
Prorise
这是我的博客,分享技术与生活的点点滴滴
Note 17. 性能加速:Spring Cache 与 Redis 分布式缓存
Note 17. 性能加速:Spring Cache 与 Redis 分布式缓存
ProriseNote 17. 性能加速:Spring Cache 抽象层与多级缓存实战
摘要:在掌握了数据一致性(Note 16)之后,本章我们将致力于解决系统的“慢”问题。缓存是高性能架构的基石,但直接使用 Redis 并不是唯一的答案。本章将从 Spring Cache 的 核心抽象 出发,先掌握业界最高性能的进程内缓存 Caffeine,再平滑迁移至 Redis 分布式缓存。我们将深入剖析“序列化乱码”、“AOP 失效”、“多租户 TTL 配置”等生产级难题,构建一套可扩展的缓存体系。
本章环境与版本锁定
为了确保大家在实战中不遇到奇怪的兼容性问题,我们将严格锁定以下技术组件的版本。Spring Boot 3.x 对 Redis 的底层支持做了较大调整,请务必对齐环境。
| 技术组件 | 版本号 | 说明 |
|---|---|---|
| Java (JDK) | 21 LTS | 推荐使用最新 LTS 版本,支持虚拟线程 |
| Spring Boot | 3.3.0 | 2025 主流稳定版 |
| Redis | 7.2 | 支持 ACL 与最新 RDB 协议 |
| Caffeine | 3.1.8 | 高性能本地缓存库 |
| Lettuce | 6.3.0 | Spring Boot 默认的高性能 Redis 客户端 |
| Commons Pool2 | 2.12.0 | Redis 连接池管理工具(生产环境必选) |
本章学习路径
- 抽象思维:理解
spring-boot-starter-cache与具体实现(Caffeine/Redis)的解耦关系。 - 本地缓存:集成 Caffeine 实现毫秒级响应,理解 W-TinyLFU 淘汰算法。
- 分布式迁移:引入 Redis,配置连接池与 JSON 序列化,解决“二进制乱码”问题。
- 注解精讲:掌握
@Cacheable、@CachePut、@CacheEvict的 SpEL 表达式与生命周期。 - 高阶实战:解决 AOP 内部调用失效、缓存穿透、自定义 TTL 等生产问题。
17.1. 缓存抽象层:Spring Cache 下的门面设计
在上一章中,我们处理了数据库层面的事务一致性问题,保证了数据的“正确性”。但在高并发的互联网架构中,仅仅“正确”是不够的,系统必须“快”。当数据库成为瓶颈时,引入缓存是必然选择。
然而,许多开发者习惯于直接引入 spring-boot-starter-data-redis 并开始在 Service 层注入 RedisTemplate。这种做法虽然直接,但导致了业务代码与中间件的强耦合。如果有一天我们需要将缓存从 Redis 迁移到 Memcached,或者在开发环境只想用内存 Map 跑单测,就需要修改大量业务代码。
本节我们将学习 Spring Framework 提供的 Spring Cache Abstraction(缓存抽象层)。它的核心价值在于“依赖倒置”:业务层只依赖标准的缓存注解,而具体的缓存实现(Redis、Caffeine、Ehcache)通过配置注入,实现真正的热插拔。
17.1.1. Spring Cache 的设计哲学
Spring Cache 的设计灵感来源于 JDBC。就像我们写 SQL 时不需要关心底层是 MySQL 还是 Oracle 一样,使用 Spring Cache 时,我们只需要关心“哪些数据需要缓存”,而不需要关心“数据存在哪里”。
它通过 AOP(面向切面编程)技术,在方法执行前后插入缓存逻辑,从而实现了对侵入性代码的屏蔽。业务开发人员只需要在方法上标记 @Cacheable,Spring 就会自动处理 Key 的生成、Value 的序列化、连接的获取与释放。
17.1.2. 核心组件深度解析
Spring Cache 的世界由两个核心接口支撑,理解它们是掌握自定义缓存配置的钥匙。我们可以把它们的关系理解为 “工厂” 与 “产品” 的关系。
核心组件 1:CacheManager(缓存管理器)
CacheManager 是整个缓存机制的 入口 和 工厂。它的主要职责是管理(创建、获取、销毁)具体的 Cache 实例。我们在配置文件中切换 spring.cache.type,本质上就是在切换不同的 CacheManager 实现类。
下表展示了 Spring 内置的几种常见管理器及其适用场景:
| 实现类 (Implementation) | 底层存储 | 特点 | 适用场景 |
|---|---|---|---|
