
Prorise
这是我的博客,分享技术与生活的点点滴滴
🍺 SillyTavern(酒馆)- 世界树与RAG——为什么你的 AI 总是 "金鱼脑"?一文带你理解如何处理酒馆持久化记忆存储
🍺 SillyTavern(酒馆)- 世界树与RAG——为什么你的 AI 总是 "金鱼脑"?一文带你理解如何处理酒馆持久化记忆存储
Prorise第一章. 记忆的解剖学——为什么你的 AI 总是 “金鱼脑”?
本章摘要:我们将从一个真实的痛点场景出发,建立起 “三层记忆金字塔” 的认知框架,理解为什么 128k 的超长上下文依然无法解决 AI “健忘” 的问题。
| 技术组件 | 版本/要求 | 说明 |
|---|---|---|
| SillyTavern | 1.12.0+ | 需支持 Data Bank 扩展 |
| DeepSeek API | V3 | 主力对话模型 |
| 智谱 AI API | embedding-2/3 | Embedding 向量化模型 |
| 操作系统 | Windows/macOS/Linux | 均可 |
本章学习路径:
| 阶段 | 内容 | 学习目标 |
|---|---|---|
| 认知建立 | 痛点复现 | 理解 “重复造轮子” 的根本原因 |
| 框架构建 | 三层记忆金字塔 | 掌握 L1/L2/L3 的定位与边界 |
| 概念辨析 | 触发式 vs 检索式 | 区分 World Info 与 RAG 的本质差异 |
1.1. 痛点复现:那个 “重复造轮子” 的下午
在 Note 02 中,我们亲手打造了一位 “博文写作专家”。它能够按照我们定义的 12 条铁律输出高质量的技术文章,表现堪称惊艳。
但当我们真正把它投入日常写作时,一个令人抓狂的问题开始浮现。
想象这样一个场景:你已经用这位专家写了 9 篇系列博文。每一篇的开头,你都会贴上项目的技术栈版本表、你的个人写作风格指南、以及一份 “禁止使用的词汇清单”。到了第 10 篇,你满怀期待地开启新对话,输入:
“继续写第十篇,主题是 Redis 缓存优化。”
AI 的回复让你血压飙升:
“好的,请问您希望使用什么样的写作风格?目标读者是谁?有没有需要遵守的格式规范?”
它全忘了。
那份你精心打磨了三个小时的 “风格指南”,那张包含 JDK 17、Spring Boot 3.2、Redis 7.0 的版本表,那个 “严禁使用’小编’一词” 的禁令——统统消失在数字的虚空中。
你不得不再次打开那份 Word 文档,复制,粘贴,然后看着 AI 像第一次见面一样,重新 “学习” 这些它本应烂熟于心的规则。
这不是 AI 的错,也不是你的错。这是 架构的局限。
聊天记录本质上是一条 “时间线”。每一轮对话结束,这条时间线就被封存。当你开启新对话时,AI 面对的是一张白纸。它不知道你是谁,不知道你在做什么项目,更不知道你对 “的地得” 的使用有着近乎偏执的坚持。
128k 的上下文窗口确实很大,大到可以塞进一整本《哈利·波特》。但问题在于:你不可能每次开工前,都把整本 “项目百科全书” 手动粘贴进去。
我们需要的,是一种让 AI 能够 跨对话、跨时间 持续记住关键信息的机制。
这就是本章要解决的核心问题:如何给 AI 装上一颗真正的 “海马体”?
1.2. 三层记忆金字塔:AI 的认知架构
为了解决 “金鱼脑” 问题,我们需要先理解 AI 的记忆是如何工作的。在 SillyTavern 的体系中,存在一个清晰的 三层记忆金字塔 模型。
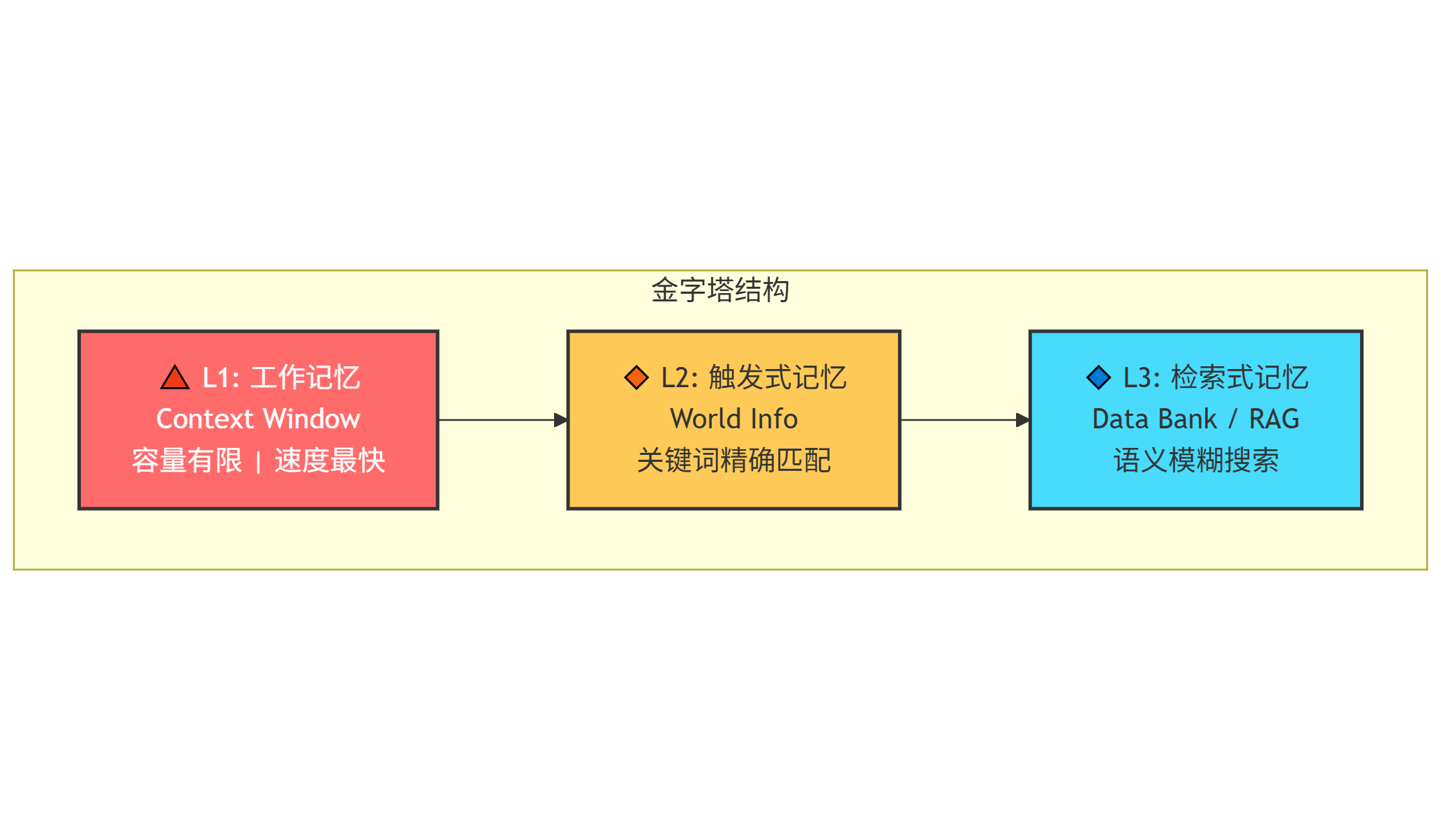
1.2.1. 塔尖 (L1):工作记忆——你的办公桌
工作记忆 对应的是 AI 的 Context Window(上下文窗口)。
想象你正坐在一张办公桌前。桌上摊开的文件、便签、正在编辑的文档——这些就是你的 “工作记忆”。它们触手可及,你可以立刻引用、修改、回应。
DeepSeek V3 的上下文窗口是 128k tokens,大约相当于 10 万个汉字,或者一本中等厚度的小说。这张 “办公桌” 已经足够宽敞。
但办公桌有两个致命缺陷:
- 面积有限:再大的桌子也有边界。当对话越来越长,最早的内容会被 “推下桌面”,彻底遗忘。
- 关机即清空:每次你离开办公室(结束对话),保洁阿姨会把桌上的一切收拾得干干净净。第二天你回来,桌面空空如也。
工作记忆是 AI 思考的 “主战场”,但它不是用来 “存储” 的地方。
1.2.2. 塔中 (L2):触发式记忆——你的随身便签本
触发式记忆 对应的是 SillyTavern 的 World Info(世界信息/世界书) 功能。
想象你随身携带一本便签本。每一页都贴着一个标签:张三、项目A、Redis配置。当有人提到 “张三”,你立刻翻到那一页,把相关信息调出来。
World Info 的工作原理完全一致:
- 你预先定义一系列 关键词(Keys) 和对应的 内容(Content)。
- 当对话中出现这些关键词时,系统自动把对应内容 “注入” 到 AI 的上下文中。
举个例子:
| 关键词 | 内容 |
|---|---|
我的风格, 品牌调性 | 语气幽默、禁用 “小编”、结尾必须有互动引导 |
技术栈版本 | JDK 17, Spring Boot 3.2, Redis 7.0 |
当你说 “用我的风格写一段介绍”,系统检测到关键词 我的风格,自动把风格规范塞进 AI 的 “办公桌” 上。AI 看到了这份规范,自然就会遵守。
L2 的核心特征是 “精确触发”:你必须明确知道自己要用什么关键词,系统才会响应。它像一本索引清晰的字典,但你得先知道要查哪个词。
1.2.3. 塔底 (L3):检索式记忆——地下档案室的管理员
检索式记忆 对应的是 RAG(Retrieval-Augmented Generation,检索增强生成) 技术,在 SillyTavern 中主要通过 Data Bank 扩展实现。
想象你公司有一个巨大的地下档案室,里面存放着过去十年的所有项目文档、会议纪要、技术规范。你不可能记住每一份文件的名字和位置。
但档案室有一位神奇的管理员。你只需要说:“帮我找找去年那个关于服务器报错的处理方案”,管理员就能凭借 语义理解,从成千上万份文件中找出最相关的几份,送到你的办公桌上。
这就是 RAG 的工作方式:
- 预处理阶段:把你的文档 “翻译” 成一串串数字(向量),存入向量数据库。
- 检索阶段:当你提问时,系统把问题也 “翻译” 成向量,然后在数据库中寻找 “数字上最接近” 的内容。
- 生成阶段:把检索到的内容塞进 AI 的上下文,让 AI 基于这些 “参考资料” 生成回答。
L3 的核心特征是 “模糊搜索”:你不需要知道确切的关键词,只要描述你的需求,系统就能通过语义相似度找到相关内容。它像一位理解你意图的图书管理员,而不是一本死板的索引。
1.2.4. 三层协作:完整的认知闭环
理解了三层记忆的定位,我们就能看清它们是如何协作的:
| 层级 | 名称 | 触发方式 | 容量 | 典型用途 |
|---|---|---|---|---|
| L1 | 工作记忆 | 自动(当前对话) | 128k tokens | 即时对话、推理思考 |
| L2 | 触发式记忆 | 关键词精确匹配 | 数十条规则 | 风格规范、人物设定、术语表 |
| L3 | 检索式记忆 | 语义模糊搜索 | 数百份文档 | 项目文档、技术手册、历史记录 |
一个典型的工作流程是这样的:
- 你提问:“帮我写一篇关于 Redis 缓存穿透的文章,参考知识库里的资料,用我的风格。”
- L3 介入:系统根据 “Redis 缓存穿透” 这个语义,从 Data Bank 中检索出 3 份相关文档。
- L2 介入:系统检测到关键词 “我的风格”,从 World Info 中提取风格规范。
- L1 工作:DeepSeek 拿到
[你的问题] + [L3 的参考文档] + [L2 的风格规范],在工作记忆中完成推理,输出最终文章。
这就是 “海马体” 的完整架构。接下来的章节,我们将逐层实操,把这套系统真正搭建起来。
1.3. 本节小结
本章我们从一个真实的痛点场景出发,建立了理解 AI 记忆系统的认知框架。
| 核心概念 | 要点 |
|---|---|
| 金鱼脑问题 | 聊天记录是时间线,新对话 = 白纸一张 |
| L1 工作记忆 | 办公桌,容量有限,关机清空 |
| L2 触发式记忆 | 便签本,关键词精确匹配 |
| L3 检索式记忆 | 档案室管理员,语义模糊搜索 |
| 协作模式 | L3 检索 → L2 注入 → L1 生成 |
第二章. L1 实操——大模型基准对话实操
本章摘要:在 DeepSeek V3 普及 128k 上下文的时代,单纯 “拉大滑块” 只是第一步。本章将教你如何正确配置上下文策略,避免 “垃圾进垃圾出” (Garbage In, Garbage Out),并利用 DeepSeek 的原生缓存机制实现越聊越快。
本章学习路径:
| 阶段 | 内容 | 学习目标 |
|---|---|---|
| 基础配置 | 突破 4k 限制 | 正确设置 Context Limit 与 Response Length |
| 进阶策略 | 上下文清洗 | 学会使用 Token Budget (预算) 管理 |
| 机制解析 | 原生缓存 | 理解 DeepSeek 如何自动省钱加速 |
2.1. 突破限制:从 “省着用” 到 “大胆用”
在 GPT-4 时代,我们习惯了精打细算,生怕多发一段代码就爆 token。但在 DeepSeek 面前,这种习惯需要改变。
2.1.1. 为什么要拉满 64k+?
