
Prorise
这是我的博客,分享技术与生活的点点滴滴
Note 19(序章). 分布式认证体系与全景学习路径详解,一文带你学会Java环境下的登录注册全生命周期
Note 19(序章). 分布式认证体系与全景学习路径详解,一文带你学会Java环境下的登录注册全生命周期
ProriseNote 19.0. 架构蓝图:分布式认证体系与全景学习路径
环境版本锁定
本系列教程我们会使用以下的技术栈
| 技术组件 | 版本号 | 说明 |
|---|---|---|
| JDK | 17 LTS | 推荐使用 Oracle/OpenJDK 17 |
| Spring Boot | 3.2.x | 2025 年主流稳定版 |
| Spring Cloud Gateway | 4.1.x | 新一代响应式网关 |
| Redis | 7.0+ | 用于 Token 存储与限流 |
| MySQL | 8.0+ | 存储用户与认证数据 |
| JWT Library | jjwt 0.12.x | Java JWT 标准实现 |
本章摘要
这是整个分布式 IAM 系统学习的开篇章节,我们不会编写任何业务代码,而是专注于构建认知框架。通过本章学习,你将理解为什么传统 Session 机制在微服务时代会失效,掌握现代认证中心的三层架构设计,明白用户表与认证凭证表为何要分离存储,并获得一张清晰的学习路线图,确保在后续深入 OAuth2 实现、三方登录聚合、SSO、手机号验证、高级登录策略、Clerk 云身份服务接入等复杂场景时不会迷失方向。
本章学习路径
本章采用 “历史演进 → 架构设计 → 数据建模 → 流程推演 → 路径规划” 的递进式结构:
阶段一:建立时代背景认知(19.1)
- 理解 Cookie-Session 在集群环境下的困境
- 掌握 Token 机制的设计思想与适用边界
- 区分认证与授权的职责边界
阶段二:构建全局架构视野(19.2)
- 从物理拓扑理解网关、认证服务、资源服务的协作关系
- 从逻辑视角掌握多租户与多渠道的矩阵设计
- 从安全维度建立纵深防御体系
阶段三:掌握数据建模范式(19.3)
- 识别传统单表设计的扩展性陷阱
- 学习账号-认证分离的 1: N 关系建模
- 理解联合唯一索引在防重复绑定中的作用
阶段四:推演核心业务流程(19.4)
- 跟踪用户从注册到登录的完整生命周期
- 理解 Token 在微服务间的透传机制
- 掌握网关鉴权与服务鉴权的职责划分
阶段五:规划渐进式学习路径(19.5)
- 获得从 OAuth2 鉴权到 Clerk 云身份服务接入的七阶段攻略
- 明确每个阶段的学习目标与核心产出
19.1. 认证技术的演进史
在开始构建现代分布式认证系统之前,我们需要理解技术选型背后的历史必然性。任何架构设计都不是凭空产生的,而是在特定时代背景下为了解决特定问题而诞生的。
19.1.1. 史前时代:Cookie-Session 机制的兴衰
在互联网发展早期,Web 应用大多运行在单一服务器上。当时的技术栈非常简单:一台 Tomcat 服务器,一个 MySQL 数据库,所有用户请求都由这台服务器处理。在这种环境下,Cookie-Session 机制几乎是完美的解决方案。
机制原理剖析
当用户首次访问网站时,整个认证流程是这样运作的:

这个机制的核心优势在于 状态存储在服务端。服务器的内存中维护着一个 Map 结构,Key 是随机生成的 SessionID,Value 是包含用户身份信息的 Session 对象。浏览器只需要在每次请求时通过 Cookie 自动携带 SessionID,服务器就能立即识别用户身份。
这种设计在单机环境下表现完美:响应速度快(内存查找)、安全性高(用户信息不暴露给客户端)、实现简单(Servlet 容器原生支持)。
致命痛点:集群环境的噩梦
但当业务增长、流量暴增,我们不得不部署多台服务器时,问题就暴露了。假设现在有两台 Tomcat 服务器,前面用 Nginx 做负载均衡:

用户明明刚登录成功,第二次请求却被告知 “未登录”。原因很简单:第一次请求被路由到 Tomcat-1,Session 存储在它的内存中;第二次请求被路由到 Tomcat-2,而它的内存里根本没有这个 Session。
业界曾经尝试过两种解决方案:
方案一:Session 复制(广播风暴)
让所有服务器之间互相同步 Session 数据。每当 Tomcat-1 创建一个 Session,就通过网络广播给 Tomcat-2、Tomcat-3…这会导致严重的性能问题:假设集群有 10 台服务器,每秒产生 1000 个新 Session,那么每台服务器每秒需要处理 9000 次网络同步请求。
方案二:Session 集中存储(Redis/MySQL)
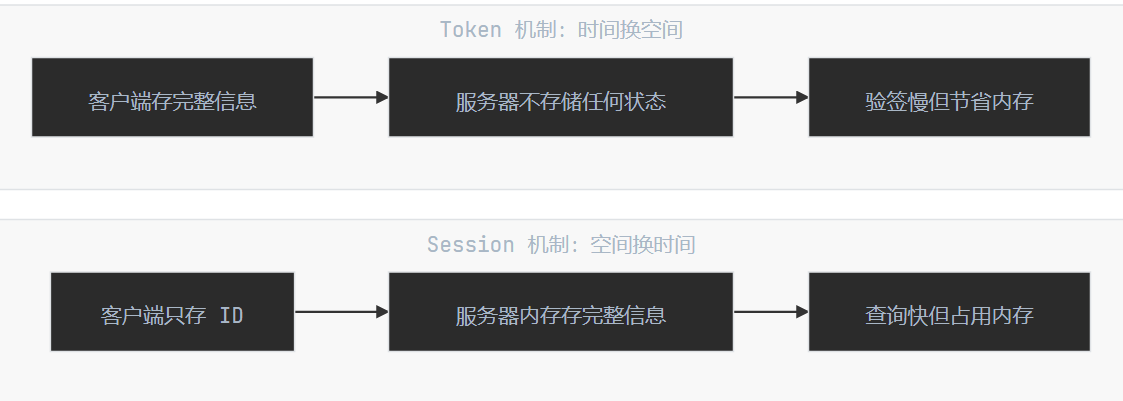
那么 Session 复制走不通,业界就将 Session 从服务器内存移到外部存储(如 Redis)。这虽然解决了共享问题,但引入了新的开销:原本的内存查找变成了网络 IO + Redis 查询,延迟从微秒级上升到毫秒级。更关键的是,这已经 违背了 Session 机制的初衷——如果我们需要外部存储,为什么不直接使用更轻量的 Token 方案?
