
Prorise
这是我的博客,分享技术与生活的点点滴滴
第二十一章. common-mybatis 核心组件:MyBatis-Plus 的企业级增强与深度定制
第二十一章. common-mybatis 核心组件:MyBatis-Plus 的企业级增强与深度定制
Prorise第二十一章. common-mybatis 核心组件:MyBatis-Plus 的企业级增强与深度定制
摘要:本章将深入剖析 RuoYi-Vue-Plus 对 MyBatis-Plus (MP) 的深度定制与扩展。我们将从架构痛点出发,详细解读 BaseMapperPlus 的双泛型设计、雪花算法的集成细节、自动化审计的实现原理以及统一分页体系的构建,帮助你彻底掌握 RVP 数据持久层的核心奥秘。
本章学习路径
- 架构总览:理解 RVP 为什么要重造 MP 的轮子,以及
common-mybatis的核心定位。 - 配置与拦截:掌握拦截器链的执行顺序,理解分页、乐观锁、数据权限的协同工作机制。
- ORM 增强:深入
BaseMapperPlus源码,学会如何利用双泛型实现 PO 到 VO 的自动转换。 - 特性攻坚:彻底搞懂雪花算法时钟回拨解决方案、自动化字段填充以及防注入的分页查询。
- 全链路实战:从零开发一个具备完整 RVP 特性的单表模块。
21.1. 架构总览:RVP 为何要重造 MyBatis-Plus 的轮子?
回顾
在上一章中,我们深入探讨了 Jackson 的序列化机制,解决了前后端交互中“数据格式不一致”的问题,确保了数据传输层的高效与规范。
引出
然而,在后端开发的核心领域——数据持久层(DAO),仅依靠数据传输的规范是不够的。虽然 MyBatis-Plus (MP) 已经极大简化了 CRUD 操作,但在面对复杂的企业级需求(如自动 VO 转换、多租户隔离、数据权限)时,原生的 MP 依然存在“最后一公里”的缺失,导致开发者不得不重复编写大量样板代码。
预告
本节我们将深入 RVP 的 ruoyi-common-mybatis 模块,解析它如何通过架构层面的封装,填补原生 MP 的空白,并确立其在整个系统中的核心定位。
21.1.1. 原生 MP 在企业级开发中的痛点
在没有 RVP 这种封装框架之前,直接使用原生 MP 开发大型企业级项目,开发者通常会面临以下四个核心痛点。这些痛点正是 RVP 进行深度定制的根本原因。
痛点一:PO 与 VO 的转换繁琐
- 现象:数据库实体
User(PO) 通常包含密码、逻辑删除标识等敏感字段,而前端展示需要UserVo(VO)。原生 MP 的BaseMapper.selectList()默认返回的是List<User>。 - 后果:开发者必须在 Service 层手动编写循环或调用
BeanUtils将List<User>转换为List<UserVo>。这种转换代码在每个查询业务中都会重复出现,既冗余又难以维护,且容易因漏转字段导致数据泄露。
痛点二:批量操作的层级错位
- 现象:原生 MP 将批量插入
saveBatch等高效方法封装在IService接口中,而不是底层的BaseMapper中。 - 后果:如果你想在 Mapper 层直接执行批量插入(例如为了极致性能优化,或是为了绕过 Service 层某些复杂的切面逻辑),你必须自己手写 XML 或者手动注入
SqlSessionFactory。RVP 认为 Mapper 层作为数据访问的原子层,应该具备完整的 CRUD 能力。
痛点三:分页参数解析的重复劳动
- 现象:前端传递的分页参数通常是标准的
pageNum(页码)、pageSize(页大小)、orderBy(排序字段)。 - 后果:开发者需要在每个 Controller 方法中手动接收这些参数,构建 MP 的
Page对象。更严重的是,如果不做特殊处理,直接拼接排序字段(如前端传来id; delete from user),将面临严重的 SQL 注入风险。
痛点四:审计字段的手动填充
- 现象:企业级应用中,每张表都有
create_time、create_by、update_by等审计字段。 - 后果:虽然 MP 提供了
