
Prorise
这是我的博客,分享技术与生活的点点滴滴
Ruo-Yi基础篇(七):第七章. 后端服务构建:从零实现课程管理 API
Ruo-Yi基础篇(七):第七章. 后端服务构建:从零实现课程管理 API
Prorise第七章. 后端服务构建:从零实现课程管理 API
在第六章中,我们以一名纯粹前端工程师的视角,从零构建了“课程管理”模块的用户界面 (index.vue)。我们精心封装了 API 服务 (course.js),但这些 API 调用目前还只是指向一个“虚空”的后端。我们的前端应用,虽然拥有了华丽的“皮囊”,却没有为其提供数据和逻辑的“灵魂”。
本章,我们将转换角色,戴上后端工程师的帽子。我们的核心任务是,在若依后端项目中,手动、完整地实现 前端所需的所有 API 接口。我们将不再依赖代码生成器,而是亲手编写每一层代码,旨在彻底揭开若依后端服务的“黑盒”,让您深刻理解一个 HTTP 请求是如何在后端被处理、与数据库交互并最终返回响应的。
我们为什么要手动实现?
代码生成器是生产力工具,它能快速生成遵循若依最佳实践的代码。但“知其然”更要“知其所以然”。通过手动实现一遍,我们将能精准地掌握:
- 三层架构的职责边界: Controller, Service, Mapper 各司其职,如何协作?
- 若依核心组件的运用: 分页插件
PageHelper、权限注解@PreAuthorize、标准响应体TableDataInfo等是如何在真实业务中发挥作用的。 - MyBatis 的精髓: 动态 SQL 是如何构建灵活查询的。这将赋予您超越“代码生成器使用者”的、真正进行深度定制和二次开发的能力。
在开始编码之前,我们必须先建立起清晰的全局视野。以下目录树展示了本章我们即将在 ruoyi-admin 模块中创建的 全部文件 及其在项目中的标准位置。这便是我们本章的“施工图”。
1 | # 路径: ruoyi-admin/ |
我们将遵循业界标准的 自底向上 的开发策略,这种方式能确保我们的依赖层总是先于使用层被构建,逻辑递进最为清晰:
7.1. 数据访问层 (Mapper): 我们将首先构建与数据库直接交互的Mapper,它是所有上层建筑的基石。7.2. 业务逻辑层 (Service): 在Mapper提供的原子数据操作之上,我们将编排和实现核心的业务流程。7.3. 控制器层 (Controller): 最后,我们将构建Controller,将内部的业务服务以标准、安全的 RESTful API 形式暴露给前端。
现在,让我们从最基础、也最重要的数据访问层开始。
7.1. 数据访问层 (Mapper)
7.1.1. 任务目标
本节的核心任务是构建 **数据访问层 **。这是后端三层架构中最底层、最接近数据库的一层,扮演着“数据搬运工”的角色。我们将手动编写 Mapper 接口及其对应的 XML 映射文件,创建一组方法,用于执行针对 tb_course 表的原子化 SQL 操作(增、删、改、查)。这一层是整个后端服务的数据基石,其质量直接决定了上层业务的稳定性和性能。
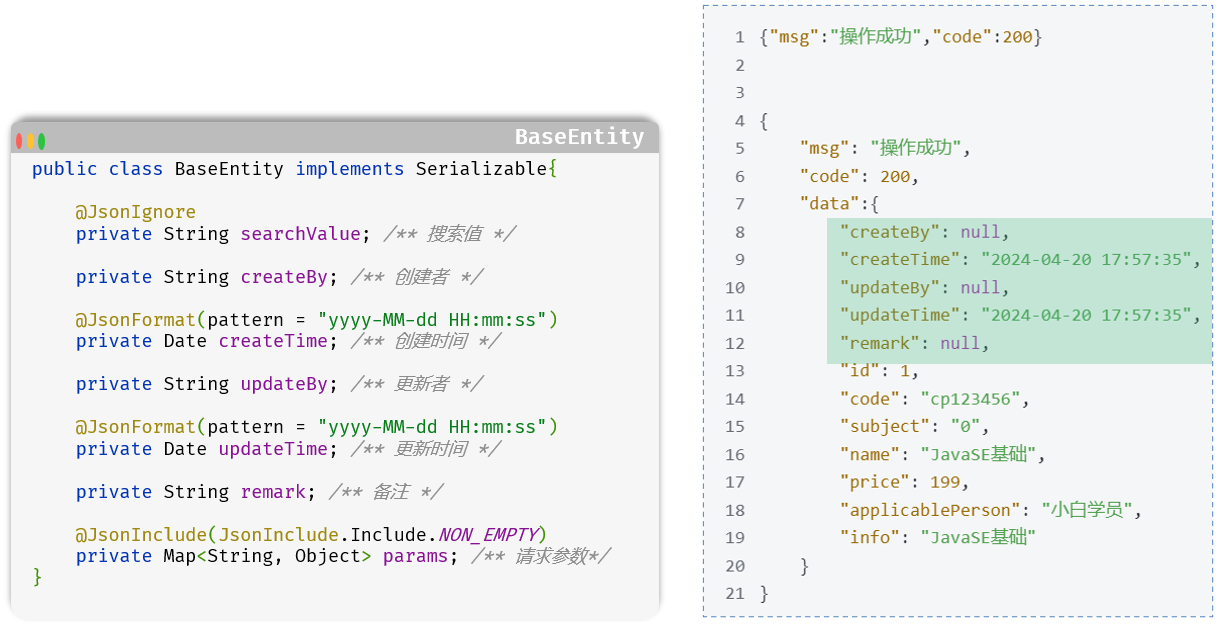
7.1.2. 前置工作:创建实体类 (Domain)
在编写 Mapper 之前,我们需要先创建一个 Java 类来承载从 tb_course 表中查询出的数据。这个类通常被称为 实体类 (Entity)、领域对象 (Domain Object) 或 POJO (Plain Old Java Object)。
它的字段必须与 tb_course 表的列一一对应。
1. 文件创建
在 com.ruoyi.course.domain 包下创建 TbCourse.java 文件。
文件路径: ruoyi-admin/src/main/java/com/ruoyi/course/domain/TbCourse.java
2. 完整代码
1 | package com.ruoyi.course.domain; |
extends BaseEntity: 继承了若依的BaseEntity,可以复用其中定义的createTime,updateTime等通用字段。@Excel注解: 这是若依为“导出 Excel”功能提供的自定义注解。它标记了哪些字段需要被导出,name属性定义了 Excel 中的列标题,readConverterExp则实现了导出时的数据字典自动转换。
7.1.3. 编写 TbCourseMapper 接口
