
Prorise
这是我的博客,分享技术与生活的点点滴滴
React组件库实战 - 第七章. 专业的 React API Mocking:MSW
React组件库实战 - 第七章. 专业的 React API Mocking:MSW
Prorise第七章. 专业的 API Mocking:从 json-server 到 MSW
本章目标: 现代前端开发与 API 紧密相连。本章,我们将深入探讨“API Mocking”这一核心工程化议题。我们将 横向对比 Mock.js、json-server 等传统方案,并最终聚焦于当前 React 社区的最佳实践——MSW (Mock Service Worker)。我们将深入其工作原理,并以构建一个智能 AutoComplete 组件为实战载体,将 MSW 与我们在第六章学习的高级 Hooks 模式(useControllableState, useReducer 模式等)进行完美结合。
7.1. 痛点与需求:为什么前端需要 API Mocking?
在深入探讨解决方案之前,我们必须先对问题本身建立一个清晰、深刻的认知。为什么一个临时的假数据文件或简单的 Mock 方式,在专业开发中是远远不够的?
7.1.1. 开发流程中的“阻塞”问题
让我们从一个在任何采用前后端分离的敏捷团队中,都几乎每周都会上演的经典场景开始。
场景: 新的 Sprint 开始,产品经理提出了一个需求:“开发用户个人资料页面”。经过评审,前后端工程师共同协定了一个 API 接口契约:
- Endpoint:
GET /api/user/:id - Success Response (JSON):
1
2
3
4
5
6{
"id": "12345",
"name": "Prorise",
"email": "contact@prorise.com",
"registeredAt": "2025-10-15T10:30:00Z"
}
任务分配完毕,后端同学去进行数据库设计和接口开发,而我们,作为前端工程师,则开始构建 UI。
前端的困境
凭借我们强大的组件库,我们可以在几个小时内就迅速搭建出页面的静态 UI 骨架。
文件路径: src/app/profile-page/page.tsx
1 | function UserProfileCard() { |
UI 骨架已经就绪,下一步就是编写 useEffect 数据请求逻辑。于是,我们与后端同学进行了如下沟通:
Hey @后端, 个人资料页面的 UI 已经准备好了。/api/user/:id 这个接口的开发环境地址出来了吗?我需要连接它来完成后续的数据绑定和加载、错误状态的处理。
抱歉,数据库那边遇到点迁移问题,比预想的要复杂一些。这个接口的 dev 环境估计要到周五才能提供。
好的,没问题…
“阻塞”发生了。
在这一刻,我们作为前端工程师的开发流程被硬生生地打断了。我们 无法:
- 编写和调试真实的数据请求逻辑 (
fetch/axios)。 - 开发和预览组件在“加载中 (Loading)”状态下的 UI (例如,一个骨架屏 Skeleton)。
- 开发和验证组件在“请求失败 (Error)”状态下的 UI (例如,一个错误提示)。
- 使用真实结构的数据来完成后续的 UI 开发。
我们陷入了被动的等待,或者只能转向一些临时的、会遗留技术债的“脏”办法,例如在组件里硬编码一个假数据对象。这种对外部服务的 强依赖,使得我们的开发流程变得脆弱、低效且充满不确定性。
我们需要一种方法,来 在前端项目内部,可靠地、真实地模拟出后端 API 的行为,从而将我们的开发流程与后端同学的进度 解耦,实现真正的并行开发。这,就是 API Mocking 的首要价值。
7.1.2. 边界测试的挑战
我们已经明确了 API Mocking 的第一个核心价值:解耦前后端,打破开发流程中的“阻塞”。
现在,我们来看第二个同样重要的理由。即使后端 API 已经完美地按时交付,我们依然需要一个专业的 Mocking 方案,因为一个健壮的前端组件,不仅要能正确处理“成功”的情况,更要能优雅地应对各种“异常”和“边界”情况。
请思考以下几个在日常开发中非常常见,但又极其难以测试的场景:
如何测试“加载中 (Loading)”状态?
如果后端 API 响应速度极快(例如,在本地开发环境中只有 10ms),我们的加载动画(如骨架屏或 Spinner)可能只会一闪而过,我们根本无法在视觉上验证它的样式和行为是否正确。如何测试“请求失败 (Error)”状态?
我们的 UI 需要在一个漂亮的Alert组件中,向用户展示“服务暂不可用,请稍后重试”的提示。我们如何触发这个场景?难道要请求后端工程师为了配合我们的前端调试,手动去关闭或弄崩溃他们的服务器吗?这在协作中显然是不现实的。如何测试“空状态 (Empty State)”?
