
Prorise
这是我的博客,分享技术与生活的点点滴滴
第九章. 可视化监控体系:InfluxDB + Grafana
第九章. 可视化监控体系:InfluxDB + Grafana
Prorise第九章. 可视化监控体系:InfluxDB + Grafana
摘要:在之前的测试中,我们一直依赖 JMeter 自带的 GUI 监听器(如聚合报告)查看结果。这种方式有两个致命缺点:一是 GUI 消耗资源大,不适合高并发;二是无法实时查看 TPS 趋势图。本章我们将搭建 JMeter + InfluxDB + Grafana 黄金链路,抛弃丑陋的静态报告,打造好莱坞大片级别的实时监控大屏。
本章学习路径
我们将按照 “数据生产 -> 数据存储 -> 数据展示 -> 数据解读” 的闭环进行掌握:
- 9.1 监控架构演进
- 9.1.1 为什么要抛弃 GUI 报告?
- 9.1.2 JIG 架构解析 (JMeter + InfluxDB + Grafana)
- 9.2 部署监控基础设施
- 9.2.1 方案 A:Docker Compose 一键部署(推荐)
- 9.2.2 方案 B:Windows 原生安装
- 9.3 配置 JMeter 后端监听器
- 9.3.1 Backend Listener 核心配置
- 9.3.2 关键参数:
summaryOnly与percentiles
- 9.4 配置 Grafana 大屏
- 9.4.1 数据源配置
- 9.4.2 导入官方经典模板 (ID: 5496)
- 9.5 深度解读:像医生一样看大屏 (新增)
- 9.5.1 顶部导航与全局概览:掌握压测节奏
- 9.5.2 核心指标仪表盘:一秒判断生死
- 9.5.3 趋势图与错误分析:定位性能拐点
9.1. 监控架构演进
9.1.1. 痛点分析
在此前的章节中,我们依靠 “聚合报告” 看数据。但在真实压测中,它有三大罪状:
- 资源黑洞:GUI 监听器会将所有结果保存在内存中。如果压测持续 1 小时,积攒的百万条数据会直接把 JMeter 客户端撑爆(OOM)。
- 后知后觉:你只能在压测结束后看到平均值,无法看到压测过程中的 “抖动”(比如第 5 分钟突然发生了 TPS 暴跌)。
- 数据孤岛:无法与服务器的 CPU/内存监控图表放在一起对比。
9.1.2. JIG 架构解析
为了解决上述问题,业界通用的方案是 JIG:
- JMeter (生产者):负责施压。它不再把数据留在内存,而是通过 Backend Listener 异步地把精简后的统计数据 “推” 出去。
- InfluxDB (存储者):一个高性能的 时序数据库,专门用来存这种带时间戳的监控数据。
- Grafana (展示者):一个颜值极高的数据可视化平台,从 InfluxDB 读数据,画成炫酷的图表。
9.2. 部署监控基础设施
为了降低学习成本,我们推荐使用 Docker 快速搭建。如果你没有 Docker 环境,也可以选择原生安装,如果您不熟悉 docker,可转至
9.2.1. 方案 A:Docker Compose 一键部署
如果你是 Spring Boot 开发者,本地应该有 Docker Desktop。
操作步骤:
- 在任意目录创建一个
docker-compose.yml文件。 - 粘贴以下内容(使用 InfluxDB 1.8 版本,因为 JMeter 对 1.x 协议支持最原生,配置最简单):
1 | version: '3' |
- 在终端执行命令:
1
docker-compose up -d
- 验证:访问
http://localhost:3000能看到 Grafana 登录页(默认账号密码admin/admin),说明部署成功。
9.2.2. 方案 B:Windows 原生安装(备选)
如果不使用 Docker,你需要分别下载软件。
- InfluxDB:下载 v1.8.10 windows 二进制包 -> 解压 -> 运行
