
Prorise
这是我的博客,分享技术与生活的点点滴滴
第十九章. 任务调度-Snail Job-企业级分布式调度与工作流
第十九章. 任务调度-Snail Job-企业级分布式调度与工作流
Prorise第十九章. 任务调度 (Snail Job): 企业级分布式调度与工作流
摘要:本章我们将深入 RVP 5.x 架构中一个强大的组件——Snail Job 任务调度中心。RuoYi 4.x 版本在任务调度与工作流编排上的缺失,在 5.x 中得到了彻底的补强。我们将学习 Snail Job 的三大核心功能:定时任务、重试任务与工作流,并掌握其架构、配置与使用。
注意: 我们这一章节不会深入实现一系列任务,这都需要编写代码,我们只需要对他有一个简单了解即可
本章学习路径
我们将按照以下路径,从架构理念到功能实操,全面掌握 Snail Job:
%20%E4%BC%81%E4%B8%9A%E7%BA%A7%E5%88%86%E5%B8%83%E5%BC%8F%E8%B0%83%E5%BA%A6%E4%B8%8E%E5%B7%A5%E4%BD%9C%E6%B5%81.png)
19.1. 核心理念与架构
在深入配置任务之前,我们必须先理解 Snail Job 的运行模式。它不是一个简单的“Cron 库”,而是一个完整的、分布式的“调度服务端”,用于统一指挥和调度所有业务应用(客户端)。
19.1.1. 登录调度中心与界面概览
首先,我们必须确保 ruoyi-snailjob-server 模块已成功启动。该模块是独立于主业务 (ruoyi-admin) 的调度服务端。
启动后,在 RuoYi-Vue-Plus 界面点击“系统监控” -> “任务调度中心”,即可打开 Snail Job 的登录页。
默认凭证:
- 用户名:
admin - 密码:
admin
登录后,我们进入主概览页面。顶部最关键的元素是 命名空间切换,它允许我们在 development (开发) 和 production (生产) 等不同环境间切换。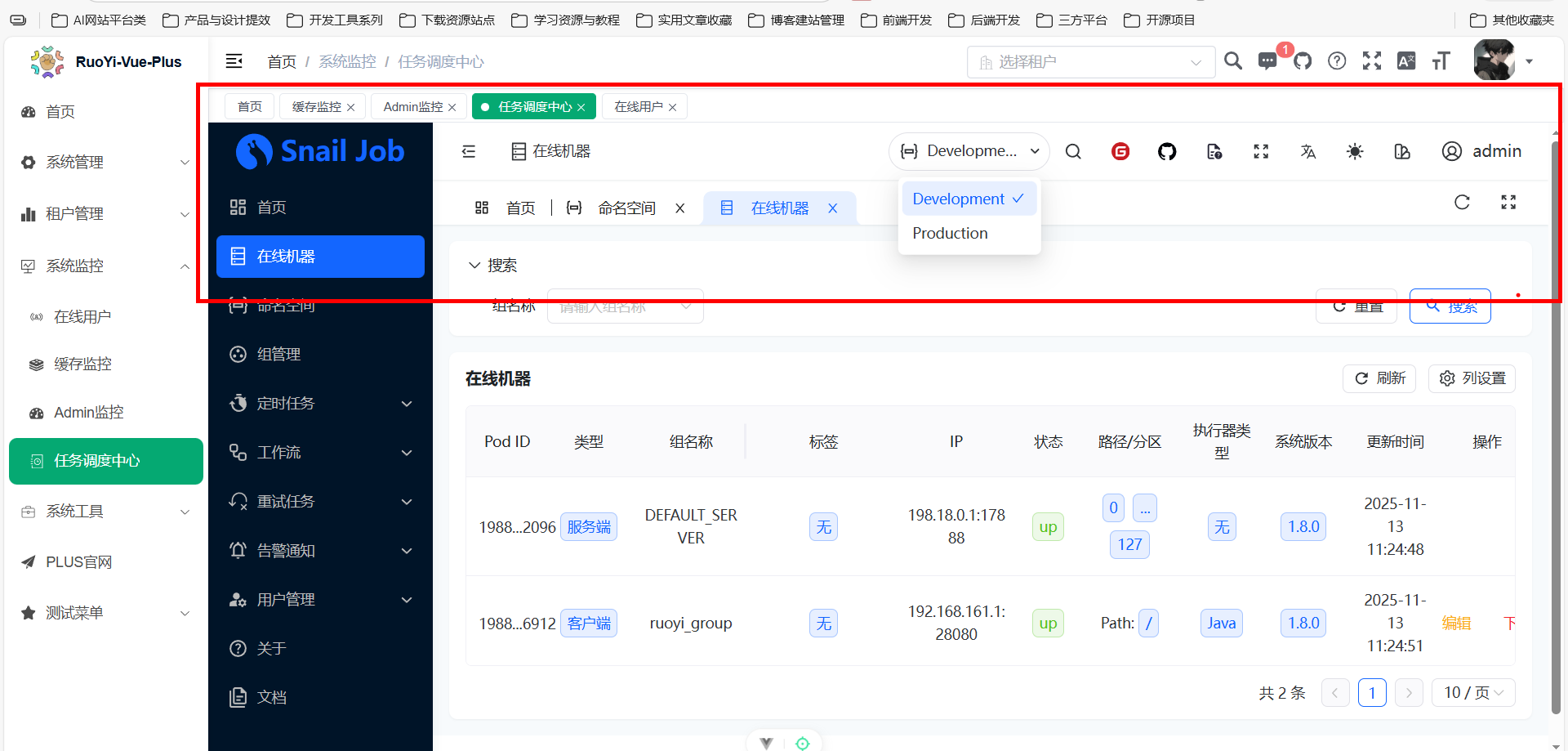
19.1.2. [核心] 三大功能:定时、重试与工作流
Snail Job 提供了三大核心能力,解决了传统单体调度(如 Quartz)在分布式和业务编排上的短板:
| 核心功能 | 解决的痛点 | 核心价值 |
|---|---|---|
| 定时任务 | Quartz 在分布式集群中的配置复杂,难以统一管理和监控。 | 提供统一的 UI,管理所有业务集群的定时任务,并提供丰富的路由策略。 |
