
Prorise
这是我的博客,分享技术与生活的点点滴滴
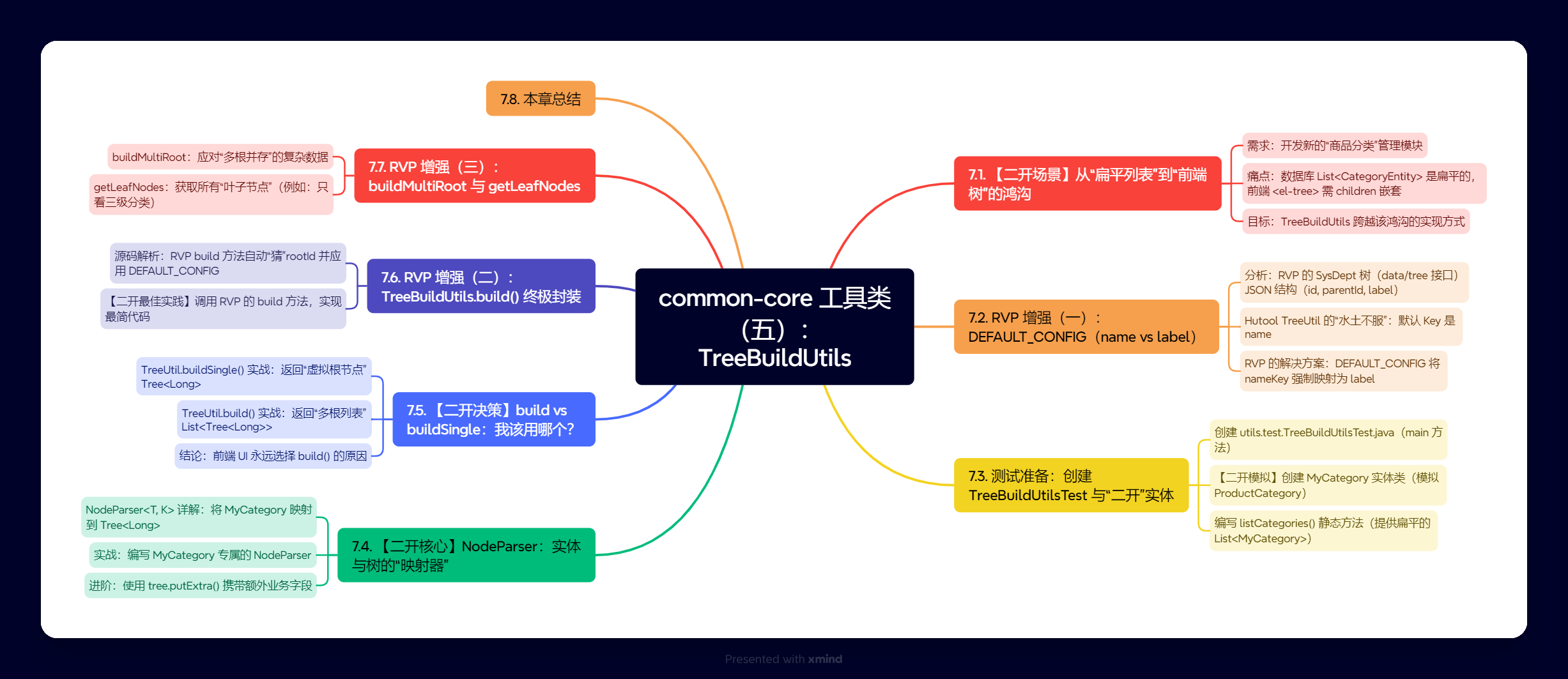
第七章. common-core 工具类(五):TreeBuildUtils 二开实战
第七章. common-core 工具类(五):TreeBuildUtils 二开实战
Prorise第七章. common-core 工具类(五):TreeBuildUtils 二开实战
摘要:本章我们将从“二次开发”的实战视角,深入 TreeBuildUtils。我们将模拟“新增商品分类”的需求,学习如何将数据库查出的“扁平列表”高效转换为前端 UI 所需的“树形 JSON”,并重点掌握 RVP 针对 Hutool TreeUtil 的核心增强。
在上一章中,我们深入剖析了 StringUtils,理解了 RVP 是如何通过“聚合”(继承 Apache Commons Lang3)和“增强”(内聚 Hutool StrUtil 和自研 isMatch)来构建其字符串工具集的。我们重点实战了 splitTo 和 isMatch 这两个 RVP 独有的核心功能。
现在,我们来看 utils 包的下一个内容,也是最具“后端特色”的工具类——TreeBuildUtils。在管理后台中,树形结构(如部门、菜单、商品分类)是无处不在的需求。TreeBuildUtils 就是 RVP 提供的,将“扁平”的数据库列表一键转换为“树形”JSON 结构的“神器”。
本章,我们 完全从“二次开发”的视角 出发,而不是罗列 API。我们的目标是模拟一个真实场景:“如果我们想为系统增加一个‘商品分类’功能,该如何使用 TreeBuildUtils 将数据库查出的 List<ProductCategory> 转换为前端 <el-tree> 需要的 JSON 结构?”
