
Prorise
这是我的博客,分享技术与生活的点点滴滴
对象映射架构:从 MapStruct 到 MapStruct Plus 的进化之路
对象映射架构:从 MapStruct 到 MapStruct Plus 的进化之路
Prorise第一章. MapStruct:核心环境构建与基础映射配置
摘要:本章将从企业级开发中“对象转换”的真实痛点切入,深入探讨为何我们需要 MapStruct 取代传统的 Getter/Setter 和 BeanUtils。我们将完成环境搭建,彻底解决 Lombok 编译冲突,理清与 MyBatis 的注解混淆,并通过一个包含嵌套属性的实战案例,完成从配置到源码审计的完整闭环。
本章学习路径
- 痛点分析:理解在分层架构中,手动转换对象的维护成本与反射工具的性能隐患。
- 技术选型:深度对比 MapStruct 与 BeanUtils,理解“编译时生成”的核心优势。
- 环境治理:正确配置 Maven 依赖,深入理解 Lombok 与 MapStruct 的 AST 资源竞争问题。
- 概念辨析:彻底厘清
org.mapstruct.Mapper(转换) 与org.apache.ibatis.annotations.Mapper(持久化) 的区别。 - 深度实战:编写第一个 Mapper 接口,实战 “点号导航” 语法处理嵌套对象。
1.1. 数据隔离的规范与实体转换的代价
在构建企业级 Spring Boot 应用时,我们通常遵循严格的分层架构规范。数据库层的实体(Entity/DO)与传输层的对象(DTO/VO)必须进行物理隔离。
这种隔离虽然保证了架构的安全性与解耦,但也带来了一个巨大的开发痛点:我们需要频繁地在不同对象之间搬运数据。
1.1.1. 手动转换的维护成本
假设我们有一个包含 50 个字段的 UserEntity,需要转换为返回给前端的 UserVO。在最原始的开发模式中,我们必须编写冗长的赋值代码。
这种纯手工的 Getter/Setter 也就是我们常说的“硬编码”,它存在两个显著问题:
- 代码冗余:业务逻辑中充斥着大量的机械性赋值代码,掩盖了核心业务流程。
- 维护脆弱:一旦实体类新增或修改了字段名,编译器不会提示我们去修改转换方法,导致转换逻辑静默失效,往往要等到运行时数据缺失才能发现。
1.1.2. 反射工具的性能隐患
为了偷懒,很多开发者会转向 Spring BeanUtils 或 Apache BeanUtils 这样的工具类。它们通过一行代码即可完成属性拷贝:
1 | BeanUtils.copyProperties(source, target); |
看起来很美好,但这种基于**运行时反射(Reflection)**的实现方式在生产环境中是巨大的隐形炸弹:
- 性能损耗:反射需要在运行时动态解析类的元数据,在大数据量或高并发场景下,CPU 占用率会显著上升。
- 类型不安全:它无法在编译期检查属性类型是否兼容。如果源字段是
String,目标字段是Integer,它可能会在运行时抛出异常或静默失败。 - 调试困难:由于是黑盒调用,一旦数据转换出错,我们很难快速定位是哪个字段出了问题。
1.2. MapStruct:编译时代码生成的革命
基于上述痛点,MapStruct 应运而生。它不是一个简单的工具库,而是一个基于 JSR-269 (Pluggable Annotation Processing API) 规范的 Java 注解处理器。
1.2.1. 核心工作机制
与 BeanUtils 在“运行时”通过反射干活不同,MapStruct 在 “编译时” 就已经完成了工作。它会扫描我们定义的接口,分析源对象和目标对象的结构,然后自动生成纯 Java 的实现类代码。
也就是说,MapStruct 帮我们在编译阶段就把那 50 行 Getter/Setter 代码写好了。
1.2.2. 技术方案深度对比
为了更直观地理解技术选型的依据,我们将三种主流方案进行多维度对比:
| 维度 | 手动 Getter/Setter | BeanUtils (反射) | MapStruct (编译时生成) |
|---|---|---|---|
| 性能 | 极高 (原生调用) | 低 (反射开销) | 极高 (原生调用) |
| 类型安全 | 安全 (编译检查) | 不安全 (运行时报错) | 安全 (编译检查) |
| 开发效率 | 低 (重复劳动) | 高 (一行代码) | 极高 (注解驱动) |
| 调试难度 | 容易 | 困难 (黑盒) | 容易 (可查看生成代码) |
| 错误发现 | 编码时 | 运行时 | 编译时 |
通过对比可见,MapStruct 完美结合了“手动写代码的高性能”与“工具库的高效率”,是目前 Java 生态中对象映射的最佳实践。
1.3. 环境构建与依赖治理
既然明确了 MapStruct 的优势,接下来我们在 Spring Boot 脚手架中引入它。这里有一个至关重要的配置细节——Lombok 冲突,如果处理不当,会导致项目编译失败,请根据下图快速搭建一个 Springboot 脚手架
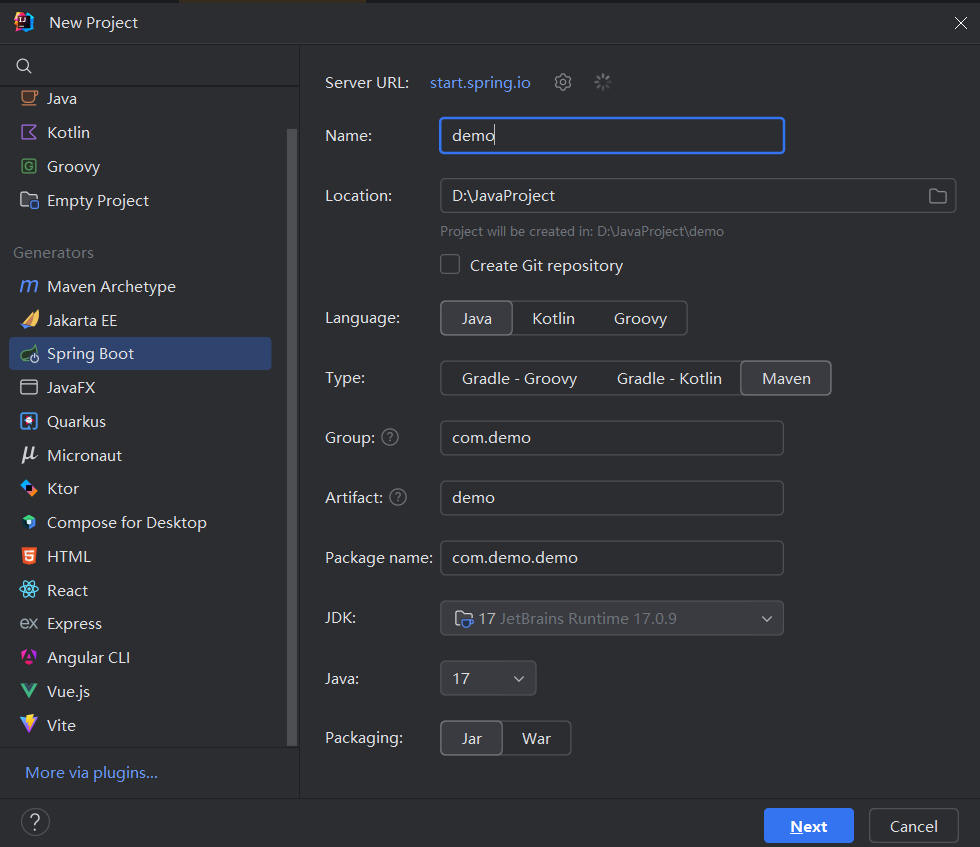
1.3.1. 核心依赖引入
MapStruct 的架构设计为 “API 与实现分离”:
mapstruct:核心库,包含@Mapper,@Mapping等注解,需要在运行期存在。mapstruct-processor:注解处理器,只在编译期工作,负责生成代码。
文件路径:pom.xml
我们需要在项目的依赖管理文件中添加以下配置(版本以 2025 年稳定版为例):
1 | <properties> |
1.3.2. 编译插件配置:解决 AST 竞争
这是新手最容易踩坑的环节。Lombok 和 MapStruct 的工作原理存在天然的时序依赖:
- Lombok:修改 抽象语法树 (AST),动态织入
get/set方法。 - MapStruct:读取 AST 中的
get/set方法,根据属性名生成映射代码。
核心冲突:如果 MapStruct 先于 Lombok 执行,它读取到的 AST 中还没有 get/set 方法,因此会认为属性不可读写,抛出 No property named 'xxx' found 错误。
解决方案:在 maven-compiler-plugin 的 annotationProcessorPaths 中,显式指定 Lombok 在前,MapStruct 在后。
文件路径:pom.xml -> <build><plugins>
1 | <plugin> |
1.4. Mapper 接口的基础定义与组件模型
配置好环境后,我们需要定义映射接口。这里存在一个极易混淆的概念,必须优先厘清。
1.4.1. 关键辨析:MapStruct @Mapper vs MyBatis @Mapper
在实际开发中,DAO 层(持久层)和 Converter 层(转换层)都会用到 @Mapper 注解。
| 特性 | MapStruct @Mapper | MyBatis / MyBatis-Plus @Mapper |
|---|---|---|
| 全限定名 | org.mapstruct.Mapper | org.apache.ibatis.annotations.Mapper |
| 作用 | 代码生成器。标记该接口需要生成 Bean 转换的实现类。 | 动态代理。标记该接口是 MyBatis 的 DAO,需要生成 SQL 执行代理。 |
| 生效阶段 | 编译期 (Compile Time) | 运行时 (Runtime) |
| 常用位置 | convert / mapper 包 (需物理隔离) | mapper / dao 包 |
特别注意:在编写代码导包时,请务必看清包名。如果给转换接口误加了 MyBatis 的注解,项目启动时会报错 “Invalid bound statement (not found)”;反之则无法生成转换代码。
1.4.2. ComponentModel 组件模型详解
MapStruct 生成的实现类如何被调用?这取决于 componentModel 属性的配置。
- 默认模式 (
default):生成普通 Java 类,需要通过Mappers.getMapper()工厂获取,适合工具类场景。 - Spring 模式 (
spring):生成带@Component注解的类,自动纳入 Spring IoC 容器,适合业务开发。
我们一般会在对应的转换 类 接口头上加上以上的注解作为区分
1 |
|
1.5. 深度映射实战:嵌套对象与异名属性
我们将通过一个包含“嵌套对象”和“异名属性”的场景,演示 MapStruct 的核心映射能力。我们将模拟一个用户查询接口,将数据库实体 UserEntity 转换为前端展示对象 UserVO。
1.5.1. 准备实体对象
为了演示深度映射,我们在 UserEntity 中嵌套一个 Address 对象,并尝试将其扁平化映射到 UserVO 中。
文件路径:src/main/java/com/example/demo/entity/UserEntity.java
1 | package com.example.demo.entity; |
文件路径:src/main/java/com/example/demo/vo/UserVO.java
1 | package com.example.demo.vo; |
1.5.2. 编写 Mapper 接口
文件路径:src/main/java/com/example/demo/convert/UserMapper.java
注意,为了区分企业常用的 mapper 文件夹,我们放在 convert 包下
1 | package com.example.demo.convert; |
1.5.3. 生成代码审计
执行 mvn compile 后,我们查看 target/generated-sources/annotations/com/example/demo/convert/UserMapperImpl.java。
1 | // 1. 自动生成了 Spring 组件注解和编译信息注解 |
通过这段生成的代码,我们可以清晰地看到 MapStruct 的优势:它不仅仅是赋值,它还自动帮我们处理了嵌套对象的空指针检查 (NPE Protection)。这是使用反射工具类极难实现的防御性编程细节。
1.6. 本章总结与最佳实践指南
本章我们完成了 MapStruct 从“理论认知”到“落地实战”的完整闭环。为了便于日后快速查阅与复盘,我们将核心知识点提炼为以下三个维度:架构原理、配置红线 与 语法速查。
1.6.1. 核心架构原理回顾
为什么我们坚决选择 MapStruct 而非 BeanUtils?请记住以下三个大点:
- 执行时机:MapStruct 是 编译期 工具,它像一个勤奋的程序员,在代码编译时帮你写好了实现类。BeanUtils 是 运行期(Runtime) 工具,依赖反射动态解析。