| 重试任务 | 外部接口调用因网络抖动瞬时失败,需要复杂的代码来重试。 | 自动化的失败重试机制,将业务从“瞬时故障”中解放出来,保障任务最终成功。 |
| 工作流 | 多个任务间有复杂的依赖关系(如 A-> B-> C),难以编排。 | 提供可视化拖拽界面,将多个定时任务编排成一个“有向无环图”(DAG)。 |
19.1.3. 架构解析:Server 与 Client 的 Netty 通信
Snail Job 采用的是 服务端/客户端 (Server/Client) 架构模式。
- Snail Job Server (服务端):
ruoyi-snailjob-server模块。职责是“发号施令”,存储任务信息、管理客户端列表、按时触发调度。 - Snail Job Client (客户端):内嵌在
ruoyi-admin模块中。职责是“执行任务”,向 Server 注册自身,接收 Server 的调度指令并执行具体的业务代码(Java 方法)。
Server 和 Client 之间并非使用 HTTP 通信,而是采用 Netty 进行了长连接交互,以实现高性能的调度和实时日志回传。
核心端口约定:
| 组件 | 交互方式 | 默认端口 | 说明 |
|---|---|---|---|
ruoyi-snailjob-server | HTTP 服务 | 8800 | Admin UI 界面访问端口 |
ruoyi-snailjob-server | Netty 服务 | 17888 | [关键] 等待 Client 连接的端口 |
ruoyi-admin (Client) | HTTP 服务 | 8080 | 业务应用端口 |
ruoyi-admin (Client) | Netty 服务 | 28080 | [关键] 客户端 Netty 端口(默认 20000 + 8080) |
19.1.4. [重点] 命名空间 (Namespace):隔离开发与生产
“命名空间”是 Snail Job 中最重要的 环境隔离 机制。
痛点:在没有命名空间时,开发环境(development)和生产环境(production)可能会共用同一个调度中心数据库。这会导致开发人员的测试任务在生产环境中被执行,引发灾难。
解决方案:Snail Job 通过命名空间将所有数据(包括任务、执行日志、客户端机器列表)进行 物理隔离。
- 我们在
development空间下创建的任务,对production空间完全不可见。 - 部署到生产环境的
ruoyi-admin客户端,其配置中应指定连接production命名空间。
⚠️ 停!先思考 5 秒
切换命名空间后,为什么首页的“定时任务”和“在线机器”数量都清零了?
