
Prorise
这是我的博客,分享技术与生活的点点滴滴
第三章. 管理员完整配置指南
第三章. 管理员完整配置指南
Prorise第三章. 管理员完整配置指南
在上一章中,我们成功在本地部署了 Open WebUI,并完成了基础的启动验证。现在,作为管理员,你需要对系统进行完整的配置,让它真正为你和你的团队服务。
本章将带你深入管理员面板,完成从模型连接、用户管理到高级功能的全部配置。在开始之前,请确保你已经以管理员身份登录 Open WebUI。
3.1. 管理员面板导航
进入管理员面板
登录 Open WebUI 后,点击左下角的用户名区域,在弹出菜单中选择 “管理员面板”(Admin Panel)。
如果你看不到这个选项,说明你的账号不是管理员。记住,只有第一个注册的账号才会自动成为管理员。
管理员面板结构
管理员面板的顶部有 四个主标签页,每个标签页左侧有各自的子菜单:
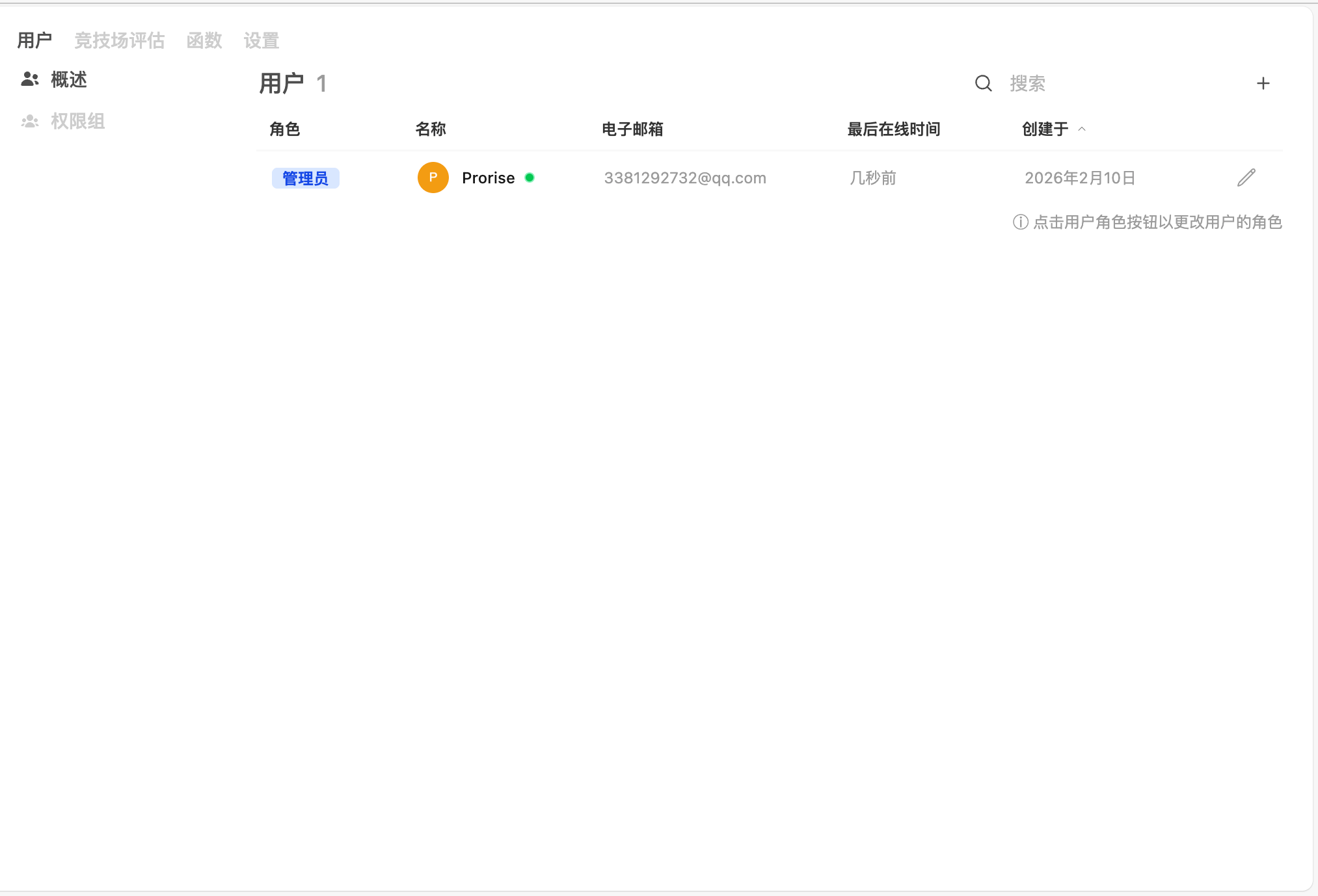
用户
管理所有用户和权限组。
| 子菜单 | 功能 |
|---|---|
| 概述 | 用户列表,显示角色、名称、邮箱、最后在线时间、创建时间。支持搜索和添加用户(右上角 + 按钮) |
| 权限组 | 创建权限组,将用户分组并批量分配权限。默认有一个"默认权限"组,用于所有"用户"角色的用户 |
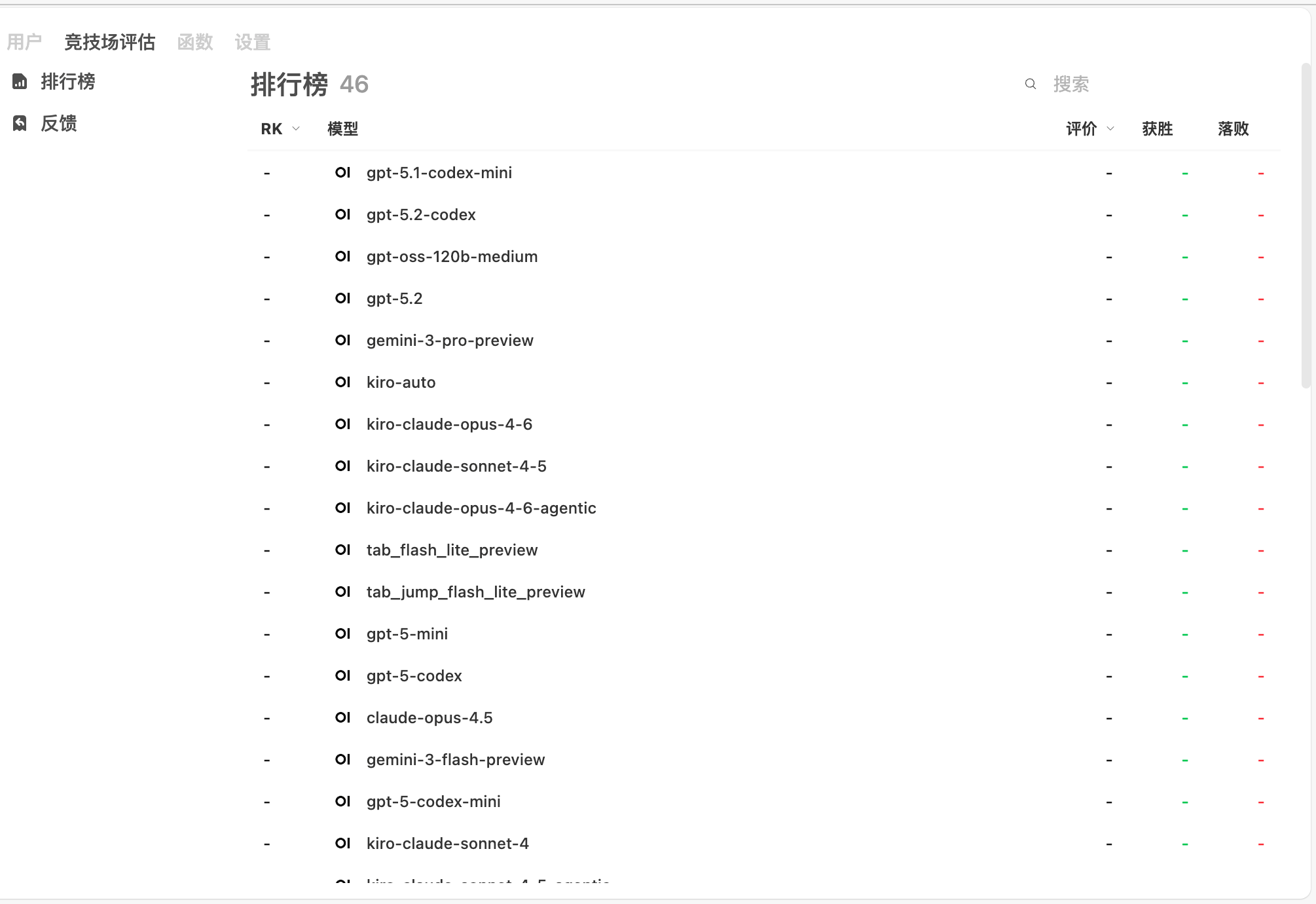
竞技场评估
模型对比评估功能,让用户盲测不同模型的回答质量。
| 子菜单 | 功能 |
|---|---|
| 排行榜 | 显示所有模型的排名(RK)、评价、获胜/落败次数 |
| 反馈 | 查看用户对模型回答的反馈记录 |
函数
管理 Open WebUI 的内置扩展函数(Functions),这是官方推荐的扩展方式。
- 顶部有 导入 和 + 新函数 按钮
- 支持按类型(全部)和标签筛选
- 底部有 “由 Open WebUI 社区开发” 入口,可以发现和下载社区函数
设置
系统全局配置,左侧子菜单最为丰富:
| 子菜单 | 功能 | 对应本章节 |
|---|---|---|
| 通用 | 版本信息、身份验证(默认用户角色、注册开关)、管理员邮箱、待激活用户界面配置 | 3.3 |
| 外部连接 | Ollama API 和 OpenAI API 的连接配置 | 3.2 |
| 模型 | 默认模型、任务模型、模型白名单等 | 3.2 |
| 竞技场评估 | 竞技场模式的全局设置 | — |
| 外部工具 | 外部工具集成配置 | — |
| Documents | RAG 文档功能配置,包括向量数据库、Embedding 模型、检索参数 | 3.4 |
| 联网搜索 | 网络搜索引擎配置(SearXNG、Google PSE、Brave 等) | 3.7 |
| Code Execution | 代码执行环境配置 | — |
| 界面 | UI 界面定制 | 3.10 |
| 语音 | STT(语音转文字)和 TTS(文字转语音)配置 | 3.6 |
| Images | 图像生成引擎配置(DALL-E、ComfyUI 等) | 3.5 |
| Pipelines | Pipelines 插件服务连接配置 | 3.8 |
| 数据库 | 数据导入导出、系统维护 | — |
配置优先级说明
Open WebUI 的配置有两个来源:
环境变量:在启动容器或 Python 程序时设置的变量(如 OLLAMA_BASE_URL)。
数据库配置:在管理员面板中设置的配置,保存在数据库中。
重要规则:对于标记为 PersistentConfig 的配置项,数据库中的配置优先级高于环境变量。这意味着:
- 首次启动时,环境变量会被写入数据库
- 之后修改环境变量不会生效,除非删除数据库中的配置
- 如果要强制使用环境变量,需要在管理员面板中清除对应配置
这个设计是为了避免配置混乱,确保配置的一致性。
3.2. 模型连接与管理
模型连接是 Open WebUI 最核心的配置。没有模型,Open WebUI 就无法工作。
连接本地 Ollama
如果你在本地运行了 Ollama,需要在 Open WebUI 中配置连接。
步骤 1:进入连接设置
管理员面板 → 设置 → 外部连接(Connections)
步骤 2:配置 Ollama API URL
在 “Ollama API URL” 字段中填入:
| 部署方式 | URL |
|---|---|
| Docker 部署(Ollama 在主机) | http://host.docker.internal:11434 |
| Docker Compose(Ollama 在容器) | http://ollama:11434 |
| Python 安装(Ollama 在主机) | http://localhost:11434 |
步骤 3:验证连接
点击 URL 输入框右侧的刷新按钮(🔄)。
如果连接成功,下方会显示 “连接成功” 的提示,并且会自动拉取 Ollama 中的模型列表。
步骤 4:配置多个 Ollama 实例(可选)
如果你有多台服务器运行 Ollama,可以添加多个连接。Open WebUI 会自动进行负载均衡。
点击 “添加 Ollama 实例” 按钮,填入新的 URL,例如:
http://192.168.1.100:11434
http://192.168.1.101:11434
这样,当用户发起请求时,Open WebUI 会自动选择负载较低的实例。
连接 OpenAI API
如果你想使用 OpenAI 的 GPT 模型,需要配置 OpenAI API。
步骤 1:获取 API 密钥
访问 OpenAI 官网:https://platform.openai.com/api-keys
登录后,点击 “Create new secret key” 创建一个新的 API 密钥。
重要:API 密钥只会显示一次,请妥善保存。
步骤 2:在 Open WebUI 中配置
管理员面板 → 设置 → 外部连接 → OpenAI
| 字段 | 值 | 说明 |
|---|---|---|
| API Base URL | https://api.openai.com/v1 | OpenAI 官方 API 地址 |
| API Key | sk-... | 你的 API 密钥 |
步骤 3:验证连接
点击刷新按钮,如果连接成功,会自动拉取可用的模型列表(如 gpt-4、gpt-3.5-turbo 等)。
步骤 4:配置代理(如果需要)
如果你的网络无法直接访问 OpenAI,可以配置代理:
在 Docker 部署中,添加环境变量:
1 | environment: |
或者使用国内的 OpenAI API 中转服务(需要自行寻找可靠的服务商)。
连接其他兼容 API
Open WebUI 支持任何兼容 OpenAI API 格式的服务,包括:
| 服务商 | API Base URL 示例 | 说明 |
|---|---|---|
| Azure OpenAI | https://your-resource.openai.azure.com/ | 需要额外配置 API 版本 |
| Anthropic Claude | https://api.anthropic.com/v1 | 需要 Claude API 密钥 |
| Google Gemini | 通过兼容层 | 需要使用 LiteLLM 等工具转换 |
| DeepSeek | https://api.deepseek.com/v1 | 国内可直接访问 |
| Groq | https://api.groq.com/openai/v1 | 速度极快的推理服务 |
| 本地 vLLM | http://localhost:8000/v1 | 自建推理服务 |
配置步骤:
管理员面板 → 设置 → 外部连接 → OpenAI → 点击 “+” 添加新连接
填写:
- 名称:给这个连接起个名字(如 “DeepSeek”)
- API Base URL:服务商的 API 地址
- API Key:对应的 API 密钥
Azure OpenAI 特殊配置:
Azure OpenAI 需要额外配置 API 版本和部署名称。在 API Base URL 中包含这些信息:
1 | https://your-resource.openai.azure.com/openai/deployments/your-deployment-name?api-version=2024-02-15-preview |
模型可见性与权限控制
默认情况下,所有用户都能看到所有模型。但在团队使用场景中,你可能希望控制哪些用户能访问哪些模型。
步骤 1:进入模型设置
管理员面板 → 设置 → 模型(Models)
步骤 2:编辑模型
找到你想要控制的模型,点击右侧的编辑按钮(✏️)。
步骤 3:设置可见性
在模型编辑页面,你会看到以下选项:
| 选项 | 说明 |
|---|---|
| 公开(Public) | 所有用户都能看到和使用 |
| 私有(Private) | 只有管理员能看到 |
| 指定用户 | 只有选中的用户能看到 |
| 指定权限组 | 只有选中的权限组能看到 |
选择合适的可见性,然后点击保存。
实际应用场景:
- 将昂贵的 GPT-4 模型设为 “指定用户”,只给核心团队成员使用
- 将实验性模型设为 “私有”,只有管理员测试
- 将免费的本地模型设为 “公开”,所有人都能使用
模型白名单
如果你连接了多个 API,可能会拉取到很多模型。你可以使用白名单功能,只显示需要的模型。
步骤 1:进入设置
管理员面板 → 设置 → 模型(Models)
步骤 2:启用白名单
找到 “模型白名单” 选项,启用它。
步骤 3:添加模型
在白名单中添加你想要显示的模型 ID,每行一个:
1 | gpt-4 |
保存后,只有白名单中的模型会显示给用户。
模型标签与排序
为了让用户更容易找到合适的模型,你可以给模型添加标签和自定义排序。
添加标签:
在模型编辑页面,找到 “标签(Tags)” 字段,添加标签:
1 | 推荐, 快速, 免费 |
或
1 | 高级, 付费, GPT-4 |
用户在选择模型时,可以通过标签筛选。
自定义排序:
在设置 → 模型页面,你可以拖动模型来调整顺序。排在前面的模型会优先显示给用户。
最佳实践:
- 将最常用的模型排在最前面
- 将免费模型和付费模型用标签区分
- 将不同能力的模型分类(如 “对话”、“编程”、“翻译”)
模型参数预设
你可以为每个模型设置默认参数,用户使用时会自动应用这些参数。
