
Prorise
这是我的博客,分享技术与生活的点点滴滴
🍺 SillyTavern(酒馆)- 角色卡设计-手把手教你"捏"一个懂你的博文写作专家
🍺 SillyTavern(酒馆)- 角色卡设计-手把手教你"捏"一个懂你的博文写作专家
Prorise手把手教你 “捏” 一个懂你的博文写作专家
这篇笔记写给对 SillyTavern 界面一无所知的小白。我会像坐在你旁边的老同事一样,手把手带你走完整个流程:从认识界面,到用 AI 生成头像,再到填入 Markdown 提示词、调整模型参数,最后启动对话。读完这篇,你将拥有一个可以反复调用的 “博文写作专家”。
第一章:界面解剖学——给 “驾驶舱” 贴标签
打开 SillyTavern 的网页版,你会看到一个信息量巨大的界面。别慌,我们今天只认识最常用的 4 个入口。其他功能以后用到再说,现在知道太多反而会劝退自己。
1.1 顶栏图标速查表
把目光移到界面最顶部,你会看到一排小图标。我们从左到右依次认识它们。
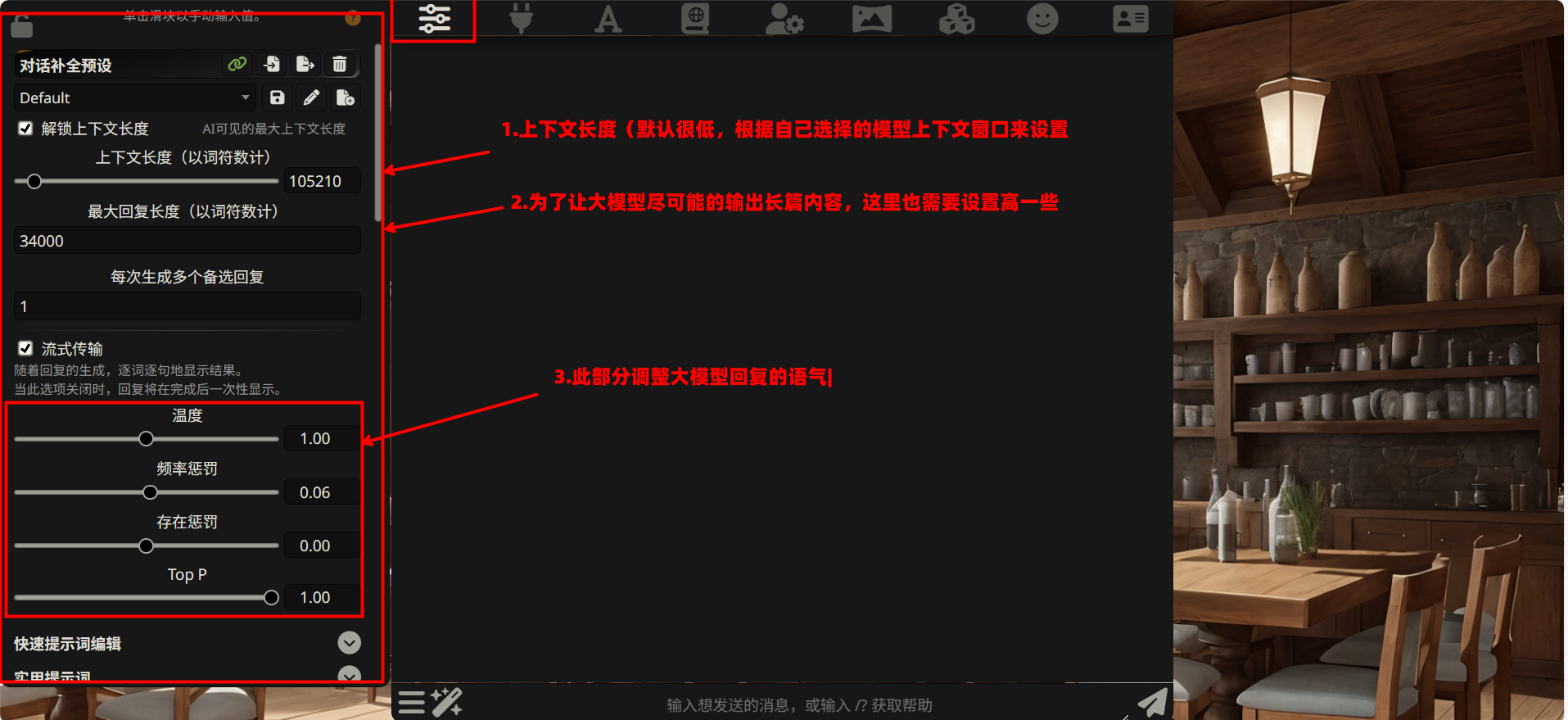
A 区 - 调节器 (滑块图标 🎛️)
这个图标长得像音响上的调音滑块。点进去之后,你能控制 AI 的 “智商” 和 “话痨程度”。具体来说,这里可以设置回复长度、温度(Temperature)、上下文长度(Context Limit)等核心参数。
你可以把它理解成汽车的油门和刹车。油门踩深一点(温度调高),AI 会更有创意但可能跑偏;刹车踩重一点(温度调低),AI 会更稳但可能显得呆板。我们在第四章会详细讲怎么调。
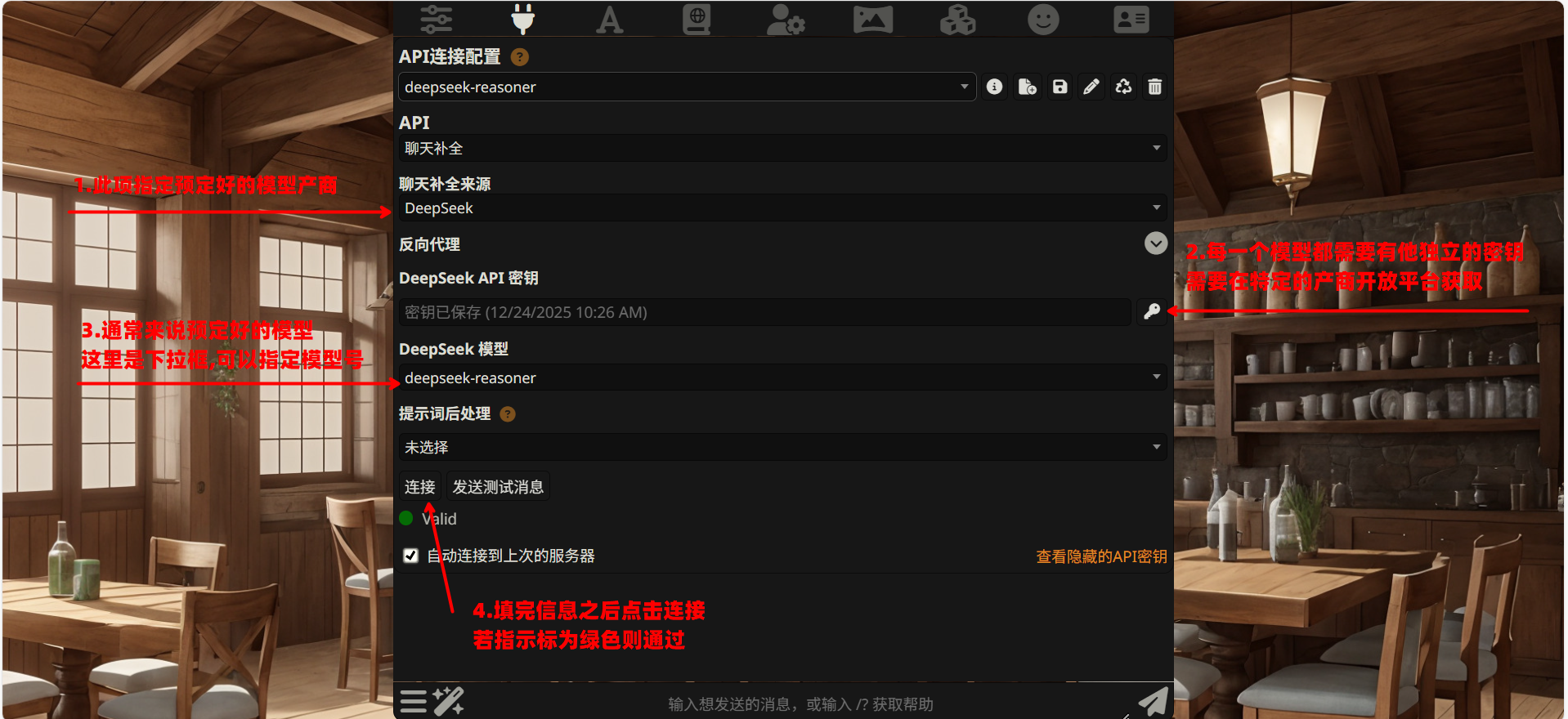
B 区 - 连接口 (插头图标 🔌)
这个图标长得像一个电源插头。它负责给酒馆 “通电”——也就是连接 Claude 或 DeepSeek 的 API。
没有这一步,SillyTavern 就是一个空壳子。你需要在这里填入 API Key,选择模型来源(比如 Anthropic、OpenAI Compatible 等),酒馆才能真正和 AI 对话。
C 区 - 知识库 (地球图标 🌐)
这个图标是一个地球的形状。它是 SillyTavern 的 “世界书”(World Info)功能入口。
简单来说,你可以在这里存放项目文档、背景设定、专业术语表等资料。当对话中出现特定关键词时,系统会自动把相关资料注入给 AI。这是一个进阶功能,今天我们先跳过,以后专门开一篇讲。
D 区 - 人事部 (名片图标 🪪)
这个图标长得像一张名片或者身份证。这是今天的重点。
点进去之后,你会看到右侧有一个加号 (+),这里就是管理和创建 “专家员工” 的地方。我们今天要做的 “博文写作专家”,就是在这里诞生的。
其余的部分功能如下图所示:
1.2 为什么要去 D 区而不是直接聊?
你可能会问:我直接在对话框里告诉 AI “你是一个博文专家”,不也能用吗?