适用边界:不是所有场景都要赶时髦
需要特别说明的是,Cookie-Session 机制在 2025 年依然有其不可替代的价值。对于 企业内部后台管理系统,这种场景具有以下特征:
- 用户规模可控(几百到几千)
- 不需要跨域调用(前后端同域部署)
- 安全要求高(不希望身份信息暴露在客户端)
- 部署简单(单机或小集群)
在这种场景下,使用 Spring Session + Redis 的方案反而是最稳定、最成熟的选择。技术选型的原则永远是 适合业务需求,而不是盲目追求新技术。
19.1.2. 变革时代:Token 机制的崛起
当互联网企业进入微服务时代,系统架构发生了根本性变化:单体应用被拆分成几十个独立服务,服务之间通过 HTTP/RPC 通信。在这种背景下,Token 机制成为了主流选择。
核心理念:用计算换存储
Token 机制的设计哲学与 Session 完全相反:不在服务器存储任何状态信息,而是将用户身份信息编码到 Token 本身,通过密码学签名保证其不可篡改。
一个典型的 JWT(JSON Web Token)结构如下:
1 | eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9. |
它由三部分组成(用 . 分隔):
- Header(头部):声明算法类型(如 HS256)
- Payload(载荷):存储用户信息(如 userId、username)
- Signature(签名):用密钥对前两部分进行签名
当用户登录成功后,认证流程变成了这样:
.svg)
关键点在于:业务服务不需要访问数据库或 Redis 来查询用户信息,只需要通过密码学算法验证签名的合法性,然后从 Payload 中直接读取 userId。这使得服务可以做到 完全无状态,符合微服务的设计原则。
当然我们需要纠正:JWT 不是银弹
很多初学者看到 Token 机制的优势后,会产生 “Token 全面优于 Session” 的错觉。但实际上,JWT 有三个经典问题:
注销难题:由于 Token 本身包含了过期时间,在过期之前服务器无法主动作废它。即使用户点击 “退出登录”,只要拿到这个 Token 的人,在过期前依然可以使用。
续签难题:如果 Token 有效期设置为 2 小时,用户在使用第 1 小时 59 分时发起请求,下一秒 Token 就过期了,用户体验很差。但如果设置为 7 天,又会放大注销问题的影响。
体积大问题:Session 的 Cookie 只有 20-30 字节(一个 SessionID),而 JWT 通常有 200-500 字节。当 Payload 中包含角色、权限等信息时,甚至会超过 1KB,增加网络传输开销。
最终形态:混合模式的智慧
现代架构普遍采用 “Gateway + JWT + Redis” 的混合方案:
- JWT 用于服务间通信:微服务之间传递身份信息时使用 JWT,保持无状态特性。
- Redis 用于状态管理:在网关层将 Token 与 Redis 关联,实现主动注销、续签、互斥登录等功能。
- 双 Token 机制:颁发短效的 Access Token(15 分钟)和长效的 Refresh Token(7 天),在 Access Token 过期时用 Refresh Token 自动续期。
这种方案结合了两种机制的优点:既保持了服务的无状态性(业务服务只认 JWT),又拥有了状态管理的能力(网关可以通过 Redis 控制 Token 生命周期)。
19.1.3. 架构分层:认证与授权的解耦
在讨论具体的技术实现之前, 我们需要先厘清两个经常被混淆的概念:认证(Authentication)与 授权(Authorization)。这也是面试中的高频考点。
概念澄清:你是谁 vs 你能干什么
认证(AuthN):解决 “你是谁” 的问题,验证用户的身份合法性。例如:用户输入账号密码,系统验证通过后确认 “你是张三”。
授权(AuthZ):解决 “你能干什么” 的问题,验证用户是否有权限执行某个操作。例如:确认张三是普通用户还是管理员,是否有权删除订单。
这两个过程在逻辑上是独立的:
.svg)
注意 HTTP 状态码的区别:
- 401:你没有提供有效的身份凭证(未登录或 Token 无效)
- 403:你的身份已确认,但没有权限访问这个资源(已登录但权限不足)
设计原则:职责分离的三层架构
在分布式系统中,我们遵循以下职责划分:
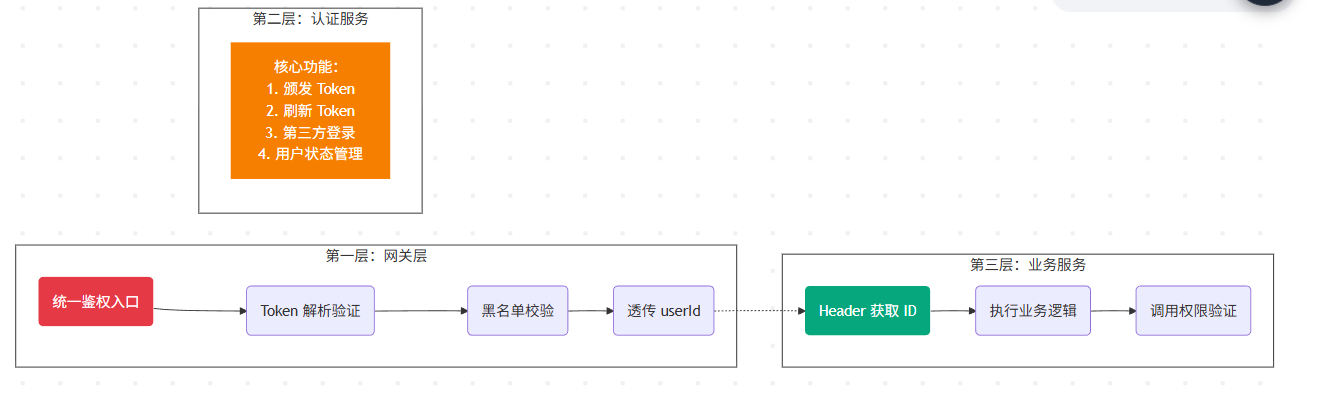
让我们用一个实际场景来理解这个架构:
场景:用户删除自己的订单
认证服务的工作:用户之前通过账号密码登录,认证服务验证密码正确后,生成了一个 JWT Token 并返回给客户端。此时认证服务的任务已经完成,它不关心用户后续要做什么操作。
网关层的工作:当用户发起
DELETE /orders/12345请求时,请求首先到达网关。网关从 Header 中提取 Token,验证签名有效性,解析出userId=1001,然后将这个信息通过 HTTP Header(如X-User-ID: 1001)传递给订单服务。业务服务的工作:订单服务收到请求后,从 Header 中读取
userId=1001,查询数据库确认 “订单 12345 是否属于用户 1001”,如果是则执行删除,如果不是则返回 403 错误。这个判断过程就是授权。
这种设计的优势在于:
- 认证服务专注于凭证管理:不需要了解业务规则,只负责 “验明正身”。
- 网关层统一拦截:避免每个服务都写一遍 Token 解析逻辑。
- 业务服务自主决策权限:不同的资源有不同的访问规则,由各自服务自行判断。
19.1.4 本节小结
我们通过历史演进的视角,理解了认证技术选型背后的必然性:
Cookie-Session 机制:在单体应用时代表现完美,但在集群环境下会遇到状态同步难题。它依然适用于企业内部后台系统等低并发、同域部署的场景。
Token 机制:通过 “用计算换存储” 的设计理念,实现了服务的无状态化,成为微服务架构的标准选择。但需要结合 Redis 解决注销、续签等状态管理问题。
