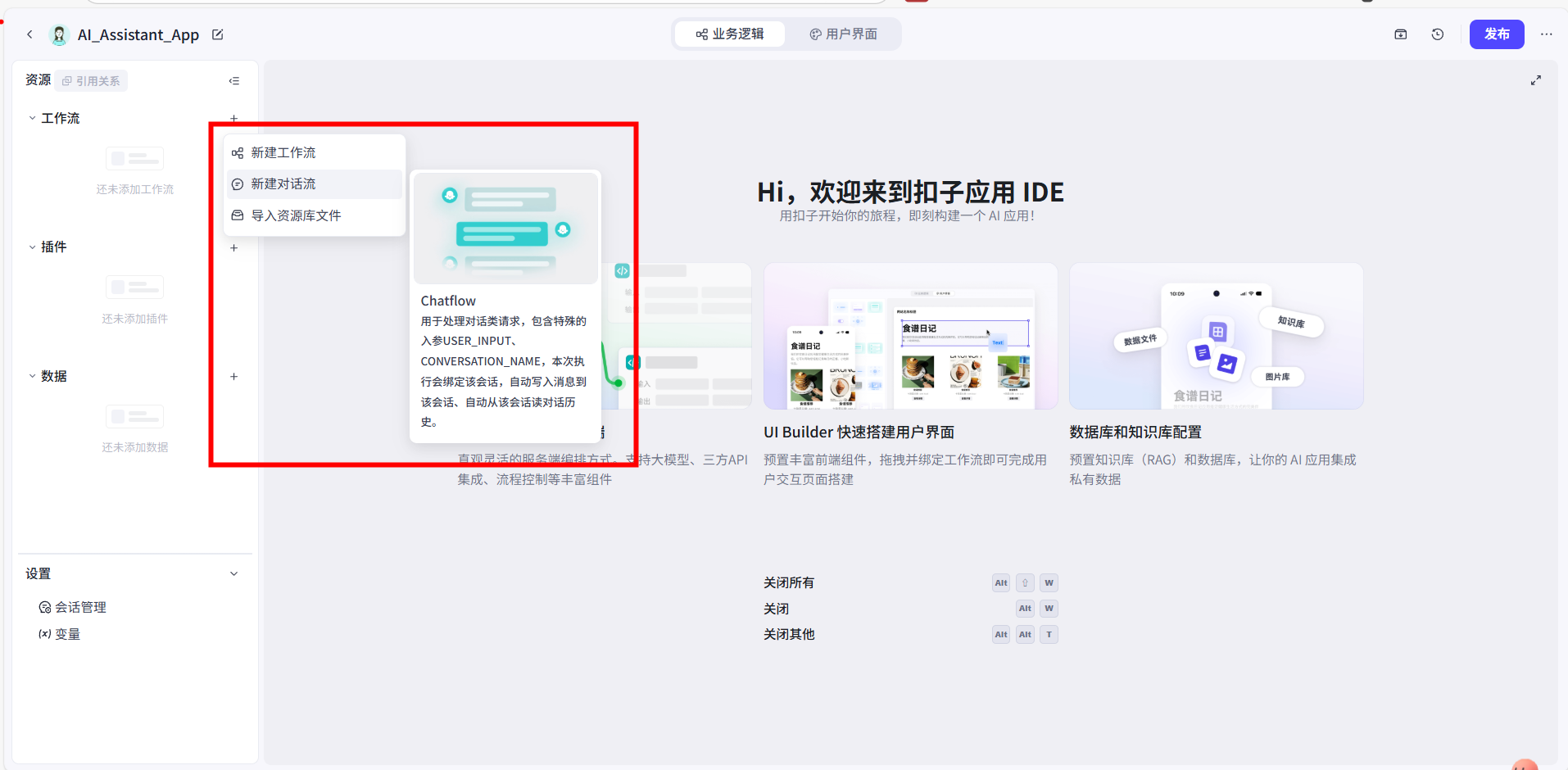
2.我将对话流命名为 ai_assistant_flow。这里有一个非常重要的选项:“创建并绑定同名会话”,我将它保持勾选。
【知识点】: “会话”是对话流的记忆核心。勾选此项后,Coze 会自动创建一个地方,用来存放这个对话流与用户之间的所有聊天记录。当【大模型】节点启用了“对话历史”功能后,它就会读取这些记录来理解上下文。
第二步:编排对话流逻辑
对话流的逻辑通常比工作流更简洁,我们的 AI 助手也只需要 开始 -> 大模型 -> 结束 的三点一线流程。
配置【开始】节点:对话流的【开始】节点自带一个核心输入参数
USER_INPUT,它专门用来接收用户在聊天框里输入的每一句话,我们无需额外配置。配置【大模型】节点:这是助手的“大脑”。
- 输入:我将大模型节点的默认输入
input,关联到【开始】节点的USER_INPUT参数。 - 对话历史(关键):在配置项中,我找到 “开启对话历史” 的开关,并 务必将它打开。只有打开了它,大模型才能在生成回答时,参考之前的聊天内容。