答案:因为数据是 物理隔离 的。development 和 production 是两套完全独立的数据,切换后看到的“清零”状态,是 production 空间下的真实情况(即尚未配置任何任务或客户端)。
19.1.5. 组管理 (Group):服务隔离与 Token 认证
如果说“命名空间”隔离的是“环境”,那么“组”隔离的就是“服务”或“项目”。
一个“组” (Group) 通常代表一个独立的服务集群(例如 ruoyi-order-service 或 ruoyi-user-service)。在 RVP 中,默认使用 ruoyi-vue-plus 作为组名。
核心配置:Token
在组的管理界面,有一个关键配置 Token。这个 Token 必须与 Snail Job Client(即 ruoyi-admin 的 application.yml)中配置的 snail-job.token 完全一致。
文件路径:ruoyi-admin/src/main/resources/application-dev.yml
1 | --- # snail-job 配置 |
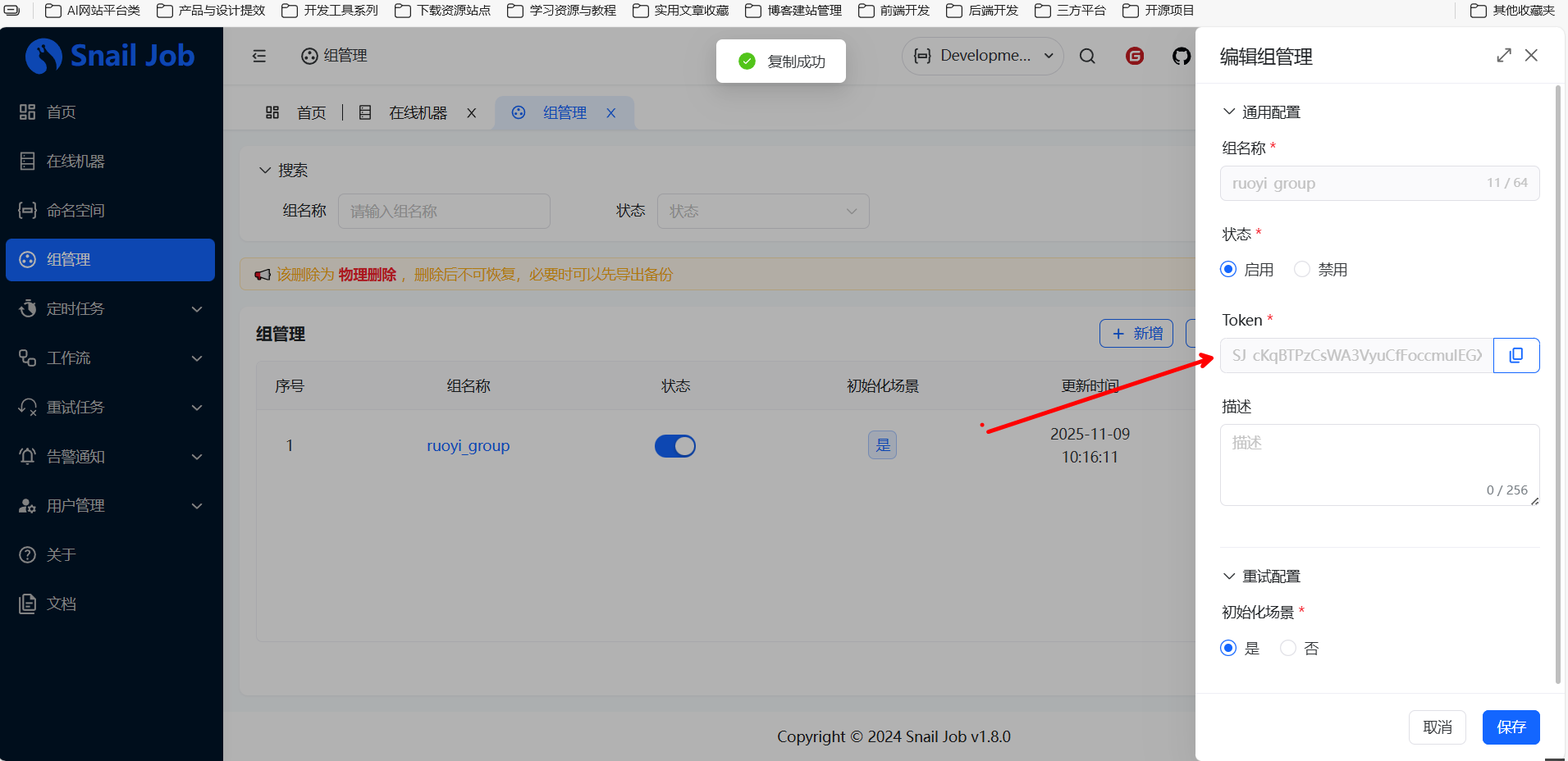
如果 Token 不一致,Server 端会拒绝 Client 的注册请求,导致客户端无法接收调度任务。
19.1.6. 本节小结
我们理解了 Snail Job 的 Server/Client 架构、三大核心功能以及两大隔离机制(命名空间与组)。
核心要点
- Snail Job 是一个独立的 Server,通过 Netty 与内嵌在业务应用中的 Client 通信。
- 三大功能是:定时任务、重试任务、工作流。
- “命名空间”用于隔离“环境”(如 dev vs prod)。
- “组”用于隔离“服务”,并通过
Token进行身份认证。
19.2. 核心功能(一):定时任务
在上一节中,我们已经掌握了 Snail Job 的整体架构。现在,我们开始深入其最基础、最常用的功能——定时任务管理。这相当于一个分布式的、可视化的 Cron 任务管理器。
19.2.1. 任务创建:核心参数详解
在“定时任务” -> “任务管理”中,点击“新增”,我们会看到创建任务的表单。
| 核心参数 | 含义与说明 |
|---|---|
| 组名称 | 选择该任务属于哪个服务集群(如 ruoyi-vue-plus)。 |
| 任务名称 | 任务的业务描述(如“每日用户数据统计”)。 |
| 执行器类型 | 通常选择 Java,表示执行一个 Java 方法。 |
| 执行器名称 | [核心] 对应 Client 端(ruoyi-admin)代码中 @Job 注解修饰的方法名。 |
| 方法参数 | 传递给上述 Java 方法的参数(字符串形式)。 |
| 任务类型 | 集群:任务只在集群中的 一台 机器上执行。广播:任务在集群中的 所有 机器上同时执行。 |
执行器名称 (Executor Name) 是如何关联的?