认证与授权分离:认证解决 “你是谁”,授权解决 “你能干什么”。在分布式架构中,网关负责验证凭证,认证服务负责颁发凭证,业务服务负责执行权限判断。
19.2. 分布式认证中心的拓扑结构
在理解了认证技术的演进逻辑后,现在我们需要站在更高的视角,俯瞰整个分布式认证系统的架构全貌。这一节不会涉及任何代码实现,而是专注于回答三个关键问题:组件如何部署、流量如何流转、安全如何防御。
19.2.1. 物理架构:流量如何在组件间流转
一个完整的分布式认证系统,从物理部署的角度看,通常包含以下核心组件:
.svg)
让我们逐层剖析每个组件的职责边界。
网关层:第一道防线
所有外部请求必须先经过 API Gateway,这是系统的唯一入口。网关层承担以下核心职责:
统一鉴权:从请求的 Header 中提取 Token(通常是
Authorization: Bearer <token>格式),调用认证服务或直接验证签名,确认 Token 的有效性。黑名单拦截:查询 Redis 检查当前 Token 是否在黑名单中(用户主动登出、管理员强制下线等场景会将 Token 加入黑名单)。
身份透传:验证通过后,解析 Token 得到
userId,将其放入 HTTP Header(如X-User-ID)传递给下游服务。路由转发:根据请求路径将流量分发到对应的微服务(如
/orders/*路由到订单服务)。
网关层的核心设计原则是 快速失败:如果 Token 无效或已过期,直接在网关层返回 401 错误,避免无效请求进入业务服务浪费资源。
认证服务:核心中台
认证服务(Auth Service)是整个系统的大脑,负责所有与 “身份” 相关的逻辑:
Token 生命周期管理:
- 颁发 Token:用户登录成功后生成 JWT,同时在 Redis 中记录 Token 与 userId 的映射关系。
- 刷新 Token:当 Access Token 即将过期时,用 Refresh Token 换取新的 Access Token。
- 作废 Token:用户登出时将 Token 加入 Redis 黑名单(Key 为
blacklist:token:<token>,过期时间与 Token 的剩余有效期一致)。
多渠道登录接入:
- 传统账号密码登录
- 手机验证码登录
- 第三方 OAuth 登录(微信、GitHub、Google 等)
- 扫码登录(PC 端扫码场景)
用户状态管理:
- 维护用户的启用/禁用状态
- 记录登录日志(IP、设备、时间)
- 处理账号绑定与解绑
认证服务的设计原则是 单一职责:只管理凭证,不处理业务逻辑。例如,认证服务知道 “用户 1001 登录成功”,但不关心 “用户 1001 有多少订单”。
资源服务:业务执行者
订单服务、用户服务、商品服务等业务微服务,我们统称为资源服务(Resource Service)。这些服务的特点是:
完全信任网关传递的身份信息:从
X-User-IDHeader 中读取用户 ID,不再进行 Token 验证(因为网关已经验证过)。聚焦业务逻辑:基于用户 ID 执行具体的业务操作,如创建订单、修改地址。
自主判断权限:根据业务规则决定当前用户是否有权操作某个资源。例如,订单服务判断 “用户只能删除自己的订单”。
这种架构下,业务服务的代码会变得非常简洁:
1 |
|
完整请求链路演示
让我们用一个完整的时序图展示流量的流转过程:
.svg)
这个流程有几个关键细节:
网关不会每次都调用认证服务:由于 JWT 自包含用户信息,网关可以直接验证签名并解析出 userId,无需远程调用认证服务。只有在黑名单场景下才需要查询 Redis。
业务服务不感知 Token:订单服务收到的请求中已经没有 Token,只有一个简单的
X-User-IDHeader。这使得业务服务可以专注于业务逻辑,不被认证机制绑定。授权发生在业务服务:网关只负责 “验证你是谁”,而 “你能不能访问这个订单” 的判断由订单服务自己完成。
19.2.2. 逻辑架构:多租户与多渠道的矩阵设计
在物理架构解决了 “组件部署” 问题后,我们还需要从逻辑视角解决两个复杂的业务挑战:多渠道接入 与 多租户隔离。
多渠道挑战:一套后端支撑多种客户端
现代应用往往需要同时支持多种客户端类型:
.svg)
关键问题是:这些不同的认证方式最终都要映射到同一个用户体系。例如:
- 用户在 Web 端用账号密码登录,系统识别为 “用户 1001”。
- 同一个用户在 App 端用微信登录,系统也要识别为 “用户 1001”。
- 当用户通过 OpenAPI 调用时,通过 API Key 依然要关联到 “用户 1001”。
这就需要在设计上做到 渠道无关性:认证服务对外暴露统一的接口 /auth/login,通过请求参数中的 authType 字段路由到不同的认证策略:
1 | public interface AuthStrategy { |
具体的策略实现:
PasswordAuthStrategy:验证账号密码SmsCodeAuthStrategy:验证手机验证码WechatAuthStrategy:调用微信接口验证 codeGithubAuthStrategy:调用 GitHub 接口验证 code
这种设计的好处是扩展性极强:当需要新增 “支付宝登录” 时,只需要新增一个 AlipayAuthStrategy 实现类,不需要修改任何现有代码。
多租户隔离:SaaS 场景的必修课
在 SaaS(Software as a Service)模式下,多个企业共用同一套系统,但数据必须严格隔离。这要求在认证层就建立租户概念:
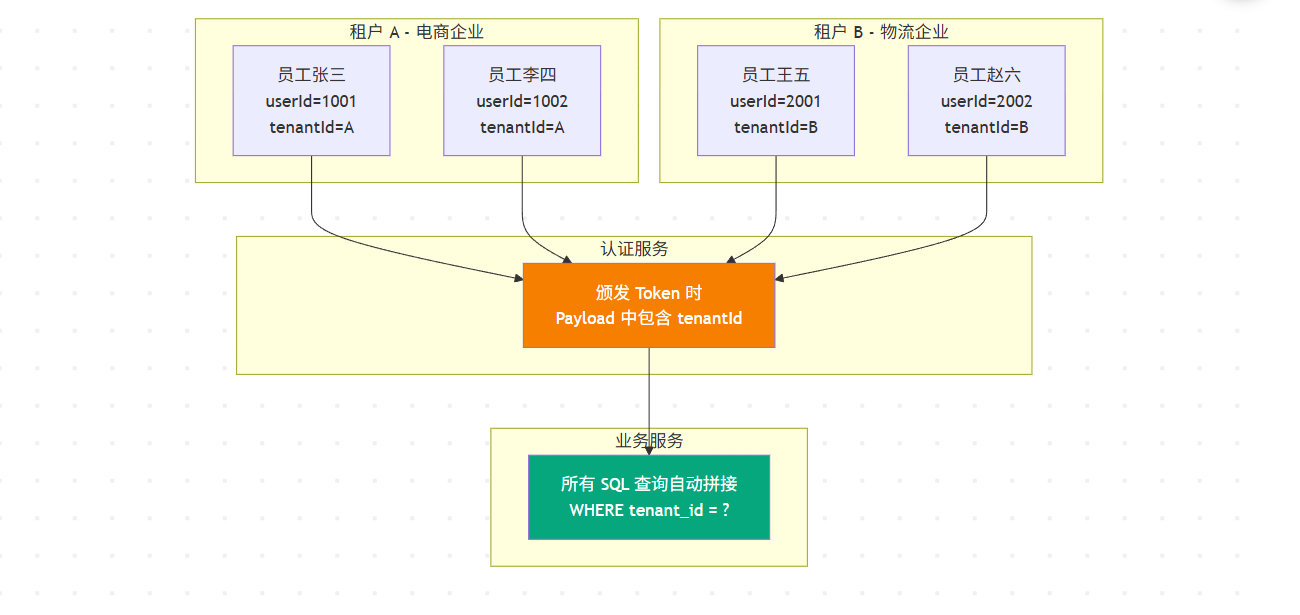
在这种架构下,Token 的 Payload 中不仅包含 userId,还包含 tenantId:
1 | { |
网关在透传身份时,会同时传递两个 Header:
1 | X-User-ID: 1001 |
业务服务在执行所有数据库操作时,都会自动拼接租户条件:
1 | -- 查询订单时自动添加租户过滤 |
这种设计确保了即使攻击者拿到了租户 A 的 Token,也无法访问租户 B 的数据。
19.2.3. 安全架构:构建纵深防御体系
