
Prorise
这是我的博客,分享技术与生活的点点滴滴
第三章. 变量与参数化:告别硬编码
第三章. 变量与参数化:告别硬编码
Prorise第三章. 变量与参数化:告别硬编码
摘要:本章我们将解决测试脚本 “千人一面” 的问题。通过引入用户自定义变量、CSV 数据文件和随机函数,我们将把硬编码的死数据转化为动态的活数据,模拟真实世界中 “千人千面” 的并发访问场景。
本章学习路径
我们将按照以下步骤改造我们的测试脚本:
- 3.1 升级靶场
- 3.1.1 增加带参接口
- 3.1.2 理解缓存对压测的干扰
- 3.2 用户自定义变量
- 3.2.1 提取全局环境配置(Host/Port)
- 3.2.2 实现环境一键切换
- 3.3 CSV 数据驱动
- 3.3.1 准备测试数据文件
- 3.3.2 配置 CSV Data Set Config
- 3.3.3 循环读取机制详解
- 3.4 随机化函数
- 3.4.1 函数助手的使用
- 3.4.2 UUID 与随机数字生成
3.1. 升级靶场:拒绝 “假” 压测
在上一节中,我们测试的是 /api/test/hello 接口。无论发多少次请求,参数和结果都是一样的。
但在真实的数据库压测中,如果 1000 个用户都查询同一个 id=1 的商品,数据库会利用 Buffer Pool(缓冲池) 机制将数据缓存到内存中。这意味着后续的 999 次请求根本没有触达磁盘 IO,这样的压测结果是失真的(看似 TPS 很高,实际上线就挂)。
为了模拟真实场景,我们需要一个能接收参数的接口。
3.1.1. 编写带参接口