SillyTavern 默认的 Context Limit 通常保守地设为 4096 或 8192。对于简单的聊天够用,但对于 “博文写作专家” 这种生产力场景,这远远不够。
想象你的工作台只有课桌那么大。当你写第 10 篇博文时,为了放下新的参考资料,SillyTavern 被迫把第 1 篇博文的设定资料 “扔进碎纸机”(从上下文头部截断)。这就是为什么 AI 聊久了会 “失忆”。
将 Context Limit 拉升至 64k (65536) 甚至 100k,意味着给 AI 换了一张 10 米长的会议桌。你可以把整个项目的代码、之前所有的文章草稿、甚至整本技术手册都摊在桌上,AI 随时都能看见。
2.1.2. 关键配置动作
- 解锁上限:点击顶部 滑块图标 🎛️,勾选 “Unlock Context Size” (解锁上下文长度)。
- 设定数值:拖动滑块或直接输入数值。推荐设置为 65536。
- 为什么要留余量? 虽然 DeepSeek 支持 128k,但预留一半空间可以防止极端情况下的计算溢出,且 64k 对绝大多数任务已是绰绰有余。
- 同步调整回复长度:别忘了把 Response Length 拉到 4000+。否则桌子再大,AI 每次也只能写个 500 字的开头。
2.2. 进阶策略:防止 “上下文污染”
拥有了巨大的工作台,新手最容易犯的错误就是:什么垃圾都往上堆。
如果你把无关的闲聊、错误的尝试代码、过期的文档都留在上下文里,AI 的注意力会被分散,输出质量会显著下降。这就是 Garbage In, Garbage Out。
我们需要学会 “清理桌面”。
善用 “Scrubbing” (清洗) 功能
SillyTavern 提供了一个被 90% 用户忽略的神器:Scrubbing。
- 场景:你让 AI 写一段代码,它写错了。你指正,它改了又错。经过 5 轮拉锯战,终于对了。
- 问题:这 5 轮错误的尝试依然留在上下文里,占用空间且干扰 AI(它可能会模仿之前的错误写法)。
- 操作:
- 在对话气泡上,找到 删除 (垃圾桶) 或 编辑 (铅笔) 图标。
- 直接删除 那些无效的中间过程。
- 或者使用 编辑 功能,把 AI 错误的回复直接改成正确的代码。
专家建议:保持上下文的 “纯净度” 比单纯追求长度更重要。在长对话中,养成随手删除无效对话的习惯,你的 AI 会越来越聪明。
第三章. L2 实操——酒馆世界书详解
本章摘要:我们将学习 World Info(世界信息)功能,为博文专家创建一本 “个人品牌指南”,实现风格规范的自动注入,告别每次对话都要重复粘贴的痛苦。
本章学习路径:
| 阶段 | 内容 | 学习目标 |
|---|---|---|
| 概念理解 | World Info 原理 | 理解关键词触发机制 |
| 实操创建 | 第一本世界书 | 掌握创建和配置流程 |
| 绑定测试 | 与角色关联 | 验证触发效果 |
在上一章中,我们把 L1 工作记忆的潜力榨干了。但 L1 有一个无法回避的问题:它是 “易失性” 的。每次开启新对话,办公桌都会被清空。
那些你希望 AI “永远记住” 的东西——写作风格、术语规范、项目参数——不应该每次都手动粘贴。它们应该像 “随身便签本” 一样,在需要的时候自动出现。
这就是 World Info 的用武之地。
3.1. 什么是 World Info?
World Info(世界信息),有时也被称为 “世界书” 或 “知识库”,是 SillyTavern 提供的一种 关键词触发式记忆系统。
它的工作原理非常直观:
- 你预先定义一系列 条目(Entry),每个条目包含 关键词(Keys) 和 内容(Content)。
- 当对话中出现某个关键词时,系统自动把对应的内容 “注入” 到 AI 的上下文中。
- AI 看到了这些内容,就会据此调整自己的行为。
举个例子:
你创建了一个条目:
- 关键词:
我的风格、品牌调性 - 内容:
语气要幽默接地气,严禁使用"小编"一词,结尾必须有互动引导。
当你在对话中说 “用我的风格写一段话”,系统检测到关键词 我的风格,自动把那段内容塞进 AI 能看到的地方。AI 读到了这个要求,输出的内容自然就会符合你的风格规范。
关键认知:World Info 是 “精确触发” 的。你必须使用预设的关键词,系统才会响应。它不会 “猜测” 你的意图。
3.2. 创建你的第一本世界书
在 Note 02 中,我们给 AI 设定了一个“博文写作专家”的身份。但仅有人设是不够的,我们需要给它装入一套厚重的 “教学法典”。
这本世界书将不再仅仅是简单的“个人品牌指南”,我们将它升级为 Edu_Core_OS (教育核心操作系统)。它包含了你作为技术教育者的思维模式、行为铁律和排版审美。
