
Prorise
这是我的博客,分享技术与生活的点点滴滴
第一章. BMAD 的本质:为什么需要它
第一章. BMAD 的本质:为什么需要它
Prorise第一章. BMAD 的本质:为什么需要它
本章将揭示 “氛围编程” 的致命缺陷,并解释 BMAD 如何通过 “规范驱动” 和 “人在回路” 两大支柱解决这些问题。
注:更详细的关于 BMAD 的方法论说明请跳转至:
1.1. 氛围编程的三大死穴
我们先从一个真实场景开始。
假设你正在用 AI 助手开发一个电商系统,对话进行到第 50 轮时,你突然发现:刚才让 AI 生成的订单服务代码,和 20 轮之前设计的用户服务完全不兼容。API 接口对不上,数据库字段也对不上。更糟糕的是,你已经记不清当时为什么要那样设计了。
这就是 氛围编程凭感觉与 AI 对话式编程,缺乏结构化规划 的典型困境。它有三个致命问题:
死穴一:上下文衰减
AI 对话的上下文窗口是有限的。即使是 Gemini 这样的长上下文模型,当对话超过 100 轮后,早期的关键决策也会被 “遗忘”。你会发现 AI 开始自相矛盾:
- 第 10 轮说用 REST API
- 第 80 轮突然建议改成 GraphQL
- 第 120 轮又回到 REST,但参数结构完全变了
更可怕的是,你自己也会忘记。三个月后回来维护代码,你会盯着屏幕问自己:“当初为什么要这么写?”
死穴二:幻觉累积
AI 在没有约束的情况下,会 “创造性地” 编造不存在的 API、配置项、甚至整个框架。举个例子:
1 | // AI 生成的代码 |
你兴高采烈地复制粘贴,运行后发现 @awesome/auth-kit 这个包压根不存在。回到对话里追问,AI 会一本正经地道歉,然后给你另一个同样不存在的方案。
在氛围编程中,这种幻觉会像滚雪球一样累积。因为没有 “规范文档” 作为事实基准,AI 每次回答都是基于概率模型的即兴发挥。
死穴三:架构漂移
没有预先规划的项目,架构会随着对话的进行而 “漂移”。最初你想做一个简单的 CRUD 应用,聊着聊着变成了微服务架构,再聊着聊着又加上了事件溯源和 CQRS。
这不是说这些技术不好,而是 决策缺乏一致性。你会发现:
- 用户模块用了 RESTful 风格
- 订单模块突然变成 RPC 调用
- 支付模块又引入了消息队列
整个系统像一个缝合怪,每个部分都能跑,但拼在一起就是灾难。
1.2. BMAD 的核心思想:规范驱动 + 人在回路
BMAD 的设计哲学可以用一句话概括:先把规则写清楚,再让 AI 按规则干活。
它通过两个核心机制解决氛围编程的问题:
规范驱动:工件即真相
在 BMAD 中,所有的关键决策都必须固化为 工件持久化的文档或代码,作为后续开发的事实依据。这些工件包括:
| 工件类型 | 作用 | 生命周期 |
|---|---|---|
| 项目简介 (Project Brief) | 定义项目目标和边界 | 整个项目 |
| PRD (产品需求文档) | 详细描述功能需求 | 整个项目 |
| 架构文档 (Architecture Doc) | 规定技术栈和系统设计 | 整个项目 |
| 故事 (Story) | 单个可交付的功能单元 | 单次迭代 |
这些工件不是摆设,而是 AI 的行动指南。当你让 Dev 代理实现一个功能时,它必须严格遵循 PRD 和架构文档中的约定。如果 PRD 里说用 PostgreSQL,Dev 就不能擅自改成 MongoDB。
这就解决了 “幻觉累积” 的问题。因为 AI 不再是凭空想象,而是基于已经确认的文档进行推理。
人在回路:检查点机制
BMAD 不是让 AI 完全自主工作,而是在关键节点设置 人工检查点。整个流程分为四个阶段:

注意那两个虚线箭头,它们代表 必须由人来决定是否继续。具体来说:
检查点 1:Planning → Solutioning
在这个阶段,PO (Product Owner) 代理会生成一份检查清单,验证 PRD 和架构文档是否一致。例如:
- PRD 里提到的 “用户角色管理”,架构文档里有没有对应的数据表设计?
- 架构文档选择了 Redis 做缓存,PRD 里有没有说明缓存失效策略?
