
Prorise
这是我的博客,分享技术与生活的点点滴滴
第十章. common-core 工具类(八):AddressUtils 与 RegionUtils 详解
第十章. common-core 工具类(八):AddressUtils 与 RegionUtils 详解
Prorise第十章. common-core 工具类(八):AddressUtils 与 RegionUtils 详解
摘要:本章我们将深入 RVP 的 IP 地址定位功能。我们将分析 AddressUtils(门面)和 RegionUtils(实现)的职责分离设计。重点是 RegionUtils 如何通过 静态代码块 加载 ip2region.xdb 离线库到内存,以及 RVP 5.x 版本(对比 4.x)在 资源加载方式上的演进。
在上一章中,我们深入剖析了 SqlUtil,并通过追踪 RVP 真实应用场景 PageQuery 的源码,理解了它在 MyBatis-Plus (MP) 体系下,作为“原生 ORDER BY 字符串校验器”的真实用途和存在价值。
现在,我们来看 utils 包下一个非常有用的功能模块——IP 地址与地理位置定位。在 RVP 中,这个功能被拆分为了两个类,位于 common-core 的 utils.ip 包下:
AddressUtils:一个“门面”工具类,负责 业务逻辑判断(如判断内网 IP、IPv4/IPv6)。RegionUtils:一个“实现”工具类,负责 真正的数据查询,它封装了ip2region.xdb离线库。
本章,我们将重点分析 RVP(V5.x 版本)是如何 重构 IP 地址库的加载机制的,以及“二开”时我们该如何正确使用它们。
本章学习路径
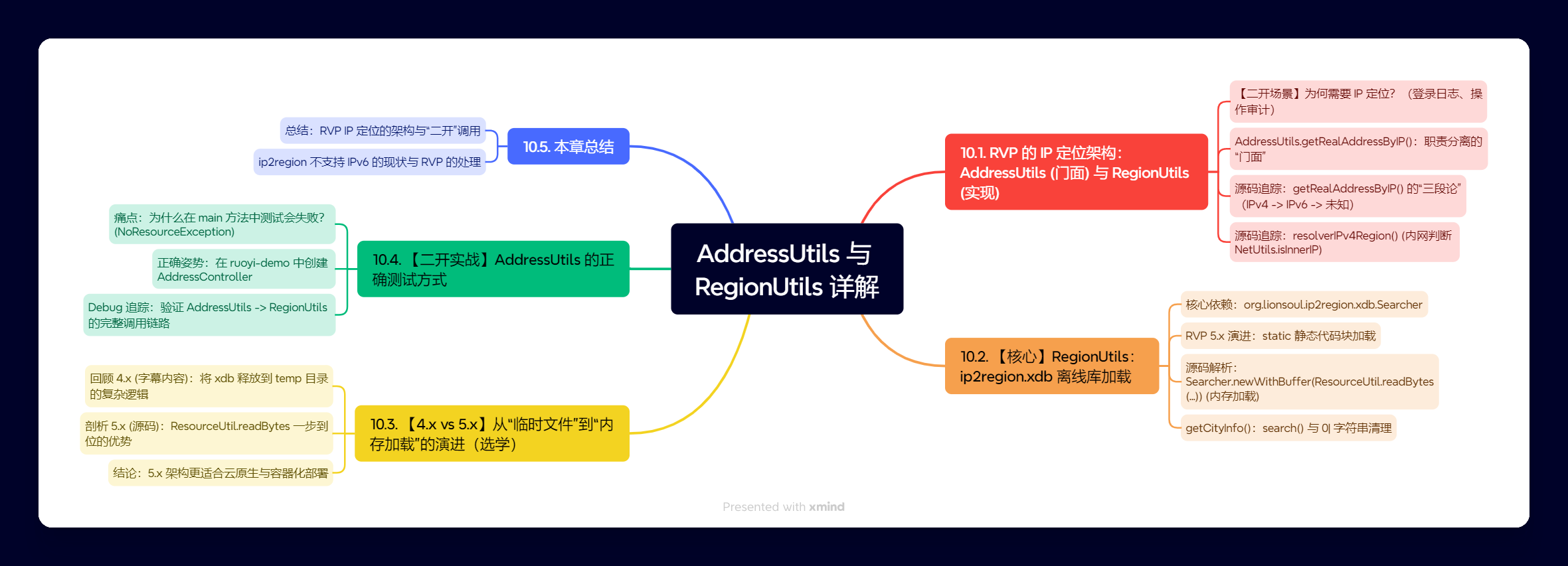
10.1. RVP 的 IP 定位架构:AddressUtils (门面) 与 RegionUtils (实现)
10.1.1. 【二开场景】为何需要 IP 定位?