文件路径:src/main/java/com/demo/jmeterdemo/controller/TestController.java
请在原有的 Controller 中添加一个新的接口:
1 | /** |
重启项目,访问 http://localhost:8080/api/test/product/999 进行验证。
3.2. 用户参数:环境一键切换
在开发过程中,我们经常需要在 本地环境 (Local)、测试环境 (Dev) 和 生产环境 (Prod) 之间切换。如果你的脚本里写死了 localhost,每次切换环境都要把几十个 HTTP 请求挨个修改一遍,这简直是噩梦。
3.2.1. 定义全局变量
操作步骤:
- 点击 JMeter 左侧最顶层的 测试计划 (Test Plan)。
- 右键点击 “测试计划” -> 添加 -> 前置处理器 -> 用户变量。
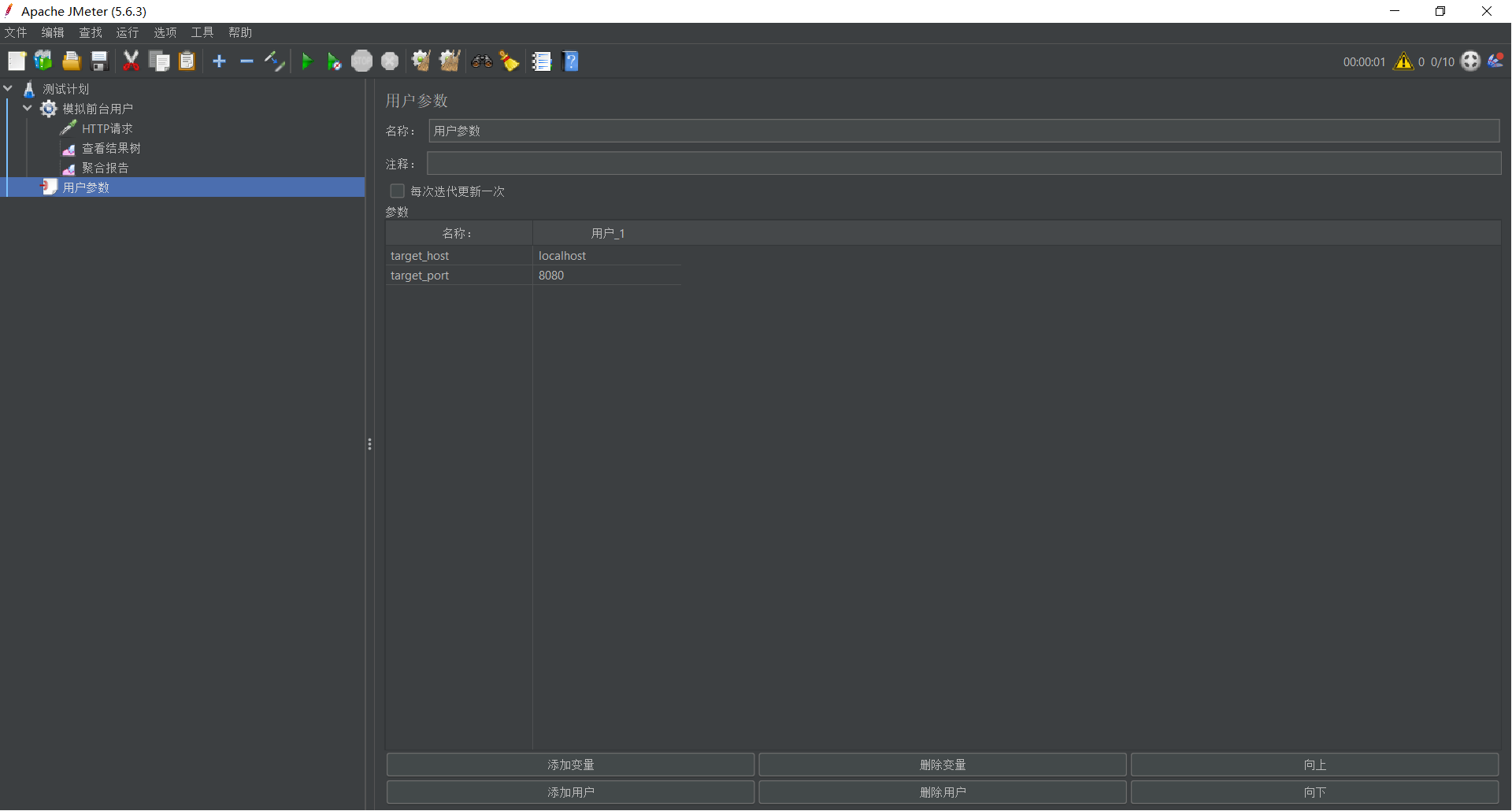
- 点击 添加,输入以下键值对:
| 名称 (Name) | 值 (Value) | 描述 |
|---|---|---|
target_host | localhost | 目标服务器地址 |
target_port | 8080 | 目标端口 |
3.2.2. 引用变量
回到我们在第二章创建的 HTTP 请求:
- 将 服务器名称或 IP 中的
localhost替换为${target_host}。 - 将 端口号 中的
8080替换为${target_port}。
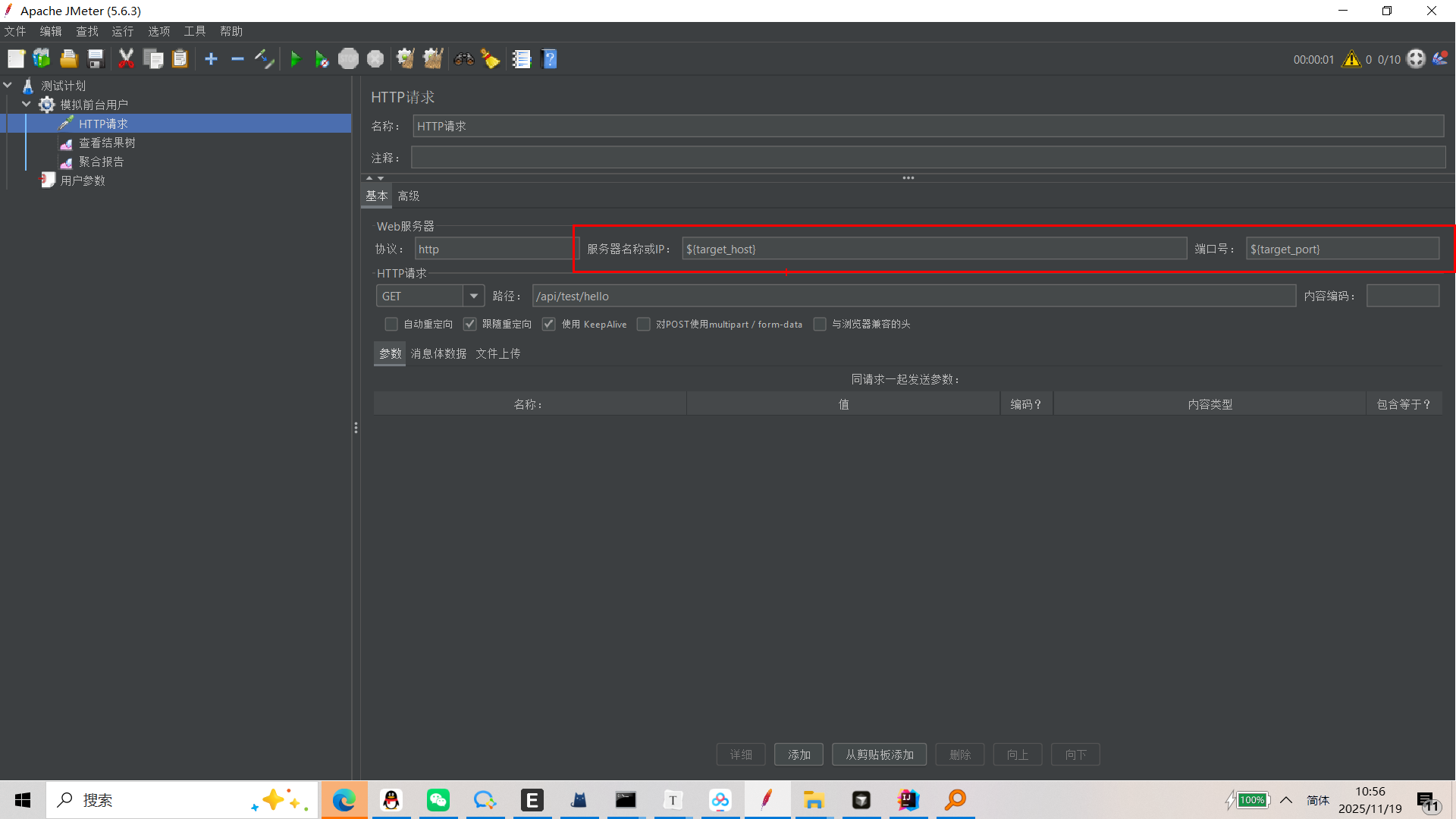
语法说明:${variable_name} 是 JMeter 中引用变量的标准语法。