步骤 1:编辑模型
设置 → 模型 → 点击模型的编辑按钮
步骤 2:配置参数
在 “模型参数” 区域,设置以下参数:
| 参数 | 说明 | 推荐值 |
|---|---|---|
| Temperature | 控制输出的随机性,0-2 | 0.7(平衡) |
| Top P | 核采样参数,0-1 | 0.9 |
| Max Tokens | 最大输出长度 | 2048 |
| Context Length | 上下文窗口大小 | 4096 |
| Frequency Penalty | 降低重复内容,-2 到 2 | 0 |
| Presence Penalty | 鼓励新话题,-2 到 2 | 0 |
参数说明:
Temperature:
- 0.1-0.3:输出非常确定,适合事实性任务(如翻译、总结)
- 0.7-0.9:平衡创造性和准确性,适合日常对话
- 1.0-2.0:输出更有创造性,适合创意写作
Top P:
- 0.9:推荐值,保持输出质量
- 0.95:更多样化的输出
- 1.0:完全随机(不推荐)
Context Length:
- 对于 Ollama 模型,默认是 2048,这太小了
- 建议设置为 8192 或更高,特别是使用 RAG 功能时
- 注意:更大的上下文会消耗更多内存
3.3. 用户与权限管理
Open WebUI 提供了完善的多用户管理功能,适合团队协作使用。
用户注册与审批流程
默认行为:
- 第一个注册的用户自动成为管理员
- 后续注册的用户状态为 “待激活”
- 管理员需要手动激活用户
配置注册开关:
管理员面板 → 设置 → 通用 → 身份验证
找到 “允许新用户注册” 开关:
| 状态 | 说明 | 适用场景 |
|---|---|---|
| 开启 | 任何人都可以注册,新用户角色由"默认用户角色"决定 | 小团队、内网环境 |
| 关闭 | 禁止注册,只能由管理员手动添加用户 | 严格控制的企业环境 |
配置默认用户角色:
在同一页面,找到 “默认用户角色” 下拉选择:
| 角色 | 说明 |
|---|---|
| 待激活 | 注册后无法使用系统,需要管理员手动激活(默认值) |
| 用户 | 注册后直接可以使用系统 |
| 管理员 | 注册后直接成为管理员(不推荐) |
配置默认权限组:
你还可以设置 “默认权限组”,新注册的用户会自动加入该权限组,继承组的权限配置。
如果你的团队成员都是可信的,可以将默认角色设为 “用户”,这样注册后就能直接使用,无需审批。
手动添加用户
如果你关闭了注册功能,或者想要批量添加用户,可以使用手动添加功能。
步骤 1:进入用户管理
管理员面板 → 用户(Users)
步骤 2:添加单个用户
点击右上角的 “添加用户” 按钮,填写信息:
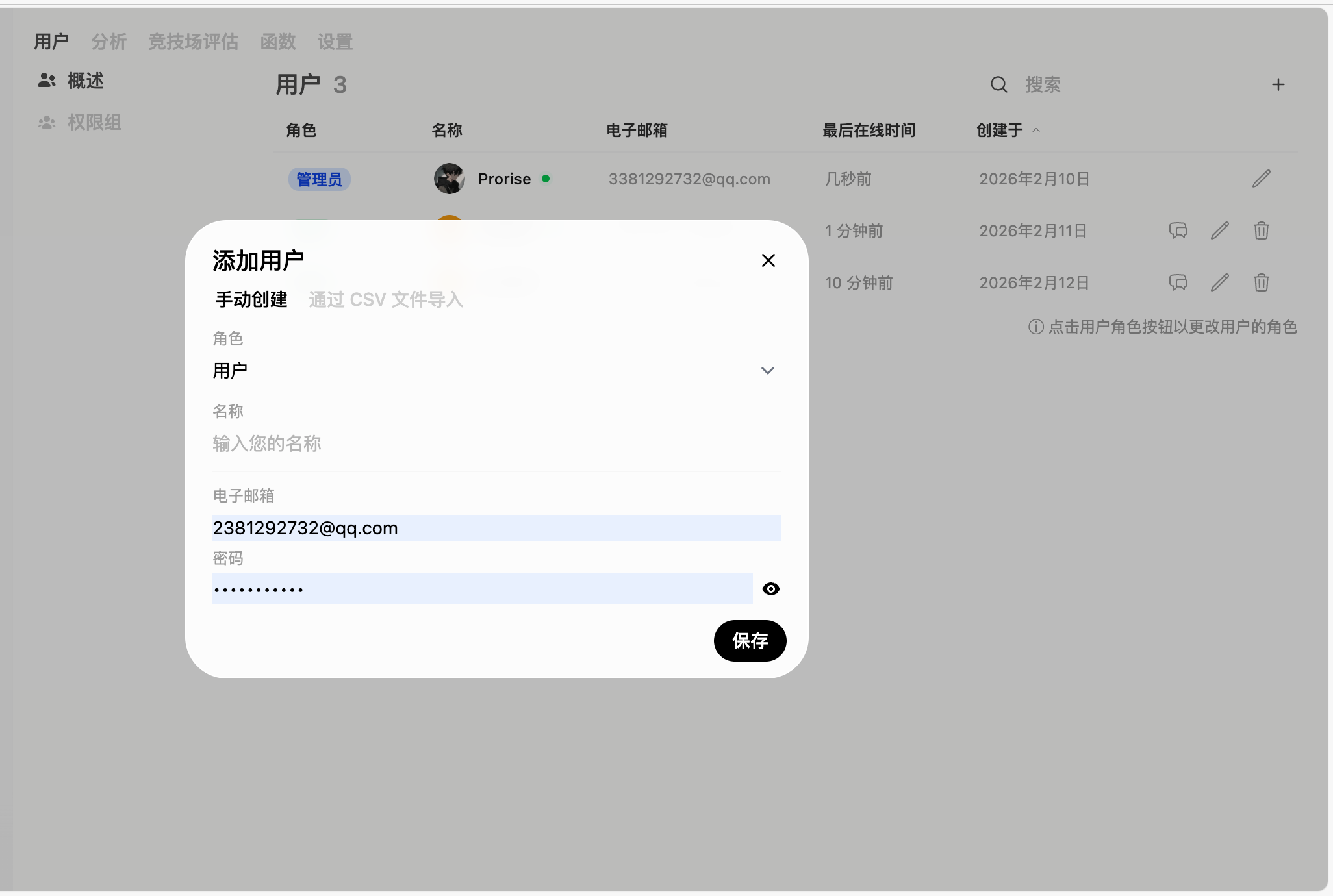
| 字段 | 说明 | 示例 |
|---|---|---|
| 邮箱 | 用户登录邮箱 | user@example.com |
| 用户名 | 显示名称 | 张三 |
| 密码 | 初始密码 | 建议生成随机密码 |
| 角色 | 用户角色 | User |
点击 “创建” 完成添加。
步骤 3:通知用户
将登录信息(邮箱和密码)发送给用户,建议用户首次登录后立即修改密码。
批量导入用户(CSV)
如果需要添加大量用户,可以使用 CSV 批量导入功能。
步骤 1:准备 CSV 文件
创建一个 CSV 文件,格式如下:
1 | email,name,password,role |
注意:
- 第一行是表头,必须包含这四个字段
- role 可以是
user、admin或pending - 密码建议使用随机生成的强密码
步骤 2:导入
管理员面板 → 用户 → 点击 “导入用户” 按钮
选择你准备好的 CSV 文件,点击上传。
系统会显示导入结果,包括成功和失败的记录。
用户角色体系
Open WebUI 有三种用户角色:
| 角色 | 权限 | 适用对象 |
|---|---|---|
| 管理员 | 完全控制权限,可以管理所有设置、用户、模型 | 系统管理员、技术负责人 |
| 用户 | 可以使用系统,创建对话,上传文档,但不能修改系统设置 | 普通团队成员 |
| 待激活 | 无法使用系统,等待管理员激活 | 新注册用户 |
修改用户角色:
管理员面板 → 用户 → 找到目标用户 → 点击角色下拉菜单 → 选择新角色
权限组管理
权限组功能允许你将用户分组,然后批量分配权限。
创建权限组:
管理员面板 → 用户 → 权限组 → 点击 “创建权限组”
填写信息:
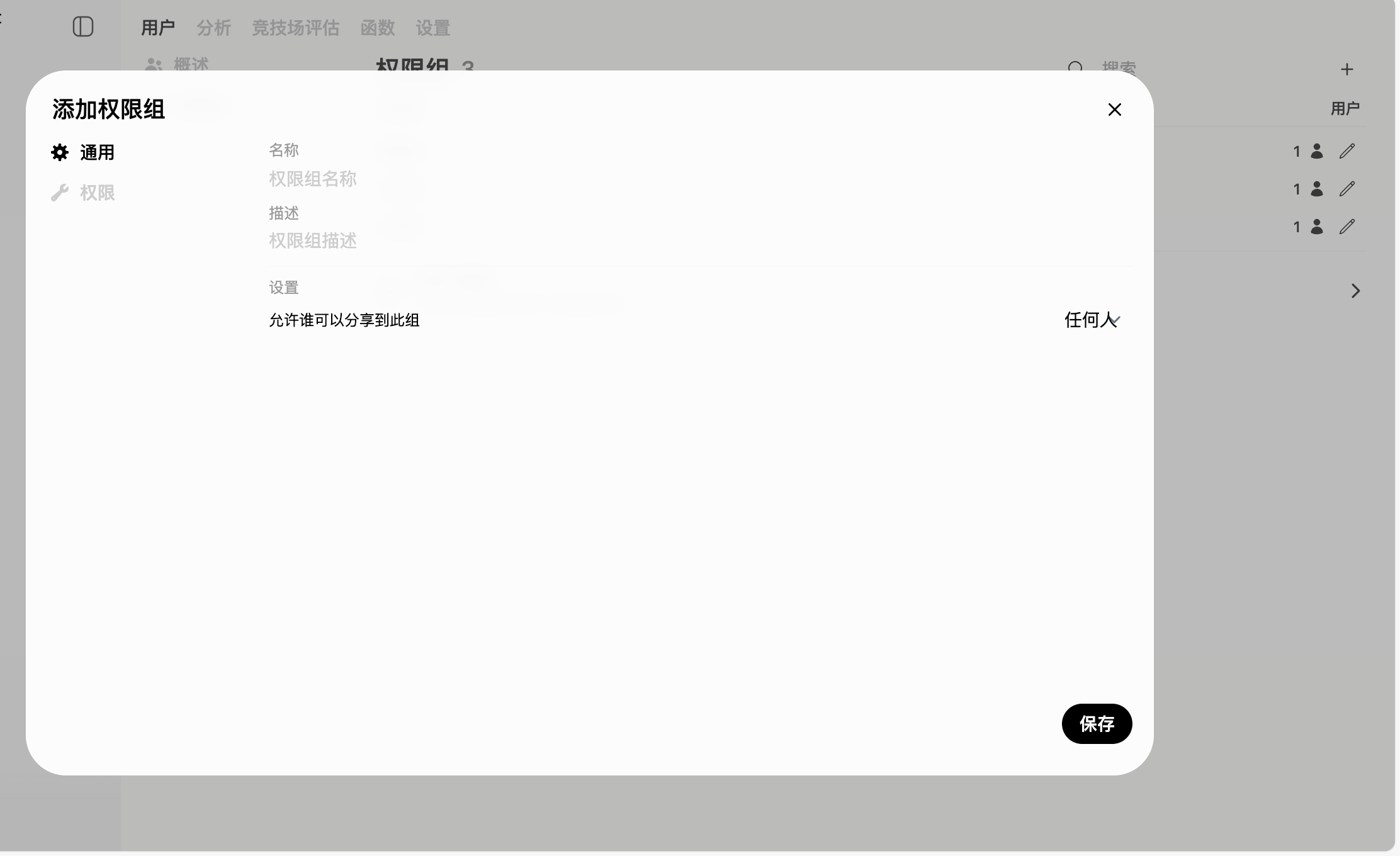
| 字段 | 说明 | 示例 |
|---|---|---|
| 组名 | 权限组名称 | 开发团队 |
| 描述 | 组的说明 | 负责产品开发的团队成员 |
添加成员到权限组:
创建权限组后,点击 “添加成员” 按钮,选择要添加的用户。
为权限组分配权限:
权限组创建后,你可以:
- 将特定模型的访问权限分配给权限组
- 将知识库的访问权限分配给权限组
- 将工具和函数的使用权限分配给权限组
这样,当你添加新成员到权限组时,他们会自动获得组的所有权限,无需逐个配置。
💡 系统默认有一个"默认权限"组,用于所有具有"用户"角色的用户。你可以点击进入修改默认权限。
我的权限组设计
我接入了大量模型(100+ 个),来源包括 AWS Bedrock、OpenAI、Google Gemini、GitHub Copilot、iFlow 代理、Moonshot 等多个渠道。不同渠道的成本差异很大,不能让所有用户无差别地使用全部模型。
我借助大模型分析了数据库中的模型列表和权限表结构,设计了三级权限组:
| 权限组 | 定位 | 可用模型数 | 说明 |
|---|---|---|---|
| 试用组 | 新用户体验 | 13 个 | 仅提供轻量级免费/低成本模型,功能受限(不可多模型对话、不可创建频道等) |
| 正式组 | 日常使用 | 77 个 | 拥有所有自有渠道模型的访问权限,功能完整 |
| 管理组 | 管理员 | 102 个(全部) | 在正式组基础上额外拥有高成本第三方渠道模型(GitHub Copilot、SciHub 镜像) |
试用组可用模型(13 个):
只开放成本最低的轻量模型,让新用户体验基本功能:
- Claude Haiku 4.5 系列(AWS 直连 + Kiro 通道)
- Gemini 2.5 Flash / Flash Lite
- GPT-5 Codex Mini / GPT-5.1 Codex Mini
- Qwen3 Coder Flash
- Kiro GPT-3.5/4/4o(旧模型,成本极低)
正式组额外可用模型(+64 个):
在试用组基础上,解锁所有自有渠道的中高端模型:
- Claude Sonnet 4/4.5、Opus 4.5/4.6 全系列(含 Thinking、Agentic 变体)
- Gemini 2.5 Pro、3 Pro/Flash Preview
- GPT-5/5.1/5.2/5.3 全系列
- DeepSeek V3/V3.1/V3.2、R1(通过 iFlow)
- Qwen3 Max/235B/Coder Plus(通过 iFlow)
- Kimi K2/K2.5(Moonshot 直连 + iFlow)
- GLM 4.6/4.7/5(通过 iFlow)
- MiniMax M2/M2.1(通过 iFlow)
管理组专属模型(+25 个):
这些模型走 GitHub Copilot 和 SciHub 镜像渠道,成本较高或属于特殊用途,仅管理员可用:
gh-*系列(21 个):GitHub Copilot 高级模型,包括 gh-gpt-5.2、gh-claude-opus-4.6、gh-gemini-3-pro-preview 等scihub.*系列(4 个):SciHub Claude 镜像,包括 scihub.claude-opus-4-6、scihub.claude-sonnet-4-5-20250929 等
权限组的功能差异:
除了模型访问权限,三个组在系统功能上也有区别:
| 功能 | 试用组 | 正式组 | 管理组 |
|---|---|---|---|
| 多模型对话 | ❌ | ✅ | ✅ |
| 创建频道/文件夹 | ❌ | ✅ | ✅ |
| 知识库管理 | ❌ | ✅ | ✅ |
| 工具/函数管理 | ❌ | ✅ | ✅ |
| 图片生成 | ❌ | ✅ | ✅ |
| 笔记功能 | ❌ | ✅ | ✅ |
| 导入/导出模型 | ❌ | ✅ | ✅ |
| 界面设置 | ❌ | ❌ | ✅ |
| 临时对话强制 | ✅(强制) | ❌ | ❌ |
模型图标规范:
为了让用户在模型列表中快速识别来源,我为每个模型统一配置了图标:
| 模型来源 | 图标 |
|---|---|
| Claude 系列 | claude-color.svg |
| OpenAI GPT 系列 | openai.svg |
| Gemini 系列 | gemini-color.svg |
| Qwen 系列 | qwen-color.svg |
| DeepSeek 系列 | deepseek-color.svg |
| Kimi 系列 | moonshot.svg |
| MiniMax 系列 | minimax-color.svg |
| GLM 系列 | zhipu-color.svg |
| Grok 系列 | grok.svg |
| Kiro(AWS 通道) | aws-color.svg |
图标统一使用 cdn.jsdelivr.net/npm/@lobehub/icons-static-svg@1.79.0/icons/ 的 SVG 资源。
批量配置方法:
手动逐个配置 100+ 个模型的权限和图标不现实。我的做法是:
- 在 Open WebUI 管理面板导出模型列表(JSON 格式)
- 用大模型编写 Python 脚本,根据模型 ID 前缀和名称自动推断图标和权限组
- 脚本批量写入
access_grants(新版格式)和meta.profile_image_url - 将修正后的 JSON 重新导入 Open WebUI
这样每次上游新增模型或系统升级后,只需重新导出 → 跑脚本 → 导入,几分钟就能完成全部配置。
⚠️ 注意:Open WebUI 升级后数据库结构可能变化。例如从旧版升级到新版时,模型权限从