- 性能差异:由于 MapStruct 生成的是纯 Getter/Setter 调用,其性能等同于手写代码(原生的 100% 速度);而反射机制通常有 10-50 倍的性能损耗。
- 安全机制:
- 类型安全:字段类型不匹配(如 String 转 Integer),MapStruct 在编译时就会报错中断,防止 Bug 上线。
- 空指针防御:MapStruct 自动生成的代码包含层层判空逻辑(如
if (entity.getAddress() != null)),这是反射工具无法做到的。
1.6.2. 关键配置“红线”检查清单
在项目初期或新环境搭建遇到问题时,请优先检查以下三条“红线”。90% 的 MapStruct 编译错误都源于此:
| 检查项 | 关键细节 | 错误表现 |
|---|---|---|
| AST 处理顺序 | 在 pom.xml 插件配置中,Lombok 必须在 MapStruct 之前。 | 报错 No property named "xxx" found,因为 MapStruct 看不到 Lombok 生成的 Getter 方法。 |
| 注解包路径 | 必须引入 org.mapstruct.Mapper,严禁引入 MyBatis 的 org.apache.ibatis...。 | 项目启动报错 Invalid bound statement (not found),或者根本没有生成实现类。 |
| 组件模型 | 必须配置 componentModel = "spring"。 | 在 Service 层注入 Mapper 时报错 Could not autowire. No beans of 'UserMapper' type found。 |
1.6.3. 基础语法速查手册
当你在开发中需要快速实现映射时,可以使用以下速查表:
1. 开启映射器
1 | // 必选:标记接口,并纳入 Spring 容器管理 |
2. 字段映射规则 (@Mapping)
| 场景 | 语法示例 | 说明 |
|---|---|---|
| 同名属性 | (无需配置) | 字段名和类型一致时,自动映射。 |
| 异名属性 | @Mapping(source = "addr", target = "address") | 将源对象的 addr 赋值给目标的 address。 |
| 嵌套提取 | @Mapping(source = "user.role.name", target = "roleName") | 点号导航。自动处理 user 和 role 的判空,直接提取 name。 |
| 忽略字段 | @Mapping(target = "password", ignore = true) | 不映射该目标字段(常用于敏感信息过滤)。 |
| 格式化 | @Mapping(source = "date", dateFormat = "yyyy-MM-dd") | 自动将日期对象格式化为字符串。 |
第二章. MapStruct:字段级映射策略与数据处理
摘要:在完成了环境搭建与基础映射后,本章我们将进入 MapStruct 的深水区。面对真实业务中复杂的“脏数据”和严格的格式要求,我们将深入掌握空值防御、常量注入、Java 表达式嵌入以及高精度的数值/日期格式化。同时,我们将构建真实的 Web 接口,通过 Postman 实测来验证反向映射与敏感字段脱敏策略,彻底解决“DTO 到 Entity”的数据回流难题。
本章学习路径
- 空值防御体系:通过
defaultValue、constant和expression构建三级防御机制,杜绝 NPE(空指针异常)。 - 高级表达式:在映射中嵌入 Java 代码与依赖导入,解决动态值生成问题。
- 格式化与隐式转换:掌握
BigDecimal货币精度控制与LocalDateTime的双向格式化,剖析框架内部的隐式转换表。 - 反向继承实战:利用
@InheritInverseConfiguration实现高效的“数据回流”,并配合ignore完成安全脱敏。 - 闭环验证:编写
Controller接口,结合 Postman 与源码断点,验证所有策略的运行时表现。
2.1. 默认值与常量控制策略
在上一章的实战中,我们留下了两个悬念:UserVO 中的 statusDesc 为 null,且我们需要为前端返回一个固定的业务来源标识。在企业级开发中,数据库中的数据往往是不完整的,或者需要根据业务规则强制覆盖某些字段。
MapStruct 提供了三个维度的控制属性,它们的优先级和触发时机各不相同,混用时极易产生误解。
2.1.1. 三级赋值策略详解
我们需要在 UserMapper 中通过具体的场景来区分这三个属性:
defaultValue(兜底策略):仅当 源字段为 null 时生效。- 场景:如果用户未设置邮箱,显示 “暂无邮箱”。
constant(强制策略):无视源字段,始终强制赋值。- 场景:API 接口版本号、固定的业务类型标识。
defaultExpression(动态兜底):当 源字段为 null 时,执行一段 Java 代码。- 场景:如果数据库中
trace_id为空,自动生成一个 UUID。
- 场景:如果数据库中
2.1.2. 增强实体类与 VO
为了演示这些特性,我们需要先对 UserEntity 和 UserVO 进行微调,增加测试字段。
修改文件:src/main/java/com/example/demo/entity/UserEntity.java
1 |
|
修改文件:src/main/java/com/example/demo/vo/UserVO.java
1 |
|
2.1.3. 编写进阶 Mapper 配置
文件路径:src/main/java/com/example/demo/convert/UserMapper.java
这里我们需要特别注意 expression 的写法。由于 MapStruct 生成代码时不知道类的包路径,如果我们在表达式中使用了 java.util.UUID 等类,要么写全限定名,要么在 @Mapper 注解中配置 imports。
1 | package com.example.demo.convert; |
2.1.4. 生成代码深度审计
执行 mvn compile,打开 target/generated-sources/.../UserMapperImpl.java。我们要验证 MapStruct 是否按照预期的逻辑生成了 if-else 代码。
1 |
|
从源码中可以清晰看到:constant 的优先级最高,完全忽略源数据;而 defaultValue 和 defaultExpression 则是互斥的,都是在 else 分支中生效。
2.2. 类型转换与高精度格式化
在金融或报表系统中,数据格式化是重灾区。前端需要 yyyy-MM-dd 格式的日期,或者带有两位小数的金额字符串。如果交给前端处理,可能会出现时区不一致或精度丢失问题,因此后端转换是最佳实践。
2.2.1. 隐式类型转换机制
MapStruct 强大之处在于其内置的“隐式转换表”。在未配置任何注解的情况下,以下转换会自动发生:
- 基本类型 <-> 包装类:
int<->Integer(自动判空与拆装箱)。 - 基本类型 <-> String:
long<->String(调用String.valueOf)。 - 枚举 <-> String:调用枚举的
name()方法。
但是,对于 Date、LocalDateTime 和 BigDecimal,我们需要显式控制格式。
2.2.2. 日期与数值格式化实战
我们在 UserEntity 中增加金额字段,并在 Mapper 中配置格式化规则。
修改 Entity:增加 BigDecimal balance。
修改 VO:增加 String balanceStr 和 String createTimeStr。
UserMapper.java 配置更新:
1 |
|
2.2.3. 源码验证
观察生成的代码,重点关注 DateTimeFormatter 和 DecimalFormat 的使用:
1 | // UserMapperImpl.java |
2.3. 反向映射与敏感数据脱敏
开发中常见的场景是:查询时 Entity 转 VO,保存时 VO 转 Entity。这两个过程通常是“镜像”的,但有两个核心区别:
- 反向:源和目标颠倒。
- 脱敏/忽略:前端传来的 VO 不应该包含
id(数据库自增)、createTime(自动生成)或password(不应明文传输),或者后端在转换回 Entity 时必须忽略这些字段以防止被恶意覆盖。
2.3.1. @InheritInverseConfiguration 继承配置
我们不需要把 @Mapping 注解再反着写一遍。MapStruct 提供了“继承反向配置”的功能。
UserMapper.java 新增方法:
1 | // ... 正向 toVO 方法 ... |
关键原理解析:
- 继承机制:
@InheritInverseConfiguration(name = "toVO")会自动查找toVO方法的配置。- 它发现
toVO中有emailAddress -> email,于是它自动生成email -> emailAddress。 - 它发现
toVO中有createTime的格式化,于是它本该自动生成String解析为LocalDateTime的代码。
- 它发现
- 覆盖机制:我们在
@Mappings中手动写了createTime ignore = true。- 规则:手动配置优先级 > 继承配置。
- 结果:MapStruct 放弃了自动生成的日期解析代码,转而直接忽略该字段。
常见报错警示:如果你看到 Target property "xxx" must not be mapped more than once,说明你在同一个 @Mappings 数组里对同一个字段写了两行配置(比如一行写格式化,一行写忽略),请务必删除其中一行,保留你最终想要的那一个。
2.4. Web 层闭环验证
光看代码不够,我们需要启动 Spring Boot,通过真实的 HTTP 请求来验证这一切。
2.4.1. 搭建测试 Controller
我们在 controller 包下创建一个测试控制器。
文件路径:src/main/java/com/example/demo/controller/MapStructTestController.java
1 | package com.example.demo.controller; |
2.4.2. 验证场景一:正向转换与格式化
启动项目,使用浏览器或 Postman 访问 GET http://localhost:8080/test/mapstruct/toVO。
预期响应结果:
1 | { |
分析:
balance原值1234.567被格式化为1234.57,符合#0.00的四舍五入规则。email原值为 null,正确回退到了默认值。traceId成功生成了随机串。