influxd.exe。 - Grafana:下载 Windows Installer -> 安装 -> 启动服务。
(注:为了教学流畅性,后续演示基于 Docker 环境,端口均为默认)
9.3. 配置 JMeter 后端监听器
基础设施搭建完毕,现在要配置 JMeter 往数据库里 “推” 数据。
9.3.1. 添加 Backend Listener
操作步骤:
- 打开你的 JMeter 脚本(建议使用包含 " API_登录 " 和 " API_下单 " 的脚本)。
- 右键点击 线程组 -> 添加 -> 监听器 -> 后端监听器 (Backend Listener)。
- 位置:放在线程组的最下方,或者测试计划的最外层(监听所有线程组)。
9.3.2. 核心参数配置
在后端监听器面板中,请依次完成以下核心参数的配置:
- Backend Listener implementation
1 | org.apache.jmeter.visualizers.backend.influxdb.InfluxdbBackendListenerClient |
选择 InfluxDB 协议客户端,这是连接的基础。
- influxdbUrl
1 | http://localhost:8086/write?db=jmeter |
数据写入地址。其中 db=jmeter 对应我们在 Docker 中预先创建的数据库名称。
- application
1 | SpringBoot_App_Test |
应用名称。该字段用于标识当前的压测项目,后续在 Grafana 中可以通过这个名字筛选出特定项目的监控数据。
- measurement
1 | jmeter |
InfluxDB 中的表名(Measurement),通常保持默认即可。
- summaryOnly
1 | false |
关键配置! 该选项默认为 false, 他使得 JMeter 记录每一个 Request 的详细数据,Grafana 才能依据这些数据绘制出精细的明细图表。