当用户搜索一个不存在的关键词时,API 应该返回一个空数组[],此时界面需要展示一个“未找到相关结果”的提示。我们或许可以通过输入一些随机字符串来触发这个场景,但这并不稳定和可靠。
核心痛点:
一个真实、健康的后端 API,其行为是 难以被前端开发者精确控制 的。我们无法轻易地让它“变慢”、让它“出错”、或者让它“返回空数据”。这种不可控性,导致我们对组件在这些边界情况下的表现,要么是凭空想象,要么是放弃测试,最终将未经充分验证的代码发布到生产环境,留下巨大的隐患。
我们需要一个“API 遥控器”,让我们能够随心所欲地控制接口的行为,精确地模拟出任何我们想要测试的场景。这,就是 API Mocking 的第二个核心价值:实现全面的、可靠的边界条件测试。
7.1.3. 故事驱动开发的障碍
最后,我们来看第三个痛点,它与我们课程的核心——“黄金工作流”——息息相关。
核心问题: 在我们以 Storybook 为中心的开发模式中,如何为一个依赖异步数据的组件(如 UserProfileCard)编写独立、稳定、可复用的 Stories?
设想一下,我们需要为 UserProfileCard 组件编写三个 Stories,分别对应“加载中”、“请求成功”和“请求失败”这三种状态。我们会立刻陷入两难的境地:
方案一:污染组件 API (错误示范)
我们可能会尝试为组件添加一些“仅供测试”的 props:
1 | // 在 Storybook 中这样使用 |
弊端: 这种做法严重 污染 了组件的生产环境 API,在组件内部塞满了与业务无关的测试逻辑,是一种非常糟糕的实践。
方案二:在 Story 中真实请求 API (错误示范)
我们也可以让 Story 在渲染时,真实地去调用 /api/user/:id 接口。
弊端:
- 依赖外部服务: 我们的 Storybook 现在依赖于一个正在运行的、健康的后端服务。如果后端环境崩溃,我们的整个组件文档和可视化测试系统也会随之瘫痪。
- 状态不确定: API 返回的数据可能会变化,这使得 Story 不再是一个确定性的、可预测的组件状态快照。这对于后续进行视觉回归测试是致命的。
- 无法模拟边界: 我们仍然无法通过这种方式,来创建一个稳定展示“请求失败”状态的 Story。
我们真正需要的:
我们需要一种能力,能够 在 Storybook 的环境中,为每一个 Story 单独提供一个特定的、可控的 API 响应。
- 对于
LoadingStory,我们需要能让/api/user/:id这个接口“假装”正在请求中,并且永远不返回结果。 - 对于
ErrorStory,我们需要能让这个接口立刻返回一个500错误。 - 对于
SuccessStory,我们需要能让这个接口立刻返回一份我们预设好的、稳定的 JSON 数据。
这,就是 API Mocking 在“组件驱动开发”流程中不可替代的价值:保障 Story 的隔离性、确定性和可维护性。
7.1.4 本节小结
通过以上分析,我们明确了在一个专业的、现代化的前端工程中,我们需要 API Mocking 来解决的三大核心痛点:
| 痛点 | 核心问题 | 导致的后果 |
|---|---|---|
| 开发流程阻塞 | 前端依赖未就绪的后端 API | 开发停滞,效率低下,交付延迟 |
| 边界测试困难 | 无法在前端精确控制 API 的响应状态 (如错误、延迟) | 组件鲁棒性不足,对异常情况的处理未经检验 |
| Storybook 隔离失效 | 异步组件的故事要么污染代码,要么依赖真实网络 | 文档不稳定,无法进行可靠的视觉回归测试 |
带着这三个明确的问题,我们现在已经做好了充分的准备,将在下一节中,开始对业界主流的 Mocking 解决方案进行一次全面的横向对比,以找到那个能够同时完美解决所有这些问题的“终极武器”。
7.2. Mocking 方案横向对比
在明确了我们需要专业的 API Mocking 工具来解决的三大痛点之后,我们来快速地对业界主流的几种方案进行横向对比,以理解为什么 MSW 是我们当前的不二之选。
方案一 (Mock.js):应用层拦截
这是早期前端 Mocking 的代表。它的核心原理是通过在代码层面覆写(Monkey-patching)浏览器原生的 XMLHttpRequest 对象,来拦截应用发出的 Ajax 请求并返回预设的假数据。
核心痛点: 这种方式 侵入性极强,直接修改了浏览器的全局对象。它默认不支持 fetch API,与 Node.js 测试环境(如 Vitest)不兼容,且社区已基本停止维护,是一种 完全过时 的方案。
方案二 (json-server):外部 Mock 服务器
json-server 提供了一种快速搭建独立 Mock 服务器的方案。
