
Prorise
这是我的博客,分享技术与生活的点点滴滴
第三章. BMAD 四阶段工作流:从需求到上线
第三章. BMAD 四阶段工作流:从需求到上线
Prorise第三章. BMAD 四阶段工作流:从需求到上线
本章将深入四个阶段的具体操作步骤,理解每个阶段的关键决策点和工件传递机制。核心思想:每个阶段都是下一个阶段的 “地基”,地基不牢,地动山摇。
🗺️ BMAD 方法论概览
| 阶段 | 核心内容 | 典型交付物 |
|---|---|---|
| Phase 1 - 分析 | 市场研究、需求分析、产品定义 | 产品简介、PRD、竞品分析 |
| Phase 2 - 架构 | 技术架构、系统设计 | 架构文档、技术选型 |
| Phase 3 - 实施 | Epic/Story 拆分、开发 | 功能规格、代码 |
| Phase 4 - 测试/发布 | 质量保证、部署 | 测试计划、发布 |
3.1. Analysis 阶段:把模糊想法变成可执行需求
这个阶段的目标是 回答三个问题:我们要做什么?为什么要做?怎么判断做成功了?
启动 Analyst 代理
在 Claude Code 中打开一个新对话,输入:
1 | *agent analyst |
或者简写:
1 | *analyst |
系统会加载 _bmad/bmm/agents/analyst.md 文件,激活需求分析师角色(Mary)。这时你会看到:
1 | 📊 Business Analyst (Mary) 已激活 |
注意:代理激活后会立即加载 _bmad/bmm/config.yaml 配置文件,读取项目名称、输出文件夹、用户名、沟通语言等设置。
WS(Workflow Status)
一个轻量级状态追踪工具,专门用来回答一个关键问题:
“我现在该做什么?” 🎯
🔍 它具体做什么?
- 读取状态文件 — 它会查找 bmm-workflow-status.yaml 文件,里面记录了项目的整个工作流程进度
- 展示当前状态 — 告诉你:
- 项目类型和级别
- 已完成的工作流
- 待处理的工作流
- 可选的工作流 - 指引下一步 — 明确指出:
- 下一个该做的工作流是什么
- 应该调用哪个代理 来执行
- 具体的命令是什么 - 管理进度 — 允许你:
- 标记工作流为「已完成」
- 跳过某些工作流
- 查看完整的状态文件
想象一下,你正在做一个大型项目,涉及需求分析、架构设计、测试等多个阶段… WS 就像一个进度灯塔 ,随时告诉你现在在哪里、下一步要去哪里!
头脑风暴:挖掘真实需求
第一步是进行头脑风暴。在 Analyst 代理的菜单中,选择 [BP] 或输入 BP(支持模糊匹配)。
Analyst 会启动 _bmad/core/workflows/brainstorming/workflow.md 工作流,开始引导式头脑风暴:
1 | 让我们开始头脑风暴会话。我会使用多种创意技巧来帮助你探索想法。 |
Analyst 的提问方式:它不问 “你想要什么功能”,而是问 “你遇到了什么问题”。
这解决了什么问题?防止需求蔓延。如果直接问 “你想要什么功能”,产品经理会列出 20 个功能。但如果问 “你遇到了什么问题”,他会聚焦在核心痛点上。
假设你回答:
1 | 我想做一个用户权限管理系统,因为当前权限分配太随意,没有审计记录。 |
Analyst 会继续追问:
1 | 很好!让我们深入挖掘一下: |
这个过程会持续多轮对话,Analyst 会使用不同的创意技巧(从 brain-methods.csv 中加载),确保探索足够深入。
研究:市场与竞品分析
头脑风暴后,如果需要更深入的研究,可以选择 [RS] 启动研究流程:
1 | [RS] 引导式研究 |
Analyst 会启动 _bmad/bmm/workflows/1-analysis/research/workflow.md,引导你进行:
- 市场研究:目标市场规模、趋势、机会
- 竞品分析:主要竞争对手的功能对比
- 技术研究:实现方案的技术可行性
研究结果会保存到 {output_folder}/analysis/research-{date}.md。
创建产品简报
头脑风暴和研究结束后,选择 [PB] 创建产品简报:
1 | [PB] 创建产品简报 |
Analyst 会启动 _bmad/bmm/workflows/1-analysis/create-product-brief/workflow.md 工作流。这个工作流使用 step-file 架构,逐步执行:
步骤 1:初始化
1 | 我将创建一份产品简报,包含以下部分: |
步骤 2-N:逐步构建
工作流会按顺序加载 steps/step-01-init.md、step-02-xxx.md 等文件,每个步骤:
- 读取完整的步骤文件
- 按顺序执行所有指令
- 等待用户输入(如果有菜单)
- 更新文档的 frontmatter 中的
stepsCompleted数组 - 加载下一个步骤文件
关键规则:
- 🛑 绝不 同时加载多个步骤文件
- 📖 总是 在行动前完整读取步骤文件
- 🚫 绝不 跳过步骤或优化顺序
- 💾 总是 在完成步骤后更新 frontmatter
所有步骤完成后,Analyst 会生成一份产品简报:
1 | --- |
这份文档会自动保存到 {output_folder}/planning/product-brief-{date}.md(路径由 config.yaml 中的 planning_artifacts 配置决定)。
派对模式 (Party Mode) 是什么
想象一下——一场多位专家代理齐聚一堂的头脑风暴盛宴!这是一个多代理协作讨论模式,让所有已安装的 BMAD 专家代理们参与进来,各自发挥专长,进行自然流畅的集体对话!