现在,如果你想切换到测试服务器,只需要在测试计划最顶层修改一次 target_host 的值,所有引用的地方都会自动生效。
3.3. CSV 数据驱动:模拟批量用户
现在我们要模拟 100 个不同的用户,查询 100 个不同的商品。我们将使用 CSV 文件来管理这些数据。
3.3.1. 准备数据文件
- 在电脑任意位置(建议在 JMeter 脚本同目录下)创建一个名为
data.csv的文件。 - 输入几行测试数据(不需要表头,直接写内容):
1 | 1001 |
3.3.2. 配置 CSV Data Set Config
这是 JMeter 中最常用的元件之一。
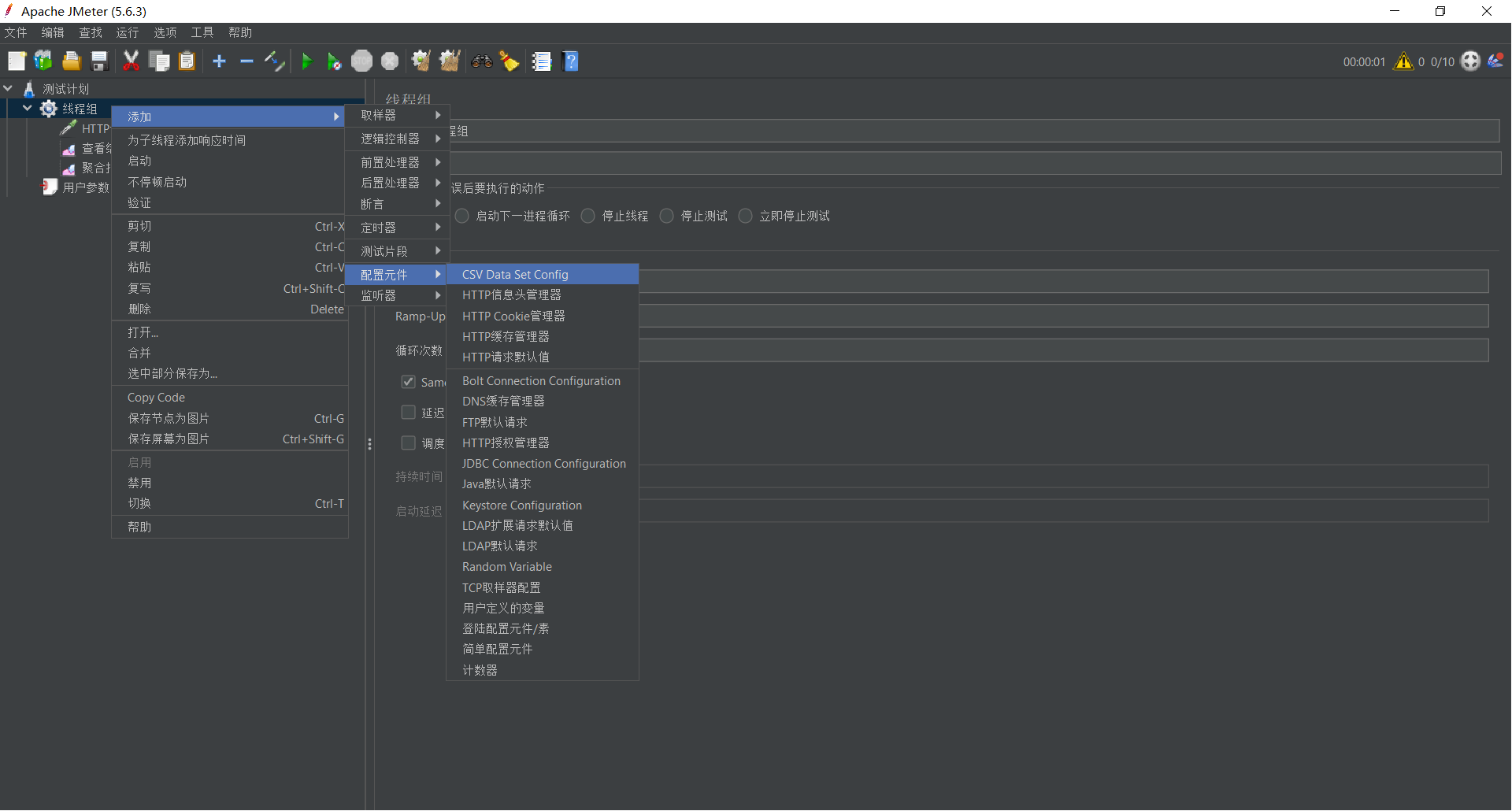
操作步骤:
- 右键点击 线程组 -> 添加 -> 配置元件 (Config Element) -> CSV 数据文件设置 (CSV Data Set Config)。
- 重要:将该组件拖拽到 “HTTP 请求” 的 上方(执行顺序很重要)。
关键参数配置:
| 参数项 | 配置值 | 解释 |
|---|---|---|
| 文件名 (Filename) | data.csv | 如果文件在脚本同目录,直接写文件名;否则写绝对路径。 |
| 文件编码 (File encoding) | UTF-8 | 防止中文参数乱码。 |
| 变量名称 (Variable Names) | p_id | 给 CSV 中的列起个变量名。如果有两列,用逗号隔开,如 username,password。 |