在任何一个严谨的后台管理系统中,“审计”都是必不可少的功能。我们需要记录“谁,在什么时间,从哪里,做了什么”。
- 登录日志:记录用户登录的 IP 地址及其地理位置。
- 操作日志:记录用户执行关键操作(如删除、修改)时的 IP 地址。
AddressUtils 和 RegionUtils 的核心使命,就是完成“从哪里”这个环节,即:根据 IP 地址,解析出真实的地理位置。
10.1.2. AddressUtils.getRealAddressByIP():职责分离的“门面”
在 RVP 框架中,我们“二开”时,唯一应该调用的就是 AddressUtils.getRealAddressByIP(ip)。
AddressUtils 扮演了一个“门面”(Facade)的角色。它负责处理所有前置的业务逻辑判断,而不关心数据到底是怎么查出来的。
文件路径:ruoyi-common/ruoyi-common-core/src/main/java/org/dromara/common/core/utils/ip/AddressUtils.java
1 |
|
10.1.3. 源码追踪:getRealAddressByIP() 的“三段论”
getRealAddressByIP 的逻辑非常清晰,是一个“三段论”:
- 预处理:使用
HtmlUtil.cleanHtmlTag防止 XSS 攻击,使用blankToDefault处理null。 - IP 类型判断:使用 Hutool 的
NetUtils.isIPv4和NetUtils.isIPv6进行分发。 - 委托处理:IPv4 交给
resolverIPv4Region,IPv6 交给resolverIPv6Region。
10.1.4. 源码追踪:resolverIPv4Region() (内网判断 NetUtils.isInnerIP)
resolverIPv6Region 目前只是简单返回“未知”,因为 ip2region 库不支持 IPv6。所以,核心逻辑全在 resolverIPv4Region 中。
1 | // 位于 AddressUtils.java |
分析:AddressUtils 的职责非常明确。它利用 Hutool 的 NetUtils.isInnerIP (判断 127.0.0.1, 10.x.x.x, 192.168.x.x 等),过滤掉了所有内网 IP。
为什么要这样做?
因为 ip2region.xdb 离线库里只包含 公网 IP 的地理信息。查询一个内网 IP 是毫无意义且浪费性能的。
只有当 AddressUtils 确认这是一个公网 IPv4 地址时,它才会把“查询”这个“脏活累活”交给 RegionUtils.getCityInfo(ip) 去做。
10.2. 【核心】RegionUtils:ip2region.xdb 离线库加载
RegionUtils 是实际的“实现”类。它封装了 ip2region 这个第三方离线 IP 定位库。
10.2.1. 核心依赖:org.lionsoul.ip2region.xdb.Searcher
ip2region 库的使用非常简单,核心就是 Searcher (查询器) 对象。
10.2.2. RVP 5.x 演进:static 静态代码块加载
在 RVP 5.x 版本中,RegionUtils 的源码发生了重大变化(我们将在 10.3 节对比 4.x)。我们来看 5.x 的源码:
文件路径:ruoyi-common/ruoyi-common-core/src/main/java/org/dromara/common/core/utils/ip/RegionUtils.java
1 |
|
10.2.3. 源码解析:Searcher.newWithBuffer(ResourceUtil.readBytes(...))
static { ... } (静态代码块) 会在 RegionUtils 类 第一次被加载到 JVM 时 执行,且 只执行一次。
ResourceUtil.readBytes(IP_XDB_FILENAME):ResourceUtil是 Hutool 的工具类。- 它会从 项目的 ClassPath(即
ruoyi-admin/src/main/resources目录)中查找ip2region.xdb文件。 readBytes将这个 11MB 左右的文件 完整地读取到内存中的一个byte[]字节数组 里。
Searcher.newWithBuffer(bytes):- 这是
ip2region库提供的“基于内存的查询”模式。 - 它告诉
Searcher:“不要去读硬盘,以后所有查询都 直接访问内存中的bytes数组。”
- 这是
这种“内存加载”模式有什么好处?