2.4.3. 验证场景二:反向转换与脱敏
使用 Postman 发送 POST http://localhost:8080/test/mapstruct/toEntity。
请求 Body (JSON):
1 | { |
预期响应结果:
1 | { |
分析:
- 即使前端恶意传递了
id: 9999,转换后的 Entity 中id依然为 null,保证了数据库自增 ID 的安全。 cityName成功被还原到了嵌套的Address对象中,证明了 MapStruct 在反向转换时的智能对象实例化能力。
2.5. 本章总结与进阶语法速查
本章我们攻克了 MapStruct 最硬核的“数据清洗”与“格式化”难题。为了方便大家在实际开发中直接 Copy 代码,我们将本章的核心技巧浓缩为一份 “场景化速查手册”。
2.5.1. 进阶语法速查手册
遇到以下业务需求时,请直接参考本表代码:
| 业务场景 | 核心方案 | 代码示例 |
|---|---|---|
| 强制赋值 (如:设置固定版本号) | constant | @Mapping(target = "version", constant = "v1.0")(注:完全忽略源字段) |
| 空值兜底 (如:为空时显示 “未知”) | defaultValue | @Mapping(source = "name", target = "name", defaultValue = "未知用户")(注:仅 source 为 null 时生效) |
| 动态生成 (如:为空时生成 UUID) | defaultExpression | @Mapping(source = "id", target = "id", defaultExpression = "java(java.util.UUID.randomUUID().toString())")(注:需配合 imports 或全限定名) |
| 日期格式化 (Date/Time ↔ String) | dateFormat | @Mapping(source = "createTime", target = "timeStr", dateFormat = "yyyy-MM-dd HH:mm") |
| 金额格式化 (BigDecimal ↔ String) | numberFormat | @Mapping(source = "price", target = "priceStr", numberFormat = "#0.00")(注:自动处理四舍五入) |
| 反向继承 (VO 转回 Entity) | @InheritInverseConfiguration | @InheritInverseConfiguration(name = "toVO")UserEntity toEntity(UserVO vo); |
| 安全过滤 (如:不修改密码/ID) | ignore = true | @Mapping(target = "password", ignore = true) |
| 引入依赖 (配合表达式使用) | imports | @Mapper(componentModel = "spring", imports = {UUID.class, LocalDateTime.class}) |
2.5.2. 核心避坑指南
在运用上述高级特性时,有三条 “铁律” 必须遵守,否则 Bug 极难排查:
- 优先级铁律:
constant>expression>source。- 如果你配置了
constant,MapStruct 会直接无视你的source属性,哪怕源字段有值也不会用。
- 如果你配置了
- 反向覆盖铁律:
@InheritInverseConfiguration是全量继承。- 如果正向转换有“日期格式化”,反向也会自动生成“日期解析”。
- 必须 手动添加
ignore = true来覆盖那些你不希望前端修改的敏感字段(如 ID、创建时间)。
- 表达式导包铁律:
- 在
expression或defaultExpression中写 Java 代码时,MapStruct 不会自动导包。 - 要么写全限定名(
java.util.UUID),要么在@Mapper(imports = {UUID.class})中显式声明。
- 在
第三章. MapStruct:集合容器与流式处理详解
摘要:在实际业务接口中,返回单一对象(如 UserVO)的场景占比不足 20%,绝大多数查询接口返回的都是列表(List)、分页对象(Page)或者键值对映射(Map)。本章将深入讲解 MapStruct 如何自动处理集合循环、如何控制“空集合”的返回策略(是 null 还是 []),以及如何利用 Java 8 Stream API 实现更高级的数据收集逻辑。
本章学习路径
- 集合自动化:掌握
List、Set等泛型容器的自动循环映射机制。 - 空值策略:解决
List为null时导致前端页面崩溃的痛点,学会配置RETURN_DEFAULT返回空数组[]。 - Map 映射:掌握
Map<K, V>容器的转换逻辑,以及从 Map 到 Bean 的转换限制。 - Stream 集成:利用 Java 8
default方法在接口中直接编写 Stream 流处理逻辑,实现 List 转 Map 等高级聚合。
3.1. 泛型集合的自动映射
在没有 MapStruct 之前,如果我们需要将 List<UserEntity> 转换为 List<UserVO>,通常需要写一个繁琐的 for 循环:
1 | // 痛苦的回忆:手动循环 |
这种代码不仅写起来累,而且容易在 entityList 为 null 时抛出空指针异常。
3.1.1. 自动循环机制
MapStruct 的强大之处在于:只要你定义了单对象的转换方法,它就能自动生成集合的转换方法。
修改 Mapper 接口:src/main/java/com/example/demo/convert/UserMapper.java
我们在原有的 UserMapper 中增加一个处理 List 的方法。
1 |
|
3.1.2. 生成代码审计
执行 mvn compile,查看 UserMapperImpl.java。
1 |
|
可以看到,MapStruct 帮我们生成了标准的循环代码。关键点:它复用了 toVO 方法,这意味着我们在 toVO 上配置的所有策略(格式化、默认值、忽略字段)都会自动应用到列表中的每一个元素上。
3.2. 空集合处理策略 (Null vs Empty)
上一节生成的代码中有一个细节:
1 | if ( entityList == null ) { |
这在前后端分离开发中是一个 巨大的隐患。如果后端返回 data: null,前端代码如果写了 data.map(item => ...),页面会直接报错白屏。
行业规范:查询列表接口,如果没有数据,应该返回空数组 [],而不是 null。
3.2.1. 配置 NullValueIterableMappingStrategy
MapStruct 提供了 nullValueIterableMappingStrategy 属性来控制这一行为。
RETURN_NULL(默认):入参为 null,返回 null。RETURN_DEFAULT(推荐):入参为 null,返回空集合(new ArrayList<>())。
我们可以将这个配置加在 @Mapper 注解上,使其对整个接口生效。
修改 Mapper 接口:
1 | import org.mapstruct.NullValueIterableMappingStrategy; |
3.2.2. 验证生成代码变化
重新编译后,查看 toVOList 方法的变化:
1 |
|
3.3. Map 容器与复杂类型转换
摘要:在企业级开发中,我们经常遇到“前后端联调”时的痛点:前端可能需要一个动态的 Key-Value 结构,或者通过动态 JSON 对象提交数据。本节将深入探讨 MapStruct 在处理 Map 容器时的能力边界,利用 @MapMapping 解决格式化问题,并引入“混合双打”模式(MapStruct + Hutool)优雅解决动态 Map 转 Bean 的难题。
3.3.1. 场景一:原生支持——Map 值格式化
业务场景:前端同学甩过来一份 Mock 数据,要求系统配置接口 (/config) 返回一个 Map。Key 是配置项名称,Value 是配置值。
核心需求:所有的日期类型,必须格式化为 yyyy-MM-dd 字符串,不能直接返回 LocalDateTime 的 ISO 格式。
Mock 数据:
1 | { |
后端现状:我们的数据源是一个 Map<String, LocalDateTime>,直接返回给前端会带有 T 符号。
解决方案:
MapStruct 原生支持 Map 到 Map 的转换,且会自动应用泛型类型的转换规则。我们利用 @MapMapping 注解即可轻松搞定。
Mapper 接口配置:
1 | /** |
生成代码审计:编译后,MapStruct 会生成如下代码。它非常智能地遍历 EntrySet,保持 Key 不变,对 Value 进行格式化。注意:这里使用了 LinkedHashMap 来保持源 Map 的顺序,并且进行了 容量优化计算。
1 |
|
3.3.2. 场景二:MapStruct 的“缺点”——Map 转 Bean
业务场景升级:前端提了新需求:“注册接口,我会传很多动态参数,有时候有 email,有时候没有。为了灵活,你后端用 Map<String, Object> 接收吧,然后存到数据库里。”
后端痛点:
Controller 层用 @RequestBody Map<String, Object> params 接收了参数,但 Service 层的方法签名是 save(UserEntity user)。我们需要把这个 Map 转为 UserEntity。
尝试 MapStruct (失败演示):如果我们直接定义这样一个接口:
1 | // 错误示范:MapStruct 无法自动实现 |
编译结果:MapStruct 会生成一个空方法!它 不会 报错,但生成的代码是空的:
1 | public UserEntity mapToEntity(Map<String, Object> map) { |
根本原因:
MapStruct 是 编译时 工具。它在编译 UserMapper.java 时,只能看到 Map 接口的定义,它不知道运行时 Map 里会有 “username” 还是 “age” 这些 Key。它无法像写代码那样生成 map.get("username"),因为 Key 是未知的。
3.3.3. 业界解决方案: (MapStruct + Hutool)
既然 MapStruct 做不到“动态反射”,我们是否要放弃它,回到 Controller 层到处写 BeanUtil.copyProperties 呢?