核心理念: 通过一个 db.json 文件,快速启动一个功能完整的、符合 RESTful 规范的 Node.js API 服务器。
1 | # 1. 创建 db.json 文件: { "users": [{ "id": 1, "name": "Prorise" }] } |
核心痛点: 它的主要问题在于 隔离性。它是一个完全独立的外部进程,难以与我们的前端项目(特别是 Storybook 和单元测试)进行无缝集成。同时,用它来模拟复杂的业务逻辑(例如,根据请求头返回不同内容)或特定的错误状态(如 500 错误)也相对繁琐。
现代答案 (MSW):网络层拦截
MSW (Mock Service Worker) 代表了当前最先进的 Mocking 思想。
核心理念: 利用浏览器标准的 Service Worker API,在 网络层 (Network Level) 对请求进行拦截。这意味着,我们的应用代码(无论是 fetch 还是 axios)在发起请求时,是完全无感知的,它认为自己正在与一个真实的服务器通信。
1 | // MSW 的 Handler 定义 (概念演示) |
MSW 成为社区首选的核心优势:
- 无侵入性: 应用代码无需任何修改,保持了生产环境的纯净性。
- 环境通用性: 通过 Service Worker (浏览器) 和请求拦截器 (Node.js),实现了 一套 Mock 定义,处处可用。无论是 Next.js 开发、Storybook 可视化,还是 Vitest 单元测试,都可以共享同一套 Mock 逻辑。
- 高保真度: 在网络层面工作,对所有类型的请求(REST, GraphQL)和所有请求库都有效。
- 强大的逻辑能力: Handler 可以是纯函数,能轻松模拟任何复杂的业务逻辑、延迟和错误状态。
对比总结
| 特性维度 | Mock.js (过时) | json-server (独立服务) | MSW (现代标准) |
|---|---|---|---|
| 工作原理 | 覆写 XHR 对象 | 独立的 Node.js 服务器 | 网络层拦截 (Service Worker) |
| 侵入性 | 高 | 低 (但需修改请求 URL) | 无 |
| 环境通用性 | 差 (仅浏览器, 不支持 fetch) | 差 (需要独立进程) | 极佳 (浏览器 & Node.js 通用) |
| 逻辑/错误模拟 | 有限 | 困难 | 非常强大 |
结论: 凭借其无侵入、环境通用和功能强大的特性,MSW 能够完美地解决我们在 7.1 节中提出的所有痛点,是我们在 2025 年构建专业前端应用时进行 API Mocking 的不二之选。
7.3. MSW 实战:为 AutoComplete 搭建 Mock API
理论学习结束,我们马上进入 MSW 的实战配置。
7.3.1. MSW 安装与初始化
首先,我们将 msw 添加为项目的开发依赖。
1 | pnpm add -D msw |
接下来,是 MSW 最具特色的一步:初始化 Service Worker 脚本。我们需要运行一个 CLI 命令,它会在我们指定的、存放静态资源的目录(在 Next.js 中是 public 目录)中,创建一个 Service Worker 文件。浏览器将会注册并运行这个文件,从而赋予 MSW 拦截网络请求的能力。
1 | pnpm msw init public/ |
验证: 执行成功后,您会发现 public 目录下多出了一个 mockServiceWorker.js 文件。请 不要 手动修改这个文件。
7.3.2. 编写 AutoComplete 的 Mock Handlers
现在,我们来创建 Mock API 的核心——请求处理器 (Request Handlers)。一个良好的实践是,将所有 Handlers 存放在一个专门的目录中。
第一步:创建 Handlers 文件
1 | # 在项目根目录下执行 |
第二步:编写处理器逻辑
我们将为 AutoComplete 组件虚构一个 /api/search 接口,并为其编写一个能够响应 GET 请求的处理器。
文件路径: src/mocks/handlers.ts
1 | import { http, HttpResponse, delay } from 'msw'; |
代码深度解析:
http.get(...): 我们使用msw提供的http对象,来定义一个针对GET请求的处理器。第一个参数是需要拦截的 URL 路径。async ({ request }) => { ... }: 处理器函数接收一个包含request信息的上下文对象。await delay(500): 我们使用delay工具函数,来强制每次请求都至少延迟 500 毫秒,这便于我们在 UI 中观察“加载中”的状态。- 错误模拟: 我们加入了一个逻辑,当搜索查询为
