
Prorise
这是我的博客,分享技术与生活的点点滴滴
🍺 SillyTavern(酒馆)- SillyTavern 核心理念教程——从“聊天框”到“人工智能操作系统”
🍺 SillyTavern(酒馆)- SillyTavern 核心理念教程——从“聊天框”到“人工智能操作系统”
ProriseSillyTavern 核心理念——从"聊天框"到"人工智能操作系统"
字数预计: 深度长文
阅读难度: 进阶
核心议题: 中间件架构、数据主权、多模型编排
前言:打破"玩具"的刻板印象
在绝大多数人的认知里,SillyTavern(酒馆)是一个用来"跑团"或者和"二次元角色"谈情说爱的玩具。如果你也是这么认为的,那么你正在把一台超级计算机当成计算器使用。
这种误解的根源在于 SillyTavern 的历史渊源——它确实脱胎于角色扮演社区,界面设计也充满了"酒馆冒险"的视觉隐喻。但正如 Linux 最初只是 Linus Torvalds 的个人爱好项目,最终却成为了支撑全球互联网基础设施的操作系统内核,SillyTavern 的底层架构早已超越了它的"出身"。
本篇文章将颠覆你的认知。我们将从软件架构的角度,深入剖析为什么 SillyTavern (ST) 是目前开源界最强大的 LLM Frontend(大模型前端),以及它如何通过"中间件"的设计哲学,成为你个人生产力的 操作系统 (LLM OS)。
在开始之前,让我先给你一个直观的类比:
| 传统认知 | 本文视角 |
|---|---|
| ChatGPT 网页版 = 完整的产品 | ChatGPT API = 一颗裸露的 CPU |
| SillyTavern = 聊天玩具 | SillyTavern = 操作系统 + IDE |
| 用户 = 被动的提问者 | 用户 = 系统架构师 |
当你完成本文的阅读,你将理解:为什么同样是调用 GPT-4 的 API,有人只能进行简单的问答,而有人却能构建出具备长期记忆、多模型协作、自动化工作流的"第二大脑"。
第一章:解构"中间件"——它到底接管了什么?
1.0 什么是"中间件"?
在深入技术细节之前,我们需要先建立一个清晰的概念框架。
中间件(Middleware) 是软件架构中的一个经典概念,指的是位于两个系统之间、负责协调和转换的软件层。它不直接产生最终结果,但它决定了结果的质量和形式。
一个生活化的类比:想象你在一家高档餐厅点餐。
- 你(用户):说出"我想吃点清淡的"
- 服务员(中间件):理解你的需求,翻译成厨房能理解的语言,比如"一份清蒸鲈鱼,少油少盐,配时令蔬菜"
- 厨房(大模型):根据精确的指令制作菜品
如果没有服务员,你就得自己走进厨房,用专业术语和厨师沟通。这不仅效率低下,而且你很可能因为不懂行而点出一道难以下咽的菜。
SillyTavern 就是这个"服务员"——但它是一个你可以完全自定义的、具备超强记忆力的、能同时对接多个厨房的超级服务员。
1.1 黑盒 vs 白盒:控制权的本质差异
当我们使用 ChatGPT 官方网页版时,我们实际上是在使用一个"黑盒"。你输入一句话,网页把它传给服务器,服务器吐回一句话。你无法控制中间发生了什么,你甚至不知道你的话在发送前是否被"阉割"过。
让我用一个具体的例子来说明这种"黑盒"的问题:
场景:你想让 ChatGPT 帮你分析一段敏感的商业数据。
黑盒模式下发生了什么:
- 你输入了数据和问题
- OpenAI 的前端可能对你的输入进行了预处理(你不知道)
- 系统可能自动添加了某些安全提示词(你不知道)
- 你的对话可能被用于模型训练(除非你手动关闭)
- 输出可能经过了某些过滤(你不知道)
你能控制的:几乎为零。你只能选择"发送"或"不发送"。
SillyTavern 的本质,不是一个聊天客户端,而是一个 可编程的中间件。它横跨在"你的意图"和"大模型 API"之间,接管了所有的控制权。
1.2 透明化的"提示词装配流水线"
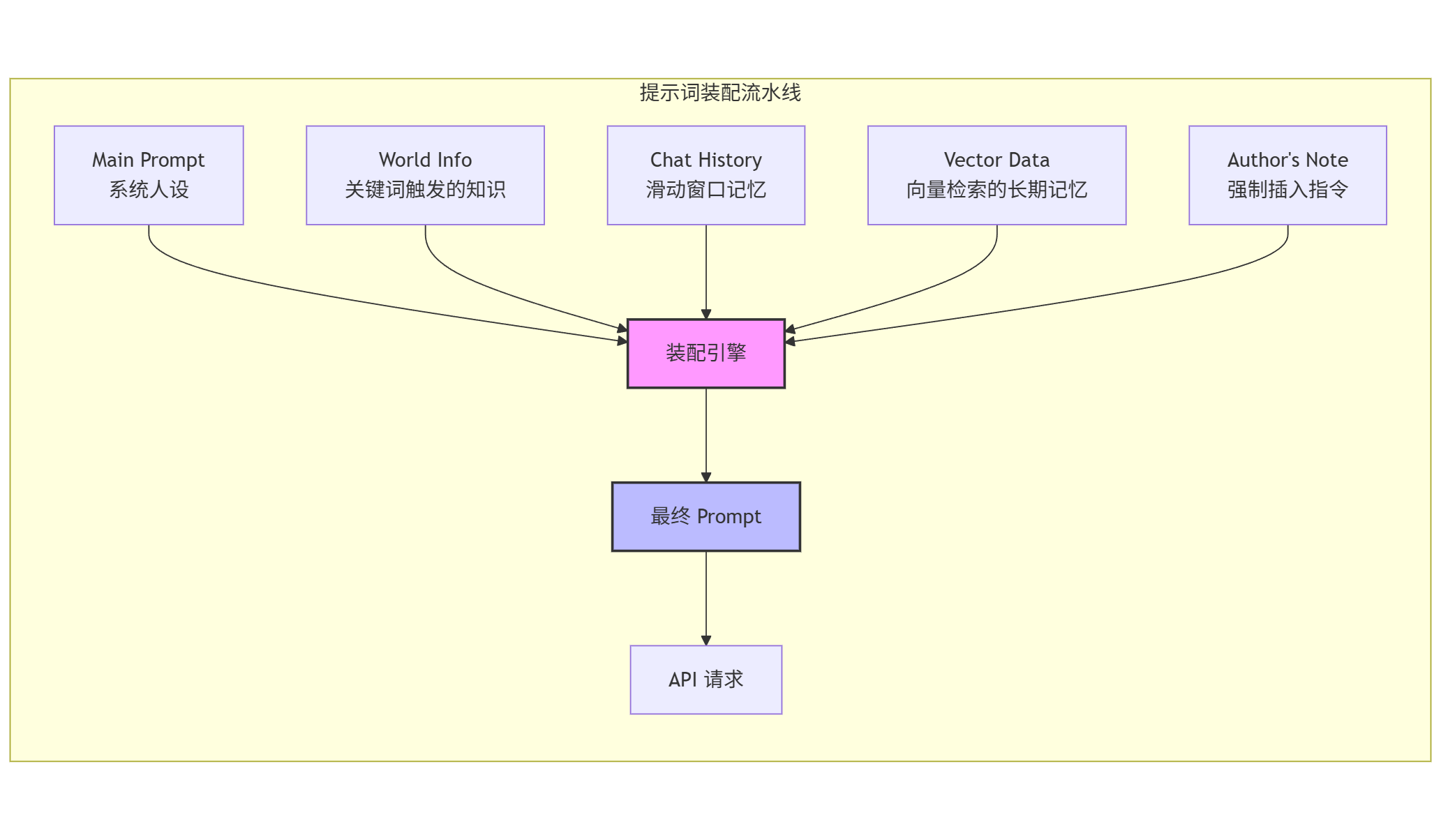
在 ST 中,你按下的每一次"发送"键,并不是直接把这一句话发给 AI。后台实际上发生了一场精密的"装配工程"。ST 会把你选中的所有组件,按照你设定的逻辑,像搭积木一样组装成最终的 Prompt。
这个过程是完全透明且可干预的。让我详细解释每一个组件:
组件 1:Main Prompt(主提示词)
这是你设定的"专家人设"或"系统指令"。它定义了 AI 应该扮演什么角色、具备什么能力、遵循什么规则。
示例:
1 | 你是一位资深的 Python 后端工程师,拥有 10 年的 Django 开发经验。 |
