Prorise
这是我的博客,分享技术与生活的点点滴滴
第五章 工作流节点深度应用:构建高级信息处理流
第五章 工作流节点深度应用:构建高级信息处理流
Prorise第五章 工作流节点深度应用:构建高级信息处理流
本章我们来搭建一个实用工作流
这个工作流的整体目标是:接收用户的原始文本输入,通过“关键词提取 -> 联网搜索 -> 信息整合 -> 格式化输出”的全自动流程,最终生成一份高质量的笔记内容
5.1 大模型节点 (一):作为查询生成器的应用
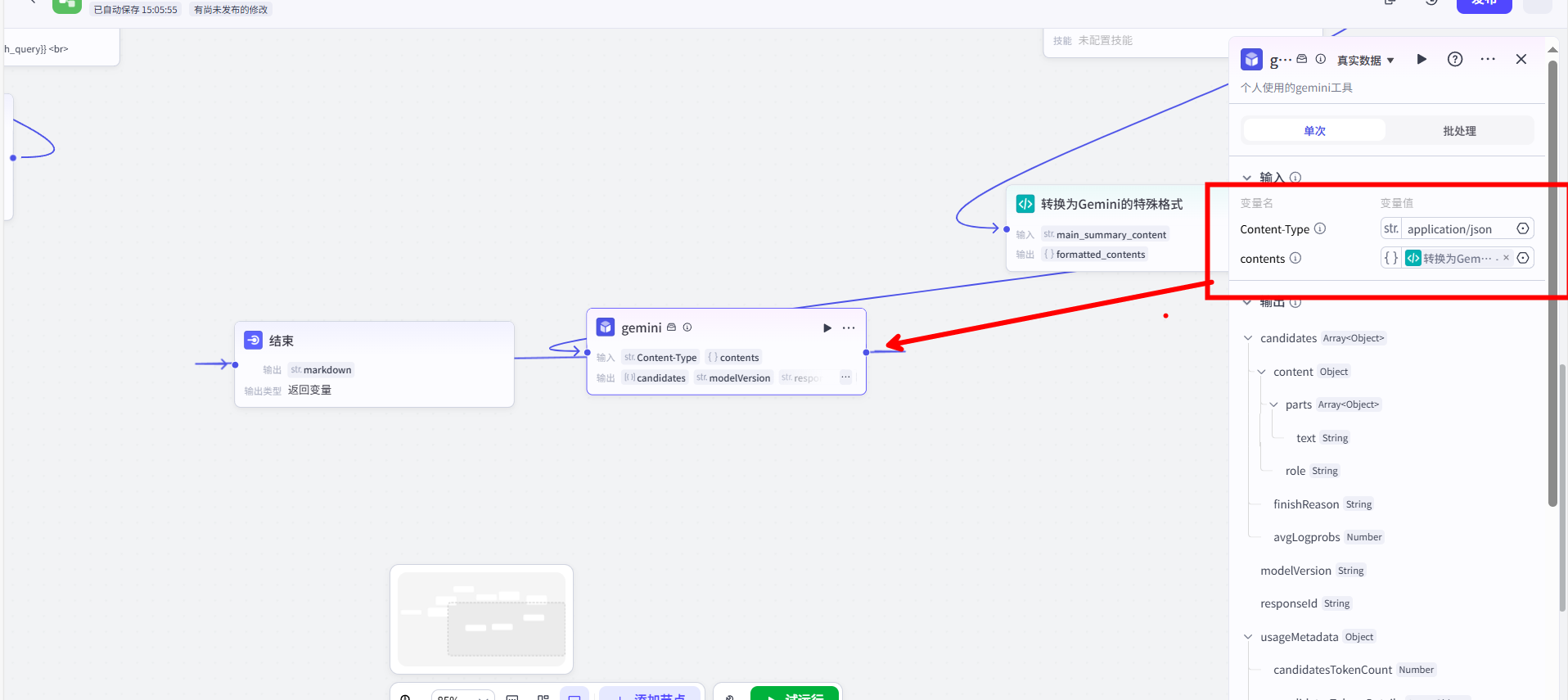
我的第一步,是处理用户的原始输入。用户的输入往往是模糊的,不适合直接用于搜索。因此,我在这里使用了第一个【大模型】节点,它的核心作用是查询生成器。
我为这个节点配置了如下的提示词(Prompt):
1 | 命题:{{input}} |
同时,为了提高工作流的透明度,我紧接着使用一个【输出】节点,将生成的 search_query 数组直接展示给用户,让他了解接下来即将执行的搜索动作。
1 | #### 一、分解声明 |