注意: 阅读此章需要您有对于前端 el-tree 的使用经验,如果没有,我们可以跳转至 Tree 树形控件 | Element Plus 进行基础预览
本章学习路径
7.1. 【二开场景】从“扁平列表”到“前端树”的鸿沟
在 ruoyi-demo 模块中,我们已经学习了如何做“商品”的 CRUD,但“商品分类”这种典型的树形结构该如何实现呢?
7.1.1. 需求:我们要开发一个新的“商品分类”管理模块
我们的需求很明确:在前端页面左侧显示一个“商品分类树”,用户可以点击树节点,右侧刷新该分类下的商品列表。
7.1.2. 痛点:数据库 List<CategoryEntity> 是扁平的,而前端 <el-tree> 需要 children 嵌套
这个需求立刻带来了一个经典的数据转换问题。
在数据库(后端):我们为了方便存储和查询,通常使用“父 ID”(
parent_id)来表示层级关系。当我们从数据库中查询商品分类时,得到的是一个扁平的列表结构。在前端 UI:像 Element Plus 的
<el-tree>或 Ant Design 的Tree这样的组件,它们的数据结构通常是需要嵌套的children数组来表示层级关系。
数据库 List<CategoryEntity> (我们拥有的)
从后端数据库中查询出来的商品分类列表,通常是下面这样的扁平化数组结构。每个对象都代表一个分类,通过 pId (父 ID) 来标识其父级分类。
1 | [ |
前端 <el-tree> JSON (我们想要的)
为了让前端的树形组件能够正确渲染出层级关系,我们需要将上面的扁平数组转换成下面这种嵌套的树形结构。每个对象中通过一个 children 数组来存放其所有的子分类。
1 | [ |
这个从“扁平”到“层级”的数据转换过程,是开发中常遇到的一个典型问题,可以通过递归或迭代等方式在后端或前端进行处理。
7.1.3. 目标:TreeBuildUtils 如何帮我们跨越这个鸿沟
要实现这个转换,我们需要自己写一套复杂的递归算法:
- 遍历列表,找到所有
pId == 0的根节点。 - 对每个根节点,再次遍历整个列表,找到所有
pId == 根节点ID的子节点。 - 对每个子节点,再递归执行第 2 步…
这个过程非常繁琐且极易出错。TreeBuildUtils 的核心价值,就是将这套复杂的递归算法封装成了一个黑盒。我们只需要把“扁平列表”丢给它,它就能自动吐出“嵌套树”。
7.2. RVP 增强(一):DEFAULT_CONFIG(name vs label)
在我们开始“二开”之前,必须先理解 RVP TreeBuildUtils 相比于 Hutool TreeUtil 做出的 第一个关键增强。
7.2.1. 分析:RVP 的 SysDept 树(data/tree 接口)JSON 结构
我们不妨碍学习一下 RVP 是怎么做的。打开 RVP 后台,F12 打开开发者工具,点击“系统管理” -> “用户管理”,在网络请求中找到 deptTree(或 treeselect)接口。
查看它的 JSON 响应:
1 | { |
我们发现,RVP 系统中(Element Plus UI)约定俗成的 显示字段是 label,而不是 name。
7.2.2. Hutool TreeUtil 的“水土不服”:Hutool 默认 Key 是 name
RVP 的 TreeBuildUtils 继承自 cn.hutool.core.lang.tree.TreeUtil。我们按住 Ctrl 点击 TreeUtil,下载源码后会发现 Hutool 的默认配置 TreeNodeConfig.DEFAULT_CONFIG:
1 | // 位于 Hutool 的 TreeNodeConfig.java |
这就是“水土不服”的根源:如果我们直接使用 Hutool 的 TreeUtil.build(),它会生成一个 name 字段。而我们的前端 <el-tree :props="{ label: 'label' }"> 需要的是 label 字段。这将导致前端树显示为 undefined。
7.2.3. RVP 的解决方案:DEFAULT_CONFIG 将 nameKey 强制映射为 label
RVP 的 TreeBuildUtils 优雅地解决了这个问题。我们打开 TreeBuildUtils.java 源码:
文件路径:ruoyi-common/ruoyi-common-core/src/main/java/org/dromara/common/core/utils/TreeBuildUtils.java
1 | public class TreeBuildUtils extends TreeUtil { |
这就是 RVP 的第一个核心增强:
- 它创建了一个 自己的 静态
DEFAULT_CONFIG。 - 它调用了 Hutool
DEFAULT_CONFIG的setNameKey("label")方法,创建了一个新配置对象。 - RVP
