
Prorise
这是我的博客,分享技术与生活的点点滴滴
【jmeter教程——从入门到全精通】 体系化教程
【jmeter教程——从入门到全精通】 体系化教程
Prorise第一章. 性能测试通识与环境搭建
摘要:本章作为全系列的基石,我们将首先厘清性能测试的核心指标(TPS、RT),接着快速搭建一个基于 Spring Boot 的待测应用,最后完成 JMeter 的安装与基础环境配置,为后续的压测实战做好准备。
本章学习路径
我们将按照以下步骤构建性能测试的实验环境:
- 1.1 核心概念扫盲
- 1.1.1 性能测试的本质与目的
- 1.1.2 关键指标详解:$TPS$ 与 $RT$
- 1.2 搭建待测靶场(Spring Boot)
- 1.2.1 使用 IDEA 快速初始化项目
- 1.2.2 编写模拟业务延迟的测试接口
- 1.2.3 验证服务可用性
- 1.3 JMeter 环境部署
- 1.3.1 JDK 环境检查(前置条件)
- 1.3.2 JMeter 下载与目录结构解析
- 1.3.3 关键配置修改(中文支持/编码格式)
1.1. 核心概念扫盲:什么是 “抗揍” 的代码
在正式动手之前,我们必须先统一语言。很多开发者认为 “程序没报错” 就是开发完成了,但在高并发场景下,功能正常的代码可能会因为资源耗尽而导致服务雪崩。
1.1.1. 性能测试的定义
性能测试(Performance Testing)是通过自动化的工具模拟多种正常、峰值以及异常负载条件来对系统的各项性能指标进行测试。
对于 Spring Boot 开发者而言,它的核心价值在于:
- 识别瓶颈:找到系统的短板(是 CPU 算不过来,还是数据库连接不够用)。
- 规划容量:明确系统最大能支撑多少用户同时访问。
- 验证稳定性:确保系统在长时间高负载下不会内存溢出(OOM)。
1.1.2. 黄金指标:$TPS$ 与 $RT$
在后续的 JMeter 报告中,我们最关注两个指标,它们存在着一种制衡关系:
- 响应时间 ($RT$ - Response Time)
- 定义:从客户端发起请求到接收到完整响应所消耗的时间。
* 体感:用户觉得 “卡不卡”。
* 标准:通常互联网应用要求核心接口 $RT < 200ms$。
- 每秒事务数 ($TPS$ - Transactions Per Second)
- 定义:系统每秒钟能够处理的业务请求数量。
* 体感:系统能 “抗多少人”。
* 关系:在理想情况下,$TPS \approx \frac{并发数}{RT}$。
注意:$TPS$ 和 $RT$ 往往是反比关系。当并发过高导致系统拥堵时,$RT$ 会急剧上升,从而导致 $TPS$ 下降。寻找这两者的 “平衡点” 就是性能调优的目标。
1.2. 搭建待测靶场:Spring Boot 测试项目
在上一节中,我们明确了性能测试的目标。为了让后续的 JMeter 学习有真实的 “攻击目标”,我们需要先构建一个标准的 Spring Boot 应用。为了模拟真实的业务场景,我们不能只写一个简单的 Hello World,而需要模拟出一定的 “耗时”。
1.2.1. 项目初始化
我们将使用 IntelliJ IDEA 快速构建项目。
操作步骤:
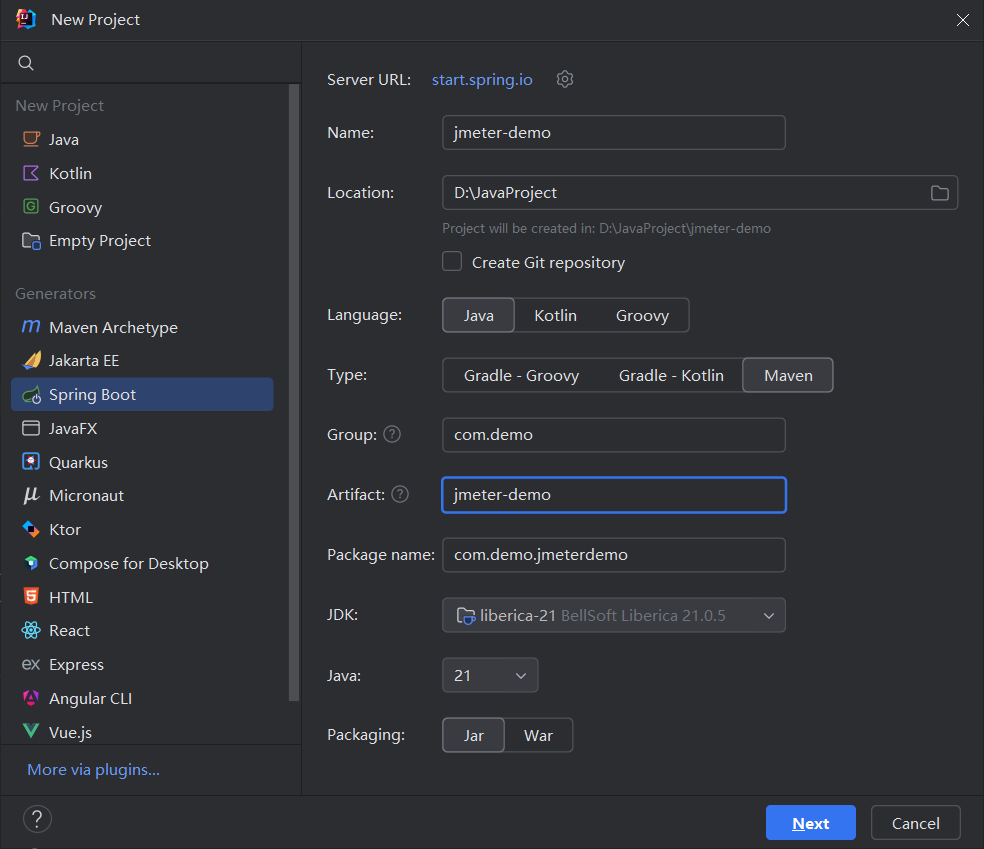
- 打开 IDEA,点击 New Project。
- 选择 Spring Initializr。
- Name:
jmeter-demo。 - JDK: 推荐选择 21(2025 年主流 LTS 版本),我们在后续会测试虚拟线程
- Java: 选择对应版本。
- Packaging: Jar。
- 点击 Next,在依赖选择中勾选:
- Web ->
Spring Web(提供 REST 接口支持)。 - Lombok (简化代码,可选)。
- Web ->
1.2.2. 编写模拟业务接口
我们需要编写一个 Controller,并模拟一定的业务处理时间(例如查询数据库耗时)。
文件路径:
1 | src/main/java/com/demo/jmeterdemo/ |
代码实现:
我们首先定义一个简单的 REST 接口,使用 Thread.sleep 来模拟业务逻辑的耗时。
1 | package com.demo.jmeterdemo.controller; |
代码解析:
ThreadLocalRandom:在高并发环境下,它的性能优于Random类,用于生成随机数。Thread.sleep:我们强制让线程休眠 50-100 毫秒。这是为了模拟真实项目中数据库查询或远程调用所需的 IO 等待时间。如果接口响应太快(0ms),JMeter 可能瞬间把 CPU 打满,无法观察到真实的并发排队现象。