我们可以假设我们模块中,有一个示例任务:
1 | package org.dromara.job.snailjob; |
要在 UI 上调度这个方法,执行器名称 就必须填写 demoJob。
19.2.2. [重点] 调度策略:路由与阻塞
当任务类型选择为“集群”(Cluster) 时,Server 端需要决定“集群中有多台机器,到底由哪一台来执行?”,这就是 路由策略。
| 路由策略 | 决策逻辑 |
|---|---|
| 轮询 | 按顺序在集群中选择一台机器执行。 |
| LRU | Least Recently Used。选择“最近最少被调用”的机器。 |
| 随机 | 随机选择一台机器。 |
| 一致性哈希 | 根据任务 ID 进行哈希,确保同一个任务尽可能落在同一台机器上。 |
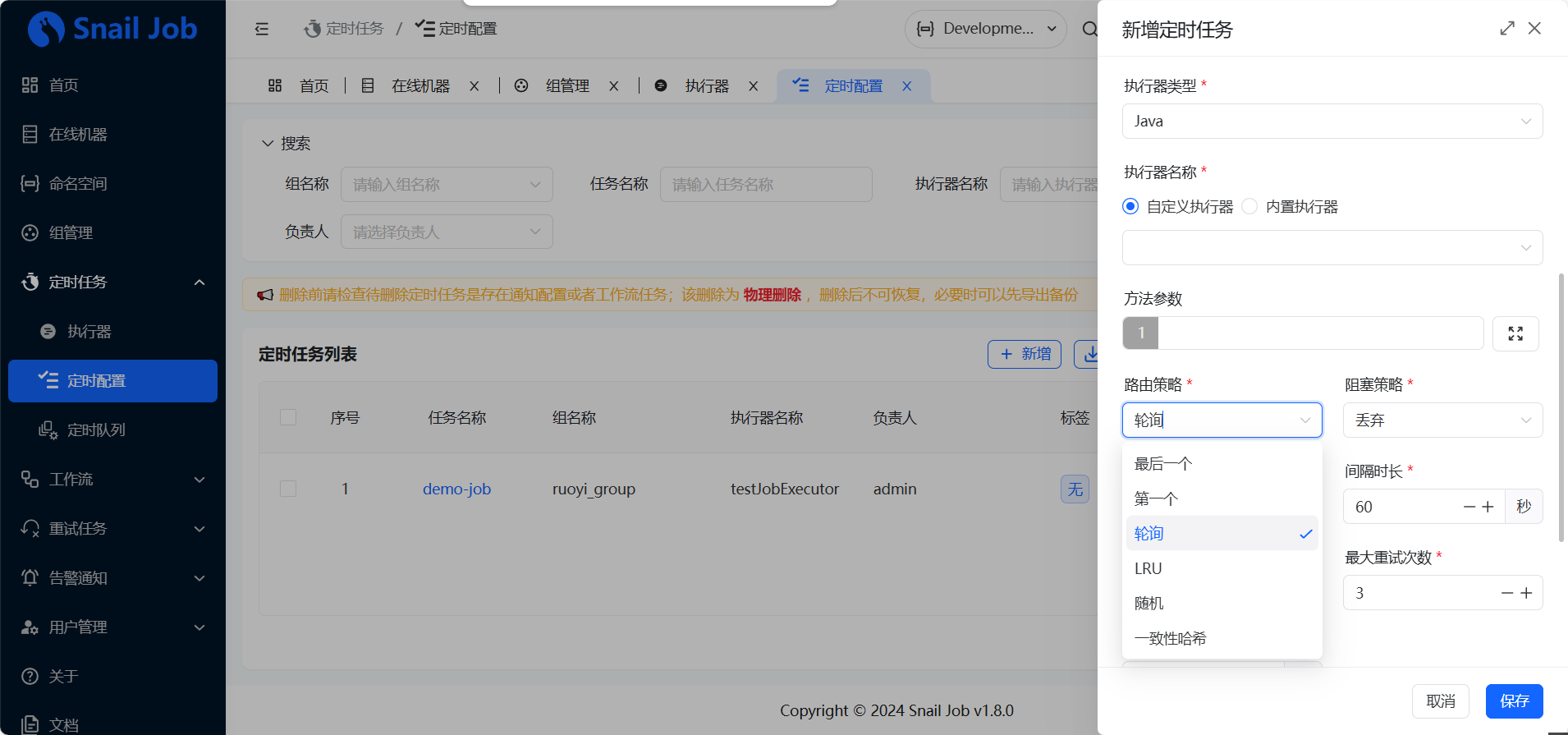
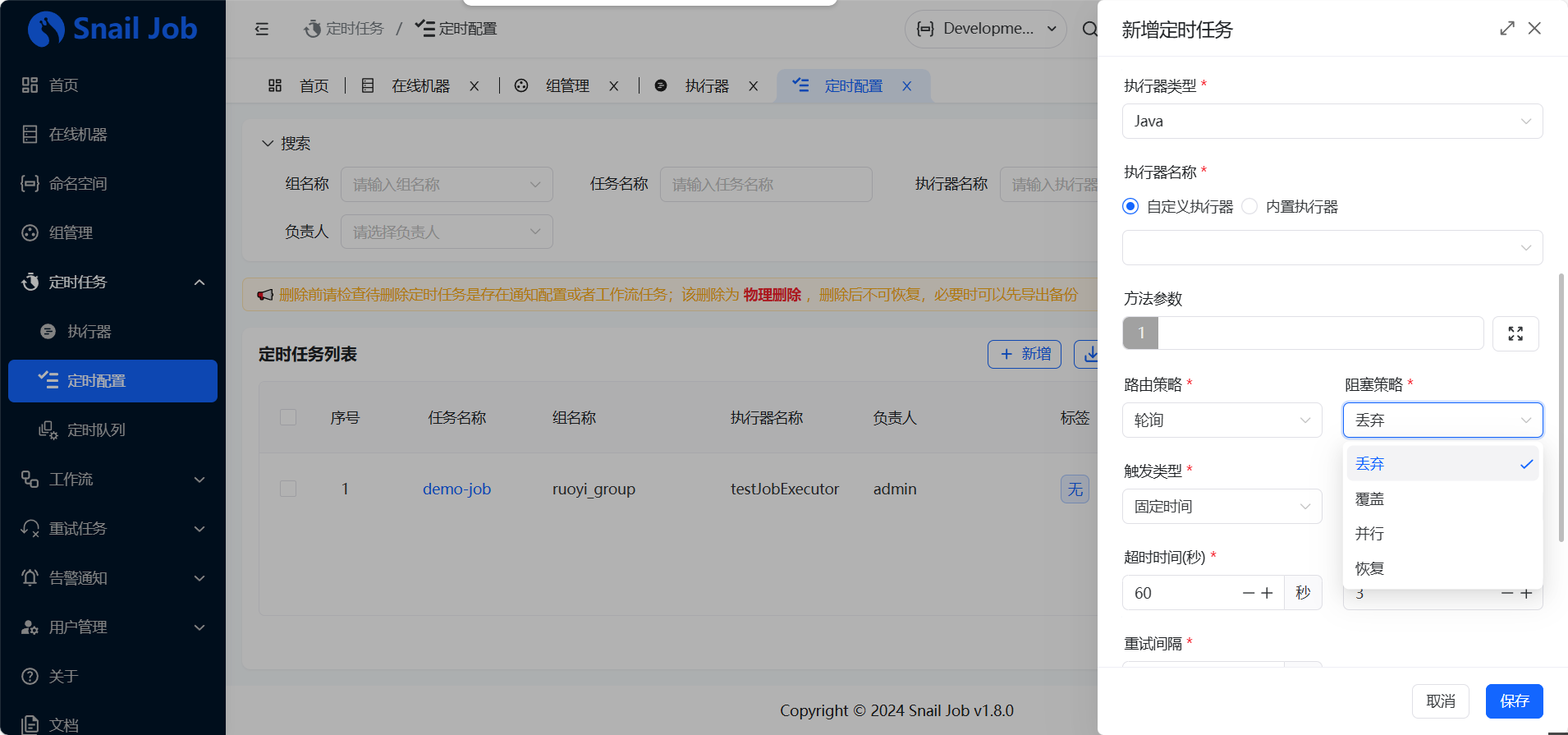
同时,如果一个任务的执行时间很长(如 5 分钟),但调度间隔很短(如 1 分钟),就会发生任务重叠。阻塞策略 决定了如何处理这种情况。
| 阻塞策略 | 决策逻辑 |
|---|---|
| 丢弃 | (Discard) 本次任务重叠,丢弃本次调度,等待下次。 |
| 覆盖 | (Cover) 停止上一个正在运行的任务,执行本次任务。 |
| 并行 | (Parallel) 不管上一个任务是否完成,都立即开始执行本次任务。 |
