
Prorise
这是我的博客,分享技术与生活的点点滴滴
🔥 建议收藏!2026 全网最全 Claude Code 入门圣经:搞定 DeepSeek 接入 + 掌握 Checkpoint 回滚,这一篇就够了!
🔥 建议收藏!2026 全网最全 Claude Code 入门圣经:搞定 DeepSeek 接入 + 掌握 Checkpoint 回滚,这一篇就够了!
Prorise基础篇:Claude Code 快速上手指南
本篇导读:这不是一份 “看完就忘” 的工具手册,而是一份 “让你真正用起来” 的实战指南。我们会从零开始,手把手带你完成 Claude Code 的安装、配置、第一次对话,以及最重要的——学会如何 “不怕搞砸”。读完本篇,你将具备独立使用 Claude Code 完成日常开发任务的能力,并掌握成本控制的核心技巧。
本篇学习路径
| 阶段 | 认知里程碑 |
|---|---|
| 第一阶段 | 理解 Agentic 编程的本质变化 |
| 第二阶段 | 掌握低成本接入方案,避免费用失控 |
| 第三阶段 | 能完成基础任务,并学会使用回撤 ↩︎ 功能 |
| 第四阶段 | 掌握日常工作流,建立项目规范 |
第一章. 认识 Claude Code - 重新定义编程范式
2024 年底,当我第一次看到 Claude Code 的演示视频时,我的第一反应是:“这不就是个终端版的 ChatGPT 吗?” 但当我真正用它写完第一个项目后,我意识到自己错了,Claude Code 是在国内第一批火的 Coding CIL,以轻量,强大而闻名
1.1. 什么是 Claude Code?
Claude Code 是 Anthropic 推出的一款 终端原生的 Agentic 编程助手。注意这三个关键词:
终端原生:它不是 IDE 插件,不是网页应用,而是直接运行在你的命令行里。这意味着它能无缝使用你的 Git、npm、Python 环境,甚至你自定义的 Shell 别名。
Agentic:这是核心。它不是被动地等你提问,而是能 主动规划、自主执行、持续反思。你给它一个目标,它会自己拆解成多个步骤,执行每一步,检查结果,发现问题就自己修正。
编程助手:它的定位不是 “代码生成器”,而是你的 编程伙伴。它理解你的项目结构、业务逻辑、技术栈,能跨文件修改代码、运行测试、操作数据库。
让我用一个类比来解释这三者的区别:
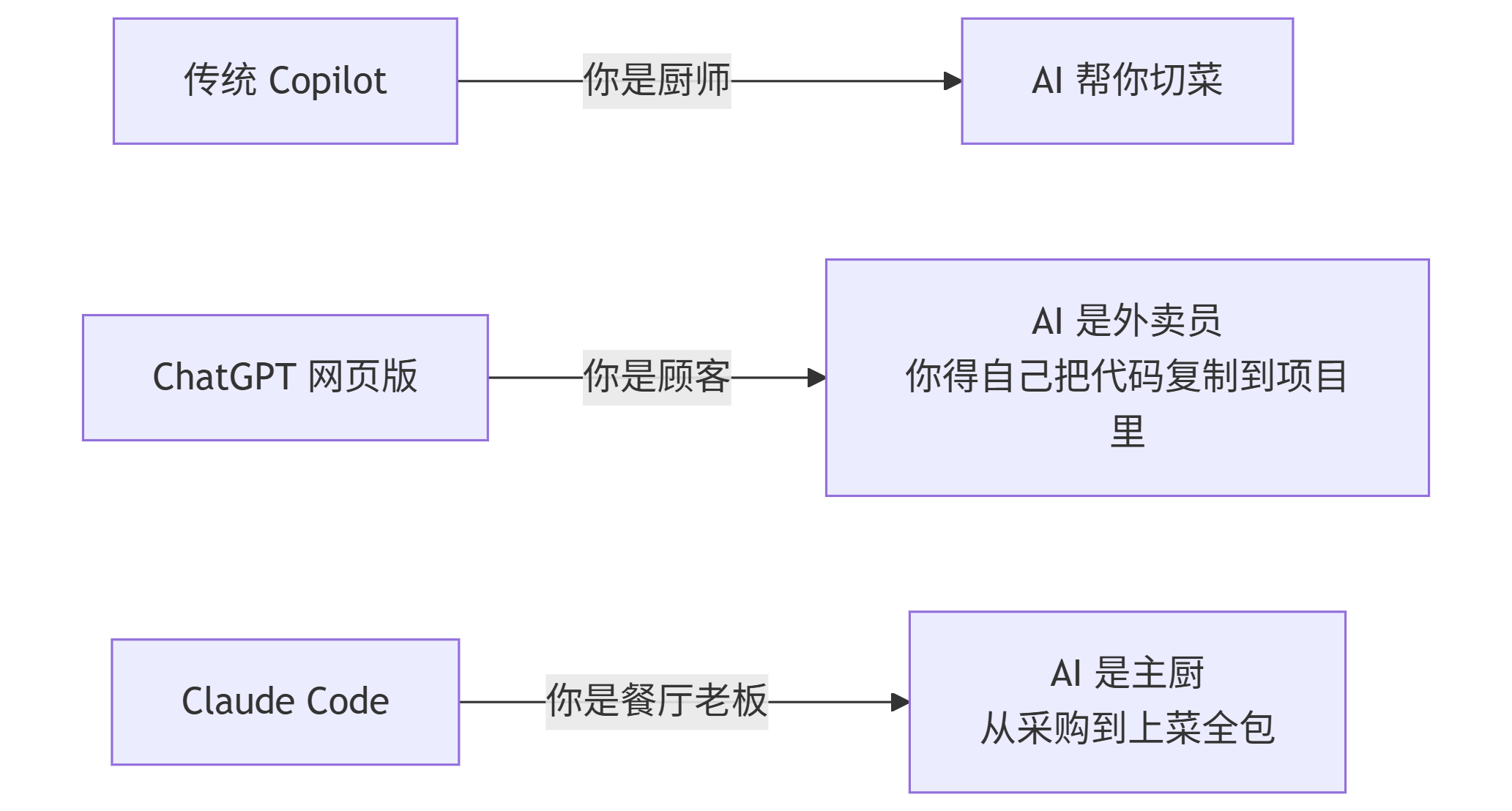
1.2. Agentic 助手 vs 传统 Copilot
很多人会问:“我已经在用 GitHub Copilot 了,为什么还需要 Claude Code?”
答案是:它们解决的是不同层次的问题。
| 维度 | GitHub Copilot | Claude Code |