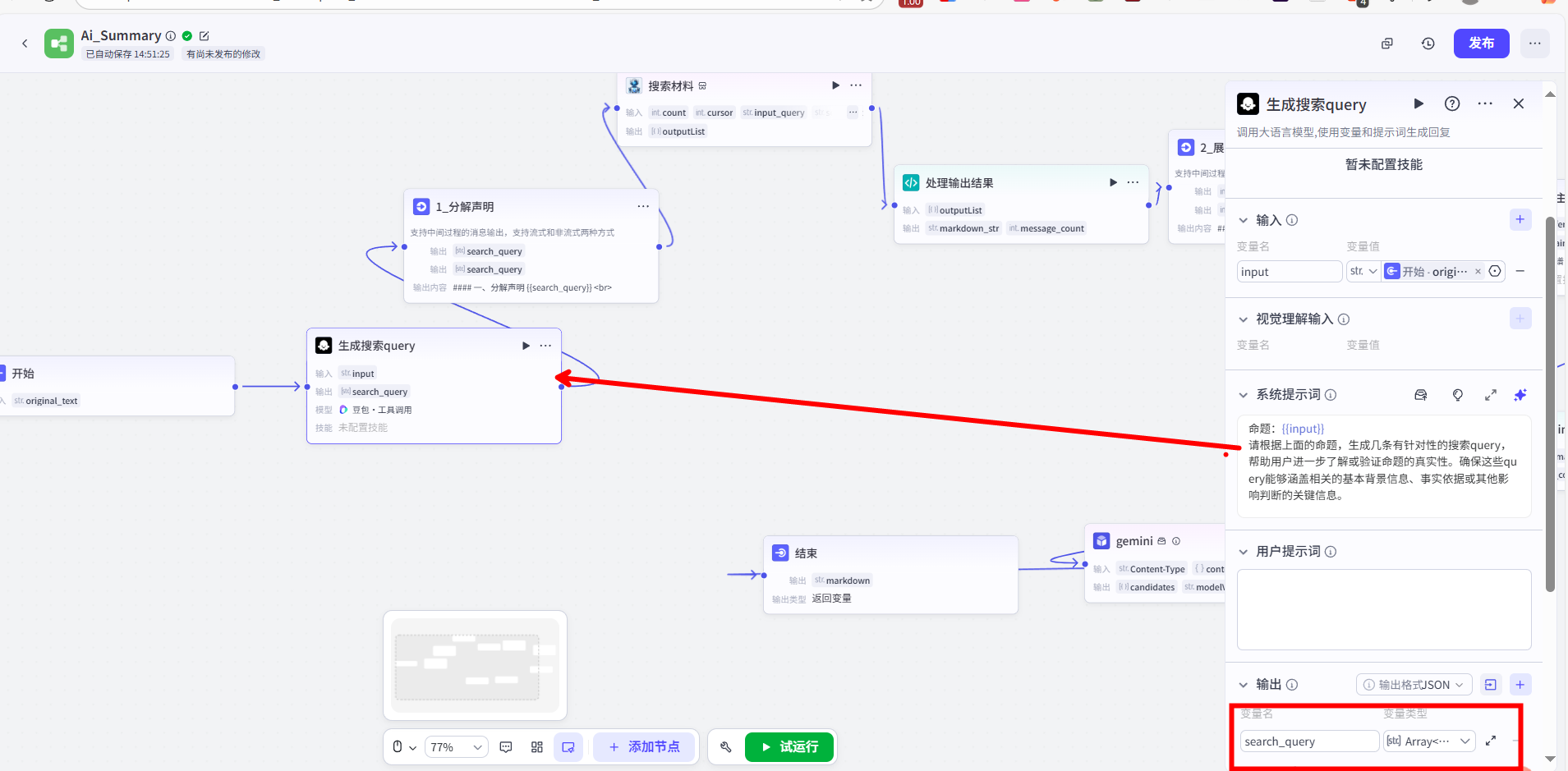
5.2 插件节点与代码节点 (一):外部数据获取与处理
在获取到搜索查询数组后,我需要从互联网获取实时、准确的资料。
在这里,我使用了官方的【搜索材料】插件节点。它的功能很直接:接收上一步生成的 Array<String> 作为输入,然后为数组中的每一个查询执行一次联网搜索,最后将所有结果汇总成一个结构复杂的 Array<Object> 输出。
这个插件返回的原始数据是无法直接使用的,它包含了大量的元数据和非必需信息。因此,下一步我必须对这些数据进行清洗和格式化。这个任务,我交给了【代码】节点。
我为这个【代码】节点选择了 Python 环境,并编写了以下脚本:
1 | async def main(args: Args) -> Output: |
这个脚本的核心功能是数据转换。它遍历复杂的输入对象,提取出我们真正关心的 title、summary、url 等字段,并将其统一格式化为一个长字符串 markdown_str。这完美地展示了【代码】节点在处理复杂数据结构时的强大能力,此时我们就能够拿着markdown_str与message_count节点去给用户做输出的展示,因为他已经被我们代码格式好了