Mapper 接口定义了数据访问的“契约”,即上层(Service)可以调用的方法。
文件路径: ruoyi-admin/src/main/java/com/ruoyi/course/mapper/TbCourseMapper.java
1 | package com.ruoyi.course.mapper; |
7.1.4. 编写 TbCourseMapper.xml
这是本节的 核心。我们将在这里为 Mapper 接口中的每一个方法编写对应的 SQL 语句。我们将深入分析每个 SQL 标签的功能。
文件路径: ruoyi-admin/src/main/resources/mapper/course/TbCourseMapper.xml
A. 文件头与可复用元素
在开始编写具体方法前,我们先定义好“命名空间”和“可复用模块”。
1 |
|
B. 查询方法 (Select)
1. selectTbCourseList (核心:动态条件查询)
- 对应接口:
public List<TbCourse> selectTbCourseList(TbCourse tbCourse); - 功能: 这是最复杂的查询,用于支持前端的“搜索”功能。用户可能只填写“课程名称”,也可能同时选择“学科”,所以 SQL 语句的
WHERE条件必须是动态生成的。
1 | <select id="selectTbCourseList" parameterType="TbCourse" resultMap="TbCourseResult"> |
解析 <where> 标签:
这是一个“智能”标签。它知道如果内部的 <if> 至少有一个成立,它就会在最前面插入一个 WHERE 关键字。更重要的是,它会自动 剔除 第一个 <if> 条件成立时,多余的 and 前缀。
2. selectTbCourseById (标准按 ID 查询)
- 对应接口:
public TbCourse selectTbCourseById(Long id); - 功能: 通过主键 ID 获取唯一的课程信息。
1 | <select id="selectTbCourseById" parameterType="Long" resultMap="TbCourseResult"> |
C. 插入方法 (Insert)
insertTbCourse (核心:动态字段插入)
- 对应接口:
public int insertTbCourse(TbCourse tbCourse); - 功能: 插入一条新的课程数据。核心在于“动态”:只插入用户传入了值的字段,没有传入的字段(如
info可能为空)则不出现在INSERT语句中,让数据库自动使用默认值。
1 | <insert id="insertTbCourse" parameterType="TbCourse" useGeneratedKeys="true" keyProperty="id"> |
解析 <trim> 标签 (用于 Insert):
这是 MyBatis 中最灵活的动态 SQL 标签。
- 这两个
<trim>块中的<if>判断条件 必须完全一致,才能保证列和值一一对应。 suffixOverrides=","是精髓所在。它解决了最后一个<if>成立时,SQL 语句末尾会多出一个,导致的语法错误。- 这种写法,使得
INSERT语句具有极高的灵活性,完美适配各种“可选字段”的插入场景。
D. 修改方法 (Update)
updateTbCourse (核心:动态字段更新)
- 对应接口:
public int updateTbCourse(TbCourse tbCourse); - 功能: 根据 ID 更新课程信息。核心在于“动态”:只更新用户传入了值的字段,未传入的字段(为 null)则不应被更新(即保持数据库原值)。
1 | <update id="updateTbCourse" parameterType="TbCourse"> |
深度解析 <trim> 标签 (用于 Update):
- 这解决了
UPDATE的两大痛点:
a. 避免更新空值: 如果不使用动态 SQL,UPDATE ... SET name=null这样的语句会把数据库的旧值冲刷掉。
b. 处理逗号:suffixOverrides=","自动处理最后一个SET字段后面多余的逗号。 prefix="SET"保证了只有在 至少一个<if>成立时,才会加上SET关键字,避免了无字段更新时UPDATE tb_course WHERE id = ...的语法错误。