组件 2:World Info(世界书)
这是一个基于关键词触发的动态知识库。当对话中出现特定关键词时,相关的背景信息会被自动注入到上下文中。
生产力场景示例:
| 关键词 | 触发内容 |
|---|---|
项目A | 项目A是一个电商后台系统,使用 Django 4.2 + PostgreSQL… |
张总 | 张总是产品经理,偏好简洁的技术方案,讨厌过度设计… |
部署 | 我们的部署环境是 AWS EKS,使用 Helm Charts 管理… |
这意味着当你说"帮我看看项目A的部署问题"时,AI 会自动获得关于项目A和部署环境的完整背景,而不需要你每次都重复解释。
组件 3:Chat History(对话历史)
这是经过滑动窗口裁切的短期记忆。ST 会根据你设定的 Token 上限,智能地保留最相关的对话历史。
关键配置项:
- Context Size:总共保留多少 Token 的上下文
- Reserved Tokens:为新回复预留多少空间
- Trim Strategy:当超出限制时,如何裁切(从头部删除 / 智能摘要)
组件 4:Vector Data(向量数据)
这是从向量数据库中检索出的长期记忆参考资料。ST 支持将历史对话、文档、笔记等内容向量化存储,然后在需要时通过语义搜索召回相关内容。
工作原理:
- 你的历史对话被切分成小块(chunks)
- 每个小块被转换成向量(embedding)
- 当你发送新消息时,ST 会搜索语义相似的历史内容
- 相关内容被注入到当前上下文中
这解决了"AI 健忘症"的问题——即使是三个月前的对话,只要语义相关,就能被召回。
组件 5:Author’s Note(作者指令)
这是强制插入在特定位置的核心指令。它的独特之处在于:无论对话多长,它永远会出现在你指定的位置。
关键参数:
- Depth:插入深度。Depth=0 表示在最后一条用户消息之后,Depth=4 表示在倒数第 4 条消息的位置。
- Role:以什么身份插入(system / user / assistant)
1.3 为什么这对生产力至关重要?
让我用三个具体场景来说明这种"可编程性"带来的实际价值:
场景 1:代码开发中的"规范遗忘"问题
普通网页版的痛点:随着对话变长,AI 开始忘记你最开始设定的"使用 Python 3.10 语法"的要求。到了第 50 轮对话,它可能突然给你写出 Python 2 风格的代码。
SillyTavern 的解决方案:你可以利用 Author's Note 功能,设定一条指令:
1 | [核心约束 - 不可违反] |
将其插入深度设为 Depth=1(即倒数第一条),这意味着无论你聊了 100 轮还是 1000 轮,这条指令永远会像钉子一样钉在 AI 的"眼前"。
场景 2:多项目切换的"上下文污染"问题
普通网页版的痛点:你上午在处理项目 A(Python 后端),下午切换到项目 B(React 前端)。如果在同一个对话中继续,AI 可能会混淆两个项目的技术栈。
SillyTavern 的解决方案:你可以为每个项目创建独立的"角色卡"(Character Card),每个角色卡包含:
- 该项目的技术栈说明
- 代码规范要求
- 常见问题的处理方式
- 相关的 World Info 条目
切换项目时,只需切换角色卡,整个上下文环境瞬间切换,零污染。
场景 3:长期项目的"记忆断层"问题
普通网页版的痛点:你在做一个持续三个月的项目。每次开新对话,都要重新解释项目背景、之前做过什么决策、为什么这样设计。
SillyTavern 的解决方案:
- World Info 存储项目的静态知识(架构设计、技术选型理由)
- Vector Database 存储历史对话,支持语义检索
- Chat History 保持当前会话的连贯性
当你说"继续上周的数据库优化工作"时,ST 会自动从向量数据库中召回上周关于数据库优化的所有讨论,注入到当前上下文中。AI 瞬间"想起"了所有相关内容。
这就是中间件带来的**“确定性”**——你不再依赖 AI 的"心情",而是通过系统设计来保证输出质量。
第二章:数据主权——构建物理级隔离的安全屋
在企业环境或高隐私需求的个人项目中,SillyTavern 提供了目前市面上最高级别的安全保障范式:Local-First(本地优先)。
2.1 理解"数据主权"的真正含义
在讨论技术细节之前,让我们先明确一个概念:数据主权 指的是你对自己数据的完全控制权,包括:
- 存储位置:数据存在哪里?