🤖 它如何运作?
- 集结专家团队 — 派对模式会加载所有 BMAD 代理的名单(比如 Mary 是商业分析师,还有产品经理、架构师、开发者、用户体验设计师等各路专家)
- 智能匹配参与 — 根据你提出的话题或问题,系统会智能选择 2-3 位最相关的专家来参与讨论,确保多角度观点的碰撞!
- 角色扮演对话 — 每个代理都会保持自己独特的性格和专业风格,互相引用、补充、甚至辩论,就像真人团队会议一样生动!
- 协作解决问题 — 代理之间可以互相提问、建立共识、深化见解,最终为你提供全面、多维度的分析!
从业务分析的角度看,这就像把跨职能团队的专家们聚集在一张桌子旁——战略分析师、产品人、技术大牛、设计达人齐上阵!不同视角的碰撞往往能发现单一视角无法察觉的机会和风险!🔍✨
3.2. Planning 阶段:PRD 与架构文档的双保险
这个阶段的目标是 把需求翻译成两份文档:PRD(给开发看的功能清单)和架构文档(给开发看的技术约束)。
启动 PM 代理
关闭 Analyst 对话,开启一个新对话,输入:
1 | *agent pm |
或者简写:
1 | *pm |
系统会加载 _bmad/bmm/agents/pm.md 文件,激活产品经理角色(John)。
1 | 📋 主菜单 |
创建 PRD
在 PM 代理的菜单中,选择 [CP] 创建 PRD:
1 | [CP] 创建产品需求文档(PRD) |
PM 会启动 _bmad/bmm/workflows/2-plan-workflows/prd/workflow.md 工作流。这个工作流是 三模态 的:
| 模式 | 触发方式 | 适用场景 |
|---|---|---|
| 创建模式 | create prd 或 -c | 从零开始写 PRD |
| 验证模式 | validate prd 或 -v | 检查现有 PRD 质量 |
| 编辑模式 | edit prd 或 -e | 修改现有 PRD |
如果模式不明确,PM 会询问:
1 | PRD 工作流 - 选择模式: |
创建模式流程:
PM 会按顺序执行 steps-c/step-01-init.md 等步骤文件,引导你:
- 发现输入文档:自动查找产品简报、项目上下文等
- 定义愿景:用一句话描述项目成功后的改变
- 识别用户:主要用户和次要用户
- 拆分 Epic:将需求组织成大的功能模块
- 编写用户故事:为每个 Epic 编写详细的用户故事
- 定义验收标准:每个故事的可测试标准
- 设置优先级:P0/P1/P2 划分
- 定义非功能需求:性能、安全、可用性等
关键步骤示例:
步骤 5:编写用户故事
1 | 让我们为 Epic 1 编写用户故事: |
注意每个 Story 都遵循固定格式:作为 [角色],我需要 [功能],以便 [目标]。
步骤 8:定义非功能需求
1 | 现在让我们定义非功能需求(NFR): |
所有步骤完成后,PM 会生成完整的 PRD,保存到 {planning_artifacts}/prd.md。
验证 PRD 质量
PRD 生成后,不要急着进入下一步。选择 [VP] 运行验证模式:
1 | [VP] 验证产品需求文档(PRD) |
PM 会启动验证流程(steps-v/step-v-01-discovery.md),进行 13 项验证:
- 完整性:所有 Epic 都有对应的 Story 吗?
- 一致性:Story 之间有没有矛盾?
- 可测试性:验收标准是否可验证?
- 优先级:P0/P1/P2 的划分是否合理?
- 可追溯性:每个 Story 是否都能追溯到产品简报?