19.2.3. 触发机制:Cron 表达式与固定间隔
Snail Job 提供了四种触发类型,但我们只需要关注最核心的两种:
- 固定时间:例如,设置“60 秒” (s),任务将每 60 秒执行一次。
- Cron 表达式:用于定义复杂的定时规则(注意不是 “clone”)。
0 0 2 * * ?:每天凌晨 2 点执行。0/10 * * * * ?:每 10 秒钟执行一次。

19.2.4. 定时队列 (Batch):集群日志的查看
在“定时任务” -> “定时队列”中,我们可以看到所有的任务执行记录。
这里有一个重要概念:“队列” 。为什么不叫“日志”?因为在集群环境下,一次调度(一个批次)可能会在多台机器上执行(例如“广播”任务)。这个“批次”是父记录,它 聚合了 本次调度中所有相关机器的执行日志。
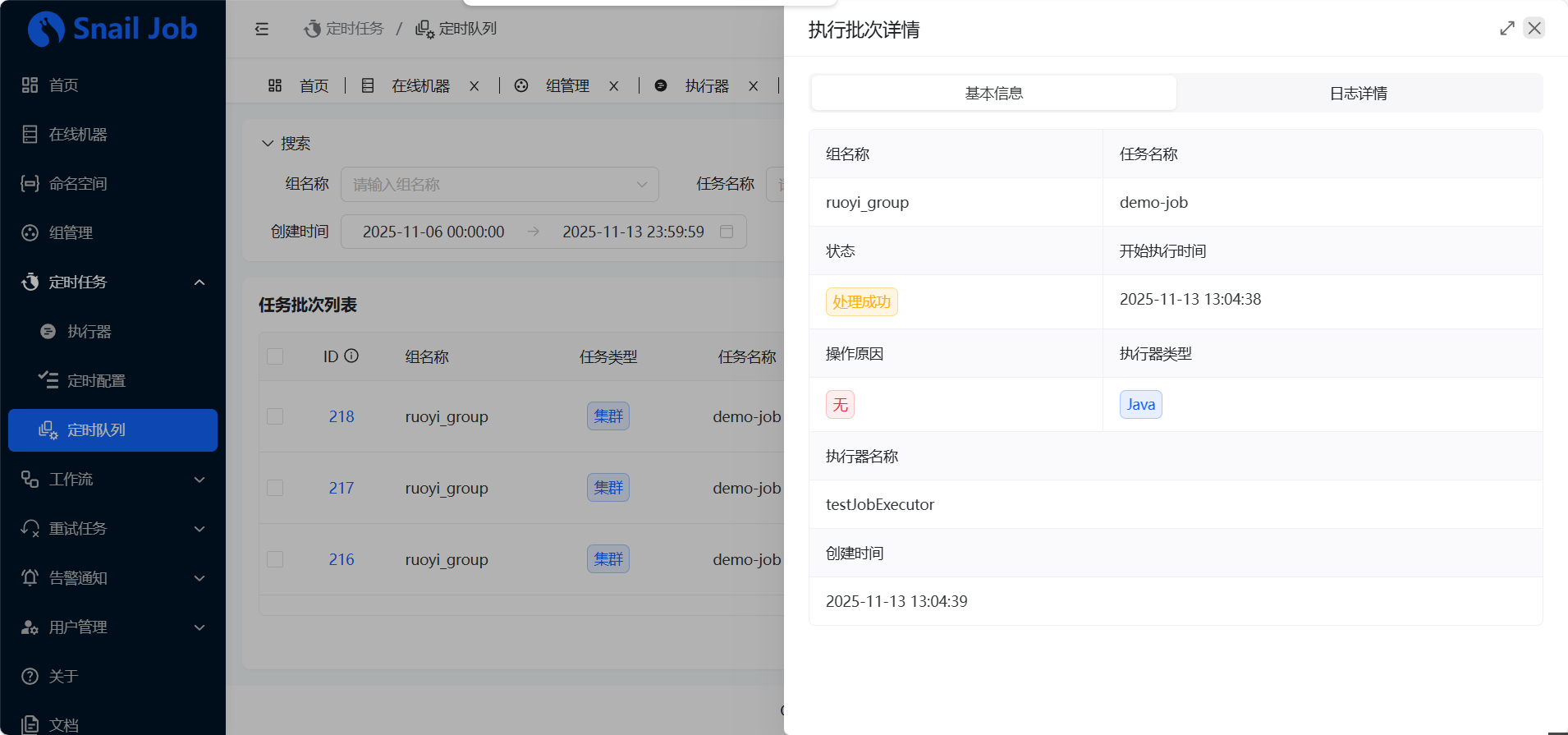
点击批次 ID,我们可以看到详情,如果任务在多台机器上运行,这里会列出所有机器的地址及其对应的执行日志。
19.2.5. 本节小结
我们掌握了定时任务的创建、执行器(Java 方法)的关联、集群环境下的路由与阻塞策略,以及如何查看执行批次日志。
核心要点
- “执行器名称”是核心,它必须与 Client 端 Java 代码中
@Job(name = "...")的值一致。 - “集群”任务只执行一次,“广播”任务在所有机器上执行。
- “路由策略”解决“哪台机器执行”的问题;“阻塞策略”解决“任务重叠”的问题。
