
Prorise
这是我的博客,分享技术与生活的点点滴滴
OpenWebUi-模型连接与管理
OpenWebUi-模型连接与管理
Prorise3.2. 模型连接与管理
模型连接是 Open WebUI 最核心的配置。没有模型,Open WebUI 就无法工作。
连接本地 Ollama
如果你在本地运行了 Ollama,需要在 Open WebUI 中配置连接。
步骤 1:进入连接设置
管理员面板 → 设置 → 外部连接(Connections)
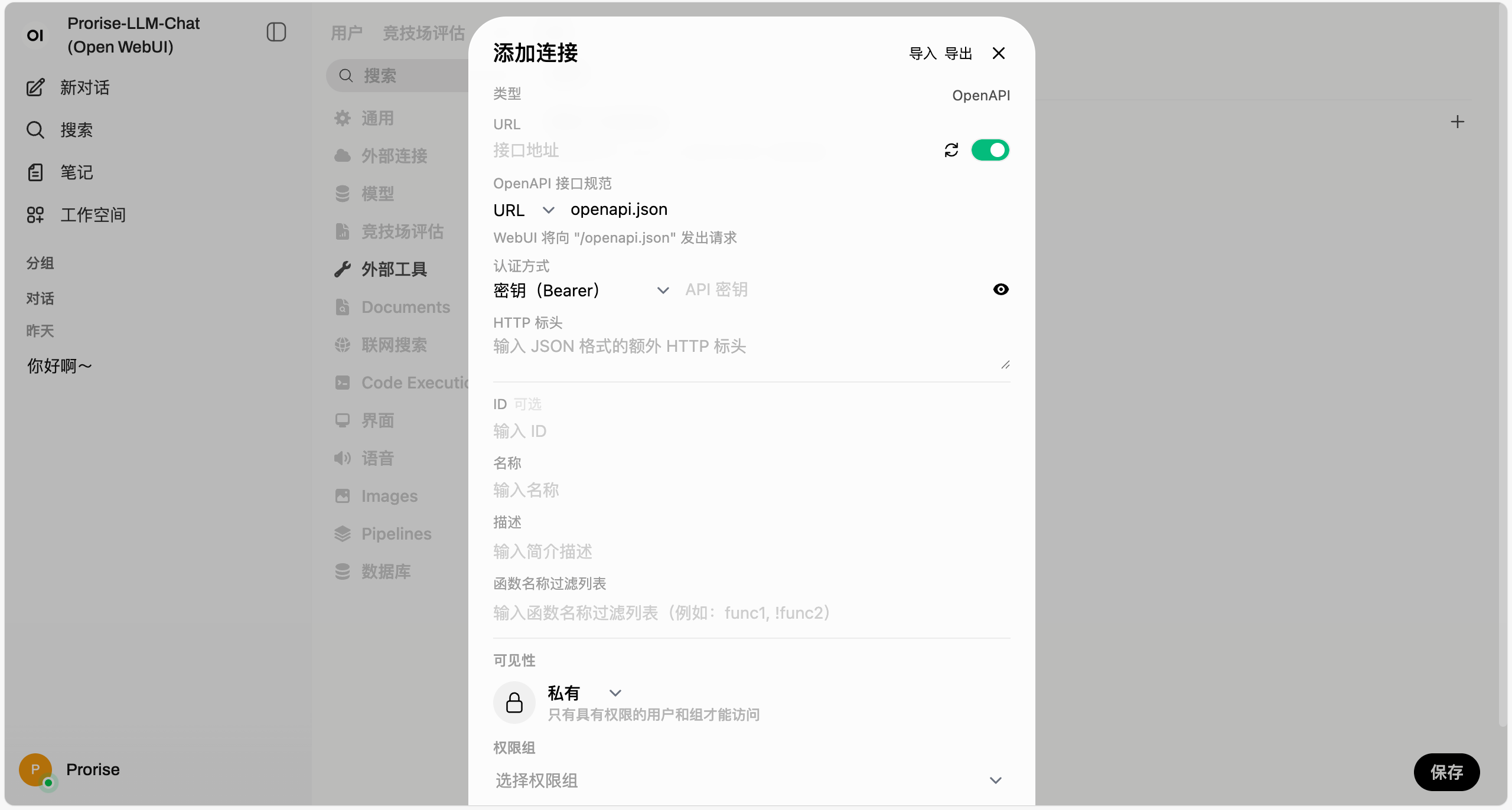
步骤 2:配置 Ollama API URL
在 “Ollama API URL” 字段中填入:
| 部署方式 | URL |
|---|---|
| Docker 部署(Ollama 在主机) | http://host.docker.internal:11434 |
| Docker Compose(Ollama 在容器) | http://ollama:11434 |
| Python 安装(Ollama 在主机) | http://localhost:11434 |
步骤 3:验证连接
点击 URL 输入框右侧的刷新按钮(🔄)。
如果连接成功,下方会显示 “连接成功” 的提示,并且会自动拉取 Ollama 中的模型列表。
步骤 4:配置多个 Ollama 实例(可选)
如果你有多台服务器运行 Ollama,可以添加多个连接。Open WebUI 会自动进行负载均衡。
点击 “添加 Ollama 实例” 按钮,填入新的 URL,例如:
http://192.168.1.100:11434
http://192.168.1.101:11434
这样,当用户发起请求时,Open WebUI 会自动选择负载较低的实例。
连接 OpenAI API
如果你想使用 OpenAI 的 GPT 模型,需要配置 OpenAI API。
步骤 1:获取 API 密钥
访问 OpenAI 官网:https://platform.openai.com/api-keys
登录后,点击 “Create new secret key” 创建一个新的 API 密钥。
重要:API 密钥只会显示一次,请妥善保存。
步骤 2:在 Open WebUI 中配置
管理员面板 → 设置 → 外部连接 → OpenAI
| 字段 | 值 | 说明 |
|---|---|---|
| API Base URL | https://api.openai.com/v1 | OpenAI 官方 API 地址 |
| API Key | sk-... | 你的 API 密钥 |
步骤 3:验证连接
点击刷新按钮,如果连接成功,会自动拉取可用的模型列表(如 gpt-4、gpt-3.5-turbo 等)。
