
Prorise
这是我的博客,分享技术与生活的点点滴滴
Python(十一):第十章: 模块与包
Python(十一):第十章: 模块与包
Prorise第十章: 模块与包
模块是 Python 中组织代码的基本单位,本质上是一个包含 Python 定义和语句的文件。本文将深入探讨模块与包的概念、使用方法以及高级应用技巧,结合 PyCharm 中的包管理最佳实践。
10.1 模块分类
在 Python 生态系统中,模块可以分为三大类:
| 模块类型 | 说明 | 示例 |
|---|---|---|
| 内置模块 | Python 解释器自带的标准库模块 | os, sys, math, datetime |
| 第三方模块 | 社区开发者创建的模块 | numpy, pandas, requests |
| 自定义模块 | 开发者自己创建的模块 | 项目中自定义的.py 文件 |
重要提示:首次导入自定义模块时,Python 会执行该模块中的所有顶层代码。每个模块都有自己的名称空间,模块中定义的变量属于该模块的名称空间。
10.2 模块导入方式
10.2.1 导入整个模块
1 | import module_name |
10.2.2 从模块导入特定内容
1 | from module_name import function_name, variable_name |
工作原理:使用
from方式导入时,被导入的对象会直接引用模块中对应变量的内存地址,可以直接使用而无需模块前缀。
10.2.3 导入时重命名
1 | ## 模块重命名 |
10.2.4 导入所有内容(不推荐)
1 | from module_name import * |
注意:这种方式可能导致命名冲突,不利于代码可读性和维护性。在大型项目中应避免使用。
10.3 控制模块导入
我们可以在每一个模块的 __init__ 文件中使用如下的操作
可以使用 __all__ 列表来控制 from module import * 语句导入的内容:
1 | ## 在模块文件中定义 |
10.4 模块的特殊属性
10.4.1 __name__ 属性
每个 Python 文件都有一个 __name__ 属性:
- 当直接运行该文件时,
__name__的值为'__main__' - 当作为模块被导入时,
__name__的值为模块名
这个特性可用于编写既可作为模块导入,又可独立运行的代码:
1 | ## 模块内的代码 |
10.4.2 From 模块无法识别问题
Python 在导入模块时会按照一定顺序搜索模块文件,在有些情况下我们自己定义的模块不一定会被检测到如下列图片:

例如,当我们的模型层期望用到另外一个 包 的代码时,往往会这样引入:
1 | from ecommerce_system.ecommerce.interfaces.payment import PaymentProcessor |
但这样是无法被识别到的,我们应该是需要这样做:
- 1.标记外层的包为根包
- 2.去掉 ecommerce_system 前缀
这样 Pycharm 就会检测到我们是在这个包下进行操作的,即可识别到
从我们的根包出发,也就是图片中蓝色的包(这个是需要在 IDEA)手动标注的

10.5 包的概念与使用
包是一种特殊的模块,它是一个包含 __init__.py 文件的目录,用于组织相关模块。包可以包含子包和模块,形成层次结构。
10.5.1 包的结构示例
1 | mypackage/ |
10.5.2 __init__.py 文件的作用
- 标识目录为包:Python 将包含
__init__.py的目录视为包 - 初始化包:在导入包时执行初始化代码
- 定义包的公共接口:通过
__all__列表指定from package import *时导入的内容 - 自动导入子模块:可以在
__init__.py中导入子模块,使它们在导入包时可用
示例 __init__.py:
1 | ## mypackage/__init__.py |
10.5.3 包的导入方式
10.5.3.1 导入包中的模块
1 | ## 完整路径导入 |
10.5.3.2 导入包中特定内容
1 | from mypackage.module1 import function1 |
10.5.4 相对导入与绝对导入
10.5.4.1 绝对导入
从项目的顶级包开始导入:
1 | from package_name.module_name import function_name |
10.5.4.2 相对导入
使用点号表示相对位置:
.module_name:当前包中的模块..module_name:父包中的模块...module_name:祖父包中的模块
1 | ## 在mypackage.subpackage.module3中导入同级模块 |
注意:相对导入只能在包内使用,不能在顶级模块中使用。相对导入基于当前模块的
__name__属性,而直接运行的脚本的__name__总是'__main__'。
10.6 高级应用技巧
10.6.1 动态导入
在运行时根据条件动态导入模块:
1 | ## 方法1:使用__import__ |
10.6.2 延迟导入
推迟导入耗时模块,直到真正需要时才导入,可以加快程序启动速度:
1 | def function_that_needs_numpy(): |
10.6.3 使用 __slots__ 优化内存
在模块级别的类中使用 __slots__ 限制属性,提高内存效率:
1 | class DataPoint: |
10.7 包的发布与安装
创建自己的包并发布到 PyPI:
10.7.1 创建 setup.py 文件
1 | from setuptools import setup, find_packages |
10.7.2 打包与上传
1 | ## 安装打包工具 |
10.7.3 安装包
1 | pip install mypackage |
10.8 PyCharm 中的包管理
PyCharm 提供了强大的图形界面来管理 Python 包,让包的安装和管理变得简单高效。
10.8.1 使用 Python Packages 工具
在 PyCharm 中管理包的最简单方法是使用内置的 Python Packages 工具:

- 点击底部的 Python Packages 标签打开包管理器
- 在搜索框中输入要安装的包名称
- 点击包右侧的 Install 按钮安装包
- 已安装的包会显示在 Installed 标签下,可以查看版本并进行升级或卸载操作
10.8.2 更改 PyCharm 的 pip 源
默认的 PyPI 源在国内访问可能较慢,可以更换为国内镜像以提高下载速度:
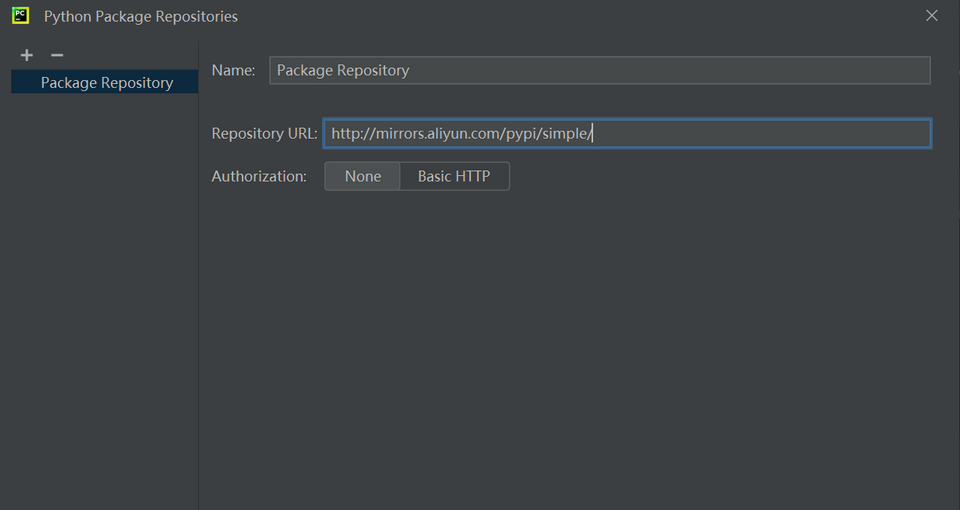
- 在 Python Packages 界面点击左上角的齿轮图标
- 点击 “+” 按钮添加新的软件源
- 输入国内镜像源地址,例如:
10.8.3 使用 Project Interpreter 管理包
除了 Python Packages 工具外,还可以通过 Project Interpreter 设置管理包:

- 进入 File > Settings > Project > Python Interpreter
- 点击 “+” 按钮添加新包
- 在弹出窗口中搜索并安装需要的包
10.8.4 导出和导入项目依赖
在团队开发中,共享项目依赖非常重要。PyCharm 提供了方便的方式来管理 requirements.txt 文件:
10.8.4.1 导出依赖
推荐使用 pipreqs 工具导出仅项目使用的依赖包:
1 | ## 安装pipreqs |
提示:
--force参数会强制覆盖已存在的 requirements.txt 文件,--encoding=utf8确保使用 UTF-8 编码处理文件。
10.8.4.2 导入依赖
在 PyCharm 的 Terminal 中执行:
1 | pip install -r requirements.txt |
或者指定国内镜像源:
1 | pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ |
10.8.5 使用虚拟环境
PyCharm 支持多种虚拟环境管理工具,如 Virtualenv、Pipenv 和 Conda:

- 创建新项目时选择虚拟环境类型
- 对于现有项目,可以在 File > Settings > Project > Python Interpreter 中配置
- 点击齿轮图标,选择 “Add…”,然后选择合适的虚拟环境类型
10.8.5.1 虚拟环境工具对比
| 工具 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| Virtualenv | 轻量级,易于使用 | 需要手动维护 requirements.txt | 简单项目 |
| Pipenv | 自动管理依赖,有锁文件 | 比 Virtualenv 慢 | 中型团队项目 |
| Conda | 同时管理 Python 版本和包 | 占用空间大 | 数据科学项目 |
10.9 模块开发最佳实践
10.9.1 模块组织
- 相关功能放在同一个模块中
- 单个模块不要过大,保持在 1000 行以内
- 使用子模块和子包组织复杂功能
- 使用清晰的命名约定,避免与标准库和流行第三方库冲突
10.9.2 导入顺序
遵循 PEP8 建议的导入顺序:
1 | ## 1. 标准库导入 |
10.9.3 文档化模块和包
为模块、类和函数编写清晰的文档字符串:
1 | """ |