1.2.3. 启动与验证
- 运行
JmeterDemoApplication.java中的main方法。 - 打开浏览器访问:
http://localhost:8080/api/test/hello。 - 如果看到类似
{"code":200,"data":"Processing time: 76ms" ...}的 JSON 返回,说明靶场搭建成功。
1.3. JMeter 环境部署
靶场已经就位,现在我们需要部署压测工具 JMeter。JMeter 是基于 Java 开发的,因此必须依赖 JDK 环境。
1.3.1. 前置检查:JDK
打开终端(Command Prompt 或 Terminal),输入以下命令:
1 | java -version |
- 成功:输出
java version "17.0.x"或更高版本。 - 失败:如果提示
'java' is not recognized(‘java’ 不是内部或外部命令),请先安装 JDK 并配置JAVA_HOME环境变量。这是 Java 开发的基本功,不再赘述。
1.3.2. 下载与安装
Apache JMeter 是免安装的绿色软件。
- 下载:访问 Apache JMeter 官网。
- 选择版本:找到 Binaries(二进制版)区域。
- Windows 用户下载
.zip文件。 - Mac/Linux 用户下载
.tgz文件。 - 注意:不要下载 Source(源码版),那是给开发者看源码用的。
- Windows 用户下载
- 解压:将压缩包解压到一个 没有中文、没有空格 的路径下(例如
D:\tools\apache-jmeter-5.6.3或/usr/local/jmeter)。
目录结构说明:
bin/:存放启动脚本(jmeter.bat,jmeter.sh)和配置文件(jmeter.properties)。lib/:存放 JMeter 的核心 Jar 包和第三方插件。docs/:官方文档。
1.3.3. 基础配置优化
默认的 JMeter 配置是英文界面且编码可能存在问题,我们需要在启动前做一次 “手术”。
文件路径:[JMeter安装目录]/bin/jmeter.properties
使用文本编辑器(如 Notepad++ 或 VS Code)打开该文件,完成以下修改:
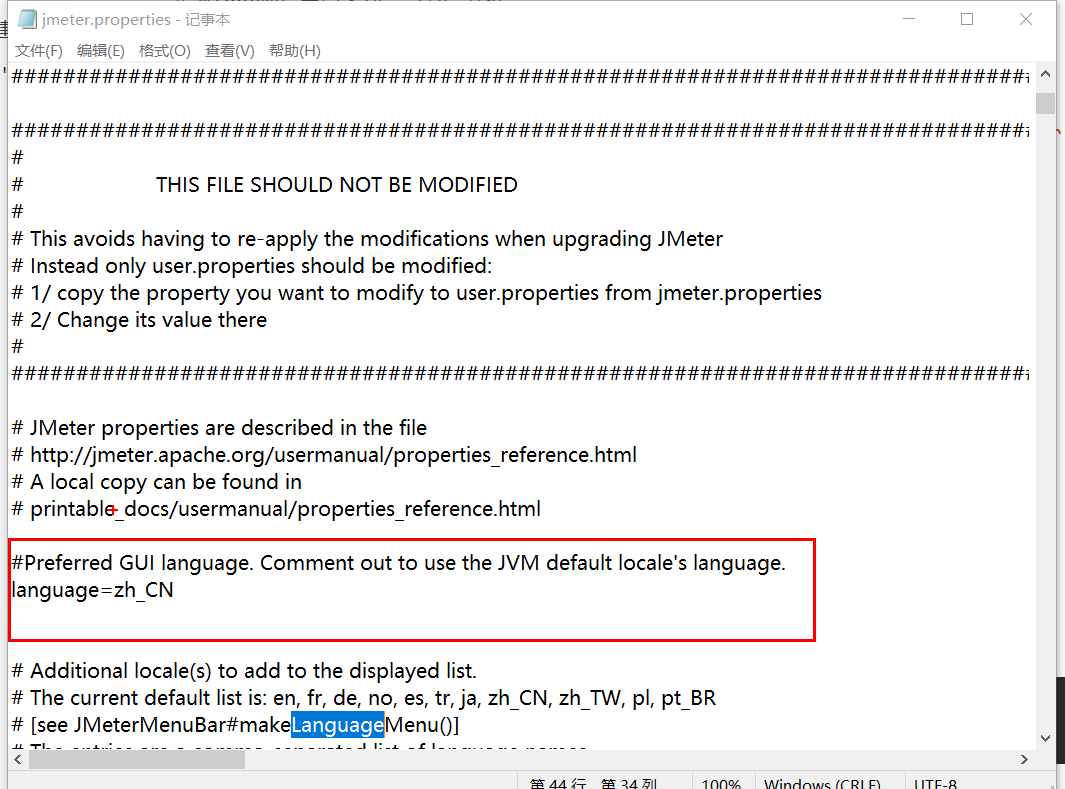
1. 界面语言设置为中文
JMeter 原生支持中文,修改配置可永久生效。
1 | # 搜索 language,去掉前面的 # 号 |
2. 强制使用 UTF-8 编码
这是为了防止压测过程中响应数据出现中文乱码。
1 | # 搜索 sampleresult.default.encoding |
3. 启动验证
- Windows:双击
bin/jmeter.bat。 - Mac/Linux:在终端执行
sh bin/jmeter.sh。
常见错误:启动时如果出现终端一闪而过,通常是因为 JAVA_HOME 环境变量未配置正确。
如果成功看到了 JMeter 的图形化界面(GUI),并且菜单栏是中文的,恭喜你,所有的准备工作已经就绪。
1.4. 本章小结
在本章中,我们完成了从理论认知到环境搭建的全过程。现在,你的电脑上同时运行着一个 “脆弱” 的 Spring Boot 应用和一个 “强大” 的压测工具。
核心要点:
- TPS 与 RT:$TPS$ 是吞吐量,$RT$ 是延迟,两者通常呈反比。
- 测试靶场:压测必须基于具有真实业务耗时(Sleep)的接口,0ms 的接口没有测试价值。
- 环境隔离:JMeter 安装路径严禁包含中文或空格,否则会导致未知的 Java 类加载错误。
下一步计划:我们的 “枪”(JMeter)和 “靶子”(Spring Boot)都准备好了。在下一章,我们将编写第一个 JMeter 测试脚本,真正地扣动扳机,看看我们的 Spring Boot 应用在 100 个并发线程下表现如何。
第二章. 第一次亲密接触:压测你的 Spring Boot 接口
摘要:本章我们将正式启动 JMeter,编写第一个测试脚本。我们将深入理解 JMeter 的 “核心三剑客”(线程组、取样器、监听器),并对上一章编写的 Spring Boot 接口发起真实的并发调用,最后通过聚合报告学会看懂基本的性能数据。
本章学习路径
我们将通过以下步骤完成第一次压测实战:
- 2.1 JMeter 核心逻辑架构
- 2.1.1 核心三剑客:测试计划的骨架
- 2.1.2 线程组与并发用户的映射关系