|---|---|---|
| 工作单位 | 单行代码 / 单个函数 | 完整功能 / 跨文件重构 |
| 交互方式 | 被动补全(你写一半,它补全) | 主动规划(你说目标,它拆解执行) |
| 上下文范围 | 当前文件 + 邻近几行 | 整个项目(200K tokens) |
| 执行能力 | 只生成代码文本 | 能修改文件、运行命令、操作 Git |
| 错误处理 | 你发现错误,你修复 | 它运行测试,发现错误,自己修复 |
举个具体例子。假设你要 “为用户模块添加邮箱验证功能”:
使用 Copilot 的流程:
- 你打开
user.service.js,开始写validateEmail函数 - Copilot 补全函数体
- 你手动去
user.controller.js调用这个函数 - 你手动去
user.test.js写测试 - 你手动运行
npm test - 测试失败,你回去改代码
- 重复 5-6 直到通过
使用 Claude Code 的流程:
- 你在终端输入:
为用户模块添加邮箱验证功能,需要修改 service、controller 和测试文件 - Claude 分析项目结构,提出修改方案
- 你批准后,它自动修改三个文件
- 它自动运行
npm test - 测试失败,它看到错误信息,自动修复代码
- 它再次运行测试,通过后告诉你 “完成”
看出区别了吗?Copilot 是 “辅助你写代码”,Claude Code 是 “替你完成任务”。
1.3. 适用场景与局限性
Claude Code 不是银弹。在决定是否使用它之前,你需要清楚它的边界。
最适合的 5 种场景
| 场景 | 为什么适合 | 典型任务 |
|---|---|---|
| CRUD 业务开发 | 模式固定,AI 训练数据充足 | 用户管理、订单处理、数据报表 |
| 快速原型验证 | 速度优先,代码质量可后期优化 | MVP 产品、黑客松项目、概念验证 |
| 遗留代码重构 | 大上下文能理解整个项目 | 拆分巨型函数、统一命名规范 |
| 测试用例编写 | AI 擅长覆盖边界情况 | 单元测试、集成测试 |
| 文档与配置 | 重复性高,规则明确 | README、API 文档、CI/CD 配置 |
不适合的 3 种场景
| 场景 | 为什么不适合 | 替代方案 |
|---|---|---|
| 高安全要求系统 | AI 可能引入隐蔽漏洞 | 人工逐行审查 + 安全扫描工具 |
| 性能敏感系统 | AI 生成的代码通常不是最优解 | 人工优化 + Profiling 工具 |
| 复杂算法实现 | 需要深度领域知识,AI 容易产生幻觉 | 参考论文 + 人工实现 |