- “执行批次”是聚合了集群中所有机器执行日志的父记录。
19.3. 核心功能(二):工作流 (Workflow)
在上一节中,我们已经掌握了如何调度和执行 单个 的定时任务。但在复杂的业务场景中,任务之间往往存在依赖关系。例如,必须先执行“任务 A:拉取订单数据”,A 成功后,才能执行“任务 B:统计订单报表”,如果 A 失败,则需要执行“任务 C:发送失败告警”。
这种对任务的 编排,就是“工作流”功能的核心价值。
19.3.1. 工作流的价值:可视化任务编排
Snail Job 的工作流提供了一个可视化的拖拽界面,允许我们将多个独立的“定时任务”组合成一个有向无环图 (DAG)。
我们不再需要用代码去硬编码复杂的依赖逻辑,而是通过“拖拽”和“连线”来定义业务流程。
19.3.2. 节点详解(一):任务节点
在工作流画布中,最基础的单元是“任务节点”。
当我们拖入一个“任务节点”时,需要配置它“具体执行哪个任务”。这里的“任务”,必须是已在“定时任务”列表中 预先定义好 的(例如我们上一节的 demoJob)。
工作流本身不定义任务的执行内容,它只负责 定义任务的执行顺序。
19.3.3. 节点详解(二):决策节点 (SpEL)
工作流的强大之处在于它支持 条件分支,这是通过“决策节点”实现的。
一个“决策节点”允许我们定义一个或多个分支,每个分支都包含一个 SpEL 表达式 (Spring Expression Language)。
它是如何工作的?