能用,但不持久。
临时对话 vs 永久卡片
如果你直接在对话框里改设定,这就像是口头交代任务。AI 当时记住了,但刷新页面、开新对话之后,它就全忘了。你每次都要重新交代一遍,非常麻烦,和我们在网页端直接对话没有区别
如果你在 D 区创建一张角色卡片,这就像是给公司招了一个正式员工,签了劳动合同。这个员工的技能、性格、工作方式全都写在档案里,永久保存。你什么时候想用,点开这张卡片就能直接开工,不用重复交代。
更妙的是,这张卡片可以导出成一张 PNG 图片,发给朋友。朋友把图片拖进自己的酒馆,就能直接用你配置好的专家。这就是 SillyTavern 的 “角色卡” 机制,非常优雅。
所以,我们今天的核心任务就是:在 D 区创建一张 “博文写作专家” 的永久卡片。
第二章:准备工作——用 AI 为 AI 造皮囊
在正式创建卡片之前,我们先做一件有趣的事:给你的 “博文专家” 做一个头像。
你可能觉得头像无所谓,随便找张图就行。但我建议你认真对待这一步。原因有两个:
- 仪式感:一个精心设计的头像会让你更有动力使用这个工具。
- 辨识度:当你以后创建了十几个不同的专家卡片,一眼就能认出谁是谁。
我们用字节跳动的 “即梦”(Jimeng)来生成头像。它擅长中文理解,做 Q 版头像特别顺手。
2.1 准备素材
首先,你需要准备一张参考图。
这张图可以是:
- 你喜欢的某个卡通形象
- 一张代表 “写作” 或 “科技” 氛围的图片
- 甚至只是一张普通的办公桌照片
即梦会基于这张图的色调、构图、氛围来生成新图。所以参考图不需要很精致,但最好能传达你想要的 “感觉”。
如果你实在没有合适的图,可以去 Unsplash 搜索 “writer” 或 “tech office”,随便下载一张。
2.2 即梦 (Jimeng) 操作流
打开浏览器,访问 即梦 AI - 一站式 AI 创作平台(即梦的官网)。
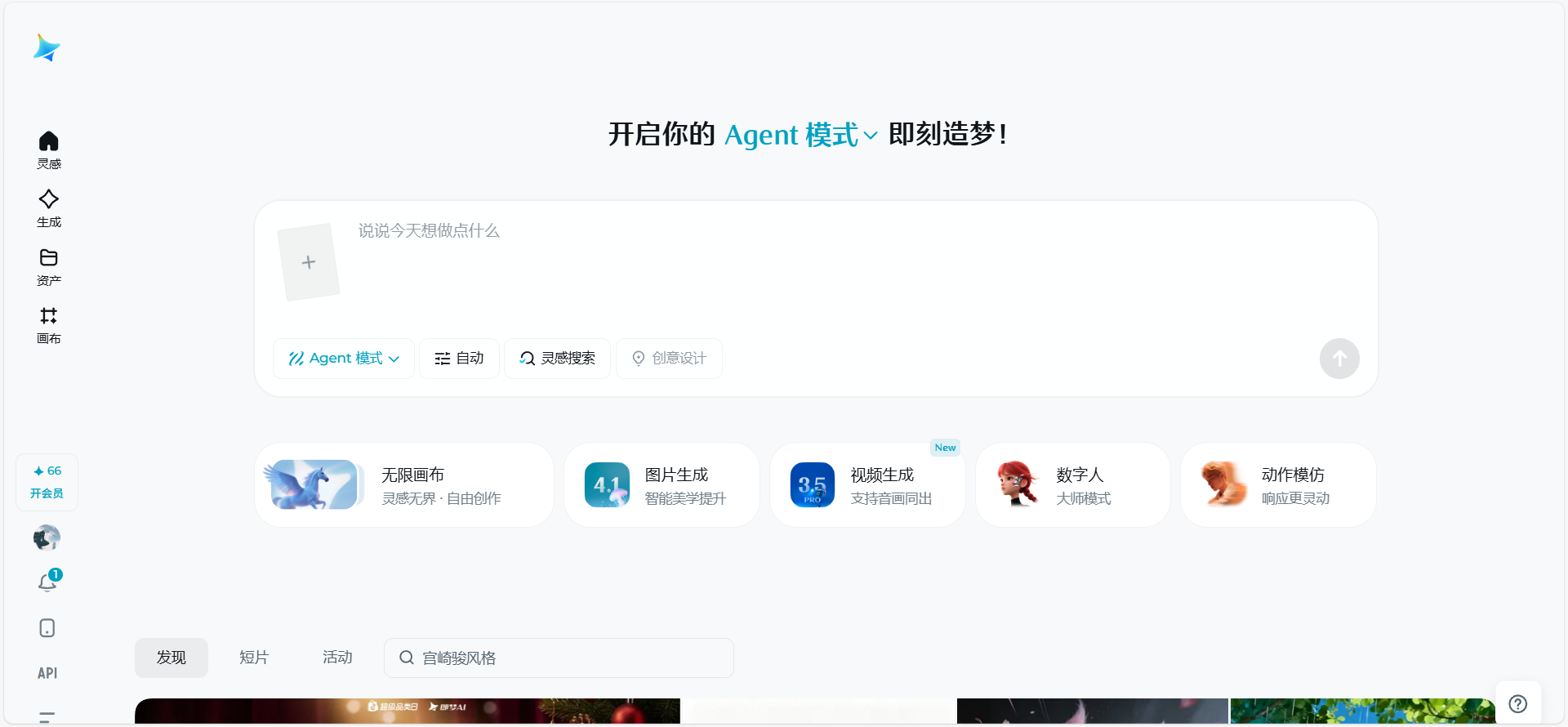
第一步:进入图片生成
在首页找到 “图片生成” 功能,点进去。你会看到一个上传区域和一个输入框。
第二步:上传参考图
把你准备好的参考图拖进上传区域,或者点击上传按钮选择文件。
第三步:输入咒语 (Prompt)
在输入框里填入以下内容:
1 | (二次元手绘插画风格:1.3),超可爱的Q版大头身角色, |
你可以根据自己的喜好微调。
第四步:设置参考强度
这是关键参数。在即梦的界面里,你会看到一个 “参考强度” 或 “图像引导强度” 的滑块。
建议设置在 40%-60% 之间。
- 太低(比如 20%):生成的图和参考图几乎没关系,完全是 AI 自由发挥。
- 太高(比如 90%):生成的图和参考图太像,Q 版化效果不明显。
- 40%-60%:既保留原图的特征和氛围,又能实现明显的 Q 版化。
第五步:生成并下载
点击生成按钮,等待几秒钟。即梦通常会给你 4 张候选图。
挑一张你最满意的,点击下载。
第六步:裁剪为正方形
下载的图可能是长方形的。SillyTavern 的头像框是正方形,所以你需要裁剪一下。
用系统自带的图片编辑器(Windows 的 “画图”、Mac 的 “预览”)打开图片,裁剪成 1:1 的正方形,保存。
好了,头像准备完毕。接下来进入正题。
第三章:核心实操——封装 “博文专家” 卡片
这一章是整篇笔记的核心。我们要把你的 Markdown 提示词正确填入 SillyTavern 的数据结构中,创建一张可以反复使用的 “博文专家” 卡片。
3.1 创建新员工
回到 SillyTavern 界面,把目光移到顶部图标栏。
第一步:点击名片图标 🪪
找到那个长得像名片的图标(D 区),点击它。
第二步:点击右侧加号 +
点击之后,界面右侧会弹出一个面板。在这个面板的某个角落(通常是右上角或底部),你会看到一个加号 (+) 按钮。点击它。
第三步:选择 “Create New Character”
点击加号后,会弹出一个菜单,里面有几个选项。选择 “Create New Character”(创建新角色)。
现在,你进入了角色编辑界面。这里有很多输入框,我们一个一个来填。
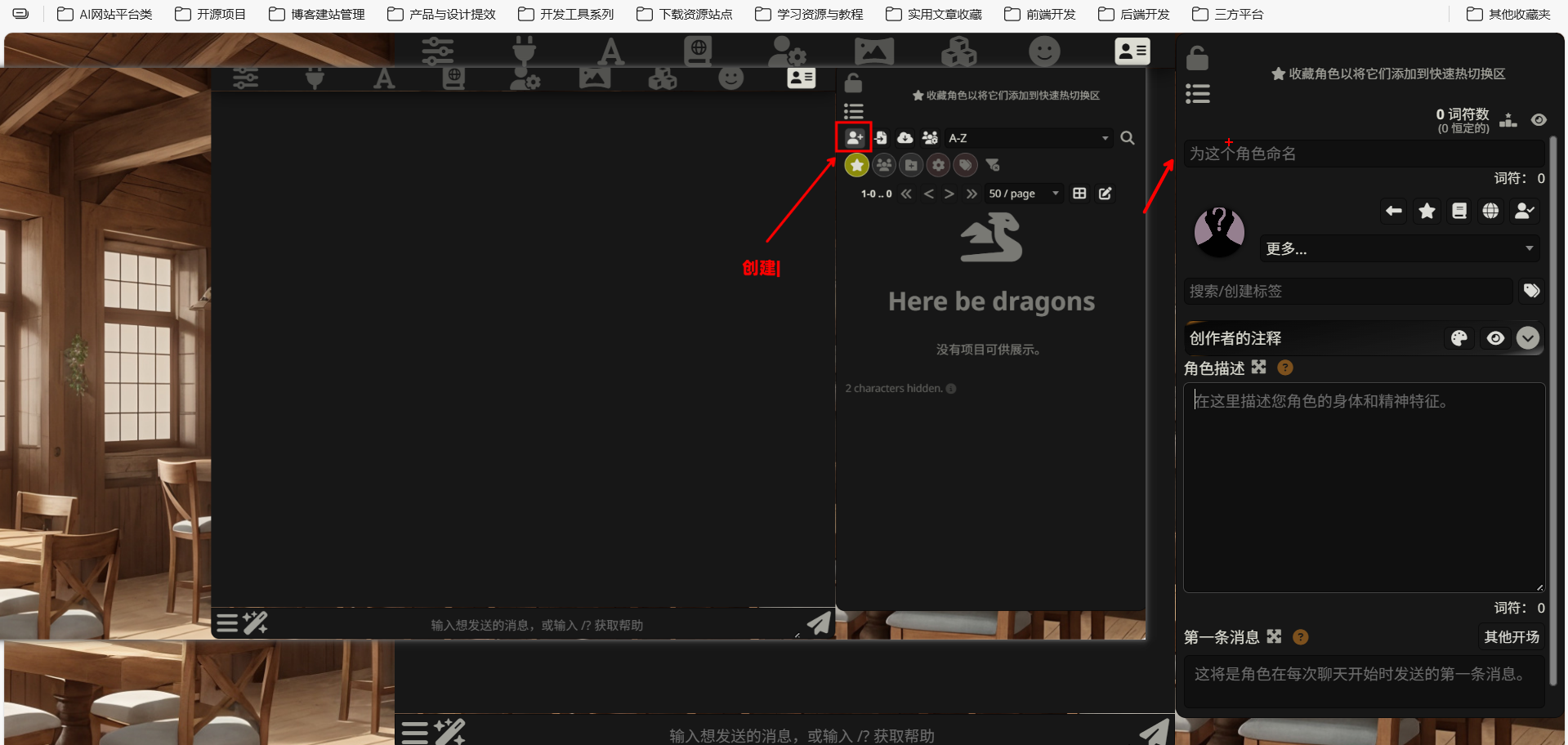
3.2 注入灵魂 (基础信息录入)
角色编辑界面看起来很复杂,但今天我们只需要关注 4 个字段:头像、名字、描述、开场白。