| 遇到文件结束符再次循环? | True | 如果文件只有 5 行,但线程循环 10 次,设为 True 会从头重新读取;设为 False 则会停止测试。 |
| 线程共享模式 | All threads | 所有线程共享这份文件。线程 1 取第一行,线程 2 取第二行,互不重复。 |
3.3.3. 实战调用
- 打开 HTTP 请求。
- 修改 路径 (Path) 为:
/api/test/product/${p_id}。 - 启动测试。
查看 察看结果树,你会发现请求路径变成了:
/api/test/product/1001/api/test/product/1002- …
这意味着 CSV 数据已成功注入。
3.4. 随机化函数:动态生成数据
有时候我们不需要固定的数据,而是需要唯一的随机数据(比如生成这就唯一的订单号,或者模拟随机的用户行为)。JMeter 提供了强大的 函数助手。
3.4.1. 函数助手 (Function Helper)
这是 JMeter 的内置外挂。
操作步骤:
- 点击 JMeter 顶部菜单栏的 工具 (Tools) -> 函数助手对话框 (Function Helper Dialog)。
- 这是一个独立的弹窗,里面列出了所有可用函数。
3.4.2. 常用函数实战
我们修改脚本,在查询商品的同时,传递一个随机生成的 Trace-ID 请求头。
场景 1:生成随机数字
- 在函数助手中选择
__Random。 - 最小值:
1000,最大值:9999。 - 点击 生成,你会得到字符串:
${__Random(1000,9999,)}。
场景 2:生成 UUID (全球唯一标识)
- 选择
__UUID。 - 点击 生成,得到:
${__UUID}。