1 | #### 二、交叉核对信息 |
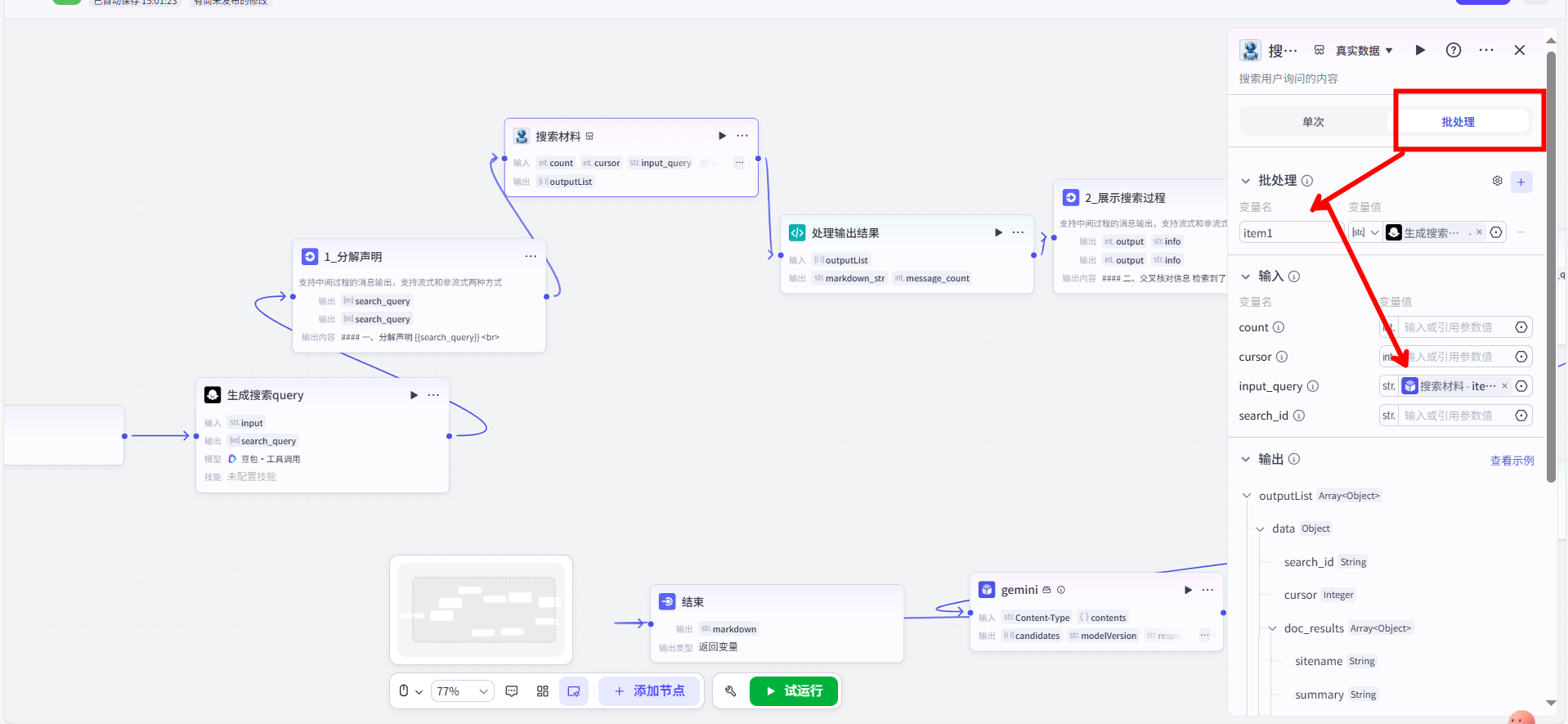
5.3 大模型节点 (二):作为信息整合器的应用
现在,我已经有了用户的原始问题和经过清洗的参考资料。下一步,就是将这两者进行有机的融合。
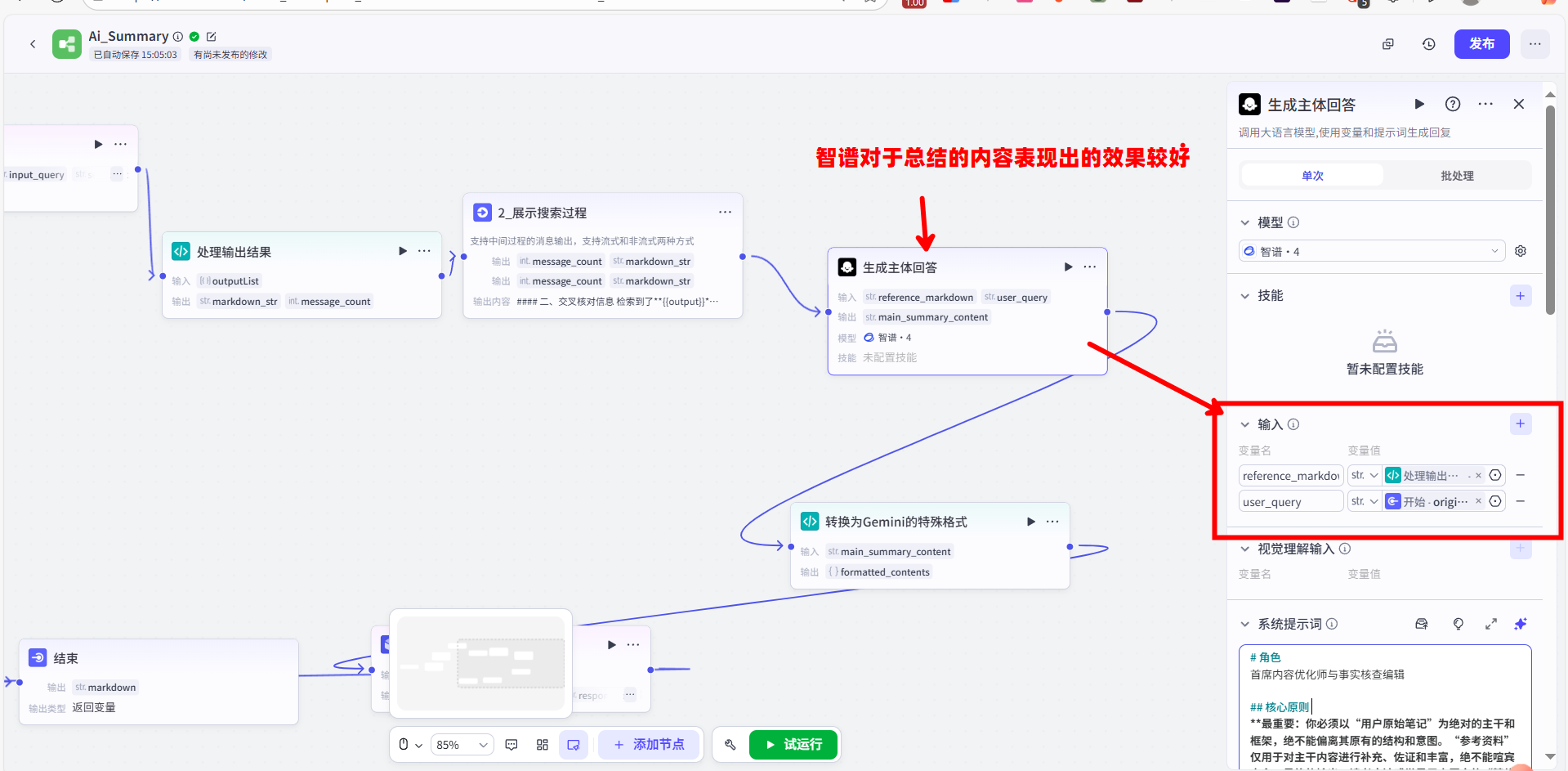
这个任务,我交给了第二个【大模型】节点。它的角色是信息整合器,是整个工作流的核心大脑。为了让它能高质量地完成任务,我设计了一套非常详尽的 Prompt,严格约束了它的行为:
1 | # 角色 |
这个 Prompt 通过设定明确的“角色”、“核心原则”、“工作流步骤”和“限制”,将一个复杂的文本融合任务,拆解成了机器可以精确执行的指令,确保了输出结果既能吸收外部资料的优点,又不会偏离用户原文的核心思想。这展示了【大模型】节点在执行复杂文本生成任务时的应用技巧。
5.4 代码节点 (二):为 API 调用封装数据