- percentiles
1 | 90;95;99 |
配置我们关心的百分位性能指标(如 TP90、TP95、TP99)。
验证配置:
点击启动 JMeter。虽然界面上看不到任何弹窗提示,但此时 JMeter 已经开始默默地通过 UDP/HTTP 协议向 localhost:8086 发送数据包了。
9.4. 配置 Grafana 大屏
最后一步,把数据画出来。
9.4.1. 配置数据源 (Data Source)
- 浏览器打开 http://localhost: 3000 ,登录 Grafana,用户名: admin,密码: admin
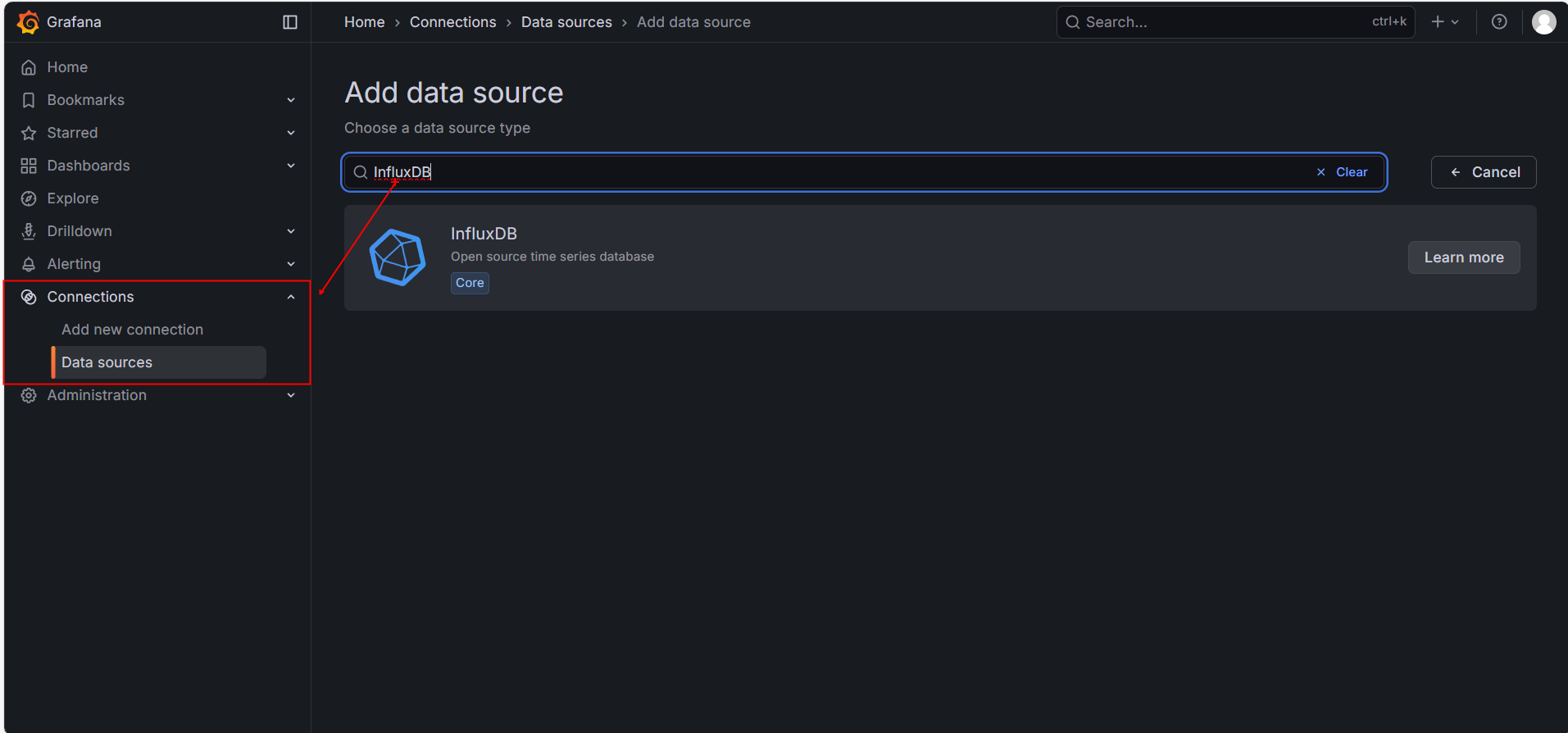
- 点击左侧齿轮图标 -> Data Sources -> Add data source。
- 选择 InfluxDB。
- 配置详情:
- URL:
http://influxdb:8086(如果你用 Docker) 或http://localhost:8086(如果你是原生安装)。 - Database:
jmeter。
- URL:
- 点击底部 Save & Test。如果显示绿色的 “Data source is working”,说明连接成功。
9.4.2. 导入炫酷模板
我们不需要自己一个一个画图,社区已经有大神做好了完美的模板。
- 点击 Grafana 左侧加号图标 -> Import。
- 在 Import via grafana.com 输入框中,填入 ID:5496。
- (注:模板 5496 是最经典的 JMeter Dashboard,由 Apache 官方推荐)
- 点击 Load。
- 在底部的 DB name 下拉框中,选择刚才创建的
InfluxDB数据源。 - 点击 Import。
9.4.3. 实战:见证奇迹的时刻
现在,屏幕上应该出现了一个空的大屏。让我们让它动起来。
- 回到 JMeter。