- 高性能:后续所有查询都是“内存查询”,速度极快,远胜于“文件查询”。
- 无状态:不需要在服务器硬盘上读写临时文件(我们将在 10.3 对比)。
10.2.4. getCityInfo():search() 与 0| 字符串清理
RegionUtils 剩下的 getCityInfo 方法就非常简单了:
1 | // 位于 RegionUtils.java |
分析:ip2region 库返回的原始格式是 国家|区域|省份|城市|ISP,中间可能包含 0(代表“无”)。RVP 通过 replace 将 0| 和 |0 去掉,使返回结果更干净。
10.3. 【4.x vs 5.x】从“临时文件”到“内存加载”的演进
我们如果打开旧版本源码(即 4.x 版本)中看到的 RegionUtils 加载逻辑,和 5.x 的源码 完全不同。
10.3.1. 回顾 4.x:将 xdb 释放到 temp 目录的复杂逻辑
在 RVP 4.x 中,static 代码块的逻辑是这样的(伪代码):
1 | // RVP 4.x 的“临时文件”加载逻辑 (Bad Practice) |
10.3.2. 剖析 5.x:newWithBuffer 一步到位的优势
对比 4.x 的“临时文件”方式,5.x 的“内存加载”方式(newWithBuffer)优势巨大:
| 对比项 | RVP 4.x (newWithFileOnly) | RVP 5.x (newWithBuffer) |
|---|---|---|
| 工作模式 | 文件 IO:resources -> 复制到 temp -> Searcher 读 temp 文件 | 内存 IO:resources -> 加载到 byte[] -> Searcher 读内存 |
| 性能 | 差。依赖磁盘 IO。 | 极高。纯内存操作。 |
| 部署 | 依赖 temp 目录的 写权限。 | 无文件依赖。 |
| 容器化 | 极差。在只读文件系统(如 Docker ro 挂载)或无状态容器中会 失败。 | 极好。byte[] 在 JVM 堆内存中,与宿主机文件系统无关。 |
10.3.3. 结论:5.x 架构更适合云原生与容器化部署
RVP 5.x 对 RegionUtils 的重构(从 newWithFileOnly 升级到 newWithBuffer)是一个 巨大进步。它摒弃了对操作系统的文件依赖,使应用 无状态化,这在当今的 云原生和容器化(Docker/K8s)部署 环境中是至关重要的。
10.4. 【二开实战】AddressUtils 的正确测试方式
10.4.1. 痛点:为什么在 main 方法中测试会失败?(NoResourceException)
在 5.x 架构下,RegionUtils 依赖 ResourceUtil.readBytes("ip2region.xdb") 从 Classpath 加载资源。
如果我们尝试在 ruoyi-demo 模块中用 main 方法测试:
1 | // 位于 ruoyi-demo/utils/test/AddressTest.java |
失败原因:ip2region.xdb 文件位于 ruoyi-admin/src/main/resources 目录下。当我们 独立运行 AddressTest.main 时,JVM 的 Classpath 只包含 ruoyi-demo,它根本“看”不到 ruoyi-admin 里的资源文件,因此 ResourceUtil 抛出 NoResourceException(找不到资源异常)。
10.4.2. 正确姿势:在 ruoyi-demo 中创建 AddressController
如何让 ResourceUtil 找到 .xdb 文件?
我们必须 启动完整的 RVP 应用(DromaraApplication),因为 ruoyi-admin 模块 依赖 了 ruoyi-common-core,并且它 拥有 ip2region.xdb 资源。
所以,正确的测试姿势是创建一个 Controller 接口:
文件路径:ruoyi-modules/ruoyi-demo/src/main/java/org/dromara/demo/controller/AddressController.java
1 | package org.dromara.demo.controller; |
验证:
- 启动
DromaraApplication。 - 在浏览器中访问
http://localhost:8080/demo/addr/addr。 - 查看后端控制台:测试成功!
1
2
3
4... INFO ... --- 开始测试 IP 地址 ---
... INFO ... 【127.0.0.1】=> 内网IP
... INFO ... 【10.0.0.1】=> 内网IP
... INFO ... 【61.145.18.18】=> 中国|广东省|江门市|电信
10.4.3. Debug 追踪:验证 AddressUtils -> RegionUtils 的完整调用链路
我们可以通过 Debug 来验证 RVP 5.x 的加载流程:
- 在
RegionUtils的static代码块第一行(try { ... })打上断点。 - 在
AddressUtils.resolverIPv4Region的第一行打上断点。 - 【关键】:重启
DromaraApplication,并使用 Debug 模式 启动。 - 第一次启动:程序会 立即暂停 在
RegionUtils的static代码块断点处。这证明了SEARCHER是在 Spring Boot 启动时 随类加载而初始化 的。按F8(Resume) 继续。 - 启动完成后,访问
http://localhost:8080/demo/addr/addr。 - 程序会暂停在
AddressUtils.resolverIPv4Region。 - 【关键】:重启
DromaraApplication(非 Debug 模式)。 - 启动完成后,再次访问
http://localhost:8080/demo/addr/addr。 - (
static断点不会再触发) 程序只会暂停在AddressUtils.resolverIPv4Region。 - 结论:
static代码块在 JVM 的生命周期中只执行一次,SEARCHER对象被成功初始化并缓存在内存中,供后续所有请求使用。
10.5. 本章总结
10.5.1. 总结:RVP IP 定位的架构与“二开”调用
本章我们深入了 RVP 的 IP 定位功能,其架构设计高度解耦:
AddressUtils(门面):作为“二开”的 唯一入口。它负责业务逻辑(过滤null、区分 IPv4/IPv6、拦截内网 IP)。RegionUtils(实现):负责数据查询。RVP 5.x 采用 静态代码块,通过ResourceUtil.readBytes+Searcher.newWithBuffer将ip2region.xdb一次性加载到内存,实现了高性能、无状态的查询。
10.5.2. ip2region 不支持 IPv6 的现状与 RVP 的处理
我们必须注意到 AddressUtils.resolverIPv6Region() 中的源码:
1 | private static String resolverIPv6Region(String ip){ |
ip2region(xdb 格式)目前不支持 IPv6。RVP 在此处做了 降级处理:如果是公网 IPv6,则记录一条警告日志并直接返回“未知”,避免了不必要的查询。