model表的access_control字段迁移到了独立的access_grant表,导出格式也从access_control对象变成了access_grants数组。升级后建议先导出一份检查格式再操作。
用户活动监控
Open WebUI 提供了用户活动监控功能,帮助你了解系统使用情况。
查看活跃用户:
管理员面板 → 设置 → 通用 → 找到 “显示活跃用户数” 选项
启用后,在主界面底部会显示当前活跃用户数和正在使用的模型。
查看用户详情:
管理员面板 → 用户 → 点击用户名
你可以看到:
- 创建的对话数量
- 使用的模型统计
注意:Open WebUI 不会记录用户的具体对话内容,只记录统计信息,保护用户隐私。
3.4. RAG 文档功能配置
RAG(检索增强生成)是 Open WebUI 的核心功能之一,允许用户基于自己的文档进行问答。本节将从上到下逐一解析 Admin Panel → Settings → Documents 页面的每个配置项,帮助你根据实际场景做出最优选择。
配置入口:管理员面板 → 设置 → Documents
内容提取引擎(Content Extraction Engine)
内容提取引擎决定了 Open WebUI 如何从上传的文件中提取文本。通过环境变量 CONTENT_EXTRACTION_ENGINE 选择,共支持 8 种引擎。
引擎横向对比
| 引擎 | 部署方式 | 费用 | 支持格式 | OCR 能力 | 表格/公式 | 适用场景 |
|---|---|---|---|---|---|---|
| 默认(Default) | 本地,零依赖 | 免费 | PDF、TXT、CSV、DOCX、代码文件 | ❌ 不支持 | ❌ 弱 | 简单文档,纯文本 PDF |
| Apache Tika | 需部署 Java 服务 | 免费(开源) | 1400+ 种格式 | ❌ 弱 | ❌ 弱 | 格式种类多的企业环境 |
| Docling(IBM) | 需部署服务或用 API | 免费(开源) | PDF、DOCX、PPTX、HTML | ✅ 支持 | ✅ 优秀 | 复杂排版、表格、公式 |
| Datalab Marker | 云 API 或自部署 | ~$6/千页(高精度) | PDF、图片 | ✅ LLM 增强 OCR | ✅ 优秀 | 复杂排版 PDF,可自部署 |
| Mistral OCR | 云 API | $1-2/千页 | PDF、图片 | ✅ 99%+ 准确率 | ✅ 优秀 | 扫描件、多语言(25+ 语言) |
| Document Intelligence | Azure 云服务 | ~$10/千页 | PDF、图片、表单 | ✅ 支持 | ✅ 支持 | Azure 生态企业用户 |
| MinerU | 自部署或云 API | 免费(开源) | PDF、图片 | ✅ 支持 | ✅ 最佳 | 学术论文、金融报告、公式密集 |
| External | 自定义 HTTP 服务 | 取决于实现 | 自定义 | 取决于实现 | 取决于实现 | 对接私有解析服务 |
各引擎详细说明
使用 Python 原生加载器(PyPDFLoader、Docx2txtLoader、CSVLoader、TextLoader),零依赖开箱即用。但不支持 OCR,无法处理扫描件,对复杂表格和公式无能为力。
适合:纯文本 PDF 和简单文档,快速上手无需任何额外配置。
老牌 Java 文档解析框架,格式覆盖最广(1400+),但对 PDF 排版理解较弱,不擅长表格结构保留和公式识别。适合已有 Tika 基础设施的组织。
1 | environment: |
Python 原生,对 PDF 排版理解好,表格提取准确,支持公式,输出干净的 Markdown/JSON。在多个评测中与 MinerU 并列 top 2。
1 | environment: |
基于开源 Marker 和 Surya 模型,LLM 增强 OCR。其 Chandra OCR 模型在 olmOCR benchmark 上得分 83.1%,超过 GPT-4o。支持云 API 和自部署两种方式。
1 | environment: |
号称 99%+ 准确率,支持表格/公式/图表转表格/签名检测,覆盖 25+ 语言。性价比高($1/千页起),但只能通过 API 调用,无法自部署。
1 | environment: |
微软企业级服务,预置发票/收据/身份证等模型,支持自定义模型训练。价格较高但有企业合规保障。
1 | environment: |
基于 PDF-Extract-Kit 微调模型,在复杂文档(学术论文、教材、金融报告)上表现最佳,表格/公式/图片提取精度高。推荐 GPU 环境运行。
1 | environment: |
万能逃生舱,指向任意 HTTP 服务,适合对接企业内部的私有文档解析服务。
1 | environment: |
引擎选择建议
| 场景 | 推荐引擎 | 理由 |
|---|---|---|
| 简单文档、快速上手 | 默认 | 零配置,开箱即用 |
| 扫描件、多语言文档 | Mistral OCR | 性价比最高,准确率高 |
| 学术论文、公式密集 | MinerU 或 Docling | 表格/公式提取精度最佳 |
| 企业 Azure 环境 | Document Intelligence | 合规保障,预置模型丰富 |
| 想自部署 + 高精度 | Datalab Marker 或 MinerU | 开源可控,精度优秀 |
| 格式种类极多 | Apache Tika | 1400+ 格式覆盖 |
PDF 提取图片(PDF Extract Images)
| 配置项 | 环境变量 | 默认值 | 说明 |
|---|---|---|---|
| PDF Extract Images | PDF_EXTRACT_IMAGES | false | 是否从 PDF 中提取嵌入的图片 |
启用后会增加处理时间和存储空间,仅在文档中的图片内容对问答有价值时开启。
PDF 加载模式
Open WebUI 提供两种 PDF 处理模式,决定了文档在进入切分器之前的预处理方式:
| 模式 | 行为 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| Page(页模式) | 每页作为独立文档单元,保留页边界 | 检索时能精确定位到具体页码 | 跨页内容会被截断 | PPT 转 PDF、每页独立主题 |
| Single Document(单文档模式) | 整个 PDF 合并为一个文本块,再统一切分 | 跨页内容不会丢失,语义连贯 | 失去页码定位能力 | 论文、书籍、报告等连续叙述型文档 |
最佳实践:大多数 RAG 场景推荐 Single Document 模式,因为语义连贯性比页码定位更重要。如果文档每页内容相对独立(如幻灯片),则用 Page 模式。
文本切分(Text Splitting)
文本切分决定了文档被拆分成多大的片段(chunk)存入向量数据库。切分质量直接影响检索精度。
切分器类型
| 切分器 | 计量方式 | 特点 | 适用场景 |
|---|---|---|---|
| 默认(Character) | 按字符数 | 使用递归分隔符(\n\n → \n → 空格 → 字符)逐级切分,简单高效,无依赖 | 英文文档、通用场景 |
| Token | 按 token 数 | 按模型 tokenizer 计算,切分大小与模型上下文窗口精确对齐 | 中文文档(1 个汉字 ≈ 2-3 个 token)、需要精确控制 token 用量 |
核心参数
| 配置项 | 环境变量 | 默认值 | 推荐值 | 说明 |
|---|---|---|---|---|
| Chunk Size | CHUNK_SIZE | 1500 | 1000-2000 | 每个 chunk 的最大大小。太小丢失上下文,太大降低检索精度 |
| Chunk Overlap | CHUNK_OVERLAP | 100 | Chunk Size 的 5%-15% | 相邻 chunk 的重叠量,保证边界处语义连贯 |
参数调优指南:
- Chunk Size 太小(<500):上下文不完整,模型难以理解片段含义
- Chunk Size 太大(>2000):包含过多无关信息,检索精度下降
- Chunk Overlap 太小:重要信息可能被切断在两个 chunk 之间
- Chunk Overlap 太大:存储冗余增加,检索效率降低
Markdown 标题文本分割器
| 配置项 | 默认值 | 说明 |
|---|---|---|
| Markdown Header Text Splitter | 关闭 | 按 Markdown 标题(H1-H6)进行结构化预切分 |
| Chunk Min Size Target | — | 合并过小片段的阈值,建议设为 Chunk Size 的 50% |
启用后,文档会先按 Markdown 标题进行结构化预切分,然后再交给标准切分器处理。好处:
- 保留文档的逻辑结构,每个 chunk 属于明确的章节
- 避免跨章节切分导致语义混乱
- 配合 Chunk Min Size Target 参数,可以将过小的片段向前合并(单向合并算法,不跨文档),官方测试显示阈值设为 1000(chunk size 2000 时)可减少 90%+ 的碎片 chunk
最佳实践:如果文档是 Markdown 格式,或提取引擎输出 Markdown(Docling、MinerU、Marker 都输出 Markdown),强烈建议开启此选项。
嵌入模型(Embedding Model)
嵌入模型将文本转换为向量表示,是 RAG 检索的基础。模型质量直接决定检索准确性。
引擎横向对比
| 引擎 | 配置值 | 费用 | 延迟 | 隐私 | 推荐模型 |
|---|---|---|---|---|---|
| SentenceTransformers(默认) | "" | 免费,本地运行 | 中等(取决于硬件) | 完全本地 | all-MiniLM-L6-v2(轻量)、BAAI/bge-m3(多语言) |
| Ollama | ollama | 免费,本地运行 | 快(已有 Ollama 实例) | 完全本地 | nomic-embed-text(推荐首选)、mxbai-embed-large |
| OpenAI | openai | 按 token 计费 | 低(云端) | 数据发送到云端 | text-embedding-3-small(性价比)、text-embedding-3-large(高精度) |