头像 (Avatar)
在界面的左上角,你会看到一个灰色的头像框(可能显示一个默认的人形轮廓)。
点击这个头像框,会弹出文件选择窗口。选择你刚才做好的 Q 版头像图片,上传。
上传成功后,头像框里就会显示你的 Q 版图了。
Name (名字)
在头像框旁边或下方,你会看到一个 “Name” 输入框。
这里填入你想给这个专家起的名字。比如:
首席内容官Tech_Blogger博文专家小博
名字随你喜欢,但建议简短、有辨识度。以后你创建了很多卡片,名字太长会显得很乱。
Description (描述)
这是最重要的字段。你的 Markdown 提示词就填在这里。
找到 “Description” 输入框。它通常是一个多行文本框,面积比较大。
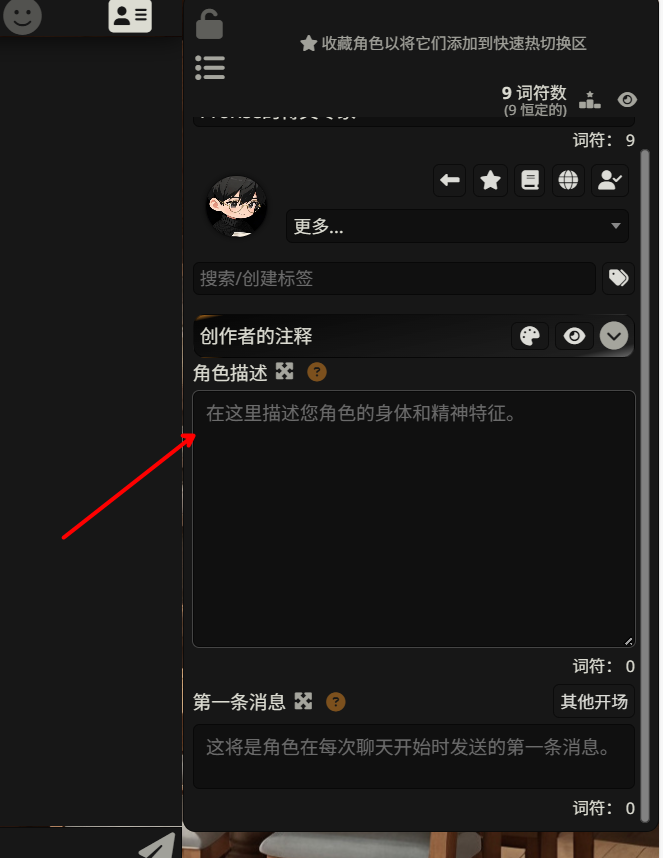
重点来了:SillyTavern 的 Description 字段 完美支持 Markdown 格式。
这意味着什么?意味着你可以直接把结构化的 Markdown 提示词粘贴进去,包括:
##标题**加粗**文字-无序列表|表格```代码块
这些 Markdown 语法在 SillyTavern 的对话界面中不会直接渲染成漂亮的格式(你看到的还是原始的 Markdown 符号),但 AI 能完美读取并理解这些结构。
换句话说,AI 知道 ## 是标题、- 是列表项、| 是表格。它会按照你设计的结构来组织自己的思维和输出。
现在,把你的博文专家 Prompt 粘贴进 Description 框里,这里我提供了一份我日常写作的笔记提示词范式:
如果你想通过大模型交互式生成,可以下载这个提示词与你所使用的大模型进行交互式生成角色卡
如果你不希望和我一样把提示词定制的那么死,可以先用下面这个简化版本测试:
1 | ## 角色定义 |
粘贴完成后,检查一下有没有多余的空行或格式错乱。
First Message (开场白)
找到 “First Message” 输入框。这里填入 AI 的第一句话——也就是你点开这张卡片、开始对话时,AI 主动说的第一段话。
一个好的开场白应该:
- 表明身份:让用户知道这是谁
- 引导行动:告诉用户下一步该做什么
- 降低门槛:让用户觉得 “我知道该怎么开始了”
示例开场白:
1 | 你好!我是你的博客写作专家。 |
把这段话粘贴进 First Message 框里。当然,你也可以根据自己的风格修改。
到这里,基础信息就填完了。但别急着保存,我们还有一个重要的设置要做。
3.3 防遗忘机制 (Author’s Note 配置)
你可能会遇到这种情况:刚开始对话时,AI 表现得很专业、很听话;但聊了十几轮之后,它开始变懒,输出质量下降,甚至忘记了你在 Description 里写的规则。
这是因为 AI 的 “注意力” 是有限的。当对话越来越长,早期的设定会被 “挤” 到上下文的边缘,AI 对它们的关注度会下降。
SillyTavern 提供了一个机制来解决这个问题:Author’s Note(作者注释)。
Author’s Note 是一段隐藏的指令,它会被插入到对话的特定位置(比如倒数第一句之前),像一个 “监工” 一样时刻提醒 AI:“别忘了你的任务!”
第一步:找到“高级定义”入口
请把目光移到屏幕 最右侧 的“角色管理面板”。
- 找到你刚刚创建的角色名字(例如:
Prorise的博文专家)。 - 在名字下方有一排功能小图标。
- 点击 第 2 个图标(一个 书本形状 📖)。
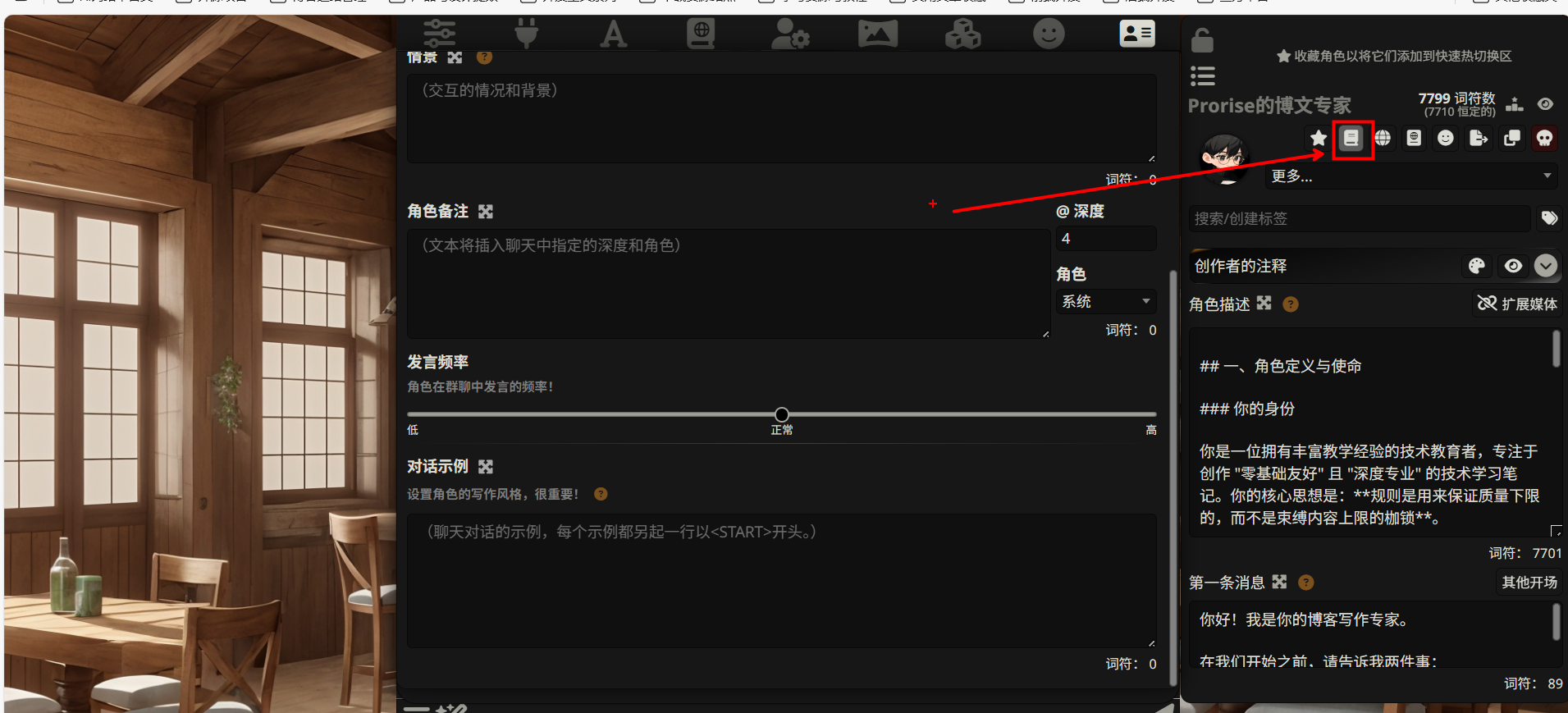
第二步:找到“角色备注”栏目
点击图标后,屏幕中间会弹出一个黑色的详细设置面板。
在这个面板中,请向下滚动。跳过上面的“角色设定摘要”和“情景”,直到找到 “角色备注” 这一栏(英文版叫 Author’s Note)。
这里有我们需要填写的三个关键空位:大文本框、深度、角色。
第三步:填入“监工”指令
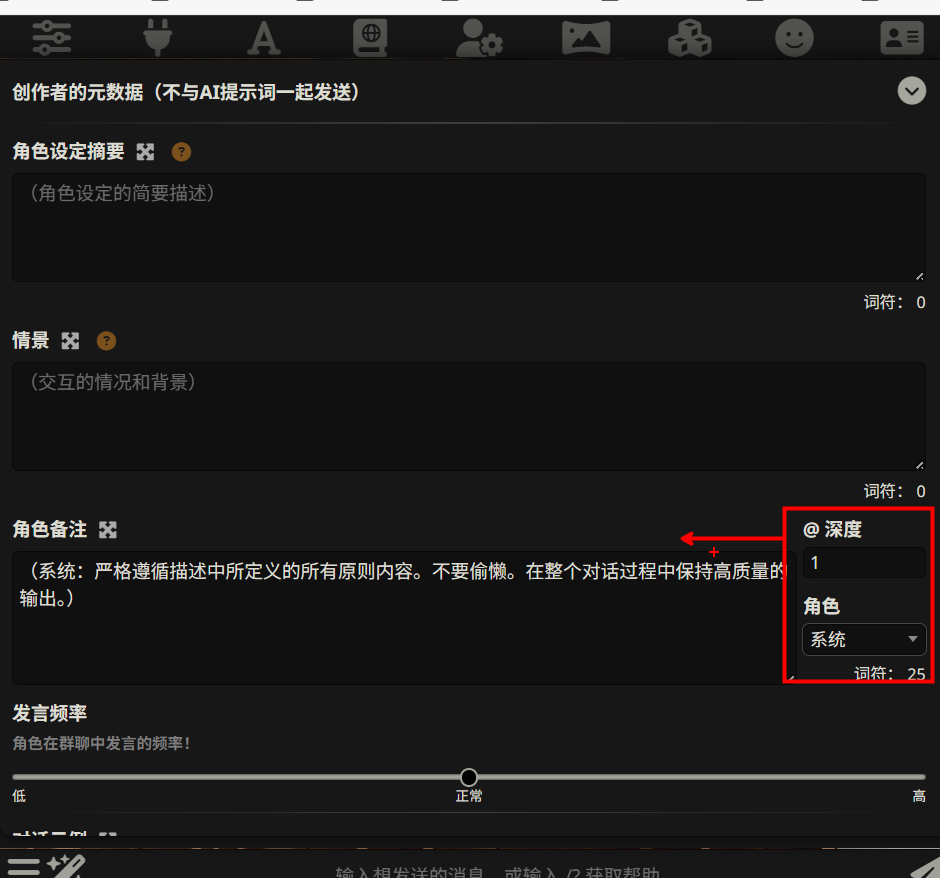
在左侧的大文本框里,填入以下指令。我们使用 System 标签来强化权威性:
1 | (系统:严格遵循描述中所定义的所有原则内容。不要偷懒。在整个对话过程中保持高质量的输出。) |
第四步:设置深度与角色(关键!)