- 访问控制:谁能看到这些数据?
- 生命周期:数据何时被删除?
- 可移植性:你能否随时导出并迁移数据?
当你使用 ChatGPT、Claude 或其他云端服务时,你在这四个维度上的控制权都是有限的:
| 维度 | 云端服务 | SillyTavern |
|---|---|---|
| 存储位置 | 服务商的服务器(通常在美国) | 你的本地硬盘 |
| 访问控制 | 服务商可以访问 | 只有你能访问 |
| 生命周期 | 取决于服务商政策 | 完全由你决定 |
| 可移植性 | 通常只能导出为有限格式 | 原生 JSON,完全开放 |
2.2 真正的数据静止
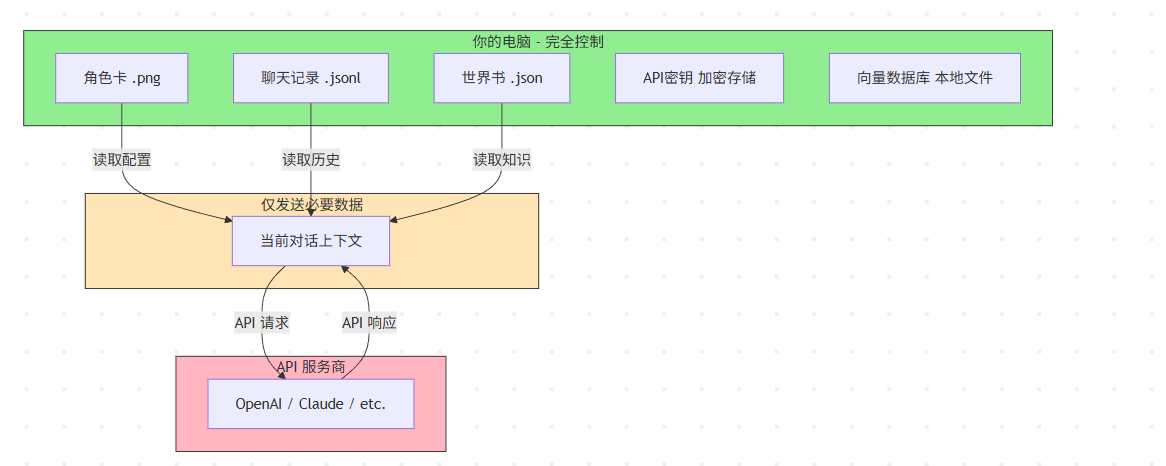
与 Notion AI 或各类云端笔记助手不同,SillyTavern 的所有核心数据都存储在你的本地硬盘中。让我详细解释每种数据的存储方式:
角色卡(Character Cards)
存储位置:/data/characters/
格式:.png 文件(是的,图片文件)
这是一个巧妙的设计:角色卡的所有配置信息(人设、示例对话、World Info 等)都被编码到 PNG 图片的元数据中。这意味着:
- 你可以直接分享图片来分享角色卡
- 图片本身就是完整的配置文件
- 任何图片查看器都能打开,但只有 ST 能解析其中的数据
聊天记录(Chat History)
存储位置:/data/chats/[角色名]/
格式:.jsonl(JSON Lines,每行一条消息)
示例内容:
1 | {"name":"user","mes":"帮我分析这段代码的性能问题","send_date":1704067200} |
这种格式的优势:
- 人类可读:用任何文本编辑器都能打开
- 流式追加:新消息直接追加到文件末尾,不需要重写整个文件
- 易于处理:标准的 JSON 格式,任何编程语言都能解析
API 密钥(Secrets)
存储位置:/secrets.json(加密存储)
ST 使用本地加密来保护你的 API 密钥。密钥永远不会以明文形式存储,也不会被发送到除了对应 API 端点之外的任何地方。
2.3 这里的"干货"在于如何利用这一点
因为数据在本地且格式开放,你可以实现一些在云端无法想象的操作:
操作 1:版本控制 (Git)
你可以直接把 ST 的 /data 文件夹作为一个 Git 仓库。这意味着你的每一次对话、每一个专家人设的修改,都可以被提交、回滚。你的工作流拥有了"时间机器"。
实际操作步骤:
1 | cd /path/to/SillyTavern/data |
应用场景:
- 你花了两小时调优一个角色卡,结果改坏了 → 一键回滚
- 你想对比两个版本的 Prompt 效果 → 创建分支,A/B 测试