| Azure OpenAI | azure | 按 token 计费 | 低(云端) | Azure 合规保障 | 同 OpenAI 模型,通过 Azure 部署 |
各引擎详细说明
使用 Python sentence-transformers 库在本地运行,模型自动从 HuggingFace 下载缓存。零成本、完全隐私,但首次加载模型较慢,且占用服务器内存/显存。默认模型 all-MiniLM-L6-v2 较轻量但精度一般。
⚠️ 网络提示:如果服务器无法访问 huggingface.co,启动时会出现 SSL 重连错误,RAG 功能将不可用。可添加镜像站环境变量解决:
1 | environment: |
如果你已经在用 Ollama 跑 LLM,这是最方便的选择。nomic-embed-text 是社区最推荐的模型:8192 token 上下文、完全开源、在 MTEB 和 LoCo 基准上表现优异。
先下载模型:
1 | ollama pull nomic-embed-text |
然后配置环境变量:
1 | environment: |
支持任何 OpenAI 兼容端点(包括第三方)。text-embedding-3-small(1536 维)性价比高,text-embedding-3-large(3072 维)精度更好。缺点是有 API 费用、网络延迟、数据隐私风险。
1 | environment: |
本质上是 OpenAI 模型通过 Azure 托管,适合有 Azure 合规要求的企业。
1 | environment: |
嵌入模型选择建议
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 本地优先、已有 Ollama | Ollama + nomic-embed-text | 最佳平衡,免费、快速、质量好 |
| 资源受限、轻量部署 | SentenceTransformers + all-MiniLM-L6-v2 | 零依赖,内存占用小 |
| 中文文档为主 | Ollama + bge-m3 或 SentenceTransformers + BAAI/bge-m3 | 多语言支持优秀 |
| 追求精度且不介意费用 | OpenAI + text-embedding-3-large | 精度最高 |
| 企业合规要求 | Azure OpenAI | 合规保障 |
其他嵌入参数
| 配置项 | 环境变量 | 默认值 | 说明 |
|---|---|---|---|
| Embedding Batch Size | RAG_EMBEDDING_BATCH_SIZE | 100 | 批量嵌入大小,显存不足时调小 |
⚠️ 重要:更换嵌入模型后,所有已有文档必须重新嵌入(re-embed),因为不同模型的向量空间不兼容。确定模型后不要轻易更换。
检索与排序(Retrieval & Ranking)
检索参数决定了从向量数据库中召回多少结果、如何过滤和排序。这是影响 RAG 最终效果的关键环节。
核心检索参数
| 配置项 | 环境变量 | 默认值 | 推荐值 | 说明 |
|---|---|---|---|---|
| Top K | TOP_K | 5 | 5-10 | 返回的最相关 chunk 数量。太少可能遗漏信息,太多会稀释上下文 |
| Relevance Threshold | RELEVANCE_THRESHOLD | 0.0 | 0.2-0.5 | 最低相关性分数阈值,低于此分数的 chunk 被过滤。设为 0 表示不过滤 |
参数调优指南:
- Top K 太少(❤️):可能遗漏重要信息,回答不完整
- Top K 太多(>10):包含过多噪音,模型可能被无关内容干扰
- Relevance Threshold 太低(0):不过滤,噪音多
- Relevance Threshold 太高(>0.7):过滤过严,可能丢失有用信息
混合搜索(Hybrid Search)
| 配置项 | 环境变量 | 默认值 | 推荐 | 说明 |
|---|---|---|---|---|
| Hybrid Search | ENABLE_RAG_HYBRID_SEARCH | false | 开启 | 结合向量搜索 + BM25 关键词匹配 |
混合搜索使用 EnsembleRetriever,同时执行:
- 向量搜索:基于语义相似度,擅长理解同义词和语义关联
- BM25 关键词匹配:基于词频统计,擅长精确匹配专有名词、代码、ID 等
两者互补,显著提升召回率,推荐开启。
重排序(Reranking)
| 配置项 | 环境变量 | 默认值 | 说明 |
|---|---|---|---|
| Reranking Model | RAG_RERANKING_MODEL | — | 使用 CrossEncoder/ColBERT 对检索结果重排序 |
| Top K Reranker | TOP_K_RERANKER | — | 重排序后保留的结果数 |
重排序的工作流程:
- 先通过向量搜索(+ BM25)召回较多候选结果
- 再用 CrossEncoder 模型对每个候选结果与查询进行精细打分
- 按新分数重新排序,保留 Top K Reranker 个最相关结果
推荐配合 Hybrid Search 使用,这是提升 RAG 质量最有效的组合。
检索策略建议
| 文档规模 | 推荐配置 |
|---|---|
| 小文档集(<100 个文档) | Top K=5,不需要混合搜索和重排序 |
| 中等文档集(100-1000) | Top K=5-8,开启 Hybrid Search |
| 大文档集(>1000) | Top K=8-10,开启 Hybrid Search + Reranking,Relevance Threshold=0.2+ |
高级设置
RAG 模板与上下文
| 配置项 | 环境变量 | 默认值 | 说明 |
|---|---|---|---|
| RAG Template | RAG_TEMPLATE | 内置模板 | 自定义 RAG 提示词模板,控制检索内容如何注入到 LLM prompt |
| RAG System Context | RAG_SYSTEM_CONTEXT | false | 设为 true 将 RAG 上下文放入 system message 而非 user message |
RAG System Context 的作用:将检索到的文档内容放入 system message,而非 user message。好处是在多轮对话中可以优化 KV cache 复用(因为 system message 不变),推荐 Ollama/llama.cpp 用户开启。
异步与性能
| 配置项 | 环境变量 | 默认值 | 说明 |
|---|---|---|---|
| Async Embedding | ENABLE_ASYNC_EMBEDDING | false | 后台线程池处理嵌入,上传大量文档时建议开启 |
文件与工具
| 配置项 | 默认值 | 说明 |
|---|---|---|
| File Context | 启用 | 控制是否对附件执行 RAG 并预注入内容 |
| Builtin Tools | 启用 | 给模型提供 query_knowledge_bases、search_chats 等函数调用工具 |
网页加载
| 配置项 | 环境变量 | 默认值 | 说明 |
|---|---|---|---|
| Web Loader SSL Verification | ENABLE_WEB_LOADER_SSL_VERIFICATION | true | 网页加载时是否验证 SSL 证书 |
| Google Drive Integration | GOOGLE_DRIVE_API_KEY 等 | — | Google Drive 文件直接导入 |
向量数据库(Vector Database)
向量数据库用于存储文档的向量表示,是 RAG 检索的底层存储。
| 配置项 | 环境变量 | 默认值 | 说明 |
|---|---|---|---|
| Vector DB | VECTOR_DB | chromadb | 向量数据库类型 |
| Vector DB URL | VECTOR_DB_URL | — | 外部向量数据库连接地址 |
支持的向量数据库
| 数据库 | 部署方式 | 适用场景 | 特点 |
|---|---|---|---|
| ChromaDB | 内置,无需额外配置 | 个人使用、小团队 | 默认选择,开箱即用 |
| Qdrant | 需部署独立服务 | 大规模部署 | 高性能,支持过滤 |
| Milvus | 需部署独立服务 | 企业环境 | 分布式,支持十亿级向量 |
| Weaviate | 需部署独立服务 | 需要混合搜索 | 内置向量+关键词搜索 |
| OpenSearch | 需部署独立服务 | 已有 OpenSearch 集群 | Elasticsearch 开源替代 |
| PGVector | PostgreSQL 扩展 | 已有 PostgreSQL 环境 | 复用现有数据库 |
| Pinecone | 云端托管 | 云端部署,免运维 | 全托管,按用量计费 |
| S3 Vector | AWS S3 | AWS 生态 | 低成本存储 |
内置数据库,无需任何额外配置,开箱即用。适合个人和小团队。
1 | environment: |
1 | environment: |
1 | environment: |
1 | environment: |
对于大多数用户,ChromaDB 已经足够使用,无需额外配置。
整体最佳实践总结
根据以上所有配置项的分析,以下是推荐的最佳实践组合:
| 配置项 | 推荐值 | 理由 |
|---|---|---|
| 提取引擎 | 根据文档类型选择(见引擎选择建议表) | 复杂 PDF 用 Docling/MinerU/Mistral OCR,简单文档用默认 |
| PDF 加载模式 | Single Document | 语义连贯性优先 |
| 文本切分器 | 中文用 Token,英文用 Character | 中文字符数 ≠ token 数 |
| Chunk Size | 1000-2000 | 平衡上下文完整性和检索精度 |
| Chunk Overlap | Chunk Size 的 10% | 保证边界语义连贯 |