验证报告会指出问题:
1 | ## 验证报告 |
根据报告修正 PRD,直到所有验证项都通过。
启动 Architect 代理
PRD 验证通过后,关闭 PM 对话,开启新对话:
1 | *agent architect |
或者简写:
1 | *architect |
系统会加载 _bmad/bmm/agents/architect.md 文件,激活架构师角色(Winston)。
1 | 请选择菜单项: |
创建架构文档
在 Architect 代理的菜单中,选择 [CA]:
1 | [CA] 创建架构文档 |
Architect 会启动 _bmad/bmm/workflows/3-solutioning/create-architecture/workflow.md 工作流,这个工作流有多个步骤:
步骤 1:发现输入文档
1 | 我将基于 PRD 创建架构文档。让我先查找相关文档... |
步骤 2-N:逐步设计
工作流会引导你完成:
- 技术栈选择:语言、框架、数据库等
- 系统架构:整体架构图和组件划分
- 数据模型:实体关系和表结构
- API 规范:所有接口的请求/响应格式
- 编码规范:命名约定、错误处理、日志等
- 部署架构:部署方式和基础设施
关键步骤示例:
步骤 2:选择技术栈
1 | 根据需求,我建议以下技术栈: |
这里的关键是 每个选择都要有理由。不是 “我们用 PostgreSQL”,而是 “我们用 PostgreSQL,因为它支持 JSONB,适合存储审计日志的复杂结构”。
步骤 4:设计数据模型
1 | 让我们设计核心数据模型: |
步骤 6:定义 API 规范
1 | 让我们定义 API 规范: |
所有步骤完成后,Architect 会生成完整的架构文档,保存到 {planning_artifacts}/architecture.md。
Planning 阶段的检查清单
在进入下一个阶段前,确认以下问题:
- [ ] PRD 是否通过了验证?
- [ ] 架构文档是否明确了技术栈?
- [ ] 数据模型是否支持所有 Story?
- [ ] API 规范是否完整(包含所有接口)?
- [ ] 编码规范是否明确(命名、错误处理、日志)?
3.3. Solutioning 阶段:Epic 与 Story 的创建
这个阶段的目标是 把 PRD 和架构文档转换成可执行的 Epic 和 Story 文件
在开发尤其是 Agile/敏捷开发 和 Scrum(阶段性冲刺) 中,Epic(史诗) 是一个项目管理术语,而不是一种代码语法
Story 全称是 User Story(用户故事)。它是 Agile 开发中 最小的需求描述单位。
什么叫“故事”而不是“功能”?因为它是 从用户的视角 来描述需求的,而不是从技术的视角。它强调的是 价值。
作为一个 <角色>, 我想要 <执行某个动作>, 以便于 <获得某种价值/解决某个问题>。
| 概念 | 形象比喻 | 关注点 | 典型周期 |
|---|---|---|---|
| Epic | 整部电影 | 宏观愿景、大模块 | 1~3 个月 |
| Story | 电影里的一个场景 | 用户能感知到的功能 | 2~5 天 |
| Task | 摄像机架设/灯光调试 | 具体的执行步骤 | 几小时~1 天 |
| Scrum | 整个剧组的拍摄日程表 | 流程、节奏、协作 | 持续进行 |
创建 Epic 和 Story
继续使用 PM 代理(或重新激活),选择 [ES]:
1 | [ES] 从 PRD 创建 Epic 和用户故事(架构完成后必需) |
PM 会启动 _bmad/bmm/workflows/3-solutioning/create-epics-and-stories/workflow.md 工作流。
步骤 1:验证前置条件
工作流首先检查:
1 | 正在验证前置条件... |
步骤 2-N:逐步创建
工作流会:
- 提取 Epic:从 PRD 中识别所有 Epic
- 创建 Epic 文件:为每个 Epic 生成详细文档
- 提取 Story:从 PRD 中识别所有用户故事
- 创建 Story 条目:将 Story 组织到对应的 Epic 中
- 添加 BDD 场景:为每个 Story 编写 Given-When-Then 场景
- 添加技术任务:为每个 Story 拆分技术实现任务
最终生成的文件结构:
1 | {planning_artifacts}/ |
每个 Epic 文件包含:
1 | # Epic 1: 角色管理 |
实现就绪检查
Epic 和 Story 创建完成后,运行实现就绪检查。可以选择 PM 代理的 [IR] 或 Architect 代理的 [IR]:
给予 PM 【IR】 功能是因为我们在拆分 epic 的时候是 PM 视角拆分的,他可以继续延续上下文进行审查
1 | [IR] 实现就绪审查 |
PM 或 Architect 会启动 _bmad/bmm/workflows/3-solutioning/check-implementation-readiness/workflow.md 工作流,进行 6 项检查:
检查 1:文档一致性
1 | 检查 PRD 和架构文档是否一致... |
检查 2:Story 完整性
1 | 检查 Story 是否完整... |
检查 3:依赖关系
1 | 检查 Story 之间的依赖关系... |
检查 4:技术风险
1 | 识别技术风险... |
检查 5:资源评估
1 | 评估开发资源... |
检查 6:生成检查报告
1 | ## 实现就绪检查报告 |
根据报告修正问题,直到所有检查项都通过。
Solutioning 阶段的检查清单
在进入下一个阶段前,确认以下问题:
- [ ] Epic 和 Story 文件是否已创建?