MetaObjectHandler接口,但原生 MP 并不知道你的权限框架用的是 Sa-Token 还是 Spring Security。如何优雅地结合权限框架,自动获取当前登录用户的 ID 并填充,往往需要开发者自己实现。如果处理不好,经常会出现“定时任务或异步调用时因未登录导致填充报错”的问题。
21.1.2. common-mybatis 模块的架构定位
为了解决上述痛点,RVP 将所有与数据库交互的通用逻辑抽离到了 ruoyi-common-mybatis 模块中。它是连接业务模块与底层数据库中间件的“桥梁”。
模块依赖图谱
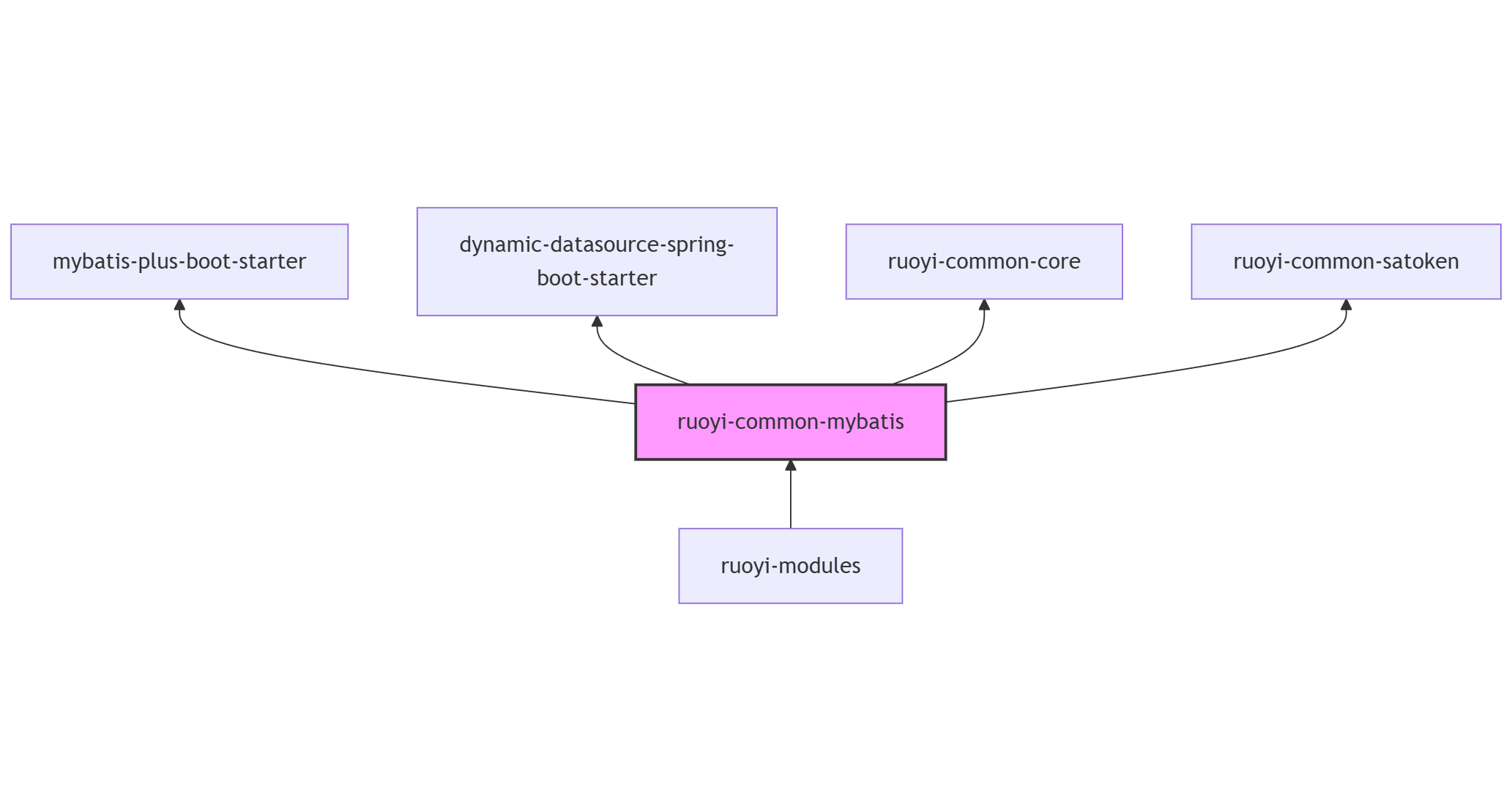
核心职责:
- 统一配置:接管 MP 的
GlobalConfig,统一全系统的配置标准,包括主键生成策略(雪花算法)、逻辑删除值(0 正常 / 2 删除)等。 - 能力增强:提供
BaseMapperPlus接口,在保留原生能力的基础上,扩展了批量操作和自动对象转换能力。 - 安全拦截:通过拦截器链(Interceptor Chain)机制,统一实现数据权限过滤、非法 SQL 拦截和多租户数据隔离。
- 自动填充:深度集成 Sa-Token,实现对业务代码完全无感知的审计字段自动填充。
21.1.3. 三大核心支柱
ruoyi-common-mybatis 模块之所以强大,主要依赖于以下三个核心组件的支撑。理解了这三个组件,就理解了 RVP 持久层的设计灵魂。
支柱一:BaseMapperPlus(数据访问层增强)
这是 RVP 最具创新性的设计之一。它打破了原生 Mapper 只能绑定一个实体泛型 <T> 的限制,引入了 双泛型 <T, V> 机制。
- 定义:
public interface BaseMapperPlus<T, V> extends BaseMapper<T> - 原理:利用 Java 的反射和泛型机制,Mapper 能够同时感知到 数据库实体类型(T) 和 视图对象类型(V)。
- 价值:当你调用
selectVoList()时,底层不仅执行查询,还会利用MapStruct或BeanUtils自动将结果集从 PO 转换为 VO。这彻底消灭了 Service 层中那些枯燥的转换代码。
支柱二:PageQuery(数据传输层增强)
这是专门用于接收前端分页参数的数据传输对象(DTO)。
- 位置:
org.dromara.common.mybatis.core.page.PageQuery - 作用:它统一封装了
pageNum、pageSize、orderByColumn、isAsc等参数。 - 核心价值:它的
build()方法不仅能快速创建 MP 的Page对象,更重要的是内置了 SQL 注入过滤器(SqlUtil.escapeOrderBySql)。这意味着即使开发者忘记做安全检查,PageQuery也会自动清洗排序字段,确保查询安全。
支柱三:PlusDataPermissionInterceptor(安全控制层增强)
这是 RVP 自定义的数据权限拦截器,是实现“行级权限控制”的关键。
- 位置:
org.dromara.common.mybatis.interceptor.PlusDataPermissionInterceptor - 作用:它利用 MP 的插件机制,在 SQL 执行前进行拦截。
- 机制:解析 Mapper 方法上的
@DataPermission注解,根据当前登录用户的角色权限,动态拼接 SQL 的WHERE子句(例如自动追加AND dept_id IN (101, 102)),从而在底层物理隔绝用户无权访问的数据。
21.1.4. 本节小结
- 痛点分析:原生 MP 虽然优秀,但在 PO/VO 转换、Mapper 层批量操作、分页参数安全封装以及审计填充方面,仍需大量手动代码。
- 架构定位:
ruoyi-common-mybatis是连接业务与数据的中间层,负责统一配置、能力扩展与安全防护。 - 核心三剑客:
- BaseMapperPlus:通过双泛型解决对象自动转换与批量操作。
- PageQuery:解决分页参数的统一封装与 SQL 注入防御。
- 拦截器:解决数据权限的动态过滤与租户隔离。
速查代码:原生 MP vs RVP 风格
1 | // 1. 原生 MP 风格 (繁琐) |
21.2. 核心配置:MybatisPlusConfig 与拦截器链