| Markdown 标题切分 | 开启(如果文档是 Markdown) | 保留文档结构,减少碎片 |
| 嵌入模型 | 本地:Ollama + nomic-embed-text | 免费、快速、质量好 |
| Hybrid Search | 开启 | 向量 + 关键词互补,显著提升召回率 |
| Reranking | 配合 Hybrid Search 开启 | 提升精度最有效的组合 |
| Top K | 5-10 | 平衡召回和噪音 |
| Relevance Threshold | 0.2-0.5 | 过滤低质量结果 |
| RAG System Context | true(Ollama 用户) | 优化多轮对话 KV cache |
| 向量数据库 | ChromaDB(默认) | 小团队足够,零配置 |
💡 核心原则:先确定嵌入模型(确定后不要轻易更换),再开启 Hybrid Search + Reranking,最后根据文档类型选择提取引擎。这三步是提升 RAG 质量投入产出比最高的操作。
3.5. 图像生成功能配置
Open WebUI 支持集成多种图像生成工具,让 AI 能够根据文字描述生成图片。
DALL-E 集成
DALL-E 是 OpenAI 的图像生成模型,质量高但需要付费。
配置步骤:
管理员面板 → 设置 → Images
找到 “图像生成引擎” 选项,选择 “OpenAI DALL-E”。
填写配置:
| 字段 | 值 |
|---|---|
| API Key | 你的 OpenAI API 密钥 |
| 模型 | dall-e-3(推荐)或 dall-e-2 |
| 图像尺寸 | 1024x1024(标准)、1792x1024(宽屏)、1024x1792(竖屏) |
| 图像质量 | standard(标准)或 hd(高清,更贵) |
费用说明:
- DALL-E 3 标准质量:$0.040 / 张
- DALL-E 3 高清质量:$0.080 / 张
- DALL-E 2:$0.020 / 张
ComfyUI 集成
ComfyUI 是一个开源的图像生成工作流工具,支持 Stable Diffusion 等模型。
前置要求:
你需要先部署 ComfyUI 服务。ComfyUI 的部署超出本教程范围,请参考 ComfyUI 官方文档。
配置步骤:
管理员面板 → 设置 → Images → 选择 “ComfyUI”
填写配置:
| 字段 | 说明 |
|---|---|
| ComfyUI Base URL | ComfyUI 服务地址,如 http://localhost:8188 |
| 工作流 JSON | ComfyUI 的工作流配置文件 |
工作流配置:
ComfyUI 使用 JSON 格式的工作流文件来定义图像生成流程。你需要:
- 在 ComfyUI 中设计好工作流
- 导出为 JSON 文件
- 将 JSON 内容粘贴到 Open WebUI 的配置中
优势:
完全免费(使用本地模型)
完全可控,可以自定义各种参数
支持多种 Stable Diffusion 模型
劣势:
- 配置复杂,需要一定的技术能力
- 需要额外的硬件资源(特别是 GPU)
AUTOMATIC1111 集成
AUTOMATIC1111 (Stable Diffusion WebUI) 是另一个流行的开源图像生成工具。
配置步骤:
管理员面板 → 设置 → Images → 选择 “AUTOMATIC1111”
填写配置:
| 字段 | 值 |
|---|---|
| API Base URL | http://localhost:7860 |
| API Key | 如果设置了认证,填入密钥 |
启用 API:
AUTOMATIC1111 默认不开启 API,需要在启动时添加参数:
1 | python launch.py --api --listen |
测试连接:
配置完成后,点击 “测试连接” 按钮,如果成功会显示可用的模型列表。
图像生成参数设置
无论使用哪种引擎,都可以配置默认的生成参数:
| 参数 | 说明 | 推荐值 |
|---|---|---|
| Steps | 生成步数,越多质量越好但越慢 | 20-30 |
| CFG Scale | 提示词引导强度 | 7-9 |
| Sampler | 采样器类型 | Euler a 或 DPM++ 2M |
| 负面提示词 | 不想出现的元素 | ugly, blurry, low quality |
这些参数主要用于 Stable Diffusion 类模型,DALL-E 不需要配置。
通过 CLIProxyAPI Plus 对接图像生成/编辑
如果你使用的是 CLIProxyAPI Plus(CPA)作为 OpenAI 兼容代理,它原生只提供 /v1/chat/completions 端点,不支持 /v1/images/generations 和 /v1/images/edits。但 Open WebUI 的 OpenAI 图像引擎恰恰需要这两个端点。
我们对 CPA 源码进行了 Fork 修改,新增了这两个端点,原理是将图像 API 请求转换为 Chat Completions 调用:
| 端点 | 请求格式 | 转换逻辑 |
|---|---|---|
POST /v1/images/generations | JSON(prompt + model) | 构建纯文本 chat completions 请求,从响应中提取 data:image/xxx;base64,... |
POST /v1/images/edits | multipart/form-data(image 文件 + prompt + model) | 将上传图片转为 base64 data URI,构建多模态 chat completions 请求(image_url + text) |
两个端点都返回标准 OpenAI Images API 格式:{"created": ..., "data": [{"b64_json": "..."}]}。
涉及的 CPA 源码文件:
sdk/api/handlers/openai/openai_images_handler.go— 新增文件,包含ImageGenerations和ImageEdits两个 handlerinternal/api/server.go— 在setupRoutes()的 v1 group 中注册路由(3 行改动)
Open WebUI 配置:
图像生成(管理员面板 → 设置 → Images):
| 字段 | 值 |
|---|---|
| 引擎 | OpenAI |
| API Base URL | http://host.docker.internal:8317/v1 |
| API Key | 你的 CPA api-key |
| 模型 | 手动输入模型 ID,如 prorise/gemini-3-pro-image-preview |
图像编辑配置同理,引擎选 OpenAI,URL 和 Key 相同,模型填支持图像编辑的模型 ID。
触发机制:
- 聊天中纯文字描述 → 触发
/images/generations(图像生成) - 聊天中上传图片 + 文字描述 → 触发
/images/edits(图像编辑,需开启ENABLE_IMAGE_EDIT)
注意事项:
- 图像模型建议在 Open WebUI 的模型高级设置中关闭流式输出(
stream_response: false),避免 chunk 过大导致前端显示异常 - CPA 源码 Fork 详见项目根目录的
FORK_README.md,同步上游更新时注意冲突风险
3.6. 语音功能配置
Open WebUI 的语音交互由两部分组成:听(STT,语音转文字) 和 说(TTS,文字转语音)。合理的配置需要在“响应速度、拟真体验、实际花销”三者之间找到平衡。
语音转文字(STT)配置
STT 决定了系统“听得有多准”和“听得有多快”,以及你聊天的成本消耗,由于语音转文字本质拉不开很大差距,一般来说都会使用网页API 或选择 Whisper 作为使用
1. 核心引擎横向对比与实际计费
| 引擎选型 | 成本梯队 | 实际计费标准 (预估) | 核心优势 |
|---|---|---|---|
| 网页 API | 免费 | $0 (利用浏览器原生能力) | 服务器零负载,响应极快,零成本 |
| Whisper (本地) | 免费 | $0 (仅消耗本机/服务器电费) | 隐私最强,完全离线,不按时长收费 |
| Deepgram | 低成本 | 约 $0.0043 / 分钟 | 专为实时语音设计,延迟极低,性价比极高 |
| OpenAI | 适中 | $0.006 / 分钟 | 业界标杆,多语言混合识别极准,无需额外注册 |
| Azure AI 语音 | 偏高 | 约 $1.00 / 小时 ($0.016/分) | 微软企业级稳定服务,带口音的方言识别优秀 |
2. 深度选型与成本解析
完全免费且省心:网页 API (Web API)
计费逻辑:绝对免费。它调用的是你当前所用浏览器(如 Chrome)内置的语音识别接口。
适用场景:预算为零,服务器没有显卡(GPU)跑不动本地模型,且能保证全程使用 HTTPS 访问的用户。
免费但吃硬件:Whisper (本地)
计费逻辑:软件层面免费,但隐性成本在硬件。它会占用你服务器的 CPU 和显存。如果租用云服务器,为了跑顺畅可能需要升级高配实例。
选型建议:如果你的服务器本身配置就高(如拥有 8GB 以上显存的独立显卡),强烈建议选这个。数据不出局域网,隐私绝对安全。
云端高性价比方案:Deepgram
计费逻辑:按秒计费,极其便宜。折算下来一小时一直说话也才两毛多美元。
选型建议:如果你需要高频使用语音对话,Deepgram 的 Nova-2 模型是首选。它的转录速度远快于 OpenAI,能大幅降低你等 AI 回复的“空窗期”。
高质量兜底方案:OpenAI Whisper
计费逻辑:按分钟计费。如果你每天和 AI 聊 10 分钟语音,一个月大约花费 $1.8。
选型建议:如果你平时说话中英文夹杂,或者专业术语多,OpenAI 的容错和纠错能力是目前云端 API 里最好的。
文字转语音(TTS)配置
TTS 决定了 AI 的“音色”和“情感”,这项功能由于需要生成音频文件,通常比 STT 更贵。
1. 核心引擎横向对比与实际计费
| 引擎选型 | 成本梯队 | 实际计费标准 (预估) | 拟真度 |
|---|---|---|---|