一个重要的认知:Claude Code 的价值不在于 “让不会编程的人能编程”,而在于 “让会编程的人效率倍增”。如果你完全不懂代码,你将无法判断 AI 生成的结果是否正确,也无法在出错时给出有效的修正指令。
1.4. 一人公司为什么需要它
如果你是一个人在做产品,你会面临一个残酷的现实:时间是你唯一的资源,也是最稀缺的资源。
传统开发模式下,一个全栈功能的开发流程是这样的:

总计:23 小时,接近 3 个工作日。
使用 Claude Code 后:

总计:4 小时,效率提升 5.75 倍。
更重要的是,这 4 小时里,你的大部分时间是在 思考和决策,而不是在敲键盘。你的精力被解放出来,可以去做更有价值的事情:
- 思考产品方向
- 优化用户体验
- 规划下一个功能
- 甚至去喝杯咖啡
这就是为什么一人公司需要 Claude Code——它让你从 “全栈工程师” 变成 “全栈指挥官”。
第二章. 环境准备与成本优化配置
在开始之前,我必须先和你聊聊钱的问题。
很多教程会跳过这一步,直接让你 “注册官方 API,开始使用”。但对于一人公司来说,成本控制是生死线。如果你不了解各种方案的成本差异,很可能在不知不觉中烧掉几百美元。
本章我会详细讲解三种 API 接入方案,确保你在享受 AI 编程便利的同时,不会因为费用失控而焦虑。
2.1. 系统要求检查
在安装 Claude Code 之前,请确认你的系统满足以下要求:
操作系统
- macOS 10.15+
- Linux(Ubuntu 20.04+ 或其他现代发行版)
- Windows 10/11(已在最新版本中适配)
软件依赖
- Node.js:v18.0 或更高版本,详细见:NVM 版本管理:Node.js 保姆级图文下载教程 | Prorise - 博客小栈
- Git:强烈建议安装,以便 Claude Code 能够执行版本控制操作,详细见:第一章. 小白也会:Windows Git 环境搭建全流程(含 P4Merge) | Prorise - 博客小栈
网络
- 稳定的互联网连接(用于与 API 通信)
- 如果在国内,需要配置代理(稍后详细讲解)
2.2. 安装 Claude Code
确认系统要求后,我们开始安装 Claude Code。
使用 NPM 全局安装(推荐)
1 | npm install -g @anthropic-ai/claude-code |
安装过程可能需要 1-2 分钟,取决于你的网络速度。
验证安装
安装完成后,运行以下命令验证:
1 | claude --version |
如果输出类似 2.0.76 (Claude Code),说明安装成功。
方案三:低成本中转站(闲鱼 / Linux.do)
适用场景:你想用 Claude 官方模型,但预算极其有限。
什么是中转站?