| ConcurrentMapCacheManager | JDK ConcurrentHashMap | 默认实现。数据存在 JVM 堆内存中,速度最快,但重启即丢失,不支持过期时间。 | 本地开发、单元测试、极小规模应用 |
| RedisCacheManager | Redis Server | 数据存储在 Redis 服务端。支持持久化、支持跨服务共享数据(分布式)。 | 生产环境首选、微服务架构 |
| CaffeineCacheManager | Caffeine (内存) | Google Guava Cache 的高性能升级版。支持设置过期时间、最大容量、淘汰策略(W-TinyLFU)。 | 高性能单体应用、作为二级缓存的本地层 |
| SimpleCacheManager | 自定义列表 | 最简单的实现,允许手动传入一个 Cache 列表。 | 特殊配置需求 |
核心组件 2:Cache(具体缓存操作接口)
Cache 接口代表了一个 具体的命名缓存区域(例如 “user_cache” 或 “product_stock”)。它定义了缓存的标准行为(增删改查)。
Spring Cache 的强大之处在于 统一了操作接口。无论底层是操作 Redis 的 TCP 连接,还是操作内存中的 Map,对于业务层来说,调用的方法都是一样的。
下表展示了 Cache 接口方法与底层实现的映射关系:
| Cache 接口方法 | 含义 | 对应 Map 实现 (伪代码) | 对应 Redis 实现 (伪代码) |
|---|---|---|---|
get(key) | 查 | map.get(key) | redis.get("cacheName::key") |
put(key, value) | 写 | map.put(key, value) | redis.set("cacheName::key", serializedValue) |
evict(key) | 删 | map.remove(key) | redis.del("cacheName::key") |
clear() | 清空 | map.clear() | redis.del("cacheName::*") |
组件协作流程演示(非注解方式)
为了让你彻底明白这两个组件是如何配合工作的,我们来看一段 不使用注解 时的伪代码。这正是 Spring 在幕后通过 AOP 帮我们做的事情:
1 | // 假设这是 Spring 内部的工作逻辑 |
通过这段代码可以看到,CacheManager 负责 找到地盘,Cache 负责 在地盘上干活。Spring 的 @Cacheable 等注解,就是把上述模版代码封装起来,让开发者无感知地使用缓存。
本节小结
- 核心要点:
- 缓存抽象层的核心是 解耦,业务代码不应直接依赖 Redis API。
CacheManager负责管理缓存容器,Cache负责具体的数据存取。- Spring Boot 通过自动配置(AutoConfiguration)根据 classpath 下的依赖自动切换
CacheManager的实现。
17.2. 第一阶段:集成 Caffeine 高性能本地缓存
在上一节中,我们建立了“面向抽象编程”的缓存理念。但在实际的高频读取场景(如字典表、系统配置、电商首页类目)中,即使是 Redis 这种高性能远程缓存,其网络 IO 开销(通常在 1-5ms)在高并发下也是不可忽视的瓶颈。
为了追求极致性能(纳秒级响应),我们需要引入 进程内缓存。本节我们将集成业界公认性能最强的本地缓存库 —— Caffeine。Caffeine 使用了独创的 W-TinyLFU 算法,解决了传统 LRU(最近最少使用)算法在面对“稀疏流量”或“扫描式流量”时的缓存污染问题,能显著提高缓存命中率。
17.2.1. 引入依赖与架构分析
要使用 Caffeine,我们需要引入两个核心模块:Spring 的缓存抽象模块和 Caffeine 的具体实现库。
步骤 1:修改 pom.xml
请注意,这里我们并不需要引入 Redis,因为第一阶段我们的目标是构建纯本地的高性能缓存。
pom.xml:
1 | <dependencies> |
17.2.2. W-TinyLFU 策略配置详解
Caffeine 的强大之处在于其灵活的淘汰策略。我们需要在 application.yml 中通过 spec 表达式来定义这些规则。
步骤 2:配置 application.yml
这里有一个非常关键的配置项 spec,它是 Caffeine 的配置描述符。
src/main/resources/application.yml:
1 | spring: |
为什么不使用 expireAfterAccess?