| 网页 API | 免费 | $0 (调用系统内置 TTS) | ⭐⭐ (明显机械音) |
| openai-edge-tts 🏆 | 免费 | $0 (微软 Edge 在线语音,中间件伪装) | ⭐⭐⭐⭐⭐ (中文场景极佳,接近 OpenAI) |
| Transformers | 免费 | $0 (消耗本地算力生成) | ⭐⭐⭐ (略带顿挫感) |
| OpenAI | 低成本 | $0.015 / 千字符 | ⭐⭐⭐⭐ (非常自然流畅) |
| Azure AI 语音 | 适中 | 约 $0.016 / 千字符 | ⭐⭐⭐⭐ (专业播音腔,可选多) |
| ElevenLabs | 昂贵 | 约 $0.22 / 千字符 (按标准套餐折算) | ⭐⭐⭐⭐⭐ (情感天花板) |
2. 深度选型与成本解析
零成本测试首选:网页 API
计费逻辑:免费。直接让你的 Windows 或 macOS 系统里的"讲述人"来读出文字。
体验:毫无感情,适合用来排查语音链路通不通,不适合长期对话。
🏆 中文场景版本答案:openai-edge-tts(强烈推荐)
计费逻辑:完全免费。它通过一个开源中间件(travisvn/openai-edge-tts,GitHub 1.6k+ Stars),将微软 Edge 浏览器内置的高质量在线语音接口伪装成 OpenAI TTS 接口给 Open WebUI 使用。你在抖音/TikTok 上听到的那些非常自然的 AI 解说音,用的就是同一套微软语音引擎。
选型建议:面向国内中文用户的最佳选择。音质接近 OpenAI TTS,远超本地机械音,且完全免费、无需 GPU。Open WebUI 官方文档已有专门的集成页面。唯一注意点:它本质是微软云服务的代理,需要联网才能使用,不是真正的离线方案。
部署步骤:
第一步:启动 Docker 容器
1
docker run -d -p 5050:5050 -e API_KEY=your_password travisvn/openai-edge-tts:latest
第二步:在 Open WebUI 管理面板中配置
进入 管理员面板 → 设置 → 语音,在 TTS 部分填写:
配置项 填写内容 说明 TTS 引擎 OpenAI注意:选 OpenAI,不是 Edge,因为中间件伪装成了 OpenAI 接口 API 基础 URL http://host.docker.internal:5050/v1如果 Open WebUI 也在 Docker 中运行;否则填 http://localhost:5050/v1API 密钥 your_password与 Docker 启动时的 API_KEY保持一致TTS 模型 tts-1固定值 TTS 语音 zh-CN-XiaoxiaoNeural最受欢迎的中文女声;男声可选 zh-CN-YunxiNeural💡 更多语音选择:Edge TTS 支持大量中文语音,如
zh-CN-XiaoyiNeural(年轻女声)、zh-CN-YunjianNeural(新闻播报男声)等,完整列表可在容器启动后访问http://localhost:5050/v1/voices查看。⚠️ 注意:此方案依赖微软在线服务,断网时无法使用。如果你需要完全离线的 TTS,请考虑 Transformers 本地方案或下方的 Kokoro-FastAPI。
补充:英文场景的替代方案 —— Kokoro-FastAPI
如果你的用户主要使用英文对话,社区中另一个高口碑项目是 Kokoro-FastAPI。它完全本地运行,英文语音质量被社区评为当前最佳,同样提供 OpenAI 兼容 API。但中文支持较弱,因此面向国内用户时 openai-edge-tts 仍是首选。
极致性价比:OpenAI TTS
计费逻辑:按生成的字符数收费。1000 个英文字符或中文字大概只要 1 分多钱(美元)。即使重度使用,每个月也就几美元。
选型建议:90% 用户的最佳选择。模型选
tts-1即可(tts-1-hd贵一倍且速度慢,对话时完全没必要)。声音推荐Alloy(中性)或Nova(活力)。如果你需要更高质量的选型(听觉享受):ElevenLabs
计费逻辑:非常贵。采用订阅+额度制(如 $22/月 给 10 万字符),折算下来单价比 OpenAI 贵了 15 倍左右。
为什么选它:物有所值。它是目前唯一能做到“根据上下文叹气、呼吸、调整情绪甚至哭腔”的 API。如果你把 AI 当作情感树洞,或者需要克隆特定人的声音,这笔钱花得值。
3.7. 网络搜索功能配置
网络搜索功能让 AI 能够获取最新的网络信息,突破模型训练数据的时效性限制。用户在对话中开启"联网搜索"开关后,Open WebUI 会先调用搜索引擎获取实时结果,再注入到 LLM 上下文中辅助回答。
配置入口:管理员面板 → 设置 → 联网搜索
配置项说明
| 配置项 | 说明 | 推荐值 |
|---|---|---|
| 启用联网搜索 | 总开关,关闭时所有用户均无法使用 | 按需开启 |
| 搜索引擎 | 下拉选择提供商,选择后下方动态显示该引擎所需字段(Key、URL 等) | 见下方选型 |
| 搜索结果数量 | 每次返回的结果条数,太少信息不足,太多增加 token 消耗 | 5-8 |
| 并发数 | 同时抓取结果页面的并发数,过高可能触发速率限制 | 默认即可 |
| 旁路 SSL 验证 | 跳过 SSL 证书验证,仅自部署引擎用自签名证书时开启 | 关闭 |
全部搜索引擎一览
🟢 完全免费(自部署或无需 Key)
- DuckDuckGo(
duckduckgo)— 零配置开箱即用,无需 API Key,通过 Python 库直接调用。缺点:可能被速率限制,国内需代理 - SearXNG(
searxng)— 🏆 社区最推荐。开源元搜索引擎,聚合 Google、Bing 等 70+ 引擎结果,需 Docker 自部署,完全免费、无限次数、隐私安全 - YaCy(
yacy)— 去中心化 P2P 搜索引擎,完全自托管,搜索质量远不如 SearXNG - Ollama Cloud(
ollama_cloud)— 用本地 Ollama 模型生成搜索,完全离线但质量有限
🔵 有免费额度(白嫖友好,需注册获取 Key)
- Serper(
serper)— 🏆 性价比之王。基于 Google SERP,注册送 2,500 次(一次性),付费 $0.30/千次起,速度极快 - Brave(
brave)— 每月 2,000 次免费(每月刷新),独立搜索索引,隐私友好,超出后 $3/千次 - Tavily(
tavily)— 每月 1,000 次免费,专为 AI/RAG 设计,返回干净文本,超出后 $0.008/次 - Exa(
exa)— 注册送 $10 额度(约 2,000 次),AI 原生语义搜索,超出后 $5/千次 - Google PSE(
google_pse)— 每天 100 次免费(约 3,000 次/月),搜索质量就是 Google 本身,超出后 $5/千次 - Firecrawl(
firecrawl)— 一次性 500 次免费,搜索 + 深度抓取网页内容,超出后 $16/月起 - SearchApi(
searchapi)— 注册送 100 次,支持 Google/Bing/Baidu/Scholar 多引擎切换,超出后 $50/月起 - Serpstack(
serpstack)— 每月 100 次免费,基于 Google SERP,超出后 $30/月起 - SerpApi(
serpapi)— 每月 100 次免费,功能最全但价格偏高 $25/月起 - Jina(
jina)— 注册送积分,支持语义搜索和网页内容提取,适合 RAG 场景
🟡 纯付费(无免费额度或需订阅)
- Bing(
bing)— ⚠️ 微软已于 2025 年 8 月宣布退役,不推荐新用户 - Kagi(
kagi)— $10/月起订阅制,高质量无广告搜索 - Mojeek(
mojeek)— 英国独立搜索引擎,有自己的爬虫索引,需联系定价 - Serply(
serply)— $49/月起,性价比不高 - Bocha(
bocha)— 🇨🇳 国产博查搜索,国内可直连,需联系定价 - Sogou(
sougou)— 🇨🇳 搜狗搜索,国内可直连,需联系定价 - Yandex(
yandex)— 俄罗斯搜索引擎,俄语搜索质量好
🟣 AI 增强搜索
- Perplexity(
perplexity)— Sonar API,搜索 + AI 总结,Pro 订阅每月附赠 $5 额度 - Perplexity Search(
perplexity_search)— 同上,纯搜索不含 AI 总结 - External(
external)— 万能逃生舱,指向任意自定义 HTTP 搜索服务
💡 以上除 Bocha、Sogou 外,其余引擎均需代理才能在国内访问。
选型推荐与部署
🏆 最优解:SearXNG 自部署
适合有服务器的个人/团队,零成本、无限次数、隐私安全。社区公认的最佳方案。
部署步骤:
- 克隆仓库并进入目录:
1 | git clone https://github.com/searxng/searxng-docker.git |
- 修改
settings.yml(最关键一步,必须启用 JSON 格式,否则 Open WebUI 报 403):
1 | use_default_settings: true |
- 启动:
docker compose up -d,或在 Open WebUI 的docker-compose.local.yaml中添加:
1 | services: |
- 在 Open WebUI 中配置:搜索引擎选
searxng,查询 URL 填http://searxng:8080/search?q=<query>(Docker 同网络)或http://localhost:8080/search?q=<query>。
⚠️ 常见问题:
- 403 错误:99% 是
settings.yml没加json格式- 结果为空:SearXNG 容器需能访问外网,国内服务器需为 SearXNG 容器配代理
- 超时:检查
limiter是否为false,上游搜索引擎是否可达
💰 零成本懒人方案:DuckDuckGo
不想部署任何服务的用户,搜索引擎选 duckduckgo 即可,无需填写任何 Key。缺点是可能被限流、国内需代理、搜索质量不如 Google。
🎯 付费性价比之选:Serper
需要 Google 级搜索质量但预算有限的用户。访问 https://serper.dev 注册,复制 API Key,搜索引擎选 serper 填入即可。注册送 2,500 次,付费后 $0.30/千次起。