中转站是一些个人或小团队搭建的 API 代理服务。他们批量购买官方 API 额度,然后以更低的价格转售。
常见的中转站来源
| 平台 | 特点 | 价格范围 | 风险 |
|---|---|---|---|
| 闲鱼 | 个人卖家多,价格最低 | $0.5-1/百万 Token | 稳定性差,可能跑路 |
| Linux.do | 社区公益性质 | 免费或极低价 | 需要贡献值,有配额限制 |
| 第三方平台 | 商业化运营 | $1-2/百万 Token | 相对稳定,但仍有风险 |
配置步骤
假设你从闲鱼购买了一个中转 API Key(格式类似 sk-xxx)和中转地址(如 https://api.example.com)。
创建配置文件 ~/.claude/config.json:
1 | { |
安全警告:使用中转站存在以下风险
- 数据泄露:你的代码会经过中转服务器,可能被记录
- 服务中断:卖家可能随时跑路,导致服务不可用
- 账号封禁:如果中转站滥用官方 API,可能导致你的请求被封
建议:仅在个人学习项目中使用,商业项目请使用官方或国产模型。
第三章. 你的第一个 Claude Code 会话
环境配置完成,现在是最激动人心的时刻——启动 Claude Code,完成你的第一次对话。
但在此之前,我要先教你一个最重要的技能:如何 “后悔”。
3.1. 启动与交互界面
进入项目目录
Claude Code 需要在项目根目录下运行,这样它才能理解你的项目结构。
启动 Claude Code
1 | claude |
启动后,你会看到一个交互式提示符:
这个 › 就是你的输入提示符,类似于 Shell 的 $ 或 >。
3.2. 第一个任务:让 Claude 理解你的项目
在让 Claude 写代码之前,最好先让它 “读一遍” 你的项目,建立上下文。
输入你的第一个指令
1 | /init |
Claude 会开始扫描你的项目文件,分析 package.json、README.md、目录结构等,然后给出一个摘要,摘要通常来说叫做“Claude.md”
3.3. 第一次代码修改
现在让我们给 Claude 一个具体的编码任务。
下达指令
1 | › 创建一个简单的 Express 服务器,监听 3000 端口,有一个 GET /hello 接口返回 "Hello, Claude!" |
Claude 的响应流程
Claude 会经历以下几个步骤:
步骤 1:规划
1 | 我将执行以下操作: |
步骤 2:等待你的批准
这是 Claude Code 的核心安全机制——任何会修改文件或执行命令的操作,都需要你明确批准。
输入 y 并回车。
步骤 3:执行操作
1 | ✓ 执行命令:npm install express |
步骤 4:验证结果
按照 Claude 的提示,运行服务器:
1 | npm start |
打开浏览器访问 http://localhost:3000/hello,你应该能看到 Hello, Claude!。
生成的代码
让我们看看 Claude 生成的 server.js:
代码简洁、清晰,符合 Express 的最佳实践。
3.4. 第一次 “后悔”:Checkpoints 与 Rewind
现在是最重要的部分——学会如何 “后悔”。
假设你刚才让 Claude 修改了代码,但运行后发现不符合预期,或者你只是想尝试另一种实现方式。传统方式下,你需要手动 git reset 或者 Ctrl+Z 撤销。
但 Claude Code 提供了更强大的机制:Checkpoints(检查点)。
3.4.1. 为什么需要 “后悔药”
在 AI 编程中,你会经常遇到这些情况:
- Claude 理解错了你的需求,生成的代码完全不对
- 你想尝试两种不同的实现方案,看哪个更好
- Claude 在重构过程中不小心删除了重要代码
- 你批准了一个操作后,突然意识到不应该这样做
如果没有 “后悔药”,你只能:
- 手动恢复文件(如果你记得改了什么)
- 从 Git 历史中恢复(如果你提交过)
- 重新开始整个会话
这些方法都很低效,而且容易出错。
3.4.2. 创建检查点
什么是 Checkpoint?
Checkpoint 是 Claude Code 的 “存档点”。它会保存:
- 当前所有文件的状态
- 当前的对话历史
- 当前的上下文信息
你可以随时回到任何一个 Checkpoint,就像游戏中的 “读档”。
创建你的第一个 Checkpoint
在刚才创建完 Express 服务器后,我们创建一个检查点:
1 | › /checkpoint create "初始 Express 服务器" |
Claude 会回复:
1 | ✓ 检查点已创建:checkpoint_001 |
最佳实践:在每次完成一个完整功能后,立即创建 Checkpoint。这样即使后续出错,也能快速回到稳定状态。
3.4.3. 回滚操作:Rewind
现在让我们故意 “搞砸” 一些东西,然后用 Rewind 恢复。
故意破坏代码
1 | 把 server.js 里的所有代码都删除,只保留一行注释 "// TODO" |
现在 server.js 变成了:
1 | // TODO |
服务器当然无法运行了。
使用 Rewind 恢复
1 | › /rewind |
Claude 会显示可用的检查点:
1 | 可用的检查点: |
输入 1 并回车。
1 | ✓ 正在恢复到检查点:checkpoint_001 |
打开 server.js,你会发现代码完好无损,就像刚才的破坏从未发生过。
3.4.4. Checkpoint 的高级用法
列出所有检查点
1 | › /checkpoint list |
删除检查点
1 | › /checkpoint delete checkpoint_001 |
自动检查点
你可以配置 Claude Code 在每次执行重要操作前自动创建检查点。编辑 ~/.claude/settings.json:
1 | { |
这样,每次 Claude 修改文件或执行命令前,都会自动创建检查点,最多保留 10 个。
Checkpoint vs Git
| 对比项 | Checkpoint | Git |
|---|---|---|
| 速度 | 极快(秒级) | 较慢(需要 commit) |
| 粒度 | 细(每个操作) | 粗(手动提交) |
| 范围 | 文件 + 对话历史 | 仅文件 |
| 持久性 | 会话级(关闭后清除) | 永久 |
| 适用场景 | 实验性修改、快速试错 | 正式版本管理 |
重要提醒:Checkpoint 不是 Git 的替代品。它只在当前会话中有效,关闭 Claude Code 后会清除。对于重要的代码变更,仍然需要使用 Git 提交。
3.4.5. 实战:撤销一次错误的重构
让我们通过一个真实场景,体会 Checkpoint 的价值。
场景:你想重构 server.js,将路由逻辑提取到单独的文件中。
步骤 1:创建检查点
1 | › /checkpoint create "重构前的稳定版本" |
步骤 2:下达重构指令
1 | › 将 /hello 路由提取到 routes/hello.js 文件中,并在 server.js 中引入 |
步骤 3:Claude 执行重构
Claude 创建了 routes/hello.js,修改了 server.js。
步骤 4:测试发现问题
你运行 npm start,发现服务器报错:
1 | Error: Cannot find module './routes/hello' |
原来 Claude 在 server.js 中写的路径是 ./routes/hello,但实际文件在 routes/hello.js。
步骤 5:快速回滚
与其让 Claude 修复这个小错误,不如直接回滚,重新描述需求:
1 | › /rewind |
选择 “重构前的稳定版本”,瞬间恢复。
步骤 6:重新下达更明确的指令
1 | › 将 /hello 路由提取到 routes/hello.js 文件中。 |
这次 Claude 生成的代码就正确了。
总结
Checkpoint 让你可以 大胆尝试,因为你知道随时可以回到安全状态。这极大地降低了使用 AI 编程的心理负担。
第四章. 核心命令与日常工作流
掌握了基础的对话和 “后悔药” 后,现在我们需要系统学习 Claude Code 的核心命令,建立高效的日常工作流。
4.1. CLI 命令速查
Claude Code 提供了丰富的命令行参数,用于不同的使用场景。
基础命令
| 命令 | 功能 | 使用场景 |
|---|---|---|
claude | 启动交互式会话 | 日常开发 |
claude "问题" | 单次查询后退出 | 快速获取答案 |
claude -p "问题" | 非交互式打印模式 | 脚本集成 |
claude -c | 继续上次会话 | 延续之前的任务 |
claude --version | 查看版本 | 检查更新 |
模型选择
1 | # 使用 Opus 模型(更强但更贵) |
上下文管理
1 | # 添加额外的目录到上下文 |
非交互式模式
1 | # 查询后直接打印结果 |
实用示例
1 | # 在 CI/CD 中使用 Claude 生成 changelog |
4.2. 交互模式核心功能
进入交互模式后,有一些快捷键和技巧能大幅提升效率。
快捷键速查
| 快捷键 | 功能 | 说明 |
|---|---|---|
| Ctrl + C | 取消当前操作 | 中断 Claude 的生成 |
| Ctrl + D | 退出会话 | 等同于输入 exit |
| Ctrl + L | 清屏 | 保留对话历史 |
| ↑ / ↓ | 导航历史命令 | 类似 Shell 的历史记录 |
| ESC ESC | 编辑上一条消息 | 修改刚发送的内容 |
多行输入
默认情况下,按 Enter 会立即发送消息。如果你想输入多行内容,有两种方式:
方式一:使用反斜杠(通用,所有终端都支持)
1 | › 请帮我写一个函数:\ |
方式二:使用 Shift + Enter(需要配置)
运行 /terminal-setup 命令配置终端,之后就可以用 Shift + Enter 换行。
编辑已发送的消息
有时候你发送消息后,发现有错别字或者想补充内容。传统方式下,你只能重新输入。但 Claude Code 允许你编辑已发送的消息。
连按两次 ESC 键,会进入编辑模式,显示你上一条消息的内容。修改后按 Enter 重新发送。
粘贴图片(实验性功能)
如果你配置了图片支持,可以用 Ctrl + V 粘贴剪贴板中的截图,让 Claude 分析。
1 | › 我粘贴了一张设计稿,请帮我用 HTML + CSS 实现 |
注意:图片功能在 Windows 原生终端中支持度不高。推荐使用 Claude Workbench 可视化工具。
4.3. 斜杠命令(/ Commands)
斜杠命令是 Claude Code 的 “内置工具箱”。输入 / 后按 Tab 键,会显示所有可用命令。
核心斜杠命令
| 命令 | 功能 | 使用场景 |
|---|---|---|
/help | 查看所有命令 | 忘记命令时 |
/clear | 清空对话历史 | 开始新任务 |
/add-dir <path> | 添加目录到上下文 | 引用其他模块 |
/compact | 压缩对话历史 | 对话太长时 |
/checkpoint create | 创建检查点 | 保存当前状态 |
/rewind | 回滚到检查点 | 撤销错误操作 |
/memory | 编辑项目记忆 | 修改 CLAUDE.md |
上下文管理命令详解
/clear - 清空对话历史
当你准备开始一个全新的任务时,使用此命令清空所有历史记录和上下文。
1 | › /clear |
何时使用 /clear?