- 调整线程组:设置 50 个线程,循环 “永远”(或设置一个很大的循环次数),持续运行 5 分钟。
- 点击 启动。
- 回到 Grafana 浏览器页面,右上角选择刷新频率为
5s。
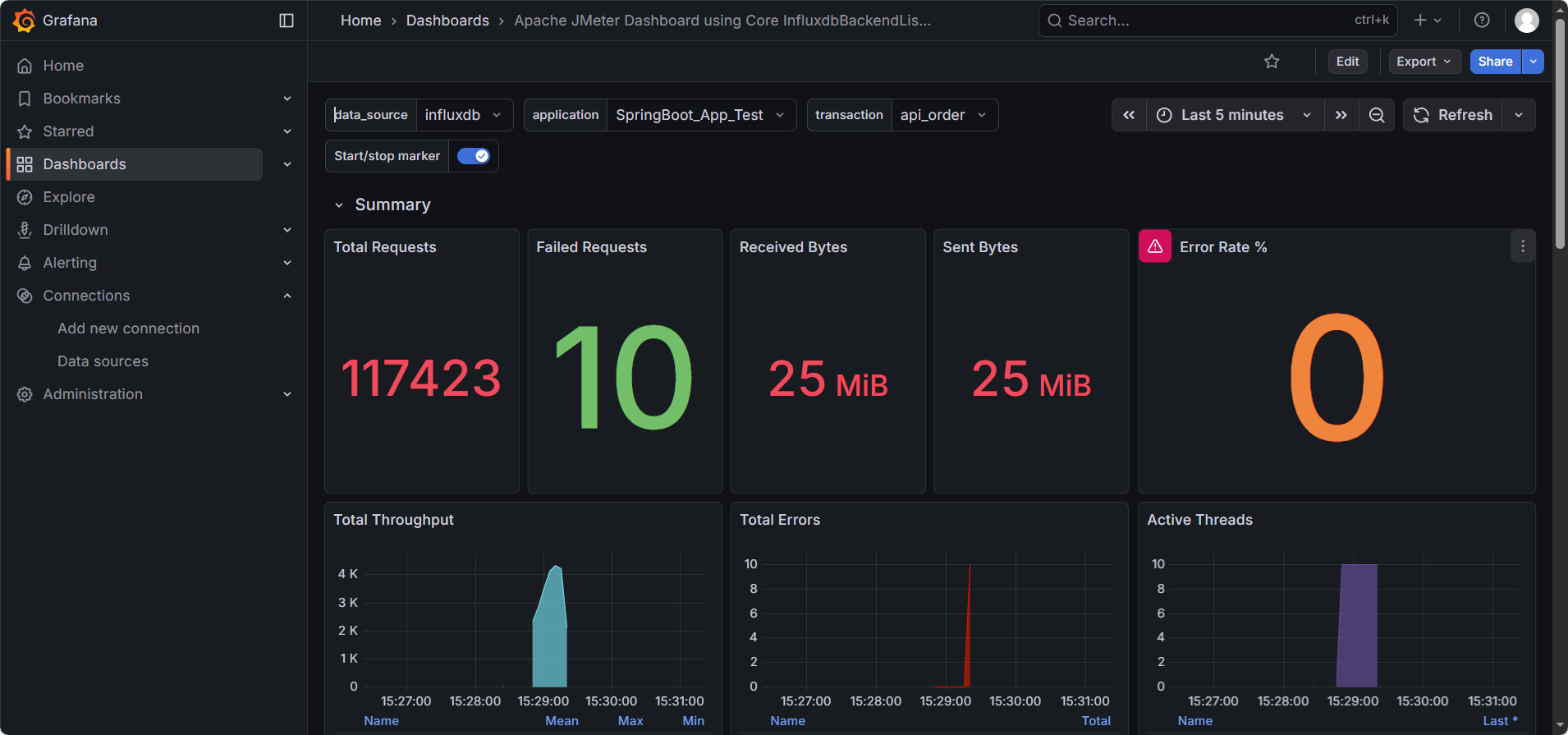
你将看到:
- Total Requests:请求数像里程表一样疯狂跳动。
- Active Users:显示当前在线的 50 个用户。
- Response Times (TR):平滑的曲线展示着 TP99 和 TP90 的波动。
- Throughput (TPS):绿色的线代表成功 TPS,红色的线代表失败 TPS。
最佳实践:在这一刻,你可以把 “察看结果树” 和 “聚合报告” 都禁用了。在大规模压测中,我们只需要盯着 Grafana 的这个大屏,就能掌握一切。
9.5. 深度解读:像医生一样看大屏
大屏跑起来了,但如果看不懂数据的含义,它就只是一张漂亮的壁纸。为了精准定位性能瓶颈,我们需要学会正确地使用 Grafana 的分区功能。
我们将遵循 “顶层筛选 -> 局部诊断 -> 异常排查 -> 全局总结” 的逻辑,带你读懂每一个像素。
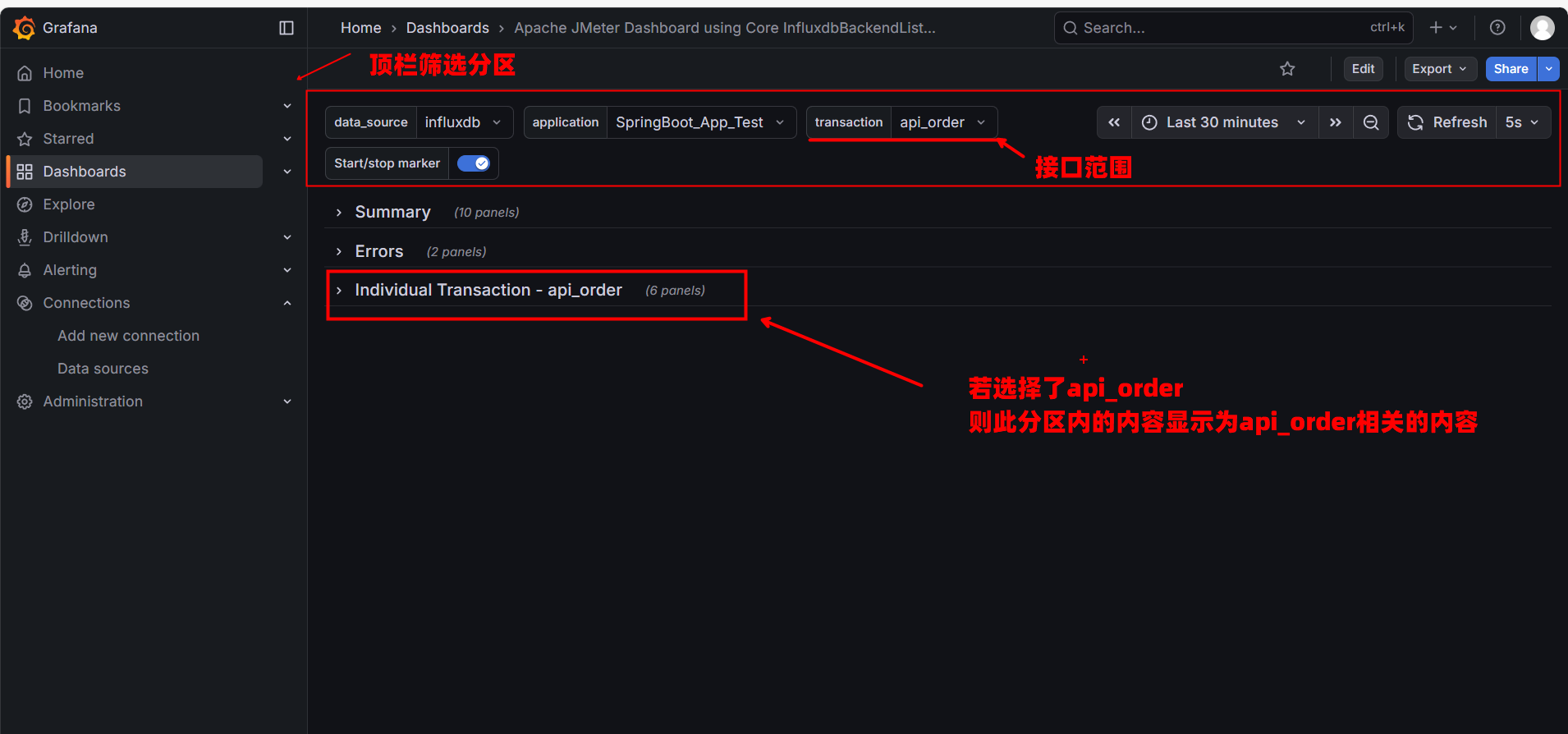
9.5.1. 驾驶舱:顶栏与折叠技巧
首先看屏幕最顶部的控制条,这是你的 “驾驶舱”。
1. 核心筛选器 (Filters)
- application: 对应 JMeter 后端监听器中配置的
application名。用于切换不同的压测项目。 - transaction (最关键):
- 默认是
all:显示所有接口的混合数据。 - 最佳实践:排查问题时,请务必切换到具体的接口(如
api_order)。因为 “登录” 的快可能会掩盖 “下单” 的慢,混合看数据容易产生误判。
- 默认是
- Time Range: 右上角的时间选择器。压测时建议选
Last 5 minutes,并开启Refresh 5s。