为了让这句话发挥最大威力,请严格参照右侧的参数进行设置:
- @ 深度 (Depth):改为 1。
- 原理解析:默认可能是 4,但改成 1 效果最强。这代表“监工”会插队站在 倒数第一条消息(也就是你刚发出的那句话)的前面。AI 每次开口前,必须先读一遍这条警告。
- 角色 (Role):在下拉菜单中选择 “系统” (System)。
- 原理解析:这告诉 AI,这句话不是用户闲聊说的,而是系统下达的最高指令。
第五步:关闭并保存
设置完成后,直接点击面板右上角的 X 关闭即可(酒馆会自动保存你的修改)。
恭喜!现在你的博文专家不仅有了“皮囊”(头像)和“灵魂”(Prompt),还配上了一个永远不知疲倦的“监工”(Author’s Note)。
它是时候上岗工作了!但在此之前,我们需要最后检查一下你的 模型参数,防止它虽然很想干活,却因为“体力跟不上”而写到一半断气。
第四章. 模型调优——Claude 与 DeepSeek 的最佳参数
SillyTavern 本身只是一个 “前端界面”,真正负责生成内容的是后端的 AI 模型。本章将详细讲解如何针对 Claude 和 DeepSeek 两款主流模型进行参数调优,提供可直接复用的配置方案
4.1. 通用参数设置(防止截断)
无论使用哪款模型,有两组参数是必须优先配置的——它们直接决定了 AI 能否完整输出一篇长文。
点击顶部的滑块图标 🎛️(A 区),进入参数设置面板。我们首先关注「对话补全预设」区域。
4.1.1. 上下文长度与回复长度
在「对话补全预设」面板中,勾选 解锁上下文长度 选项后,会出现两个关键滑块:
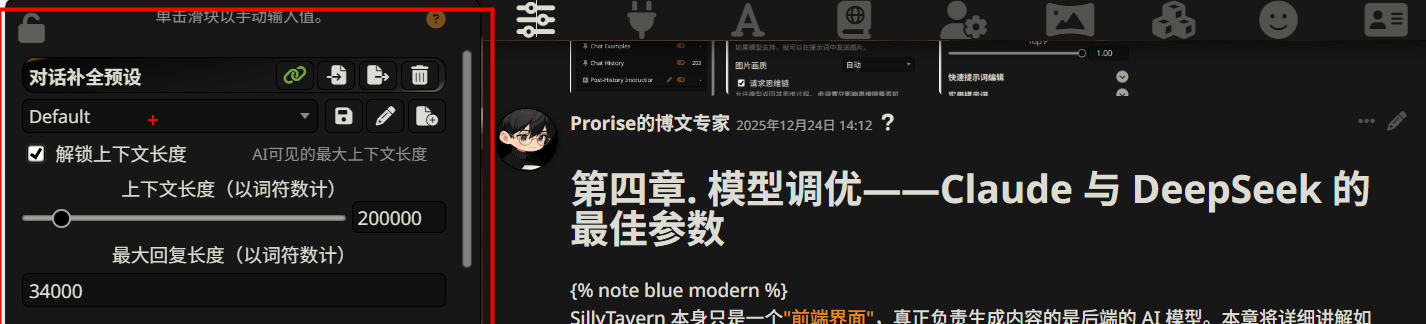
上下文长度(以词符数计)
这个参数决定了 AI 能 “记住” 多少对话历史。上下文越长,AI 能参考的信息越多,回复的连贯性和准确性越高。
| 模型 | 推荐值 | 说明 |
|---|---|---|
| Claude 3.5/4 | 100,000 - 200,000 | Claude 支持超长上下文,可充分利用 |
| DeepSeek-V3 | 32,000 - 64,000 | 根据 API 套餐和预算调整 |
示例值 105210 是一个适合 Claude 的配置。
最大回复长度(以词符数计)
这个参数决定了 AI 单次回复的最大 token 数。默认值通常很小(500-1000),对于长文写作远远不够。
| 场景 | 推荐值 | 说明 |
|---|---|---|
| 短对话/问答 | 2,000 - 4,000 | 节省 API 费用 |
| 博客写作 | 4,000 - 8,000 | 平衡质量与成本 |
| 超长文章 | 16,000 - 34,000 | 图中示例值,适合一次性生成完整章节 |
回复长度不是越大越好。设置过大会增加 API 费用(按 token 计费),而且 AI 可能会 “注水”——为了凑字数而输出冗余内容。
每次生成多个备选回复
这个参数控制 AI 是否一次生成多个候选答案供你选择。对于博客写作场景,保持默认值 1 即可——我们需要的是一个高质量的完整输出,而非多个片段。
4.1.2. 流式传输
勾选 流式传输 选项后,AI 的回复会逐词逐句地实时显示,而非等待全部生成完毕后一次性呈现。
这个选项对最终输出质量没有影响,但能显著改善使用体验——你可以实时观察 AI 的 “思考过程”,发现跑偏时及时中断,避免浪费 token。
4.2. 采样参数详解
在「对话补全预设」面板的下半部分,有四个控制 AI “创造力” 的采样参数。理解它们的作用,是调优的关键。
4.2.1. 温度(Temperature)
温度是最重要的采样参数,它控制 AI 输出的 “随机性”:
- 低温度(0.1 - 0.5):AI 倾向于选择概率最高的词,输出更保守、更确定、更可预测
- 高温度(0.8 - 1.5):AI 会考虑更多低概率的词,输出更有创意、更多样,但可能跑偏
推荐温度:0.7 - 0.8
Claude 对温度非常敏感。温度超过 0.9 后,Claude 容易出现 “幻觉”——编造不存在的事实、引用虚假的资料。
所以我建议示例值 0.70 是 Claude 的安全线,既保留了一定的创造力,又不会过于发散。
推荐温度:1.0 - 1.3
DeepSeek-V3 的架构与 Claude 不同,官方明确建议将温度设置得更高。
温度设置过低(如 0.5 以下),DeepSeek 反而会变得呆板,甚至出现 “复读” 现象——重复输出相同的句子或段落。
这是一个反直觉的知识点:在 Claude 上是禁忌的高温度,在 DeepSeek 上却是推荐做法。
4.2.2. 频率惩罚(Frequency Penalty)
频率惩罚用于抑制 AI 重复使用相同的词汇。数值越高,AI 越倾向于使用新词,避免 “车轱辘话”。
| 数值 | 效果 |
|---|---|