- 切换到完全不同的任务
- 对话轮次超过 20 轮,Claude 开始 “遗忘” 早期内容
- 你发现 Claude 的回复受到了之前错误信息的 “污染”
/add-dir - 添加额外目录
默认情况下,Claude 只能访问当前项目目录。如果你需要引用其他目录的文件,使用此命令。
1 | › /add-dir ../shared-utils |
/compact - 压缩对话历史
当对话历史变得很长,但你又不想完全清空时,此命令会智能地总结之前的对话,保留关键信息。
1 | › /compact |
Claude 会生成一个摘要,类似于:
1 | 已压缩对话历史。保留的关键信息: |
高级技巧:你可以将压缩后的摘要保存为自定义命令,方便后续调用。
/memory - 编辑项目记忆
这个命令会打开 CLAUDE.md 文件(项目的 “宪法”),让你编辑项目的长期记忆。
1 | › /memory |
会在默认编辑器中打开 CLAUDE.md。保存后,Claude 会重新加载这些规则。
快捷方式:在输入内容的开头使用 #,该行文本会自动追加到 CLAUDE.md。
1 | › # 所有 API 接口必须返回统一的 JSON 格式:{ data, error, meta } |
这行内容会被添加到 CLAUDE.md 的末尾。
4.4. 权限管理入门
权限管理是 Claude Code 的核心安全机制。理解它的工作原理,能让你在享受自动化的同时,保持对项目的完全控制。
4.4.1. 三种权限模式
Claude Code 支持三种执行模式:
| 模式 | 行为 | 适用场景 |
|---|---|---|
| manual(手动) | 每个操作都需要你输入 y 确认 | 默认模式,最安全 |
| auto(自动) | 命令自动执行,无需确认 | 你完全信任 Claude 的计划时 |
| plan(规划) | 只输出计划,不执行任何操作 | 头脑风暴、任务拆解 |
切换模式
1 | # 切换到自动模式 |
警告:自动模式虽然方便,但存在风险。Claude 可能会执行你不期望的操作(如删除文件、修改配置)。建议仅在小范围实验时使用,生产环境请保持手动模式。
4.4.2. 理解权限提示
当 Claude 需要执行操作时,会显示一个权限提示:
1 | 我将执行以下操作: |
选项说明
| 选项 | 含义 | 结果 |
|---|---|---|
y | Yes,批准执行 | Claude 执行所有操作 |
n | No,拒绝执行 | Claude 取消操作,等待新指令 |
d | Details,查看详情 | 显示每个操作的具体内容 |
查看详情(d 选项)
如果你不确定 Claude 要做什么,输入 d 查看详细信息:
1 | 操作 1 详情: |
4.4.3. 常见权限场景
场景一:Claude 想删除文件
1 | 我将执行以下操作: |
你应该怎么做?
输入 d 查看详情,确认这是你想要的操作。如果只是想重新安装依赖,更安全的做法是:
1 | › 不要删除 node_modules,直接运行 npm install 更新依赖 |
场景二:Claude 想执行 Git 操作
1 | 我将执行以下操作: |
你应该怎么做?
如果你还没有检查代码,不要批准。输入 n,然后:
1 | › 只执行 git add 和 git commit,不要 push |
场景三:Claude 想修改配置文件
1 | 我将执行以下操作: |
你应该怎么做?
.env 文件通常包含敏感信息。输入 d 查看详情,确认数据库 URL 是否正确。如果不对,输入 n 并重新描述:
1 | › 修改 .env,但数据库 URL 应该是 postgresql://localhost:5432/production_db |