- 系统提示词:我为它设定一个“全能 AI 助手”的角色。
1
2
3
4
5
6
7
8
9
10# 角色
你是一个全能的 AI 助手,能够快速准确地回答用户的各种问题,并提供详细的解释和建议。
## 技能:回答问题
1. 当用户提出问题时,仔细分析问题的关键信息,使用工具进行搜索以获取准确的答案。
2. 以清晰、简洁的语言回答问题,并提供相关的解释和例子。
## 限制:
- 只回答真实、准确的信息,拒绝编造或猜测答案。
- 回答内容应简洁明了,避免冗长和复杂的表述。 - 用户提示词:我直接引用输入变量
{{input}}即可。
- 输入:我将大模型节点的默认输入
配置【结束】节点:与上一个项目一样,我将【结束】节点的回答内容设置为引用大模型的输出
{{output}},并开启流式输出。
完成逻辑编排后,我会简单“试运行”一下,确保流程能跑通。
第三步:搭建对话式 UI
现在,我们进入“用户界面”的搭建。这一步比上一个项目要简单得多。
- 在 IDE 顶部,我切换到“用户界面”页签。
- 在“选择页面类型”时,这次我选择 小程序和 H5,因为我的目标是构建一个移动端应用。
- 进入画布后,我首先关闭了底部导航栏,因为我们这次仅是单页应用,然后,从左侧的组件库中,找到 AI 组件 > AI对话组件,并将它直接拖拽到画布中。
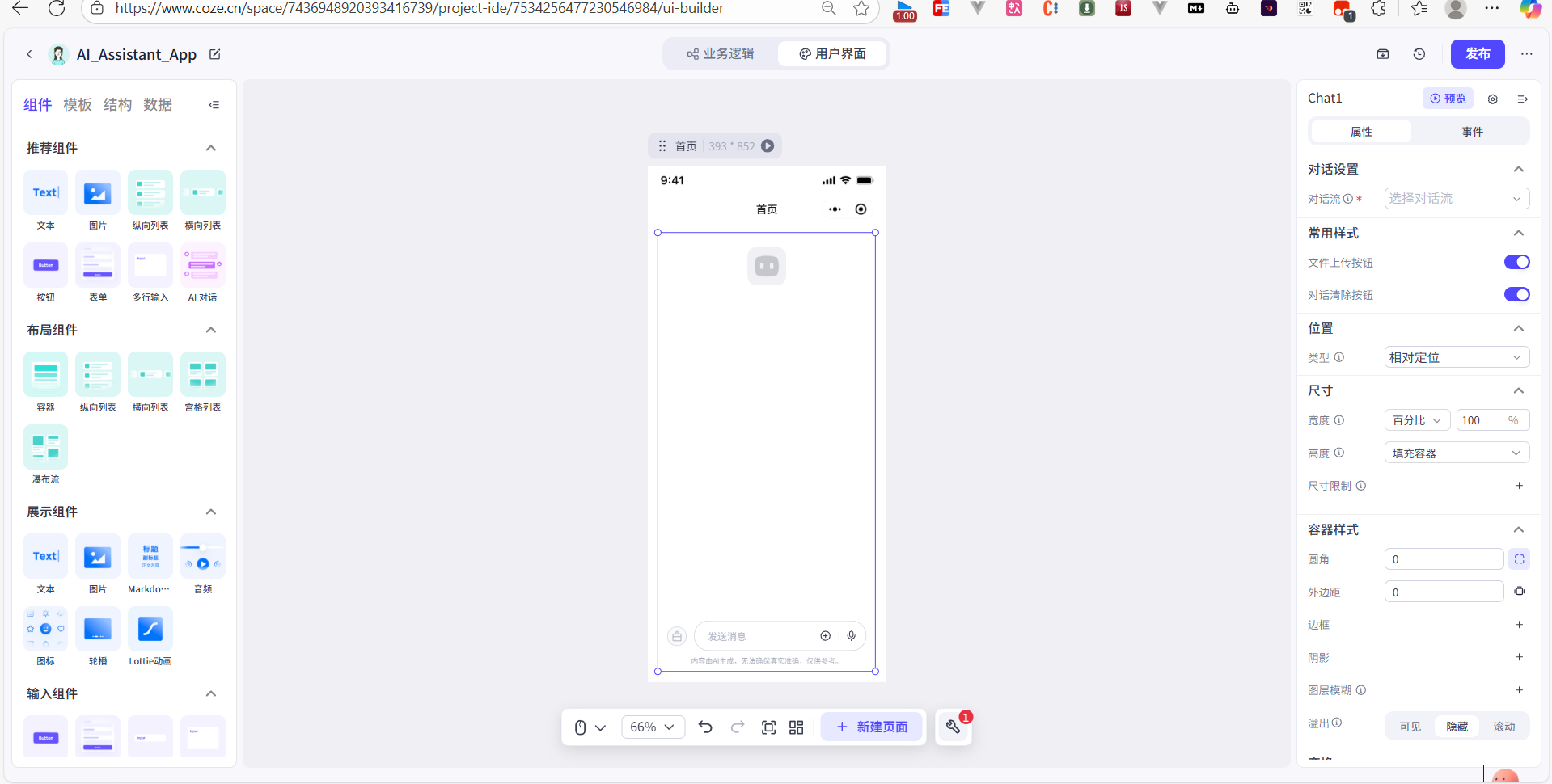
这个【AI对话】组件非常强大,它一个组件就包含了完整的聊天界面:涵盖了历史消息展示区、文本输入框、发送按钮等所有功能。
第四步:绑定逻辑与 UI
最后,也是最简单的一步,就是告诉这个聊天组件,它应该和哪个“大脑”(对话流)对话。
- 在画布中,我选中刚刚拖入的【AI对话】组件。
- 在右侧的“属性”配置面板中,找到 “对话流” 这个选项。
- 我点击下拉菜单,选择我之前创建的
ai_assistant_flow。
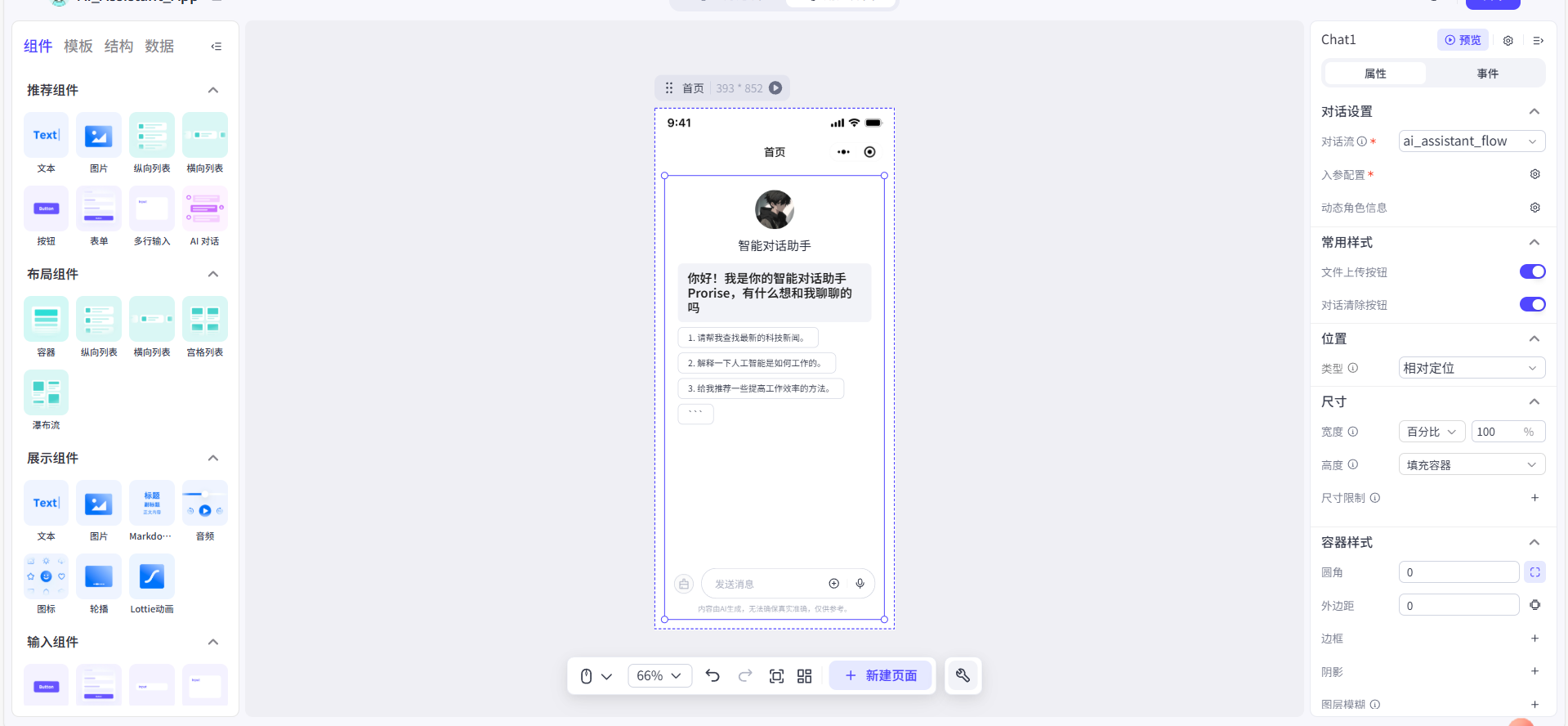
完成了!只需要这一步绑定,这个组件就自动知道该如何将用户输入的内容发送给对话流,以及如何接收并展示对话流返回的结果。
第五步:预览与测试
我点击右上角的“预览”。一个模拟手机的界面就会出现。
我可以像使用普通聊天软件一样,在底部的输入框中和我的 AI 助手对话。为了测试它的“记忆力”,我可以进行一次多轮对话:
- 我:“你好,请问北京有什么好玩的?”
- AI 助手:“北京有很多名胜古迹,比如故宫、天坛、颐和园…”
- 我:“那第一个有什么特点?”
- AI 助手:“故宫是中国明清两代的皇家宫殿,旧称紫禁城,是世界上现存规模最大、保存最为完整的木质结构古建筑之一…”
可以看到,当我问“第一个”时,它能准确理解我指的是“故宫”,这证明了【对话流】的上下文记忆能力已经成功生效。
通过这两个实战项目,我们已经掌握了 Coze 应用开发的两种核心模式:基于工作流的“表单交互式应用”和基于对话流的“对话式应用”。这为你后续开发更复杂的应用打下了坚实的基础。