2. 分区折叠技巧
Grafana 的信息量很大,为了避免干扰,建议先利用行标题左侧的 小箭头 (>) 将所有分区折叠起来,只展开你需要关注的区域。
9.5.2. 局部诊断:Individual Transaction (独立分区)
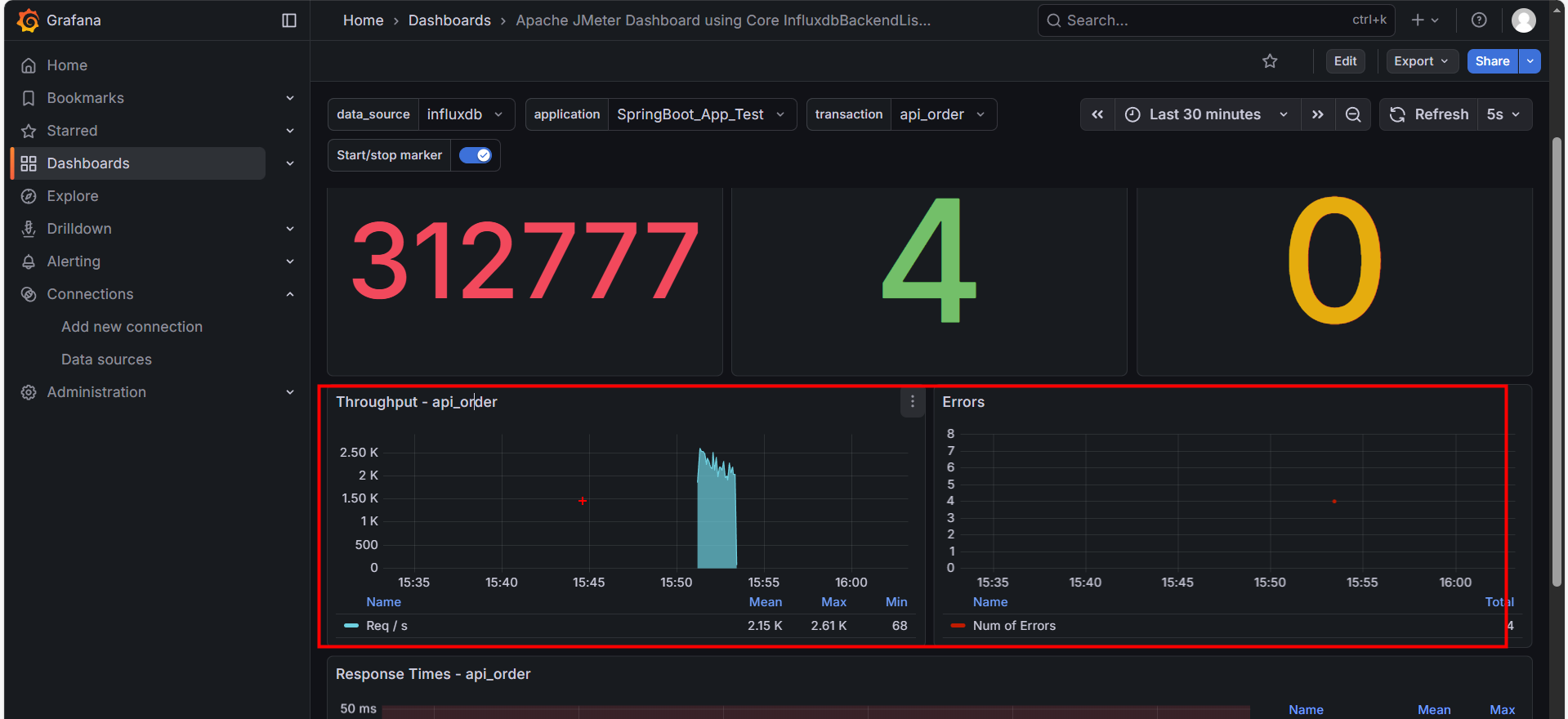
这是我们最先要关注的地方。请在顶栏 transaction 选择 api_order,然后展开 Individual Transaction - api_order 分区。这里展示了单一接口的健康状况。
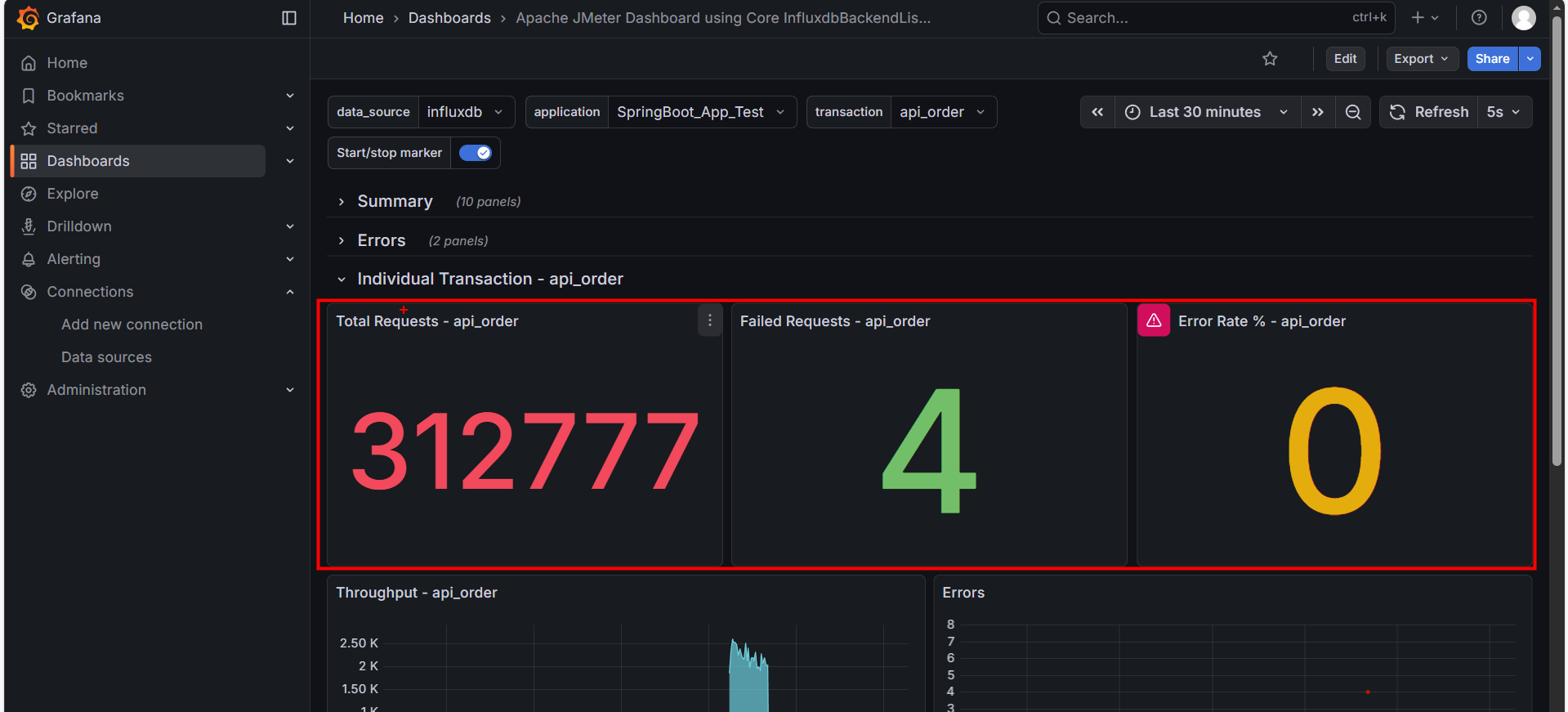
1. 核心仪表盘 (Dashboard)
- Total Requests: 该接口的请求总量。
- Failed Requests: 该接口的失败数量。
- Error Rate %: 红线指标。如果这里不是 0,说明该业务功能有 Bug 或服务器已崩溃。
2. 吞吐量趋势 (Throughput)
- 蓝色面积图:表示每秒处理成功的请求数 (TPS)。
- 健康形态:应该随着线程数的增加而平滑上升,最后趋于稳定。
- 病态形态:如果图像出现剧烈的 “断崖式下跌”,说明系统发生了阻塞(如数据库锁死)。
3. 响应时间 (Response Times)
这是判断性能拐点的核心图表。注意图中的几条线:
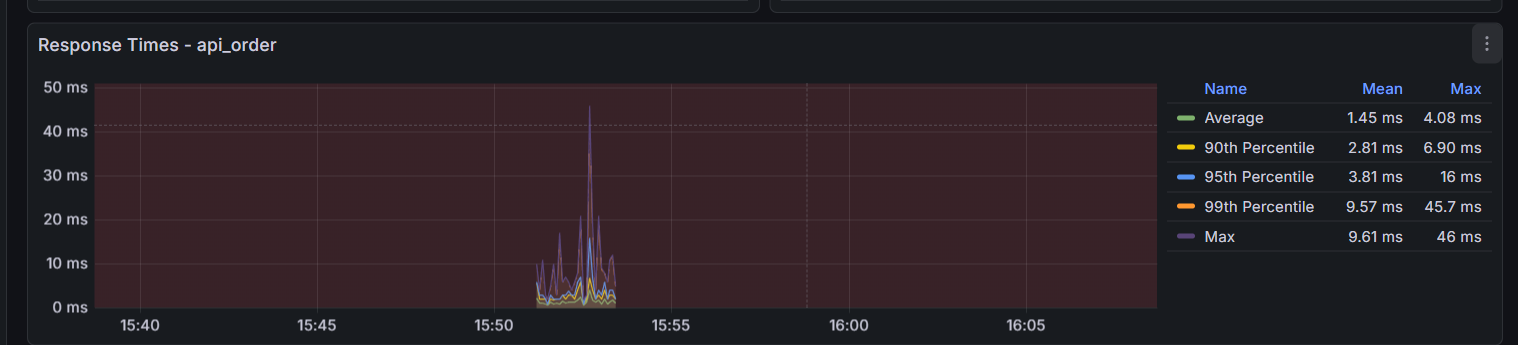
- Green (Mean): 平均响应时间。不要只看它,它具有欺骗性,假设马云和 9 个穷人在一起,平均资产是“人人都是亿万富翁”。在性能测试中,如果 99 个请求是 1ms,有 1 个请求卡死用了 10000ms(10 秒),平均时间 大约是 100ms。你看着 100ms 觉得“还行啊”,但那个卡死 10 秒的用户已经卸载你的 App 了。
黄线 (90th Percentile):第 90 名的成绩。