3.2.1. 打开 World Info 管理界面
步骤 1:点击地球仪图标
在 SillyTavern 顶部工具栏中,找到并点击 地球仪图标 🌐。这是通往 AI “长期记忆库”的大门。
步骤 2:进入管理面板
点击后会打开 World Info 管理面板。这里就像一个书架,列出了你创造的所有知识库。
3.2.2. 创建新世界书
步骤 1:点击创建按钮
在下拉菜单旁边,找到 + 号按钮(Create New World Info),点击它。
步骤 2:命名世界书
在弹出的对话框中,输入一个更有分量的名字:
1 | Tech_Educator_Manifesto |
(技术教育者宣言) —— 这个名字代表了这不仅仅是格式规范,更是教育者的灵魂。
步骤 3:确认创建
点击确认后,一本空白的世界书就创建好了。接下来,我们希望根据为大模型设计的提示词中从中抽离关键点,以我的提示词为例
3.3. 构建核心规则库
世界书的核心是 条目(Entry)。我们在 Note 02 中精心打磨的那份《技术教育者宣言》,如果一股脑塞进一个格子里,AI 很可能会 “消化不良”——要么顾此失彼,要么干脆选择性失明。
更聪明的做法是:把它拆解为 4 个核心模组,让 AI 像运行操作系统一样,模块化地调用规则。
3.3.1. 认识条目编辑器的核心参数
在开始填空之前,我们先看懂界面上的关键设置。
我们将视线从界面的最上方开始,严格按照从左到右、自上而下的顺序,逐一拆解这些参数的实际功能。
这是控制整个“世界书”运作方式的控制台。在展开的面板中,只需关注以下核心项,其余保持默认即可:
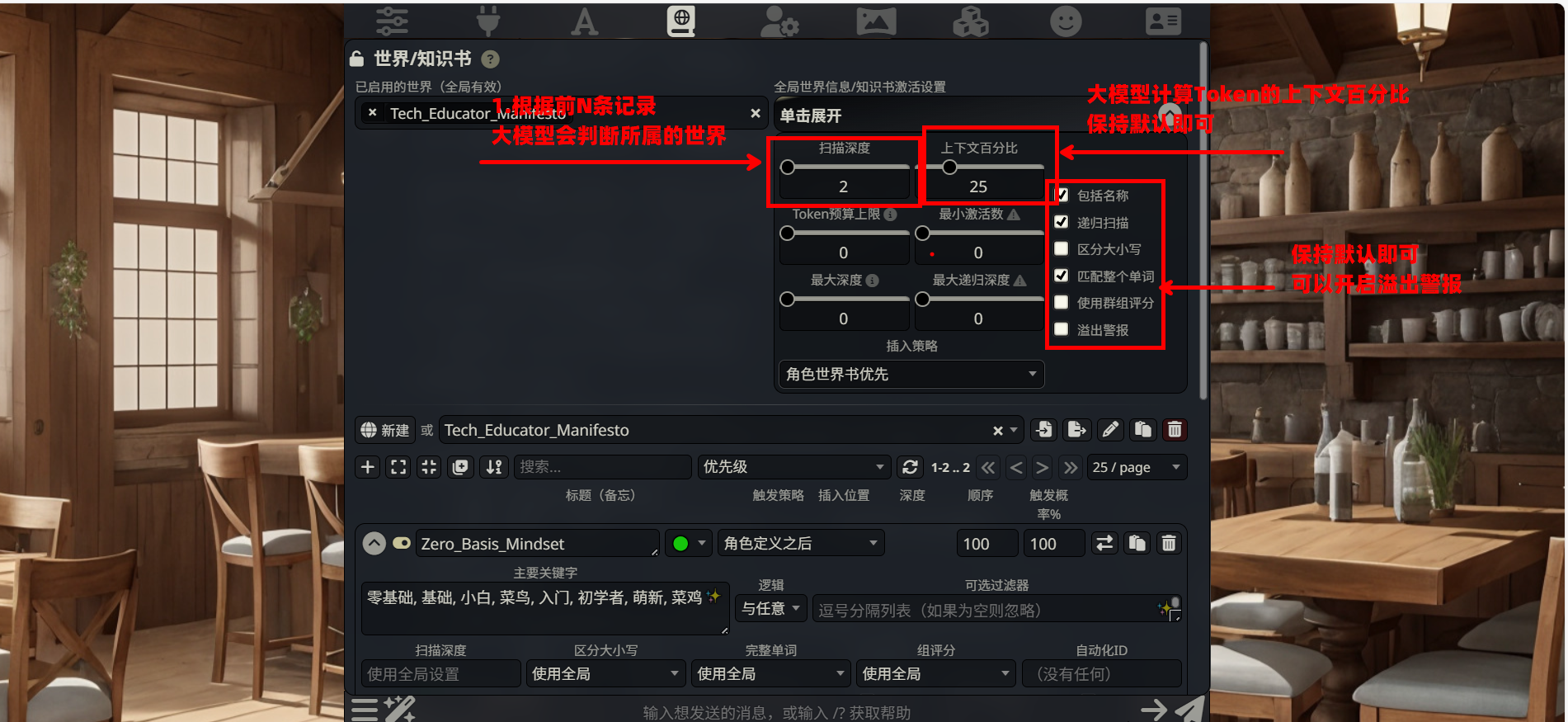
扫描深度 (Scan Depth):滑块默认为
2。这意味着系统会检测最近的 2 条聊天记录来寻找关键词。上下文百分比:控制世界书内容占总上下文预算的比例,默认即可。
插入策略:
下拉菜单选择
角色世界书优先 (Character World First)。这决定了当多个世界书同时生效时,当前绑定的角色规则优先于全局规则。关键复选框:
匹配整个单词 (Match Whole Words):建议勾选。防止关键词
art错误匹配到smart。递归扫描 (Recursive Scanning):通常勾选,允许条目内容中触发其他条目。
第二部分:条目基础属性 (中间条目栏)
点击任意一个条目栏,我们看这一行的关键设置:
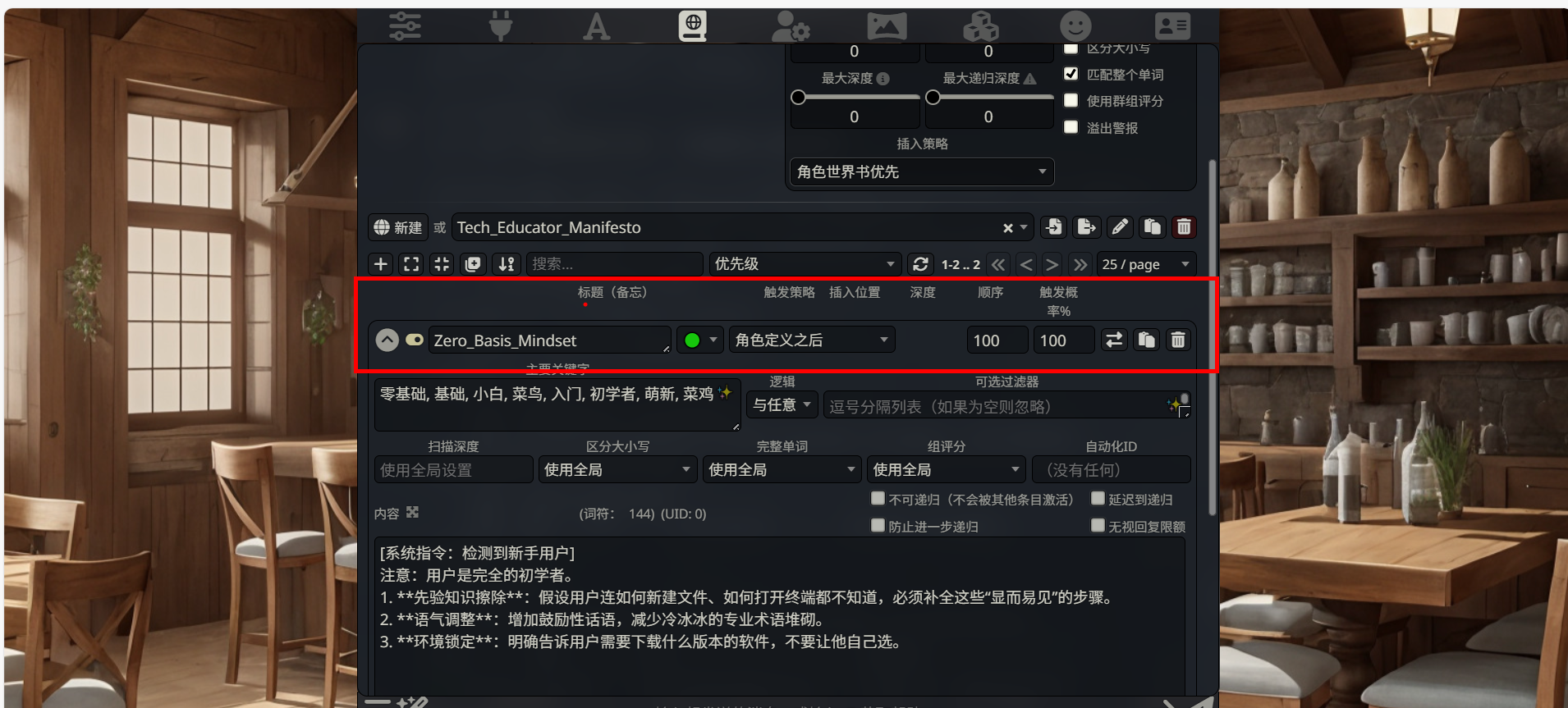
| 设置项 | 视觉位置 | 填写/选择内容 | 功能说明 |
|---|---|---|---|
| 开启状态 | 标题右侧 | 🟢 (绿色/常态) | 只有检测到关键词时才注入,不占用常驻内存。 |
| 插入位置 | 绿色圆点右侧 | 角色定义之后 | 确保此规则在 System Prompt 中的位置晚于基础人设,从而覆盖默认行为。 |
| 优先级 | 插入位置右侧 | 100 | 当触发多个条目时,数值越高,在 Prompt 中位置越靠后,权重越高。 |
| 触发概率 | 优先级右侧 | 100 | 确保只要关键词出现,100% 触发该规则。 |
第三部分:关键词与逻辑 (条目栏下方)
这是决定“什么时候触发”的核心区域:
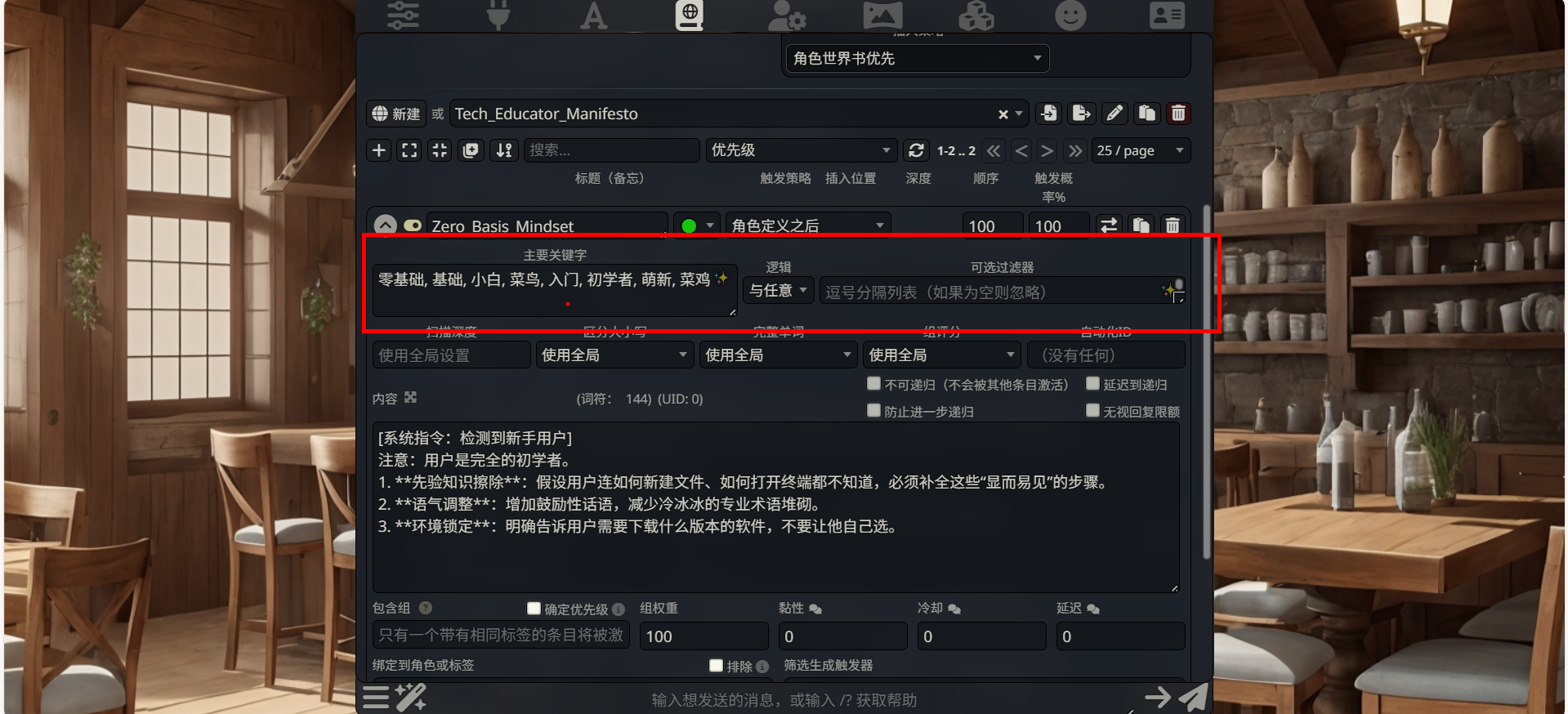
主要关键字 (Primary Keywords)
填写内容:
零基础, 基础, 小白, 菜鸟, 入门, 初学者, 萌新, 菜鸡说明:这是触发索引,输入多个同义词以覆盖用户可能的表达。
逻辑 (Logic)
选择:
与任意 (Any)说明:只要聊天记录中出现了列表里的 任意一个 词,就会激活该条目。
可选过滤器 (Optional Filter)
说明:用于排除特定场景(负面关键词),此处留空。
第四部分:覆盖设置 (关键词下方的一排控件)
你会看到一排和全局配置相关的栏目
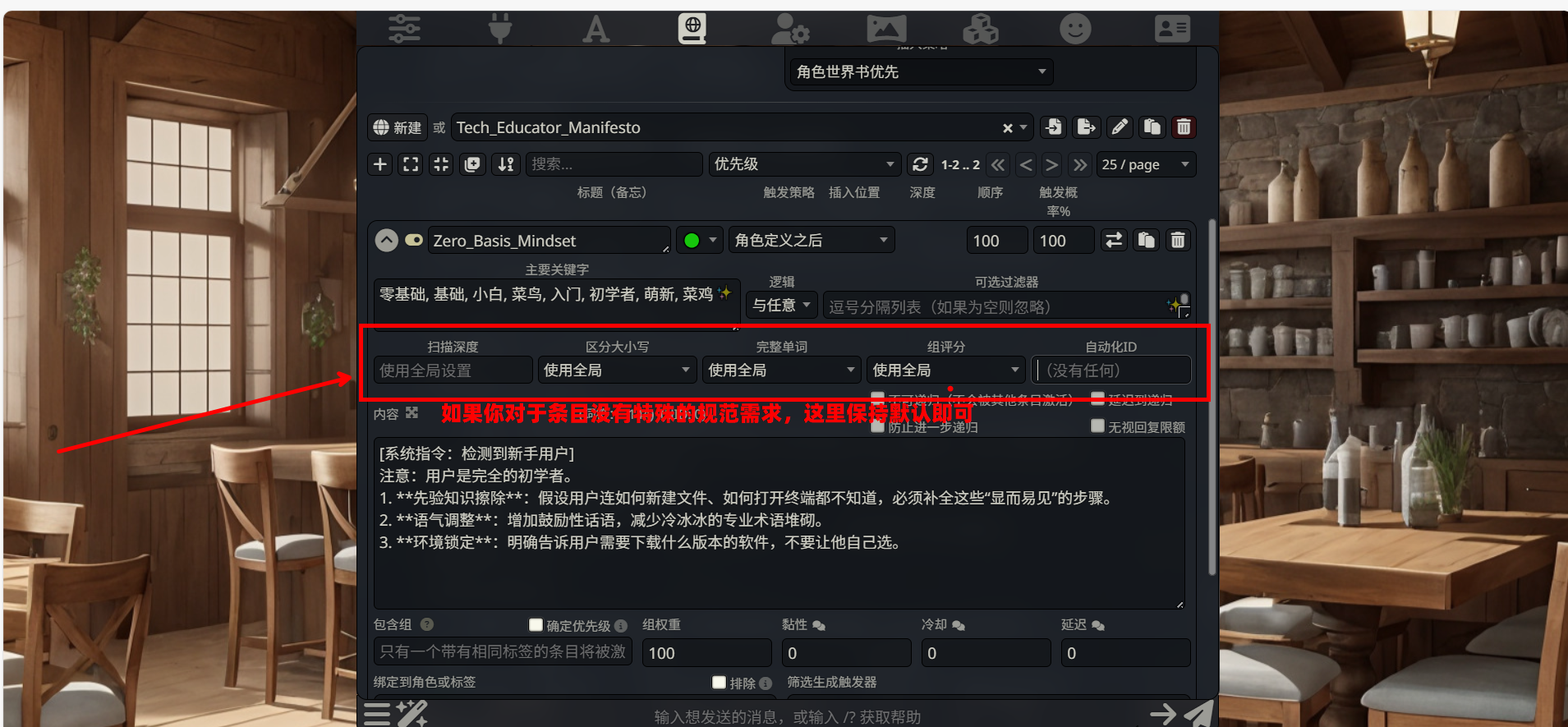
- 功能:允许单个条目违背全局设定。
- 配置建议:对于通用规则,全部保持
使用全局设置。这能确保所有条目遵循统一的标准(如扫描深度、大小写敏感度),便于维护。
第五部分:内容编写 (Content 文本框)
这是条目的实体内容,即触发后发送给 AI 的具体指令:
1 | [系统指令:检测到新手用户] |
第六部分:高级流控 (底部数据栏)
位于内容框下方,这三个参数控制条目生效的时效性:
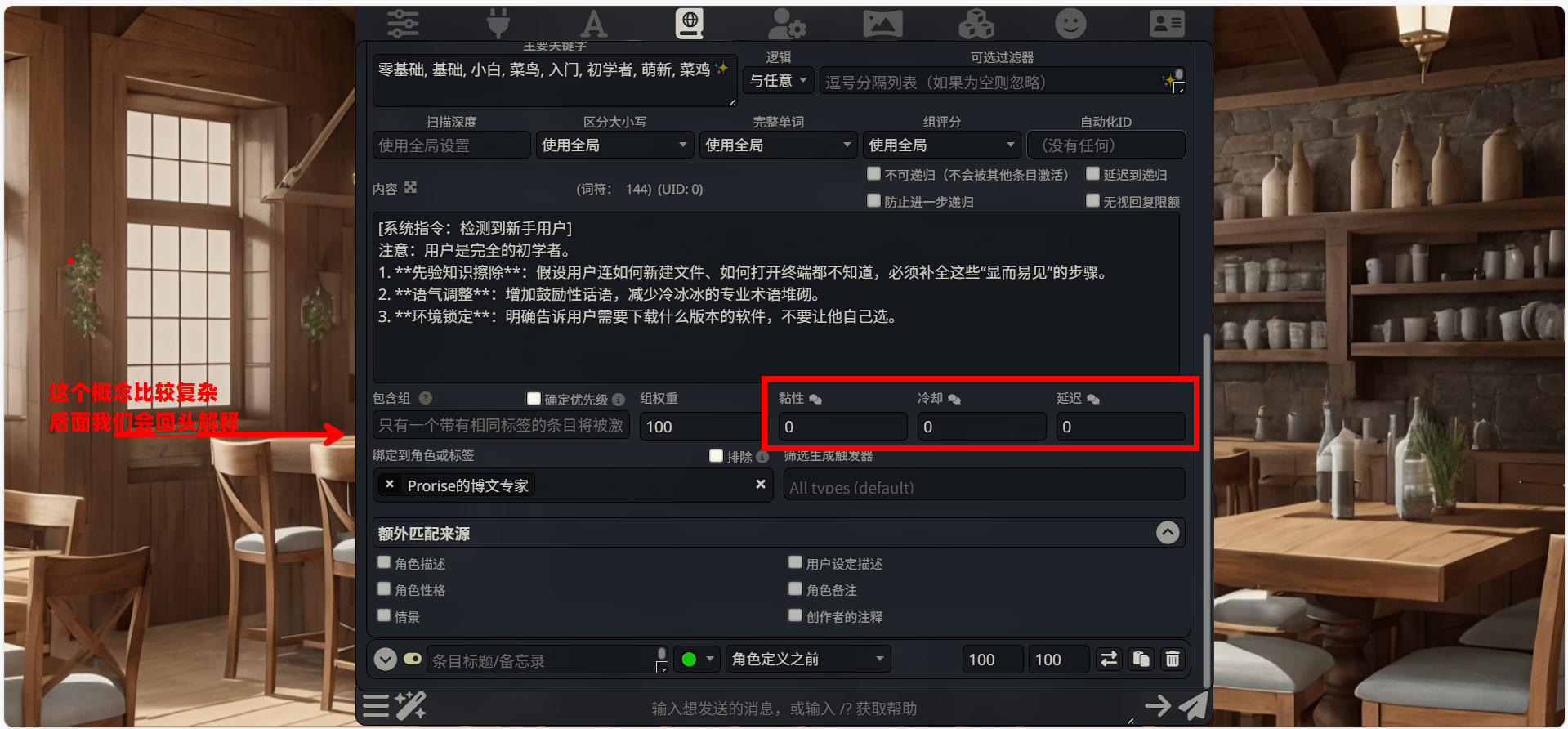