TreeBuildUtils封装的build方法,会强制使用这个DEFAULT_CONFIG。
这就保证了 RVP 体系内,所有通过 TreeBuildUtils 生成的树,其显示字段 永远是 label,完美适配前端 UI。
7.3. 测试准备:创建 TreeBuildUtilsTest 与“二开”实体
理解了 RVP 的“良苦用心”后,我们开始模拟“二开”商品分类。
7.3.1. 创建 utils.test.TreeBuildUtilsTest.java (main 方法)
和 StreamUtils 一样,TreeBuildUtils 也不依赖 Spring 容器,我们使用 main 方法测试。
文件路径:ruoyi-modules/ruoyi-demo/src/main/java/org/dromara/demo/utils/test/TreeBuildUtilsTest.java
1 | package org.dromara.demo.utils.test; |
7.3.2. 【二开模拟】创建 MyCategory 实体类
我们不能(也不该)在 demo 模块里直接依赖 system 模块的 SysDept。为了模拟我们的“商品分类”实体 (ProductCategory),我们直接在 TreeBuildUtilsTest 类中创建一个 静态内部类 MyCategory 来充当我们的 POJO。
1 | // ... |
关键点:我们的实体字段是 categoryId、parentCategoryId,这与 Hutool 默认的 id、parentId 完全不同。我们将在下一节展示如何处理这个“不匹配”。
7.3.3. 编写 listCategories() 静态方法
最后,我们模拟 myCategoryMapper.selectAll() 从数据库查出的“扁平列表”。
1 | // ... |
至此,我们的测试环境和“二开”模拟数据已全部准备就绪。
7.4. 【二开核心】NodeParser:实体与树的“映射器”
我们面临的第一个问题是:Hutool 的 TreeUtil 根本不认识我们的 MyCategory 类。它怎么知道 MyCategory.getCategoryId() 应该对应树节点的 id?它又怎么知道 MyCategory.getCategoryName() 应该对应 label?
NodeParser (节点解析器) 就是我们实现这个“映射关系”的“二开”接口。
NodeParser<T, K> 是 Hutool TreeUtil 中定义的一个函数式接口,T 是我们的原始数据类型(MyCategory),K 是 ID 的类型(Long)。
7.4.1. NodeParser<T, K> 详解
它只有一个需要我们实现的方法:void parse(T object, Tree<K> treeNode)
这个方法告诉我们:
- “我会遍历
List<MyCategory>,把每一个MyCategory对象(object)传给你。” - “我还会为你创建好一个 空的
Tree<K>节点(treeNode)。” - “你的工作:就是从
object中取值,然后set到treeNode中。”
7.4.2. 实战:编写 MyCategory 专属的 NodeParser
在 TreeBuildUtilsTest.java 中,我们来定义这个映射器。
1 | // ... |
运行 main 方法,控制台输出:
1 | ... INFO ... --- 1. 测试 Hutool Build (NodeParser) --- |
分析:成功了!我们通过 NodeParser 成功将 MyCategory 转换为了 Tree。但是,正如 7.2 节分析的,Hutool 默认生成的是 name 字段,而不是 RVP 前端需要的 label。
7.4.3. 进阶:使用 tree.putExtra() 携带额外业务字段
如果我们希望前端树节点上 附带一些 id/parentId/label 之外的业务字段(比如 orderNum 本身,或者 categoryType),NodeParser 也能做到。
我们修改 testHutoolBuild 中的 parser:
1 | // ... |
putExtra 的作用:它会在生成的 Tree 对象(本质上是个 Map)中,添加一个 extra 字段,extra 内部再存放你 put 进去的 K-V。(注:Hutool Tree 对象本身就是 extends LinkedHashMap,setId, setName 只是在 put("id", ...),putExtra 则是 put(key, value),但 Hutool 5.x 后 putExtra 是存入 extra Map 中)。
7.5. 【二开决策】build vs buildSingle:我该用哪个?