在上一节中,我们了解了 RVP 持久层架构的三大支柱(BaseMapperPlus、PageQuery、拦截器)。这些组件就像是散落的珍珠,需要一根线将它们串联起来。这根线就是 Spring Boot 的配置类——MybatisPlusConfig。MyBatis-Plus 的强大之处在于其开放的插件机制(Interceptor),但如果插件的执行顺序弄错了,轻则分页数据不准,重则数据权限失效导致重大安全事故。本节我们将深入 MybatisPlusConfig,剖析 RVP 是如何通过“洋葱模型”将多租户、数据权限、分页和乐观锁等插件组装成一套严密的业务逻辑处理链的。
21.2.1. 拦截器链深度解析
在 MybatisPlusConfig 中,我们通过 MybatisPlusInterceptor 来管理所有的内部插件。
请务必注意代码中 addInnerInterceptor 的调用顺序。这绝不是随意摆放的,而是严格遵循了“洋葱模型”——SQL 语句从外层向内层穿透,每一层拦截器都对 SQL 进行一次加工。
文件路径:src/main/java/org/dromara/common/mybatis/config/MybatisPlusConfig.java
代码解析:
1 |
|
执行顺序的核心逻辑:
- 物理隔离优先(多租户):SQL 进入后,首先要解决“我是谁的 SQL”的问题。必须先追加
tenant_id,防止 A 公司查到 B 公司的数据。这是最高优先级的物理隔离。 - 业务隔离次之(数据权限):在确定的租户范围内,再根据当前用户的角色(如“销售经理”)追加
dept_id过滤。这是业务逻辑隔离。 - 统计与切分在后(分页):这是最容易出错的地方。必须先过滤,再分页。
- 错误顺序:如果先分页再过滤,会导致
SELECT * LIMIT 10查出来的数据,被后面的权限插件过滤掉 5 条,最终前端只显示 5 条,用户会疑惑“明明每页显示 10 条,为什么这页只有 5 条?”。 - 正确顺序:先追加所有
WHERE条件,再执行COUNT(*)和LIMIT,确保分页的准确性。
- 错误顺序:如果先分页再过滤,会导致
- 并发控制收尾(乐观锁):最后处理 UPDATE 语句的
version字段,确保数据一致性。
21.2.2. 分页插件 PaginationInnerInterceptor
RVP 对分页插件进行了一项关键配置:setOverflow(true),这是一个非常人性化的用户体验优化。
1 | public PaginationInnerInterceptor paginationInnerInterceptor() { |
业务场景演示:
假设当前用户列表中有 11 条数据,每页显示 10 条,共 2 页。用户正在浏览第 2 页(只有 1 条数据)。
- 场景:用户删除了第 2 页唯一的那条数据,然后刷新页面。
- 不开启合理化(Default):前端请求
pageNum=2。数据库只剩 10 条数据,总页数变为 1。第 2 页查询结果为空。用户会看到一个空白表格,以为系统出 Bug 了。 - 开启合理化(RVP):当请求页码(Page 2)超过最大页码(Page 1)时,插件会自动将请求重置为最大页码(Page 1)。用户删除后,会自动跳回上一页看到剩余的 10 条数据,体验丝滑。
21.2.3. 异常处理器 MybatisExceptionHandler
在配置类的末尾,注册了 MybatisExceptionHandler。这是一个全局异常翻译器。
1 |
|
核心价值:
MyBatis 在底层报错时,通常会抛出 BadSqlGrammarException(SQL 语法错误)或 MyBatisSystemException。这些异常堆栈信息中可能包含表结构、字段名等敏感信息。该处理器结合 Spring 的 @ControllerAdvice 机制,将这些晦涩且危险的底层异常捕获,并包装成标准的 HTTP 500 响应(如“系统繁忙,请联系管理员”),既保护了系统安全,又提升了接口的友好度。
21.2.4. 本节小结
- 洋葱模型:拦截器的顺序决定了 SQL 的命运。租户 -> 权限 -> 分页 -> 乐观锁 是经过验证的最佳实践顺序。
- 分页合理化:通过
setOverflow(true)解决了“删除最后一页数据导致空白”的用户体验问题。 - 安全防护:通过