🇨🇳 国内直连方案:Bocha / Sogou
服务器在国内、无法配代理的用户。Bocha(博查)和 Sogou(搜狗)国内可直连,中文搜索质量较好,需联系服务商获取 Key 和定价。
成本速算
假设日均搜索 20 次(月均 600 次):
| 方案 | 月成本 | 说明 |
|---|---|---|
| SearXNG 自部署 | $0 | 仅消耗服务器资源 |
| DuckDuckGo | $0 | 可能被限流 |
| Brave 免费额度 | $0 | 每月 2,000 次,完全够用 |
| Google PSE 免费额度 | $0 | 每天 100 次,完全够用 |
| Tavily 免费额度 | $0 | 每月 1,000 次,勉强够用 |
| Serper 免费额度 | $0 | 2,500 次一次性,约可用 4 个月 |
| Serper 付费 | ~$0.18 | 超出免费额度后 |
| Brave 付费 | ~$1.80 | 超出免费额度后 |
| Kagi | $10+ | 订阅制 |
💡 个人使用(日均 <30 次),Brave(2,000 次/月)或 Google PSE(100 次/天)的免费额度完全够用。团队或高频搜索,SearXNG 自部署是唯一真正无限制的方案。
3.8. Pipelines 与 Functions 扩展系统
Open WebUI 提供了两种扩展机制:Functions(函数)和 Pipelines(管道)。理解它们的区别非常重要,选错了会让简单的事情变复杂。
⚠️ 官方明确建议:对于大多数扩展需求(如添加新的 API 提供商、基础过滤器、简单工具),请使用 Functions,不要使用 Pipelines。Pipelines 仅适用于需要将计算密集型任务卸载到独立进程的场景。
Functions vs Pipelines:如何选择
| 对比项 | Functions(推荐优先) | Pipelines |
|---|---|---|
| 部署方式 | 内置于 Open WebUI,无需额外服务 | 需要独立部署 Pipelines 服务 |
| 适用场景 | 添加 API 提供商、过滤器、工具、按钮动作 | 计算密集型任务(如大规模数据处理、自定义 ML 推理) |
| 管理方式 | 管理员面板 → 函数 | 管理员面板 → 设置 → Pipelines |
| 开发难度 | 简单,直接在 Web 界面编写 | 较复杂,需要独立服务和 Docker 部署 |
| 性能影响 | 在主进程中运行 | 独立进程,不影响主服务 |
简单判断规则:如果你不确定该用哪个,用 Functions。只有当你明确需要在独立进程中运行计算密集型任务时,才考虑 Pipelines。
Functions(函数)
Functions 是 Open WebUI 内置的扩展机制,直接在管理员面板中管理,无需额外部署。
Functions 的四种类型:
| 类型 | 说明 | 使用场景 |
|---|---|---|
| Filter | 在消息发送到模型前/后进行处理 | 内容过滤、格式转换、日志记录 |
| Action | 在消息气泡上添加自定义按钮 | 一键翻译、一键总结、复制格式化内容 |
| Tool | 为模型提供可调用的工具 | 网络搜索、数据库查询、API 调用 |
| Pipe | 添加新的模型端点或 API 提供商 | 接入自定义 API、代理转发 |
管理 Functions:
管理员面板 → 函数(Functions)
在这里你可以:
- 创建新函数(直接在 Web 编辑器中编写 Python 代码)
- 从社区导入函数
- 启用/禁用函数
- 配置函数参数(Valves)
社区函数库:
Open WebUI 社区提供了大量现成的函数,访问 https://openwebui.com/functions/ 浏览和导入。
💡 Functions 的详细开发将在后续章节中介绍。本节重点是让管理员了解如何管理和配置。
Pipelines(仅限计算密集型场景)
如果你确实需要将计算密集型任务卸载到独立进程,才需要部署 Pipelines。
部署 Pipelines 服务:
在你的 docker-compose.local.yaml 中添加 Pipelines 服务:
1 | services: |
启动后访问 http://localhost:9099/docs 验证 Pipelines API 是否正常。
在 Open WebUI 中连接:
管理员面板 → 设置 → Pipelines → 填入 http://pipelines:9099 → 点击刷新
管理插件:
连接成功后,你可以:
- 上传 Python 插件文件(
.py) - 启用/禁用插件
- 配置插件参数(Valves)
Pipelines 插件示例:
官方示例仓库:https://github.com/open-webui/pipelines/tree/main/examples
| 插件名称 | 功能 | 使用场景 |
|---|---|---|
| Langfuse | 集成 Langfuse 监控平台 | 大规模使用量监控 |
| LLM Guard | 防止提示词注入攻击 | 安全防护(计算密集) |
| Detoxify | 基于 ML 模型的有害内容过滤 | 内容安全(需要 GPU) |
💡 像 Rate Limit(限流)、LibreTranslate(翻译)这类轻量级功能,现在推荐使用 Functions 实现,不再需要部署 Pipelines。
3.9. 安全与认证配置
这一章讲的是“谁能登录、谁能调用 API、用户身份如何同步、会话如何保活”。
如果你是个人用户,这部分很多配置可以先不动;但只要进入团队协作、公司内网、对接脚本或自动化系统,这一章就会变成必修课。
在开始之前,先解释几个经常会混在一起的术语:
- 认证(Authentication):证明“你是谁”。例如账号密码登录、LDAP 登录、Google 登录。
- 授权(Authorization):决定“你能做什么”。例如能不能看某个模型、能不能导出模型、能不能管理工具。
- API Key:发给程序用的密钥,适合脚本、集成平台、外部服务调用 Open WebUI API。
- LDAP:企业常见的目录服务协议,很多公司的 AD(Active Directory)也兼容这套方式。
- OAuth / OIDC:第三方登录体系。OAuth 偏“授权”,OIDC 是建立在 OAuth 之上的“身份登录”标准。
- SCIM:自动开通和回收账号的标准,不负责“登录”,而负责“账号生命周期同步”。
API 密钥认证
这是什么
Open WebUI 支持为用户生成 API Key,让外部脚本、自动化流程、内部平台、工作流引擎通过 HTTP API 访问它。
典型场景包括:
- 用 Python、Node.js 或 Shell 脚本调用聊天接口
- 用企业内部系统转发请求到 Open WebUI
- 给工作流平台、Bot、自动化任务提供一个稳定认证方式
它和“浏览器登录 Cookie”不是一回事:
- 浏览器登录主要给人用
- API Key 主要给程序用
如何启用
管理员面板 → 设置 → 通用 → 启用 API Key
启用后,用户就可以在自己的账号设置中创建 API Key。
当前版本除了总开关外,还支持 API Key Endpoint Restrictions,也就是“限制 API Key 只能访问哪些接口”。这个能力很重要,因为它可以避免把一把过大的密钥发给外部系统。
用户如何生成密钥
点击头像 → 设置 → 账号 → API 密钥 → 点击“创建新密钥”
创建后要立即保存,因为这类密钥通常不会反复明文展示。
调用示例
1 | curl -X POST http://localhost:3000/api/chat \ |
官方建议理解
官网当前的方向不是“默认把所有接口都敞开”,而是:
- 可以启用 API Key
- 可以进一步启用接口级限制
- 在可信内网环境里可以更宽松,在生产环境则建议更严格
我的管理方式
在我的环境里,API Key 主要给“程序”而不是“人”使用,所以我通常这样管理:
- 浏览器用户走正常登录,不给所有人默认要求 API Key。
- 只有确实需要脚本调用的账号,才生成 API Key。
- 给外部系统时,优先启用接口限制,不给过大的权限面。
- 定期清理不再使用的密钥,避免历史脚本长期持有可用凭证。
- 如果只是临时测试,我会单独创建测试用密钥,不和正式环境长期复用。
LDAP 集成
这是什么
LDAP 可以理解为“公司统一通讯录 / 账号目录”的标准接口。
如果你所在的组织已经有 AD、OpenLDAP 或其他企业目录系统,那么 Open WebUI 可以直接对接这个目录,让员工使用公司账号登录,而不是在 Open WebUI 里重复创建本地账号。
适合谁
- 公司内网部署
- 已有统一身份管理
- 希望账号、邮箱、用户名来自企业目录
个人部署、小团队、临时测试环境,通常不需要上 LDAP。
官方配置思路
LDAP 推荐先通过环境变量初始化,然后在管理员面板里继续维护。官网特别强调一件事:
如果启用了持久化配置(默认就是),很多环境变量只在第一次启动时读入;后续修改通常要在管理后台里改,而不是只改
docker-compose。
这点非常重要,也是很多人“明明改了环境变量,怎么界面没变”的根源。
当前版本常见环境变量
1 | environment: |
你会发现,这一版和很多旧博客里写的 LDAP_SERVER_URL、LDAP_BIND_DN 之类名字不完全一样。写文档时一定要以当前版本为准。
参数解释
| 参数 | 说明 |
|---|---|
ENABLE_LDAP | 是否启用 LDAP 登录 |
LDAP_SERVER_LABEL | 在界面里显示的 LDAP 名称 |
LDAP_SERVER_HOST / LDAP_SERVER_PORT | LDAP 服务器地址和端口 |
LDAP_ATTRIBUTE_FOR_MAIL | 从 LDAP 条目里取邮箱的字段 |
LDAP_ATTRIBUTE_FOR_USERNAME | 从 LDAP 条目里取用户名的字段 |
LDAP_APP_DN / LDAP_APP_PASSWORD | 用于查询目录的服务账号 |
LDAP_SEARCH_BASE | 搜索用户的根 DN |
LDAP_SEARCH_FILTER | 登录时查找用户的过滤器 |