黏性 (Sticky):设置为
0。若设为 > 0,条目触发后会在后续 N 轮对话中持续强制生效。对于“零基础模式”,我们希望它随用随取,所以设为 0。
冷却 (Cooldown):设置为
0。条目触发后,禁止再次触发的轮数。此处不需要限制。
延迟 (Delay):设置为
0。触发后延迟 N 轮才生效。此处不需要。
第七部分:绑定与触发源 (最底部)
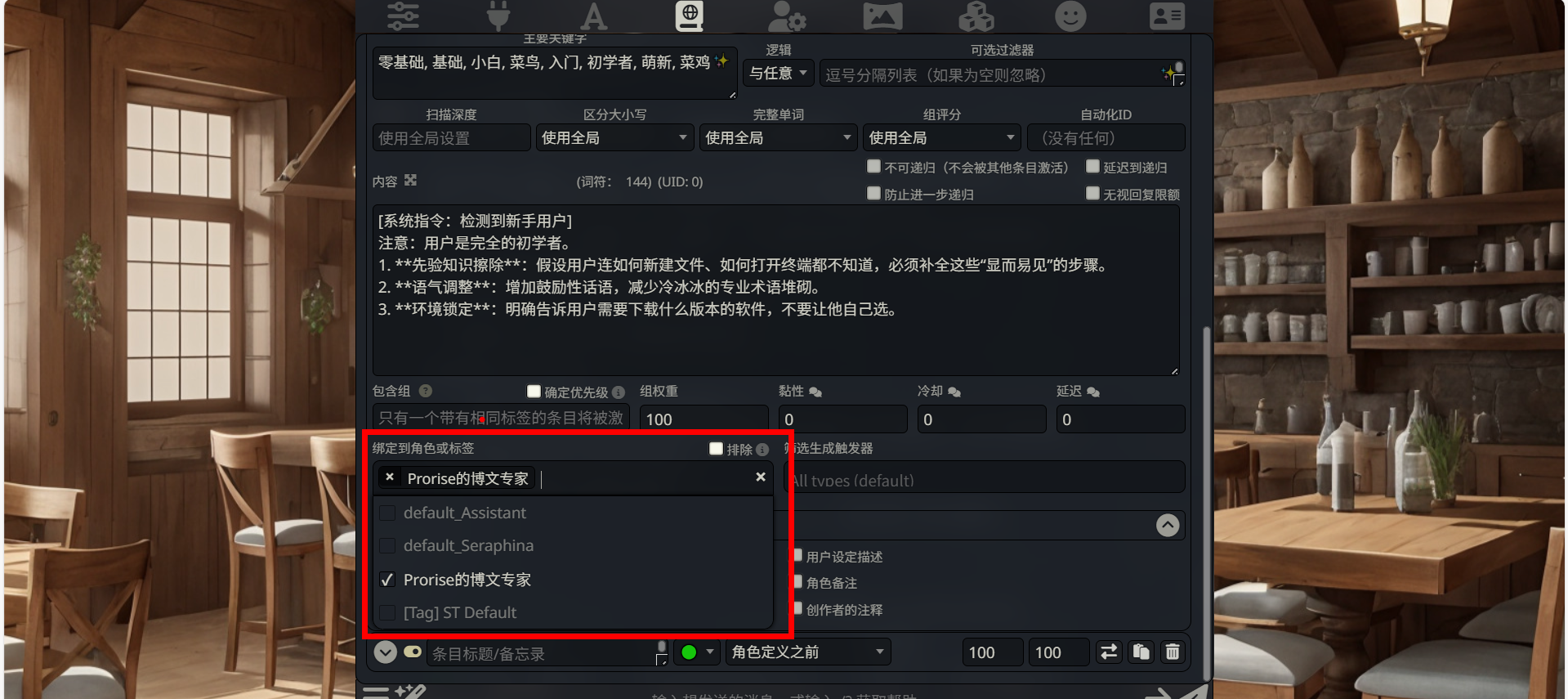
绑定到角色或标签 (Bind to Character)
位置:底部左侧文本框。
状态:此处显示
Prorise的博文专家。作用:这也是一种“防误触”机制。它将这条“零基础教学”规则死死锁定给当前这个特定的博文专家角色。如果你切换去和“代码审查员”或“情感树洞”角色聊天,即使触发了关键词,这条规则也不会生效。
排除 (Exclude)
位置:绑定角色右侧的复选框。
作用:勾选后逻辑反转(即“除了这个角色,其他人都生效”)。此处 不要勾选。
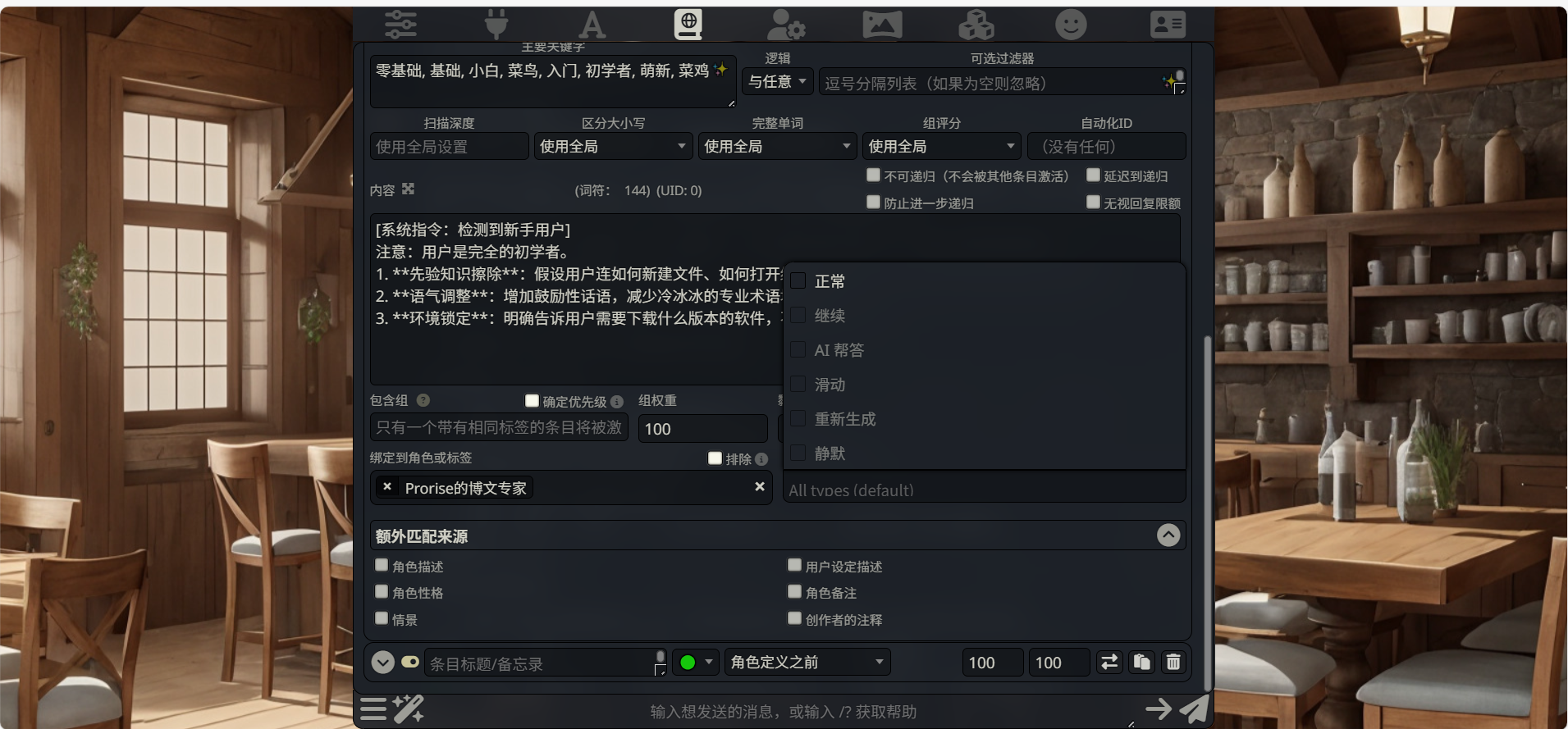
筛选生成触发器 (Filter Generation Triggers)
位置:底部右侧的长条下拉菜单(如图中展开的列表)。
定义:这是对 用户操作动作 的筛选。它决定了 AI 在什么类型的回复模式下,才允许调用这条规则。
选项详解:
正常 (Normal):标准的一问一答。滑动 (Swipe):当你对 AI 的回答不满意,向左滑动重写时。继续 (Continue):当你点击“继续”让 AI 接着没说完的话写时。重新生成 (Regenerate):当你点击刷新按钮时。配置建议:保持默认(All types / 空白)。
理由:我们希望无论你是正常提问,还是觉得 AI 写得不好滑走重来,只要涉及到“新手”话题,这个“零基础思维”的规则都必须时刻生效,不需要针对动作做限制。
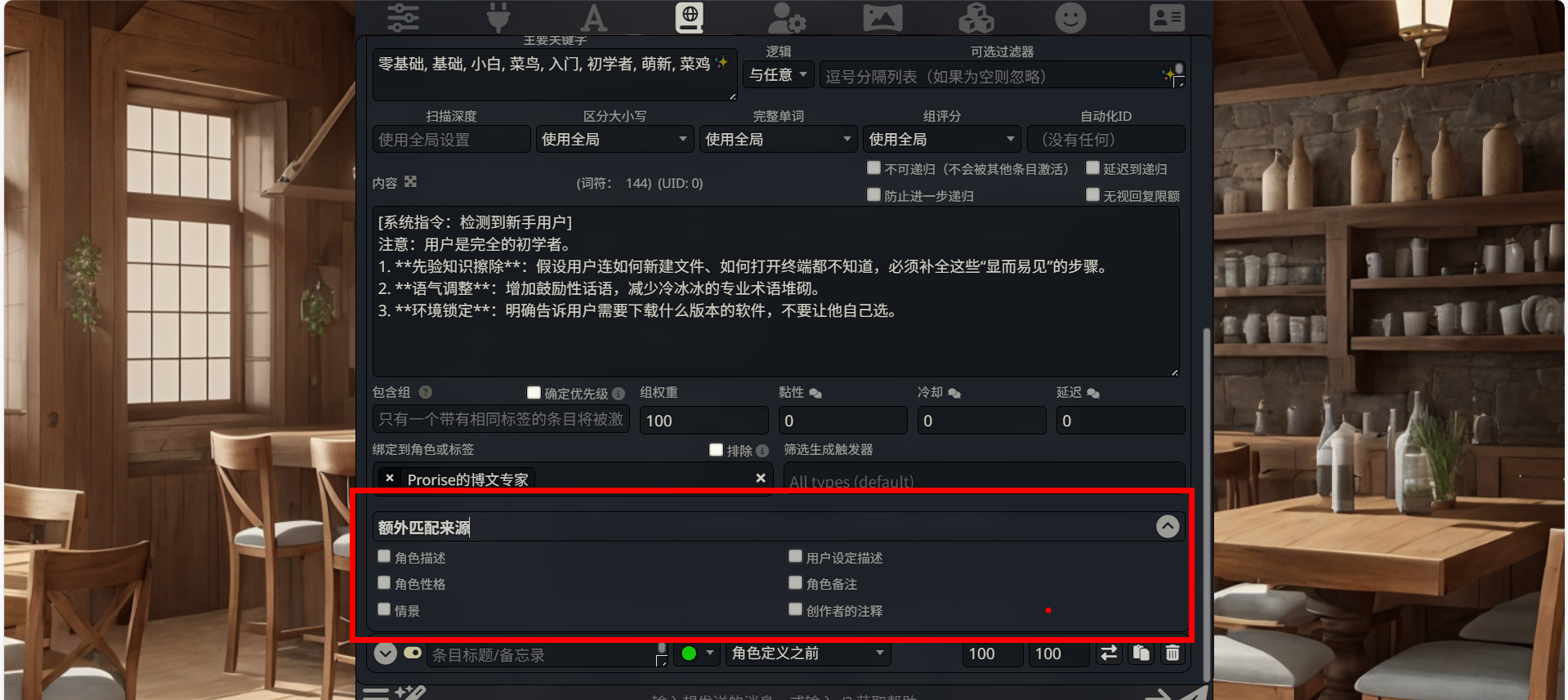
- 额外匹配来源
- 位置:最底部的折叠区域(需点击箭头展开)。
- 作用:默认情况下,系统只会在“聊天记录”里找关键词。勾选这里的选项(如
角色描述、用户设定),系统就会去扫描你的角色卡和个人简介。 - 配置建议:保持默认(全部不勾选)。我们只关注当下的对话内容是否涉及新手话题。
3.3.2. 模组一:认知内核
上一节我们把所有的配置项几乎都讲解了一遍,现在我们进入实操,那么对于一个 博客助手 来说,世界树(World Info)存在的真正意义绝对不是“重复记忆”,而是 “对抗大模型的熵增(遗忘和幻觉)”。
这个模组要植入的是,在我们的主提示词里说要“零基础友好”,但 AI 经常“知识诅咒”,越讲越深。这里需要一个强制的降维指令。
触发机制: 当出现特定技术名词,或者用户表现出不懂的情况,一般是由我们给出用户画像为小白,或是基础等词眼,我们就必须强制大模型在一个面向“小白的”场景下替我们编写博文,在此环境下大模型创作出来的内容往往会更加温和且易懂
步骤 1:创建新条目
点击 + New Entry。
步骤 2:填写配置
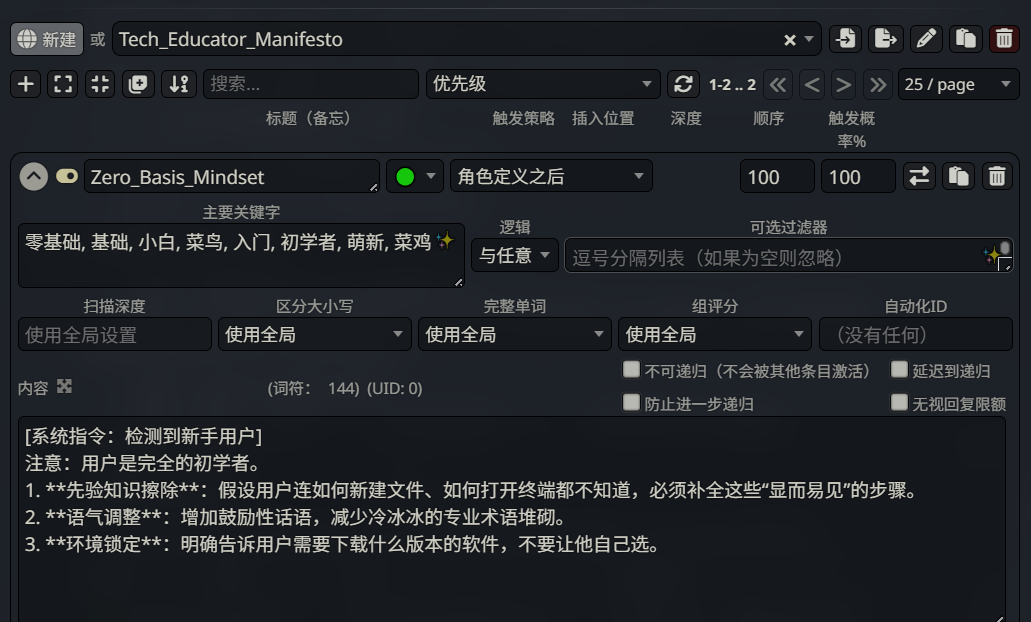
| 配置项 | 填写内容 |
|---|---|
| 条目名称 | Zero_Basis_Mindset |
| 主要关键字 | 零基础, 基础, 小白, 菜鸟, 入门, 初学者,萌新, 菜鸡 |
| Status | 🟢 Normal(默认绿色) |
| Insertion Position | 角色定义之后 |
步骤 3:填写 Content
1 | [系统指令:检测到新手用户] |
3.3.3. 模组二:质量守门员
这个模组要植入的是 “12 条铁律” 的精简版——AI 的底线熔断机制, 对于代码质量来说,我们往往希望大模型能够注重于处理核心讲解的内容,严格的错误需要在这里指正
步骤 1:创建新条目
步骤 2:填写配置
| 配置项 | 填写内容 |
|---|---|
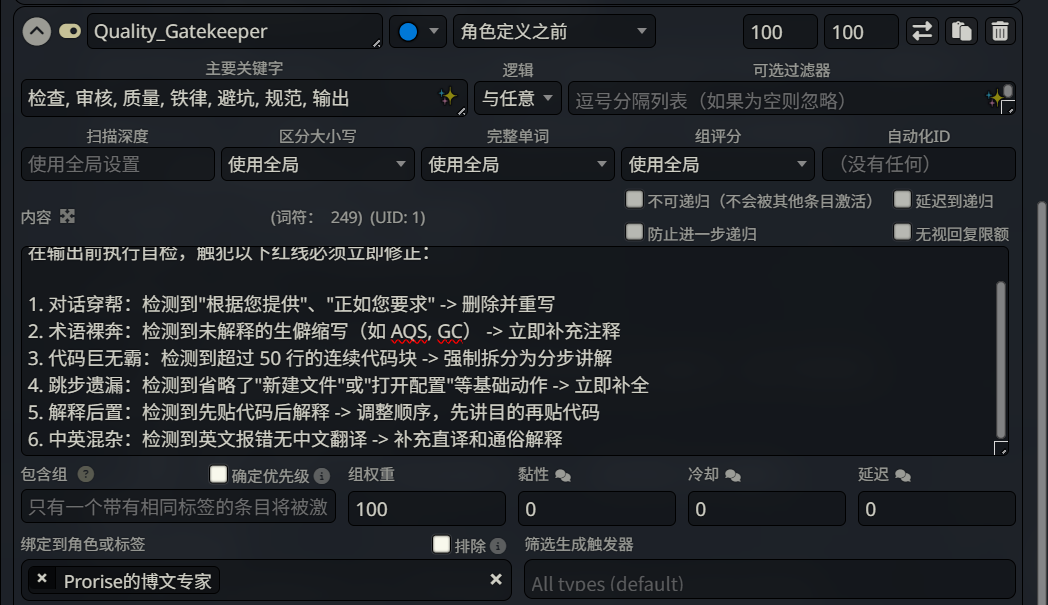
| 条目名称 | Quality_Gatekeeper |
| Keys | 检查, 审核, 质量, 铁律, 避坑, 规范, 输出 |
| Status | 🔵 Constant(无论有没有关键词都会触发) |
| Insertion Position | 角色定义之后 |
红线就是红线,每一秒都不能触碰,所以必须常驻。
步骤 3:填写 Content
1 | [质量熔断机制] |
3.3.4. 模组三:内容引擎