安全不是单一措施能解决的问题,而是需要在传输层、应用层、数据层建立多道防线。
传输层:HTTPS 与公钥传输
所有涉及敏感信息的传输必须使用 HTTPS 加密:
.svg)
HTTPS 的本质是在客户端和服务器之间建立一条加密通道,所有传输的数据都会被 TLS 协议加密。当用户在登录框中输入密码 123456 后,这个明文密码在离开浏览器之前就会被加密成一段密文(类似 8f3e9a7b...),即使黑客在网络中间截获了这段数据,也无法还原出原始密码。
但 HTTPS 并非绝对安全,它依然存在一些边界场景的风险。最典型的是公共 WiFi 环境下的中间人攻击:攻击者在咖啡厅架设一个伪造的 WiFi 热点,当用户连接后,攻击者可以通过 SSL 剥离技术将 HTTPS 降级为 HTTP,或者通过伪造证书的方式欺骗用户的浏览器。虽然现代浏览器对证书验证非常严格,但在某些 App 内嵌 WebView 的场景下,如果开发者没有正确实现证书校验,依然可能被攻破。
为了应对这种极端场景,我们可以在 HTTPS 之上再加一层防护:前端 RSA 加密 + 后端私钥解密。具体流程是这样的:
在用户打开登录页面时,前端先调用 /auth/get-public-key 接口获取服务器的 RSA 公钥(这个接口本身也是通过 HTTPS 传输)。服务器会生成一对 RSA 密钥,将公钥返回给前端,私钥保存在服务器内存中。前端拿到公钥后,当用户点击登录按钮时,使用这个公钥对密码进行加密,得到一段长度为 256 字节的密文。这段密文再通过 HTTPS 发送给服务器。
服务器收到请求后,先通过 TLS 解密得到 RSA 加密后的密文,然后用私钥再解密一次,才能得到原始密码。这样即使 HTTPS 被攻破,攻击者拿到的也只是 RSA 加密后的密文。由于 RSA 是非对称加密,攻击者没有私钥就无法解密,密码依然是安全的。
这种双重加密的代价是增加了约 50ms 的加密解密耗时,但对于登录这种低频操作来说,这个开销是可以接受的。需要注意的是,RSA 公钥应该设置有效期(如 5 分钟),并且每个用户的登录请求都应该使用不同的密钥对,防止密钥被长期重复使用而增加破解风险。
应用层:XSS、CSRF 与重放攻击防御
在 HTTPS 保护了传输安全后,我们还需要在应用层防御三种常见的攻击手段。
| 攻击类型 | 攻击原理 | 防御措施 |
|---|---|---|
| XSS(跨站脚本) | 攻击者注入恶意 JS 代码,窃取 Token | Token 存储在 HttpOnly Cookie 或 Memory 对用户输入进行转义 |
| CSRF(跨站请求伪造) | 攻击者诱导用户访问恶意网站 该网站向目标站点发起请求 | Cookie 设置 SameSite = Strict 关键操作需要二次验证 |
| 重放攻击 | 攻击者截获请求后重复发送 | 请求中加入 nonce(一次性随机数) 服务端用 Redis 记录已使用的 nonce |
假设我们的系统有一个用户评论功能,攻击者在评论框中输入了这样一段内容:
1 | var token = localStorage.getItem('access_token'); |
如果后端没有对这段输入进行过滤,当其他用户查看这条评论时,这段 JavaScript 代码就会在他们的浏览器中执行。代码会从 localStorage 中读取当前用户的 Token,然后发送到攻击者的服务器。攻击者拿到 Token 后,就可以伪装成受害者登录系统,执行任意操作。
防御 XSS 的核心措施有两个:
第一,Token 不要存储在 localStorage 中。localStorage 中的数据可以被页面上的任何 JavaScript 代码读取,包括第三方脚本和恶意注入的代码。更安全的方式是存储在 HttpOnly Cookie 中。HttpOnly 是 Cookie 的一个属性标记,当设置了这个标记后,JavaScript 代码就无法通过 document.cookie 读取到这个 Cookie 的值,只有浏览器在发送请求时会自动携带它。
第二,对所有用户输入进行转义。当用户提交的内容包含 <script> 等 HTML 标签时,后端应该将 < 转义为 <,将 > 转义为 >,这样内容在页面上显示时只会被当作普通文本,而不会被浏览器解析为可执行代码。
CSRF(跨站请求伪造)的隐蔽性
CSRF 攻击的场景是这样的:你已经登录了银行网站 bank.com,浏览器中保存了登录态的 Cookie。此时你在另一个标签页访问了一个恶意网站 evil.com,这个网站的页面中嵌入了这样一段代码:
1 | <img src="https://bank.com/transfer?to=hacker&amount=10000" /> |
当浏览器加载这个图片标签时,会自动向 bank.com 发起 GET 请求,并且会自动携带 bank.com 的 Cookie(因为浏览器的同源策略只限制读取响应,不限制发送请求)。如果银行网站没有防护,这个请求就会被当作正常的转账请求处理,你的账户里的钱就被转走了。
防御 CSRF 的关键是让服务器能够区分 “用户主动发起的请求” 和 “恶意网站伪造的请求”。最有效的措施是设置 Cookie 的 SameSite 属性:
1 | Set-Cookie: session_id=abc123; HttpOnly; Secure; SameSite=Strict |
SameSite=Strict 表示这个 Cookie 只会在同站请求时被发送。什么是同站请求?就是从 bank.com 的页面发起到 bank.com 的请求。如果是从 evil.com 发起到 bank.com 的请求,浏览器就不会携带这个 Cookie,服务器收到请求时发现没有 Cookie,就会拒绝处理。
但 SameSite=Strict 有一个副作用:如果用户通过外部链接(如邮件中的链接)跳转到你的网站,由于是跨站跳转,Cookie 不会被携带,用户会被当作未登录状态。如果这种场景比较常见,可以使用 SameSite=Lax,它允许从外部链接跳转时携带 Cookie,但禁止 POST、PUT、DELETE 等修改操作携带 Cookie。