- 含义:意味着 90% 的用户,响应时间都 快于 这个数值。
蓝线 (95th Percentile):第 95 名的成绩。
- 含义:意味着 95% 的用户,体验都好于这个数值。这是业界最常用的 SLA (服务等级协议) 标准。如果老板问“我们系统慢不慢”,你就看这条线。
橙线 (99th Percentile):第 99 名的成绩。
- 含义:这条线代表了 系统的“短板”。如果这条线很高(例如飙升到 3 秒),说明偶尔会有用户遇到严重的卡顿。
Purple (Max): 最大响应时间。如果这条紫线偶尔飙升到几秒,说明存在 “长尾效应”(如 Full GC 停顿)
- 如果紫线紧贴着橙线(像图中医院):说明系统 极其稳定,没有奇怪的卡顿。
- 如果紫线偶尔 像针一样刺向天空(例如突然飙到 5000ms),而其他线很低:说明系统有 **“毛刺” **。
- 常见原因:Java 的垃圾回收 (Full GC) 卡顿、网络抖动、数据库死锁。
9.5.3. 异常分析:Errors (错误分区)
如果 Error Rate 变红了,我们需要立刻展开 Errors 分区来查明原因。
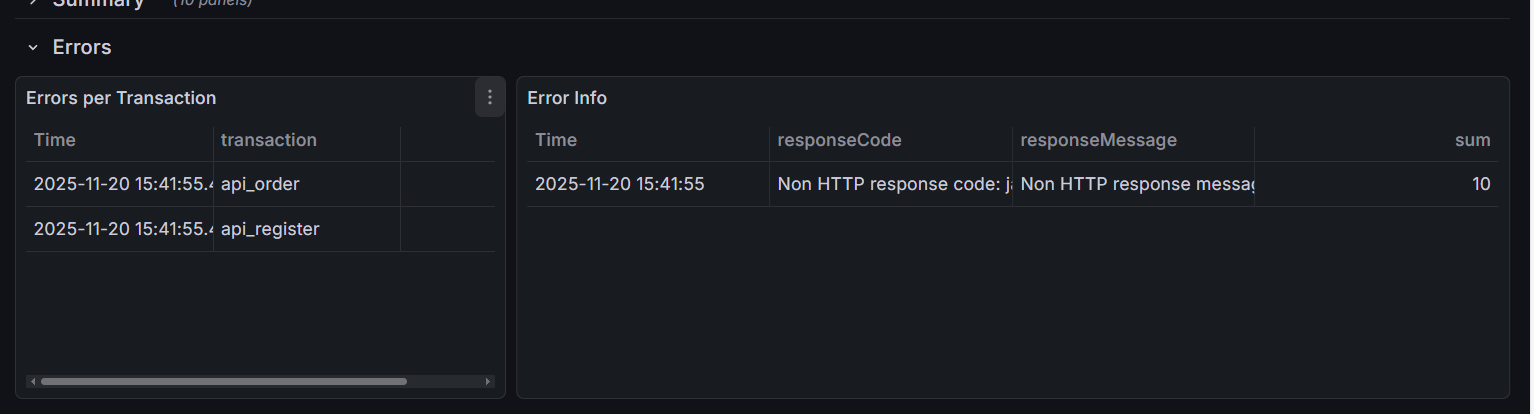
1. 错误分布表 (Errors per Transaction)
左侧表格告诉你 “谁错了”。是所有接口都挂了(可能是网关问题),还是只有 api_order 挂了(代码逻辑问题)。
2. 错误详情表 (Error Info)
右侧表格告诉你 “为什么错”。
- Response Code 500: 服务端内部错误(空指针、数据库连接失败)。
- Response Code 502/504: 网关超时。说明后端处理太慢,Nginx 等不及了。
特别注意:JMeter 强制停止导致的误报
如果你在压测过程中点击了 JMeter 的 “STOP” (强制停止) 按钮,Grafana 上可能会突然出现一批错误,报错信息通常为:
Non HTTP response code: java.net.SocketExceptionSocket closed
原因:JMeter 暴力断开了连接,导致 InfluxDB 记录了网络异常。
判断方法:如果这些错误仅出现在 压测结束的那一秒,请直接忽略它们,这属于 “人工误报”。
9.5.4. 全局总结:Summary (总结分区)
最后,我们展开最上方的 Summary 分区。这是给老板看 “最终成绩单” 的地方。
1. 宏观计数器
- Total Requests: 整个压测期间的总发包量。
- Error Rate %: 全局错误率。互联网应用通常要求小于 0.01%。
2. 网络流量 (Received/Sent Bytes)
- 作用:判断带宽瓶颈。
- 分析:如果你的 TPS 上不去,CPU 也很闲,但这里显示 Sent/Received 达到了几十 MB/s(接近千兆网卡极限),说明 带宽被打满了。这是很多新手容易忽略的硬件瓶颈。
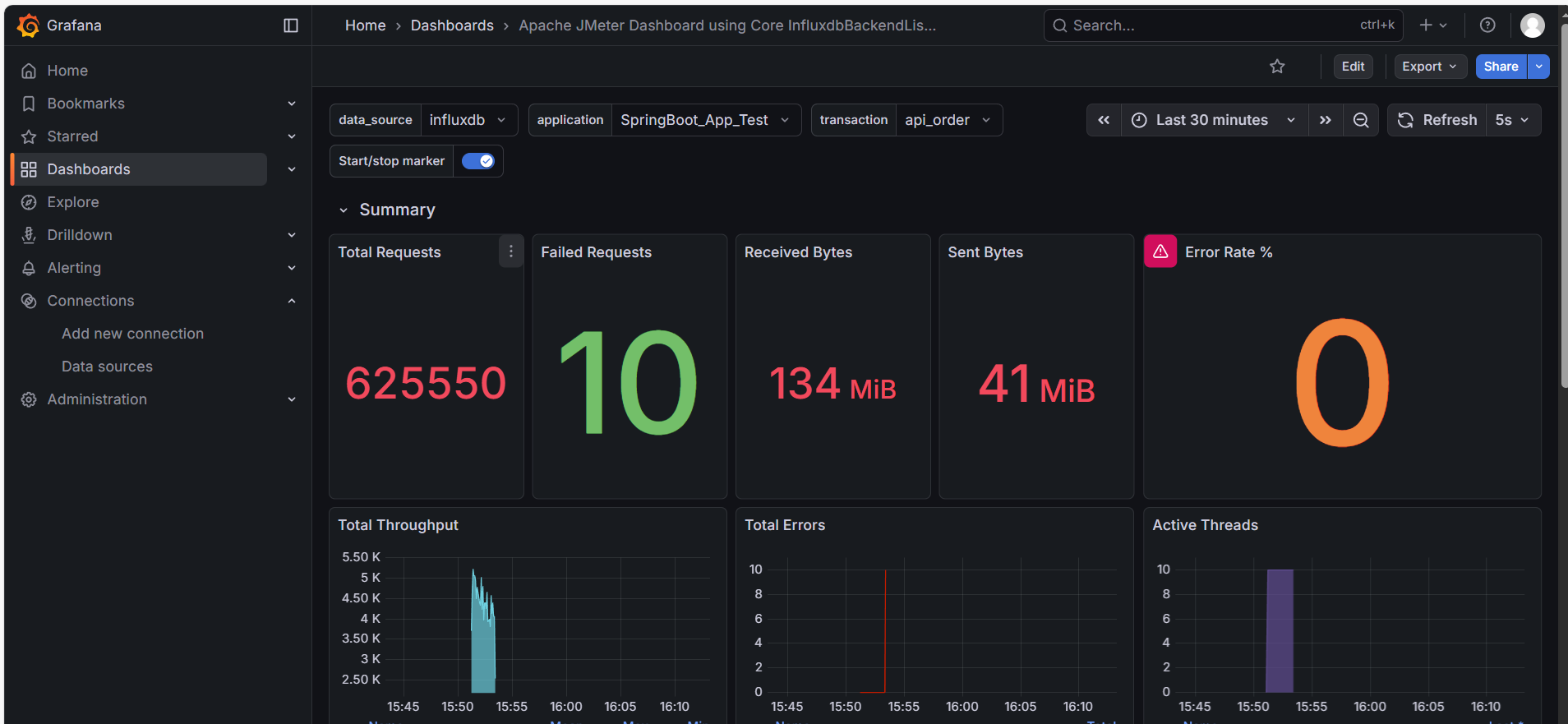
3. 活跃线程数 (Active Threads)
- 右下角的紫色柱状图。它展示了并发用户的爬升过程(Ramp-up)。
- 如果线程数突然 “腰斩”,说明 JMeter 客户端可能因为内存溢出(OOM)而崩溃了。
9.6 本章小结
本章我们搭建了专业的 JIG 监控链路,并学会了如何解读 Grafana 大屏。
核心要点:
- 架构优势:JMeter + InfluxDB + Grafana 彻底解决了 GUI 消耗资源大、无法回溯历史数据的问题。
- 看图逻辑:遵循 “筛选接口 -> 局部诊断 -> 查错 -> 全局总结” 的顺序,避免被海量数据淹没。
- 误报识别:压测结束时的
Socket closed错误通常是强制停止导致的,可忽略。 - 瓶颈判断:结合 TPS 曲线、P99 响应时间和网络带宽,综合定位是软件问题还是硬件限制。