'error'时,返回一个500的 HTTP 响应。这为我们后续测试组件的错误状态提供了极大的便利。 - 数据过滤: 我们模拟了真实的后端行为,根据查询参数
q来过滤数据。 HttpResponse.json(...): 返回一个Content-Type为application/json的成功响应。
7.3.3. 在开发环境中启动 MSW
最后,我们需要让我们的 Next.js 应用在开发模式下加载并启动 MSW。这需要我们创建一个 Mocking 的“启动文件”。
第一步:创建启动文件
1 | # 在 mocks 目录下创建浏览器环境的启动文件 |
第二步:配置启动文件
文件路径: src/mocks/browser.ts
1 | import { setupWorker } from 'msw/browser'; |
文件路径: src/app/msw-provider.tsx
1 | 'use client'; |
第三步:在根布局中应用 MSWProvider
文件路径: src/app/layout.tsx
1 | // ... imports ... |
最终验证:
现在,重新运行 pnpm run dev 并打开浏览器控制台。您应该会看到一条来自 MSW 的日志,提示 [MSW] Mocking enabled.。
这标志着我们的 API Mocking 基础设施已全部搭建完毕。我们的 Next.js 应用现在拥有了一个“虚拟后端”,它能可靠地响应 /api/search 请求,并且其行为完全由我们前端开发者掌控。我们终于为构建 AutoComplete 组件的异步逻辑,扫清了所有外部依赖的障碍。
7.4. 终极实战:构建与集成 useAutoComplete Hook
我们已经拥有了一个由 MSW 驱动的、行为可预测的“虚拟后端”。现在,是时候构建 AutoComplete 组件的“逻辑大脑”了。
遵循我们在第六章中确立的架构思想,我们将把所有复杂的业务逻辑,全部封装到一个独立的、与 UI 无关的 useAutoComplete 自定义 Hook 中。这将是对我们高级 Hooks 知识的一次终极检验和综合应用。
7.4.1. 构建 useAutoComplete Hook
第一步:创建 Hook 文件与类型定义
首先,创建我们的 Hook 文件。
1 | touch src/hooks/use-auto-complete.ts |
接下来,我们打开这个文件,并首先定义好这个 Hook 将要管理的所有状态的“形状”。这是一个 状态机 设计的核心步骤,我们使用 TypeScript 的类型系统来精确地描述我们的数据结构。
文件路径: src/hooks/use-auto-complete.ts
1 | // 1. 定义异步请求的几种可能状态 |
解析: 我们通过类型,严格地定义了一个异步请求的生命周期。State 接口确保了我们不会有无效状态(例如,data 和 error 不能同时存在值),Action 则枚举了所有可能触发状态变更的事件。
第二步:实现管理异步状态的 Reducer
Reducer 是一个纯函数,它是我们状态机的“规则手册”。它接收当前的状态和一个 action,并根据规则返回一个全新的状态。
文件路径: src/hooks/use-auto-complete.ts
1 | // ... 此前的类型定义 ... |
解析: 这个 Reducer 函数清晰地定义了状态转换的逻辑。例如,当 FETCH_START action 被派发时,状态会立即切换到 loading,并清除任何历史的 error 信息。这种集中式的管理,使得我们的状态变更变得完全可预测。
第三步:构建 useAutoComplete Hook 骨架并组合 Hooks
现在,我们来构建 Hook 的主体,并将我们在第六章中构建的 useDebounce 和刚刚定义的 useReducer 组合起来。
文件路径: src/hooks/use-auto-complete.ts
1 | import { useState, useEffect, useReducer } from 'react'; |
解析: 我们将不同的职责委托给了最适合的 Hook:useState 负责高频更新的 UI 状态,useDebounce 负责性能优化,useReducer 负责复杂但更新频率较低的异步状态。这就是 Hooks 组合 的威力。
第四步:实现核心异步逻辑 (useEffect)