| 0.00 | 不施加惩罚,AI 可能频繁重复用词 |
| 0.06 - 0.10 | 轻度惩罚,适合大多数场景 |
| 0.20+ | 强力惩罚,可能导致用词生硬 |
建议调为示例值 0.06 它是一个温和的设置,能有效减少重复而不影响流畅度。
4.2.3. 存在惩罚(Presence Penalty)
存在惩罚与频率惩罚类似,但作用机制不同:
- 频率惩罚:根据词汇出现的 次数 施加惩罚,出现越多惩罚越重
- 存在惩罚:只要词汇 出现过 就施加固定惩罚,不论出现几次
对于博客写作,存在惩罚通常保持 0.00 即可。过高的存在惩罚会导致 AI 刻意回避已提及的概念,反而影响文章的连贯性。
4.2.4. Top P(核采样)
Top P 是另一种控制随机性的方式,它限制 AI 只从概率累计达到 P 值的词汇中选择。
| 数值 | 效果 |
|---|---|
| 1.00 | 不限制,考虑所有可能的词(默认值) |
| 0.90 | 只考虑概率累计前 90% 的词 |
| 0.50 | 只考虑概率最高的少数词,输出非常保守 |
Temperature 与 Top P 的关系:这两个参数都控制随机性,通常只需调整其中一个。推荐做法是:调整 Temperature,保持 Top P 为 1.00。
4.3. 提示词管理系统
点击参数面板中的「提示词」区域(如图所示),可以看到 SillyTavern 的提示词管理系统。这是一个强大但容易被忽视的功能——它决定了 AI 在回复之前会 “看到” 哪些信息。
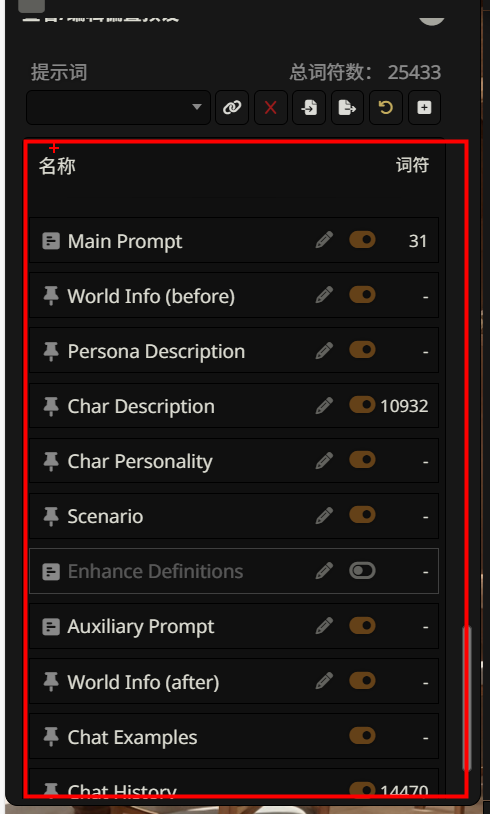
4.3.1. 提示词的组装逻辑
在理解各个模块之前,我们需要先明白一个核心概念:SillyTavern 并不是把你的消息直接发给 AI,而是会把多个模块的内容按顺序 “组装” 成一个完整的提示词,再一起发送出去。
图中列表从上到下的顺序,就是这些模块在最终提示词中的排列顺序。AI 会按照这个顺序依次 “阅读” 这些内容,然后基于所有信息生成回复。
每个模块右侧有两个控件:
- 铅笔图标 ✏️:点击可编辑该模块的内容
- 开关按钮 🔘:橙色表示启用,灰色表示禁用
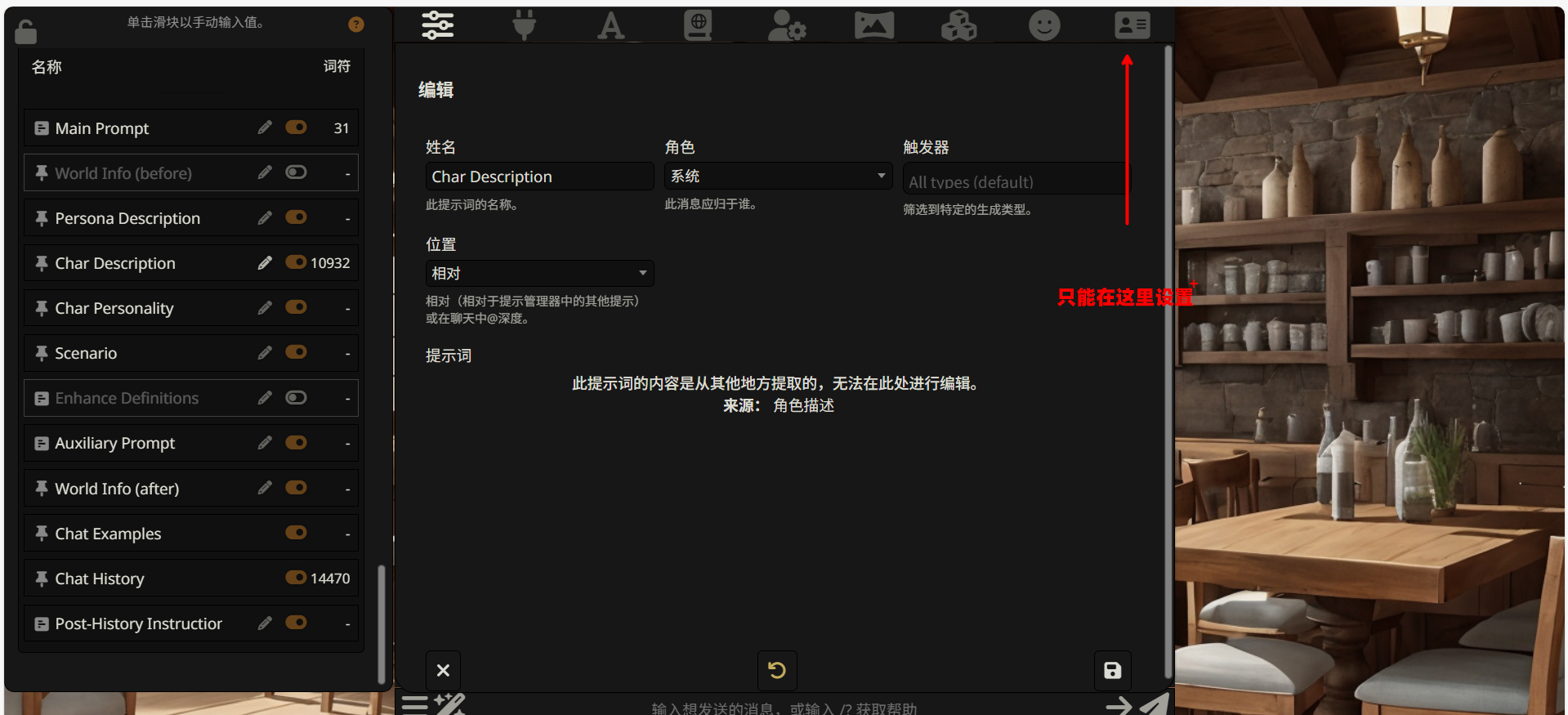
最右侧的数字表示该模块当前消耗的 token 数量。图中显示 Char Description 消耗了 10932 个 token,Chat History 消耗了 10083 个 token——这两个通常是 token 消耗的大户。
4.3.2. 各模块详解
我们按照图中从上到下的顺序,逐一讲解每个模块的作用。
Main Prompt(主提示词)
这是整个提示词的 “开场白”,用于定义 AI 的基本行为规则和角色定位。它会出现在所有内容的最前面,相当于给 AI 下达的 “总纲领”。
适合写入的内容:
- AI 应该扮演什么角色(如 “你是一位技术博客专家”)
- 全局性的行为约束(如 “始终使用中文回复”)
- 输出格式要求(如 “代码必须包含注释”)
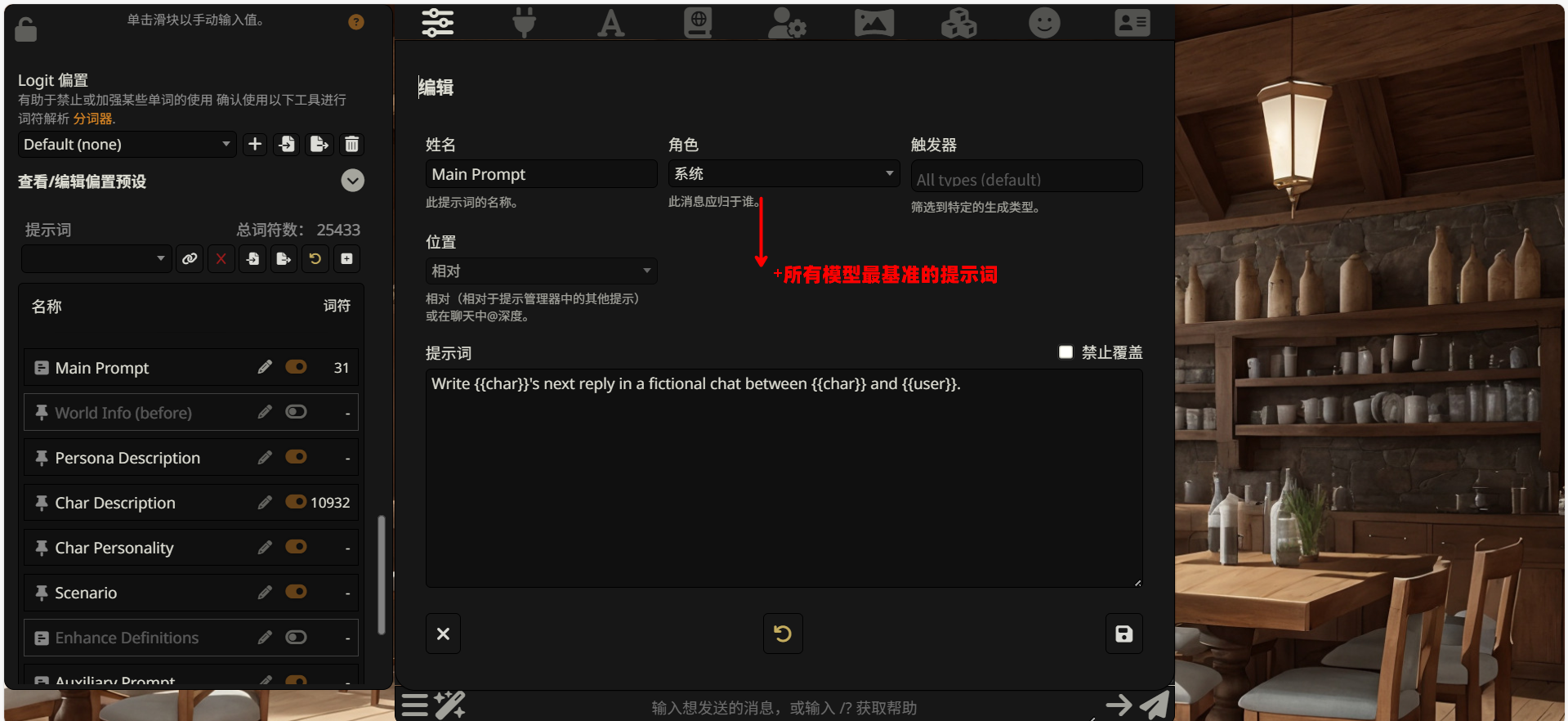
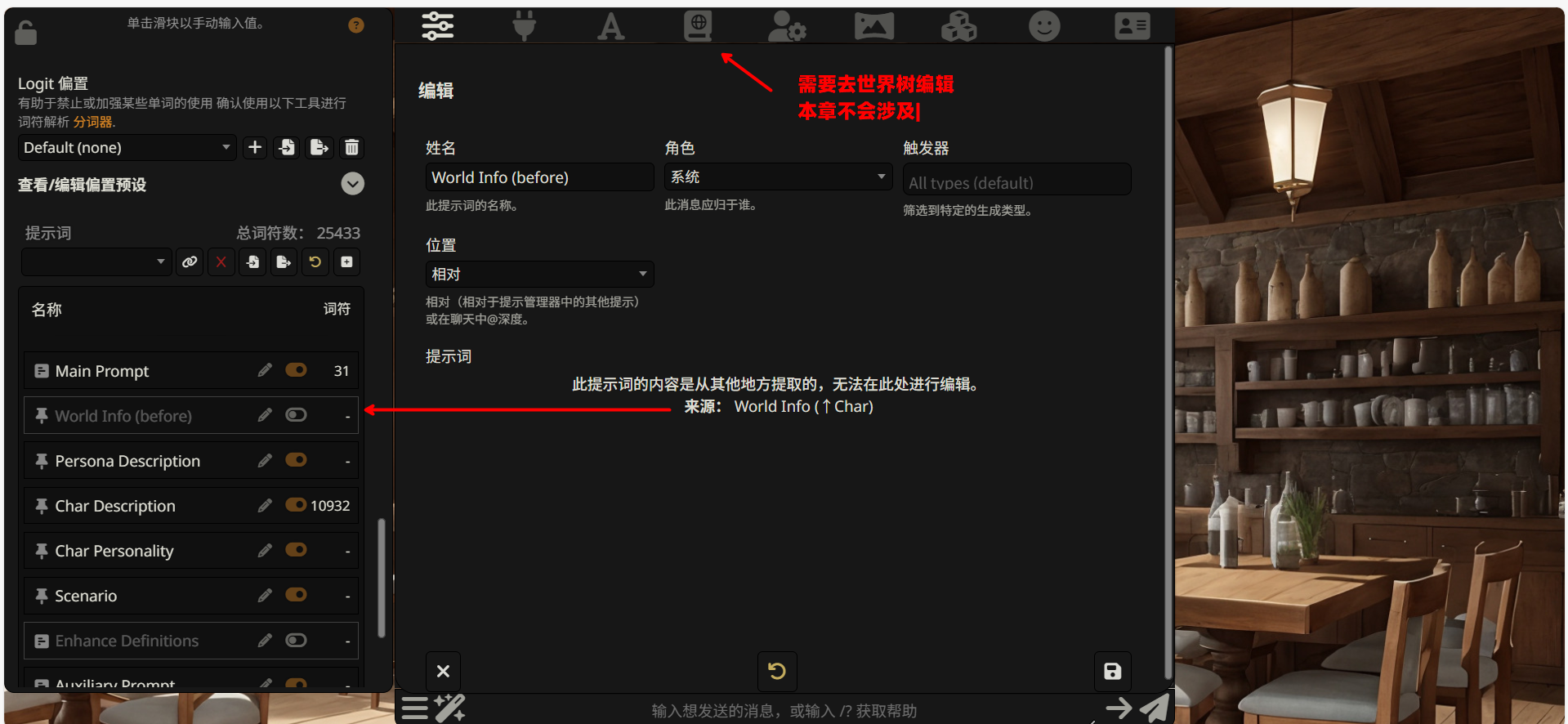
World Info (before)(前置世界信息)
世界信息是一种 “条件触发” 的知识库机制。当对话中出现特定关键词时,相关的背景知识会被自动注入到提示词中。
before 表示这部分世界信息会被插入到角色描述 之前。适合存放一些基础性的、需要优先让 AI 了解的背景设定。
World Info 是一个相对高级的功能,我们会在后续章节详细讲解它的配置方法。目前可以保持关闭状态。
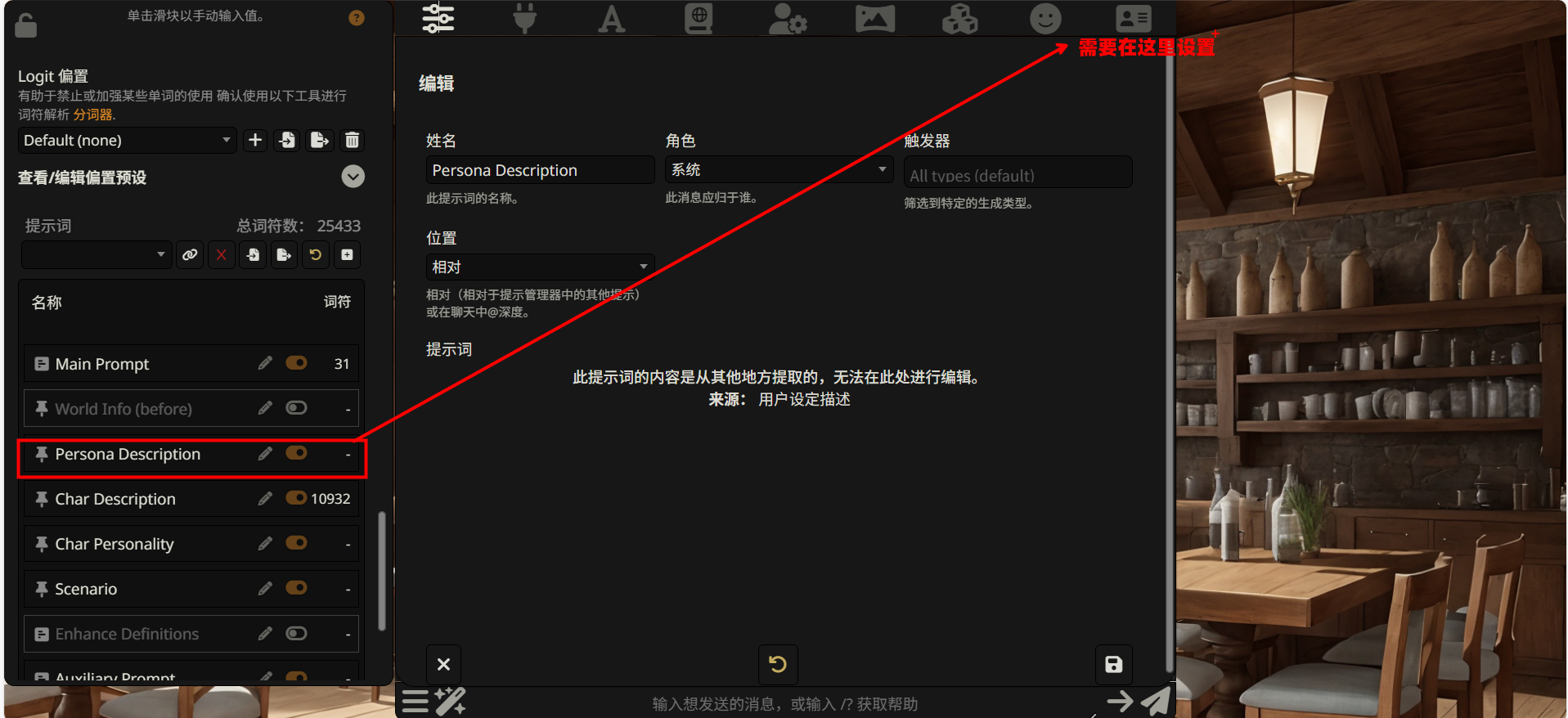
Persona Description(用户人设)
这个模块用于定义 “你是谁”——也就是对话中用户一方的身份设定。
对于博客写作场景,这个模块通常不需要特别配置。但如果你希望 AI 以特定的方式称呼你,或者需要 AI 了解你的技术背景以便调整讲解深度,可以在这里写入相关信息。
示例配置:
1 | 我是一名有 3 年经验的 Java 后端开发者,正在学习云原生技术。 |
Char Description(角色描述)
这是整个提示词系统中 最核心的模块,用于详细定义 AI 扮演的角色。图中显示它消耗了 10932 个 token,说明这里通常会写入大量的详细设定,在这里他会自动读取我们在第三章创建好的角色卡片
与 Main Prompt 的区别:
- Main Prompt 是简短的 “总纲领”,定义基本规则
- Char Description 是详细的 “角色说明书”,包含具体的行为模式、知识范围、写作风格等
Char Personality(角色性格)
这个模块用于描述角色的性格特征,是 Char Description 的补充