步骤 4:配置代理(如果需要)
如果你的网络无法直接访问 OpenAI,可以配置代理:
在 Docker 部署中,添加环境变量:
1 | environment: |
或者使用国内的 OpenAI API 中转服务(需要自行寻找可靠的服务商)。
连接其他兼容 API
Open WebUI 支持任何兼容 OpenAI API 格式的服务,包括:
| 服务商 | API Base URL 示例 | 说明 |
|---|---|---|
| Azure OpenAI | https://your-resource.openai.azure.com/ | 需要额外配置 API 版本 |
| Anthropic Claude | https://api.anthropic.com/v1 | 需要 Claude API 密钥 |
| Google Gemini | 通过兼容层 | 需要使用 LiteLLM 等工具转换 |
| DeepSeek | https://api.deepseek.com/v1 | 国内可直接访问 |
| Groq | https://api.groq.com/openai/v1 | 速度极快的推理服务 |
| 本地 vLLM | http://localhost:8000/v1 | 自建推理服务 |
配置步骤:
管理员面板 → 设置 → 外部连接 → OpenAI → 点击 “+” 添加新连接
填写:
- 名称:给这个连接起个名字(如 “DeepSeek”)
- API Base URL:服务商的 API 地址
- API Key:对应的 API 密钥
Azure OpenAI 特殊配置:
Azure OpenAI 需要额外配置 API 版本和部署名称。在 API Base URL 中包含这些信息:
1 | https://your-resource.openai.azure.com/openai/deployments/your-deployment-name?api-version=2024-02-15-preview |
模型可见性与权限控制
默认情况下,所有用户都能看到所有模型。但在团队使用场景中,你可能希望控制哪些用户能访问哪些模型。
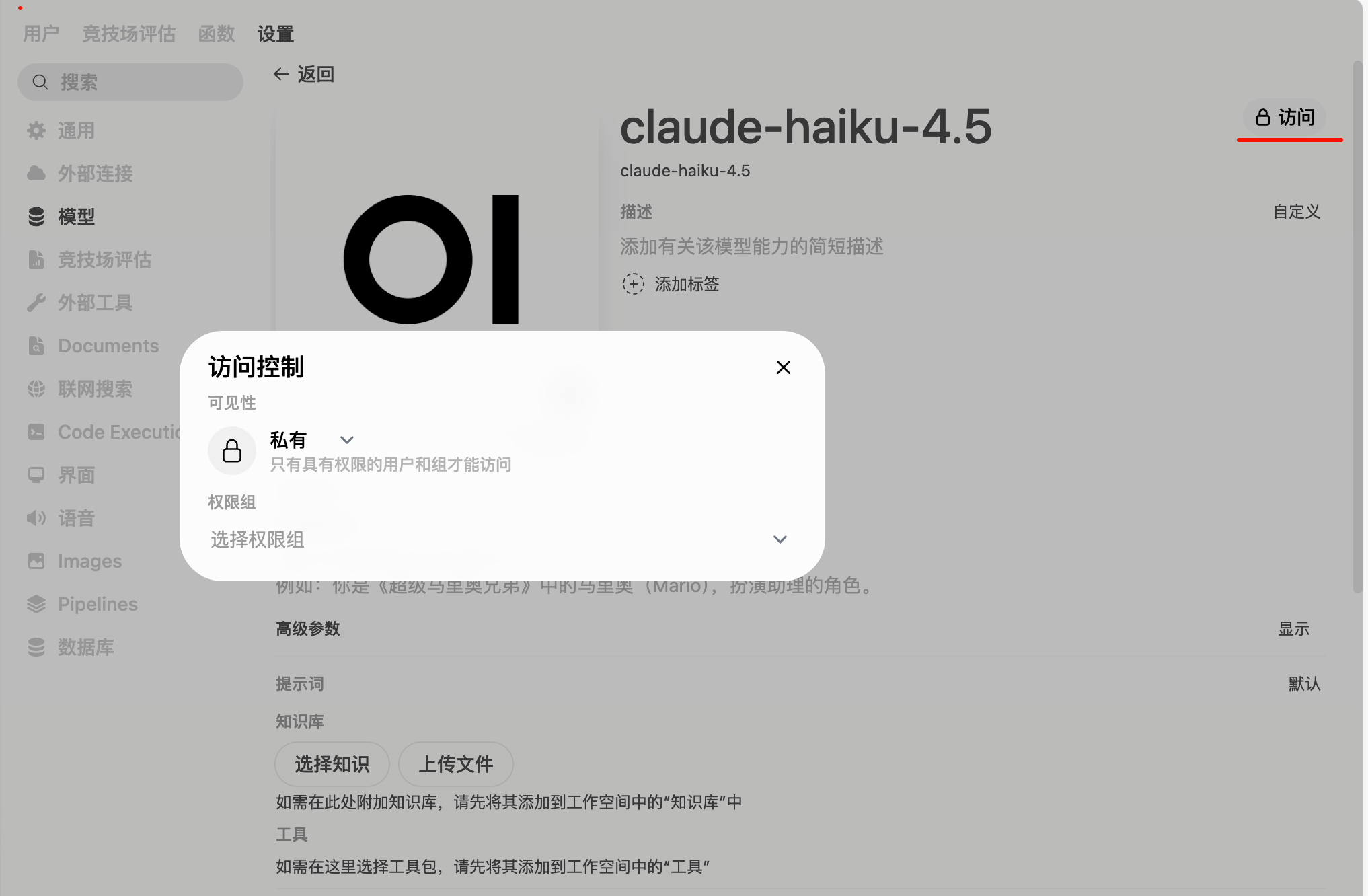
步骤 1:进入模型设置
管理员面板 → 设置 → 模型(Models)
步骤 2:编辑模型
找到你想要控制的模型,点击右侧的编辑按钮(✏️)。
步骤 3:设置可见性
在模型编辑页面,你会看到以下选项:
| 选项 | 说明 |
|---|---|
| 公开(Public) | 所有用户都能看到和使用 |
| 私有(Private) | 只有管理员能看到 |