- 2.2 编写第一个压测脚本
- 2.2.1 配置线程组(模拟用户)
- 2.2.2 配置 HTTP 请求(发起攻击)
- 2.2.3 添加结果树(查看明细)
- 2.3 运行与数据解读
- 2.3.1 成功与失败的标志
- 2.3.2 聚合报告核心指标解读
- 2.3.3 GUI 模式的性能陷阱
2.1. JMeter 核心逻辑架构
在上一章中,我们已经准备好了基于 com.demo.jmeterdemo 包结构的 Spring Boot 项目。现在打开 JMeter,面对空空如也的界面,我们需要先理解它的构建逻辑。
JMeter 的脚本编写其实就是在 “搭积木”,而最核心的三块积木被称为 “三剑客”。
2.1.1. 核心三剑客
| 组件名称 | 英文名称 | 对应现实场景 | 作用 |
|---|---|---|---|
| 线程组 | Thread Group | 用户 | 决定有多少人来访问,以及这些人进来的速度(并发数)。 |
| 取样器 | Sampler | 动作 | 决定用户做什么操作(打开网页、调用接口、查询数据库)。 |
| 监听器 | Listener | 报表 | 负责收集测试结果,展示为图表、表格或日志。 |
2.1.2. 线程组 = 虚拟用户
在 Java 开发中,我们知道 “线程(Thread)” 是 CPU 调度的基本单位。在 JMeter 中,一个线程就严格对应一个虚拟用户。
- 如果设置 10 个线程,就意味着有 10 个用户同时在这个时间点操作。
- 这与 Spring Boot 中的 Tomcat 线程池是对应的:客户端发起 10 个线程请求,服务端就需要分配资源来处理这 10 个请求。
2.2. 编写第一个压测脚本
理论清楚后,我们开始动手。请确保你的 Spring Boot 项目(JmeterDemoApplication)已启动,且端口为 8080。
2.2.1. 第一步:创建线程组(模拟用户)
操作步骤:
- 右键点击 “测试计划 (Test Plan)” -> 添加 (Add) -> 线程 (Threads) -> 线程组 (Thread Group)。
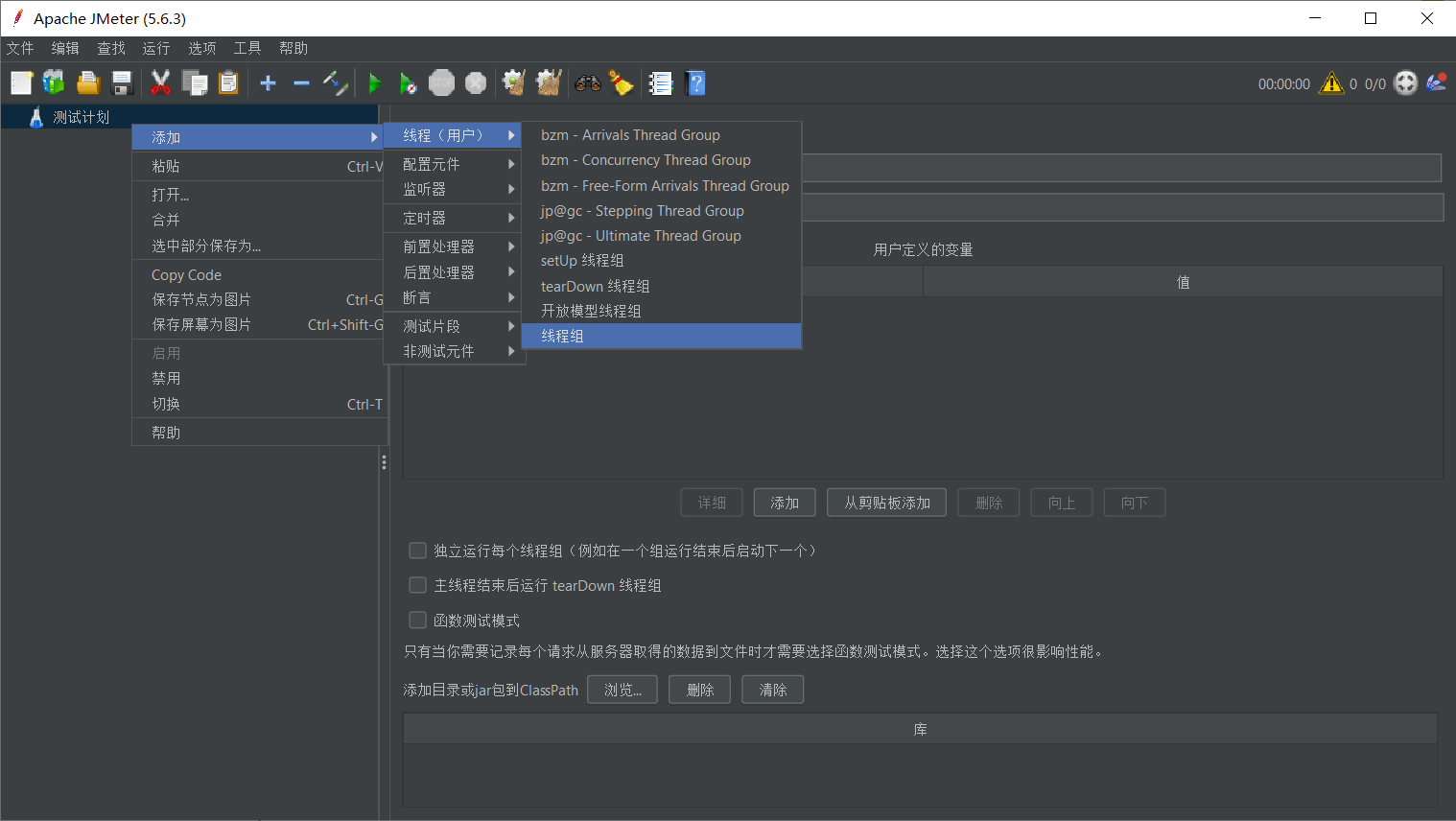
- 在右侧面板配置以下参数:
| 参数名 | 建议值 | 含义解释 |
|---|---|---|
| 名称 | 模拟前台用户 | 给脚本起个可读的名字,便于管理。 |
| 线程数 (Number of Threads) | 10 | 模拟 10 个用户并发访问。 |
| Ramp-Up 时间 (Ramp-Up Period) | 1 | 让这 10 个用户在 1 秒内陆续启动(即每 0.1 秒启动一个),避免瞬间压力过大导致系统误判。 |
| 循环次数 (Loop Count) | 10 | 每个用户执行 10 次操作。总请求数 = $10 \times 10 = 100$。 |
关于 Ramp-Up 的思考:如果设置线程数为 100,Ramp-Up 为 0,意味着 100 人在同一毫秒瞬间涌入(秒杀场景)。如果设置线程数为 100,Ramp-Up 为 10,意味着每秒进来 10 人(常规业务场景)。
2.2.2. 第二步:配置 HTTP 请求(定义动作)
我们要调用的接口地址是:GET http://localhost:8080/api/test/hello
操作步骤:
- 右键点击刚才创建的 “线程组” -> 添加 -> 取样器 (Sampler) -> HTTP 请求 (HTTP Request)。
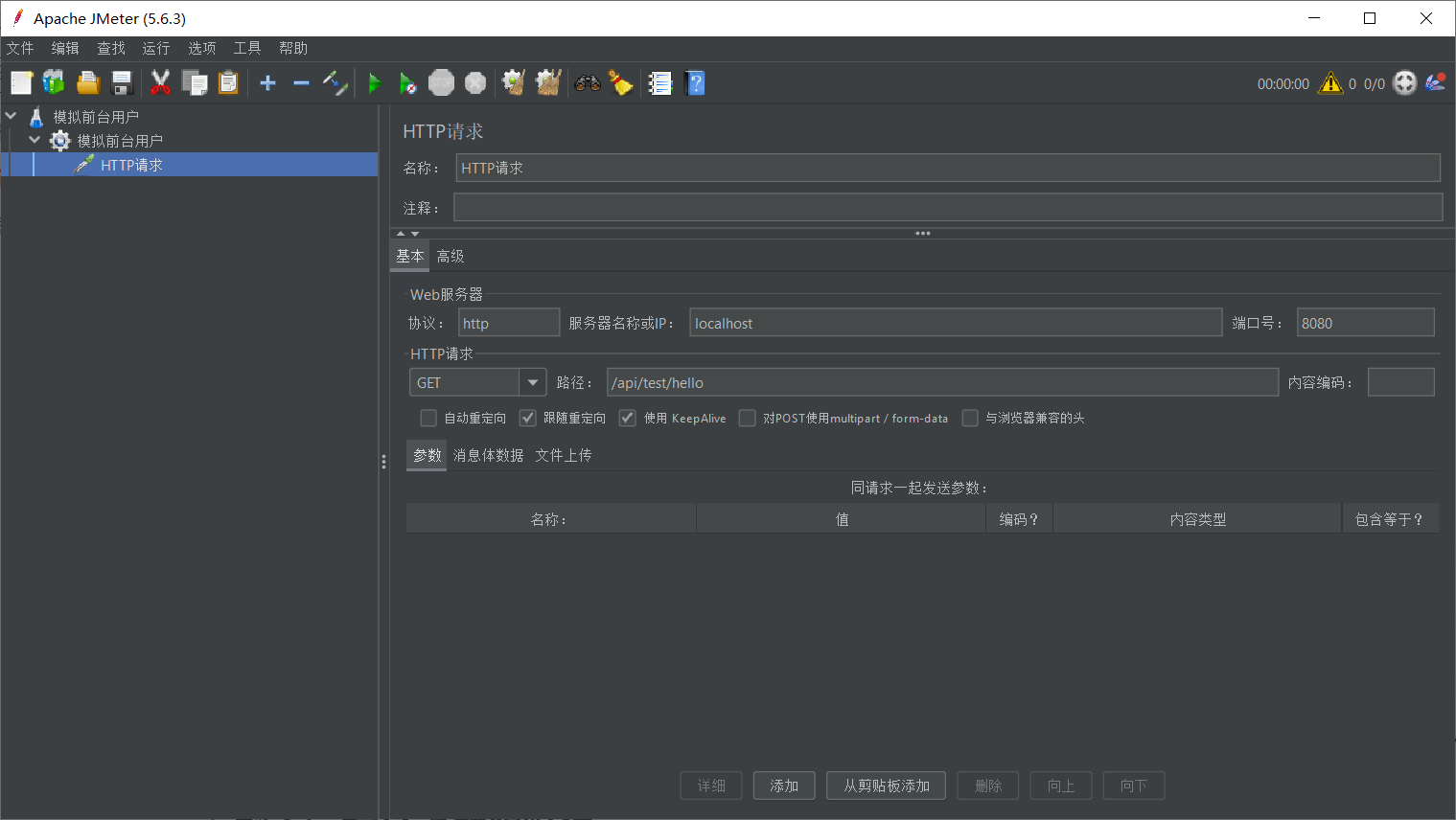
- 填写核心配置:
- 协议 (Protocol):
http - 服务器名称或 IP:
localhost - 端口号:
8080 - 方法 (Method):
GET - 路径 (Path):
/api/test/hello(注意不要包含 host 和 port,且以/开头)
- 协议 (Protocol):
2.2.3. 第三步:添加监听器(查看结果)
为了验证脚本是否配置正确,我们需要一个能够看到详细请求响应的组件。
操作步骤:
- 右键点击 “线程组” -> 添加 -> 监听器 (Listener) -> 察看结果树 (View Results Tree),这样就够了
2.3. 运行与数据解读
脚本编写完成,点击工具栏上的绿色 启动按钮 (Start)。记得先保存脚本,通常命名为 hello-test.jmx。
2.3.1. 察看结果树:调试神器
运行结束后,点击左侧的 “察看结果树”。你会在列表中看到 100 条记录(10 线程 x 10 循环)。