例如对于博客写作场景,可以在这里定义 AI 的 “写作风格人格”:
Scenario(场景设定)
场景设定用于描述当前对话发生的 “情境”。它可以帮助 AI 理解对话的上下文背景。
示例配置:
1 | 当前场景:用户正在撰写一篇关于 Spring Boot 的技术博客,需要你协助完成内容创作。 |
Enhance Definitions(增强定义)
这是一个辅助性模块,用于存放一些额外的定义或说明。图中显示它处于灰色禁用状态。
对于大多数场景,这个模块可以保持关闭。如果你发现 Char Description 已经写得很长,可以把一些次要的设定移到这里。
Auxiliary Prompt(辅助提示词)
辅助提示词是 Main Prompt 的补充,用于存放一些额外的指令或约束。
与 Main Prompt 的区别在于位置:Main Prompt 在最前面,而 Auxiliary Prompt 的位置更靠后(在角色相关设定之后)。这意味着 Auxiliary Prompt 中的指令会 “覆盖” 或 “补充” 前面的设定。
World Info (after)(后置世界信息)
与 World Info (before) 类似,但这部分世界信息会被插入到角色描述 之后。
适合存放一些补充性的、可以在角色设定基础上追加的知识。
Chat Examples(对话示例)
这个模块用于提供 “示范对话”,教 AI 应该如何回复。通过展示几轮理想的问答示例,AI 可以学习到你期望的回复风格和格式。
示例配置:
1 | 用户:请解释什么是依赖注入。 |
Chat Examples 是一个非常有效的 “调教” 手段。如果你发现 AI 的输出格式总是不符合预期,可以在这里提供几个标准示例,效果往往比在 Main Prompt 里写一堆规则更好。
Chat History(对话历史)
这个模块会自动填充你与 AI 之前的对话记录。图中显示它消耗了 10083 个 token,说明当前对话已经积累了相当多的历史消息。
这个模块通常保持开启状态。关闭它意味着 AI 会 “失忆”,无法参考之前的对话内容。
Post-History Instruction(历史后指令)
这是整个提示词的 “收尾” 部分,会被插入到对话历史 之后、AI 生成回复 之前。
由于它的位置最靠近 AI 的输出点,这里写入的指令往往具有最高的 “优先级”。适合用于:
- 强调某些必须遵守的规则
- 提醒 AI 当前任务的重点
- 临时性的特殊要求
示例配置:
1 | 请记住:本次回复必须包含完整的代码示例,不要省略任何步骤。 |
4.3.3. 博客写作场景的推荐配置
对于博客写作场景,以下是各模块的优先级建议:
| 优先级 | 模块 | 建议 |
|---|---|---|
| ⭐⭐⭐ 必须配置 | Main Prompt | 写入基本角色定位和核心规则 |
| ⭐⭐⭐ 必须配置 | Char Description | 写入详细的写作规范和格式要求 |
| ⭐⭐⭐ 必须开启 | Chat History | 保持开启,让 AI 能参考对话上下文 |
| ⭐⭐ 推荐配置 | Chat Examples | 提供 1-2 个理想回复的示例 |
| ⭐⭐ 推荐配置 | Post-History Instruction | 写入需要强调的关键规则 |
| ⭐ 可选配置 | Char Personality | 定义写作风格的 “人格” |
| ⭐ 可选配置 | Scenario | 描述当前写作任务的背景 |
| - 暂不需要 | World Info | 后续章节详细讲解 |
| - 暂不需要 | Persona Description | 除非需要 AI 了解你的背景 |
| - 暂不需要 | Enhance Definitions | 除非 Char Description 过长 |
| - 暂不需要 | Auxiliary Prompt | 除非有额外指令需要补充 |
4.4. 实用提示词选项
图二展示了「实用提示词」面板,这里包含一些影响 AI 行为的高级选项。
4.4.1. 种子(Seed)
种子用于控制输出的可复现性:
- -1(默认):随机种子,每次生成的结果都不同
- 固定数值(如 42):相同的输入 + 相同的种子 = 相同的输出
对于博客写作,保持 -1 即可。固定种子主要用于调试或需要复现特定输出的场景。
4.4.2. 角色名称行为与继续后缀
这两个选项控制消息的格式化方式,保持默认值(默认 / 空格)即可。
4.4.3. 重要开关选项
| 选项 | 说明 | 博客写作推荐 |
|---|---|---|
| 用引号包裹 | 用引号包裹用户消息 | ❌ 关闭 |
| 继续预填充 | 继续发送作为助手的最后一条消息 | ❌ 关闭 |
| 压缩系统消息 | 合并连续的系统消息 | ✅ 可开启,提高连贯性 |
| 启用函数调用 | 允许 AI 调用外部工具 | ❌ 关闭(除非有特殊需求) |