最后一步,是编写 useEffect 来监听 防抖后 的输入值变化,并据此触发 API 请求和状态派发。
文件路径: src/hooks/use-auto-complete.ts (最终版本)
1 | // ... 此前的 imports, 类型定义, reducer ... |
代码深度解析:
useEffect的依赖: 这是整个模式的核心。useEffect只依赖debouncedInputValue。这意味着只有当用户停止输入 500ms 后,这个副作用才会运行,从而实现了请求的防抖。isCancelled标志: 这是一个处理异步副作用的 最佳实践。设想用户在请求还未返回时就离开了页面,组件被卸载。如果没有isCancelled保护,当请求最终返回时,dispatch会尝试去更新一个已经不存在的组件的状态,这会导致 React 报错(内存泄漏警告)。通过在清理函数中设置isCancelled = true,我们确保了只有在组件仍然挂载时,才会派发状态更新。
至此,我们已经成功地构建了一个功能完备、逻辑内聚、性能优化的 useAutoComplete Hook。它是一个完全独立的“逻辑引擎”,现在,我们只需要为它打造一个“UI 外壳”即可。
7.4.2. 构建 AutoComplete UI 组件
本节,我们将回归到我们熟悉的 UI 组件构建工作。我们的任务非常纯粹:创建一个“哑” 的 AutoComplete UI 组件。
这个组件自身不包含任何复杂的业务逻辑。它的唯一职责,就是接收来自 useAutoComplete Hook 的状态(如 isLoading, suggestions),并将其渲染为用户可见的界面。我们将在这个过程中,综合运用 shadcn 工作流、组件组合以及 daisyUI 样式。
第一步:shadcn add 实战,获取 Popover 原语
AutoComplete 的下拉建议列表,是一个需要“浮动”在所有内容之上、且需要处理复杂定位和焦点管理的浮层。手动实现它非常困难,因此,我们将再次借助 shadcn 和 Radix UI 的力量,获取一个专业的“无头”Popover 组件作为其基础。
在项目根目录下执行:
1 | pnpm dlx shadcn@latest add popover |
解析: 这个命令会自动为我们安装 @radix-ui/react-popover 依赖,并在 src/components/ui 目录下创建一个经过样式化封装的 Popover.tsx 文件。它为我们处理了所有关于浮层定位、可访问性(a11y)和外部点击关闭的逻辑。
第二步:创建 AutoComplete UI 组件文件
1 | touch src/components/ui/AutoComplete.tsx |
第三步:搭建静态 UI 骨架
我们首先在 AutoComplete.tsx 文件中,通过 组件组合,搭建出它的静态 UI 结构。
文件路径: src/components/ui/AutoComplete.tsx
1 | 'use client'; |
代码深度解析
AutoCompleteProps: 我们定义了一个丰富的props接口,它继承了Input的所有属性,并增加了suggestions(建议列表),isLoading(加载状态)等我们useAutoCompleteHook 将会提供的新状态。- 组件组合: 这个组件完美地体现了组件组合的思想。它像一个“总装厂”,将
Popover(来自shadcn/Radix)、Input(我们自己的增强版)和Icon(我们自己的统一版) 组合在了一起。 - Popover:
PopoverAnchor: 我们使用它包裹住Input的容器,它会成为PopoverContent定位的“锚点”。PopoverContent: 我们为其添加了w-[--radix-popover-trigger-width]这个 CSS 变量类,这是一个shadcn Popover提供的技巧,能让浮动面板的宽度与触发器(即我们的Input)的宽度完全一致。onOpenAutoFocus={(e) => e.preventDefault()}: 这是一个关键的交互细节。默认情况下,Popover打开时会尝试将焦点移入面板内部。但在AutoComplete场景中,我们希望用户的焦点 始终保持在输入框中,以便继续输入。这行代码阻止了默认的焦点转移行为。
daisyUI样式: 我们再次使用了daisyUI的menu类来快速、一致地样式化我们的建议列表。
结论:
我们已经成功地构建了一个结构清晰、样式统一的 AutoComplete UI 组件。它是一个纯粹的、由 props 驱动的“哑”组件,已经为下一步注入“逻辑大脑”做好了充分的准备。