- 团队协作 → 通过 Git 同步角色卡和配置
操作 2:批量数据处理
你可以写脚本来批量处理你的聊天记录。因为这些都是明文的 JSON 数据,数据完全属于你。
示例:提取本周所有代码块
1 | import json |
更多应用场景:
- 统计你和 AI 的对话模式(提问频率、话题分布)
- 自动生成周报(提取本周所有完成的任务)
- 构建个人知识库(将有价值的对话整理成文档)
操作 3:跨设备同步
因为所有数据都是文件,你可以使用任何文件同步工具来实现跨设备同步:
- Syncthing:开源、去中心化、端到端加密
- Resilio Sync:基于 BitTorrent 协议,速度快
- 云盘 + 加密:将 data 文件夹加密后同步到云盘
这比依赖服务商的"云同步"功能更灵活、更安全。
2.4 隐私场景的实际应用
让我给你一个具体的企业级应用场景:
场景:你是一家创业公司的 CTO,需要用 AI 来辅助分析公司的财务数据和用户数据。
传统方案的风险:
- 将财务数据发送到 ChatGPT → 数据可能被用于训练 → 潜在的商业机密泄露
- 使用企业版 API → 仍然需要信任服务商的隐私承诺
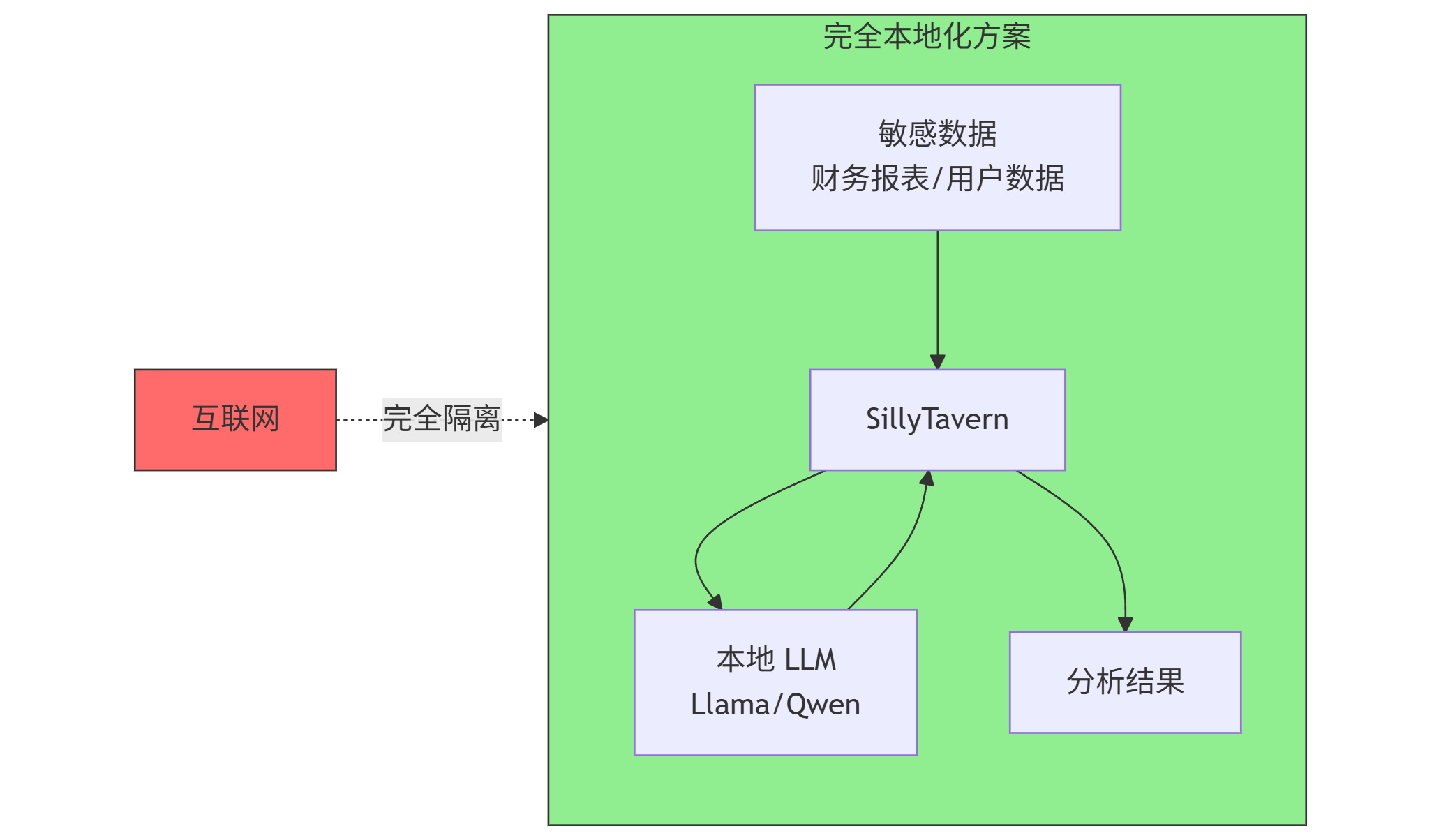
SillyTavern + 本地模型方案:
- 在本地部署 Llama-3-70B 或 Qwen-2.5
- 使用 ST 连接本地模型
- 所有数据处理都在本地完成
- 网络完全隔离,物理级安全
第三章:模型民主化——独创的"三位一体"工作流
这是 SillyTavern 作为生产力工具最核心的杀手锏。它打破了"原本你只能和一个模型对话"的限制。
3.1 理解"模型民主化"的含义
在传统的 AI 使用模式中,你被锁定在单一模型上:
- 用 ChatGPT 就只能用 GPT 系列
- 用 Claude 就只能用 Anthropic 的模型
- 想换模型?重新开一个网页,重新解释上下文
这就像你只能在一家餐厅吃饭,无论你想吃什么菜系,都只能从这家餐厅的菜单里选。
SillyTavern 打破了这个限制。在 ST 中,你可以预设多个 Connection Profile(连接配置文件)。这不仅仅是换个模型,而是连同温度(Temperature)、惩罚参数(Penalty)、上下文长度(Context Limit)一起切换。
更重要的是:切换是无缝的。你的对话历史、角色设定、World Info 都保持不变,只是"后端引擎"换了。
3.2 "三位一体"生产力范式
我们推荐一种极具性价比且高效的工作流,我称之为**"三位一体"范式**:
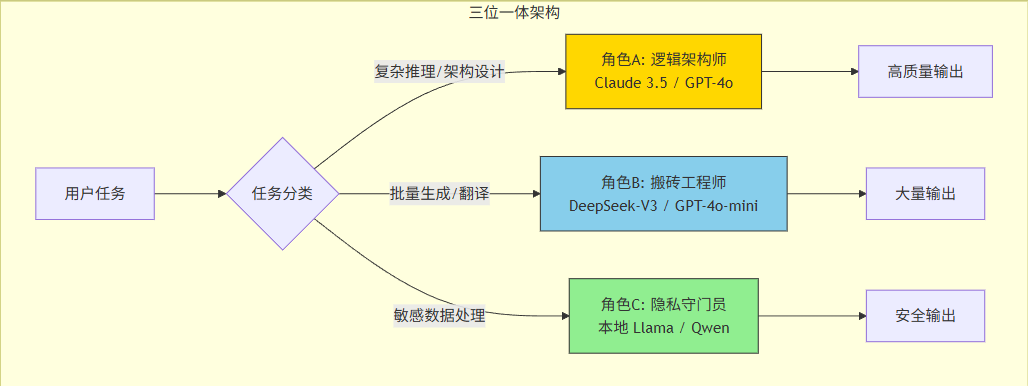
角色 A:逻辑架构师 (The Brain)
模型选择:GPT-4o 或 Claude 3.5 Sonnet