- [ ] 所有 Story 是否都有完整的验收标准和技术任务?
- [ ] Story 之间的依赖关系是否清晰?
- [ ] 技术风险是否已识别并有应对方案?
- [ ] 实现就绪检查是否通过?
3.4. Implementation 阶段:故事驱动的开发循环
这个阶段的目标是 按 Story 写代码,每个 Story 一个完整的开发-审查循环。
启动 SM 代理
关闭 PM/Architect 对话,开启新对话:
1 | *agent sm |
或者简写:
1 | *sm |
系统会加载 _bmad/bmm/agents/sm.md 文件,激活 Scrum Master 角色(Bob)。
Sprint 规划
首先,选择 [SP] 生成或更新 sprint 状态文件:
1 | [SP] 生成或重新生成 sprint-status.yaml(Epic+Story 创建后必需) |
SM 会启动 _bmad/bmm/workflows/4-implementation/sprint-planning/workflow.yaml 工作流,从 Epic 文件中提取所有 Story,生成 {implementation_artifacts}/sprint-status.yaml:
1 | project_name: "用户权限管理系统" |
这个文件会跟踪所有 Story 的状态:draft → approved → in_progress → review → done。
创建 Story 文件
选择 [CS] 创建下一个 Story 文件:
1 | [CS] 创建 Story(准备 Story 用于开发) |
SM 会启动 _bmad/bmm/workflows/4-implementation/create-story/workflow.yaml 工作流:
- 读取 sprint-status.yaml:找到下一个待开发的 Story
- 加载相关文档:PRD、架构文档、Epic 文件
- 创建 Story 文件:生成详细的 Story 文件,包含:
- Story 描述和验收标准
- BDD 场景
- 技术任务和子任务
- 相关文档引用
- 实现指南
生成的 Story 文件示例:
1 | --- |
Story 文件会保存到 {implementation_artifacts}/{story_key}.md。
启动 Dev 代理
Story 文件创建完成后,关闭 SM 对话,开启新对话:
1 | *agent dev |
或者简写:
1 | *dev |
系统会加载 _bmad/bmm/agents/dev.md 文件,激活开发者角色(Amelia)。
开发 Story
在 Dev 代理的菜单中,选择 [DS]:
1 | [DS] 执行 Dev Story 工作流(完整的 BMM 路径,包含 sprint-status) |
Dev 会启动 _bmad/bmm/workflows/4-implementation/dev-story/workflow.yaml 工作流:
- 读取 Story 文件:加载完整的 Story 文件和相关文档
- 按顺序执行任务:严格按照 Story 文件中的任务顺序执行
- 遵循 TDD 原则:每个任务先写测试,再写实现
- 更新 Story 状态:完成任务后更新 Story 文件中的复选框
关键规则:
- 🛑 绝不 跳过任务或重新排序
- 📖 总是 先读取完整的 Story 文件
- ✅ 总是 先写测试,再写实现
- 💾 总是 完成任务后更新 Story 文件
- 🚫 绝不 在测试失败时继续下一个任务
开发过程示例:
1 | 正在加载 Story 1.1... |
代码审查
Story 开发完成后,选择 [CR] 进行代码审查:
1 | [CR] 执行彻底的代码审查(强烈推荐,使用新上下文和不同 LLM) |
Dev 会启动 _bmad/bmm/workflows/4-implementation/code-review/workflow.yaml 工作流。这个工作流是 对抗性的,会:
- 挑战一切:代码质量、测试覆盖、架构合规、安全性、性能
- 找出问题:每个 Story 必须找出 3-10 个具体问题
- 提供修复建议:可以自动修复(需用户批准)
审查报告示例:
1 | ## 代码审查报告:Story 1.1 |
根据报告修正问题,然后重新提交审查。
循环继续
Story 1.1 完成后,回到 SM 对话:
1 | [CS] 创建 Story |
SM 会根据 sprint-status.yaml 和依赖关系,推荐下一个 Story:
1 | Story 1.1 已完成 ✓ |
重复 SM → Dev → CR 的循环,直到所有 Story 完成。
Implementation 阶段的检查清单
每个 Story 完成后,确认以下问题:
- [ ] 所有验收标准是否已满足?