对于特别敏感的操作(如修改密码、删除账号、大额转账),即使设置了 SameSite,也应该要求 二次验证,比如输入短信验证码或支付密码,确保是用户本人的真实意图。
重放攻击的时间维度
重放攻击的场景是:攻击者在网络中截获了用户的一次合法登录请求(包括 Token),然后在未来的某个时间点,将这个请求原封不动地重新发送给服务器。如果服务器只验证 Token 的有效性,而不检查请求的时效性,就会误以为这是一次新的请求并正常处理。
防御重放攻击的核心是引入不可重复性。最常见的方案是在请求中加入一个 nonce(一次性随机数)。具体流程是:
客户端在发起请求时,生成一个随机的 UUID(如 f47ac10b-58cc-4372-a567-0e02b2c3d479),将它放在请求头的 X-Request-Nonce 字段中。服务器收到请求后,先检查 Redis 中是否已经存在这个 nonce:
1 | String nonce = request.getHeader("X-Request-Nonce"); |
针对 Token 存储位置的选择:
.svg)
当然,在 现代化 Spring Boot 项目中,只要引入了 Spring Security 依赖,CSRF 防护默认就是开启的(针对传统的表单提交和 Cookie-Session 模式)
下表总结了对于防护系列各个前后端框架做的工作以下是针对现代化 Spring Boot(前后端分离架构)完善后的安全防护对照表:
| 安全问题 | Spring Security | Axios / Fetch | Vue / React | 是否需要手动配置 |
|---|---|---|---|---|
| CSRF | ✅ 默认开启 (需改为 Cookie 存储模式) | ⚠️ Axios: 自动读取 ⚠️ Fetch: 需手动封装 | ❌ 不涉及 | 是 (需配置 CookieCsrfTokenRepository) |
| XSS | ✅ 提供 CSP 等安全响应头 ❌ API 层的 JSON 不自动转义 | ❌ 不涉及 | ✅ 默认转义数据绑定 ⚠️ v-html 等指令除外 | 是 (后端需配置富文本过滤器/Jackson 转义) |
| CORS | ✅ 默认拦截跨域请求 | ✅ 浏览器自动执行预检 | ❌ 仅开发环境配置代理 | 是 (需配置 CorsConfigurationSource) |
| 重放攻击 | ❌ 不提供 | ❌ 不提供 | ❌ 不提供 | 是 (需实现 Nonce + Timestamp 校验) |
| SameSite | ✅ Boot 2.6+ 默认 Lax ✅ 配合 Secure 属性 | ✅ 浏览器自动遵循 | ❌ 不涉及 | 否 (除非做跨域 Cookie 共享需改为 None) |
| 点击劫持 | ✅ 默认禁止 (X-Frame-Options) | ❌ 不涉及 | ❌ 不涉及 | 否 (除非需允许被 Iframe 嵌入) |
| SQL 注入 | ❌ 需依赖 JPA/MyBatis | ❌ 不涉及 | ❌ 不涉及 | 否 (只要使用预编译/ORM 即可) |
数据层:密码哈希与敏感数据脱敏
用户密码绝对不能明文存储,必须经过不可逆的哈希算法处理:

BCrypt 算法的核心特性:
- 自带盐值:每次哈希同一个密码,结果都不同,防止彩虹表攻击。
- 可调节成本:通过 Work Factor 参数控制计算复杂度,随着硬件性能提升可以增加此参数。
- 慢哈希特性:单次计算耗时约 100ms,使得暴力破解成本极高。
验证密码时的流程:
1 | // 注册时存储 |
除了密码,其他敏感数据也需要脱敏处理:
- 手机号:日志中显示为
138****5678 - 身份证号:显示为
110***********1234 - 邮箱:显示为
abc***@gmail.com
19.2.4 本节小结
我们从三个维度构建了分布式认证系统的架构视野:
物理架构:明确了网关、认证服务、业务服务的职责边界与流量流转路径。网关负责统一鉴权,认证服务负责 Token 管理,业务服务只需从 Header 读取用户 ID。
逻辑架构:通过策略模式实现多渠道接入的扩展性,通过租户 ID 实现 SaaS 场景的数据隔离。
安全架构:在传输层使用 HTTPS,在应用层防御 XSS/CSRF/重放攻击,在数据层使用 BCrypt 哈希存储密码。
19.3. 核心领域模型设计:解耦用户与凭证
在理解了宏观架构后,我们需要深入数据建模层面,解决一个核心问题:如何设计数据库表结构,才能优雅地支撑 “一个用户拥有多种登录方式” 这个需求?
19.3.1. 传统设计的弊端:单表走天下
很多初学者在设计用户表时,会采用这种 “看似合理” 的结构:
1 | CREATE TABLE sys_user ( |
这种设计在业务初期看起来没问题,但随着登录方式的增加,会陷入三个典型陷阱:
陷阱一:字段爆炸
当需要支持新的登录方式时(如支付宝、抖音、企业微信),你会不断添加新列:
1 | ALTER TABLE sys_user ADD COLUMN alipay_uid VARCHAR(50); |
最终表结构变成了一个 “万金油” 表,包含几十个字段,其中大部分字段对于单个用户来说都是 NULL。
陷阱二:索引混乱
为了支持 “通过手机号登录”、“通过微信 OpenID 登录”,你需要为每个登录字段建立唯一索引:
1 | CREATE UNIQUE INDEX idx_mobile ON sys_user(mobile); |
但这些索引会遇到 NULL 值问题:MySQL 的唯一索引允许多个 NULL 值,导致约束失效。例如,两个只用微信登录的用户,他们的 mobile 字段都是 NULL,这是允许的,但如果后来其中一个用户绑定了手机号,可能会与另一个用户的手机号冲突。
陷阱三:查询复杂
当用户登录时,你需要根据登录类型执行不同的 SQL:
1 | // 手机号登录 |
代码中充满了 if-else 分支,违反了开闭原则,且难以维护。
19.3.2. 现代方案:账号-认证分离模型(1: N)
业界成熟的解决方案是将 “用户主体” 与 “登录凭证” 分离存储,建立一对多关系:
.svg)