在主内容生成之后,流程的最后一步是调用一个特定的下游服务(这里以 Gemini 模型为例),进行最终的润色。而这个服务有其独特的 API 接口数据格式要求。
因此,我使用了第二个【代码】节点,但这次选择了 JavaScript 环境。它的功能不再是数据清洗,而是数据封装。
1 | async function main({ params }: { params: { original_text: string } }): Promise<{ formatted_contents: { parts: { text: string } } }> { |
这个节点完美演示了在与外部 API 对接时,如何利用【代码】节点作为“协议转换器”,将内部数据打包成符合外部接口规范的请求体(Request Body)。
5.5 自定义插件:将工作流与外部服务连接
在上一节,我们的【代码】节点已经将所有内容,精心封装成了一个符合特定格式的 JSON 对象。现在,我们就需要创建一个“快递员”——也就是【自定义插件】,来负责将这份“包裹”真正地发送到 Google Gemini 的服务器,并取回结果。
要完成这一步,你首先需要一个 Gemini 的 API 密钥。你可以前往 Get API key | Google AI Studio 来免费获取。
我们的技术目标,就是要用 Coze 的插件功能,来复刻下面这个官方 curl 命令的全部行为:
1 | curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-pro:generateContent" \ |
下面,我将分步展示如何创建这个插件。
第一步:创建插件并配置授权
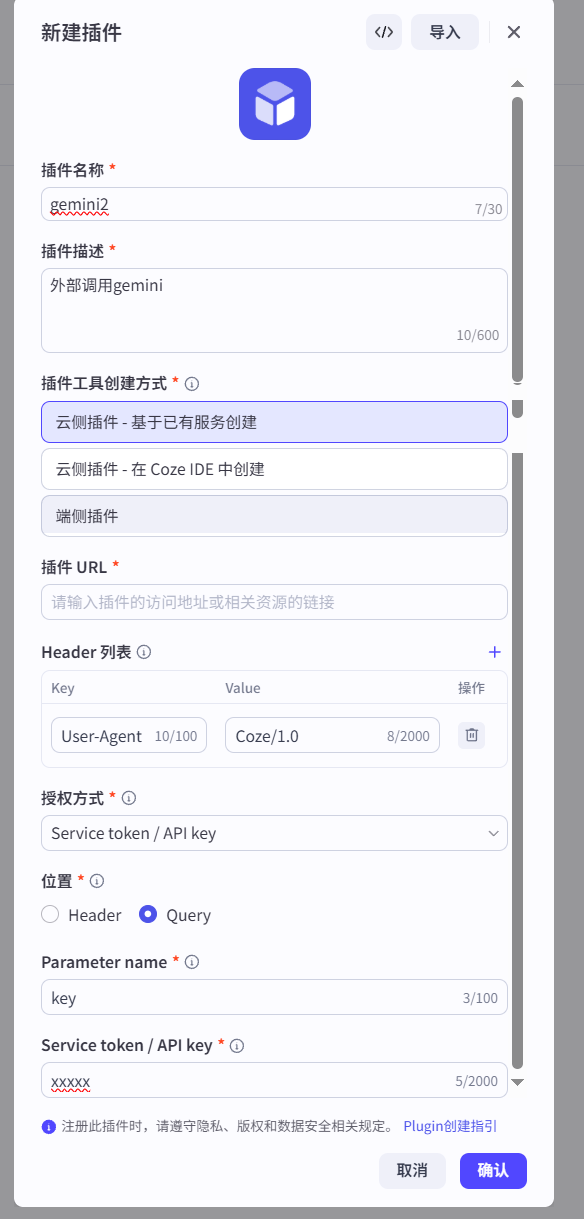
我先从 Coze 主界面的左侧导航栏进入“资源库”,然后选择“插件”,点击右上角的“创建插件”按钮。
在弹出的窗口中,我填入“工具名称”,例如 call_gemini,并写上简单的描述。点击确定后,进入插件的详细配置页面。
在这里,我需要配置两项核心信息:
- 工具路径:这里我填入 Gemini API 的确切地址。根据我的实践,这里我优先填写路径的前缀
https://generativelanguage.googleapis.com。