setMaxLimit防止全表查询攻击,通过异常处理器隐藏底层数据库细节。
21.3. BaseMapperPlus:双泛型架构深度解析
在配置好拦截器链后,我们的 MP 已经具备了安全防护能力。但在开发具体业务(Service 层)时,我们最大的痛点依然存在:数据库实体(PO)和前端视图(VO)之间的频繁转换。这导致 Service 层充斥着大量无意义的 BeanUtils.copyProperties 代码。本节将深入 RVP 持久层最核心的创新——BaseMapperPlus。我们将剖析它如何利用 Java 泛型机制与动态代理,实现“查询即 VO”
21.3.1. 设计哲学:为何引入 <T, V> 双泛型?
原生 MP 的标准接口是 BaseMapper<T>,它只能感知实体类 T(例如 SysUser)。但在实际业务中,数据库查询出的 SysUser(包含密码、逻辑删除标识)不能直接返回给前端,必须转换为 SysUserVo(脱敏后的数据)。
RVP 扩展了这一接口,定义了 双泛型架构:
public interface BaseMapperPlus<T, V> extends BaseMapper<T>
- T (Table Entity):数据库映射者。绑定
@TableName,负责生成 SQL。 - V (View Object):视图表现者。绑定
@AutoMapper,负责最终的数据形态。
开发者实战:
在定义 Mapper 接口时,你必须明确告诉 MP:“我查的是表 A,但我要返给前端的是对象 B”。
1 | /** |
21.3.2. 【源码】selectVo* 系列方法的执行内幕
当我们在 Service 中写下 sysUserMapper.selectVoById(1L) 这行代码时,底层到底发生了什么?为了讲清楚这个过程,我们必须深入源码,看看 Java 8 default 方法 与 动态代理 是如何配合的。
场景模拟:
- 调用方:Service 层调用
sysUserMapper.selectVoById(1001L)。 - 预期:数据库查出
SysUser,自动转为SysUserVo返回。
源码追踪与深度解析:org.dromara.common.mybatis.core.mapper.BaseMapperPlus
1 | // 这是一个接口中的 default 方法 |
数据流转全景图 (Data Flow):
为了更直观地理解,我们将一次查询拆解为 3 个核心阶段:
1. 泛型嗅探阶段Service 调用 selectVoById
$\downarrow$BaseMapperPlus.currentVoClass() 被触发
$\downarrow$
关键点:利用 this 指针(代理对象)反向查找接口定义,锁定 V = SysUserVo.class。
2. 数据库查询阶段BaseMapperPlus 调用 this.selectById(id)
$\downarrow$
MyBatis 拦截器链(租户 -> 权限)介入
$\downarrow$
执行 SQL: SELECT * FROM sys_user WHERE id = 1001
$\downarrow$
返回 PO 对象: SysUser(id=1001, password="***", del_flag="0")
3. 对象转换阶段BaseMapperPlus 调用 MapstructUtils.convert(po, voClass)
$\downarrow$
MapStruct 实例将 PO 属性拷贝给 VO
$\downarrow$
关键点:敏感字段(如 password)因为 VO 中没有定义,自动被丢弃;重命名字段自动匹配。
$\downarrow$
返回 VO 对象: SysUserVo(id=1001, name="admin")
21.3.3. 【源码】insertBatch 的下沉设计
原生 MP 的批量插入 saveBatch 是在 IService 层实现的,其底层依然是 for 循环调用 sqlSession.insert。RVP 将其下沉到了 Mapper 层,并利用了 MP 扩展包的 Db 工具类。
1 | /** |
为什么这样做?