- 上一个“任务节点”(如
demoJob)在执行完毕时,可以返回一个结果(例如一个 JSON 字符串)。 - “决策节点”会获取这个返回结果,并使用 SpEL 表达式对其进行判断。
- 例如,任务返回了
{"code": 200, "userId": 1}。 - 决策节点的分支可以写:
- 分支 A (成功):
#taskResult.code == 200 - 分支 B (失败):
#taskResult.code != 200
- 分支 A (成功):
- 工作流会根据表达式的
true/false结果,自动流转到对应的分支(例如执行“成功”路径上的任务 B,或“失败”路径上的任务 C)。
19.3.4. 查看执行详情:追踪编排路径
当一个工作流执行完毕后,我们可以在“工作流” -> “执行批次”中查看结果。
与定时任务不同,工作流的执行详情会 高亮显示 实际执行的路径。例如,如果 demoJob 执行失败,导致工作流走向了“失败告警”分支,那么这个路径在 UI 上会清晰地标识出来,帮助我们快速定位问题,我们简单了解即可
19.3.5. 本节小结
我们学习了 Snail Job 的工作流功能,它通过可视化编排和 SpEL 决策节点,将孤立的定时任务串联成复杂的业务流程。
核心要点
- 工作流的价值在于“编排”,它解决的是任务之间的“依赖”和“顺序”问题。
- “任务节点”必须引用一个已在“定时任务”中创建的任务。
- “决策节点”使用 SpEL 表达式,根据上一个任务的返回结果,实现条件分支(如成功/失败)。
19.4. 核心功能(三):重试任务
在掌握了定时任务和工作流之后,我们来探索 Snail Job 提供的第三大“杀手锏”——重试任务。
19.4.1. 重试的价值:应对瞬时故障
痛点:在分布式系统中,我们的业务逻辑(例如 demoJob)经常需要调用外部 API 或其他微服务。这些调用可能因为网络抖动、对方服务瞬时高负载等原因导致“瞬时失败”。
如果不处理,这个任务就被标记为“失败”了。但这种瞬时故障,往往在 10 秒后重试一次就能成功。
解决方案:“重试任务”模块就是为了解决这个问题而生的。它提供了一个 独立于定时任务 的、专门的、健壮的重试机制。当我们的业务代码(不一定是定时任务,任何 Java 方法都可以)在执行中捕获到“可重试”的异常时,可以将它提交给 Snail Job 的重试队列。Snail Job 会在后台按照配置的策略(如 1 分钟后、5 分钟后、15 分钟后)自动发起重试,直到成功。
重要区别:定时任务配置中的“最大重试次数”,指的是 调度失败(如 Server 无法连接 Client)的重试;而“重试任务”模块,解决的是 业务逻辑执行失败(如 API 调用超时)的重试。
19.4.2. [核心] 四大概念:场景、任务、日志与死信
要理解重试模块,必须先弄清它的四个核心菜单(概念)及其关系:
- 重试场景 (Scene):
- 是什么:定义了一个“业务类别”,例如“订单支付回调”或“同步用户信息”。它是一类重试任务的集合。
- 重试任务 (Task):
- 是什么:一个具体的、待重试的业务操作。例如,“回调订单号 10086”失败了,它会作为一条“任务”进入“订单支付回调”这个“场景”中。
- 重试日志 (Log):
- 是什么:记录了 Snail Job 对“重试任务”每一次尝试的日志。例如,10:00 尝试失败,10:05 尝试失败,10:15 尝试成功。
- 死信任务 (Dead-Letter Task):
- 是什么:当一个“重试任务”达到了配置的“最大重试次数”后(例如 10 次),如果依然失败,Snail Job 会放弃重试,并将该任务转储到“死信”列表中。
- 为什么:这是一种保护机制,防止无限重试,并允许开发人员“手动介入”处理这些“真正失败”的任务。
它们的关系是:一个“场景”下,会产生多个“任务”;每个“任务”的执行过程,会产生多条“日志”;当“任务”重试耗尽后,会变为“死信任务”。
19.4.3. [重点] 声明式集成:基于注解的自动注册
与“定时任务”不同,Snail Job 的“重试任务”和“重试场景”一般不推荐在 UI 上手动新增。
Snail Job 提倡的是一种“代码优先”的声明式集成。开发者在业务代码中(例如 ruoyi-admin)通过 添加注解 的方式,来定义一个重试方法。
1 | // 这是一个示例注解,非 Snail Job 真实注解,仅为说明概念 |
当 ruoyi-admin (Client) 启动时,Snail Job Client 会自动扫描这些注解,并 自动将“场景”和“任务”注册 到 Snail Job Server 的 UI 界面上。