参数设定:
- Temperature: 0.7(较低,保证逻辑严谨)
- Top-P: 0.9
- Context: 最大可用值
- Max Tokens: 4096+
职责:负责最困难的任务
- 需求分析和拆解
- 系统架构设计
- 疑难杂症的 Debug
- 代码审查和优化建议
- 技术方案评估
使用策略:虽然单价贵(GPT-4o 约 $15/1M tokens),但因为只用在"刀刃"上,所以值得。一个好的架构决策可能为你节省几天的开发时间。
示例对话:
1 | 用户:我需要设计一个支持 10 万 QPS 的实时推荐系统,预算有限, |
角色 B:搬砖工程师 (The Worker)
模型选择:DeepSeek-V3 或 GPT-4o-mini
参数设定:
- Temperature: 0.8(稍高,增加多样性)
- Context: 128k(超长上下文)
- Max Tokens: 8192+
职责:负责"脏活累活"
- 根据架构设计编写样板代码
- 文档翻译(中英互译)
- 代码注释补充
- 单元测试生成
- 数据格式转换
- 批量文本处理
使用策略:速度极快,价格极低(DeepSeek 的价格大约是 GPT-4 的 1/50),哪怕生成几万字也不心疼。
示例对话:
1 | 用户:根据上面架构师给出的设计,帮我实现 Redis 缓存层的代码, |
角色 C:隐私守门员 (The Vault)
模型选择:本地模型(Llama-3-70B / Qwen-2.5-72B)
参数设定:
- 根据本地硬件调整
- 可以使用量化版本(如 Q4_K_M)来降低显存需求
职责:处理绝对机密的数据
- 公司财务报表分析
- 含有客户 PII(个人敏感信息)的数据处理
- 内部战略文档的整理
- 竞品分析(不想让竞争对手知道你在分析他们)
使用策略:网线拔了也能 用,物理隔绝,安全性 100%。虽然本地模型的能力可能不如顶级云端模型,但对于数据处理、格式转换、信息提取等任务,已经完全够用。
示例对话:
1 | 用户:这是我们公司上季度的财务报表(包含详细的收入、成本、利润数据), |
3.3 成本对比:为什么这套方案能省钱
让我用一个具体的数字来说明"三位一体"方案的经济性:
场景:你需要完成一个中等复杂度的功能开发,包括架构设计、代码实现、文档编写。
| 任务 | 纯 GPT-4o 方案 | 三位一体方案 |
|---|---|---|
| 架构设计(5k tokens) | $0.075 | $0.075(GPT-4o) |
| 代码实现(50k tokens) | $0.75 | $0.01(DeepSeek) |
| 文档编写(20k tokens) | $0.30 | $0.004(DeepSeek) |