- 绕过 Service 循环依赖:
- 场景:你在
UserListener(监听器)中解析 Excel 并批量导入用户。如果 Listener 注入UserService,而UserService又可能依赖 Listener,容易造成循环依赖。 - 解决:直接注入
UserMapper调用insertBatch,切断依赖链。
- 场景:你在
- 性能可控性:
Db.saveBatch默认开启了 JDBC 的RewriteBatchedStatements优化。- 重要配置:在 JDBC 连接串中必须添加
&rewriteBatchedStatements=true,否则批量插入依然是一条条发送 SQL,性能不会提升。 - RVP 默认设置
batchSize为 1000。这意味着如果你插入 10000 条数据,它会切分为 10 次网络交互(每一次交互包含 1000 条 INSERT),有效防止因 SQL 语句过长(超过 MySQL 的max_allowed_packet)导致报错。
21.3.4. 本节小结
- 双泛型机制:通过
BaseMapperPlus<T, V>,让 Mapper 接口同时具备了“数据库思维(T)”和“前端思维(V)”。 - 动态代理与 This:
selectVo*方法利用接口 default 方法中的this指针,通过反射动态获取当前 Mapper 绑定的 VO 类型,这是实现通用的核心。 - 流转闭环:
Reflection(获取类型)->DB(获取数据)->Convert(转换结构),三步走完,Service 层彻底解放。 - 批量下沉:
insertBatch赋予了 Mapper 层独立的高性能批量处理能力,不再依赖 Service 层的事务包裹。
21.4. 分布式主键:雪花算法 (Snowflake) 的深度攻坚
回顾
解决了查询(BaseMapperPlus)和转换(MapStruct)问题后,我们必须回到数据的源头——主键生成。
引出
在分布式微服务架构中,传统的数据库自增 ID(Auto Increment)面临着分库分表难、ID 容易被遍历(导致业务数据泄露)等严重问题。Twitter 开源的 雪花算法 (Snowflake) 是目前的行业标准,但在容器化(Docker/K8s)环境下,它面临两个棘手的“水土不服”问题:WorkerID 重复 和 前端精度丢失。
预告
本节我们将深入 RVP 的源码配置,揭秘它是如何通过一行代码实现“零配置”的 ID 防冲突,以及如何通过 Jackson 全局配置彻底根治精度丢失问题。
21.4.1. 理论基础:64 位比特结构
雪花算法生成的 ID 是一个 64 位的 Long 型整数,其内部结构像是一个精密的仪表盘:
| 1 位 | 41 位 | 10 位 | 12 位 |
|---|---|---|---|
| 符号位 | 时间戳 | 机器 ID | 序列号 |
| 始终为 0 | 记录毫秒级时间差 | 5 位数据中心 + 5 位工作机器 | 毫秒内的计数器 |
- 时间戳 (41 bit):可以使用约 69 年。
- 机器 ID (10 bit):支持 1024 个节点。这是分布式不重复的关键。
- 序列号 (12 bit):同一毫秒、同一机器内支持生成 4096 个 ID。
21.4.2. 【源码解析】容器化环境下的 ID 防冲突
痛点场景:在 K8s 集群中,服务实例(Pod)是动态扩缩容的。如果我们在配置文件中写死 worker-id: 1,当扩容出 3 个 Pod 时,它们全都持有 worker-id: 1。在同一毫秒内,这 3 个实例生成的 ID 必然冲突,导致 Duplicate Key Error。
RVP 解决方案:
RVP 并没有引入复杂的 Redis 发号器,而是利用了 MyBatis-Plus 原生提供的 DefaultIdentifierGenerator 结合 Hutool 的网络工具,实现了一种 基于 IP 的自适应策略。
核心源码:org.dromara.common.mybatis.config.MybatisPlusConfig
1 | /** |
原理解密:
- 获取 IP:
NetUtil.getLocalhost()(Hutool 工具)会获取当前容器或服务器的InetAddress。在 K8s 网络平面中,每个 Pod 都会被分配一个独立的集群 IP(例如10.244.1.5)。 - IP 转 WorkerID:MP 的
DefaultIdentifierGenerator内部逻辑非常巧妙。它拿到 IP 后,并没有机械地使用 IP 的全部,而是截取 IP 地址的 低 16 位(最后两段),通过算法映射到雪花算法的 10 bit 机器码空间中。 - 结果:只要集群内的 Pod IP 不完全相同(且低位不碰撞),生成的 WorkerID 就绝对不同。这实现了 零配置、无状态 的分布式 ID 生成。
优势:无需依赖 Redis 或 Zookeeper 等外部组件维护 WorkerID,降低了架构复杂度,极大提升了系统启动速度。
21.4.3. 【源码解析】Jackson 全局配置解决精度丢失
痛点场景:
Java 的 Long 最大值是 $2^{63}-1$(约 19 位数字),而 JavaScript 的 Number 类型最大安全整数只有 $2^{53}-1$(约 16 位数字)。当后端生成的 ID(如 1746829462819428352)传给前端时,最后几位会被 JS 自动截断并补零,变成 1746829462819428000,导致前端查不到详情数据。
常规方案 vs RVP 方案:
- 常规方案:在每个 ID 字段上加
@JsonSerialize(using = ToStringSerializer.class)。缺点是容易漏加,且代码侵入性强。 - RVP 方案:通过 Jackson 模块进行 全局配置,对所有
Long类型统一拦截。
核心源码:org.dromara.common.json.config.JacksonConfig
1 |
|
原理解密:
- BigNumberSerializer:这是一个自定义序列化器,它的
INSTANCE内部实现逻辑是将数字直接执行String.valueOf(value)。 - 全局生效:通过
javaTimeModule.addSerializer注册后,Spring Boot 在处理 JSON 响应时,只要遇到Long或long类型的字段,就会自动调用该序列化器。 - 效果:后端实体
Long id = 123L$\rightarrow$ JSON 报文"id": "123"。前端接收到的是字符串,精度完美保留。
21.4.4. 【实战】手动调用雪花算法
虽然 MP 会自动为标记了 @TableId(type = IdType.ASSIGN_ID) 的字段填充 ID,但在某些业务场景(如生成订单号、TraceId、日志流水号)中,我们需要在代码中手动获取 ID。
文件路径:src/main/java/org/dromara/demo/service/impl/OrderServiceImpl.java (示例)
正确姿势:
1 |
|
避坑指南:严禁在代码中自己 new DefaultIdentifierGenerator()。必须使用 Spring 注入的实例,否则无法保证 WorkerID 的唯一性(自己 new 的实例无法获取配置中的 IP 策略)。
21.4.5. 本节小结
- 防冲突机制:RVP 在
MybatisPlusConfig中通过NetUtil.getLocalhost()绑定当前容器 IP,利用 MP 默认算法将 IP 映射为 WorkerID,解决了 K8s 环境下 ID 重复问题。 - 防精度丢失:RVP 在
JacksonConfig中注册了全局的BigNumberSerializer,将所有 Long 类型自动转为 String 返回给前端,实现了对业务代码的零侵入。 - 最佳实践:始终通过注入
IdentifierGenerator接口来获取 ID,严禁手动实例化生成器。
21.5. 自动化审计:MetaObjectHandler 源码剖析
在解决了分布式主键(Identity)问题后,数据已经拥有了唯一的“身份证”。但在企业级开发中,数据入库仅仅是第一步。根据审计合规要求,我们必须清楚地记录每条数据的“前世今生”:是谁创建的?什么时候修改的?所属部门是哪里?如果你还在 Service 层手动编写 setCreateTime(new Date()),那么本节将为你展示 RVP 是如何通过 InjectionMetaObjectHandler 拦截器,在 MyBatis 层面彻底消灭这些冗余代码,并解决“定时任务无用户上下文”这一经典难题。
21.5.1. 审计字段填充的演进与痛点
在没有自动填充功能的传统项目中,维护审计字段(CreateTime, CreateBy, UpdateTime, UpdateBy)通常面临两大痛点:
- 代码冗余:开发者需要在每一个
insert或update方法前,手动调用 4 个 Setter 方法。 - 数据完整性风险:一旦某个新人开发者忘记设置
CreateBy,或者在复制粘贴代码时漏改了UpdateTime,就会导致数据归属权丢失,且难以排查。
RVP 的解决方案:基于 MyBatis-Plus 提供的 MetaObjectHandler 接口,实现全局拦截。它像一个从不休息的守门员,在 SQL 语句即将发送给数据库执行的 毫秒级瞬间,自动检查并填充这些字段。
21.5.2. insertFill 插入填充的深度逻辑
我们来看 InjectionMetaObjectHandler 的核心实现。这是一个标准的“模板方法模式”落地,RVP 在此处的处理非常细腻,兼顾了灵活性与健壮性。
源码路径:org.dromara.common.mybatis.handler.InjectionMetaObjectHandler
代码片段一:契约检查与时间同步
1 |
|
关键设计解析:
instanceof BaseEntity:这是一个重要的 防御性编程。MP 的拦截器是全局生效的,但并非所有表都需要审计字段。RVP 通过BaseEntity划定了一条清晰的界限:只有遵守契约的实体,才有资格被自动填充。- 手动优先(Manual Priority):