- [ ] 代码是否通过代码审查?
- [ ] 测试覆盖率是否达标(> 80%)?
- [ ] Story 文件中的任务是否全部完成?
- [ ] Story 状态是否已更新为 Done?
- [ ] sprint-status.yaml 是否已更新?
3.5. 本章总结与完整工作流速查
让我们把四个阶段的操作流程完整串联起来,并给出每个环节的最佳实践建议。****
完整工作流图谱
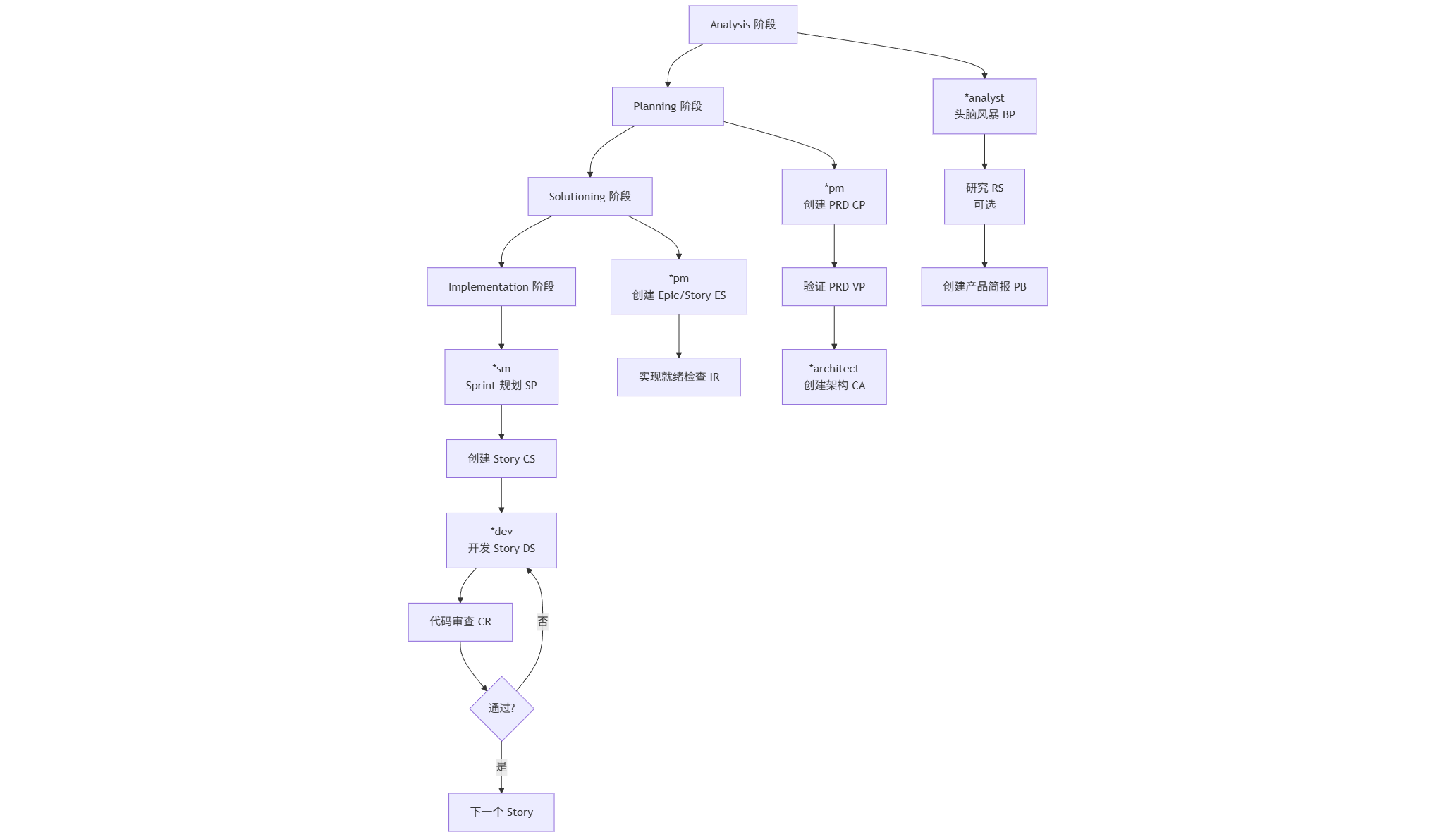
阶段一:Analysis(分析阶段)
目标:把模糊想法变成清晰的产品简报
操作流程:
| 步骤 | 命令 | 说明 | 输出工件 |
|---|---|---|---|
| 1. 激活代理 | *analyst 或 *agent analyst | 激活需求分析师 Mary | - |
| 2. 检查状态 | WS | 查看当前工作流状态(可选) | - |
| 3. 头脑风暴 | BP | 引导式头脑风暴会话 | 头脑风暴记录 |
| 4. 深入研究 | RS | 市场/竞品/技术研究(可选) | 研究报告 |
| 5. 创建简报 | PB | 创建产品简报(6 个步骤) | product-brief-{date}.md |
| 6. 派对模式 | PM | 多代理协作讨论(可选) | - |
关键检查点:
- [ ] 产品简报是否明确了 “为什么要做”?