绝对不要。为了保持架构的整洁性,所有的转换逻辑(无论是静态的还是动态的)都应该收口在 UserMapper 接口中。Service 层不应该感知到底层是用 MapStruct 还是 Hutool。
我们可以利用 Java 8 的 default 方法,在 MapStruct 接口中“偷渡”一个反射工具类。
第一步:引入 Hutool (如果尚未引入)
1 | <dependency> |
第二步:修改 Mapper 接口
我们在 UserMapper 中编写一个 default 方法,内部调用 BeanUtil。
1 | import cn.hutool.core.bean.BeanUtil; |
这样设计的好处是:
- 统一入口:Service 层只知道
userMapper.mapToEntity(map),不需要引入BeanUtil。 - 灵活兼容:大部分接口用 MapStruct 高性能转换,极少数动态 Map 接口用 Hutool 兜底,兼顾了性能与灵活性。
3.3.4. 闭环验证与空值策略总结
我们更新 MapStructTestController 来验证这两个 Map 场景。
1 |
|
Postman 请求结果:
1 | { |
小结:企业级空值策略配置表
我们在处理集合和 Map 时,防止空指针是第一要务。以下是推荐的全局配置策略:
| 策略属性 | 作用对象 | 推荐配置值 | 效果说明 |
|---|---|---|---|
nullValueIterableMappingStrategy | List, Set, 数组 | RETURN_DEFAULT | 源为 null 时,返回 [] (空集合),避免前端遍历报错 |
nullValueMapMappingStrategy | Map | RETURN_DEFAULT | 源为 null 时,返回 {} (空 Map),避免空指针 |
nullValueMappingStrategy | POJO Bean | RETURN_NULL | 源为 null 时,返回 null。通常实体类不需要兜底为空对象 |
最佳实践代码:
1 |
|
3.4. Stream 流集成与自定义聚合
MapStruct 的自动生成代码通常是非常标准的 for 循环,这能满足 90% 的 List 到 List 的转换需求。但在实际业务中,我们经常需要对转换后的数据进行 二次聚合,例如:
- 列表转 Map:将用户列表转换为
<ID, UserVO>的 Map,方便在内存中进行 O(1) 复杂度的快速查找。 - 分组:按城市 (
cityName) 对用户进行分组。 - 过滤:在转换后剔除某些不符合业务规则的数据。
如果完全依赖 MapStruct 的注解配置(如 @IterableMapping),很难优雅地实现这些逻辑。最最佳实践是:MapStruct 负责对象属性的映射(繁琐工作),Java Stream 负责数据的聚合(逻辑工作)。
3.4.1. 利用 Default 方法扩展能力
Java 8 引入的接口 default 方法是 MapStruct 的绝配。MapStruct 生成的实现类会自动继承接口中的 default 方法,这允许我们在接口中编写自定义逻辑,同时调用 MapStruct 生成的方法。
实战需求:前端需要一个“用户字典”接口,返回结构为 Map<Long, UserVO>,Key 为用户 ID,Value 为用户详情,以便前端通过 ID 快速渲染。
修改 Mapper 接口:src/main/java/com/example/demo/convert/UserMapper.java
1 | // 1. 基础的 List 转换 (MapStruct 自动生成) |
代码深度解析:
- 分工明确:
toVOList由 MapStruct 实现,它解决了最麻烦的字段拷贝、格式化、类型转换问题;toVOMap由我们要自己写,专注于数据结构的重组。 - MergeFunction:在使用
Collectors.toMap时,必须 指定第三个参数(合并函数)。否则一旦 List 中存在 ID 相同的对象,生产环境会直接抛出Duplicate key异常导致接口崩溃。这是企业级开发必须注意的细节。
3.5. Web 层闭环验证
为了验证集合处理(List)、空集合策略(Empty List)以及 Stream 聚合(Map)的正确性,我们需要构建一个覆盖全场景的测试控制器。
3.5.1. 编写全场景测试 Controller
文件路径:src/main/java/com/example/demo/controller/MapStructTestController.java
1 | // ... 注入 UserMapper |
3.5.2. Postman 验证实录
我们需要验证三个关键点,请打开 Postman 或浏览器进行测试:
测试 1:空集合策略验证
- 请求:
GET /test/mapstruct/list?mockNull=true - 响应:
[] - 结论:
nullValueIterableMappingStrategy = RETURN_DEFAULT生效。前端收到的是空数组,不会报错。
测试 2:列表转换验证
- 请求:
GET /test/mapstruct/list - 响应:
1
2
3
4[
{ "id": 1, "email": "user1@test.com", ... },
{ "id": 2, "email": "no-email@example.com", ... } // 验证:循环中依然应用了 defaultValue
]
测试 3:Stream 聚合与冲突处理验证
- 请求:
GET /test/mapstruct/mapAggregate - 响应:
1
2
3
4
5
6
7
8
9
10
11{
"100": {
"id": 100,
"username": "Admin"
// 验证:ID为100的重复数据被 mergeFunction 处理,保留了第一个(Admin),丢弃了(Admin_Duplicate)
},
"200": {
"id": 200,
"username": "Guest"
}
} - 结论:
default方法逻辑正确,Stream API 成功将 List 转换为了 Map,且防御了重复 Key 异常。
3.6. 本章总结与场景化代码速查
本章我们从单一对象跨越到了集合容器。在实际开发中,请根据您的具体业务场景(是转列表、转 Map、还是防空指针),直接参考以下 4 个标准范式。
3.6.1. 场景一:基础列表转换
需求:将 List<UserEntity> 转为 List<UserVO>。
方案:利用 MapStruct 的泛型推断能力,只需定义接口,无需写逻辑。
1 | // UserMapper.java |
3.6.2. 场景二:空集合防御
需求:当数据库查询结果为 null 时,接口应返回空数组 [],而不是 null,防止前端白屏。
方案:在 @Mapper 注解中全局配置 RETURN_DEFAULT。
1 | // UserMapper.java |
3.6.3. 场景三:列表聚合为 Map
需求:查询出用户列表后,需要将其转化为 Map<ID, UserVO> 以便快速查找。
方案:使用 Java 8 Default 方法 + Stream,不要试图用注解解决。
1 | // UserMapper.java |
3.6.4. 场景四:动态 Map 转实体 (MapStruct + Hutool)
需求:Controller 接收 Map<String, Object> (动态参数),需要转为 UserEntity。
方案:MapStruct 搞不定动态 Key,需引入 Hutool 并在 Default 方法中调用。
1 | // UserMapper.java |
第四章. MapStruct:高级映射逻辑与自定义扩展
摘要:前三章我们解决了 80% 的标准映射场景。但在复杂的业务系统中,我们经常面临:“字段转换依赖数据库查询”、“转换后需要计算冗余字段”、“多个源对象合并为一个 DTO” 或 “部分更新已有对象” 等需求。本章将深入 MapStruct 的 抽象类模式、生命周期回调 及 表达式注入,掌握处理这剩余 20% 复杂场景的终极武器。
本章学习路径
- 表达式注入:在注解中直接嵌入 Java 代码,处理简单的动态逻辑(如时间戳生成)。
- 限定符策略:解决“多个转换方法签名冲突”的问题,通过
@Named精确指定映射逻辑。 - 抽象类模式:打破接口限制,通过
abstract class注入 Spring Service,实现“转换时查库”。 - 生命周期回调:利用
@AfterMapping实现复杂的后置处理(如 VIP 等级计算)。 - 增量更新:掌握
@MappingTarget,实现 RESTful PATCH 接口的标准更新模式。
4.1. Java 表达式与限定符
4.1.1. Java 表达式注入 (expression)
有时候,字段的转换逻辑非常简单,写一个专门的工具方法显得多余,但又无法通过简单的 source 映射完成。例如:生成当前的系统时间戳、生成随机 UUID,或者进行简单的字符串拼接。
MapStruct 允许通过 expression 属性直接注入 Java 代码片段。
实战场景:在 UserVO 中增加一个 serverTime 字段,记录接口返回时的服务器时间;增加一个 welcomeMessage,拼接 “Hello, {username}”。
修改 Mapper 接口:src/main/java/com/example/demo/convert/UserMapper.java
1 | // 1. 导入 System 类,以便在表达式中使用 |
生成的代码审计:
1 | // UserMapperImpl.java |
注意:expression 中的代码是不受编译器检查的(它是字符串)。如果拼写错误,只有在生成代码阶段(mvn compile)才会报错。因此,仅建议用于极简单的逻辑。
4.1.2. 限定符解决冲突 (@Named)
当我们在 Mapper 中定义了多个“类型相同”但“逻辑不同”的转换方法时,MapStruct 会陷入困惑,报 Ambiguous mapping methods 错误。
实战场景:我们需要两个 String -> String 的转换方法:
- 普通转换:不做处理。
- 脱敏转换:手机号中间 4 位变 *。
Mapper 接口配置:
1 |
|
4.2. 自定义方法与抽象类模式
接口(Interface)最大的局限性在于无法持有状态(无法定义成员变量)。但在企业级开发中,我们经常需要在转换过程中查询数据库(例如:将 deptId 转换为 deptName)。这时,我们需要将 @Mapper 标记在 抽象类 (abstract class) 上。