- 绿色盾牌:表示请求成功(HTTP 状态码 200)。
- 红色感叹号:表示请求失败。
点击任意一条成功的记录,切换到 响应数据 (Response Data) 选项卡:
1 | { |
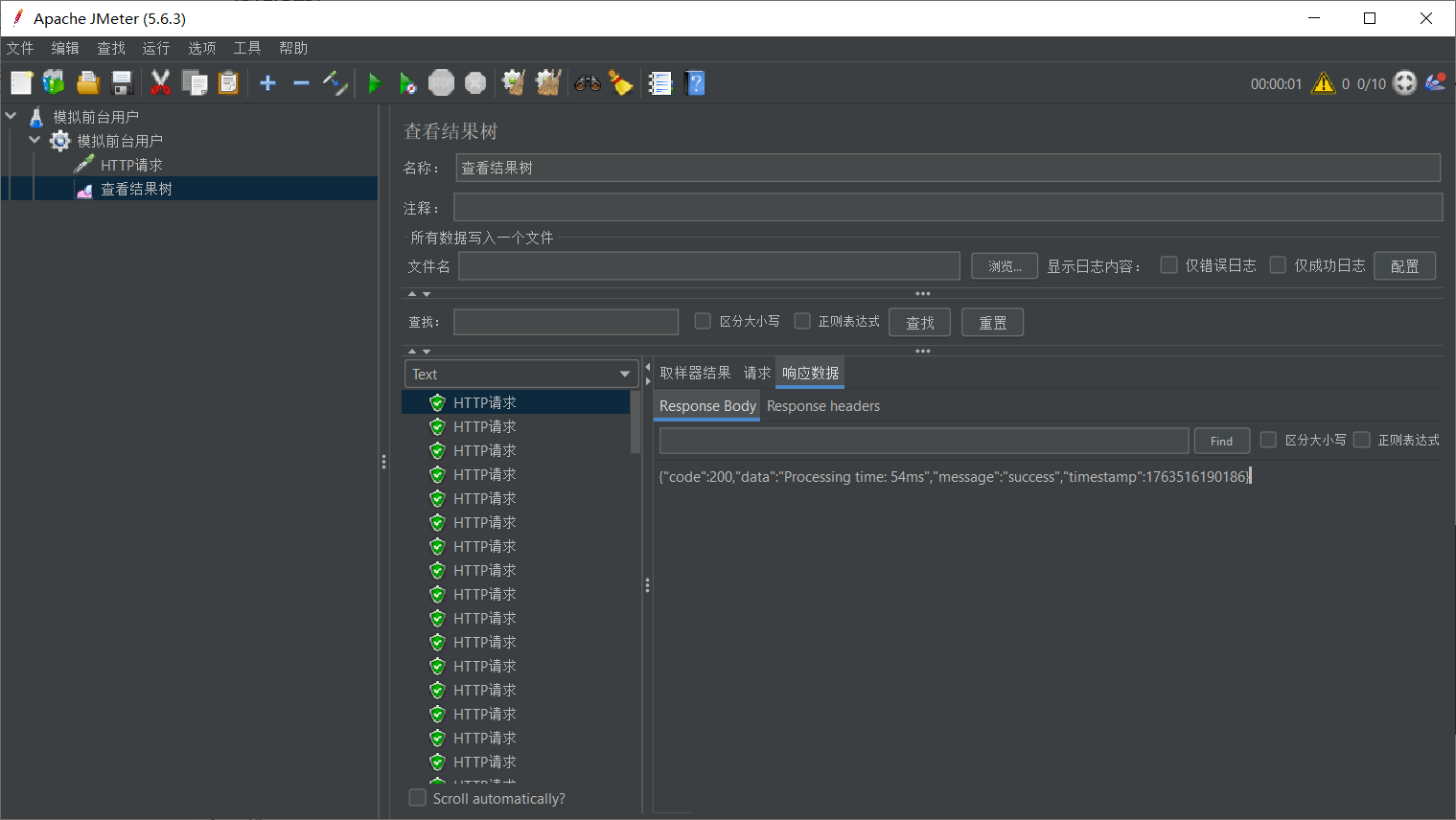
如果你看到了我们在 Spring Boot 代码中定义的 JSON 返回,说明 网络连通性 和 接口逻辑 都没有问题。
2.3.2. 聚合报告:宏观视角
“察看结果树” 只能看单次请求的细节,无法评估整体性能。我们需要添加 “聚合报告” 来查看 TPS 和 RT。
操作步骤:
- 右键点击 “线程组” -> 添加 -> 监听器 -> 聚合报告 (Aggregate Report)。
- 清除数据:点击工具栏的小扫把(清除全部),然后重新运行一次测试。
核心指标解读:
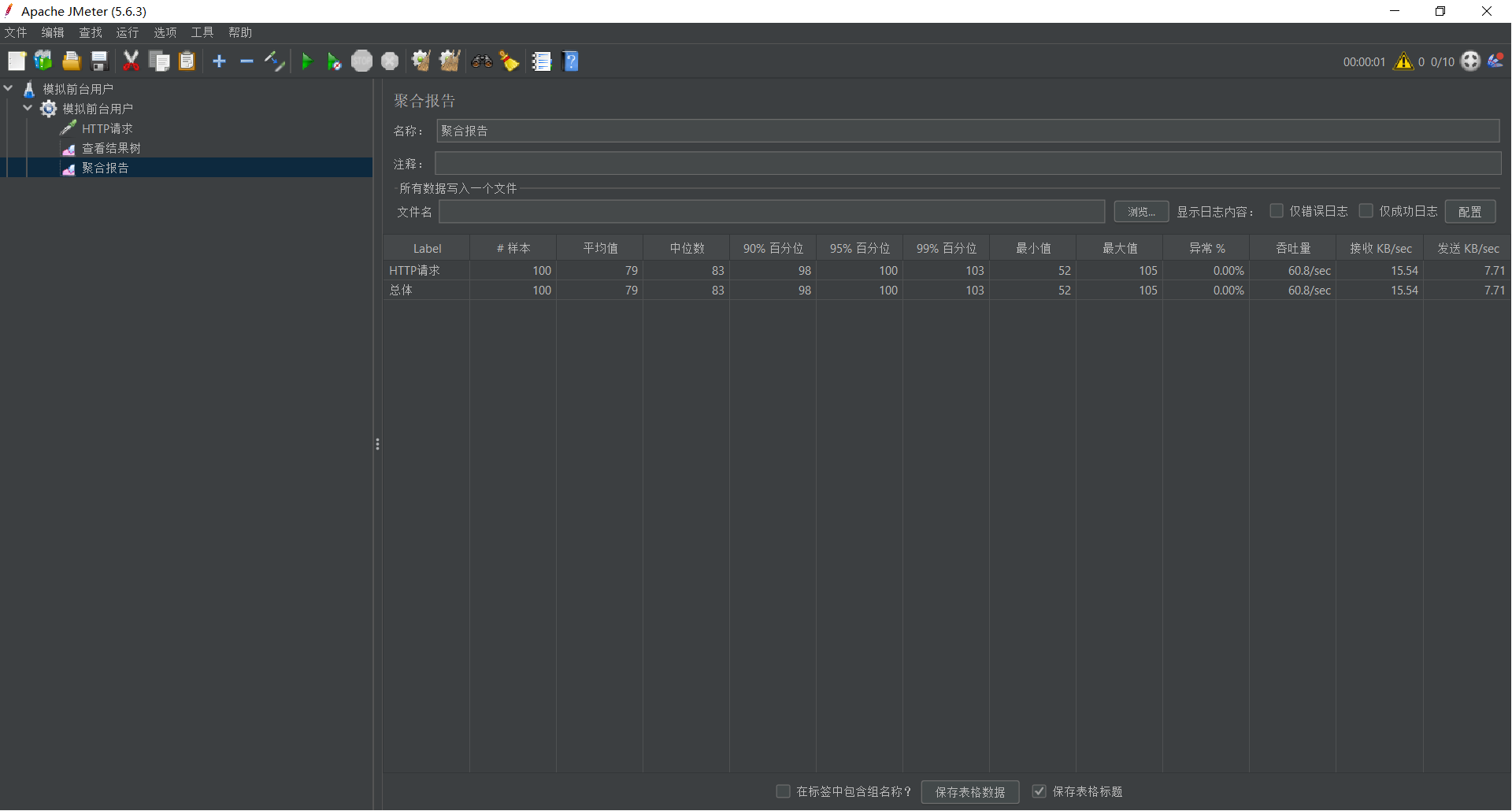
| 指标 (Label) | 含义 | 理想状态 |
|---|---|---|
| 样本 (Samples) | 总请求数 | 应等于 线程数 x 循环次数。 |
| 平均值 (Average) | 平均响应时间 (ms) | 越低越好。但在长尾效应下,参考价值不如 99% 线。 |
| 99% 百分位 (99% Line) | 最重要的指标 | 表示 99% 的请求都在这个时间内完成了。这代表了绝大多数用户的体验。 |
| 异常 % (Error %) | 错误率 | 必须为 0.00%。任何报错都需要排查。 |
| 吞吐量 (Throughput) | TPS | 每秒处理请求数。越高越好(前提是报错率为 0)。 |
实战分析:假设你的聚合报告显示:
- Average: 75ms
- Throughput: 120.5/sec
这说明在当前并发下,我们的 Spring Boot 应用每秒能处理约 120 个请求,平均每个请求处理耗时 75ms(这与我们在代码中写的 Thread.sleep(50~100) 吻合)。
2.3.3. 重要警告:GUI 模式的陷阱
新手必读:在使用 JMeter 进行 正式的大规模压测(例如成千上万并发)时,严禁 开启 “察看结果树” 和 “聚合报告” 等 GUI 监听器。
因为 GUI 组件渲染图表和记录实时日志会消耗大量的客户端 CPU 和内存资源。这会导致 JMeter 自身成为瓶颈,测量出的数据不准确(比如 TPS 上不去是因为你电脑卡了,而不是服务器卡了)。
最佳实践:
- GUI 模式:仅用于编写、调试脚本(验证通不通)。
- CLI (命令行) 模式:用于正式执行压测(验证快不快)。我们将在后续章节详细讲解。
2.4. 本章小结
在本章中,我们打通了 JMeter 到 Spring Boot 的第一条测试链路。
核心要点:
- 三剑客:线程组(人)、取样器(动作)、监听器(结果)是构建脚本的基石。
- Ramp-Up:用于控制用户进入系统的速率,避免瞬间洪峰导致测试失真。
- 指标分析:重点关注 99% Line(绝大多数人的体验)和 Throughput(系统处理能力),而不是简单的平均值。
- GUI 限制:调试用 GUI,压测用 CLI。
下一步计划:目前的脚本虽然能跑,但所有参数都是 “写死” 的。在真实业务中,每个用户的 ID、Token 或者查询的商品都不一样。在下一章,我们将学习 变量与参数化,让我们的压测脚本学会 “千人千面”。
第三章. 变量与参数化:告别硬编码
摘要:本章我们将解决测试脚本 “千人一面” 的问题。通过引入用户自定义变量、CSV 数据文件和随机函数,我们将把硬编码的死数据转化为动态的活数据,模拟真实世界中 “千人千面” 的并发访问场景。
本章学习路径
我们将按照以下步骤改造我们的测试脚本:
- 3.1 升级靶场
- 3.1.1 增加带参接口
- 3.1.2 理解缓存对压测的干扰
- 3.2 用户自定义变量
- 3.2.1 提取全局环境配置(Host/Port)
- 3.2.2 实现环境一键切换
- 3.3 CSV 数据驱动
- 3.3.1 准备测试数据文件
- 3.3.2 配置 CSV Data Set Config
- 3.3.3 循环读取机制详解
- 3.4 随机化函数
- 3.4.1 函数助手的使用
- 3.4.2 UUID 与随机数字生成
3.1. 升级靶场:拒绝 “假” 压测
在上一节中,我们测试的是 /api/test/hello 接口。无论发多少次请求,参数和结果都是一样的。