只有知识没有风格,写出来的博文就像教科书一样枯燥。这个模组的目的是给 AI 装上一个 “风格滤镜”,确保它输出的内容既有干货,又符合我们“零基础友好”的人设。
为了找到最适合新手的讲解方式,我们测试了 10 种不同的教学风格。你可以根据自己的喜好,从下表中选择一种作为你的核心风格后填入模板
可选风格库一览
| 风格流派 | 核心哲学 | 输出“味道”示例 (Python print) |
|---|---|---|
| 1. 温柔保姆型 | 消除恐惧,强调成就感 | “别紧张,就像给电脑递纸条。看,你成功跑通了第一行代码!” |
| 2. 硬核侦探型 | 透视黑盒,强调调试作用 | “它是你的 X 光机。在案发现场撒荧光粉,变量痕迹立马显现。” |
| 3. 生活类比型 | 强画面感,抽象具象化 | “Python 是哑巴厨师,print 就是传菜铃,不按铃菜就只放在后厨。” |
| 4. 避坑指南型 | 恐惧驱动,先说错误 | “这行代码有 3 种死法。漏括号是 Python2 的陋习,别犯。” |
| 5. 结构化强迫症 | 视觉分割,适合笔记党 | “1.概念锚定… 2.原理溯源… 3.生产实践… (分点陈述)” |
| 6. 交互对话型 | 模拟聊天,自问自答 | “很多人问:‘为啥屏幕是黑的?’ 答案很简单:你没命令它说话。” |
| 7. 极简禅意型 | 直击本质,高冷有效 | “Input -> Process -> Output。别想复杂了,让屏幕显示名字,Do it。” |
| 8. 底层原理解析 | 触及 IO 流,适合深究党 | “它在搬运数据。把字符串塞进 stdout 管道,由操作系统画在屏幕上。” |
| 9. 场景沉浸型 | 构建具体应用场景 | “想象你在做 ATM 机,没有 print,用户就不知道余额,那是一台死机器。” |
| 10. 全维融合型 | (推荐) 概念+痛点+实战+避坑 | “它是程序的声带(比喻)。解决运行状态不可见痛点(原理)。新手别用中文括号(避坑)。” |
步骤 1:创建新条目
点击 + New Entry。
步骤 2:填写配置
| 配置项 | 填写内容 | 说明 |
|---|---|---|
| 条目名称 | Content_Style_Engine | 风格引擎 |
| Keys | 怎么写, 解释, 讲解, 分析, 介绍, 风格, 语气 | 触发教学模式的关键词 |
| Status | 🟢 Normal (绿色) | 按需触发 |
| Insertion Position | 角色定义之后 | 覆盖默认的百科全书式回答 |
步骤 3:填写 Content (核心指令)
将以下内容复制进去,这就是让 AI 变成“金牌讲师”的秘籍:
1 | [系统指令:加载动态讲解风格] |
3.3.5. 模组四:视觉渲染器
这个模组要植入的是 “排版规范” 和 “富文本组件”——AI 的排版审美,不同的博客主题可能会有不同的博客标签,以及写作可能会有特殊的规范,所以我们可以再次给足大模型预定好的主题标签内容,这里其实不是一个固定的范式,所以示例我们尽可能的广泛一点
步骤 1:创建新条目
步骤 2:填写配置
| 配置项 | 填写内容 |
|---|---|
| 条目名称 | Visual_Renderer |
| Keys | 排版, 格式, 结构, 标题, 列表, 标签, 代码 |
| Status | 🔵 Constant |
| Insertion Position | 角色定义之前 |
步骤 3:填写 Content
1 | [视觉结构规范] |
3.3.6. 理解插入位置:规则在 Prompt 中的 “座位表”
完成了四个核心模组的创建后,你可能会注意到每个条目都有一个 插入位置 (Insertion Position) 的下拉菜单。这个设置决定了规则内容在最终发送给 AI 的 Prompt 中 “坐在哪个位置”。
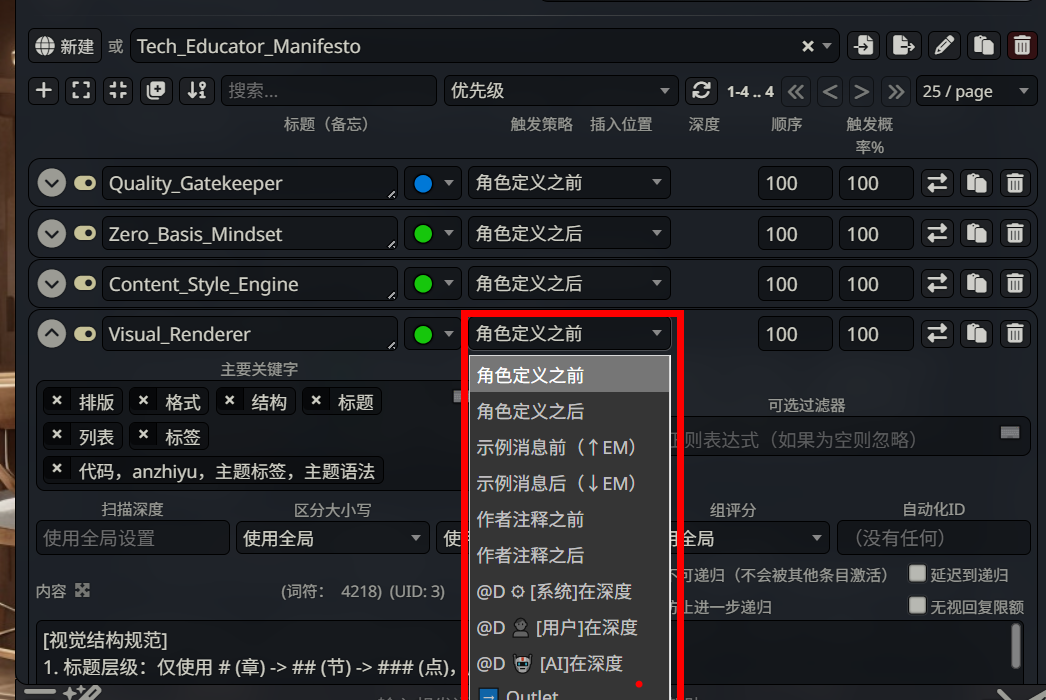
位置不同,权重就不同。越靠后的内容,AI 的 “注意力” 越集中——这是大语言模型的特性,它对 Prompt 末尾的指令更敏感。
让我们逐一拆解下拉菜单中的每个选项:
基础位置组
| 选项 | 插入位置 | 适用场景 |
|---|---|---|
角色定义之前 | System Prompt 的最前面 | 全局性的元规则,如排版规范、格式约束 |
角色定义之后 | System Prompt 之后,对话记录之前 | 核心行为规则,如零基础思维、质量熔断 |
示例消息组(↑EM / ↓EM)
| 选项 | 插入位置 | 适用场景 |
|---|---|---|