expireAfterAccess(访问后过期):适合 Session 等需要“保活”的数据。expireAfterWrite(写入后过期):适合配置信息、字典数据。对于大多数业务缓存,我们希望数据在固定时间后失效以刷新最新数据,所以通常首选expireAfterWrite。
非常棒的反馈。对于初学者来说,“完整的链路” 至关重要。如果只给一段 Service 代码,读者往往会因为缺少实体类、忘记开启缓存开关(@EnableCaching)、或者不知道如何写 Controller 进行测试而卡住。
我们需要补充完整的 实体类 (Entity)、启动类配置 (Main)、以及 Web 层 (Controller)。
以下是重写后的 17.2.3. 编写第一个缓存业务:
17.2.3. 编写第一个缓存业务
环境准备就绪后,我们通过一个完整的 CRUD 链路来体验 @Cacheable 的魔力。我们将模拟一个“查询慢、读取频繁”的商品详情场景。
请按顺序创建以下 4 个文件。
第一步:开启缓存开关(重要)
很多新手配置了半天发现缓存不生效,往往是因为忘记在启动类上加 @EnableCaching 注解。
文件:src/main/java/com/example/demo/DemoApplication.java
1 | package com.example.demo; |
第二步:定义实体对象
创建一个简单的商品 POJO 类。这里使用 Lombok 简化代码。
文件:src/main/java/com/example/demo/domain/Product.java
1 | package com.example.demo.domain; |
第三步:实现业务逻辑(模拟耗时)
这是核心部分。我们在 getProductById 方法上添加 @Cacheable 注解,并故意增加 2 秒延迟来模拟真实的数据库 IO。
文件:src/main/java/com/example/demo/service/ProductService.java
1 | package com.example.demo.service; |
第四步:创建 Web 接口进行测试
为了方便在浏览器中验证,我们编写一个简单的 Controller。
文件:src/main/java/com/example/demo/controller/ProductController.java
1 | package com.example.demo.controller; |
第五步:验证效果
启动 Spring Boot 应用,打开浏览器或 Postman 进行测试:
第一次访问:http://localhost: 8080/product/1
- 现象:浏览器转圈圈等待约 2 秒 才显示 JSON 结果。
- 控制台:打印出
--- [DB查询] 缓存未命中...。 - 结论:缓存为空,执行了真实方法。
第二次访问:
http://localhost:8080/product/1- 现象:结果 瞬间出现(< 10ms)。
- 控制台:没有任何日志打印。
- 结论:方法体根本没执行,Spring 直接从内存返回了上次存入的对象。
访问不同 ID:
http://localhost:8080/product/2- 现象:再次等待 2 秒。
- 结论:缓存是根据 ID(Key)隔离的,ID = 2 还没有缓存。
本节小结
核心要点:
本地缓存(Caffeine)没有网络开销,适合“读多写少、数据量可控”的场景(如系统参数、国家代码)。
spec表达式中的maximumSize是保护 JVM 内存溢出的最后一道防线,必须配置。@Cacheable是声明式缓存的核心,它利用 AOP 实现了“查缓存 -> 查库 -> 写缓存”的经典模式。速查代码:
1 | # Caffeine 黄金配置:初始100,最大1万,写后5分钟过期 |
17.3. 第二阶段:平滑迁移至 Redis 分布式缓存
在上一节,我们利用 Caffeine 实现了极速的本地查询(微秒级响应)。这在单机应用或个人项目中是非常完美的方案。然而,当我们把视线转向现代化的微服务架构或集群部署时,本地缓存(Local Cache) 就显露出了它的局限性。
想象一下,你的服务为了应对双十一大促,部署了 10 个节点(实例)。此时,单纯依赖本地缓存会带来两个致命问题:
数据孤岛(一致性灾难):假设运营人员后台修改了商品 A 的价格为 99 元。请求刚好打到了 节点 1,节点 1 删除了自己的缓存。但是,节点 2 到 节点 10 的内存里,商品 A 的价格依然是旧的 199 元。这就导致了用户在不同页面刷到的价格不一致,极易引发客诉。
- 解决方案:我们需要一个 公共的、中心化的 存储,让所有节点都去同一个地方拿数据。
缓存雪崩(重启即穿透):本地缓存是存储在 JVM 堆内存中的。一旦应用发布重启,或者节点崩溃,所有缓存瞬间清零。重启后的那一瞬间,成千上万的并发请求发现缓存为空,会像洪水一样直接冲击数据库(Database),极可能把数据库打挂。
- 解决方案:我们需要一个 持久化的、独立于应用之外的 缓存服务(Redis),即使应用重启,Redis 里的数据依然安然无恙。
得益于 Spring Cache 的抽象层设计,我们 不需要修改 ProductService 的任何一行 Java 业务代码,只需要调整底层配置,就能完成从“个人笔记本”到“共享黑板”的切换。
17.3.1. 生产级依赖管理:Lettuce 与连接池
在 Spring Boot 2.x/3.x 中,官方默认御用的 Redis 客户端是 Lettuce,而不是早期的 Jedis。
为什么是 Lettuce?