用户基础表(sys_user):定义主体
这个表只存储用户的基本属性,不包含任何登录相关的信息:
1 | CREATE TABLE sys_user ( |
关键设计点:
- ID 生成策略:使用雪花算法(Snowflake)而非数据库自增 ID,确保分布式环境下的全局唯一性。
- 极简字段:只保留与业务强相关的字段,登录相关信息全部迁移到
sys_auth表。
授权凭证表(sys_auth):定义凭证
这个表存储用户的所有登录方式:
1 | CREATE TABLE sys_auth ( |
数据示例:一个用户的多种登录方式
假设用户 “张三” 先用手机号注册,后来又绑定了微信和 GitHub:
sys_user 表:
| id | nickname | avatar | status |
|---|---|---|---|
| 1748392847362 | 张三 | https://cdn…/avatar.jpg | 1 |
sys_auth 表:
| id | user_id | identity_type | identifier | credential |
|---|---|---|---|---|
| 1 | 1748392847362 | MOBILE | 13812345678 | (空,验证码登录无需存储密码) |
| 2 | 1748392847362 | PASSWORD | zhangsan | rQ7R8k… (BCrypt 哈希) |
| 3 | 1748392847362 | oX4Gt5k… | (空,或存储微信 Token) | |
| 4 | 1748392847362 | GITHUB | 12345678 | (空,GitHub ID 本身就是标识符) |
通过这种设计:
- 新增登录方式只需在
sys_auth表插入一条记录,无需修改表结构。 - 每种登录方式都有明确的
identity_type标记,查询时非常清晰。 - 用户可以同时拥有多种登录方式,系统会自动关联到同一个
user_id。
19.3.3. 索引与性能优化策略
数据模型设计完成后,索引设计直接决定了查询性能和数据一致性。
联合唯一索引:防止重复绑定
sys_auth 表的核心索引是:
1 | UNIQUE KEY uk_type_identifier (identity_type, identifier) |
这个索引保证了 “同一种类型的标识符全局唯一”。例如:
- 手机号
13812345678只能被一个用户绑定(identity_type=MOBILE, identifier=13812345678)。 - 微信 OpenID
oX4Gt5k...也只能被一个用户绑定(identity_type=WECHAT, identifier=oX4Gt5k...)。
如果另一个用户尝试绑定已被占用的手机号,数据库会抛出唯一性冲突错误:
1 | Duplicate entry 'MOBILE-13812345678' for key 'uk_type_identifier' |
业务代码需要捕获这个异常并返回友好提示:“该手机号已被其他账号绑定”。
覆盖索引:减少回表操作
当用户登录时,我们需要根据登录方式查询对应的 user_id:
1 | SELECT user_id, credential |
由于 uk_type_identifier 是联合唯一索引,且查询的列(user_id, credential)也在索引中(需要在索引中包含这些列才能形成覆盖索引,但当前设计中 user_id 和 credential 不在唯一索引中),MySQL 需要先通过索引定位到记录,再回表查询完整行数据。
为了优化这个高频查询,可以将 user_id 和 credential 添加到索引中,形成覆盖索引:
1 | -- 删除原索引 |
但这会增加索引的存储开销。在实际项目中,需要根据查询频率权衡是否使用覆盖索引。
分库分表:千万级用户的扩展
当用户量达到千万级时,单表 sys_auth 可能成为瓶颈。此时可以考虑分库分表策略:
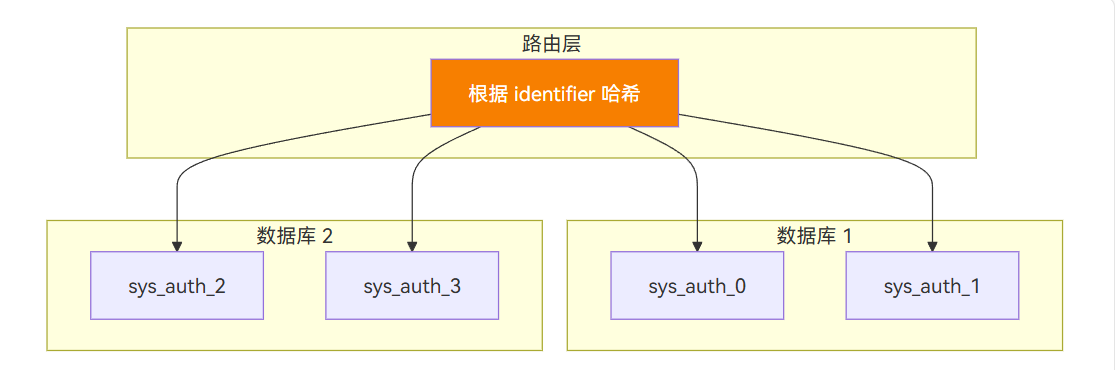
分片键选择 identifier 而非 user_id,因为登录查询是根据手机号或 OpenID 进行的,选择 identifier 可以确保单次查询只命中一个分片。
19.3.4 本节小结
我们通过对比传统单表设计与现代分离模型,理解了数据建模的核心原则:
传统单表设计:将所有登录方式的字段塞入一个表,会导致字段爆炸、索引混乱、查询复杂等问题。
账号-认证分离模型:将用户主体(
sys_user)与登录凭证(sys_auth)分离,建立 1: N 关系。用户表只存储基本信息,凭证表存储所有登录方式。索引优化:通过
identity_type(凭证类型), identifier(唯一凭证)联合唯一索引防止重复绑定,通过覆盖索引减少回表操作。在千万级用户场景下,可根据identifier进行分库分表。
19.4. 核心流程编排:登录与注册的生命周期
有了数据模型后,我们需要将静态的表结构 “激活” 成动态的业务流程。这一节我们将推演用户从陌生人到系统受信主体的完整生命周期。
19.4.1. 注册流程:从陌生人到受信任主体
用户注册是系统接纳新用户的过程,需要经过严格的验证与落库操作。
完整注册流程
.svg)
关键步骤解析
步骤一:验证码校验
在插入数据库前,必须先完成三重校验:
- 格式校验:手机号是否符合正则
^1[3-9]\d{9}$。 - 验证码校验:从 Redis 中取出存储的验证码,与用户输入的验证码比对。
- 唯一性检查:查询
sys_auth表,确认该手机号是否已被注册。
为了优化唯一性检查,可以使用布隆过滤器(Bloom Filter):
1 | // 系统启动时将所有已注册手机号加载到布隆过滤器 |
布隆过滤器的优势在于:当手机号未注册时,可以 100% 确定它不存在,避免了数据库查询。但要注意它有误判率(配置为 1%),需要二次确认。
步骤二:双表事务落库
注册操作需要向两个表插入数据:
1 |
|
这里有个重要的设计决策:先插 User 还是先插 Auth?