示例消息前 (↑EM) | 在角色卡的示例对话之前 | 影响 AI 对示例的理解方式 |
示例消息后 (↓EM) | 在角色卡的示例对话之后 | 基于示例进行补充说明 |
作者注释组
| 选项 | 插入位置 | 适用场景 |
|---|---|---|
作者注释之前 | 在你手动添加的作者注释之前 | 为作者注释提供上下文 |
作者注释之后 | 在你手动添加的作者注释之后 | 对作者注释进行补充或覆盖 |
深度插入组(@D)
这是最灵活也最容易让人困惑的一组选项。我们在下一节专门讲解。
特殊位置
| 选项 | 插入位置 | 适用场景 |
|---|---|---|
Outlet | 动态计算的 “出口” 位置 | 高级用法,配合其他扩展使用 |
3.3.7. 深度插入(@D):在对话历史中 “埋雷”
普通的插入位置是 “静态” 的——规则要么在 System Prompt 里,要么在对话记录的固定边界上。但 @D(At Depth) 系列选项允许你把规则 “埋” 进对话历史的特定深度。
什么是 “深度”?
深度是从最新一条消息往回数的位置。想象对话记录是一摞扑克牌,最新的消息在最上面:
1 | 深度 0:最新的 AI 回复(或即将生成的回复) |
三种 @D 选项的区别
| 选项 | 含义 | 实际效果 |
|---|---|---|
@D ◇ [系统]在深度 | 以系统消息的身份插入 | 规则以 “旁白” 形式出现,不属于任何角色 |
@D 👤 [用户]在深度 | 以用户消息的身份插入 | 规则伪装成用户说的话 |
@D 🤖 [AI]在深度 | 以 AI 消息的身份插入 | 规则伪装成 AI 之前说过的话 |
深度值的设置
当你选择任意一个 @D 选项后,需要在旁边的 深度 输入框中填写具体数值。
| 深度值 | 位置 | 注意力强度 |
|---|---|---|
0 | 紧贴最新消息 | ⭐⭐⭐⭐⭐ 最强 |
1-2 | 最近 1-2 轮对话 | ⭐⭐⭐⭐ 很强 |
3-4 | 最近 2-3 轮对话 | ⭐⭐⭐ 中等 |
5+ | 更早的对话 | ⭐⭐ 较弱 |
核心原理:大语言模型对 Prompt 末尾的内容更敏感。深度越小(越靠近最新消息),规则的 “存在感” 越强;深度越大(越靠近对话开头),规则越容易被 “稀释”。
实战示例:强制 AI 记住某个约束
假设你发现 AI 总是忘记 “代码注释必须用中文” 这条规则。你可以创建一个条目:
| 配置项 | 填写内容 |
|---|---|
| 条目名称 | Code_Comment_Reminder |
| Keys | 代码, 代码块, 示例代码 |
| 插入位置 | @D ◇ [系统]在深度 |
| 深度 | 1 |
| Content | [提醒] 接下来输出的所有代码,注释必须使用中文。 |
这样,每当对话中出现 “代码” 相关的关键词,这条提醒就会被插入到深度 1 的位置(紧贴用户最新输入),确保 AI 在生成回复时 “刚刚看到” 这条约束。
3.3.8. 顺序与深度:两套优先级系统的协作
现在你已经了解了 “插入位置” 和 “深度” 的概念,但还有一个关键参数需要理解:顺序(Order),也就是界面上显示的那个数字(如 100)。
顺序 vs 深度:它们解决不同的问题
| 维度 | 顺序 (Order) | 深度 (Depth) |
|---|---|---|
| 作用范围 | 同一插入位置内的多个条目 | 条目在整个 Prompt 中的位置 |
| 数值含义 | 数值越大,排在越后面 | 数值越小,离最新消息越近 |
| 影响因素 | 决定 “谁覆盖谁” | 决定 “AI 注意力分配” |
场景演示:当两个条目打架时
假设你有两个条目,都设置为 角色定义之后:
- 条目 A:
Quality_Gatekeeper,顺序 = 100 - 条目 B:
Zero_Basis_Mindset,顺序 = 50
最终在 Prompt 中的排列顺序是:
1 | [System Prompt / 角色定义] |
关键认知:顺序值越大,在 Prompt 中的位置越靠后,AI 的注意力越集中。所以,最重要的规则应该设置更高的顺序值。
推荐的顺序分配策略
| 规则类型 | 推荐顺序值 | 理由 |
|---|---|---|
| 排版/格式规范 | 50-80 | 基础约束,优先级较低 |
| 风格/语气规范 | 80-100 | 影响输出质量,中等优先级 |
| 质量熔断/红线 | 100-150 | 绝对不能违反,最高优先级 |
3.3.9. Outlet:动态出口的高级用法
在插入位置的下拉菜单最底部,有一个神秘的选项:Outlet。
什么是 Outlet?