但在真实的数据库压测中,如果 1000 个用户都查询同一个 id=1 的商品,数据库会利用 Buffer Pool(缓冲池) 机制将数据缓存到内存中。这意味着后续的 999 次请求根本没有触达磁盘 IO,这样的压测结果是失真的(看似 TPS 很高,实际上线就挂)。
为了模拟真实场景,我们需要一个能接收参数的接口。
3.1.1. 编写带参接口
文件路径:src/main/java/com/demo/jmeterdemo/controller/TestController.java
请在原有的 Controller 中添加一个新的接口:
1 | /** |
重启项目,访问 http://localhost:8080/api/test/product/999 进行验证。
3.2. 用户参数:环境一键切换
在开发过程中,我们经常需要在 本地环境 (Local)、测试环境 (Dev) 和 生产环境 (Prod) 之间切换。如果你的脚本里写死了 localhost,每次切换环境都要把几十个 HTTP 请求挨个修改一遍,这简直是噩梦。
3.2.1. 定义全局变量
操作步骤:
- 点击 JMeter 左侧最顶层的 测试计划 (Test Plan)。
- 右键点击 “测试计划” -> 添加 -> 前置处理器 -> 用户变量。
- 点击 添加,输入以下键值对:
| 名称 (Name) | 值 (Value) | 描述 |
|---|---|---|
target_host | localhost | 目标服务器地址 |
target_port | 8080 | 目标端口 |
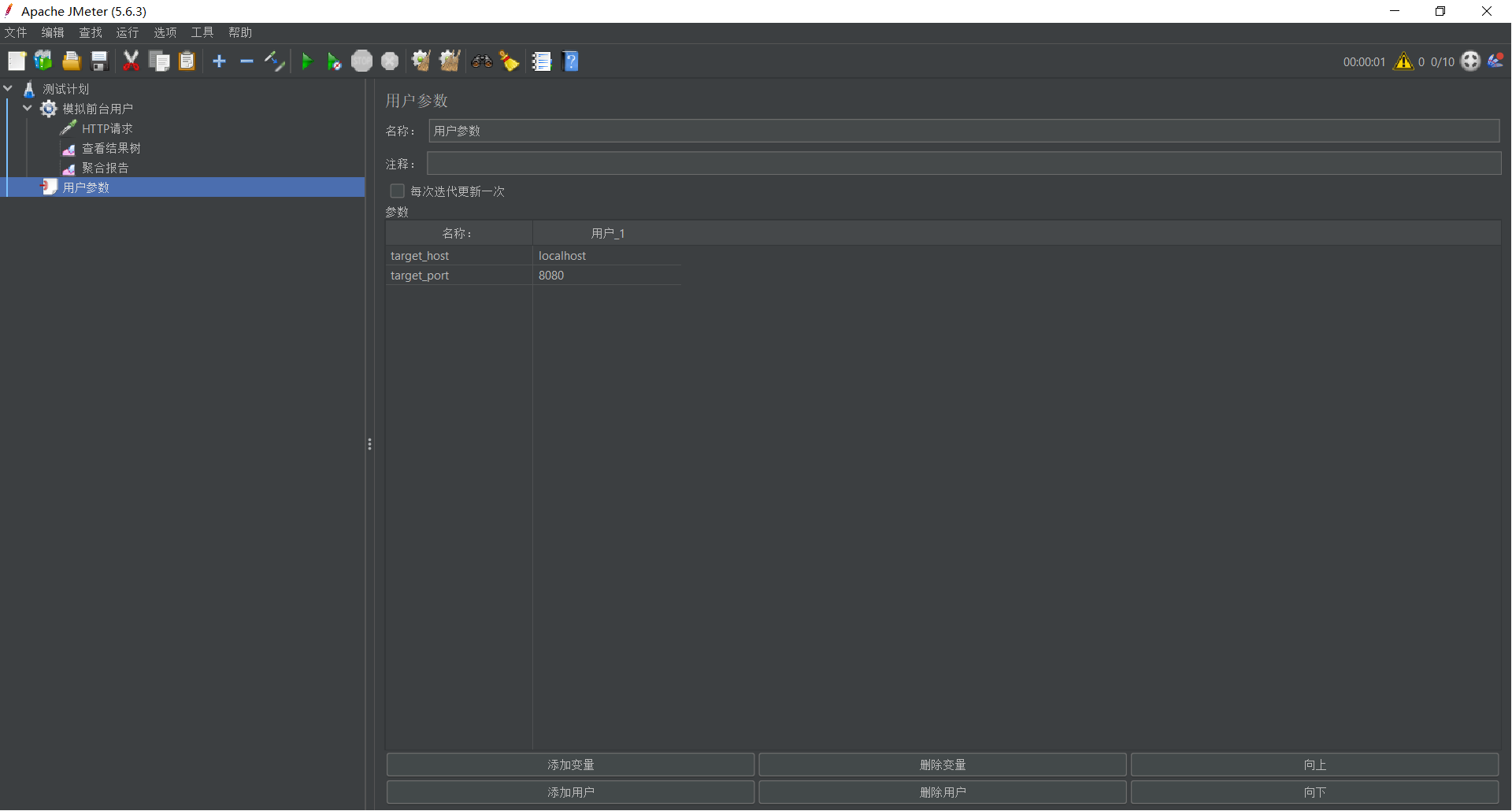
3.2.2. 引用变量
回到我们在第二章创建的 HTTP 请求:
- 将 服务器名称或 IP 中的
localhost替换为${target_host}。 - 将 端口号 中的
8080替换为${target_port}。
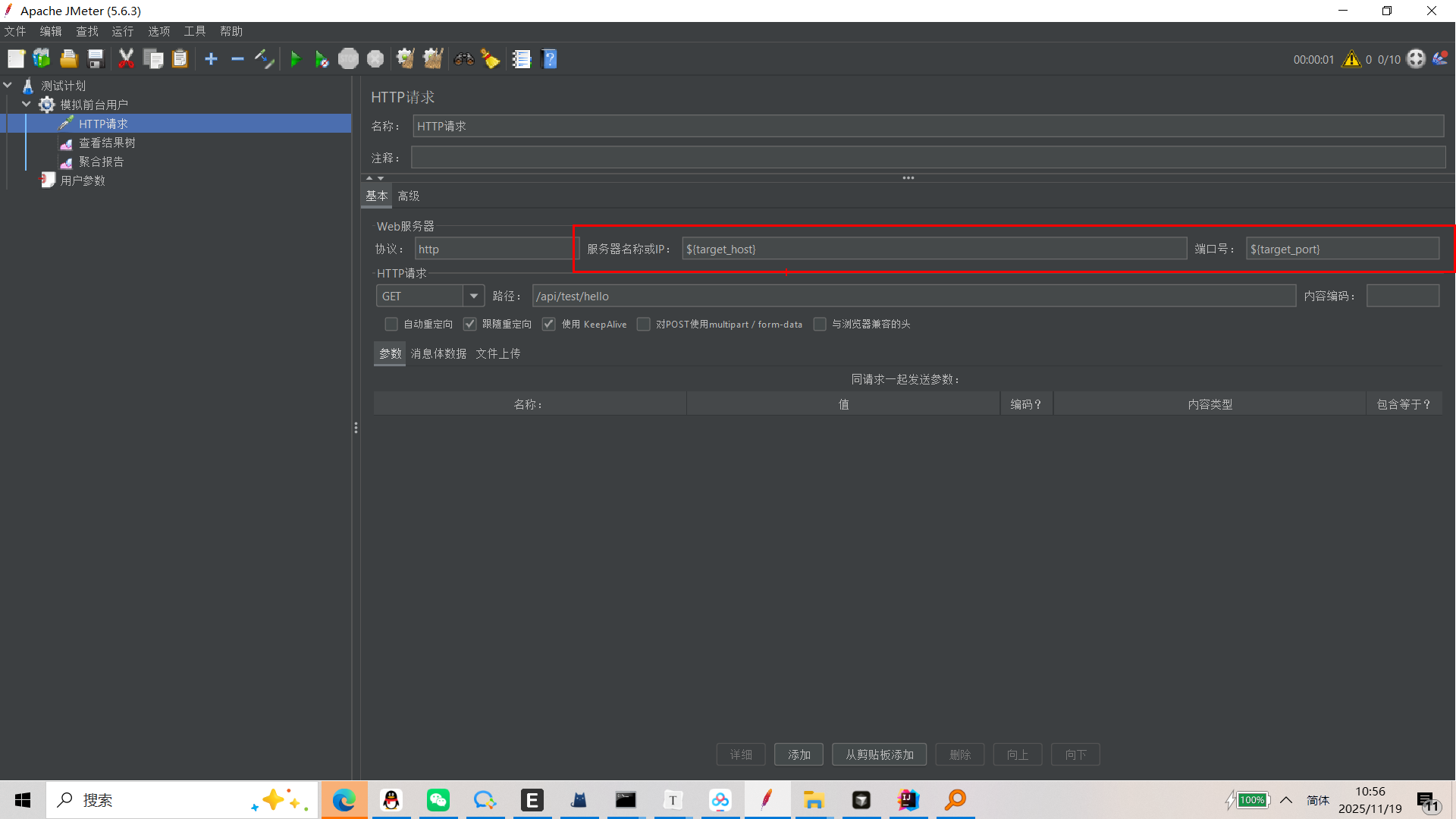
语法说明:${variable_name} 是 JMeter 中引用变量的标准语法。
现在,如果你想切换到测试服务器,只需要在测试计划最顶层修改一次 target_host 的值,所有引用的地方都会自动生效。
3.3. CSV 数据驱动:模拟批量用户
现在我们要模拟 100 个不同的用户,查询 100 个不同的商品。我们将使用 CSV 文件来管理这些数据。
3.3.1. 准备数据文件
- 在电脑任意位置(建议在 JMeter 脚本同目录下)创建一个名为
data.csv的文件。 - 输入几行测试数据(不需要表头,直接写内容):
1 | 1001 |
3.3.2. 配置 CSV Data Set Config
这是 JMeter 中最常用的元件之一。
操作步骤:
- 右键点击 线程组 -> 添加 -> 配置元件 (Config Element) -> CSV 数据文件设置 (CSV Data Set Config)。
- 重要:将该组件拖拽到 “HTTP 请求” 的 上方(执行顺序很重要)。
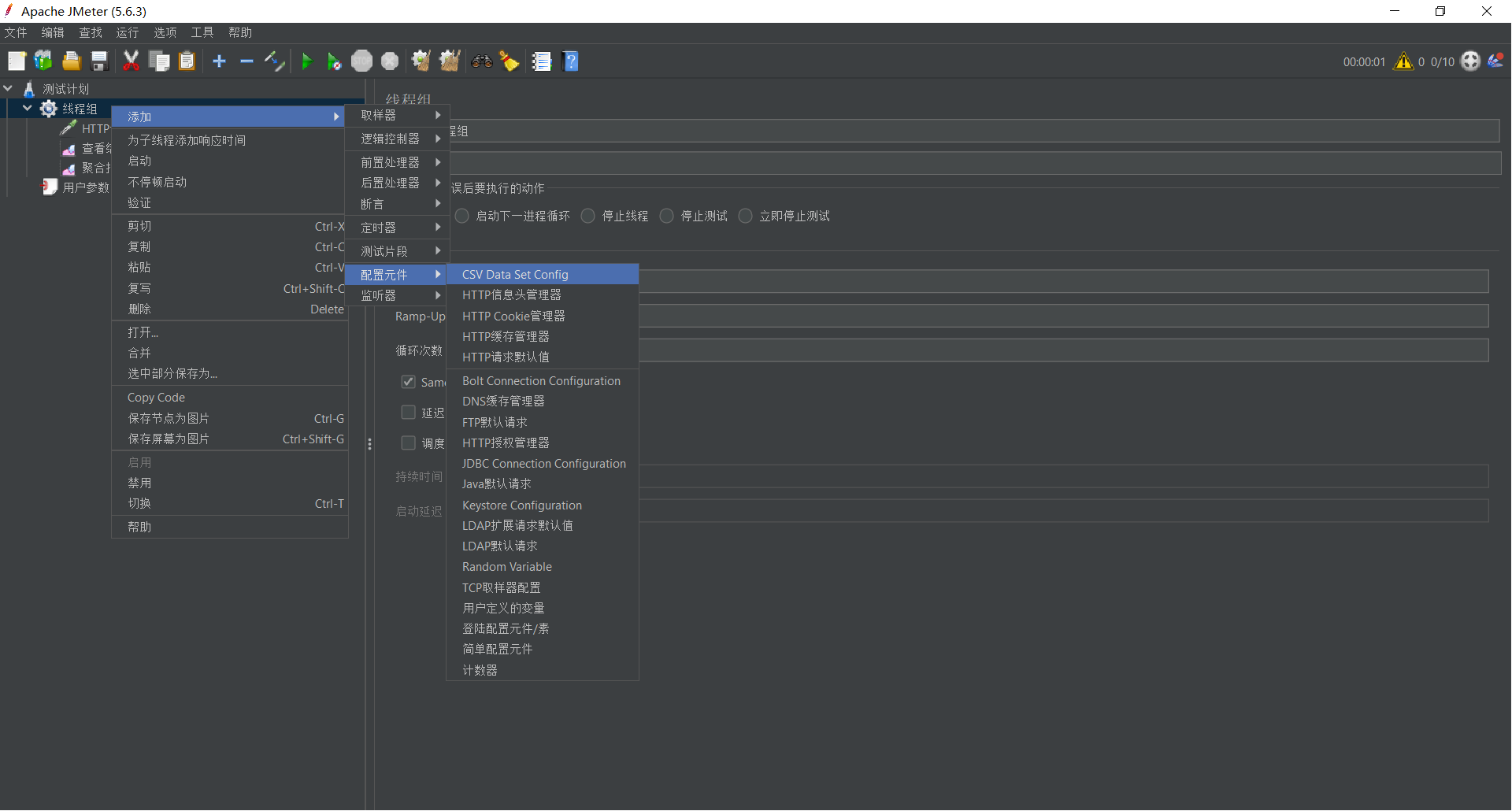
关键参数配置:
| 参数项 | 配置值 | 解释 |
|---|---|---|
| 文件名 (Filename) | data.csv | 如果文件在脚本同目录,直接写文件名;否则写绝对路径。 |
| 文件编码 (File encoding) | UTF-8 | 防止中文参数乱码。 |
| 变量名称 (Variable Names) | p_id | 给 CSV 中的列起个变量名。如果有两列,用逗号隔开,如 username,password。 |
| 遇到文件结束符再次循环? | True | 如果文件只有 5 行,但线程循环 10 次,设为 True 会从头重新读取;设为 False 则会停止测试。 |
| 线程共享模式 | All threads | 所有线程共享这份文件。线程 1 取第一行,线程 2 取第二行,互不重复。 |
3.3.3. 实战调用
- 打开 HTTP 请求。
- 修改 路径 (Path) 为:
/api/test/product/${p_id}。 - 启动测试。
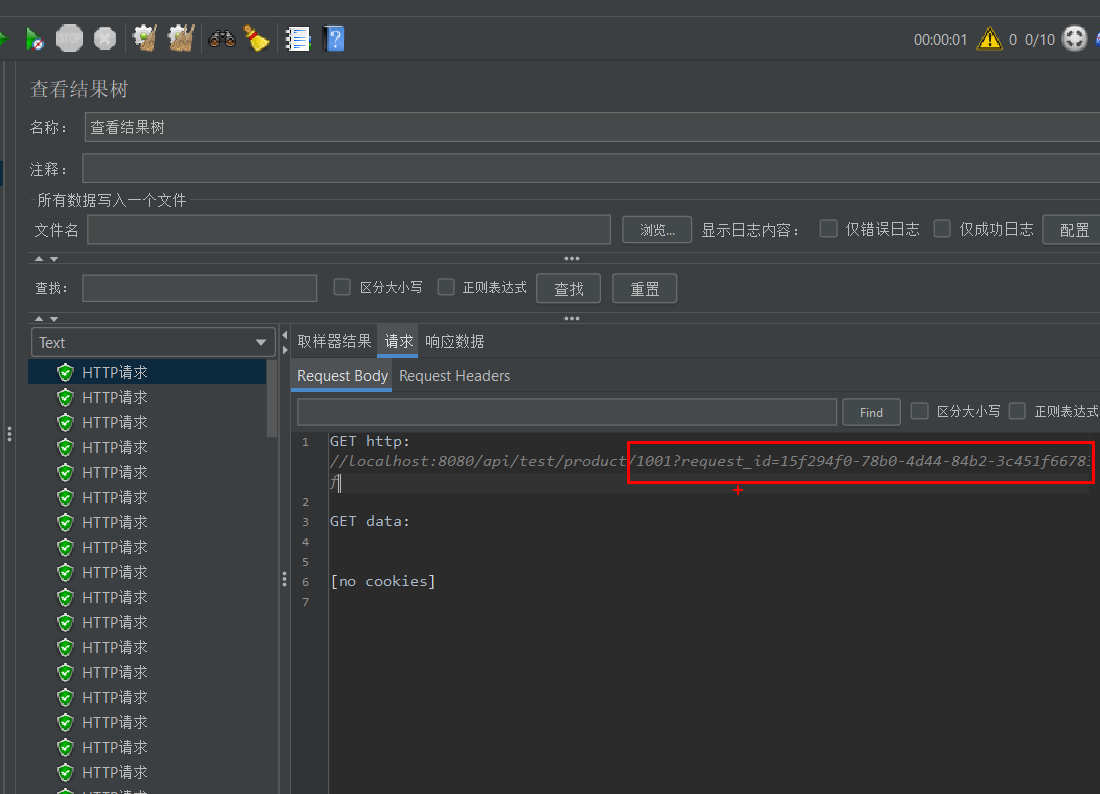
查看 察看结果树,你会发现请求路径变成了:
/api/test/product/1001/api/test/product/1002- …
这意味着 CSV 数据已成功注入。
3.4. 随机化函数:动态生成数据
有时候我们不需要固定的数据,而是需要唯一的随机数据(比如生成这就唯一的订单号,或者模拟随机的用户行为)。JMeter 提供了强大的 函数助手。