| 敏感数据处理(10k tokens) | $0.15 | $0(本地模型) |
| 总计 | $1.275 | $0.089 |
节省比例:93%
这还只是单次任务。如果你是重度用户,每天都在和 AI 协作,一个月下来的差距可能是几百美元。
在 SillyTavern 的界面顶部,你可以通过下拉菜单在 2 秒钟内完成这三个角色的切换。
完整的工作流演示:
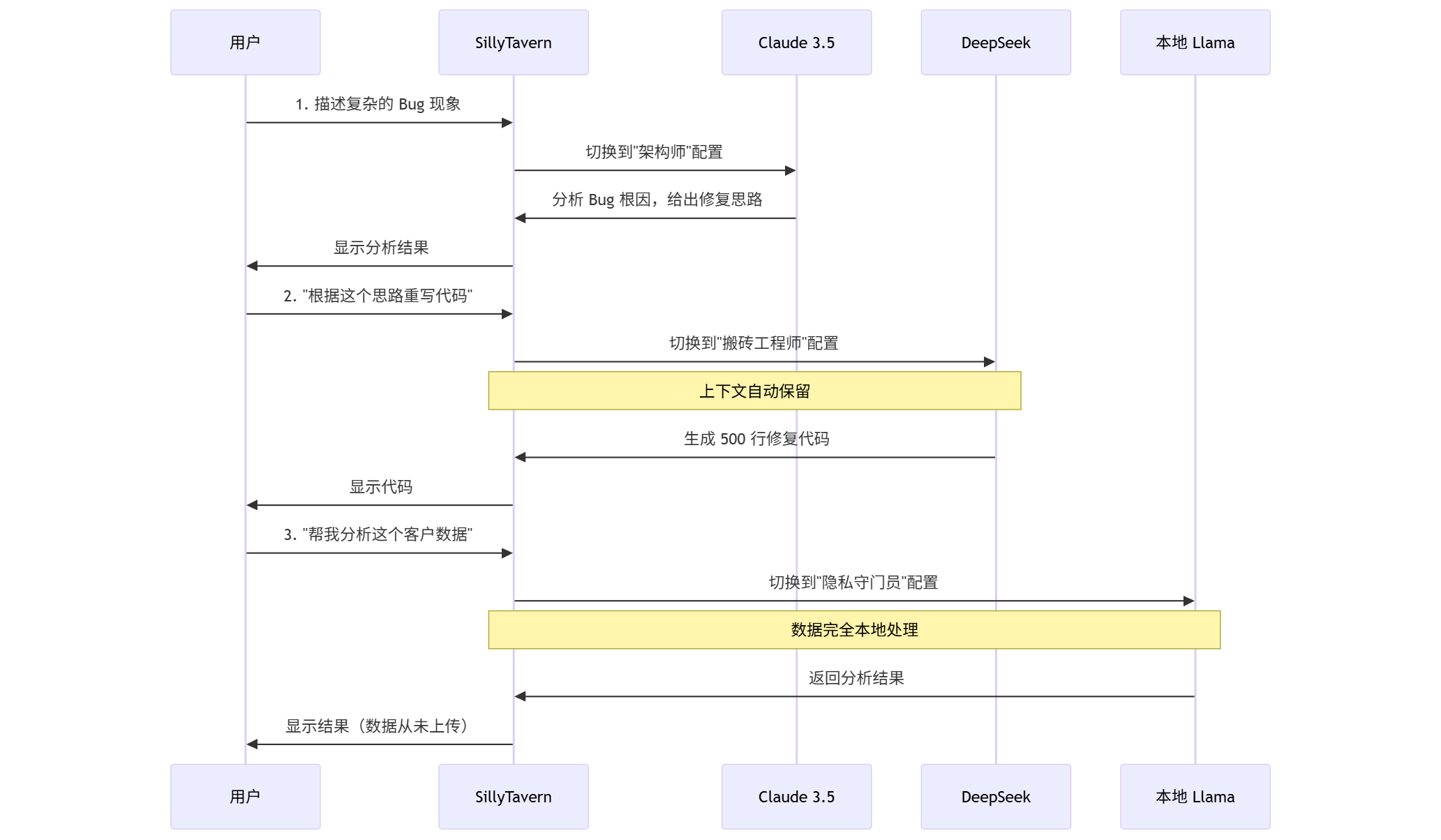
关键点:
- 切换模型时,对话历史自动保留
- 每个配置文件可以有独立的参数设定
- 切换过程对用户几乎无感
这就是"模型民主化"带来的降维打击——你不再被任何单一服务商绑架,而是根据任务特性选择最合适的工具。
第四章:正则脚本 (Regex)——打造你的专属 IDE
这一部分是真正的极客干货,也是 ST 区别于所有其他客户端的核心特征。ST 允许你在 AI 的输出显示到屏幕之前,用正则表达式(Regex)去"篡改"它。
4.1 理解正则脚本的工作原理
首先,让我解释一下这个功能的本质:
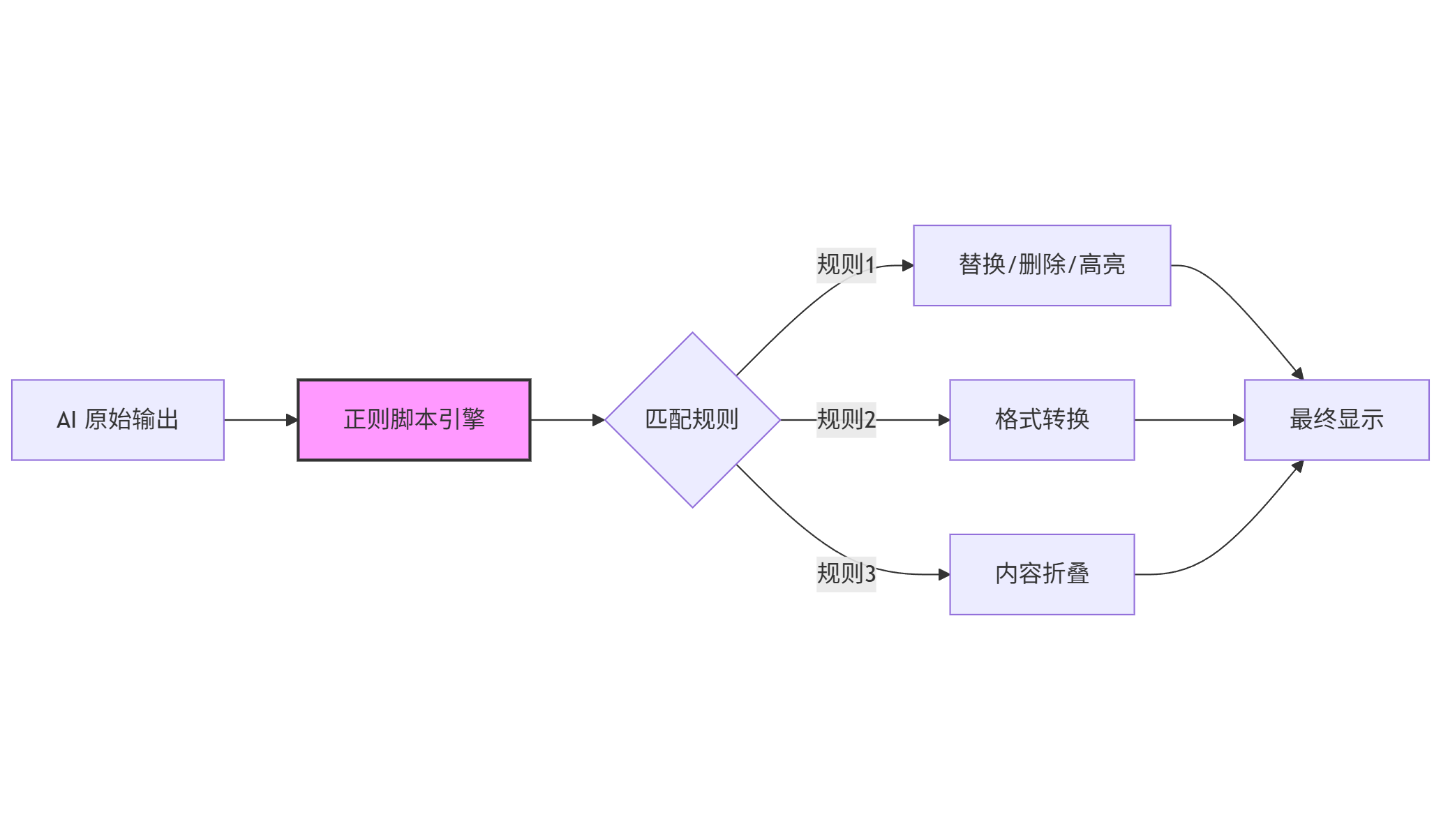
关键概念:
Placement(作用范围):
Only Formatting:仅影响显示,不影响保存的记录Send to AI:在发送给 AI 之前处理Receive from AI:在收到 AI 回复后处理
Regex Pattern(正则模式):标准的正则表达式语法
Replacement(替换内容):可以是纯文本,也可以包含捕获组引用
4.2 案例 1:隐藏思维链 (Hide Chain of Thought)
像 DeepSeek-R1 这样的推理模型,会输出大量的 <think> 标签内容。在生产力场景下,你可能只想要结果,不想看几千字的思考过程。
配置方法:
| 字段 | 值 |
|---|---|
| Regex Pattern | <think>[\s\S]*?</think> |
| Replacement | <details><summary>💭 点击展开推理过程</summary>$&</details> |
| Placement | Only Formatting |
效果:
- 原本占据半屏的思考过程被折叠成一行
- 需要时点击即可展开查看
- 不影响保存的原始记录
4.3 案例 2:代码块自动增强
有些模型输出代码不带语言标识,或者格式不够规范。你可以用正则脚本来自动增强。
配置 1:自动添加语言标识
| 字段 | 值 |
|---|---|
| Regex Pattern | ```\n([^]+)``` ` |
| Replacement | ```python\n$1``` |
| Placement | Only Formatting |