E. 删除方法 (Delete)
1. deleteTbCourseById (标准按 ID 删除)
- 对应接口:
public int deleteTbCourseById(Long id); - 功能: 删除单条记录。
1 | <delete id="deleteTbCourseById" parameterType="Long"> |
2. deleteTbCourseByIds (核心:批量删除)
- 对应接口:
public int deleteTbCourseByIds(Long[] ids); - 功能: 根据前端传来的 ID 数组(例如
[1, 2, 3]),批量删除多条记录。
1 | <delete id="deleteTbCourseByIds" parameterType="String"> |
解析 <foreach> 标签:
这个标签是批量操作的利器。如果传入的 ids 是 [1, 5, 9],<foreach> 标签会自动将 SQL 拼接为:delete from tb_course where id in (1, 5, 9)
这是一个单独执行的、高效的 SQL 语句,远胜于在 Java 中循环调用 deleteTbCourseById。
7.2. 业务逻辑层 (Service)
7.2.1. 任务目标与设计哲学
在 7.1 节,我们构建了与数据库直接交互的 Mapper 层。现在,我们将进入后端三层架构的核心——业务逻辑层 (Service Layer)。
Service 层是连接 Controller 与 Mapper 的桥梁,它的核心职责不再是单纯的数据读写,而是 编排和实现具体的业务规则。我们将在这里,深度利用若依框架提供的各种工具类和设计模式,构建一个健壮、可维护的业务服务。
我们将严格遵循 面向接口编程 的设计范式,先定义 ITbCourseService 接口作为“业务契约”,再创建 TbCourseServiceImpl 实现类来完成“契约”的具体内容。
7.2.2. 编写 ITbCourseService 接口
接口文件定义了“课程管理”模块能对外提供的所有业务能力。
文件路径: ruoyi-admin/src/main/java/com/ruoyi/course/service/ITbCourseService.java
1 | package com.ruoyi.course.service; |
7.2.3. 编写 Impl 实现类
这是本节的 核心。我们将一步步构建这个实现类,并在每一步中,详细解析若依框架提供的特色工具是如何帮助我们提升开发效率和代码质量的。
1. 搭建基础结构与依赖注入
首先,我们创建 TbCourseServiceImpl.java 文件,并实现 ITbCourseService 接口。然后,注入我们底层依赖的 TbCourseMapper。
文件路径: ruoyi-admin/src/main/java/com/ruoyi/course/service/impl/TbCourseServiceImpl.java
1 | package com.ruoyi.course.service.impl; |
2. 实现查询方法 (select)
查询方法通常是业务层最直接的部分,它们现阶段主要是对 Mapper 方法的透传调用。
1 | // ... (依赖注入) ... |
至此,我们的“读”(Read)操作已经完成。
3. 实现新增方法 (insert) 并应用若依工具
现在我们来实现 insertTbCourse 方法。这不再是简单的透传,我们需要在这里 注入业务规则。
业务规则: 任何一条课程记录在被创建时,其 create_time 字段都应自动被设置为当前的服务器时间。
我们引入若依 common 模块下的 DateUtils 工具类。
1 | // 在文件顶部 import 区域添加: |
若依工具类: DateUtils
- 位置:
ruoyi-common/src/main/java/com/ruoyi/common/utils/DateUtils.java - 价值: 它统一了整个项目的日期和时间处理方式,避免了在代码中散落各种