4.2.1. 抽象类注入 Service
需求:UserEntity 中只有 deptId,但 UserVO 需要展示 deptName。deptName 需要调用 DeptService 查询。
步骤 1:定义 Service 模拟
1 |
|
步骤 2:改造 Mapper 为抽象类
文件路径:src/main/java/com/example/demo/convert/UserMapper.java
1 | // 1. 改为 abstract class |
生成的代码审计:
1 |
|
4.2.2. 生命周期回调 (@AfterMapping)
有时候,我们需要在 MapStruct 完成所有自动赋值 之后,再执行一些复杂的逻辑。比如建立双向关联,或者计算一些依赖于多个字段的属性。
实战场景:UserEntity 转换为 UserVO 后,需要根据 balance (余额) 计算 vipLevel (VIP 等级)。这个逻辑写在 expression 里太乱,适合用后置处理。
在抽象类 UserMapper 中增加:
1 | // 映射完成后自动回调 |
生成的代码审计:
1 | public UserVO toVO(UserEntity entity) { |
4.3. 多源参数与对象更新
4.3.1. 多对一映射 (Multi-Source)
有时候,一个 VO 的数据来源不只是一个 Entity,而是来自多个对象。MapStruct 支持在方法中传入多个参数。
实战场景:UserDetailVO 需要包含 UserEntity 的基础信息,以及 AccountEntity 的账户信息。
1 |
|
Mapper 接口配置:
1 |
|
注意:当参数超过一个时,@Mapping 中的 source 必须指定参数名称前缀(如 user. 或 account.),否则 MapStruct 不知道去哪个对象里找属性。
4.3.2. 对象更新模式 (@MappingTarget)
通常我们是 toVO(创建新对象)。但在 “修改用户信息” 的接口中,我们通常是先从数据库查出 UserEntity(旧对象),然后用前端传来的 UserDTO(新数据)去 更新 这个旧对象,而不是 new 一个新的。
这就需要用到 @MappingTarget。
实战场景:updateUser(UserDTO dto, UserEntity entity)。将 DTO 中非空的字段更新到 Entity 中。
1 |
|
生成的代码审计:
1 | public void updateEntityFromDto(UserDTO dto, UserEntity entity) { |
4.4. Web 层闭环验证
我们更新 MapStructTestController,验证上述高级功能。
4.4.1. 更新 Controller
文件路径:src/main/java/com/example/demo/controller/MapStructTestController.java
1 | // ... 注入 UserMapper |
4.4.2. Postman 验证
请求:PUT /test/mapstruct/update/100
Body:
1 | { |
响应:
1 | { |
4.5. 本章总结与高阶场景速查
本章我们突破了“纯字段映射”的限制,掌握了如何将 Spring 容器、复杂计算以及生命周期管理融入 MapStruct。
遇到以下 5 种高阶场景时,请直接 Copy 下方的标准代码模版:
4.5.1. 场景一:注入 Java 代码 (简单逻辑)
需求:不写额外方法,直接在注解里调用 System.currentTimeMillis() 或生成 UUID。
方案:使用 expression="java(...)"。
1 | // 1. 记得导入类 |
4.5.2. 场景二:解决多意图冲突 (@Named)
需求:同一个字段(如手机号),在后台需要“明文展示”,在前台需要“脱敏展示”。
方案:使用 @Named 定义别名,并在 @Mapping 中通过 qualifiedByName 指定。
1 | // 1. 定义两个不同逻辑的方法,用 @Named 区分 |
4.5.3. 场景三:注入 Spring Service (查库映射)
需求:转换过程中需要查数据库(例如:根据 deptId 查询 deptName)。
方案:使用 抽象类 (abstract class) 替代接口,并利用 @Autowired 注入 Bean。
1 |
|
4.5.4. 场景四:复杂后置处理 (@AfterMapping)
需求:字段 A 的值依赖于字段 B 和 C 的运算结果(例如:根据余额计算 VIP 等级),无法通过简单的 source 搞定。
方案:使用生命周期回调,在自动转换完成后执行自定义逻辑。
1 | public abstract class UserMapper { |
4.5.5. 场景五:增量更新 (Patch 接口)
需求:前端只传了修改过的字段(其他为 null),后端更新数据库时,不能把数据库里原有的值覆盖为 null。
方案:使用 @MappingTarget 配合 IGNORE 策略。
1 | // 1. 核心策略:源字段为 null 时,忽略赋值 (即保留目标对象原值) |
4.5.6. 核心避坑指南
在使用上述高级特性时,请务必注意以下三点,否则编译必报错:
- 抽象类注入陷阱:
- 注入的 Service 变量必须使用
protected修饰符。如果用private,MapStruct 生成的子类(Impl)无法访问该变量,导致空指针或编译错误。
- 注入的 Service 变量必须使用
- 多源参数命名陷阱:
- 当方法有多个入参时(如
toVO(User u, Account a)),@Mapping中 必须 指定参数前缀(如source = "u.id")。如果不指定前缀,MapStruct 不知道去哪个对象找id。
- 当方法有多个入参时(如
- 表达式导包陷阱:
- 在
expression中使用UUID、LocalDate等非java.lang包下的类时,必须在@Mapper(imports = {UUID.class})中显式注册,或者在表达式里写全限定名(java.util.UUID...)。
- 在
第五章. MapStruct-Plus :数据传输对象 DTO 到业务对象 BO 的相互映射
摘要:本章我们将正式引入 MapStruct-Plus (MSP),通过“入站”数据流(DTO -> BO)的实战,彻底重构之前的开发模式。我们将建立符合阿里巴巴规范的分层架构,深入理解 MSP 如何通过 @AutoMapper 注解消除繁琐的接口定义,并掌握全局 Converter 的依赖注入机制。
本章学习路径
- 环境重塑:清理旧的 MapStruct 依赖,引入 MSP Starter,并配置关键的编译顺序(AST 冲突解决)。
- 架构落地:初始化
client(传输层) 与domain(领域层) 的包结构。 - 核心对比:通过 Tab 对比,直观感受“接口优先”与“注解优先”的差异。
- 入站实战:编写
UserCreateDTO,使用@AutoMapper建立通往UserBO的数据桥梁。 - 全局调用:掌握
io.github.linpeilie.Converter的统一调用方式。
5.1. 环境依赖清洗与重构
在开始新的架构之前,我们需要确保工程环境的纯净。MSP (MapStruct-Plus) 是基于 MapStruct 的增强封装,为了避免类加载冲突(Jar Hell),我们需要移除原生的 MapStruct 依赖,转而使用 MSP 的全家桶 Starter。
5.1.1. 依赖变更
文件路径:pom.xml
请打开项目根目录下的 pom.xml 文件,执行以下操作:
- 删除:移除原有的
org.mapstruct:mapstruct和mapstruct-processor依赖。 - 新增:引入
mapstruct-plus-spring-boot-starter。
1 | <dependencies> |
5.1.2. 编译插件配置(至关重要)
MapStruct 和 Lombok 都是基于 JSR-269 的注解处理器(Annotation Processor)。它们在编译期修改字节码(AST 修改)。
- Lombok:生成 getter/setter。
- MapStruct:读取 getter/setter 生成转换代码。
如果 MapStruct 先执行,它会发现对象里没有 getter/setter(因为 Lombok 还没干活),从而导致无法生成映射代码。因此,必须严格控制插件的执行顺序。
文件路径:pom.xml -> <build><plugins>
1 | <plugin> |
5.2. 初始化分层包结构
根据阿里巴巴 Java 开发手册的分层规范,我们不再把所有类都堆在 entity 包下。我们需要明确区分 数据传输对象 (DTO) 和 业务对象 (BO)。
5.2.1. 创建目录
请在 IDE 中按照以下结构创建包:
目录树结构:
1 | src/main/java/com/example/demo/ |
- client.dto:这是“入站”的最前线,接收前端传来的 JSON 参数。
- domain.bo:这是业务的内核,Service 层只处理 BO,不关心 DTO 的存在。
5.3. MSP 核心理念:零接口开发
在编写代码前,我们必须理解 MSP 究竟改变了什么。它将 MapStruct 的 Interface-First(接口定义优先) 模式转变为 Annotation-First(注解绑定优先) 模式。
以下通过对比展示两种模式在实现 DTO -> BO 时的差异:
繁琐的接口定义模式
在原生模式下,你需要手动创建一个接口文件,添加 @Mapper 注解,定义方法签名。随着业务增长,这个接口文件会变得极其庞大且难以维护。
1 | // 必须手动创建 Mapper 接口 |
极速的注解驱动模式
在 MSP 模式下,Mapper 接口文件消失了。你只需要在类头上加一个 @AutoMapper 注解,编译器会自动帮你生成背后的接口和实现类。
1 | // 直接在类上声明转化关系 |
5.4. 入站实战:DTO 到 BO 的转化
现在我们模拟一个用户注册场景。前端提交了用户名、手机号和密码,我们需要将这些数据转化为业务对象,以便在 Service 层进行处理。
5.4.1. 定义业务对象 (BO)
首先定义转化的 目标,即业务对象。BO 对象应该包含业务逻辑所需的所有属性,它是纯净的,不包含任何 @NotNull 等前端校验注解。