配置 2:为代码块添加复制按钮
这需要配合 ST 的自定义 CSS 功能,但正则脚本可以为代码块添加特定的 class:
| 字段 | 值 |
|---|---|
| Regex Pattern | (<pre><code) |
| Replacement | $1 class="copyable" |
4.4 案例 3:敏感信息脱敏
在某些场景下,你可能希望在显示时自动隐藏敏感信息(比如 API 密钥、密码等)。
配置方法:
| 字段 | 值 |
|---|---|
| Regex Pattern | (sk-[a-zA-Z0-9]{20,}) |
| Replacement | [API_KEY_HIDDEN] |
| Placement | Only Formatting |
这样,即使 AI 在回复中不小心暴露了你的 API 密钥,显示时也会被自动隐藏。
4.5 案例 4:自动格式化 JSON
当 AI 返回 JSON 数据时,有时候是压缩的单行格式,阅读困难。
配置方法:
这个场景更适合用 ST 的 JavaScript 扩展功能,但基础的正则也能实现部分效果:
| 字段 | 值 |
|---|---|
| Regex Pattern | \{([^{}]+)\} |
| Replacement | (使用 JS 函数进行格式化) |
4.6 正则脚本的高级玩法
对于更复杂的需求,ST 支持在正则替换中使用 JavaScript 函数:
1 | // 示例:自动为代码块添加行号 |
应用场景:
- 自动计算代码行数并显示统计
- 将特定格式转换为表格
- 自动提取并高亮关键信息
第五章:扩展生态——无限可能的插件系统
SillyTavern 不仅仅是一个独立的应用,它还拥有一个活跃的扩展生态系统。这些扩展可以进一步增强 ST 的能力。
5.1 核心扩展介绍
扩展 1:向量存储
功能:为 ST 添加长期记忆能力
工作原理:
- 将历史对话切分成语义块
- 使用 Embedding 模型将文本转换为向量
- 存储在本地向量数据库中
- 对话时自动检索相关内容
配置要点:
- Embedding 模型选择(本地 vs API)
- 切分策略(按句子 / 按段落 / 按 Token 数)
- 检索数量(召回多少条相关记录)
扩展 2:图像生成
功能:在对话中直接生成图像
支持的后端:
- Stable Diffusion WebUI
- ComfyUI
- DALL-E API
- Midjourney(通过第三方桥接)
应用场景:
- 让 AI 描述一个概念,然后直接生成示意图
- 代码架构的可视化
- 数据分析结果的图表生成
扩展 3:语音交互
功能:语音输入和语音输出
支持的后端:
- 本地 TTS(如 Coqui TTS)
- 云端 TTS(如 ElevenLabs)
