
Prorise
这是我的博客,分享技术与生活的点点滴滴
一次由 23G 巨型日志引发的服务器雪崩:从磁盘 100% 到 Java 死循环复盘
一次由 23G 巨型日志引发的服务器雪崩:从磁盘 100% 到 Java 死循环复盘
Prorise第一章: 一次由 23G 巨型日志引发的服务器雪崩:从磁盘 100% 到 Java 死循环复盘
问题现象:
起初是图库后台频繁报错,用户反馈图片无法上传,随后监控面板显示服务器系统盘(Root Partition)占用率飙升至 100%。进一步排查发现,Redis 服务因无法写入磁盘而崩溃,Java 后端服务响应极其缓慢甚至未响应,整个业务陷入瘫痪状态。
1.1. 排查历程:抽丝剥茧
初步诊断:扩容误区
面对磁盘告警,第一反应是“空间不够了”。我们紧急购买并挂载了一块 50GB 的数据盘。然而,挂载后发现系统盘(/dev/vda4)依然是 100% 满载。教训: 新买的硬盘像一个新仓库,如果不手动迁移数据,旧仓库里的垃圾依然会把门堵死。

深入排查:寻找“真凶”
通过 SSH 进入服务器,使用 df -h 确认根目录爆满。接着在 /www/wwwroot 下执行 du -sh *,惊讶地发现业务代码目录仅占用 1.2G。这说明“吃”掉 40G 空间的不是业务文件。我们将排查范围扩大到全盘,最终在项目目录下发现了一个惊人的文件:pro_admin_jar.log,大小高达 23.14 GB!
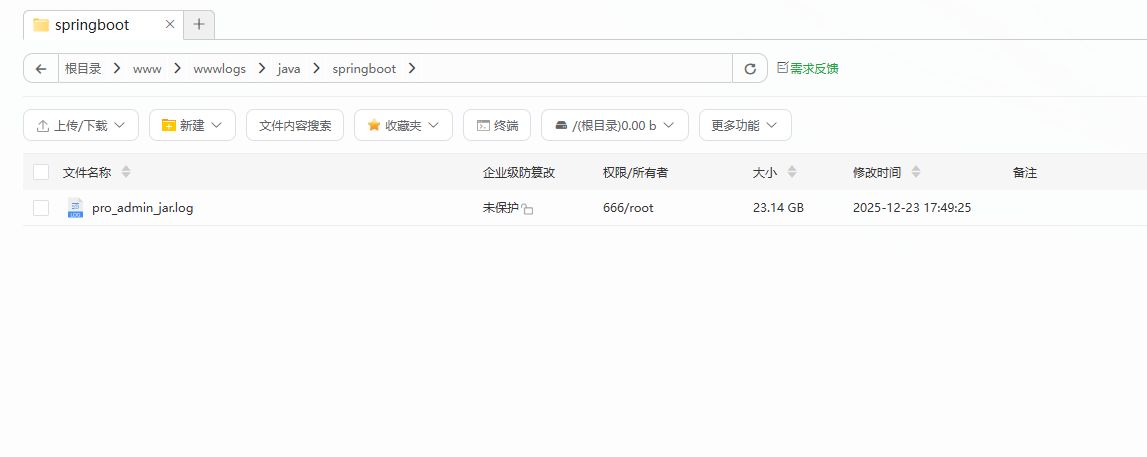
柳暗花明:死循环揭秘
面对巨大的日志文件,我们不敢直接打开,而是使用 tail -n 50 pro_admin_jar.log 查看末尾。屏幕上疯狂刷屏着 Communications link failure 和 Connection refused。
真相浮出水面:由于磁盘空间不足或系统保护机制,MySQL 进程挂掉了。Java 程序连接数据库失败,抛出异常 -> 异常堆栈被打印到控制台 -> 写入日志文件 -> 日志撑爆磁盘 -> MySQL 更起不来 -> Java 疯狂重试。这是一个完美的死循环。
1.2. 根因分析与最终解决方案
根本原因:
这是一起典型的 不规范启动命令 导致的运维事故。
Java 项目在宝塔面板中的启动命令使用了 nohup java -jar xxx.jar > pro_admin_jar.log 2>&1 & 这种形式。这会将 标准输出(stdout) 和错误信息全部重定向到一个物理文件中,且 没有任何日志切割策略。当系统出现异常(如 DB 宕机)导致报错刷屏时,该文件会无限膨胀,直到耗尽所有 inode 或磁盘空间。
解决方案:
- 止血:不直接删除文件(防止句柄占用不释放),而是清空文件内容:
echo "" > pro_admin_jar.log。 - 恢复:释放空间后,重启 MySQL 服务,确保数据库连接恢复正常。
- 根治:修改启动命令,采用“黑洞模式”。丢弃标准输出,只依赖框架内部(如 Logback/Log4j)生成规范的、按天切割的业务日志。
修改后的宝塔启动命令:
1 | # 核心变更:将 > pro_admin_jar.log 修改为 > /dev/null |
1.3. 总结与反思:沉淀经验
核心收获:
- 永远不要信任 stdout: 生产环境禁止将 Java 的标准输出重定向到单一文件,必须使用
/dev/null,日志的事情交给日志框架(Logback/Log4j)去处理。 - 扩容不是万能药: 硬件扩容只能缓解症状,找到占用空间的“烂代码”或“烂日志”才是根治之道。
- 关联效应: 磁盘满了往往不是终点,它会引发数据库崩溃、Redis 无法持久化等连锁反应,排查时要具备全局视角。
可落地的改进措施:
| 检查项 | 描述 |
|---|---|
| 启动命令审查 | 检查所有 nohup 启动脚本,确保结尾是 > /dev/null 2>&1。 |
| 日志策略 | 确认 logback-spring.xml 中配置了 RollingFileAppender,日志必须按天切割并限制最大保留天数(如 30 天)。 |
| 监控告警 | 为服务器磁盘设置 80% 阈值告警,为 MySQL 进程设置存活监控。 |