| 指定用户 | 只有选中的用户能看到 |
| 指定权限组 | 只有选中的权限组能看到 |
选择合适的可见性,然后点击保存。
实际应用场景:
- 将昂贵的 GPT-4 模型设为 “指定用户”,只给核心团队成员使用
- 将实验性模型设为 “私有”,只有管理员测试
- 将免费的本地模型设为 “公开”,所有人都能使用
模型白名单
如果你连接了多个 API,可能会拉取到很多模型。你可以使用白名单功能,只显示需要的模型。
步骤 1:进入设置
管理员面板 → 设置 → 模型(Models)
步骤 2:启用白名单
找到 “模型白名单” 选项,启用它。
步骤 3:添加模型
在白名单中添加你想要显示的模型 ID,每行一个:
1 | gpt-4 |
保存后,只有白名单中的模型会显示给用户。
模型标签与排序
为了让用户更容易找到合适的模型,你可以给模型添加标签和自定义排序。
添加标签:
在模型编辑页面,找到 “标签(Tags)” 字段,添加标签:
1 | 推荐, 快速, 免费 |
或
1 | 高级, 付费, GPT-4 |
用户在选择模型时,可以通过标签筛选。
自定义排序:
在设置 → 模型页面,你可以拖动模型来调整顺序。排在前面的模型会优先显示给用户。
最佳实践:
- 将最常用的模型排在最前面
- 将免费模型和付费模型用标签区分
- 将不同能力的模型分类(如 “对话”、“编程”、“翻译”)
模型参数预设
你可以为每个模型设置默认参数,用户使用时会自动应用这些参数。
步骤 1:编辑模型
设置 → 模型 → 点击模型的编辑按钮
步骤 2:配置参数
在 “模型参数” 区域,设置以下参数:
| 参数 | 说明 | 推荐值 |
|---|---|---|
| Temperature | 控制输出的随机性,0-2 | 0.7(平衡) |
| Top P | 核采样参数,0-1 | 0.9 |
| Max Tokens | 最大输出长度 | 2048 |
| Context Length | 上下文窗口大小 | 4096 |
| Frequency Penalty | 降低重复内容,-2 到 2 | 0 |
| Presence Penalty | 鼓励新话题,-2 到 2 | 0 |
参数说明:
Temperature:
- 0.1-0.3:输出非常确定,适合事实性任务(如翻译、总结)
- 0.7-0.9:平衡创造性和准确性,适合日常对话
- 1.0-2.0:输出更有创造性,适合创意写作
Top P:
- 0.9:推荐值,保持输出质量
- 0.95:更多样化的输出
- 1.0:完全随机(不推荐)
Context Length:
- 对于 Ollama 模型,默认是 2048,这太小了
- 建议设置为 8192 或更高,特别是使用 RAG 功能时
- 注意:更大的上下文会消耗更多内存