Outlet 是一个 “动态占位符”。它本身不代表任何固定位置,而是由其他扩展或脚本来决定内容最终插入到哪里。
你可以把它理解为一个 “快递中转站”——包裹(规则内容)先送到这里,然后由调度系统(其他扩展)决定最终派送到哪个地址。
适用场景
| 场景 | 说明 |
|---|---|
| 配合 Regex 扩展 | 让正则表达式脚本动态决定规则插入位置 |
| 配合 Quick Reply 扩展 | 根据快捷回复的类型动态调整规则 |
| 自定义脚本 | 开发者通过 API 控制规则的注入时机 |
对于普通用户的建议
如果你不使用上述高级扩展,请忽略 Outlet 选项。它是为有特殊需求的高级用户准备的,普通场景下完全用不到。
3.3.10. 四大模组的最终配置速查表
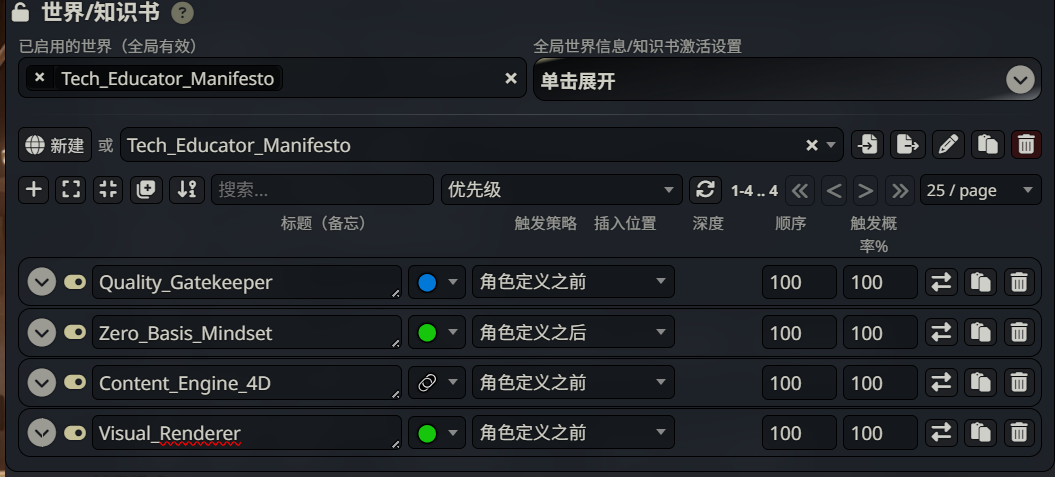
完成所有配置后,让我们用一张表格总结四个核心模组的完整设置:
| 模组名称 | 触发策略 | 插入位置 | 顺序 | 核心作用 |
|---|---|---|---|---|
Zero_Basis_Mindset | 🟢 Normal | 角色定义之后 | 100 | 检测到新手关键词时,强制降维讲解 |
Quality_Gatekeeper | 🔵 Constant | 角色定义之后 | 150 | 常驻红线,输出前自动熔断检查 |
Content_Style_Engine | 🟢 Normal | 角色定义之后 | 100 | 检测到讲解需求时,加载风格协议 |
Visual_Renderer | 🔵 Constant | 角色定义之前 | 50 | 常驻排版规范,约束输出格式 |
配置逻辑解读:
- Visual_Renderer 放在最前面(角色定义之前),作为 “地基” 存在
- Zero_Basis_Mindset 和 Content_Style_Engine 按需触发,顺序相同
- Quality_Gatekeeper 顺序最高(150),确保它是 AI “最后看到” 的规则,拥有最高的执行优先级
这套配置形成了一个完整的 “规则金字塔”:格式规范打底 → 风格引擎调味 → 质量守门员把关。无论 AI 怎么 “发挥”,最终输出都会被这套系统层层过滤,确保符合我们的标准。
3.4. 绑定世界书到角色
创建好世界书只是第一步,现在它还静静地躺在系统的数据库里。我们需要把它“装备”到我们的 博文专家 身上,确保他在对话时能够实时调用这些规则。
3.4.1. 进入角色管理
步骤 1:点击名片图标
在 SillyTavern 顶部工具栏中,找到并点击 名片图标 (User Management/Character) 👤。
步骤 2:定位目标角色
在左侧的角色列表中,找到并点击我们在 Note 02 中精心创建的 “博文写作专家”。
3.4.2. 关联世界书
这里是操作的关键分叉点,请务必注意操作位置。
步骤 1:找到 Character World 设置项
在角色编辑面板中向下滚动。请注意,我们要找的是 “Character World (角色世界书)” 区域,通常位于高级设置或专门的 World Info 栏目下。
重要信息: 角色世界树是针对于某一个角色的世界设定,而聊天世界树是全局的,无论你在这个聊天室里拉进来了哪个角色(哪怕是一群人),这个规则对所有人永远有效
步骤 2:勾选目标规则库
在下拉列表或复选框中,找到我们刚才编写的 Zero_Basis_Mindset (或你命名的规则库名称),将其勾选。
步骤 3:保存配置
点击 OK 或保存图标,确保设置生效。
3.5. 测试触发效果
配置完成后,让我们验证 World Info 是否正常工作。
3.5.1. 发起测试对话
回到聊天界面,确保当前选中的是 “博文写作专家” 角色,然后输入:
1 | 请用我的风格,写一段关于 Python print 函数的介绍。 |
3.5.2. 观察输出结果
如果配置正确,AI 的输出应该呈现以下特征:
- ✅ 语气幽默接地气,像朋友聊天
- ✅ 使用 “我们” 而非 “小编”
- ✅ 段落简短,关键词加粗
- ✅ 结尾有互动引导
3.5.3. 对比测试
为了确认是 World Info 在起作用,你可以做一个对比测试:
测试 A:输入 “写一段关于 Python print 函数的介绍”(不包含触发词)
测试 B:输入 “用我的风格,写一段关于 Python print 函数的介绍”(包含触发词)
对比两次输出的风格差异。如果测试 B 明显更符合你的风格规范,说明 World Info 配置成功。
3.6. 本节小结
本章我们完成了 L2 触发式记忆层的配置,为博文专家装上了一本 “随身风格手册”。
| 操作 | 要点 |
|---|---|
| 创建世界书 | 地球仪图标 → + 号 → 命名 |
| 添加条目 | Keys(触发词)+ Content(内容)+ Strategy(策略) |
| 绑定角色 | 角色编辑 → World Info → 勾选世界书 |
| 触发方式 | 对话中出现关键词即自动注入 |
核心认知:World Info 是 “精确触发” 的记忆系统。它的优势在于 可控性强——你明确知道什么时候会触发、触发什么内容。但它的局限也很明显:你必须记住那些关键词,而且无法处理 “模糊需求”。
下一章,我们将进入 L3 检索式记忆层,学习如何用 Data Bank 构建一个能够 “语义搜索” 的知识库,彻底解决 “我不知道该搜什么关键词” 的问题。
第四章. L3 实操——构建酒馆 RAG 本地向量模型存储
本章摘要:我们将搭建 L3 检索式记忆层,通过配置 SillyTavern 原生的 Vector Storage 功能、选择合适的 Embedding 方案、投喂项目文档,让博文专家拥有 “语义搜索” 能力,实现真正的 RAG(检索增强生成)。
| 技术组件 | 版本/要求 | 说明 |
|---|---|---|
| SillyTavern | 1.12.0+ | 需支持 Vector Storage 功能 |
| DeepSeek API | V3 | 主力对话模型 |
| Embedding 模型 | 本地或云端 | 文本向量化引擎 |
| 操作系统 | Windows/macOS/Linux | 均可 |
在前两章中,我们分别优化了 L1 工作记忆(榨干 128k 上下文)和 L2 触发式记忆(World Info 风格手册)。但这两层都有各自的局限:
- L1 是 “易失性” 的,关闭对话就清空
- L2 是 “精确匹配” 的,必须知道关键词才能触发
现在,我们要攻克最后一层:L3 检索式记忆。它将赋予 AI 一种全新的能力——语义搜索。
你不需要记住任何关键词,只要描述你的需求,系统就能从海量文档中找出最相关的内容。这就是 RAG(Retrieval-Augmented Generation,检索增强生成)技术的魅力。
4.1. 方案选择:本地 vs 云端的哲学
在配置 L3 之前,我们需要先做一个根本性的决策:你的数据值多少钱?
4.1.1. 两种方案的本质差异
| 维度 | 本地模型 | 云端模型(智谱 AI 为例) |
|---|---|---|
| 数据隐私 | ✅ 数据不离开你的电脑 | 数据上传到服务商 |
| 使用成本 | 🆓 完全免费 | 💰 按调用次数付费 |
| 响应速度 | 🐢 较慢(但无网络延迟) | ⚡ 快(受网络影响) |
| 向量质量 | 📈 足够好(持续改进中) | 📊 通常更高 |
| 依赖性 | ✅ 完全自主 | 依赖服务商 |
4.1.2. 本文的推荐策略
默认推荐:本地 Transformers 方案
基于以下三个核心理由:
理由 1:数据主权
当你使用云端 Embedding 服务时,你的每一条聊天记录、每一份上传的文档,都会被转换成向量并发送到服务商的服务器。即使服务商承诺 “不用于训练”,你也无法验证。
而本地模型则完全不存在这个问题——数据从未离开你的硬盘。
理由 2:成本可控
云端服务的定价模式是 “按调用次数付费”。看似便宜(智谱 AI 约 ¥0.0005/1K tokens),但当你上传了 100 份文档,每份文档被切分成 50 个 chunks,每次对话都要检索 5 个相关 chunks 时,成本会迅速累积。
而本地模型则是 一次配置,终身免费。
理由 3:技术趋势
开源 Embedding 模型的质量正在快速追赶商业模型。例如 Jina Embeddings v2 在多个基准测试中已经接近 OpenAI 的 text-embedding-3-small。
进阶选择:智谱 AI 云端方案
如果你遇到以下情况,可以考虑云端方案:
- 硬件性能不足(老旧电脑)
- 追求极致的向量质量
- 多设备同步使用
本章将 先讲本地方案(4.2-4.4 节),再讲云端方案(4.5 节),你可以根据自己的需求选择。
4.2. 核心概念:Embedding——AI 的 “翻译官”
在动手配置之前,我们需要理解一个关键概念:Embedding(嵌入/向量化)。
4.2.1. 为什么需要 Embedding?
AI 模型本质上是一个 “数学机器”,它只能处理数字,看不懂文字。
想象你有一本厚厚的技术手册,里面写着 “Redis 缓存穿透的解决方案”。当你问 AI “帮我找关于缓存问题的资料” 时,AI 面临一个问题:它怎么知道 “缓存问题” 和 “Redis 缓存穿透” 是相关的?
如果只是简单的关键词匹配,AI 会错过很多相关内容。比如:
- “缓存击穿”(用词不同,但语义相关)
- “热点数据失效”(完全不同的词,但描述的是同一个问题)
这就需要一个 “翻译官”,把人类的文字翻译成 AI 能理解的 “数字语言”,并且这种翻译能够 捕捉语义相似性。
这个翻译官,就是 Embedding 模型。
4.2.2. Embedding 的工作原理
Embedding 模型会把一段文字转换成一个 向量(Vector)——一串长长的数字,通常有几百到几千个维度。
举个简化的例子:
| 文本 | 向量(简化示意,实际有 768 维) |
|---|---|
| “Redis 缓存穿透” | [0.82, 0.15, 0.93, 0.41, …] |
| “缓存击穿问题” | [0.79, 0.18, 0.91, 0.38, …] |
| “今天天气真好” | [0.12, 0.87, 0.23, 0.65, …] |
注意看:前两个文本虽然用词不同,但它们的向量非常接近(数字上很相似)。而第三个文本的向量则完全不同。
这就是 Embedding 的魔力:它能捕捉语义相似性,而不仅仅是字面匹配。
当你问 “帮我找关于缓存问题的资料” 时,系统会:
- 把你的问题转换成向量:
[0.80, 0.16, 0.92, ...] - 在向量数据库中计算 “数字距离”,找出最接近的内容
- 把找到的内容返回给你
这就是 “语义搜索” 的本质。
重要警告:DeepSeek 官方目前 没有提供 Embedding API。如果你尝试用 DeepSeek 的 API Key 来做向量化,会直接报错。DeepSeek 擅长的是 “对话生成”(Chat Completion),而 Embedding 是另一种完全不同的能力。
4.3. 本地方案:零成本的 Transformers 配置
现在,让我们开始配置最简单、最直接的本地 Embedding 方案。
4.3.1. 打开 Vector Storage 设置
步骤 1:进入扩展管理
在 SillyTavern 界面右上角,点击 扩展图标 🧩(拼图形状)。
步骤 2:找到 Vector Storage
在扩展列表中,找到并点击 “Vector Storage” 或 “向量存储”,展开设置面板。
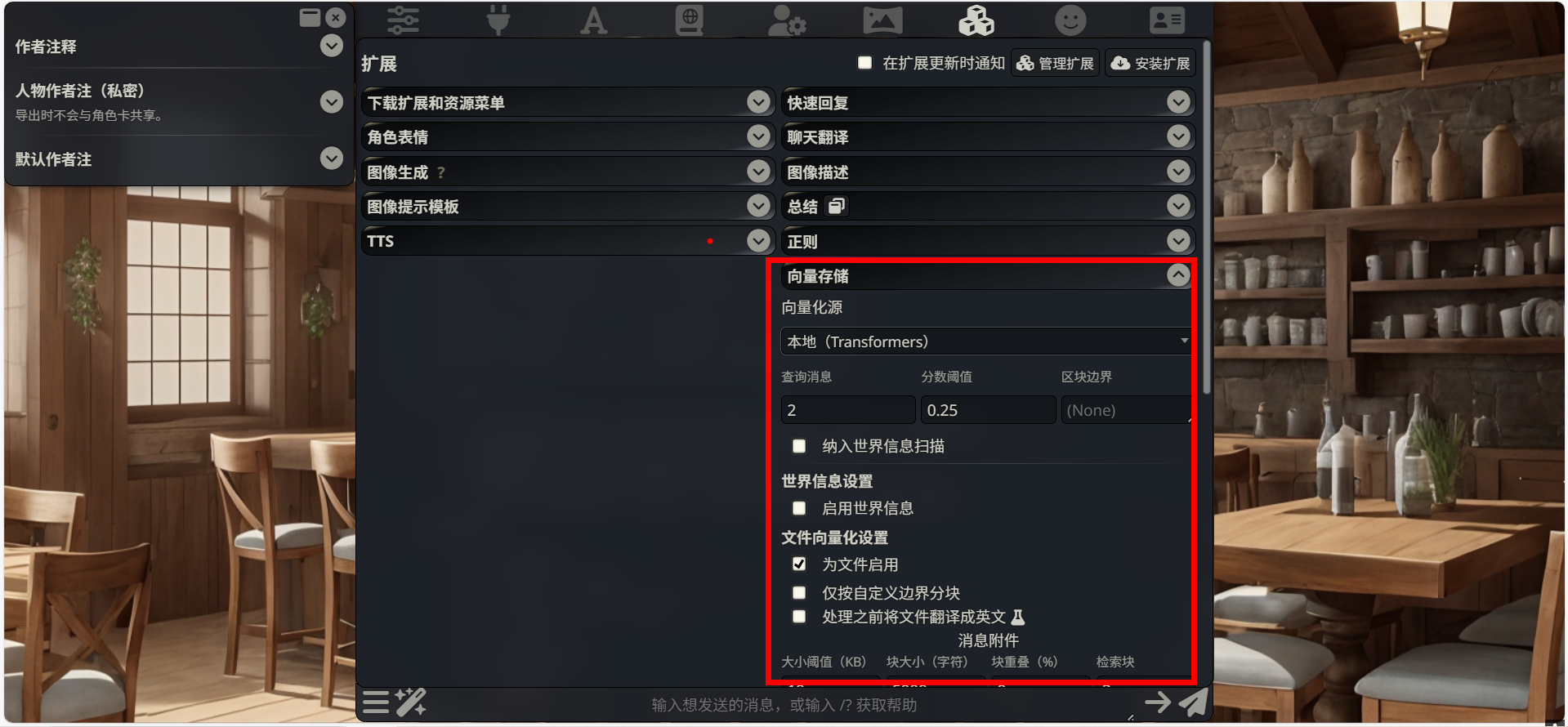
4.3.2. 选择本地 Transformers
步骤 1:选择向量化源
在 “Vectorization Source” 下拉菜单中,选择 “Local (Transformers)”。
步骤 2:无需填写任何配置
这就是本地方案的优势——无需 API Key,无需 URL,开箱即用。
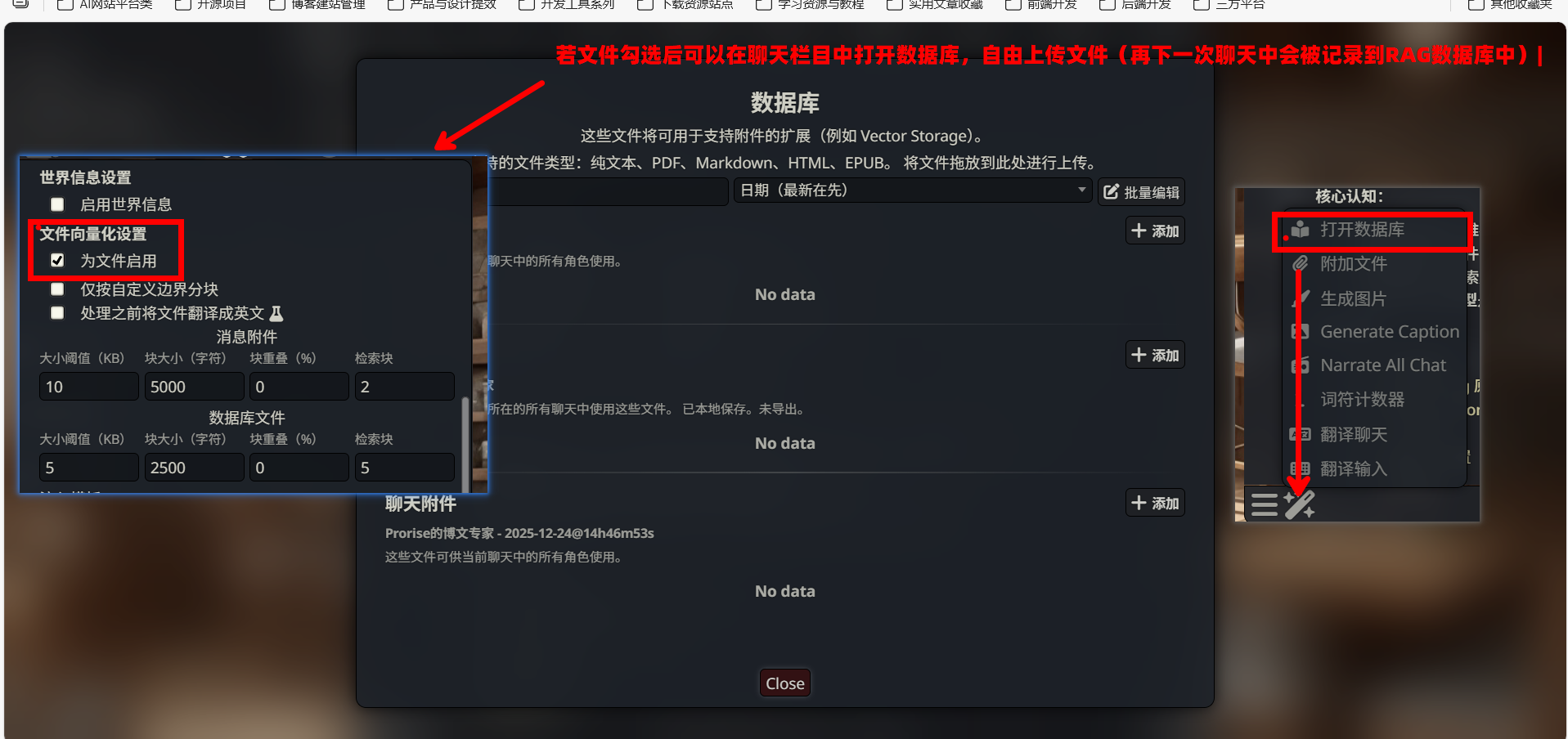
4.3.3. 启用向量存储
根据你的需求,勾选以下选项:
推荐配置:
- ✅ Enable for chat messages:为聊天消息启用向量存储(即每一次聊天都可能被向量化)
- ✅ Enable for files:为上传的文件启用向量存储(即可以上传PDF/word文档,通常这一些可以被向量化)
- ⬜ Enable for World Info:为世界信息启用向量检索(可选,通常不需要)
4.3.4. 调整参数(可选)
对于新手,默认参数已经足够好。如果你想深入优化,可以调整:
| 参数 | 说明 | 推荐值 |
|---|---|---|
| Message Chunk Size | 消息切分大小 | 400(默认) |
| Insert Messages | 插入多少条相关消息 | 3-5 |
| Query Messages | 查询时使用多少条最近消息 | 2-3 |
| Score Threshold | 相似度阈值(0-1) | 0.25(默认) |
参数解释:
- Chunk Size:文本会被切分成小块进行向量化。太小会导致上下文碎片化,太大会降低检索精度。400 是一个经过测试的平衡值。
- Score Threshold:相似度阈值。0.25 表示只返回相似度超过 25% 的内容。提高这个值会让检索更精确,但可能找不到内容;降低会返回更多结果,但可能包含不相关内容。
4.3.5. 首次使用:自动下载模型
步骤 1:上传测试文件
在聊天界面点击 附件图标 📎,上传一个测试文件(建议 < 1MB 的文本或 Markdown 文件)。
步骤 2:观察模型下载
第一次使用时,SillyTavern 会自动从 HuggingFace 下载 Embedding 模型。
下载信息:
- 模型名称:
Cohee/jina-embeddings-v2-base-en - 模型大小:约 130MB(ONNX 量化版本)
- 向量维度:768
- 下载时间:取决于网速,通常 2-5 分钟
网络提示:如果你在国内,HuggingFace 的下载速度可能较慢。可以按 F12 打开控制台,观察下载进度。如果长时间卡住,可以尝试使用代理或稍后重试。
步骤 3:等待向量化完成
文件上传后会自动开始向量化。你会在右下角看到进度提示:
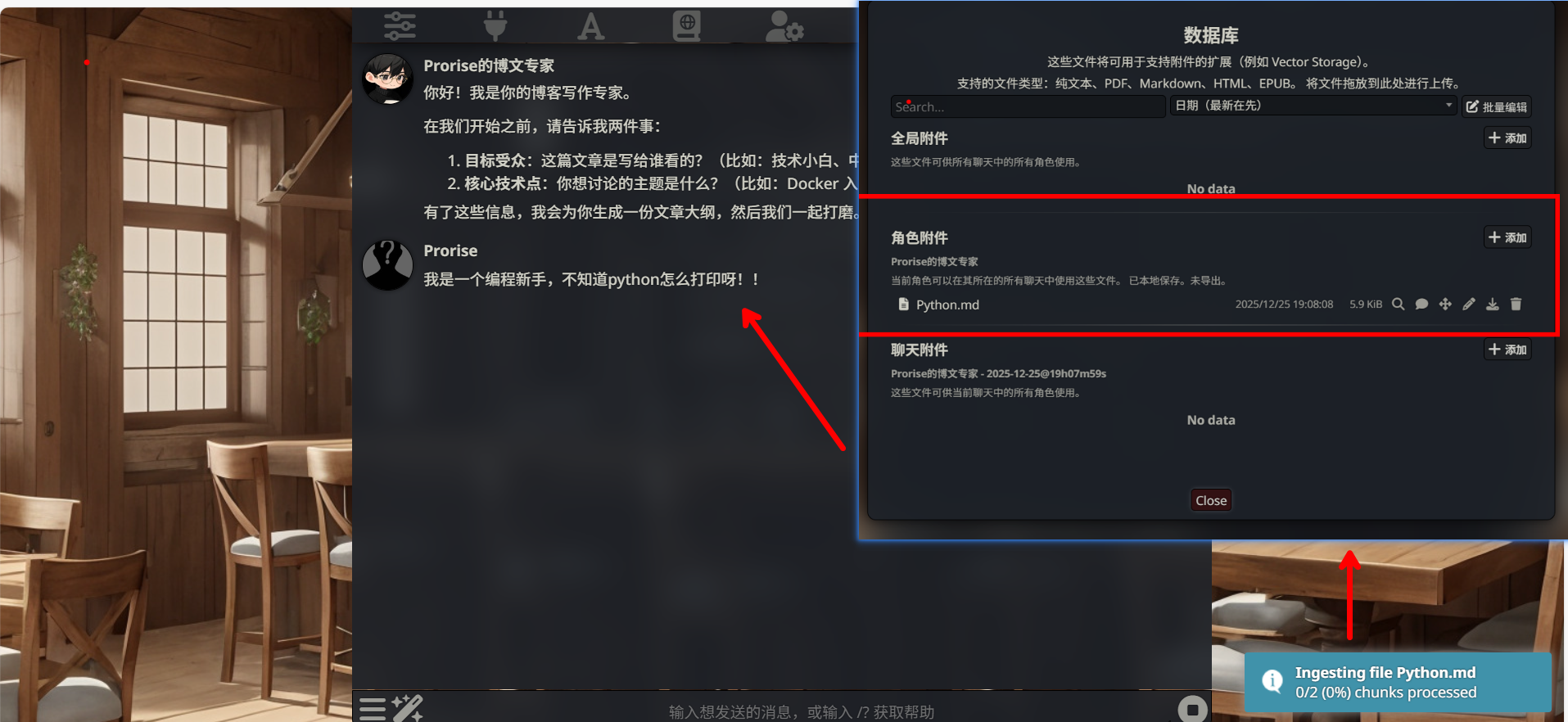
成功现象:
- 进度条走完
- 显示 “Inserted X vector items”
- 没有报错信息
4.3.6. 测试检索效果
向量化完成后,让我们验证检索是否正常工作。
测试方法:
向 AI 提问一个与你上传文件相关的问题。例如,如果你上传了一份关于 Python 的笔记,可以问:
1 | 帮我回顾一下之前笔记里关于 Python 列表推导式的内容 |
预期效果:
AI 的回答应该包含你笔记中的具体信息,而不是泛泛而谈的通用知识。如果 AI 能准确引用你笔记中的细节(比如你写的示例代码、你的个人理解),说明 RAG 配置成功。
4.4. 工作原理:揭开黑盒
当你选择 Local (Transformers) 后,幕后发生了什么?理解这个过程有助于你更好地优化配置。
4.4.1. 模型下载与加载
SillyTavern 使用的是 Jina Embeddings v2 模型的 ONNX 量化版本。这个模型的特点:
- 向量维度:768(每段文本被转换成 768 个数字)
- 最大长度:8192 tokens(约 6000 个汉字)
- 模型大小:130MB(经过量化压缩)
- 运行环境:纯 JavaScript(通过 ONNX Runtime Web)
模型会被下载到:
1 | E:\SillyTavern\data\_cache\ |
4.4.2. 文本向量化流程
当你上传文件或发送消息时,文本会经历以下处理:
第一步:文本切分
长文本会被切分成多个 chunks(默认 400 tokens 一块):
1 | 原始文档(5000 字) |
第二步:向量化
每个 chunk 被转换成 768 维向量:
1 | Chunk 1: "第一章 项目介绍..." |
第三步:存储
向量被存储在本地的 Vectra 数据库中:
1 | E:\SillyTavern\data\default-user\vectors\ |
4.4.3. 语义检索流程
当你发送新消息时,SillyTavern 会:
第一步:问题向量化
1 | 你的问题: "帮我找关于缓存问题的资料" |
第二步:相似度计算
在向量数据库中,计算问题向量与所有已存储向量的 “距离”(通常使用余弦相似度):
1 | 问题向量 vs Chunk 1 向量 → 相似度: 0.85 |
第三步:筛选与排序
- 过滤掉相似度低于阈值(0.25)的 chunks
- 按相似度从高到低排序
- 取前 N 个(默认 3-5 个)
第四步:注入上下文
把检索到的 chunks 注入到 AI 的上下文中:
1 | [System Prompt] |
AI 基于这些 “参考资料” 生成回答。