new Date()或LocalDateTime.now(),保证了格式和时区的一致性。getNowDate()返回的是一个java.util.Date对象,与数据库的datetime类型兼容。这是若依“约定优于配置”思想的体现。
4. 实现修改方法 (update)
与新增类似,修改操作也需要注入业务规则。
业务规则: 任何一条课程记录在被修改时,其 update_time 字段都应自动被设置为当前的服务器时间。
1 | // ... (insertTbCourse method) ... |
5. 实现删除方法 (delete)
删除操作目前是直接透传,但在复杂业务中,这里是添加 删除前置校验 的最佳位置(例如,检查该课程是否有关联的学生订单,若有则不允许删除)。
1 | // ... (updateTbCourse method) ... |
7.3. 控制器层 (Controller): 暴露 HTTP 接口
7.3.1. 任务目标
至此,我们已经拥有了功能完备的 Mapper (数据访问) 和 Service (业务逻辑)。现在,我们来到了将内部服务“暴露”给外部世界的最后一站——控制器层 (Controller Layer)。
本节的核心任务是,手动编写 TbCourseController.java,创建一个符合 RESTful 风格的 API 控制器。它将扮演“交通枢纽”的角色,负责:
- 接收前端 HTTP 请求: 解析 URL、请求方法、参数和请求体。
- 调用业务服务: 将解析后的数据传递给
Service层进行处理。 - 构建标准响应: 将
Service层返回的结果,封装成统一、规范的 JSON 格式返回给前端。
我们将重点学习并应用若依框架在 Controller 层提供的 三大特色“利器”:权限控制、分页处理 和 日志记录。
7.3.2. 编写 TbCourseController (渐进式构建)
1. 搭建基础结构与依赖注入
首先,我们创建 TbCourseController.java 文件,并为其添加 Spring MVC 的核心注解,同时注入我们刚刚完成的 ITbCourseService。
文件路径: ruoyi-admin/src/main/java/com/ruoyi/course/controller/TbCourseController.java
1 | package com.ruoyi.course.controller; |
extends BaseController: 继承若依的BaseController是关键。我们将从中获得大量便捷的工具方法,如startPage(),getDataTable(),toAjax()等。
2. 实现列表查询 (list) 方法
这是最能体现若依框架便捷性的一个方法。我们将在这里一次性集成 权限控制 和 分页处理 两大功能。
1 | // ... (依赖注入) ... |
startPage();:- 这是若依的分页处理核心。此方法继承自
BaseController。 - 工作机制: 它内部会从前端请求中解析出
pageNum和pageSize等分页参数,然后调用PageHelper.startPage()方法。PageHelper会将这些分页信息存入一个ThreadLocal变量中。这意味着,这个分页设置 只对接下来执行的第一条 MyBatis 查询有效。
- 这是若依的分页处理核心。此方法继承自
List<TbCourse> list = tbCourseService.selectTbCourseList(tbCourse);:- 执行正常的业务查询。此时,MyBatis 的分页插件
PageHelper的拦截器会自动生效,它会拦截这条即将执行的 SQL,并根据ThreadLocal中的分页信息,自动在原始 SQL 的末尾拼接上LIMIT子句(如LIMIT 0, 10),从而实现物理分页。
- 执行正常的业务查询。此时,MyBatis 的分页插件
return getDataTable(list);:- 这是若依的标准分页响应封装。此方法同样继承自
BaseController。 - 工作机制: 它接收经过分页查询后的
List结果(这个List实际上是PageHelper返回的一个特殊子类Page,其中包含了总记录数等信息)。getDataTable会从中提取出当前页的数据列表和总记录数total,然后封装成一个TableDataInfo对象。 - 最终效果: 该对象被