- [ ] 目标用户是否清晰且完整?
- [ ] 成功指标是否可量化?
- [ ] 范围边界是否明确(包含什么,不包含什么)?
- [ ] 约束条件(时间、预算、技术)是否已识别?
推荐模型:
| 模型 | 推荐理由 | 适用场景 |
|---|---|---|
| Gemini ⭐ | 超大上下文窗口,适合处理大量研究资料;思考模式适合深度分析 | 头脑风暴、研究、产品简报创建 |
| Claude | 理解能力强,擅长结构化输出 | 产品简报创建、派对模式 |
| GPT | 平衡性好,响应速度快 | 头脑风暴、快速迭代 |
为什么推荐 Gemini:Analysis 阶段需要处理大量信息(市场研究、竞品分析、用户访谈),Gemini 的超大上下文窗口可以一次性加载所有资料,避免信息丢失。Thinking 模式能进行深度推理,挖掘隐藏需求。
阶段二:Planning(规划阶段)
目标:把产品简报翻译成 PRD 和架构文档
操作流程:
Part 1:创建 PRD
| 步骤 | 命令 | 说明 | 输出工件 |
|---|---|---|---|
| 1. 激活 PM | *pm 或 *agent pm | 激活产品经理 John | - |
| 2. 检查状态 | WS | 查看当前工作流状态 | - |
| 3. 创建 PRD | CP | 创建模式(12 个步骤) | prd.md |
| 4. 验证 PRD | VP | 验证模式(13 项检查) | 验证报告 |
| 5. 编辑 PRD | EP | 根据验证报告修正(可选) | 更新后的 prd.md |
Part 2:创建架构文档
| 步骤 | 命令 | 说明 | 输出工件 |
|---|---|---|---|
| 1. 激活 Architect | *architect 或 *agent architect | 激活架构师 Winston | - |
| 2. 创建架构 | CA | 创建架构文档(8 个步骤) | architecture.md |
关键检查点:
- [ ] PRD 是否通过了 13 项验证?
- [ ] 所有 Epic 都有对应的 Story 吗?
- [ ] 所有 Story 都有验收标准吗?
- [ ] 非功能需求(NFR)是否明确?
- [ ] 架构文档是否明确了技术栈?
- [ ] 数据模型是否支持所有 Story?
- [ ] API 规范是否完整?
- [ ] 编码规范是否明确?
推荐模型:
| 模型 | 推荐理由 | 适用场景 |
|---|---|---|
| Claude ⭐ | 结构化输出能力最强,擅长编写规范文档;对细节把控严格 | PRD 创建、PRD 验证、架构文档创建 |
| GPT | 平衡性好,适合快速迭代 | PRD 编辑、小幅修正 |
为什么推荐 Claude:Planning 阶段需要输出高质量的结构化文档,Claude 在这方面表现最佳。它能严格遵循模板格式,输出的 PRD 和架构文档条理清晰、逻辑严密。验证模式需要挑刺能力,Claude 的批判性思维更强,而 Gemini1 的幻觉率高,对于这一类需要严苛保证标准的题材,Claude 往往更能发挥出优点
阶段三:Solutioning(方案阶段)
目标:把 PRD 和架构文档转换成可执行的 Epic 和 Story
操作流程:
| 步骤 | 命令 | 说明 | 输出工件 |
|---|---|---|---|
| 1. 激活 PM | *pm | 继续使用 PM 代理 | - |
| 2. 创建 Epic/Story | ES | 从 PRD 提取并创建(4 个步骤) | epics.md + Story 文件 |
| 3. 实现就绪检查 | IR | 6 项检查(可用 PM 或 Architect) | 就绪检查报告 |
关键检查点:
- [ ] 所有 Epic 都有对应的 Story 吗?
- [ ] 所有 Story 都有完整的验收标准吗?
- [ ] 所有 Story 都有技术任务拆分吗?
- [ ] 所有 Story 都有 BDD 场景吗?
- [ ] Story 之间的依赖关系是否清晰?
- [ ] 技术风险是否已识别并有应对方案?