Hutool TreeUtil(TreeBuildUtils 也继承了)提供了两个核心的构建方法:
buildSingle(List<T> list, K rootId, ...):返回Tree<K>(一个对象)build(List<T> list, K rootId, ...):返回List<Tree<K>>(一个列表)
这在“二开”时会造成困惑:我该用哪个?我的 Controller 应该返回 Tree 还是 List<Tree>?
答案是:99% 的场景下,你都应该使用 build()。
7.5.1. TreeUtil.buildSingle() 实战:返回“虚拟根节点”
buildSingle 会创建一个 虚拟的根节点(你传入的 0L),然后把你真正的根节点(“电子产品”、“图书音像”)作为它的 children。
我们在 TreeBuildUtilsTest.java 中添加 testBuildSingle:
1 | // ... |
运行 main 方法,控制台输出:
1 | ... INFO ... --- 2. 测试 buildSingle (返回对象) --- |
7.5.2. TreeUtil.build() 实战:返回“多根列表”
build 则 不会 创建那个虚拟根节点。它会直接返回一个 只包含顶级节点(parentId == 0L)的列表。
7.5.3. 结论:为什么前端 UI 永远选择 build()
buildSingle 返回的对象结构 {"id": 0, "children": [...]} 并不是前端 <el-tree> 想要的。前端 <el-tree :data="treeData"> 想要的 treeData 是一个 数组 (List),就像 RVP deptTree 接口返回的 data: [ ... ] 一样。
结论:在“二开”中,我们应该总是调用 build() 方法,它返回的 List<Tree<K>> 才能被前端 UI 直接消费。
7.6. RVP 增强(二):build 终极封装(与“二开”陷阱)
build 方法我们选定了,但是 7.4 节的调用还是太复杂了:TreeUtil.build(list, 0L, TreeNodeConfig.DEFAULT_CONFIG, parser)
我们需要传 4 个参数,包括 0L(根 ID)和 Hutool 的 Config。
RVP TreeBuildUtils 提供了一个 两参数 的 build 方法,试图简化这个调用。
7.6.1. 源码解析:RVP build 方法(与“二开”陷阱)
我们来看 RVP TreeBuildUtils.java 的源码:
1 | // 位于 RVP 的 TreeBuildUtils.java |
分析 RVP 的 build 封装:
- 优点:自动应用了
DEFAULT_CONFIG(label映射)。 - 【“二开”陷阱】:它通过 硬编码反射
list.get(0).getParentId()来自动猜测根 ID。
这对我们的“二开”意味着什么?
我们的 MyCategory 实体,父 ID 字段叫 parentCategoryId,不叫 parentId!如果我们调用 RVP 这个两参数的 build 方法,ReflectUtils.invokeGetter(...) 会因找不到 getParentId() 方法而 崩溃。
7.6.2. 【二开最佳实践】
RVP 还提供了另一个 三参数 的 build 方法,它没有那个“自作聪明”的反射:
1 | // 位于 RVP 的 TreeBuildUtils.java |
这就是“二开”的最佳实践:
- 我们 不 使用 RVP 的两参数
build方法,因为它有硬编码。 - 我们 使用 RVP 的三参数
build方法,它同时满足了:- 自动应用
DEFAULT_CONFIG(name->label)(RVP 增强)。 - 允许我们安全地传入
0L作为根 ID(Hutool 功能)。 - 允许我们传入自定义的
NodeParser(“二开”核心)。
- 自动应用
我们在 TreeBuildUtilsTest.java 中添加 testRvpBuild:
1 | // ... |
运行 main 方法,控制台输出:
1 | ... INFO ... --- 3. 测试 RVP Build (最佳实践) --- |
完美!
- 根节点是
List<Tree>(✔) - 显示字段是
label(✔) - 额外字段
extra也成功代入 (✔) - 我们避开了 RVP
build两参数方法的反射陷阱 (✔)
7.7. RVP 增强(三):buildMultiRoot 与 getLeafNodes
这两个方法提供了在特定“二次开发”场景下非常有用的高级能力,专门用于处理不规则的树形数据。
7.7.1. 场景一:buildMultiRoot (构建多根树)
如果我的数据压根没有统一的 0 作为根节点怎么办?