@RestController序列化后,生成了前端所期望的{ "code": 200, "msg": "查询成功", "rows": [...], "total": 20 }这种标准 JSON 格式。
- 这是若依的标准分页响应封装。此方法同样继承自
3. 实现增、删、改方法
这些方法相对简单,但同样集成了若依的 日志记录 和 统一结果封装 功能。
1 | // ... (list method) ... |
@Log(title = "课程管理", businessType = BusinessType.INSERT):- 这是若依的操作日志记录功能。
@Log是一个自定义注解。 - 工作机制: 一个 AOP 切面 (
LogAspect) 会拦截所有带@Log注解的方法。在方法执行完毕后,切面会异步地收集本次操作的各种信息(如模块标题、操作类型、请求 URL、方法名、参数、操作人 IP、耗时等),并将它们封装成一个SysOperLog对象,最终存入sys_oper_log数据库表中。 - 优势: 以非侵入式的方式,轻松实现了对所有关键操作的审计和追溯功能,极大提升了系统的安全性。
businessType是一个枚举,定义了操作的类型。
- 这是若依的操作日志记录功能。
return toAjax(tbCourseService.insertTbCourse(tbCourse));:toAjax()方法继承自BaseController。Service层的增删改方法返回的是受影响的行数 (int)。toAjax的逻辑很简单:return rows > 0 ? AjaxResult.success() : AjaxResult.error();。- 作用: 这是一个便捷的转换器,将业务层返回的
int结果,转换成前端需要的、标准的{ "code": 200, "msg": "操作成功" }或{ "code": 500, "msg": "操作失败" }格式的AjaxResult对象。
4. 实现导出方法 (export)
1 | // ... (remove method) ... |
深度解析 ExcelUtil:
ExcelUtil是若依common-poi模块中提供的 核心工具,它基于 Apache POI 库进行了深度封装。- 工作机制:
new ExcelUtil<TbCourse>(TbCourse.class): 在实例化时,它会通过反射读取TbCourse.class中所有被@Excel注解标记的字段。util.exportExcel(response, list, "课程数据"): 此方法会:- 创建一个 Excel 工作簿。
- 根据
@Excel注解的name属性生成表头。 - 遍历
list集合,将每个TbCourse对象的数据填入对应的单元格。如果@Excel中定义了readConverterExp(字典转换),它会自动进行值的转换。 - 设置 HTTP 响应头(
Content-Type为application/vnd.ms-excel,Content-Disposition为attachment;filename=...)。 - 将生成的 Excel 文件流写入
HttpServletResponse的输出流中,从而触发浏览器的文件下载。
7.4 前后端交互全流程解析
想象一下,用户打开了“课程管理”页面,输入了课程名称“Java”,然后点击了“搜索”按钮。这个看似简单的操作,背后触发了一系列精妙的连锁反应。让我们来一步步追踪这个请求的生命周期。
第 1 步:前端 Vue 组件发起请求
一切始于 index.vue。当用户点击搜索,getList() 方法被调用。
1 | /** 查询课程管理列表 */ |
此时,queryParams.value 可能看起来是这样的:{ pageNum: 1, pageSize: 10, name: 'Java', ... }。这个对象被传递给了我们的 API 服务层。
第 2 步:API 层封装与代理转发
getList() 调用了在 course.js 中定义的 listCourse 函数。这一层是前端的“外交部”,专门负责与后端打交道。
1 | // course.js |
关键问题:跨域
我们的前端(例如 http://localhost:80)和后端(http://localhost:8080)运行在不同的端口上,这构成了“跨域”。浏览器出于安全考虑,会默认阻止前端直接向后端发送请求。若依前端项目是如何解决这个问题的呢?