文件路径:src/main/java/com/example/demo/domain/bo/UserBO.java
1 | package com.example.demo.domain.bo; |
5.4.2. 定义传输对象 (DTO) 并绑定映射
接下来定义 源头,即传输对象。DTO 负责接收外部参数,并承载基础的格式校验。
关键操作:我们需要在 DTO 上添加 @AutoMapper 注解,告诉 MSP:“请在编译时生成代码,将本类转换为 UserBO”。
文件路径:src/main/java/com/example/demo/client/dto/UserCreateDTO.java
1 | package com.example.demo.client.dto; |
5.4.3. 编写 Controller 进行全链路验证
配置完成后,我们不需要写任何 Mapper 接口,直接在 Controller 中注入 MSP 的全局转换器 Converter。
文件路径:src/main/java/com/example/demo/controller/UserRegistrationController.java
1 | package com.example.demo.controller; |
5.4.4. 启动验证与代码审计
步骤 1:执行编译
在终端执行 mvn clean compile。此时 MSP 的注解处理器开始工作。
步骤 2:生成代码审计
请到项目的 target/generated-sources/annotations 目录下查看。你应该能找到一个名为 com.example.demo.client.dto.UserCreateDTOToUserBOMapper 的类。
1 | // 自动生成的代码片段 |
步骤 3:Postman 调用
发送 POST 请求到 http://localhost:8080/users/register。
Body:
1 | { |
响应结果:
1 | { |
结果分析:
username,phone转换成功:证明@AutoMapper生效。source为null:证明 MSP 默认只处理同名属性,异名属性(platformvssource)被忽略了。我们在下一章处理这个问题。
5.5. 全局策略配置
在刚才的实战中,platform 字段因为没有匹配到目标字段而被静默忽略了。在生产环境中,这种“静默”是非常危险的,可能导致数据丢失而不自知。
我们需要配置 MSP,使其在发现未映射字段时发出警告。
5.5.1. 创建配置类
MSP 提供了 @MapperConfig 注解来控制全局行为,我们首先需要开启 pom.xml 下的 maven 编译预警
1 | <configuration> |
然后再配置类中新增配置
文件路径:src/main/java/com/example/demo/config/MapStructPlusConfig.java
1 | package com.example.demo.config; |
配置完成后,再次执行 mvn compile,如果 UserBO 中有字段未被赋值,控制台将会打印 Warning 日志,提醒开发者检查映射规则。

5.6. 本章小结
本章我们完成了从“传统 Mapper 接口”到“MSP 注解驱动”的架构转型,并打通了 入站 (DTO -> BO) 的数据链路。
核心要点:
- 架构分层:DTO 用于传输,BO 用于业务,两者通过 MSP 解耦。
- 零接口:在 Source 类上使用
@AutoMapper(target = Target.class)即可自动生成转换器。 - 统一调用:注入
Converter接口,使用.convert(source, targetClass)方法,无需关心底层实现。
场景化代码速查:
场景:前端传入注册表单,需要转为业务对象。
方案:
1 | // 1. DTO 定义 (Source) |
在下一章中,我们将深入业务核心层。UserBO 需要被持久化到数据库(转换 UserPO),这中间将面临 枚举转换 (Enum vs Int) 和 复杂 JSON 字段 的挑战,我们将展示 MSP 如何与 MyBatis-Plus 完美配合解决这些难题。
第六章. MapStruct-Plus:业务对象(BO)与持久化对象(PO)的深度映射
摘要:本章我们将深入核心业务层,解决从业务对象 (BO) 到数据库持久化对象 (PO) 的落地难题。为了拒绝繁琐的手写转换逻辑,我们将引入 Hutool 工具库,结合 MapStruct Plus 的 Java 表达式 (Expression) 能力,实现一行代码完成复杂类型(如 Map 到 JSON)的序列化。同时,我们将搭建 H2 内存数据库 环境,确保每一行代码都能进行真实的 SQL 交互验证。
本章学习路径
- 环境构建:引入 H2 Database 和 Hutool,配置自动建表脚本,打造“开箱即用”的验证环境。
- 标准定义:基于 MyBatis-Plus 规范定义 PO,理解数据库“扁平结构”与对象“立体结构”的差异。
- 极简映射:利用 MSP 的
expression特性结合JSONUtil,通过注解实现复杂字段的序列化与反序列化。 - 枚举处理:使用
@AutoEnumMapper解决 Java 枚举与数据库 TinyInt 之间的自动转换。 - 闭环验证:通过模拟 Service 层的实战操作,验证数据在“对象 <-> 数据库”之间的完整流转。
6.1. 基础设施搭建:H2 与 Hutool
在上一章中,我们完成了 DTO 到 BO 的数据清洗与转换,确保了进入业务层的数据是干净的。但在实际开发中,业务逻辑处理完的数据最终需要落地到数据库,这就涉及到了数据库环境的搭建和工具库的选型。本节我们将引入 H2 内存数据库和 Hutool 工具包,为后续的持久化实战打下坚实的基础。
6.1.1. 引入核心依赖
我们需要引入三个关键组件来支撑本章的实战:MyBatis-Plus 负责 ORM 映射,H2 负责提供无需安装的运行时数据库,Hutool 则用来简化 Java 代码。
文件路径:pom.xml
请在项目的 <dependencies> 节点中添加以下配置:
1 | <dependencies> |
关键点解析:
- H2 Database:它是一个纯 Java 编写的关系型数据库,支持内存模式。这意味着我们不需要你在本地安装 MySQL 即可运行本章代码,且每次重启后数据会自动重置,非常适合单元测试和教学演示。
- Hutool:在这个场景中,我们需要它的
JSONUtil来替代笨重的 Jackson 或 Gson 进行手动配置,实现“一行代码”处理 JSON 转换。
6.1.2. 配置数据库与自动建表
为了让 H2 模拟 MySQL 的行为,并能够打印出直观的 SQL 日志,我们需要对 Spring Boot 进行配置。
文件路径:src/main/resources/application.yml
1 | spring: |
接下来,我们需要定义表结构。为了演示复杂类型映射,我们在表中特意设计了一个 extra_info 字段来存储 JSON 字符串。
文件路径:src/main/resources/schema.sql
1 | DROP TABLE IF EXISTS sys_user; |
6.2. 持久化层建设:PO 与 Mapper
在上一节中,我们搭建好了底层的数据库环境。但在 Java 世界中,我们需要一个对象来“镜像”数据库表结构,以便 ORM 框架进行操作。本节我们将按照 MyBatis-Plus 的规范定义持久化对象 (PO),并理解它与业务对象 (BO) 在结构上的根本差异。
6.2.1. 定义 UserPO
PO (Persistent Object) 的设计原则是“完全忠实于数据库表结构”。既然数据库里的 extra_info 是 VARCHAR 类型,那么 PO 里的字段就必须是 String,而不能是 Map 或 Object。这种数据类型的差异正是我们需要解决的核心问题。
文件路径:src/main/java/com/example/demo/infrastructure/po/UserPO.java
1 | package com.example.demo.infrastructure.po; |
6.2.2. 定义 Mapper 接口
有了 PO,我们还需要一个数据访问接口。得益于 MyBatis-Plus,我们只需继承 BaseMapper 即可获得涵盖增删改查的几十种通用方法。
文件路径:src/main/java/com/example/demo/infrastructure/mapper/UserMapper.java
1 | package com.example.demo.infrastructure.mapper; |
6.3. Hutool + MSP:极简转换实战
在上一节中,我们定义了结构扁平的 PO,其中 extraInfo 是一个 JSON 字符串。但在业务层(BO),我们希望操作的是一个灵活的 Map<String, Object>。传统做法是手写一个 Converter 类,注入 Jackson 进行解析。但在本节,我们将利用 MapStruct Plus 的 Expression 能力,配合 Hutool,直接在注解中完成这一复杂的序列化逻辑。
6.3.1. 准备枚举与 Hutool
业务逻辑中经常使用枚举来表示状态,而数据库通常存储 TINYINT。为了实现自动转换,我们需要定义一个包含标准接口的枚举。
文件路径:src/main/java/com/example/demo/domain/enums/UserStatus.java
1 | package com.example.demo.domain.enums; |
6.3.2. BO 定义:一行代码搞定 JSON 转换
这是本章的核心。我们将定义 UserBO,并使用 MapStruct 的 expression 功能调用 Hutool 的静态方法。
设计思路:
- 正向映射 (BO -> PO):需要将 BO 的
Map转换为 PO 的String。使用JSONUtil.toJsonStr()。 - 反向映射 (PO -> BO):需要将 PO 的
String还原为 BO 的Map。使用JSONUtil.toBean()。 - 依赖导入:因为生成的代码需要调用
JSONUtil,必须显式通过imports属性告知 MSP。
文件路径:src/main/java/com/example/demo/domain/bo/UserBO.java
1 | package com.example.demo.domain.bo; |
6.3.3. 为什么这样写?