- Jedis:直连模式。基于标准 I/O(阻塞式),线程不安全。在多线程环境下,必须配合连接池使用,每个线程独占一个连接,并发高时资源消耗大。
- Lettuce:基于 Netty 框架(非阻塞 I/O)。它的连接是 线程安全 的,支持复用。多个线程可以共享同一个连接实例来并发发送指令,极其高效。
为什么要加连接池?
虽然 Lettuce 单连接支持复用,但在生产环境(高并发)下,单纯依赖一个 TCP 连接依然存在物理瓶颈(如网络包处理速度、Redis 单线程处理能力)。此外,一旦网络抖动导致连接断开,重建连接需要时间。引入连接池(Connection Pool)可以维持一定数量的“温连接”,不仅能分摊流量,还能在连接异常时快速切换。
步骤 1:追加 pom.xml 依赖
我们需要引入 Redis 启动器,并额外引入 commons-pool2,这是 Lettuce 实现连接池所必须的依赖。
1 | <!-- 1. Spring Data Redis (默认包含 Lettuce 客户端) --> |
17.3.2. 深度配置:Redis 与 CacheManager
这里的配置是生产环境稳定性的关键。很多线上的“Redis 连接超时”或“获取连接排队”故障,都是因为这里的参数设置过于随意。
步骤 2:修改 application.yml
我们将配置分为两部分:底层连接配置(管连接)和 Spring Cache 逻辑配置(管数据)。
1 | spring: |
17.3.3. 验证迁移结果与“乱码”初现
配置完成后,我们不需要修改任何 Java 代码,直接启动应用进行验证。
环境准备:
如果你本地没有安装 Redis,推荐使用 Docker 快速启动一个:
1 | docker run -d -p 6379:6379 --name my-redis redis |
验证步骤:
- 启动应用:观察控制台日志,确保没有报错。
- 触发缓存:访问接口
GET http://localhost:8080/product/1。- 此时控制台会打印
[DB查询] ...,说明查了数据库并写入了 Redis。
- 此时控制台会打印
- 再次访问:再次访问同一接口。
- 控制台 无日志,说明直接从 Redis 读取了数据。
- 眼见为实:最重要的一步,打开 Redis 客户端(推荐
Another Redis Desktop Manager或命令行redis-cli),查看里面的数据。
问题出现了:
你会惊讶地发现,Redis 里存的 Key 和 Value 是一串看不懂的“乱码”(其实是十六进制数据),如下图所示:

17.3.4. 为什么会有“乱码”?(JDK 序列化的坑)
这并非真正的乱码,而是 Java 标准序列化(Java Serialization) 产生的二进制流。
Spring Boot 的 RedisCacheManager 在默认情况下,因为不知道你要缓存什么对象,所以采取了最保守、最通用的策略:使用 JdkSerializationRedisSerializer。
只要你的实体类实现了 Serializable 接口,Java 就能把它转成二进制存进去。但这在现代互联网架构中,有 三大罪状:
- 可读性差(运维噩梦):运维人员或开发者在 Redis 客户端里查看数据时,完全看不出存的是什么(比如看不出价格是 5999 还是 99),无法进行线上排查或紧急修改。
- 空间浪费(烧钱):
JDK 序列化不仅存储数据本身,还会存储完整的类名、包路径、元数据等。一个简单的{"id":1}对象,转换成二进制后可能膨胀几倍,导致 Redis 内存成本飙升。 - 跨语言障碍(架构死穴):
Java 的二进制流只有 Java 能读懂。如果你的系统里还有用 Python 写的数据分析脚本,或者用 Go 写的网关,它们根本无法读取这些缓存数据。
如何解决?