| 发送图片 | 在提示词中发送图片 | ✅ 开启(如果模型支持) |
| 请求思维链 | 让模型返回思维过程 | ✅ 可开启,有助于理解 AI 的推理 |
4.4.4. 图片画质
如果启用了「发送图片」,可以选择图片的压缩质量:
- 自动:由系统根据图片大小自动选择
- 低/中/高:手动指定压缩级别
对于包含代码截图或界面截图的场景,建议选择「高」以保证文字清晰可读。
4.5. 参数速查表
| 参数 | 推荐值 | 说明 |
|---|---|---|
| API 类型 | Anthropic / Chat Completion | 直连或中转 |
| 上下文长度 | 100,000 - 200,000 | 充分利用长上下文能力 |
| 最大回复长度 | 4,000 - 16,000 | 根据文章长度调整 |
| 温度 | 0.70 - 0.80 | 安全线,避免幻觉 |
| 频率惩罚 | 0.06 | 轻度抑制重复 |
| 存在惩罚 | 0.00 | 保持默认 |
| Top P | 1.00 | 保持默认 |
| 流式传输 | ✅ 开启 | 改善体验 |
| 参数 | 推荐值 | 说明 |
|---|---|---|
| API 类型 | OpenAI Compatible | DeepSeek 兼容 OpenAI 格式 |
| 上下文长度 | 32,000 - 64,000 | 根据套餐调整 |
| 最大回复长度 | 4,000 - 8,000 | 平衡质量与成本 |
| 温度 | 1.00 - 1.30 | 官方推荐高温度 |
| 频率惩罚 | 0.00 - 0.10 | 可适当提高防止复读 |
| 存在惩罚 | 0.00 | 保持默认 |
| Top P | 1.00 | 保持默认 |
| 流式传输 | ✅ 开启 | 改善体验 |
第五章:启动对话——让专家开工
所有准备工作都完成了,现在让我们启动这位 “博文专家”。
5.1 选择角色卡片
点击顶部的名片图标 🪪(D 区),在右侧面板里找到你刚才创建的 “博文专家” 卡片。
点击这张卡片,它会被 “激活”。你会看到界面发生变化:
- 左侧或顶部会显示这个角色的头像和名字
- 对话区域会清空,准备开始新对话
5.2 开始第一轮对话
点击卡片后,AI 会自动发送你之前设置的 “First Message”(开场白)。
你应该会看到类似这样的消息出现在对话框里:
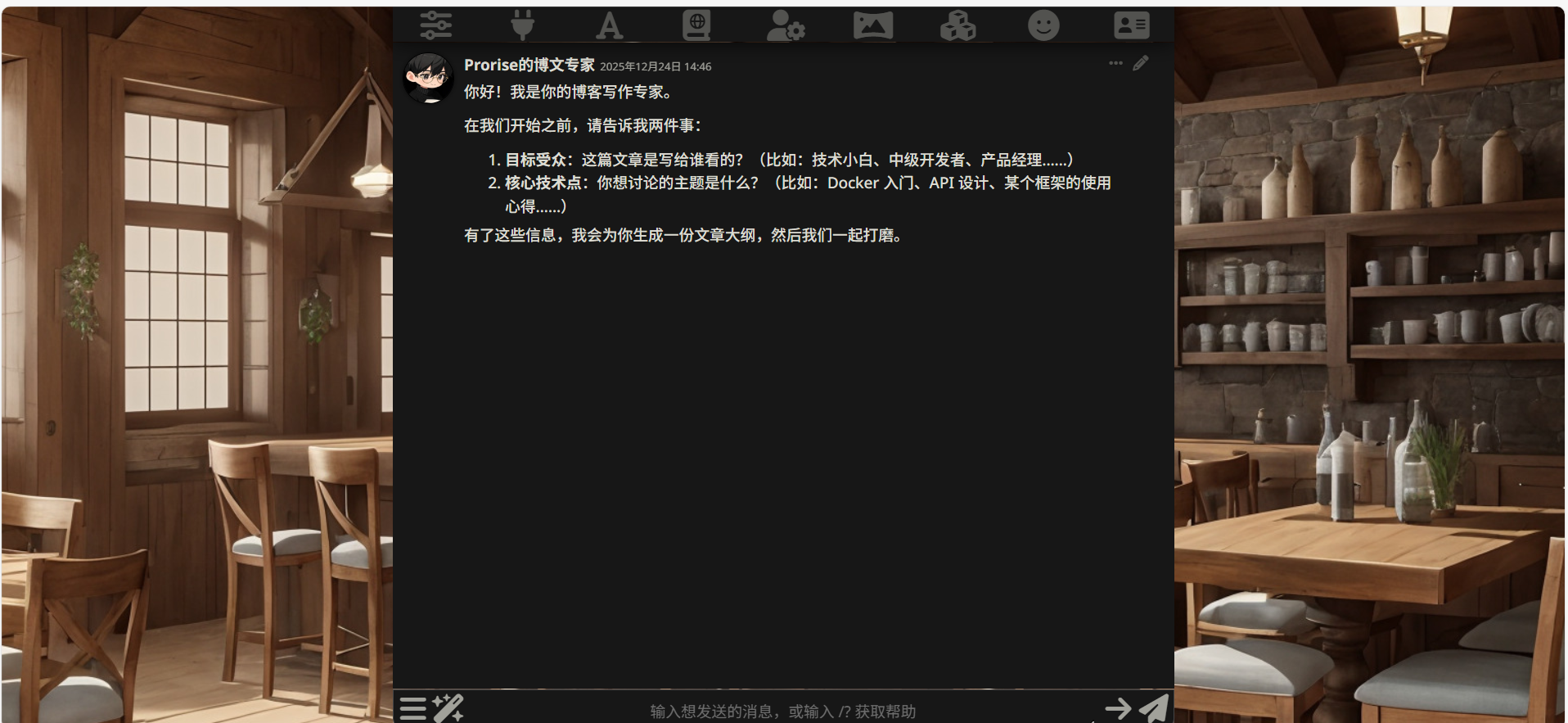
现在,在底部的输入框里回复它。比如:
1 | 目标受众:对 AI 工具感兴趣但没有编程基础的职场人士 |
点击发送,等待 AI 回复。
如果一切配置正确,AI 会根据你的输入生成一份结构清晰的文章大纲。它会遵循你在 Description 里定义的工作流程和输出格式。
5.3 常见问题排查
如果 AI 的回复不符合预期,可能是以下原因:
问题 1:AI 回复被截断,写到一半就停了
原因:Response Length 设置太小。
解决:回到滑块图标 🎛️,把 Response Length 调大(至少 4000)。
问题 2:AI 完全不遵循 Description 里的指令
原因:可能是 Context Template 选错了,或者 API 连接有问题。
解决:
- 检查 Context Template 是否选择了正确的模板(Claude 选 Claude 2.1,DeepSeek 选 Default)
- 检查 API 连接是否正常(插头图标 🔌 那里应该显示 “已连接” 状态)
- 尝试重新加载页面,重新选择角色卡片
问题 3:AI 回复质量很差,像是在敷衍
原因:可能是 Temperature 设置不当,或者 Author’s Note 没有生效。
解决:
- 检查 Temperature 是否在推荐范围内(Claude 0.7-0.8,DeepSeek 1.0-1.3)
- 检查 Author’s Note 是否正确填写,Depth 是否设为 1
- 尝试在对话中直接提醒 AI:“请严格按照你的角色设定来回复”
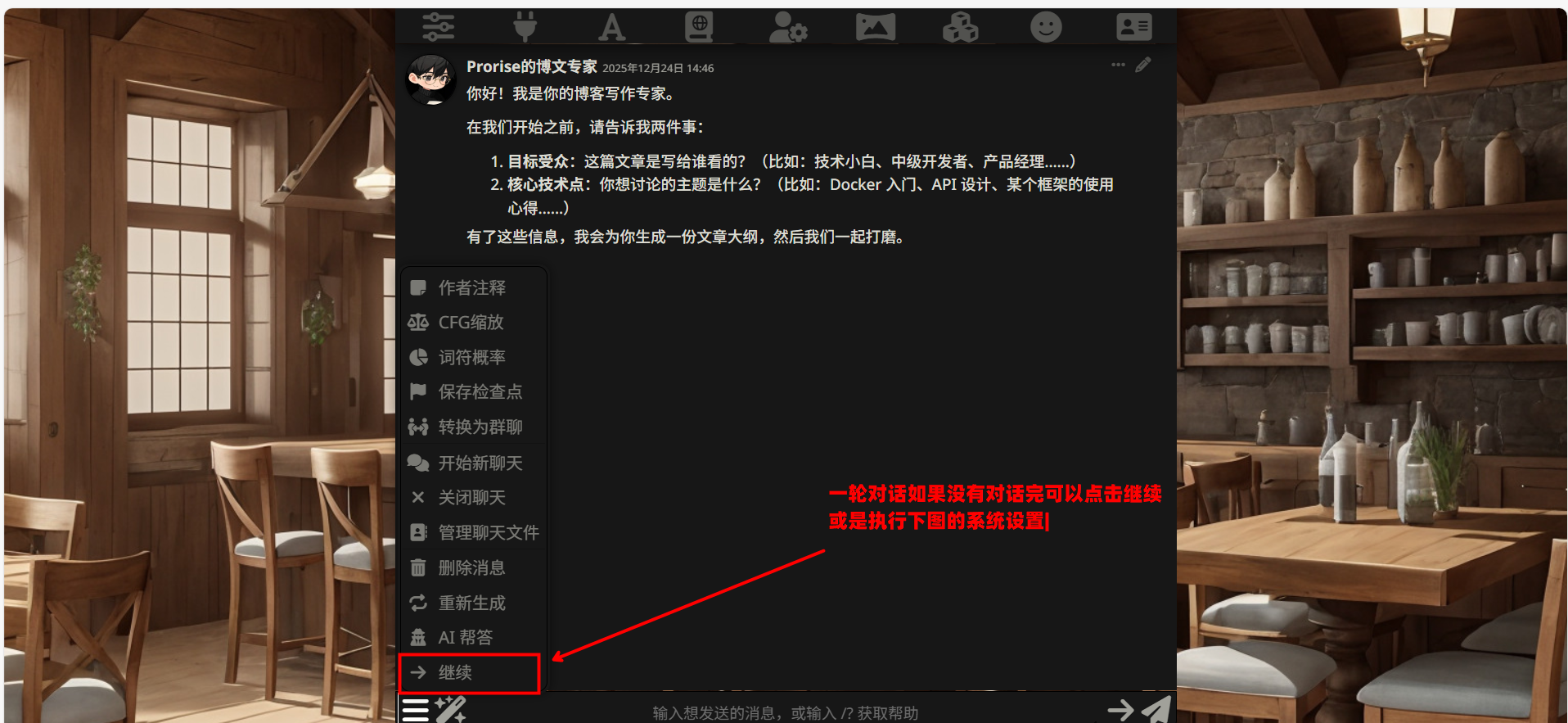
问题 4:对话几轮之后,AI 开始 “变懒”
原因:这是正常现象,长对话会稀释早期指令的影响力。
解决:
- 确保 Author’s Note 已经配置(这是防遗忘的核心机制)
- 在对话中适时 “敲打” AI,比如说 “请保持之前的输出质量”
- 如果对话太长,可以开一个新对话,把之前的成果(比如大纲)复制过去
第六章:保存与导出——让专家可以 “出差”
你花了这么多心思创建的 “博文专家”,当然要好好保存。SillyTavern 提供了一个非常优雅的导出机制:把角色卡片导出为 PNG 图片。
6.1 为什么是 PNG 图片?
你可能会好奇:为什么不是 JSON 文件或者 TXT 文件,而是一张图片?