这里使用了 expression = "java(...)" 语法。这是一个非常强大的功能,它允许我们在注解中直接编写 Java 代码片段。MapStruct 在生成代码时,会直接将这段字符串“复制粘贴”到 Mapper 实现类中。
如果不使用 Hutool 和 expression,你需要:
- 编写一个
JsonConverter类。 - 注入 ObjectMapper。
- 处理
try-catch异常。 - 在 Mapper 接口中通过
@Mapper(uses = JsonConverter.class)引用它。
现在,利用 Hutool 对异常的静默处理(Runtime Exception)和静态方法特性,我们将 20 行代码压缩到了 1 行,我们感受到了
- Expression 的威力:
expression="java(...)"允许直接嵌入 Java 代码,是处理特殊映射逻辑的“逃生舱”。 - Import 的必要性:在使用 Expression 调用静态方法时,必须在
@AutoMapper(imports = {...})中注册该类,否则生成的代码会因找不到类而编译失败。 - 反向映射陷阱:在
@ReverseAutoMapping中,source关键字指的是 入参对象(即 PO),这一点在编写表达式时容易混淆。
速查代码:
1 | // 正向:对象 -> JSON 串 |
6.4. 全链路闭环验证
在上一节中,我们完成了极其优雅的映射配置。现在,代码写得再漂亮,也必须经得起运行时的检验。本节我们将编写一个 Controller 来模拟业务流程,验证数据从创建、落库、回查到还原的完整生命周期。
6.4.1. 编写验证逻辑
我们将模拟一个典型的业务场景:创建一个包含复杂信息的 UserBO,将其保存到数据库(转为 PO),然后立即读出来(还原为 BO),验证数据是否无损。
文件路径:src/main/java/com/example/demo/controller/PersistenceController.java
1 | package com.example.demo.controller; |
6.4.2. 运行结果预期
启动项目,访问 http://localhost:8080/test/db。请观察控制台输出:
1 | ==> Preparing: INSERT INTO sys_user ... VALUES (?, ?, ?, ?, ?) |
现象解读:
- SQL 日志:可以看到
status被存为了1,extraInfo被存为了 JSON 字符串。 - 对象还原:还原后的 BO 中,
status变回了枚举ENABLE,extra变回了Map结构。
6.5. 本章总结与持久层映射速查
本章我们深入了业务核心层,解决了 BO(业务对象)与 PO(持久化对象)之间“结构不对等”的难题。通过引入 Hutool 工具库与 MSP 的 Expression 能力,我们将原本复杂的序列化逻辑压缩到了注解之中。
遇到以下 3 种持久化映射场景时,请直接 Copy 下方的标准代码模版:
6.5.1. 场景一:一行代码实现 JSON 序列化 (Map -> String)
需求:业务对象 BO 中是灵活的 Map 或 List,但数据库 PO 中存的是 JSON 字符串。
方案:使用 expression 配合 JSONUtil.toJsonStr。
1 | // 1. 核心:必须在 imports 中导入 JSONUtil 和 Map,否则编译报错找不到类 |
6.5.2. 场景二:一行代码实现 JSON 反序列化 (String -> Map)
需求:从数据库查出 JSON 字符串后,自动还原为 BO 中的 Map 对象。
方案:使用 @ReverseAutoMapping 配合 JSONUtil.toBean。
1 |
|
6.5.3. 场景三:枚举自动映射 (Enum <-> int)
需求:Java 代码中使用语义清晰的 Enum,数据库中使用节省空间的 TINYINT。
方案:使用 @AutoEnumMapper 指定取值字段。
1 |
|
第七章. MapStruct-Plus:多态视图(VO)与精细化输出
摘要:在上一章,我们完成了数据从业务层 (BO) 到持久层 (PO) 的双向流转。本章我们将视角转向“输出端”。在实际业务中,BO 处理完的数据往往需要转换为 VO (View Object) 才能返回给前端。本章我们将重点讲解如何利用 @AutoMappers 实现“一个 BO 对应多个 VO”,并利用 targetClass 精确控制 单向输出 时的特殊逻辑(如枚举转中文、手机号脱敏),避免产生不必要的双向映射冗余。
本章学习路径
- 架构回顾:明确 DTO(入) -> BO(核) -> PO(存) 与 PO(取) -> BO(核) -> VO(出) 的单向数据流。
- 多态配置:使用
@AutoMappers定义 BO 到 PO/VO 的多路映射。 - 精准输出:利用
targetClass实现仅针对 VO 的单向格式化逻辑(Enum -> String),拒绝过度设计。 - 闭环验证:验证数据库读取数据后,分别输出为“详情视图”和“列表视图”的效果。
7.1. 视图层设计:VO 只是“显示器”
在开始映射之前,我们需要明确 VO 的定位:它只是数据的“显示器”,只负责出,不负责进。因此,我们在设计 VO 映射时,只需要关注 BO -> VO 的正向过程,不需要考虑 VO -> BO 的逆向过程。
在绝大多数标准的业务架构中,VO (View Object) 仅作为 输出对象 回显给前端,前端提交数据时使用的是 DTO (Input Object)。
- 入站 (Write):
前端 (DTO)->Controller->Service (DTO转BO)->BO (业务处理)->Mapper (BO转PO)->数据库- 关注点:BO 到 PO 的转换(如 Map 转 JSON 串,Enum 转 int)。
- 出站 (Read):
数据库->Mapper->PO->Service (PO转BO)->BO (数据加工)->Controller (BO转VO)->前端 (VO)- 关注点:PO 到 BO 的还原(JSON 串转 Map),以及 BO 到 VO 的修饰(Enum 转中文描述,手机号脱敏)。
结论:
- PO <-> BO:必须是 双向 的(存进去,查出来)。
- BO -> VO:通常是 单向 的(只负责展示)。
7.1.1. 定义详情视图 (DetailVO)
详情页需要展示状态的中文含义,以及完整的扩展信息。
文件路径:src/main/java/com/example/demo/interfaces/vo/UserDetailVO.java
1 | package com.example.demo.interfaces.vo; |
7.1.2. 定义列表视图 (ListVO)
列表页需要对敏感数据进行脱敏。
文件路径:src/main/java/com/example/demo/interfaces/vo/UserListVO.java
1 | package com.example.demo.interfaces.vo; |
7.2. 核心映射:多态与规则隔离
这是本章的重点。UserBO 处于架构的核心位置,它左手连接数据库(PO),右手连接前端展示(VO)。
我们需要在 UserBO 上配置三种规则:
- 对 PO (双向):JSON 字符串与 Map 的互转(存取必备)。
- 对 DetailVO (单向):提取枚举的中文描述。
- 对 ListVO (单向):手机号脱敏。
文件路径:src/main/java/com/example/demo/domain/bo/UserBO.java
1 | package com.example.demo.domain.bo; |
7.2.1. 代码精简解析
经过优化,现在的代码逻辑非常清晰:
- 去除了冗余的反向映射:对于
phone和status,我们只配置了@AutoMapping(去 VO),删除了@ReverseAutoMapping。这符合 VO 只读的架构特性,代码量减少了一半。 - 保留了必要的双向映射:对于
extra字段,因为它是要存入数据库并读出来的,所以必须保留 PO 维度的双向转换(JSON <-> Map)。 targetClass的精准控制:status.desc的提取只会在生成UserDetailVO时发生。DesensitizedUtil的调用只会在生成UserListVO时发生。JSONUtil的调用只会在生成UserPO时发生。- 三者互不干扰,彻底解决了“多目标转换时的字段冲突”问题。
本节小结
- 架构先行:代码是为架构服务的。明确了 VO 仅用于输出的定位后,我们可以大胆砍掉 VO -> BO 的反向映射代码。
- 隔离原则:在
@AutoMappers场景下,习惯性地 为每一个@AutoMapping加上targetClass属性,是防止编译报错和逻辑混淆的最佳实践。 - 级联取值:
source = "status.desc"是处理“对象转字符串”(如枚举转中文、关联对象转名称)的神器,它能省去在 BO 中编写专门 Getter 方法的麻烦。
速查代码:
1 | // 单向输出模式:仅在转为 VO 时提取属性,无需反向逻辑 |
7.3. 表现层实战:模拟不同接口
有了安全的映射规则,我们将在 Controller 层模拟两个不同的接口,验证数据是否按预期“变形”。
7.3.1. 编写 Controller
文件路径:src/main/java/com/example/demo/controller/UserViewController.java
我们将构造一个包含完整隐私数据的 BO,验证它在通过不同视图输出时,是否做到了“该藏的藏,该显的显”。
1 | package com.example.demo.controller; |
7.3.2. 验证结果
启动项目,访问接口并观察控制台输出。
请求 1:列表视图GET /users/list-item
控制台输出:
1 | >>> 列表视图: UserListVO(username=Linus, phoneMask=138****8000) |
- 分析:
phone成功转换为phoneMask并脱敏。extra字段因 ListVO 中不存在而被自动忽略(且因为我们限制了 JSON 转换规则只对 PO 生效,所以不会报错)。
请求 2:详情视图GET /users/detail
控制台输出:
1 | >>> 详情视图: UserDetailVO(id=10086, username=Linus, phone=13800138000, statusDesc=启用, extra={vipLevel=SVIP}) |
- 分析:
status枚举被成功提取为中文 “启用”。phone保持原样(因为没有命中 ListVO 的脱敏规则)。extraMap 原样传递。
7.4. 本章总结与视图映射速查
本章我们构建了应用层的“最后一公里”,解决了 BO(业务对象)如何根据不同场景(列表 vs 详情)输出不同 VO(视图对象)的问题。核心在于理解 VO 的单向性 以及如何利用 targetClass 实现映射规则的物理隔离。
遇到以下 3 种视图层映射场景时,请直接 Copy 下方的标准代码模版:
7.4.1. 场景一:一源多配 (Polymorphism)
需求:一个 UserBO 需要同时映射给 UserPO (存库)、UserDetailVO (详情展示)、UserListVO (列表展示)。
方案:使用 @AutoMappers 数组包裹多个 @AutoMapper。
1 |
|
7.4.2. 场景二:级联取值 (Enum -> String)
需求:BO 中是 UserStatus 枚举对象,VO 中只需要展示它的中文描述 desc。
方案:使用 source 属性进行链式调用,配合 targetClass 限制生效范围。
1 | // BO 字段 |
7.4.3. 场景三:数据脱敏 (String -> String)
需求:列表页展示手机号时需要打码(如 138 **** 0000),详情页展示明文。
方案:使用 expression 调用 Hutool 工具类,配合 targetClass 隔离逻辑。
1 | // BO 字段 |
第八章. MapStruct-Plus:集合、流与分页
摘要:在前面的章节中,我们已经打通了单体对象(UserBO -> UserVO)的映射通道。但在现实业务中,我们更多时候是在处理“列表”。本章我们将基于已有的单体映射配置,通过实战解锁 MSP 的 自动集合映射 和 MyBatis-Plus 分页集成 能力,并结合 Java 8 Stream API 实现高效的数据清洗。
本章学习路径
- 数据准备:在 Service 层快速构建模拟批量数据,为实战做准备。
- 集合实战:无需新增任何注解,直接实现
List<BO>到List<VO>的转换。 - 流式结合:在 Stream 流处理中融入 Converter,实现“过滤+排序+转换”一条龙。
- 分页实战:体验 MSP 与 MyBatis-Plus 的深度集成,一行代码完成
Page对象的整体转换。
8.1. 准备工作:构建数据源
为了验证批量转换的效果,我们首先需要在 UserService 中模拟一些数据。为了专注于映射本身,我们暂时不操作数据库,而是直接在内存中生成对象。
请打开或新建 src/main/java/com/example/demo/service/UserService.java,添加以下逻辑:
1 | package com.example.demo.service; |
8.2. 场景一:自动集合映射 (List)
很多同学会有疑问:“我在第七章只定义了 UserBO 到 UserListVO 的一对一映射,现在我要转一个 List,需要再去写一个 toVOList 方法吗?”