3.4.1. 函数助手 (Function Helper)
这是 JMeter 的内置外挂。
操作步骤:
- 点击 JMeter 顶部菜单栏的 工具 (Tools) -> 函数助手对话框 (Function Helper Dialog)。
- 这是一个独立的弹窗,里面列出了所有可用函数。
3.4.2. 常用函数实战
我们修改脚本,在查询商品的同时,传递一个随机生成的 Trace-ID 请求头。
场景 1:生成随机数字
- 在函数助手中选择
__Random。 - 最小值:
1000,最大值:9999。 - 点击 生成,你会得到字符串:
${__Random(1000,9999,)}。
场景 2:生成 UUID (全球唯一标识)
- 选择
__UUID。 - 点击 生成,得到:
${__UUID}。
应用到 HTTP 请求:在 HTTP 请求面板,点击底部的 添加 按钮(参数区域):
- 名称:
request_id - 值:
${__UUID}
再次运行测试,查看结果树中的 请求数据 (Request Body/Header),你会看到类似 request_id=550e8400-e29b-41d4-a716-446655440000 的动态参数。
3.5. 本章小结
在本章中,我们将静态的脚本进化为了动态脚本。
核心要点:
- 变量引用:使用
${var_name}语法可以引用任何地方定义的变量。 - CSV 数据集:这是实现 “参数化” 的核心手段,特别适用于大量账号登录、批量查询等场景。线程共享模式 决定了数据是在线程间共享还是独享。
- 函数助手:善用
${__Random}和${__UUID}可以模拟离散的流量,避免热点数据造成的缓存假象。
思考题:如果你在 CSV 中配置了 100 个用户账号,并且启动了 200 个线程,同时设置 “遇到文件结束符再次循环” 为 False,会发生什么?
(答案:前 100 个线程会成功获取数据,后 100 个线程会因为取不到数据而停止执行。)
下一步计划:现在的接口都是独立的。但在实际业务中,往往是 “用户登录” -> “获取 Token” -> “拿着 Token 下单”。这涉及到了接口之间的数据传递。下一章,我们将学习性能测试中最关键的技术——关联 (Correlation),教你如何从上一个接口的响应中提取数据传递给下一个接口。
第四章. 关联:搞定 Spring Security 认证
摘要:本章我们将攻克性能测试中最大的拦路虎——接口依赖。我们将模拟真实的 “登录 -> 获取 Token -> 携带 Token 访问受保护接口” 的业务闭环,掌握 JSON 提取器和正则表达式提取器的核心用法,实现跨请求的数据传递。
本章学习路径
我们将按照以下步骤构建动态的业务链路:
- 4.1 场景与靶场升级
- 4.1.1 什么是 “关联” (Correlation)
- 4.1.2 模拟 Spring Security 登录与鉴权
- 4.2 JSON 提取器实战
- 4.2.1 JSONPath 语法速成
- 4.2.2 提取 Token 变量
- 4.3 跨请求传递
- 4.3.1 HTTP 信息头管理器的使用
- 4.3.2 调试与验证变量传递
- 4.4 正则表达式提取器(进阶)
- 4.4.1 万能的 Regex 语法
- 4.4.2 提取响应头中的 Cookie
4.1. 场景与靶场升级:模拟真实的业务链
在上一章,我们通过随机参数模拟了独立的查询请求。但在现实世界中,90% 的业务操作都需要先 “登录”。
在 Spring Boot + Spring Security 的架构中,通常采用 JWT (JSON Web Token) 机制:
- 客户端调用
/login,服务端校验账号密码,返回一个加密字符串(Token)。 - 客户端在后续请求头中携带
Authorization: Bearer {Token}。 - 服务端拦截器校验 Token 有效性。
为了在 JMeter 中实现这一过程,我们需要先升级我们的 Spring Boot 靶场。
4.1.1. 编写模拟鉴权接口
为了专注于 JMeter 本身,我们不引入笨重的 Spring Security 依赖,而是手动编写代码模拟这一行为。
文件路径:src/main/java/com/demo/jmeterdemo/controller/AuthController.java
请创建新的控制器类:
1 | package com.demo.jmeterdemo.controller; |
重启项目,我们有了两个新目标:
POST /api/auth/login:获取 Token。GET /api/auth/order/create:需要 Token 才能访问。
4.2. JSON 提取器实战:抓取 Token
现在回到 JMeter。如果我们直接按顺序调用这两个接口,第二个接口必然报错(403 Forbidden),因为 JMeter 默认是一个 “健忘” 的客户端,它不会自动把上一次请求的响应带到下一次。
我们需要手动建立关联,这一步在 JMeter 中通过 后置处理器 (Post Processor) 实现。
4.2.1. 第一步:配置登录请求
创建一个新的 线程组,命名为 " S01_下单流程 "。
添加 HTTP 请求,命名为 " API_登录 "。
配置如下参数:
- Method:
POST - Path:
/api/auth/login - 消息体数据:
1 | { |
- 重要:因为我们要发送 JSON Body,必须添加 HTTP 信息头管理器 (HTTP Header Manager)。
配置步骤如下:
右键点击 " API_登录 " -> 添加 -> 配置元件 -> HTTP 信息头管理器。
添加一行:Content-Type = application/json。
4.2.2. 第二步:添加 JSON 提取器
我们的目标是从登录接口返回的 JSON 中提取 token 字段的值。
1 | { |
操作步骤:
右键点击 " API_登录 " -> 添加 -> 后置处理器 -> JSON 提取器 (JSON Extractor)。
配置核心参数:
| 参数名 | 配置值 | 解释 |
|---|---|---|
| 变量名称 (Names of created variables) | jwt_token | 给提取出来的值起个名字,后续用 ${jwt_token} 引用。 |
| JSON 路径表达式 (JSON Path expressions) | $.token | $ 代表根节点,.token 代表下一级 key。 |
| 匹配号 (Match No.) | 1 | 如果有多个 token,取第 1 个。0 代表随机,-1 代表全部。 |
| 默认值 (Default Value) | TOKEN_NOT_FOUND | 如果提取失败,变量会被赋值为这个字符串(便于排查错误)。 |
4.3. 跨请求传递:使用 Token
拿到了 Token,下一步是将其 “注入” 到下单接口的请求头中。
4.3.1. 配置下单请求
- 在线程组下添加第二个 HTTP 请求,命名为 " API_创建订单 "。
配置如下参数:
- Method:
GET - Path:
/api/auth/order/create
- 关键步骤:添加请求头。
操作步骤如下:
- 右键点击 " API_创建订单 " -> 添加 -> 配置元件 -> HTTP 信息头管理器。
- 添加一行配置:
- 名称*:
Authorization
- 名称*:
- 值*:
Bearer ${jwt_token}
- 值*:
注意:这里的值必须严格遵循后端代码的校验规则(即前缀 Bearer + 空格 + 变量)。
4.3.2. 调试与验证
点击启动运行测试,观察 察看结果树。
API_登录:响应数据中包含 Token。
API_创建订单:
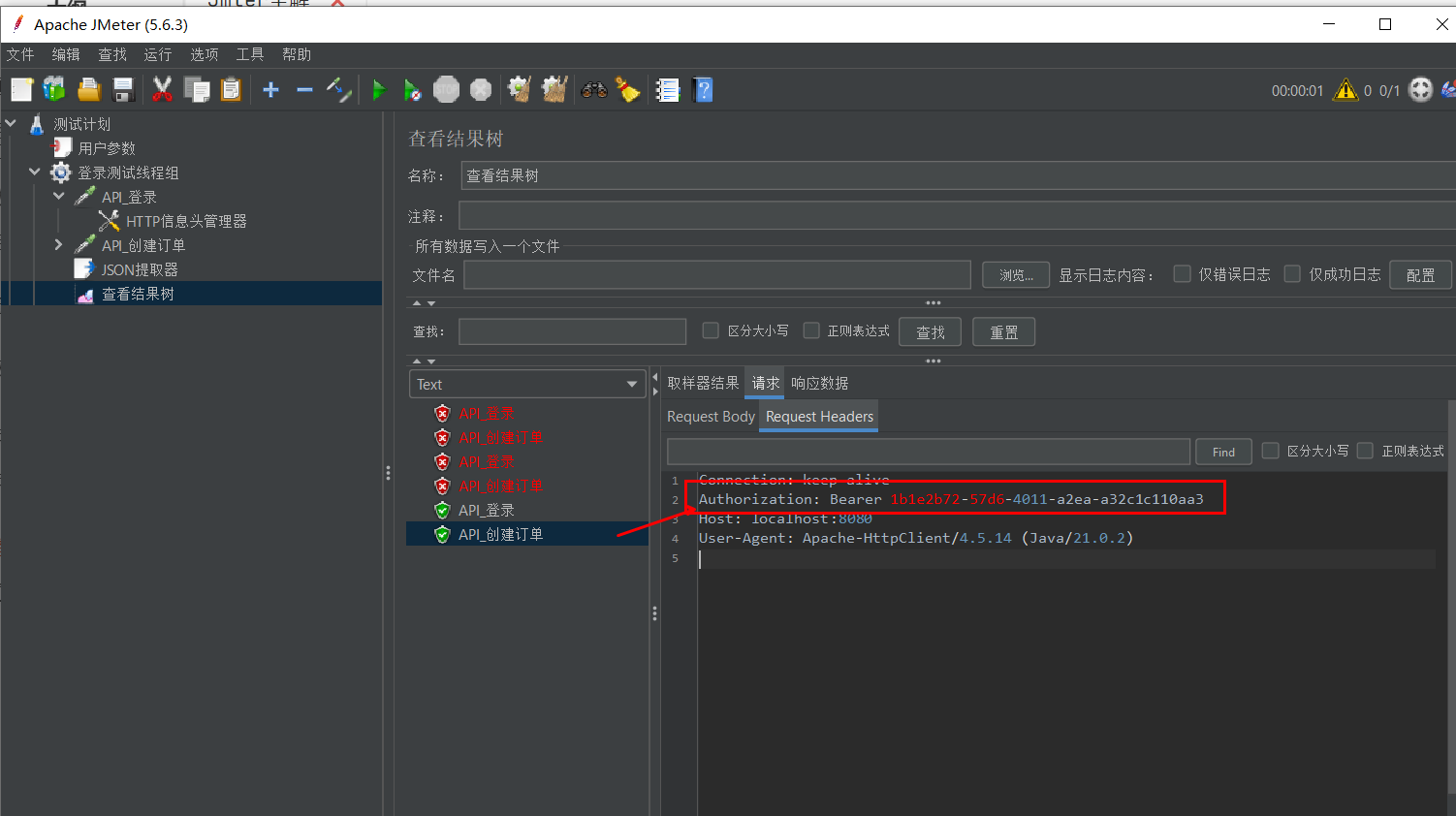
验证步骤如下:
- 点击 请求 (Request) 选项卡 -> Request Headers。
- 你应该能看到
Authorization: Bearer 550e8400...。 - 如果看到
Authorization: Bearer TOKEN_NOT_FOUND,说明 JSON 提取器配置有误(通常是 JSONPath 写错了)。 - 如果响应状态码为
200且msg: "Order Created Successfully",说明关联成功!
4.4. 正则表达式提取器:处理非 JSON 场景
在现代前后端分离开发中,JSON 确实是主流。但在企业级开发中,我们经常会遇到 “老旧系统”(Legacy System)或第三方回调接口,它们返回的可能不是标准的 JSON,而是 XML、HTML 甚至纯文本字符串。此外,像 Set-Cookie、Location 重定向地址等关键信息,往往隐藏在响应头(Response Headers)而非响应体中。
面对这些场景,JSON 提取器就失效了。这时,我们需要请出 JMeter 的万能军刀——正则表达式提取器。
4.4.1. 场景升级:模拟 “老旧” 接口