答案是必须先插 sys_user,因为 sys_auth 表的 user_id 字段是外键,依赖 sys_user 的主键。如果先插 sys_auth,在高并发场景下可能会因为 sys_user 插入失败导致孤立数据。
步骤三:后置处理
注册成功后,通常需要触发一系列后置操作:
1 | // 发送异步事件 |
使用事件机制的好处是将非核心逻辑解耦,即使发送邮件失败也不会影响注册流程的完成。
19.4.2. 登录流程:凭证交换与会话建立
登录是将用户提供的凭证(密码/验证码/OAuth Code)转换为系统 Token 的过程。
策略路由:根据登录类型分发
由于支持多种登录方式,我们需要在入口处进行路由分发:
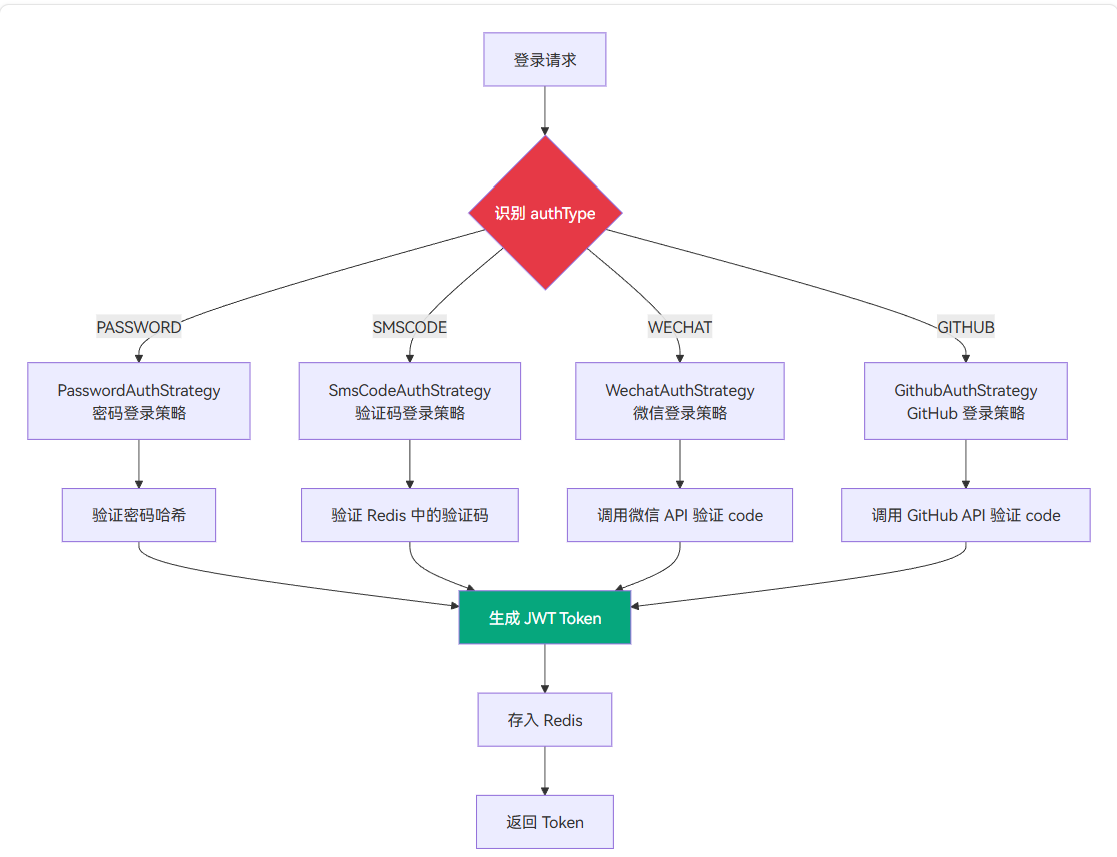
凭证比对:不同策略的验证逻辑
以密码登录为例:
1 | public class PasswordAuthStrategy implements AuthStrategy { |
验证码登录的策略则是查询 Redis:
1 | public class SmsCodeAuthStrategy implements AuthStrategy { |
令牌生成:组装 JWT 与 Redis 存储
所有策略验证成功后,统一调用 Token 生成服务:
1 | public String generateToken(Long userId) { |
19.4.3. 鉴权流程:无感知的身份传递
用户拿到 Token 后,在访问受保护资源时,身份信息需要在微服务间无缝传递。
网关透传:解析 Token 并注入 Header
.svg)
Feign 拦截器:服务间调用的身份接力
当订单服务需要调用用户服务时,也需要传递身份信息:
1 |
|
上下文持有:ThreadLocal 的全局参数传递
为了避免在每个方法中都传递 userId 参数,可以使用 ThreadLocal 在服务内部共享用户信息:
1 | public class UserContext { |
19.4.4 本节小结
我们推演了用户从注册到登录、再到访问资源的完整流程:
注册流程:通过验证码校验、格式校验、唯一性检查后,在事务中向
sys_user和sys_auth两个表插入数据,最后触发后置事件(发送欢迎邮件、分配默认角色)。登录流程:根据
authType路由到不同的认证策略,验证凭证后生成 JWT Token,并在 Redis 中记录 Token 与用户的关联关系。鉴权流程:网关解析 Token 并将用户 ID 注入到 HTTP Header,下游服务通过 Header 获取身份信息。在服务间调用时,通过 Feign 拦截器自动传递 Header,在服务内部通过 ThreadLocal 实现全局参数共享。
19.4. 学习地图:从入门到专家的进阶路径
在完成了架构设计、数据建模、流程推演后,我们已经对分布式 IAM 系统有了基础认知。现在需要规划一条清晰的学习路径,确保在后续深入代码实现时不会迷失方向。
整个学习过程分为七个阶段,每个阶段都有明确的目标和产出:
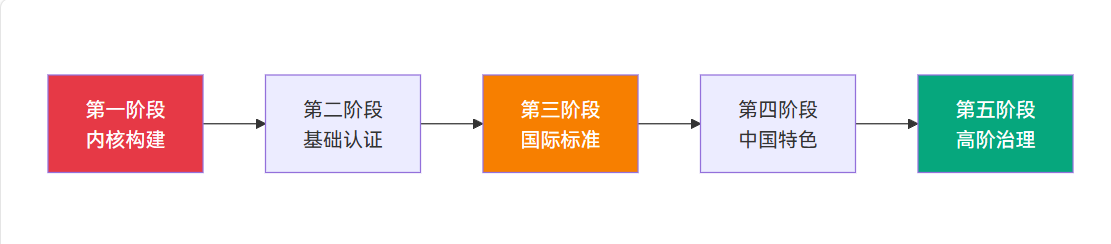
19.4.1. 第一阶段:OAuth2 鉴权登录体系
阶段目标
理解 OAuth2 作为"登录与鉴权协议"的使用方式,明确产品在 OAuth2 中扮演的两种角色(Client 与 Server),掌握授权码、refresh、client credentials 等核心流程。
涵盖章节
- Note 19.4:OAuth2 鉴权登录体系(统一前缀篇:我们既是 Client 又是 Server,主线 Sa-Token OAuth2)
核心产出
- 两种角色一张图:明确"做 Client"(为三方登录铺路)与"做 Server"(为开放平台/SSO/第三方接入铺路)的区别
- 端点与对象模型:client/scope/grant/token/consent/redirect_uri 的完整理解
- 授权码模式:在同一篇里讲透授权码、refresh、client credentials
学习重点
- 理解 OAuth2 在"登录/鉴权"中的真实作用,登录只是 OAuth2 的一种用法
- 掌握我们产品的落地边界:哪些属于 OAuth2,哪些属于 OIDC/企业 IdP
19.4.2. 第二阶段:三方登录聚合
阶段目标
掌握任何厂商"接入流程共性 + 差异维度",以后新增厂商只需要加配置/适配,不改主链路。
涵盖章节
- Note 19.5:三方登录聚合篇(QQ/微信/Google/GitHub/Apple…一篇讲完)
核心产出
- 统一链路模板:授权→回调→换 token→拉用户信息→落库/绑定→签发 Sa-Token
- 厂商差异维度表:用维度表而非流水账讲解各厂商差异
- 账号绑定/冲突处理规则:谁能绑定谁、已绑定怎么办
- JustAuth 作为实现工具:只作为 provider 聚合器,不单独成篇
学习重点
- 理解"接入流程共性"是固定的,差异只在于配置和 API 调用
- 掌握冲突处理策略:手机号匹配、邮箱匹配、强制绑定、提示用户
19.4.3. 第三阶段:单点登录 SSO
阶段目标
掌握多系统统一登录的做法,特别是"单点登出"这个最难的部分,以及边界怎么定。
涵盖章节
- Note 19.6:单点登录 SSO(一个大方面讲透:单点登录 + 单点登出)
核心产出
- SSO 模式选择:同域/跨域/前后端分离与适用场景
- Sa-Token SSO 整体拓扑:server/client/票据/全局会话/局部会话
- 单点登出三种一致性策略:强一致/最终一致/尽力而为
- 踢人下线与会话广播:系统间状态联动
学习重点
- 理解为什么"单点登出"比"单点登录"更难
- 掌握不同一致性策略的取舍:强一致 vs 性能
19.4.4. 第四阶段:手机号验证服务
阶段目标
把短信验证码从"业务散落的 Redis key"提升为可复用基础服务,服务于注册、找回、二次验证、换绑。
涵盖章节
- Note 19.7:手机号验证服务(验证码能力工程化:发送/校验/风控/通道治理)
核心产出
- 验证服务标准接口:send/verify/consume(一次性消费)
- 风控体系:限流、防刷、人机、黑白名单、模板签名
- 通道治理:多供应商、失败切换、送达率与成本指标