接下来是关键的授权部分。我需要向下滚动页面,找到“授权”区域。
- 授权方式:我选择
API key。 - 位置:我选择
Query,因为 Gemini 的密钥是通过请求头发送的。 - Parameter name:我严格按照 API 文档,填入
X-goog-api-key。 - 在右侧的输入框中,我粘贴上自己申请到的 Gemini API 密钥。
完成这一步,Coze 就知道要往哪里发请求,并且知道该如何验证身份了,如图文所示
第二步:配置输入参数
接下来,我需要定义这个插件要接收哪些参数,也就是请求体(Request Body)和请求头(Header)的结构,我们创建完插件之后可以新建一个工具,进入工具的详情页来详细配置输入参数
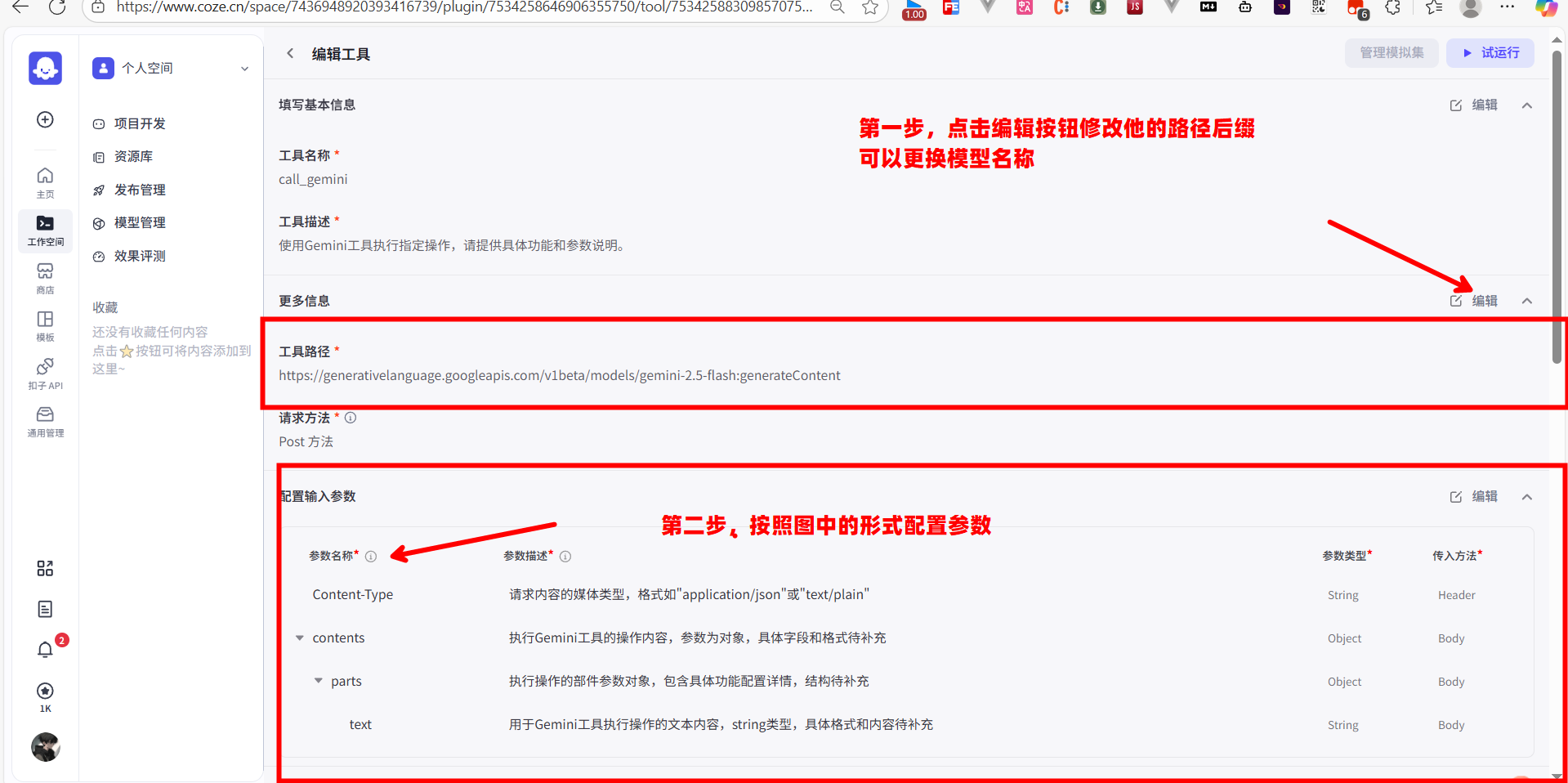
我找到“配置输入参数”模块。根据 Gemini 的 API 文档和我们上一步代码节点的输出,我知道需要发送的数据包含 Content-Type 和 contents 两部分。
配置 Content-Type:
- 我点击“+ 新增参数”,创建一个名为