这种方式的优势在于,业务逻辑和重试策略在代码中是“高内聚”的,我们无需在 UI 和代码库之间来回切换和维护两套配置。
19.4.4. 本节小结
我们理解了 Snail Job 重试模块的核心价值、四大概念(场景、任务、日志、死信)之间的关系,以及它所提倡的“基于注解的声明式”集成方式。
核心要点
- 重试任务的核心价值是:解决业务逻辑中的“瞬时故障”(如网络抖动)。
- 它的四大组件关系为:场景 -> 任务 -> 日志 -> 死信。
- 最佳实践是通过在 Client 端(业务代码)使用注解来“声明”重试,Snail Job 会自动将其注册到 Server 端。
- “死信任务”是重试达到上限后依然失败的产物,需要人工介入。
19.5. 运维与管理
在掌握了 Snail Job 的三大核心业务功能(定时、工作流、重试)之后,我们还需要确保这套系统能够被安全、稳定地运维。本节我们将学习 Snail Job 提供的运维管理功能,包括告警、权限和监控概览。
19.5.1. 告警通知:配置多渠道告警
一个健壮的调度系统,必须具备“主动发现问题”的能力,而不是等待用户反馈“任务没执行”。“告警通知”就是实现这一目标的核心。
Snail Job 允许我们配置精细化的告警规则,在任务执行失败或客户端异常时,主动通知相关人员。
配置分为两步:
第一步:配置通知人(“通知谁”)
在“通知人”菜单中,我们可以定义接收告警的渠道和目标。
- 渠道支持:Snail Job 支持钉钉、企业微信、飞书、邮箱和通用 Webhook。
- 配置:例如,选择“邮箱”,需要输入接收人的邮箱地址;选择“钉钉”,则需要输入钉钉群机器人的 Webhook 地址。
- 注意:使用“邮箱”渠道,必须先在 Snail Job Server 端(
ruoyi-snailjob-server)的application.yml中配置好 SMTP 发件服务器信息。
第二步:配置通知列表(“何时通知”)
在“告警通知”菜单中,我们创建告警规则,将其与“通知人”关联起来。
- 组名称:选择要监控的组(如
ruoyi-vue-plus)。 - 任务类型:选择要监控的类型(如“定时任务”、“工作流”)。
- 通知场景:[核心] 选择触发告警的条件,例如
执行失败、客户端执行失败等。 - 通知人:选择第一步中配置好的通知人。
通过这套配置,我们就可以实现“当 ruoyi-vue-plus 组的 demoJob 任务 执行失败 时,自动发送 钉钉 消息给 开发A组”的自动化运维。
19.5.2. 权限管理:用户与组的权限分配
默认情况下,我们使用 admin 用户登录,它拥有系统的最高权限。但在企业环境中,我们不能把 admin 账号共享给所有人。
“用户管理”功能允许我们创建新的操作员账号,并为其分配精细化的权限。
- 管理员:如果勾选“管理员”,该用户将拥有和
admin一样的所有权限。 - 普通用户:如果不勾选“管理员”,我们可以为其指定“组”的权限。
例如,我们可以创建一个“业务A组”的用户,并只为他分配 ruoyi-group-A 这个组的管理权限。这样,该用户登录后,就只能看到和操作 ruoyi-group-A 相关的任务,无法查看其他组(如 ruoyi-group-B)的任何信息,实现了权限的严格隔离。
19.5.3. 关键指标概览:任务、批次与机器
Snail Job 的“首页”仪表盘是运维人员最常访问的界面。它提供了四大核心指标的概览:
| 指标模块 | 核心数据 | 运维价值 |
|---|---|---|
| 定时任务 | 总次数、成功、失败、停止、取消 | 快速查看定时任务的整体健康度,失败占比是关键。 |
| 重试任务 | 总次数、成功、运行中、最大重试、暂停 | 最大重试 和 暂停 的数量,预警了可能转为死信任务的风险。 |
| 工作流 | 总次数、成功、失败、停止、取消 | 监控核心业务流程(工作流)的执行情况。 |
| 总在线机器 | 服务端数量、客户端数量 | [核心] 监控 Client 存活。如果 ruoyi-admin 集群有 3 台,这里却只显示 2 台,说明有 1 台已掉线。 |
此外,首页的统计图表还展示了最近一周的任务执行趋势,帮助我们分析任务的成功率波动。
19.5.4. 本节小结
我们学习了 Snail Job 在运维侧的告警、权限和监控功能。这些功能是保障调度中心在生产环境中稳定、安全运行的基石。
核心要点
- “告警通知”通过“通知人”+“通知规则”的组合,实现对失败任务的主动监控。
- “用户管理”可以创建普通用户,并按“组”对其进行权限隔离。
- “首页”仪表盘是核心监控入口,特别是“总在线机器”指标,用于监控 Client 端的存活状态。