答案就在于 开发服务器代理 (Proxy)。

这段配置告诉 vue-cli 的开发服务器:
“任何发往
/prod-api的请求,都不要真的发往/prod-api。请你(开发服务器)代我将这个请求转发到http://localhost:8080,并且在转发时,请把路径中的/prod-api去掉。”
因此,前端代码中看似请求了 /prod-api/course/course/list,实际上经过代理转发,最终到达后端服务器的请求是 GET http://localhost:8080/course/course/list?pageNum=1&...。这样就巧妙地绕过了浏览器的同源策略限制。
第 3 步:后端 Controller 层接收与处理
请求成功抵达若依后端。Spring MVC 框架根据请求的 URL (/course/course/list) 和 HTTP 方法 (GET),精准地将其路由到 TbCourseController 的 list 方法。
1 | // TbCourseController.java |
这里的每一步都体现了若依框架的设计精髓:
- 权限校验先行:在执行任何业务逻辑之前,
@PreAuthorize注解首先会利用 Spring Security 检查当前登录用户是否拥有course:course:list这个权限标识。如果没有,请求将被直接拒绝,返回 403 错误。 - 参数自动绑定:Spring MVC 会自动将 URL 中的查询参数(
name=Java,pageNum=1等)与Course对象的属性进行匹配和赋值。 - 声明式分页:
startPage()是一个神奇的方法。它并不执行查询,而是从请求中提取分页参数,并将它们存入一个线程级别的变量中。这为后续的数据库查询埋下了“伏笔”。 - 职责下放:Controller 不关心具体的查询逻辑,它只负责调度,将任务委托给
courseService。 - 标准格式封装:
getDataTable(list)会从PageHelper分页查询后的结果中,自动提取出列表数据和总条数,封装成前端需要的{ rows: [...], total: ... }结构。
第 4 步:Service 层编排业务
Controller 调用了 TbCourseServiceImpl.selectCourseList()。在查询这个场景下,Service 层没有复杂的业务逻辑,所以它主要扮演了一个“管道工”的角色,直接将请求透传给 Mapper 层。
1 | // TbCourseServiceImpl.java |
第 5 步:Mapper 层执行 SQL
这是与数据库交互的最后一环。courseMapper.selectCourseList(course) 的调用,会触发 MyBatis 框架去执行 TbCourseMapper.xml 中对应的 SQL 语句。
1 | <!-- TbCourseMapper.xml --> |
此时,两个“魔法”同时发生:
- PageHelper 插件:在 MyBatis 执行这条 SQL 之前,分页插件的拦截器会生效。它发现之前调用了
startPage(),于是自动在这条 SQL 的末尾拼接上LIMIT子句,使其变成一条物理分页查询语句。 - 动态 SQL:MyBatis 根据传入的
Course对象,动态地构建出WHERE子句。因为只有name字段有值,所以最终执行的 SQL 类似于:select ... from tb_course WHERE name like '%Java%' limit 0, 10。
第 6 步:数据回流与前端渲染
数据库执行 SQL 后,将查询结果集返回给 MyBatis,MyBatis 将其映射为 List<Course> 对象。这个列表经历了回家的路:
Mapper -> Service -> Controller (被 getDataTable 封装成 TableDataInfo) -> Spring MVC (序列化为 JSON 字符串) -> 网络 -> 前端代理服务器 -> 浏览器
浏览器接收到 JSON 响应后,axios 的 Promise 进入 resolved 状态,getList 函数中的 await 结束等待,res 变量被赋值。
最后,courseList.value = res.rows; 和 total.value = res.total; 这两行代码触发了 Vue 3 的响应式系统,页面上的表格和分页组件自动更新,向用户展示出经过筛选和分页的数据。loading.value = false; 则隐藏了加载动画。
至此,一次完整的前后端交互闭环圆满完成。