- [ ] PRD 和架构文档是否一致?
推荐模型:
| 模型 | 推荐理由 | 适用场景 |
|---|---|---|
| Claude 3.5 Sonnet ⭐ | 擅长任务拆解和依赖分析;对抗性审查能力强 | Epic/Story 创建、实现就绪检查 |
| Gemini 2.0 Flash Thinking | 思考深度好,适合风险识别 | 实现就绪检查、技术风险评估 |
为什么推荐 Claude:Solutioning 阶段需要精细的任务拆解能力,Claude 能准确识别 Story 之间的依赖关系,避免遗漏。实现就绪检查需要对抗性思维,Claude 的批判性更强,能发现潜在问题。
阶段四:Implementation(实现阶段)
目标:按 Story 写代码,每个 Story 一个完整的开发-审查循环
操作流程:
Part 1:Sprint 规划(SM)
| 步骤 | 命令 | 说明 | 输出工件 |
|---|---|---|---|
| 1. 激活 SM | *sm 或 *agent sm | 激活 Scrum Master Bob | - |
| 2. Sprint 规划 | SP | 生成 sprint-status.yaml | sprint-status.yaml |
| 3. 创建 Story | CS | 创建下一个 Story 文件 | {story_key}.md |
Part 2:开发 Story(Dev)
| 步骤 | 命令 | 说明 | 输出工件 |
|---|---|---|---|
| 1. 激活 Dev | *dev 或 *agent dev | 激活开发者 Amelia | - |
| 2. 开发 Story | DS | 按任务顺序开发(TDD) | 代码 + 测试 |
| 3. 代码审查 | CR | 对抗性审查(强烈推荐) | 审查报告 |
| 4. 修正问题 | 根据审查报告修正 | 重新提交审查 | 修正后的代码 |
Part 3:循环继续
重复 SM → Dev → CR 的循环,直到所有 Story 完成。
关键检查点:
- [ ] sprint-status.yaml 是否已生成?
- [ ] Story 文件是否包含完整的技术任务?
- [ ] 是否严格按照任务顺序开发?
- [ ] 是否遵循 TDD 原则(先写测试)?
- [ ] 所有验收标准是否已满足?
- [ ] 代码是否通过审查?
- [ ] 测试覆盖率是否达标(> 80%)?
- [ ] Story 状态是否已更新为 Done?
推荐模型:
| 模型 | 推荐理由 | 适用场景 |
|---|---|---|
| Claude 后端 ⭐ | 代码质量最高,遵循规范能力强;代码审查最严格 | Story 开发、代码审查 |
| Gemini 前端 ⭐ | 思考深度好,适合复杂逻辑;上下文大,适合大型代码库 | 复杂 Story 开发、架构级重构 |
| GPT(审查) ⭐ | 思考链强大,往往能找到更准确的系统漏洞 | 系统复杂对抗 |
为什么推荐 Claude + Gemini 双模型:
- Claude:代码质量最高,严格遵循架构文档和编码规范。代码审查时批判性最强,能发现细微问题。适合 80% 的常规 Story。
- Gemini Thinking:思考深度更好,适合复杂的算法逻辑、性能优化、架构级重构。超大上下文适合处理大型代码库。适合 20% 的复杂 Story。
双模型协作策略:
- 常规 Story:用 Claude 开发 + Claude 审查
- 复杂 Story:用 Gemini Thinking 开发 + Claude 审查
- 架构级重构:用 Gemini Thinking 开发 + Gemini Thinking 审查
角色切换的黄金法则
规则 1:必须在新对话中切换角色
❌ 错误做法:
1 | 你:*analyst |
✅ 正确做法:
1 | 对话 1: |
为什么:防止角色污染。同一对话中切换角色,AI 的上下文会混杂两个角色的思维方式,导致输出质量下降。
规则 2:必须保存工件后再切换
❌ 错误做法:
1 | Analyst:我已经完成头脑风暴... |
✅ 正确做法:
1 | Analyst:我已经完成头脑风暴... |
为什么:工件是阶段之间的信息传递媒介。如果不保存工件,下一个阶段的代理无法获取前一个阶段的输出。
规则 3:必须通过检查点才能进入下一阶段
❌ 错误做法:
1 | PM:PRD 已创建 |
✅ 正确做法:
1 | PM:PRD 已创建 |
为什么:每个检查点都是质量门槛。跳过检查点,问题会累积到后期,导致大量返工。
规则 4:必须使用正确的菜单命令
❌ 错误做法:
1 | 你:请执行 _bmad/bmm/workflows/2-plan-workflows/prd/workflow.md |
✅ 正确做法:
1 | 你:*pm |
为什么:菜单命令会自动处理前置条件检查、文件路径解析、配置加载等。直接调用工作流文件可能导致路径错误或配置缺失。
常见错误与纠正
| 错误 | 后果 | 正确做法 | 检测方法 |
|---|---|---|---|
| 跳过 Analysis 直接写 PRD | 需求不清晰,后期频繁返工 | 必须先用 Analyst 明确需求 | PRD 中出现大量 “待定” 或 “可选” |
| PRD 未验证就进入开发 | 文档质量差,开发时发现问题 | 必须运行 VP 验证 PRD | 开发时频繁回头修改 PRD |
| 不创建架构文档直接开发 | 技术选型混乱,代码风格不一致 | 必须用 Architect 创建架构文档 | 代码中出现多种技术栈混用 |
| 跳过实现就绪检查 | Story 不完整,依赖关系混乱 | 必须运行 IR 检查 | 开发时发现 Story 缺少关键信息 |
| 不创建 Story 文件直接开发 | 任务不清晰,容易遗漏 | 必须用 SM 创建 Story 文件 | 开发时不知道该做什么 |
| 跳过代码审查直接合并 | 代码质量无保障 | 必须通过 CR 审查 | 上线后出现大量 Bug |
| 不更新 sprint-status.yaml | Story 状态混乱,进度不可追踪 | SM 会自动更新,但需确认 | 不知道哪些 Story 已完成 |
| 在同一对话中切换角色 | 角色污染,输出质量下降 | 必须在新对话中切换 | 代理开始做不属于它的事 |
自检清单
每个阶段结束时,问自己:
Analysis 阶段:
- [ ] 产品简报是否已保存到
{planning_artifacts}/product-brief-{date}.md? - [ ] 产品简报是否明确了目标用户、核心问题、成功指标?
- [ ] 是否进行了必要的研究(市场/竞品/技术)?
Planning 阶段:
- [ ] PRD 是否已保存到
{planning_artifacts}/prd.md? - [ ] PRD 是否通过了
VP验证(13 项检查)? - [ ] 架构文档是否已保存到
{planning_artifacts}/architecture.md? - [ ] 架构文档是否明确了技术栈、数据模型、API 规范、编码规范?
Solutioning 阶段:
- [ ] Epic 和 Story 是否已保存到
{planning_artifacts}/epics.md? - [ ] 所有 Story 是否都有验收标准、BDD 场景、技术任务?
- [ ] 是否通过了
IR实现就绪检查(6 项检查)?
Implementation 阶段:
- [ ] sprint-status.yaml 是否已生成?
- [ ] 每个 Story 是否都有独立的 Story 文件?
- [ ] 每个 Story 是否都通过了代码审查?
- [ ] 测试覆盖率是否达标(> 80%)?
- [ ] sprint-status.yaml 中的 Story 状态是否已更新为 Done?
快速命令速查表
| 代理 | 激活命令 | 常用菜单命令 | 说明 |
|---|---|---|---|
| Analyst | *analyst | BP 头脑风暴RS 研究PB 产品简报 | 需求分析 |
| PM | *pm | CP 创建 PRDVP 验证 PRDEP 编辑 PRDES 创建 Epic/StoryIR 实现就绪检查 | 产品管理 |
| Architect | *architect | CA 创建架构IR 实现就绪检查 | 架构设计 |
| SM | *sm | SP Sprint 规划CS 创建 Story | 迭代管理 |
| Dev | *dev | DS 开发 StoryCR 代码审查 | 开发实现 |
通用命令:
WS:查看工作流状态(所有代理通用)PM:启动派对模式(所有代理通用)MH:重新显示菜单(所有代理通用)DA:解除代理(所有代理通用)
最后的建议
1. 不要急于求成
BMAD 的价值在于 减少返工,而不是 加快初始速度。前期在文档上多花的时间,会在后期以 “避免返工” 的形式百倍偿还,一个模型可能跑的比较旧,我们在后续的篇章中会推出更强大的公族流,并行执行多个模型进行工作,互相获取上下文并行工作…
2. 严格遵循流程
不要跳过任何检查点。每个检查点都是质量门槛,跳过一个,问题就会累积到下一个阶段。
3. 善用派对模式
当你对某个决策不确定时,启动派对模式(PM),让多个代理从不同角度讨论。这能避免单一视角的盲点。
4. 定期回顾工件
每完成一个阶段,回头看看之前的工件(产品简报、PRD、架构文档)。如果发现不一致,立即修正,不要拖到后期。
5. 记录技术债务
代码审查时发现的 “重构建议”,即使暂时不修复,也要记录到技术债务清单中。定期回顾和偿还技术债务。