应用到 HTTP 请求:在 HTTP 请求面板,点击底部的 添加 按钮(参数区域):
- 名称:
request_id - 值:
${__UUID}
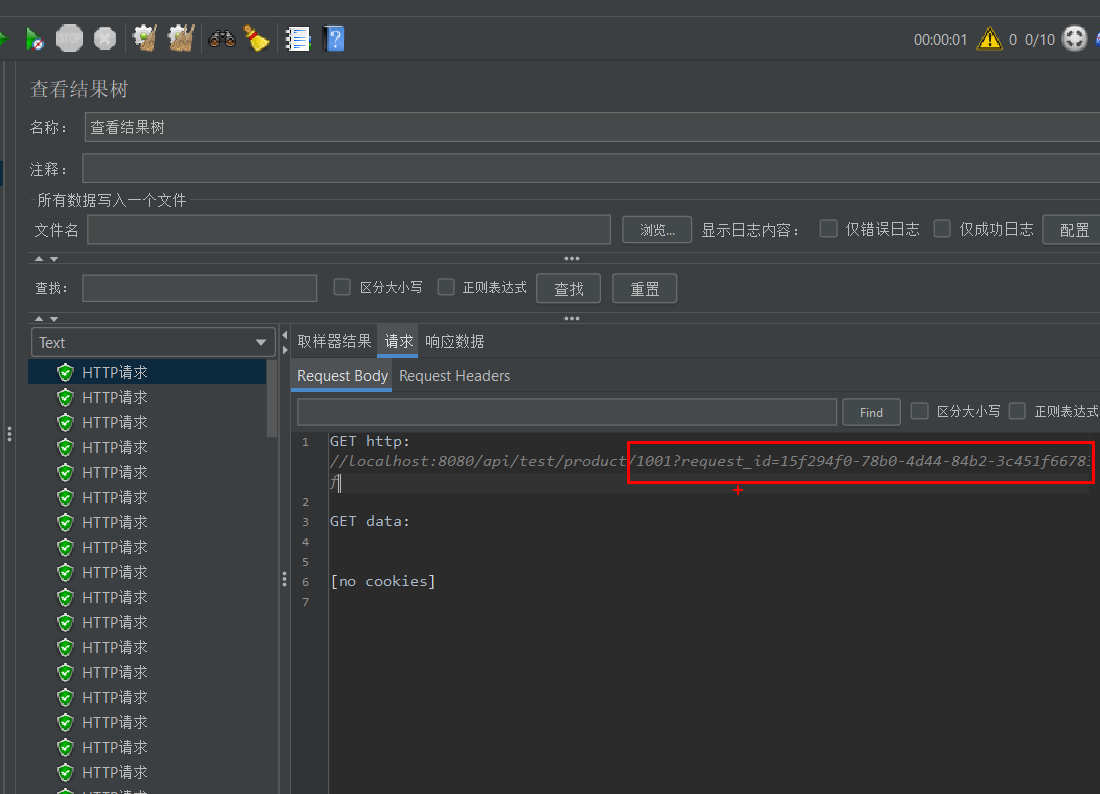
再次运行测试,查看结果树中的 请求数据 (Request Body/Header),你会看到类似 request_id=550e8400-e29b-41d4-a716-446655440000 的动态参数。
3.5. 本章小结
在本章中,我们将静态的脚本进化为了动态脚本。
核心要点:
- 变量引用:使用
${var_name}语法可以引用任何地方定义的变量。 - CSV 数据集:这是实现 “参数化” 的核心手段,特别适用于大量账号登录、批量查询等场景。线程共享模式 决定了数据是在线程间共享还是独享。
- 函数助手:善用
${__Random}和${__UUID}可以模拟离散的流量,避免热点数据造成的缓存假象。
思考题:如果你在 CSV 中配置了 100 个用户账号,并且启动了 200 个线程,同时设置 “遇到文件结束符再次循环” 为 False,会发生什么?
(答案:前 100 个线程会成功获取数据,后 100 个线程会因为取不到数据而停止执行。)
下一步计划:现在的接口都是独立的。但在实际业务中,往往是 “用户登录” -> “获取 Token” -> “拿着 Token 下单”。这涉及到了接口之间的数据传递。下一章,我们将学习性能测试中最关键的技术——关联 (Correlation),教你如何从上一个接口的响应中提取数据传递给下一个接口。