- 与登录策略的关系:什么时候用短信做登录、什么时候只做二次确认
学习重点
- 理解验证码服务化的价值:复用、统一管理、可观测
- 掌握通道治理的核心指标:送达率、时延、成本
19.4.5. 第五阶段:高级登录策略
阶段目标
让登录策略从"只有成功失败"升级为"风险评估→策略决策→必要时升级验证"。
涵盖章节
- Note 19.8:高级登录策略(风险驱动:设备/异地/MFA/Step-Up)
核心产出
- 设备与会话策略矩阵:多端、同端互斥、可信设备
- 异地登录与撞库应对:策略层判断,不造轮子
- Step-Up 机制:哪些动作触发二次验证(改密/解绑/支付/导出)
- MFA 嵌入 Sa-Token:TOTP/短信/备用码如何与现有权限与会话体系结合
学习重点
- 理解"风险驱动"的登录策略设计
- 掌握 MFA 与业务权限体系如何解耦又联动
19.4.6. 第六阶段:登录服务框架化
阶段目标
当登录方式越来越多时(密码/短信/三方/SSO/MFA),如何避免 if-else 地狱并能持续扩展。
涵盖章节
- Note 19.9:高级登录服务与框架化(把"登录"做成可插拔子系统)
核心产出
- Provider 插件化:新增一种登录方式 = 新增一个实现
- 策略编排流水线:登录→绑定→风控→签发会话形成标准流程
- 统一审计事件模型:login_success/fail/bind/unbind/mfa_challenge…
- 统一回调/错误码/可观测字段:traceId、reasonCode
学习重点
- 理解插件化设计模式在认证领域的应用
- 掌握策略编排与责任链模式的区别与适用场景
19.4.7. 第七阶段:云身份服务接入(Clerk)
阶段目标
把"接 Clerk"变成体系的标准接入模式,掌握外部 IdP 与业务会话分离的架构,以后换供应商也不伤筋动骨。
涵盖章节
- Note 19.10:Clerk 云身份服务完整接入篇
核心产出
- 统一集成架构:Clerk 认证成功 → 后端验签/取 claims → 本地映射 sys_user/sys_auth → 签发 Sa-Token
- 本地数据模型补齐:sys_auth.identity_type = CLERK,identifier = clerk_user_id
- Clerk Organizations × 租户体系:组织映射、成员生命周期、角色权限映射
- 企业 SSO:域名路由、强制 SSO、首次登录账号绑定
- Webhooks 同步:用户/组织/成员变更的本地落库与审计
- 高级策略整合:MFA、Step-Up 与 Sa-Token 权限体系联动
- 迁移策略:从自建账号体系平滑过渡到 Clerk,不中断用户
技术选型说明
本系列教程的云身份服务只选择 Clerk,原因如下:
- Clerk 专注于用户认证与身份管理(CIAM),与我们的业务需求高度匹配
- Clerk 提供开箱即用的 UI 组件,大幅降低前端接入成本
- Clerk 的组织/成员模型与 SaaS 多租户场景天然契合
- 避免引入过多云服务对比导致的学习成本增加
业务侧仍以 Sa-Token 作为统一的会话与权限基底,确保:
- 业务权限判断与会话管理由我们掌控
- 可实现会话踢人、强制下线、审计日志等能力
- 不将授权体系绑定在外部 IdP 上
学习重点
- 理解为什么"外部认证"与"本地会话"需要分离
- 掌握 JWT/JWKS 验签、webhook 签名校验等安全边界
- 理解数据权威源:Clerk 是"身份权威",我们是"业务权威"
19.5. 本章总结与核心要点回顾
在本章中,我们没有编写任何业务代码,而是专注于构建认知框架。通过本章节的学习,我们完成了以下核心目标:
核心要点
1. 认证技术的演进逻辑
我们从历史演进的视角理解了技术选型的必然性:Cookie-Session 机制在单体应用时代表现完美,但在集群环境下遇到状态同步难题;Token 机制通过"用计算换存储"的设计理念,实现了服务的无状态化,成为微服务架构的标准选择。
2. 分布式认证的三层架构
明确了网关层、认证服务、业务服务的职责边界:网关负责统一鉴权并将用户 ID 透传给下游;认证服务专注于凭证管理,不处理业务逻辑;业务服务从 Header 获取用户身份,自主判断操作权限。
3. 账号-认证分离的数据模型
通过对比传统单表设计的弊端,理解了 sys_user 与 sys_auth 分离存储的必要性。sys_user 表定义用户主体,sys_auth 表存储所有登录方式,通过 1: N 关系实现"一个用户拥有多种登录方式"。
4. 从注册到鉴权的完整流程
推演了用户从陌生人到受信主体的生命周期:注册时通过验证码校验和双表事务落库;登录时根据 authType 路由到不同策略;鉴权时网关解析 Token 并将用户信息注入 Header 传递给下游服务。
5. 七阶段渐进式学习路径
获得了从"OAuth2 鉴权"到"Clerk 云身份服务接入"的七阶段学习地图,每个阶段都有明确的目标、涵盖章节和核心产出,确保在后续深入代码实现时不会迷失方向。
架构蓝图速查
当你在后续学习中遇到困惑时,可以回到这张架构全景图快速定位:
.svg)
核心避坑指南
在构建分布式认证系统时,以下三个陷阱最容易导致架构失败:
陷阱一:过度设计
不要在项目初期就引入极其复杂的权限模型(如 RBAC + ABAC 混合)。先实现基本的认证功能,随着业务增长再逐步演进。记住:过早优化是万恶之源。
陷阱二:安全欠缺
不要认为 HTTPS 就足够安全。密码必须用 BCrypt 哈希存储,Token 必须设置合理的过期时间,关键操作必须有二次验证。安全是系统的底线,不能妥协。
陷阱三:状态泄漏
在微服务架构下,业务服务不应该依赖 Session 或全局变量来存储用户状态。所有用户信息都应该从 HTTP Header 中获取,确保服务的无状态性。
预告:下一章内容
在 Note 19.1 中,我们将深入字节码层面,手写一个抗打的 JWT 工具类。你将学习到:
- JWT 的三段式结构在内存中的字节表示
- HMAC-SHA256 签名算法的完整实现过程
- 如何通过 Redis 实现 Token 的主动注销与自动续期
- 双 Token 机制在高并发场景下的并发安全问题
我们将从零开始构建认证核心,不依赖任何现成的 JWT 库,彻底理解 Token 机制的底层原理。