这份清单生成后,你必须人工审查。如果发现不一致,回到 Planning 阶段修正文档,而不是带着问题进入开发。
检查点 2:每个 Story 的 Review 阶段
当 Dev 代理完成一个故事的开发后,QA 代理会进行代码审查。审查报告会明确指出:
- 哪些地方符合规范
- 哪些地方需要改进
- 是否可以合并到主分支
这个决定权在你手上。如果 QA 发现了严重问题(比如缺少事务处理),你可以要求 Dev 返工,而不是 “先合并再说”。
这种机制确保了 质量门槛。每个阶段的输出都经过验证,不会把问题遗留到下一个阶段。
1.3. 适用场景判断树
BMAD 不是银弹,它有明确的适用边界。我们用一个决策树来说明:
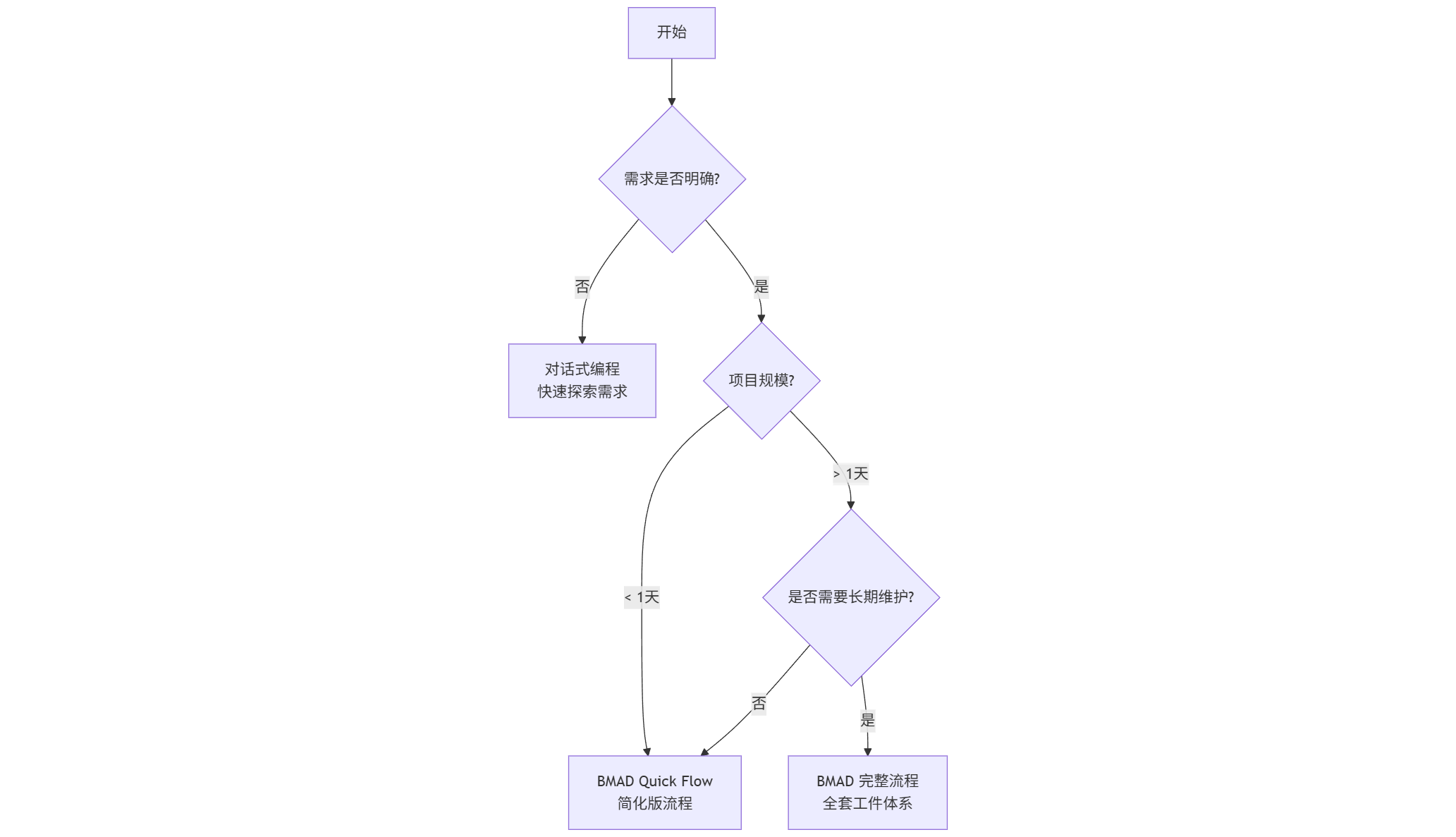
我们逐个解释每个分支:
分支 1:需求不明确 → 对话式编程
如果你还在探索 “到底要做什么”,BMAD 反而会拖慢节奏。这时候应该用对话式编程快速试错:
- 写几个原型验证想法
- 和 AI 讨论不同的技术方案
- 频繁推翻重来
等需求逐渐清晰后,再切换到 BMAD 进行正式开发。
分支 2:小项目(< 1 天)→ Quick Flow
对于简单的功能(比如给现有系统加一个导出 Excel 的接口),完整的 BMAD 流程过于重量级。这时可以用简化版:
- 直接写一个简单的 Story(跳过 PRD)
- 用 Dev 代理实现
- 用 QA 代理快速审查
这样既保留了 “规范驱动” 的核心思想,又不会陷入文档泥潭。
分支 3:大项目 + 长期维护 → 完整流程
如果你的项目满足以下任一条件,强烈建议用完整的 BMAD 流程:
- 开发周期超过 1 周
- 涉及多个模块或服务
- 需要多人协作(即使是 “你 + AI” 的协作)
- 三个月后还要继续迭代
这种情况下,前期在文档上多花的时间,会在后期以 “减少返工” 的形式百倍偿还。
1.4. 本章总结与决策速查
让我们回顾一下核心要点:
氛围编程的三大死穴
- 上下文衰减:对话越长,早期决策越容易被遗忘
- 幻觉累积:AI 会编造不存在的 API 和配置
- 架构漂移:缺乏规划导致系统变成缝合怪
BMAD 的两大支柱
- 规范驱动:用工件(PRD、架构文档、Story)固化决策
- 人在回路:在关键节点设置人工检查点
决策速查表
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 探索性编程 | 对话式 | 需求未定,频繁试错 |
| 临时脚本 | 对话式 | 一次性任务,无需维护 |
| 小功能增强 | BMAD Quick | 保留规范,简化流程 |
| 新产品开发 | BMAD 完整 | 需要长期维护和迭代 |
| 遗留系统改造 | BMAD 完整 | 风险高,需要严格规划 |
自检问题
在开始一个项目前,问自己三个问题:
- 三个月后,我还能看懂这些代码吗?(如果答案是 “不确定”,用 BMAD)
- 这个项目会不会有第二个人参与?(如果是,用 BMAD)
- 我能接受推倒重来的成本吗?(如果不能,用 BMAD)