7.4.3. 最终组装:将“逻辑”与“视图”合二为一
我们已经拥有了两个独立的、各自都很强大的部分:
- 一个负责所有复杂逻辑的
useAutoComplete“逻辑引擎”。 - 一个负责所有视觉呈现的
AutoComplete“UI 外壳”。
现在,是时候将它们进行最终的组装,见证“关注点分离”架构模式所带来的真正魅力了。我们将把“逻辑大脑”植入“UI 躯体”中,创造出一个完整、智能的组件。
第一步:精简 Props 接口
一个关键的架构优势是:在引入 useAutoComplete Hook 后,我们的 UI 组件本身不再需要从外部接收 isLoading, suggestions 等状态。这些状态将由 Hook 在内部进行管理和提供。因此,我们可以先简化 AutoComplete 组件的 Props 接口。
文件路径: src/components/ui/AutoComplete.tsx
1 | // ... imports ... |
第二步:注入 Hook 并连接状态与视图
现在,我们在 AutoComplete 组件内部调用 useAutoComplete Hook,然后将 Hook 返回的状态和方法,与我们已经写好的 JSX 进行“连接”。
文件路径: src/components/ui/AutoComplete.tsx (最终版本)
1 | 'use client'; |
代码深度解析:
- 调用 Hook:
const { ... } = useAutoComplete<string>();这一行代码,就是我们植入“逻辑大脑”的瞬间。所有关于防抖、请求、状态机的复杂逻辑,都被包含在了这个简单的函数调用中。 - 连接
Input: 我们将Input组件变成了一个完全由useAutoCompleteHook 控制的 受控组件。value来自inputValue状态,onChange事件则调用setInputValue方法。 - 连接状态到 UI: 我们使用从 Hook 中获取的
isLoading状态,来动态地改变Input的suffix图标和className,实现了加载状态的可视化反馈。 - 连接数据到 UI: 我们使用
suggestions数组来动态地渲染下拉列表中的<li>元素。 - 连接交互到方法: 当用户点击某个建议项时,我们调用 Hook 返回的
setInputValue方法来更新输入框的值。这个更新会再次触发useDebounce和useEffect,形成一个完整的数据流闭环(通常,选择后debouncedValue变为空,suggestions数组清空,Popover随之关闭)。
架构优势:“胖 Hooks,瘦组件”
请再次审视 AutoComplete.tsx 这个文件。您会发现,在完成了最终组装后,这个 UI 组件本身变得非常“轻薄”和“纯粹”。它不包含任何 useEffect, useReducer, setTimeout 等复杂逻辑,其唯一的职责就是根据从 Hook 中获取的 props,忠实地渲染出对应的 UI。
这就是**“胖 Hooks,瘦组件 (Fat Hooks, Thin Components)”**的现代 React 架构思想。这种模式带来了巨大的好处:
- 高度可读性: UI 组件的渲染逻辑一目了然。
- 逻辑可复用性:
useAutoCompleteHook 可以被用于任何其他需要自动完成功能的组件,无论它长什么样。 - 独立可测试性: 我们可以独立地为
useAutoComplete编写单元测试,而无需渲染任何 UI。
最终验证
现在,回到我们在 7.3.3 中创建的、用于启动 MSW 的 Next.js 应用。为了方便测试,我们可以简单地将新组件添加到首页。
文件路径: src/app/page.tsx
1 | import { AutoComplete } from '@/components/ui/AutoComplete'; |
运行 pnpm run dev,访问首页。现在,尝试在输入框中输入 “app”。您会看到:
- 输入框末尾的搜索图标变成了加载图标,并伴有脉冲动画。
- 等待 500 毫秒后,加载动画消失,下方弹出一个包含 “Apple” 和 “Pineapple” 的建议列表。
- 尝试输入 “error”,您会看到组件下方提示错误,并在控制台中看到
MSW模拟的 500 错误。
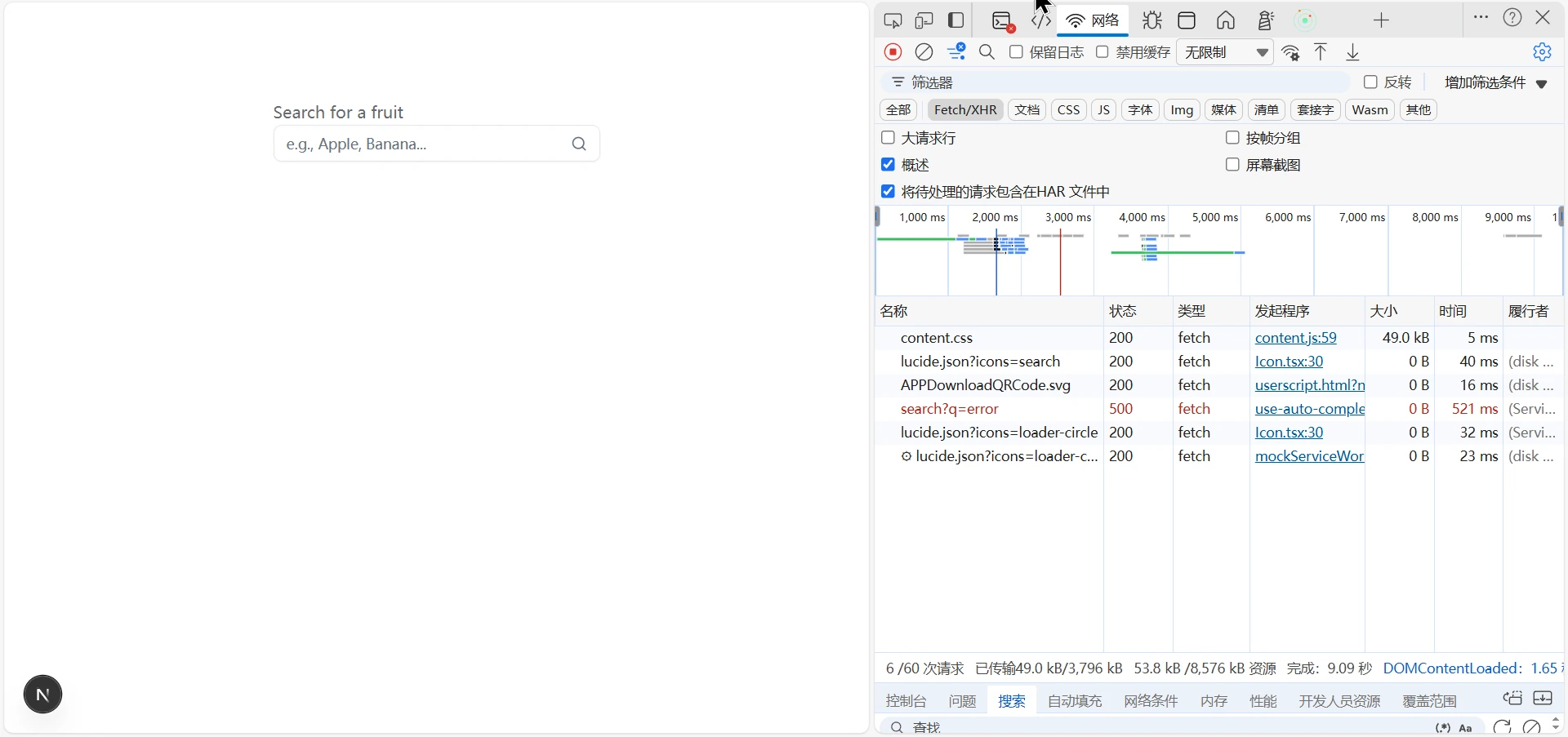
我们的 AutoComplete 组件已经功能完备,并且正在与我们搭建的 Mock API 完美地协同工作。现在,只剩下“黄金工作流”的最后一步:将它带入 Storybook。