想象一个场景,你的 MyCategory 列表可能是这样的:
[ {id: 1, pId: -1, name: "数码"}, {id: 2, pId: -1, name: "图书"}, {id: 10, pId: 1, name: "手机"} ]
这里有两个根节点(它们的pId都是-1)。如果调用build(list, -1L, ...),它会正确返回一个包含“数码”和“图书”的列表。
但如果数据是下面这样混乱的情况呢?
[ {id: 1, pId: -1, name: "数码"}, {id: 2, pId: -2, name: "图书"}, {id: 10, pId: 1, name: "手机"} ]
此时,根节点的parentId都不统一!build(list, ???, ...)方法直接“抓瞎”了,我们无法提供一个固定的rootId。
buildMultiRoot 就是为了解决这个痛点而生。我们来看它的源码(TreeBuildUtils.java):
1 | public static <T, K> List<Tree<K>> buildMultiRoot(List<T> list, Function<T, K> getId, Function<T, K> getParentId, NodeParser<T, K> parser) { |
逻辑分析:buildMultiRoot 的逻辑非常巧妙。它基于一个核心假设:如果一个 parentId 在所有节点的 id 列表里都找不到,那它必定是一个“虚拟根节点的 ParentId”。通过这个方法,它能自动帮你找出 -1 和 -2,然后分别执行 build(list, -1L, ...) 和 build(list, -2L, ...),最后把两棵树的结果合并(flatMap)成一个 List 返回给你。
结论:当你的数据源不规范,存在多个不同
parentId的根节点时,buildMultiRoot是你的“救星”,但我们一般不会用这个方法,这是一个亡羊补牢的补救方法
7.7.2. 场景二:getLeafNodes (获取所有叶子节点)
我如何只获取树的“最后一级”节点?
例如,在“商品分类”管理中,我们常常需要一个“只看叶子类目”的筛选功能。因为业务规定,商品 只能 挂在叶子类目下(例如,你不能把商品挂在“电子产品”上,必须挂在“智能手机”这个具体的、最底层的分类上)。
getLeafNodes 就为此而生。它会递归遍历一棵(或多棵)树,将所有 children 属性为空(或 null)的节点筛选出来,汇总成一个列表。
1 | public static void testGetLeafNodes() { |
运行 main 方法,控制台输出:
1 | 叶子节点名称 [智能手机, 笔记本电脑, 科技图书] |
分析:从结果中可以看到,“电子产品”、“图书音像”、“手机” 这些非叶子节点都被成功过滤掉了。getLeafNodes 精准地找到了所有“最后一级”的分类。
7.8. 本章总结
在本章中,我们 严格地从“二次开发”的视角 而非罗列 API 的视角,完成了对 TreeBuildUtils 的深度实战。
我们以“新增商品分类”的需求为背景,推导并验证了一套在 RVP 体系下的 树构建最佳实践:
定义实体 (
MyCategory)
你的实体类(POJO/VO)字段可以 任意命名,例如categoryId,parentCategoryId等,无需遵循Tree对象的字段名。定义映射器 (
NodeParser)
这是“二开”的 核心。我们必须提供一个NodeParser实现,它负责将MyCategory的getCategoryId()、getParentCategoryId()、getCategoryName()等方法的值,set到Tree对象的setId()、setParentId()、setName()等标准字段上。携带自定义数据 (
putExtra)
在NodeParser的实现中,使用treeNode.putExtra("key", value)来携带任意前端需要的 额外业务字段,如orderNum,status等。调用三参数
build方法
在 Controller 或 Service 中,始终调用TreeBuildUtils.build(list, rootId, parser)。- 为什么用 RVP 的
build? 因为它内置了DEFAULT_CONFIG,能自动将setName()映射为前端组件(如 Element UI)普遍需要的label字段。 - 为什么用三参数(带
rootId)? 因为 RVP 的两参数build方法存在 硬编码反射parentId字段的陷阱,不适用于我们“二开”的自定义实体。
- 为什么用 RVP 的
最后,我们还掌握了 RVP 提供的两个高级工具:buildMultiRoot(用于处理不规范的多根数据)和 getLeafNodes(用于提取所有叶子节点),它们能在特定场景下极大地提升开发效率。
掌握了 TreeBuildUtils,你就掌握了 RVP 后台管理系统中所有“树形结构”的构建秘诀。