我们需要将缓存格式标准化为全宇宙通用的 JSON 格式。这将是下一节的重点——自定义 CacheManager 与序列化策略。这是 Spring Cache 实战中最复杂但也最核心的配置。
本节小结
- 平滑迁移:从 Local Cache 切到 Redis Cache,业务代码零修改,仅需改动配置。
- 连接池至关重要:生产环境务必引入
commons-pool2并配置max-active等参数,防止 Redis 连接成为瓶颈。 - 序列化陷阱:默认的 JDK 序列化虽然省事,但在可读性、体积和跨语言兼容性上表现极差。不要在生产环境直接使用默认配置!
17.4. [核心] 解决序列化“乱码”问题
17.4.1. 为什么 JDK 序列化是生产禁忌?
回顾:上一节我们在 Redis 中看到的 \xAC\xED\x00\x05 开头的数据,是 Java 原生序列化(ObjectOutputStream)的产物。
引出:这种格式虽然兼容性好(只要是 Java 都能读),但在分布式架构中存在致命缺陷:
- 体积膨胀:它不仅存数据,还存了完整的类路径(
com.example.demo.domain.Product)和版本号,导致数据体积比 JSON 大 5-10 倍。 - 语言隔离:PHP、Go、Python 等其他语言无法读取 Java 的序列化流。
- 可读性为零:你无法通过 Redis 客户端直接修改某个字段来快速修复线上数据。
预告:我们将使用 GenericJackson2JsonRedisSerializer 替换默认序列化器,将数据转为标准的 JSON 格式。
17.4.2. 编写生产级 CacheConfig
这是 Spring Cache 中最复杂的一步。我们需要接管 RedisCacheConfiguration 的创建权。
文件路径:src/main/java/com/example/demo/config/CacheConfig.java
我们将分步构建这个配置类。
步骤 1:定义配置类骨架
1 | package com.example.demo.config; |
步骤 2:配置 JSON 序列化策略(核心)
我们需要告诉 Spring:“Key 请用 String 格式,Value 请用 JSON 格式”。
1 | /** |
17.4.3. 验证“乱码”消除
配置完成后,重启应用。
- 再次访问接口
GET /product/1。 - 查看 Redis。
此时,你会发现 Key 变成了清晰的字符串,Value 变成了标准的 JSON:
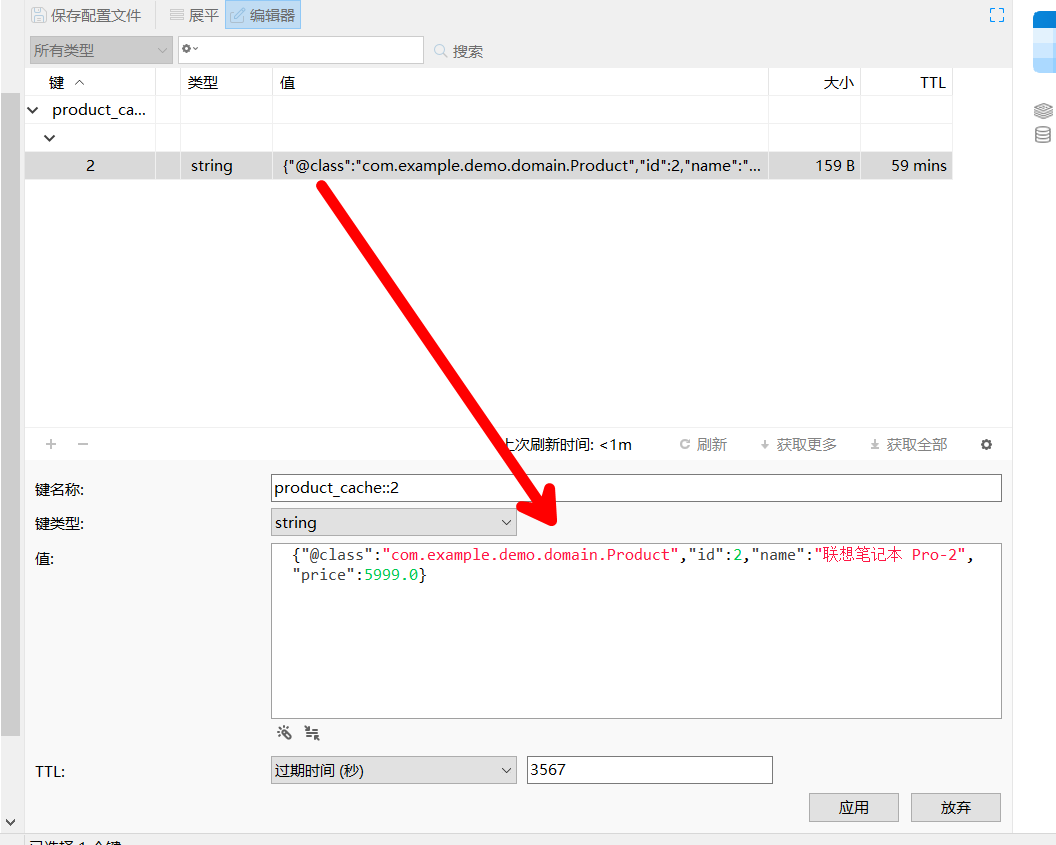
注意 @class 属性:这就是 GenericJackson2JsonRedisSerializer 的功劳。它记录了全类名,确保反序列化时不会报错。这也带来了一个小副作用:如果你重命名了类或移动了包,旧缓存会解析失败(详见本章末尾的避坑指南)。
本节小结
- 核心要点:
- 生产环境严禁使用默认的 JDK 序列化,必须切换为 JSON 序列化以提升可读性和性能。
- 配置
RedisCacheConfiguration时,必须同时设置 Key(String)和 Value(JSON)的序列化器。 GenericJackson2JsonRedisSerializer能够处理泛型和多态,是目前最通用的选择。
17.5. 深度解析:注解三剑客与 SpEL
掌握了底层配置,接下来我们回到业务层。Spring Cache 提供了三个核心注解,覆盖了 CRUD 的全生命周期。熟练使用 SpEL (Spring Expression Language) 是灵活运用这些注解的关键。