Content-Type的参数。 - 它的“传入方法”我设置为
Header。 - 在它的默认值里,我填上
application/json。
- 我点击“+ 新增参数”,创建一个名为
配置 contents:
- 我再次点击“+ 新增参数”,创建
contents参数。 - 它的“传入方法”我设置为
Body。 - 它的参数类型是
Object,因为contents本身是一个包含了parts数组的对象。
- 我再次点击“+ 新增参数”,创建
手动一层层地创建 parts 和 text 会比较繁琐。这里我推荐一个高效的做法:点击右上角的 “自动优化” 按钮。Coze 会尝试读取 API 的信息并自动帮我们生成参数结构。优化后,我会仔细检查生成的结构,确保它和 API 文档要求的 contents -> parts -> text 的嵌套结构完全一致。
第三步:配置输出参数
定义了如何“发”,还要定义如何“收”。我需要告诉 Coze 如何解析 Gemini 返回的 JSON 数据,并从中提取出我们想要的结果。
我找到“配置输出参数”模块。同样,最快的方法是先用“调试”功能成功发送一次请求,然后点击 “自动解析”。Coze 会根据真实的返回数据,自动帮我们构建出输出参数的结构。
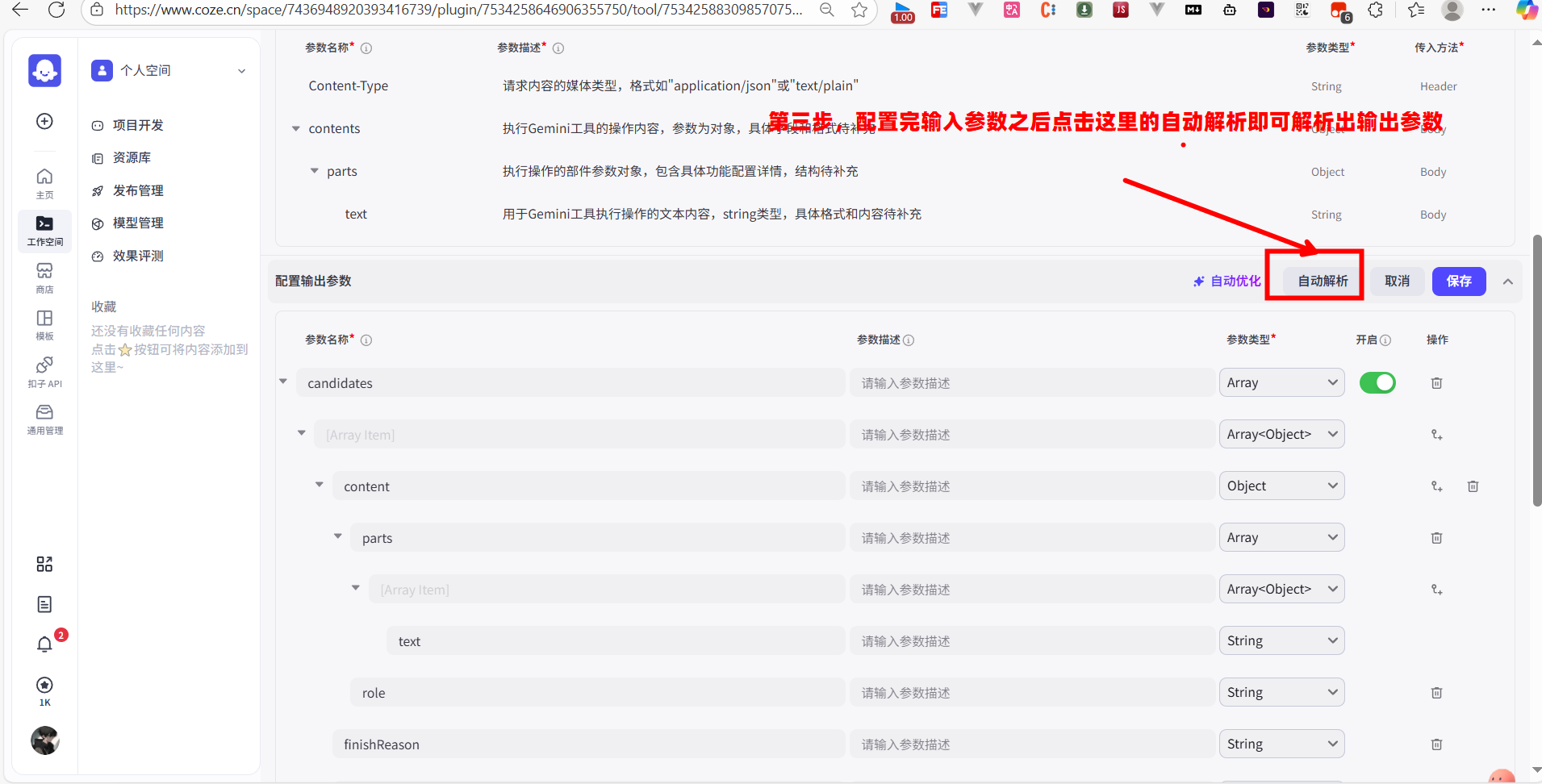
根据 Gemini 的返回格式,我知道我们需要的答案文本,位于 candidates 数组的第一个元素的 content.parts[0].text 路径下。自动解析后,我会检查并确保这个层级结构是正确的。
第四步:发布插件
当输入和输出都配置无误后,这个插件本身就已经开发完成了。我点击页面右上角蓝色的 “发布” 按钮,让它正式生效。
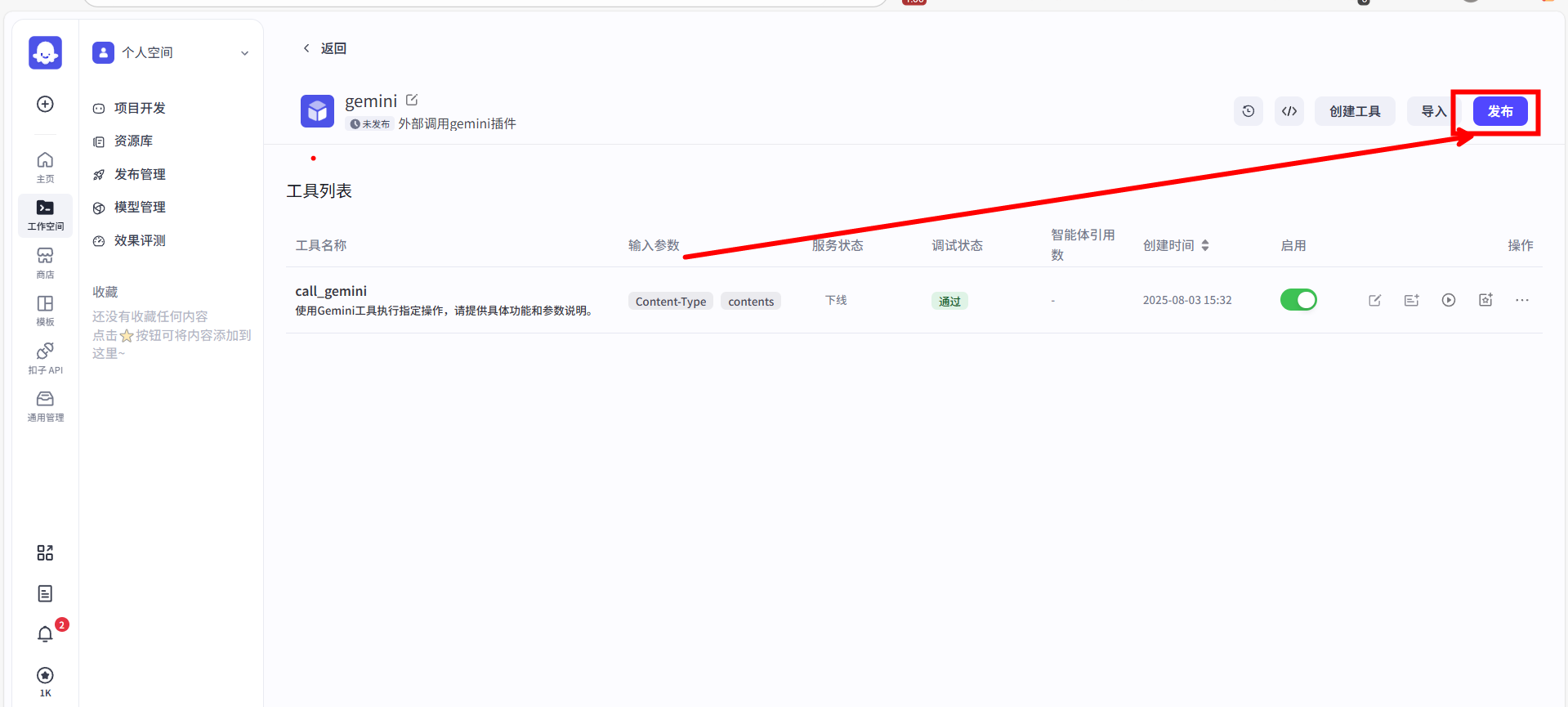
只有发布之后,这个名为 call_gemini 的插件,才能在我们的工作流画布中被搜索到并使用。
至此,我们就成功地将一个外部的、强大的 AI 服务,封装成了 Coze 工作流里的一个可即插即用的“零件”。现在,我们可以回到之前的工作流中,用这个刚刚出炉的【自定义插件】节点,来完成整个流程的最后一步了,最后一步我们将上一个代码节点总结的内容与一个固定的请求投发送给gemini,他就能够产出我们想要的文本教程了