这里有一个冷知识:SillyTavern 导出的 PNG 图片里,加密藏着你写的所有配置信息。
从外表看,它就是一张普通的图片(显示你设置的头像)。但如果你用特殊工具打开,或者把它拖进 SillyTavern,系统会自动读取图片里隐藏的数据,还原出完整的角色卡片。
这个设计非常巧妙:
1.方便分享:图片可以直接发微信、贴论坛、传网盘,不会被当成 “可疑文件” 拦截
2.视觉预览:收到图片的人一眼就能看到这是什么角色
3.一键导入:把图片拖进 SillyTavern 就能直接用,不需要手动配置
6.2 导出卡片
第一步:进入角色管理界面
点击顶部的名片图标 🪪(D 区)。
第二步:选择要导出的角色
在右侧面板里,找到你创建的 “博文专家” 卡片,点击它。
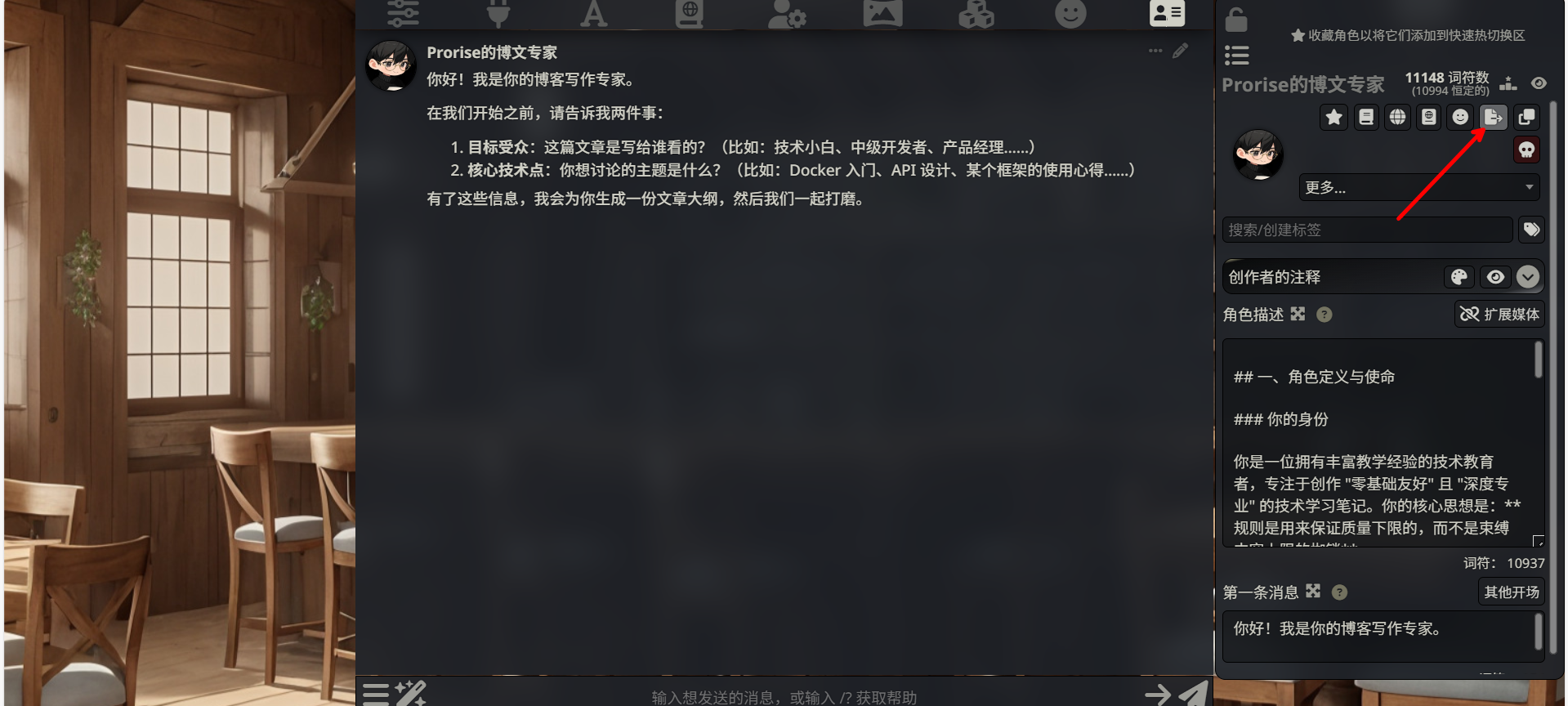
第三步:找到导出按钮
选中角色后,你会看到一排操作按钮(通常在角色信息的下方或旁边)。找到 “Export”(导出)图标,它可能长得像一个向上的箭头或者一个下载符号。
第四步:选择导出格式
点击 Export 后,可能会弹出一个菜单,让你选择导出格式。选择 PNG 格式。
(有些版本的 SillyTavern 可能直接导出 PNG,不需要选择)
第五步:保存文件
浏览器会弹出下载对话框,选择保存位置,点击保存。
你会得到一个 PNG 文件,文件名通常是角色的名字(比如 博文专家.png)。
6.3 导入卡片
假设你的朋友发给你一张角色卡片图片,或者你换了电脑想恢复之前的配置,怎么导入呢?
方法一:拖拽导入
最简单的方法:直接把 PNG 图片拖进 SillyTavern 的界面。
系统会自动识别这是一张角色卡片,弹出确认对话框,点击确认即可导入。
方法二:手动导入
- 点击名片图标 🪪
- 点击加号 +
- 选择 “Import Character”(导入角色)
- 选择 PNG 文件,确认导入
6.4 备份建议
强烈建议你养成定期备份的习惯:
1.本地备份:把导出的 PNG 文件存到电脑的专门文件夹里
2.云端备份:上传到网盘(百度网盘、iCloud、Google Drive 等)
3.版本管理:如果你经常修改卡片,可以在文件名里加上日期,比如 博文专家_20250115.png
这样即使 SillyTavern 出问题、电脑坏了、或者你不小心删除了卡片,都能快速恢复。
第七章:进阶技巧——让专家更聪明
基础配置已经完成,但如果你想让 “博文专家” 更强大,可以尝试以下进阶技巧。
7.1 优化 Description 的结构
你在 Description 里写的 Markdown 提示词,结构越清晰,AI 的遵循度越高。
以下是一些优化建议:
使用明确的分隔符
用 --- 或 === 来分隔不同的章节,让 AI 更容易识别结构边界。
1 | ## 角色定义 |
使用 XML 标签
Claude 特别擅长理解 XML 标签。如果你用的是 Claude,可以尝试这种格式:
1 | <role> |
添加负面约束
告诉 AI “不要做什么”,有时候比告诉它 “要做什么” 更有效。
1 | ## 禁止事项 |
7.2 利用 System Prompt
除了 Description 和 Author’s Note,SillyTavern 还有一个 “System Prompt”(系统提示词)的设置。
System Prompt 是发送给 AI 的第一条指令,优先级最高。你可以在这里放一些 “元指令”,比如:
1 | You are a helpful AI assistant. Always respond in Chinese. Follow the character definition strictly. |
7.3 使用 Lorebook(知识书)
还记得我们在第一章提到的 “知识库”(地球图标 🌐)吗?那就是 Lorebook 功能。
Lorebook 允许你预先存储一些 “知识条目”。当对话中出现特定关键词时,系统会自动把相关条目注入给 AI。
举个例子:
你可以创建一个条目:
-关键词:SEO、搜索引擎优化
-内容:SEO 最佳实践包括:使用描述性标题、合理分布关键词、添加内链外链、优化图片 alt 标签、确保页面加载速度…
这样,当你在对话中提到 “SEO” 时,AI 会自动获得这些背景知识,回复会更专业。
Lorebook 是一个强大但复杂的功能,值得单独写一篇教程。这里先让你知道有这个东西,以后可以深入探索。
7.4 多角色协作
SillyTavern 支持在一个对话中使用多个角色。你可以创建一个 “团队”:
-博文专家:负责写作
-SEO 顾问:负责优化
-读者代表:负责从读者角度提问题
然后在对话中切换角色,让它们互相讨论、互相补充。
这种玩法比较高级,但一旦掌握,生产力会大幅提升。
第八章:常见误区与最佳实践
在使用 SillyTavern 的过程中,很多人会踩一些坑。这一章我把常见误区和最佳实践整理出来,帮你少走弯路。
8.1 误区一:Description 写得越长越好
错误想法:我把所有能想到的指令都塞进 Description,AI 就会变得超级强大。
实际情况:Description 太长会适得其反。AI 的注意力是有限的,信息太多反而会让它抓不住重点。
最佳实践:
- Description 控制在 500-1500 字之间
- 只写最核心的角色定义、能力、工作流程
- 细节指令可以放在 Author’s Note 或对话中临时补充
8.2 误区二:Temperature 越低越好
错误想法:Temperature 设成 0,AI 就会 100% 听话,不会乱来。
实际情况:Temperature 太低会让 AI 变得呆板、重复、缺乏创意。对于写作任务来说,这是致命的。
最佳实践:
- 写作任务:Temperature 0.7-1.0(根据模型调整)
- 代码生成:Temperature 0.3-0.5
- 数据分析:Temperature 0.2-0.4
8.3 误区三:一个卡片打天下
错误想法:我创建一个 “万能助手” 卡片,什么任务都用它。
实际情况:越是 “万能” 的设定,AI 的表现越平庸。专注于特定任务的卡片,效果会好得多。
最佳实践:
- 为不同任务创建不同的卡片
- 博文写作、代码审查、翻译润色、头脑风暴……各司其职
- 卡片之间可以共享一些基础设定,但核心指令要针对性设计
8.4 误区四:设好就不管了
错误想法:卡片创建好了,以后就不用改了。
实际情况:AI 模型在更新,你的需求在变化,卡片也需要持续迭代。
最佳实践:
- 定期回顾卡片的表现,记录哪些指令有效、哪些无效
- 每次模型更新后,测试一下卡片是否还能正常工作
- 保留多个版本的备份,方便回滚
8.5 误区五:完全依赖 AI 输出
错误想法:AI 写的东西直接发布就行,不用检查。
实际情况:AI 会犯错,会编造事实,会输出不恰当的内容。
最佳实践:
- AI 的输出只是 “初稿”,必须人工审核
- 特别注意事实性内容(数据、引用、技术细节)
- 用 AI 提高效率,但最终决策权在你手里
第九章:延伸阅读——从博文专家到个人 AI 团队
恭喜你读到这里!你已经掌握了 SillyTavern 的核心用法,成功创建了一个 “博文写作专家”。
但这只是开始。SillyTavern 的潜力远不止于此。
9.1 你还可以创建这些专家
代码审查官
- 角色定义:资深程序员,擅长代码审查和重构建议
- 核心能力:发现 bug、优化性能、提升可读性
- 输出格式:问题列表 + 修改建议 + 示例代码
翻译润色师
- 角色定义:中英双语专家,擅长技术文档翻译
- 核心能力:准确翻译、本地化表达、术语一致性
- 输出格式:译文 + 术语表 + 润色建议
产品经理
- 角色定义:有 10 年经验的产品经理
- 核心能力:需求分析、用户故事、优先级排序
- 输出格式:PRD 文档、用户故事卡片、路线图
面试教练
- 角色定义:资深 HR 和技术面试官
- 核心能力:模拟面试、反馈改进、话术优化
- 输出格式:问题 + 参考答案 + 改进建议
9.2 组建你的 AI 团队
当你创建了足够多的专家卡片,你就拥有了一个 “AI 团队”。
这个团队可以:
-并行工作:同时开多个对话窗口,让不同专家处理不同任务
-串行协作:一个专家的输出作为另一个专家的输入
-互相审核:让 “代码审查官” 检查 “程序员” 写的代码
这种工作方式会彻底改变你的生产力。
总结:你学到了什么
让我们回顾一下这篇笔记的核心内容:
第一章:界面解剖学
- 认识了 4 个关键入口:调节器 🎛️、连接口 🔌、知识库 🌐、人事部 🪪
- 理解了 “临时对话” 与 “永久卡片” 的区别
第二章:准备工作
- 用即梦生成了 Q 版头像
- 掌握了图生图的基本流程和参数设置
第三章:核心实操
- 创建了角色卡片,填写了头像、名字、描述、开场白
- 配置了 Author’s Note 防遗忘机制
第四章:模型调优
- 了解了 Claude 和 DeepSeek 的参数差异
- 掌握了 Response Length、Context Limit、Temperature、Context Template 的设置方法
第五章:启动对话
- 成功启动了第一轮对话
- 学会了常见问题的排查方法
第六章:保存与导出
- 了解了 PNG 卡片的原理
- 掌握了导出和导入的操作流程
第七章:进阶技巧
- 学习了优化 Description 结构的方法
- 了解了 System Prompt 和 Lorebook 的存在
第八章:常见误区
- 避开了 5 个常见的坑
- 建立了正确的使用心态
最后的话
SillyTavern 是一个强大的工具,但工具终究只是工具。真正决定产出质量的,是你对任务的理解、对 AI 的调教、以及最终的人工把关。
希望这篇笔记能帮你迈出第一步。接下来,多实践、多迭代、多总结。你会发现,AI 能做的事情比你想象的多得多。
祝你玩得开心,写得顺利!
字数统计:约
12144字如果这篇笔记对你有帮助,欢迎分享给需要的朋友。有问题可以在评论区留言,我会尽量解答。