17.5.1. @Cacheable(查:若无则查库,若有则返回)
这是最常用的注解,用于读取操作。
SpEL 表达式实战:有时我们需要组合多个参数作为 Key,或者根据条件决定是否缓存。
1 | // 场景:多参数组合 Key |
17.5.2. @CachePut(改:双写更新)
语义:无论缓存有没有,都执行方法体,并将方法的返回值更新到缓存中。
常用于“保存”或“更新”操作,保证缓存与数据库的 最终一致性。
常见错误示范:
1 | // ❌ 错误! |
原因:@CachePut 会把方法的返回值放入缓存。如果返回 void,缓存中就会被置为 null。
修正:必须返回更新后的最新数据对象。
1 | // ✅ 正确 |
17.5.3. @CacheEvict(删:清理缓存)
语义:从缓存中移除数据。
用于删除操作,或者在无法保证增量更新正确性时,直接清空缓存强迫下次查库。
1 | // 场景 1:删除单条数据 |
本节小结
- 核心要点:
@Cacheable用于读,@CachePut用于双写更新(必须有返回值),@CacheEvict用于删除。key属性支持 SpEL 表达式,可以灵活组合参数;如果不指定,Spring 会使用默认策略(所有参数的 hash),容易产生 Key 冲突。- 慎用
@CacheEvict(allEntries = true),在高并发下瞬间清空所有缓存可能导致数据库压力骤增。
17.6. 生产环境避坑指南与高阶配置
在开发环境跑通代码只是第一步,生产环境往往隐藏着更多细节魔鬼。本节我们将解决三个最常见的“线上事故”源头。
17.6.1. 经典大坑:内部调用失效
现象:你在 OrderService 中写了 findById(带缓存)和 createOrder。在 createOrder 内部调用了 this.findById(id),发现缓存注解 完全失效,每次都查数据库。
1 |
|
原理:
Spring Cache(以及事务 @Transactional)是基于 AOP 动态代理 实现的。
- 外部调用
orderService.findById()时,实际上是调用了Proxy.findById(),代理类在执行目标方法前先检查了缓存。 - 内部调用
this.findById()时,this指的是目标对象本身,直接执行了原方法代码,根本没有经过代理类的“缓存拦截器”。
解决方案:
- 拆分 Service(推荐):将缓存方法移到另一个 Service(如
OrderQueryService)中,然后注入调用。 - 自我注入(勉强可用):在类中注入自己
@Lazy @Autowired OrderService self;,然后用self.findById()调用。
17.6.2. 进阶需求:不同业务,不同 TTL
痛点:全局配置里我们设置了 TTL 为 1 小时。但业务要求:验证码(VerifyCode) 必须 5 分钟过期,而 每日热榜(DailyRank) 需要存 24 小时。
Spring Cache 注解本身不支持 ttl 参数(这是它被诟病最多的点)。
解决方案:RedisCacheManagerBuilderCustomizer
在 Spring Boot 3 中,我们可以在 CacheConfig 中通过 RedisCacheManagerBuilderCustomizer 来实现精细化控制。
追加配置到 CacheConfig.java:
1 | /** |
用法:
1 | // 这个缓存会自动遵循 5 分钟过期的规则 |
17.6.3. 缓存穿透与 Null Object Pattern