7.5. 流程闭环:在 Storybook 中消费 Mock API
如果我们现在直接为 AutoComplete 编写 Story,它在 Storybook 中发出的 API 请求将会失败(404 Not Found),因为 Storybook 环境中并没有一个真实的后端,也没有任何 Mock 拦截。我们为 Next.js 应用配置的 MSW,其 Service Worker 监听的是主应用的 fetch 请求。而 Storybook 是一个完全独立的开发服务器,运行在不同的端口上,它自己的 iframe 预览环境无法自动利用我们之前的 MSW 配置。我们需要一个专门的“连接器”,让 Storybook 也能加载并使用我们已经编写好的 MSW 请求处理器 (Handlers)。这个连接器就是 msw-storybook-addon。
在这一节中,我们将安装并配置这个插件,将我们在 src/mocks/handlers.ts 中定义的“虚拟后端”,无缝地集成到 Storybook 的开发环境中。
7.5.1. 配置 msw-storybook-addon
解决方案:
为了让 Storybook 能够识别并使用我们在 src/mocks/handlers.ts 中定义的请求处理器,我们需要一个专门的“连接器”插件——msw-storybook-addon。它负责在 Storybook 的环境中,启动 MSW 的 Service Worker 并加载我们的 Mock 规则。
第一步:安装插件
我们将 msw-storybook-addon 添加为项目的开发依赖。
1 | pnpm add -D msw-storybook-addon |
第二步:在 Storybook 中注册插件
与任何其他插件一样,我们需要在 Storybook 的主配置文件中“注册”它,以便 Storybook 在启动时加载它。
文件路径: .storybook/main.ts
1 | import type { StorybookConfig } from "@storybook/nextjs-vite"; |
解析:
- 我们在
addons数组中添加了msw-storybook-addon。 - 同时,我们 必须 确保
staticDirs配置中包含了public目录。这是因为msw init命令生成的mockServiceWorker.js文件位于public目录下,Storybook 需要能够访问并提供这个文件给浏览器。
第三步:在 preview.ts 中加载全局 Handlers
最后,也是最关键的一步,我们需要在 .storybook/preview.ts 文件中进行配置,告诉 msw-storybook-addon 如何初始化,以及在哪里找到我们定义的 Mock API 规则。
文件路径: .storybook/preview.ts
1 | import type { Preview } from "@storybook/react"; |
代码深度解析:
import { initialize, mswLoader }: 我们从插件中导入两个核心工具。initialize(): 这个函数必须在文件的顶层调用一次。它负责在浏览器中查找并注册位于public目录下的 Service Worker 脚本 (mockServiceWorker.js)。import { handlers }: 我们导入了在7.3.2小节中创建的、包含/api/search接口 Mock 逻辑的handlers数组。这完美地体现了 MSW “一次定义,处处使用”的理念。parameters.msw.handlers: 我们在全局parameters中配置msw,将导入的handlers作为所有故事的 默认 Mock 规则。这意味着,除非在单个 Story 中特别覆盖,否则所有 Storybook 中的fetch请求都会被这套规则所拦截。loaders: [mswLoader]: 这是至关重要的一步。loaders是 Storybook 7+ 的一个特性,它允许在 Story 渲染 之前 执行一些异步操作。mswLoader会确保 Service Worker 已经成功激活,然后再开始渲染组件。这可以有效防止组件在 MSW 就绪前提早发起请求而导致真实网络穿透或失败的问题。
第四步:最终验证
所有配置都已完成。现在,让我们重新启动 Storybook。
1 | pnpm storybook |
启动成功后,打开浏览器的开发者工具,并切换到 控制台 (Console) 标签页。您应该能看到一条与在 Next.js 应用中看到的完全相同的日志:
[MSW] Mocking enabled.