答案是:完全不需要。
MapStruct Plus 的底层机制非常智能,它只要发现你定义了元素 A 到 B 的映射,就会自动支持 List<A> 到 List<B> 的转换。
8.2.1. 编写 Controller 验证
我们在 UserViewController 中增加一个接口,直接返回转换后的列表。
文件路径:src/main/java/com/example/demo/controller/UserViewController.java
1 | // ... 这里的 import 省略,保留原有的 Controller 类结构 |
8.2.2. 验证结果
启动项目,访问 http://localhost:8080/users/list/all。
观察响应:
1 | [ |
我们看到,虽然我们从未显式定义 List 的转换规则,但所有数据都成功转换成了 UserListVO,并且手机号都应用了脱敏规则。
8.3. 场景二:流式处理 (Stream + Convert)
实际业务往往更复杂:我们需要先过滤掉“禁用”的用户,再按“积分”排序,最后才输出 VO。这时,将 MSP 结合 Java 8 Stream API 使用是最佳实践。
MSP 的 converter 接口设计得非常符合函数式编程习惯,可以完美嵌入 map 操作中。
8.3.1. 编写带逻辑的转换代码
继续在 UserViewController 中添加接口:
1 |
|
8.3.2. 验证结果
访问 http://localhost:8080/users/list/active。
观察响应:
1 | [ |
结果中只剩下了 User_1, 3, 5。这证明了我们可以在数据流转的任意环节插入 converter,实现灵活的业务编排。
8.4. 场景三:分页映射 (IPage)
这是 Web 开发中最高频的场景。MyBatis-Plus 查询返回的是 IPage<UserPO>(或 BO),但前端接口文档要求返回 IPage<UserVO>。
由于 Java 的 泛型擦除 机制,直接尝试将 Page<UserBO> 强转为 Page<UserVO> 是极其危险的。为了保证类型安全并精确控制元数据,标准做法分为两步:
- 转换内容:提取
records列表,利用 MSP 进行批量转换。 - 重组对象:创建一个新的
Page对象,填入转换后的列表,并拷贝total、current等分页参数。
8.4.1. 模拟分页数据
回到 UserService,添加一个模拟分页返回的方法:
1 | // 模拟 MyBatis-Plus 的 selectPage 返回结果 |
8.4.2. 编写分页接口
在 UserViewController 中添加分页接口。这里我们展示最稳健的 “三步走” 写法:
1 |
|
8.4.3. 封装通用工具 (推荐)
虽然上面的代码很稳,但在每个 Controller 里都写这几行略显繁琐。我们可以封装一个简单的工具类来简化操作。
文件路径:src/main/java/com/example/demo/infrastructure/utils/PageUtils.java
1 | package com.example.demo.infrastructure.utils; |
Controller 调用优化:
1 |
|
8.4.4. 验证结果
访问 http://localhost:8080/users/page?current=1&size=10。
观察响应:
1 | { |
结果确认:
- 数据转换成功:
records中的字段已根据UserListVO的规则进行了脱敏。 - 结构保持一致:分页元数据完整保留。
- 零报错风险:完全遵循 Java 强类型规范,避开了运行时类型转换异常。
8.5. 本章总结与集合映射速查
本章我们攻克了批量数据处理的三大关卡:列表自动映射、Stream 流式编排以及 MyBatis-Plus 分页集成。
遇到以下 3 种批量场景时,请直接 Copy 下方的标准代码模版:
8.5.1. 场景一:普通 List 转换
需求:Service 返回 List<BO>,Controller 需要返回 List<VO>。
方案:直接调用 convert,MSP 自动支持集合遍历。
1 | List<UserBO> boList = service.findAll(); |
8.5.2. 场景二:Stream 流式处理
需求:在转换前需要进行过滤(Filter)、排序(Sorted)或去重。
方案:在 Stream.map 中嵌入 converter。
1 | List<UserVO> voList = boList.stream() |
8.5.3. 场景三:MyBatis-Plus 分页转换
需求:数据库查出 IPage<PO>,接口返回 IPage<VO>,且必须保留分页元数据。
方案:为了绝对的类型安全,建议解包后重组,或使用工具类。
1 | // 方式:手动解包重组 (最稳健) |
第九章. MapStruct-Plus:自定义转换器与生命周期回调
摘要:在前面的章节中,我们依靠 @AutoMapping 和 expression 解决了很多字段映射问题。但在面对复杂的业务逻辑时(例如:根据身份证号计算年龄、调用 Redis 补充数据、依赖多字段的联合判断),在注解里写 Java 代码会变得极难维护。本章我们将引入 MapStruct 的 自定义装饰器 (Decorator) 模式,利用 uses 属性和 @AfterMapping 生命周期钩子,以最优雅的 Java 原生代码方式解决复杂的转换需求。
本章学习路径
- 痛点分析:理解为什么
expression不适合处理超过 1 行的复杂逻辑。 - 装饰器模式:定义一个独立的 Spring Bean 作为转换辅助类,支持依赖注入。
- 生命周期挂载:使用
@AfterMapping在自动转换完成后“补刀”,执行自定义逻辑。 - 实战演练:通过身份证号(BO 字段)自动计算出年龄、性别和星座(VO 字段)。
9.1. 突破注解的局限
在第六章和第七章中,我们使用了类似 expression = "java(JSONUtil.toJsonStr(...))" 的写法。这对于单行静态调用非常完美,但当遇到以下场景时,这种写法就变成了噩梦:
- 逻辑复杂:包含
if-else分支、循环或异常处理。 - 依赖注入:转换过程中需要查询数据库或 Redis(例如:把
userId转为userName)。 - 多字段联动:目标字段的值依赖源对象中的多个属性计算得出。
这时,我们需要将逻辑剥离到专门的 Java 类中,而不是塞在字符串里。
9.2. 引入自定义映射类 (Mapper Uses)
MapStruct Plus 完全兼容 MapStruct 原生的 uses 特性。我们可以定义一个普通的 Java 类(甚至可以是 Spring Bean),然后在 @AutoMapper 中引用它。
9.2.1. 定义需求
假设 UserBO 中有一个身份证号字段 idCard。在转为 UserVO 时,我们需要自动计算出:
age(年龄)genderText(性别中文)constellation(星座)
这些字段在 BO 中都不存在,且计算逻辑较复杂,适合使用 Hutool 的 IdcardUtil。
9.2.2. 定义辅助类 (CustomMapper)
这是一个普通的 Spring 组件。注意,为了方便 MapStruct 调用,方法的参数需要遵循特定规则。
文件路径:src/main/java/com/example/demo/infrastructure/converter/UserCustomMapper.java
1 | package com.example.demo.infrastructure.converter; |
关键点解析:
@AfterMapping:这是 MapStruct 的核心注解,表示该方法会在主转换逻辑执行之后被调用。@MappingTarget:标记哪个参数是“转换结果”。在这里,target是已经被 MSP 填充了一半的 VO 对象。
9.3. 配置 BO 关联辅助类
现在我们有了 UserCustomMapper,需要告诉 UserBO:“在转换时,请带上这个帮手”。
我们需要修改 UserBO,在 @AutoMapper 中添加 uses 属性。
文件路径:src/main/java/com/example/demo/domain/bo/UserBO.java
我们需要先在 UserBO 中添加 idCard 字段,并在 UserDetailVO 中添加对应的展示字段。
步骤 1:更新 UserDetailVO
1 | // src/main/java/com/example/demo/interfaces/vo/UserDetailVO.java |
步骤 2:更新 UserBO 并配置 uses
1 | package com.example.demo.domain.bo; |
9.4. 实战验证:计算逻辑生效
我们更新 Controller,模拟一个带有身份证号的 BO,验证 VO 中是否自动生成了年龄和性别。
文件路径:src/main/java/com/example/demo/controller/UserDecoratorController.java
1 | package com.example.demo.controller; |
运行结果预期:
访问 http://localhost:8080/users/calc-info。
控制台输出:
1 | >>> 自定义转换逻辑执行完毕,计算结果:[年龄:24, 性别:男] |
(注:年龄会根据当前年份自动变化)
HTTP 响应:
1 | { |
可以看到,虽然 UserBO 里只有一串冷冰冰的数字字符串,但 UserDetailVO 里却展现出了丰富的结构化信息。
9.5. 本章总结与自定义逻辑速查
本章我们突破了注解开发的最后一道防线,掌握了 MapStruct 强大的 Decorator(装饰器)模式。通过引入外部 Java 类和生命周期钩子,我们让映射过程具备了处理复杂业务(如身份证计算、数据库反查)的能力。
遇到以下 2 种复杂转换场景时,请直接 Copy 下方的标准代码模版:
9.5.1. 场景一:复杂计算与填充 (@AfterMapping)
需求:转换完成后,需要根据 BO 的 idCard 字段,自动计算并填充 VO 的 age 和 gender 字段。逻辑太长,不适合写在 expression 里。
方案:定义 @Component 类,使用 @AfterMapping 钩子。
1 | // 1. 定义辅助类 (必须注册为 Bean) |
9.5.2. 场景二:注入 Spring Service (查库映射)
需求:BO 中只有 deptId,VO 需要展示 deptName。需要调用 DeptService 查询数据库。
方案:在辅助类中注入 Service。
1 |
|