ObjectUtils.notNull(原值, 默认值)。这解决了“数据迁移”或“补录历史数据”的场景。如果你显式调用了setCreateTime(yesterday),框架会尊重你的决定,而不是强行覆盖为当前时间。
代码片段二:环境感知的用户填充
1 | // 接上文... |
为什么需要分支 B(降级策略)?
这是新手最容易踩的坑。当代码由 定时任务 (Quartz/SnailJob) 或 消息队列消费者 触发时,当前线程并不处于 HTTP 请求上下文中,LoginHelper.getLoginUser() 会返回 null。
- 错误做法:直接抛出
NullPointerException或NotLoginException,导致定时任务全线崩溃。 - RVP 做法:当获取不到用户时,将创建人标记为
-1(系统默认 ID)。这既保证了程序的健壮性,又在数据库中留下了明确的标记(-1代表这是系统自动产生的记录)。
21.5.3. updateFill 更新填充的差异化处理
更新操作的填充逻辑与插入略有不同,主要体现在对“空值”的处理上。
1 |
|
21.5.4. 本节小结
| 核心特性 | 实现机制 | 业务价值 |
|---|---|---|
| 范围控制 | instanceof BaseEntity | 规范领域模型,避免误伤无关表 |
| 时间同步 | current 变量复用 | 保证 create_time 与 update_time 毫秒级一致 |
| 环境适配 | getLoginUser 判空降级 | 完美兼容 Web 请求与定时任务/异步线程 |
| 手动优先 | ObjectUtils.notNull | 支持数据迁移等特殊场景的手动赋值 |
21.6. 统一分页:从 PageQuery 到 TableDataInfo
有了自动填充,写数据变得简单了。查数据(尤其是分页查询)在 Web 系统中更高频。然而,原生 MP 的 Page 对象直接暴露在 Controller 层存在两个问题:一是参数接收麻烦(需要手动解析 pageNum/pageSize),二是存在严重的 SQL 注入风险(排序字段)。
RVP 引入了 PageQuery 和 TableDataInfo 两个核心类,构建了分页操作的“输入-输出”安全闭环。
21.6.1. PageQuery:不仅仅是参数接收器
PageQuery 位于 org.dromara.common.mybatis.core.page 包下,它的职责是将前端零散的参数(pageNum, pageSize, orderByColumn, isAsc)组装成 MP 需要的 Page 对象。
核心源码:SQL 注入防御与参数清洗
这是 PageQuery 中最精彩的部分。如果不做处理,前端传递 orderByColumn="id; delete from user" 将直接导致数据库被清空。
1 | private List<OrderItem> buildOrderItem() { |
21.6.2. build() 方法:MP 对象的生成工厂
PageQuery 最终通过 build() 方法产出 MP 的 Page 对象。
1 | public <T> Page<T> build() { |
21.6.3. TableDataInfo:标准化的响应格式
当 Service 层查询结束后,我们需要将 MP 的 IPage 结果转换给前端。TableDataInfo 就是这个标准容器,它配合 BaseController.getDataTable 使用。
1 | // 统一响应结构 |
21.6.4. 本节小结
| 问题领域 | 痛点 | RVP 解决方案 | 核心代码位置 |
|---|---|---|---|
| 安全性 | SQL 注入攻击 | 白名单过滤非法字符 | SqlUtil.escapeOrderBySql |
| 规范性 | 命名风格差异 | 驼峰转下划线 | StringUtils.toUnderScoreCase |
| 兼容性 | UI 组件参数差异 | 关键字映射转换 | StringUtils.replaceEach |
21.7. 全链路演示:商品管理 (Product)
在前面的小节中,我们已经深入理解了 RVP 对 MyBatis-Plus 的三大增强:
- BaseMapperPlus:解决了 PO 到 VO 的自动转换。
- PageQuery:解决了分页参数的解析与防注入。
- MetaObjectHandler:解决了审计字段的自动填充。
现在,我们将通过开发一个精简版的 商品管理 (Product) 模块,亲手验证这三大神器的威力。
说明:为了聚焦于持久层的实战,本案例将省略权限校验(Sa-Token)和参数校验(Validation)等非核心代码,这些高级特性将在后续章节专门讲解。
21.7.1. 步骤一:定义实体 (Entity)
首先,我们需要定义与数据库表映射的实体类。这一步的关键在于继承 TenantEntity。
文件路径:domain/Product.java
我们先看代码骨架,这里有两个关键点需要注意:
1 |
|
为什么要这样写?