- 浏览器原生语音识别
应用场景:
- 解放双手,边做其他事边和 AI 对话
- 为视障用户提供无障碍访问
- 语言学习场景
第六章:实战工作流——从理论到落地
让我用一个完整的实战案例,展示如何将前面所有的概念整合成一个高效的工作流,这里不需要实操,而是模拟演示一个真实的工作流设计
6.1 场景设定
你的身份:一名全栈开发者
当前任务:开发一个新功能——用户行为分析仪表盘
时间周期:一周
6.2 工作流设计
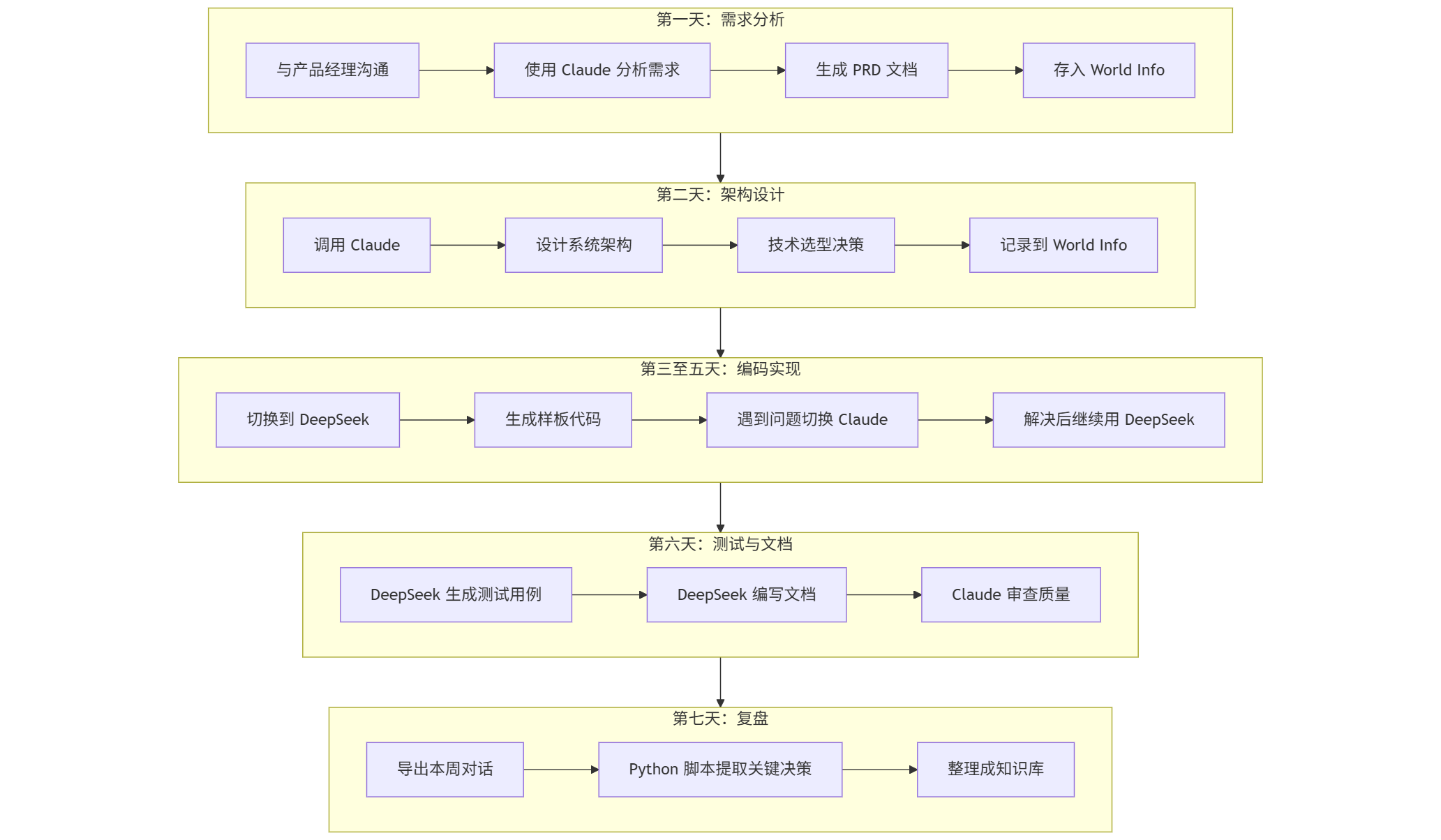
6.3 具体配置
角色卡配置
角色卡名称:用户行为分析项目
Main Prompt:
1 | 你是一位资深的全栈开发工程师,正在协助开发一个用户行为分析仪表盘。 |
World Info 配置
| 关键词 | 内容 |
|---|---|
PRD, 需求 | [产品需求文档的完整内容] |
架构, 设计 | [系统架构设计文档] |
API, 接口 | [API 设计规范和已有接口列表] |
数据库, 表结构 | [数据库 Schema 定义] |
Author’s Note 配置
1 | [当前阶段提醒] |
6.4 一周后的成果
通过这套工作流,你将获得:
1.完整的项目文档:需求、架构、API 文档都在对话中自然产生
2.可追溯的决策记录:为什么选择 TimescaleDB?对话记录里有完整的分析
3.可复用的知识库:下次做类似项目,World Info 可以直接复用
4.成本优化:复杂决策用 Claude,批量编码用 DeepSeek,总成本可控
结语:工具决定思维
SillyTavern 的核心理念在于:不要等待大模型变得完美,而要构建一个完美的系统来驾驭大模型。
通过将 API 视为 CPU,将 ST 视为操作系统,你不再是被动的"提问者",而是主动的"编排者"。你拥有了对记忆、数据、模型选择和输出格式的绝对控制权。
让我用一张图来总结 SillyTavern 的核心价值:
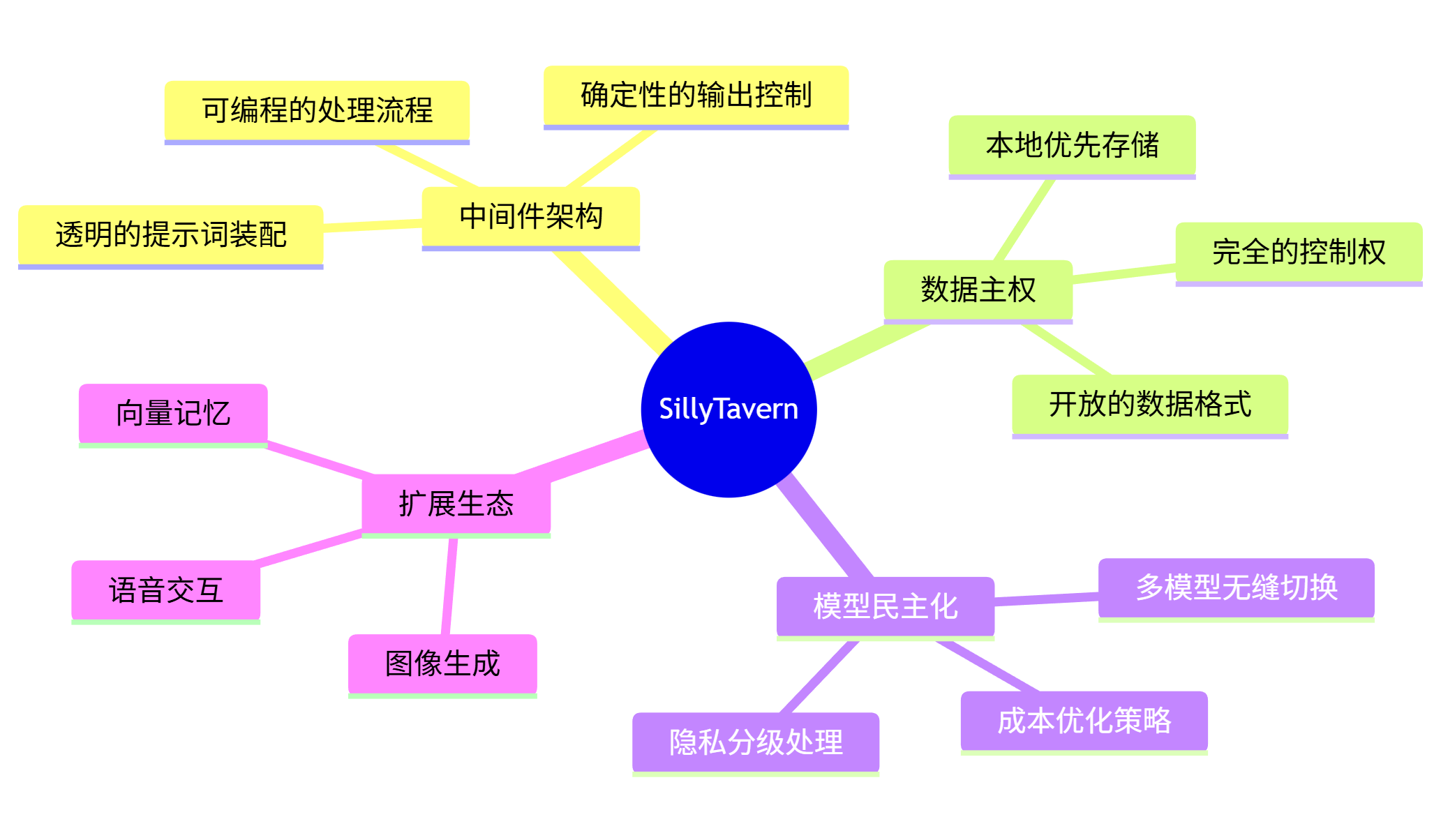
这才是"AI 学习助理"或"AI 工程师"该有的完全体形态。
当你掌握了这些概念和技术,你会发现:那些还在用 ChatGPT 网页版的人,就像是在用记事本写代码的程序员——能用,但效率差了一个数量级。
下一篇笔记预告:
既然我们理解了 ST 的"中间件"本质,下一篇我们将进入**《笔记 02:大脑皮层——如何编写"不听话就惩罚"的专家级 Prompt》**。我们将手把手教你如何用 ST 的格式(Character Card)封装一个具备苏格拉底教学法的超级导师,包括:
- 角色卡的完整结构解析
- 如何设计"防越狱"的约束系统
- 示例对话的正确写法
- 动态人设的高级技巧
敬请期待。