现象:黑客恶意查询一个不存在的 ID(如 -999)。
- 查询缓存 -> 无。
- 查询数据库 -> 无(返回 null)。
- Spring Cache 默认不缓存 null。
- 下一次请求 -> 再次查库。这就导致请求直接穿透缓存打到数据库。
防御方案:我们需要允许缓存 null 值,但给它一个极短的过期时间(防止未来该 ID 真的产生数据了却读不到)。
- 在全局配置中开启
.cacheNullValues()(我们在 17.3.2 中配置了 true,或者在 CacheConfig 中移除.disableCachingNullValues())。 - 利用
unless排除非空结果(如果非空正常存,如果为空则走特殊逻辑),或者简单地依赖 Redis 的 TTL 自动过期。
最简单的生产实践是:开启缓存 null 值,并设置合理的全局 TTL。Spring 默认是允许缓存 null 的,它会存一个特殊的 NullValue 对象到 Redis 中。
本节小结
- 核心要点:
- 严禁在类内部通过
this调用带缓存注解的方法,这会导致 AOP 失效。 - 使用
RedisCacheManagerBuilderCustomizer可以灵活地为不同cacheName设置差异化的 TTL。 - 防御缓存穿透的最简单方法是允许缓存 null 值(
cache-null-values: true),Spring 会自动处理 Null 值的序列化。
17.7. 本章总结与实战速查
17.7.1. 摘要回顾
本章我们从 Spring Cache 的抽象层出发,首先利用 Caffeine 实现了高性能的进程内缓存,随后平滑迁移至 Redis 分布式缓存。我们重点攻克了 JSON 序列化配置 这一难关,解决了 Redis 数据不可读的问题,并深入探讨了 SpEL 表达式、AOP 失效机制以及多租户 TTL 的配置策略。
17.7.2. 场景化代码模版
遇到以下 3 种场景时,请直接 Copy 下方模版:
1. 场景一:标准对象查询(JSON 序列化 + 1 小时过期)
需求:缓存用户详情,常规过期时间。
前提:已在 CacheConfig 配置好 JSON 序列化。
1 |
|
2. 场景二:列表数据缓存(组合 Key)
需求:根据 类型 和 页码 缓存商品列表。
1 | // Redis Key: "product_list::phone:1" |
3. 场景三:数据更新联动(双写一致性)
需求:更新用户时,刷新用户详情缓存,并清空该用户的所有关联列表缓存。
1 |
|
17.7.3. 核心避坑指南
- 序列化兼容性炸弹:
- 现象:重构代码修改了类名或包名后,读取旧缓存报错
ClassNotFoundException。 - 原因:JSON 中存了
{"@class": "com.old.package.User"}。 - 对策:在上线重大重构前,必须评估是否需要 FlushDB 清空旧缓存,或使用 Key 版本号隔离(如
cacheNames="user_v2")。
- AOP 内部调用失效:
- 现象:
this.method()不走缓存。 - 对策:自我调用时,请将缓存方法抽取到独立的 Service Bean 中。
- 大 Key 瞬间清理:
- 现象:
@CacheEvict(allEntries=true)删除了包含 100 万个 Key 的缓存分区。 - 对策:Redis 处理
DEL命令是单线程阻塞的。对于超大数据集,应避免使用allEntries=true,或者改用异步删除(UNLINK命令,Spring Data Redis 较新版本支持)。