extends TenantEntity:不仅是为了支持多租户,更是为了触发InjectionMetaObjectHandler的拦截逻辑。如果你不继承它,自动填充功能将不会生效,你的create_time将永远是null。ASSIGN_ID:即使你的数据库表主键没有设置AUTO_INCREMENT,MP 也会利用我们在配置中集成的IdentifierGenerator生成分布式唯一的雪花 ID。
###21.7.2. 步骤二:定义视图 (VO)
接下来定义返回给前端的 VO 对象。我们希望查询结果能自动映射,不需要在 Service 层手写 Convert。
文件路径:domain/vo/ProductVo.java
1 |
|
原理解析:加上 @AutoMapper 注解后,RVP 的编译时工具会自动生成 Product 到 ProductVo 的转换代码。这为后续 Mapper 层的自动化转换打下了基础。
21.7.3. 步骤三:增强 Mapper 接口 (核心)
这是本章最高光的时刻。我们将继承 BaseMapperPlus,并见证奇迹。
文件路径:mapper/ProductMapper.java
1 | /** |
这一步解决了什么问题?
在原生 MP 中,你需要自己写 XML 或者在 Service 层循环转换对象。而现在,通过这一行继承代码,Mapper 层直接具备了“查出 PO 自动转 VO”的能力。
21.7.4. 步骤四:Service 业务实现
现在我们进入 Service 层。你会发现,得益于前面的铺垫,业务代码变得异常简洁。
场景 A:分页查询
我们需要支持根据商品名称模糊查询,并支持自定义排序。
文件路径:service/impl/ProductServiceImpl.java
1 |
|
场景 B:新增数据
我们需要插入一条数据,并确保审计字段被填充。
1 |
|
###21.7.5. 步骤五:Controller 调用最后,我们在 Controller 层对外暴露接口。
文件路径:controller/ProductController.java
1 |
|
###21.7.6. 实战总结让我们回顾一下,在这个过程中我们 省去 了哪些代码:
- 省去了 SQL:
BaseMapperPlus帮我们生成了所有 SQL。 - 省去了 PO-VO 转换:
selectVoPage帮我们自动完成了对象拷贝。 - 省去了
setCreateTime:拦截器帮我们自动填充了审计字段。 - 省去了分页参数解析:
PageQuery帮我们处理了 request 参数。
这就是 RVP 架构带来的 极速开发体验。
##21.8. 本章总结与速查
###21.8.1. 核心要点回顾
- 双泛型架构:
BaseMapperPlus<T, V>是 RVP 的灵魂,它打通了 Entity 与 VO 的自动化壁垒。 - 审计自动化:只要继承
BaseEntity,你就永远不用再写setCreateTime(new Date())。 - 分页标准化:使用
PageQuery接收参数,使用TableDataInfo返回结果,这是 RVP 分页的标准范式。
###21.8.2. 场景化代码模版
遇到以下 [3] 种 [持久层] 场景时,请直接 Copy 下方的标准代码模版:
####1. 场景一:查询列表并返回 VO
需求:查询状态正常的商品,返回 VO 列表。
代码:
1 | // 直接使用 BaseMapperPlus 的 selectVoList 方法 |
####2. 场景二:高性能批量插入
需求:导入 1 万条数据,防止数据库报错。
代码:
1 | List<Product> list = ...; |
####3. 场景三:自定义排序分页
需求:前端指定排序字段(如 price),后端分页。
代码:
1 | // pageQuery.build() 会自动处理 orderBy=price desc |