这条日志的出现,标志着我们的 API Mocking 基础设施已经成功地、无缝地集成到了 Storybook 的开发环境中。我们的“可视化工作台”现在拥有了一个功能齐全、行为可控的“虚拟后端”。
我们终于为 AutoComplete 组件这个复杂异步组件,铺平了最后一块道路,可以在 Storybook 中为它的各种异步状态编写可视化、可交互、可测试的 Stories 了。
7.5.2. 编写异步组件的 Stories
现在,我们的 Storybook 环境已经具备了 Mock API 的能力。我们将利用这一能力,为 AutoComplete 组件编写一套完整的、能够覆盖其所有异步状态的可视化文档。
第一步:创建 Story 文件
1 | touch src/components/ui/AutoComplete.stories.tsx |
第二步:编写 Meta 对象和基础 Story
我们首先创建 meta 对象,并编写一个最基础的、用于展示成功状态的 Default Story。这个 Story 会直接使用我们在 preview.ts 中配置的全局 MSW Handlers。
文件路径: src/components/ui/AutoComplete.stories.tsx
1 | import type { Meta, StoryObj } from '@storybook/nextjs-vite'; |
第三步:为“加载中”状态编写 Story
这是 msw-storybook-addon 威力初显的时刻。为了稳定地展示 AutoComplete 在请求过程中的“加载中”状态,我们只需要为这个特定的 Story 覆盖 默认的 MSW Handler,让它返回一个永不结束的 Promise。
文件路径: src/components/ui/AutoComplete.stories.tsx
1 | // ... 此前的 meta 和 Default Story ... |
代码深度解析:
parameters.msw.handlers:msw-storybook-addon允许我们通过这个参数,为 单个 Story 提供特定的 handlers。这些 handlers 会覆盖我们在preview.ts中设置的全局 handlers。await delay('infinite'):msw提供的这个工具函数,会创建一个永远不会 resolve 的Promise,完美地模拟了一个长时间运行的网络请求。
第四步:为“请求失败”和“无结果”状态编写 Story
同理,我们可以轻松地创建用于展示其他边界情况的 Stories。
文件路径: src/components/ui/AutoComplete.stories.tsx
1 | // ... 此前的 meta 和 Stories ... |
现在,如果您运行 pnpm storybook,您将在 UI/AutoComplete 下看到四个独立的 Story,每一个都精确、稳定地展示了组件在一种特定异步状态下的 UI 表现。
7.6 本章小结
在本章中,我们围绕着“异步”这一主题,进行了一次从工程化基建到高级 Hooks 应用的深度实践。
- API Mocking 战略: 我们首先深入探讨了前端开发中 API Mocking 的必要性,横向对比了多种方案,并最终确立了
MSW作为我们项目的最佳实践。我们学会了它的核心原理(网络层拦截)和基础配置。 - 高级 Hooks 组合: 我们构建了一个复杂的
useAutoCompleteHook,它完美地 组合 了我们在第六章学习的useDebounce(性能优化)和useReducer(状态机管理),是“胖 Hooks,瘦组件”架构思想的终极体现。 - 复杂组件构建: 我们通过 组合
Input和Popover原语,并为其注入daisyUI样式,成功地构建了一个功能与外观兼备的AutoCompleteUI 组件。 - 异步 Storytelling: 我们掌握了使用
msw-storybook-addon为异步组件编写独立、确定的 Stories 的高级技巧,能够轻松地文档化loading,error等边界状态。
通过本章,您不仅收获了一个生产级的 AutoComplete 组件,更重要的是,掌握了一整套应对任何复杂异步组件的 通用解决方案。