LDAP_USE_TLS | 是否启用 TLS / StartTLS |
正确的排错顺序
不要一上来就怀疑 Open WebUI。
官网推荐的思路是:
- 先验证 LDAP 服务器本身通不通
- 再验证用户条目能不能查到
- 最后才看 Open WebUI 配置
例如:
1 | ldapsearch -x -H ldap://ldap.example.com:389 \ |
如果这一步都查不到用户,就不要继续在 WebUI 里盲改了。
我的管理方式
我自己的判断规则很简单:
- 如果是企业内部正式使用,并且员工已经有统一账号体系,我会优先接 LDAP。
- 如果只是个人站点、朋友共用、测试环境,我不会为了“看起来企业化”硬上 LDAP。
- 上 LDAP 后,我会尽量让用户名、邮箱、显示名都来自目录系统,避免 Open WebUI 自己成为第二套主数据来源。
OAuth / OIDC / SSO 集成
这是什么
这一组就是“第三方登录”。
最常见的使用方式是:
- 用 Google 账号登录
- 用 Microsoft / Entra ID 账号登录
- 用 GitHub 账号登录
- 用企业自己的 OIDC 服务登录
如果说 LDAP 更像“公司内网目录登录”,那 OAuth / OIDC 更像“现代网站统一登录”。
先说结论:本地开发完全可以配
而且你现在这个仓库已经改成了:
docker-compose.local.yaml自动读取.env.local- 本地端口由
OPEN_WEBUI_PORT控制 - Google、Microsoft、GitHub 三家都可以直接写在
.env.local
所以对读者来说,最容易跟做的方式就是:
- 去各自官网创建 OAuth 应用
- 把回调地址填成 Open WebUI 本地回调
- 把拿到的密钥填进
.env.local - 重启本地容器
本地统一配置模板
如果你的本地端口是 3000,那么 .env.local 先这样写:
1 | OPEN_WEBUI_PORT=3000 |
写完后执行:
1 | docker compose -f docker-compose.local.yaml up -d --build |
如果你的端口不是 3000,例如 5050,那上面所有 localhost:3000 都要统一改成 localhost:5050。
适用场景
如果你想直接使用 Google 账号登录,这是最常见的一种配置。
第 1 步:去 Google 官方后台创建应用
访问:
https://console.cloud.google.com/apis/credentials
进入后:
- 创建或选择一个 Project
- 打开
APIs & Services - 进入
Credentials(凭证) - 点击
Create Credentials - 选择
OAuth client ID - Application type 选择
Web application
第 2 步:登记回调地址
在 Authorized redirect URIs 中填写:
1 | http://localhost:3000/oauth/google/login/callback |
第 3 步:把拿到的密钥填入 .env.local
1 | GOOGLE_CLIENT_ID=你的 Google Client ID |
第 4 步:重启本地 Open WebUI
1 | docker compose -f docker-compose.local.yaml up -d --build |
注意事项
- Google 开发环境允许
http://localhost - 回调地址必须和后台里登记的 URI 完全一致
- 如果你改了端口,Google 后台也要一起改
适用场景
如果用户本身就在 Microsoft 365、Entra ID、企业账号体系里,这一项非常常见。
第 1 步:去 Microsoft Entra 后台注册应用
访问:
进入后:
- 打开
Microsoft Entra ID - 进入
App registrations - 点击
New registration - 创建一个应用
第 2 步:配置回调地址
在 Authentication 页面里添加:
1 | http://localhost:3000/oauth/microsoft/login/callback |
第 3 步:生成 Secret 并写入 .env.local
在 Certificates & secrets 中生成一个 Client secret,然后填入:
1 | MICROSOFT_CLIENT_ID=你的 Microsoft Client ID |
如果你只允许某一个租户登录,把 common 改成你的实际 Tenant ID 即可。
第 4 步:重启本地 Open WebUI
1 | docker compose -f docker-compose.local.yaml up -d --build |
注意事项
- Microsoft 也支持本地
localhost回调 - 本地开发可以先用
common - 正式环境建议单独使用正式域名和正式应用注册
适用场景
如果你的用户本身大量使用 GitHub,这是最容易理解、也最容易测试的一项。
第 1 步:去 GitHub Developer Settings 创建 OAuth App
访问:
https://github.com/settings/developers
进入后:
- 打开
OAuth Apps - 点击
New OAuth App
第 2 步:填写回调地址
最关键的是 Authorization callback URL:
1 | http://localhost:3000/oauth/github/login/callback |
第 3 步:把密钥填入 .env.local
1 | GITHUB_CLIENT_ID=你的 GitHub Client ID |
第 4 步:重启本地 Open WebUI
1 | docker compose -f docker-compose.local.yaml up -d --build |
注意事项
- GitHub 对 callback URL 也是精确匹配
- 如果后台填的是
127.0.0.1,本地配置也要统一成127.0.0.1 - 不要后台填
127.0.0.1,本地却写localhost
为了更容易排错,我建议不要一上来三个一起配,而是按这个顺序:
- 先配一个,例如 GitHub
- 测通之后,再加 Google
- 最后再加 Microsoft
这样如果出现问题,最容易定位。
最常见的报错就是:
redirect_uri_mismatch- 端口改了,但开放平台后台没改
.env.local改了,但容器没重启- 后台写的是
127.0.0.1,本地写的是localhost
SCIM 自动开通与回收
这是什么
SCIM 不是登录协议,而是“账号生命周期同步协议”。
它解决的问题是:
- 新员工入职时,自动在 Open WebUI 创建账号
- 员工信息变化时,自动同步更新
- 员工离职时,自动停用账号
- 用户组成员关系自动同步
所以可以把它理解成“自动开账号、改账号、停账号”的标准接口。
和 OAuth / LDAP 的关系
- LDAP / OAuth / OIDC:解决“怎么登录”
- SCIM:解决“账号怎么自动创建和同步”
很多企业会同时使用:
- 用 OIDC 登录
- 用 SCIM 做账号与组同步
当前版本配置
1 | environment: |
参数解释
| 参数 | 说明 |
|---|---|
SCIM_ENABLED | 是否启用 SCIM |
SCIM_TOKEN | 调用 SCIM API 的 Bearer Token |
SCIM_AUTH_PROVIDER | 用于把 SCIM externalId 和对应认证提供商关联起来,例如 microsoft、oidc |
这里的 SCIM_AUTH_PROVIDER 很容易被漏掉,但当前版本里它是重要配置,尤其是在账户关联和 externalId 保存上。
对接端点
SCIM Base URL:
1 | https://your-domain.com/api/v1/scim/v2/ |
常见资源端点:
| 资源 | 端点 |
|---|---|
| 用户 | /api/v1/scim/v2/Users |
| 组 | /api/v1/scim/v2/Groups |
我的管理方式
我把 SCIM 视为“企业级增强项”:
- 小规模自用:完全不需要
- 团队规模不大,但已有统一登录:先上 OAuth / LDAP,SCIM 可以以后再说
- 企业正式上生产:如果人事变动频繁、合规要求高,就值得上 SCIM
它的价值不在“让用户多一个登录按钮”,而在于减少人工维护账号、降低离职账号遗留风险。
会话、JWT 与 Cookie
这是什么
用户在浏览器里登录后,Open WebUI 需要一种机制记住登录状态,这通常会涉及:
- JWT:登录令牌
- Session Cookie:浏览器保存的登录凭证
- Secret Key:服务器用来签名和加密敏感数据的密钥
当前版本重点配置
1 | environment: |
参数解释
| 参数 | 说明 |
|---|---|
WEBUI_SECRET_KEY | 最关键的持久化密钥,用于会话签名和敏感数据解密 |
JWT_EXPIRES_IN | 登录令牌过期时间,例如 4w、7d |
WEBUI_SESSION_COOKIE_SAME_SITE | Cookie 的跨站策略 |
WEBUI_SESSION_COOKIE_SECURE | 是否只通过 HTTPS 发送 Cookie |
为什么 WEBUI_SECRET_KEY 非常重要
官网 FAQ 专门提到,如果你每次重建容器都不保留同一个 WEBUI_SECRET_KEY,会出现两类典型问题:
- 用户升级或重启后被全部强制退出
- 一些已经加密保存的令牌、API Key、OAuth 凭证无法解密
所以这个值一定要固定,不要让容器每次随机生成。
我的管理方式
这一点我会非常保守:
- 生产环境固定设置
WEBUI_SECRET_KEY - HTTPS 环境强制
WEBUI_SESSION_COOKIE_SECURE=true - 不把
JWT_EXPIRES_IN设成无限期 - 升级容器前先确认密钥仍然通过同样方式注入
这是最容易被忽略、但一出问题就会直接影响所有用户登录体验的一块。