为了演示这个场景,我们需要在 Spring Boot 靶场中增加一个模拟的老旧接口。它不返回 JSON,而是返回一段具有特定格式的字符串。
修改文件:src/main/java/com/demo/jmeterdemo/controller/AuthController.java
请在 AuthController 类中添加以下方法:
1 | /** |
重启项目,访问 http://localhost:8080/api/auth/legacy/status,你会看到类似这样的响应:User:admin|SessionID:sess_1731981234567|Status:Active
挑战目标:我们需要从这串文本中精准提取出 sess_1731981234567。
4.4.2. 核心语法拆解
在使用提取器之前,我们必须先搞懂正则表达式在 JMeter 中的特殊语法。
我们要提取的目标是 SessionID: 和 | 之间的内容。
正则表达式公式:SessionID:(.*?)\|
SessionID::左边界。告诉 JMeter 从哪里开始找(锚点)。():捕获组。括号里的内容就是我们真正想要的数据。.:匹配任意字符。*:匹配 0 次或多次。?:非贪婪模式(关键!)。- 如果不加
?(贪婪模式),它会一直匹配到这一行的最后一个|。 - 加上
?,它会匹配到 最近的 一个|就停止。
- 如果不加
\|:右边界。因为|在正则中是特殊字符(表示 “或”),所以需要用\转义。
4.4.3. 实战配置:提取 SessionID
现在我们来配置 JMeter 脚本。
操作步骤:
- 添加请求:在线程组下添加一个新的 HTTP 请求,命名为 " API_老旧接口 "。
- Path:
/api/auth/legacy/status
* Method:GET
添加提取器:右键点击 " API_老旧接口 " -> 添加 -> 后置处理器 -> 正则表达式提取器 (Regular Expression Extractor)。
详细配置(请严格按照下表填写):
| 参数项 | 配置值 | 深度原理解析 |
|---|---|---|
| 要检查的响应字段 | 主体 (Body) | 因为我们的数据在 Response Body 里。如果要提取 Cookie,这里需选 信息头。 |
| 引用名称 | legacy_sess | 提取后的变量名,后续用 ${legacy_sess} 使用。 |
| 正则表达式 | SessionID:(.*?)| | 见上文的语法拆解。 |
| 模板 (Template) | $1$ | $1$ 表示提取第 1 个括号对捕获的内容。如果是 $0$ 则表示提取整个表达式(包含边界)。 |
| 匹配数字 (Match No.) | 1 | 如果响应中有多个 SessionID,填 1 取第一个;填 0 会随机取一个(常用于随机点击链接)。 |
| 缺省值 | ERR_SESS | 最佳实践:永远给一个显眼的错误默认值,方便后续 Debug。 |
4.4.4. 验证与调试
提取配置好了,但正则很容易写错(比如漏了转义符)。我们如何验证它是否工作正常?
方法一:使用 Debug Sampler(推荐)
- 在线程组中添加一个 调试取样器 (Debug Sampler)(位于:添加 -> 取样器 -> Debug Sampler)。
- 这个组件的作用是把当前线程所有的变量都打印出来。
- 运行脚本。
- 在 察看结果树 中点击
Debug Sampler的响应数据。 - 搜索
legacy_sess:- ✅ 成功:
legacy_sess=sess_1731981234567 - ❌ 失败:
legacy_sess=ERR_SESS(此时需要回头检查正则表达式)
- ✅ 成功:
方法二:正则测试器(RegExp Tester)
JMeter 的 “察看结果树” 自带了一个正则测试工具,不需要反复运行脚本 即可调试。
- 点击 察看结果树,选择 " API_老旧接口 " 的请求记录。
- 将结果树面板中的下拉框(默认是 Text)切换为 RegExp Tester。
- 在
Regular expression输入框中填入SessionID:(.*?)\|。 - 点击 Test 按钮。
- 界面下方会直接显示提取结果。这是调试复杂正则最高效的方法。
4.5. 本章小结
在本章中,我们攻克了性能测试中 “数据流通” 的难题。
核心要点:
- JSON 提取器:处理标准 REST API 的首选,简单高效,认准
$.key语法。 - 正则提取器:处理非标数据(如老旧系统、HTML、Header 头信息)的终极方案。
- 口诀:
左边界(想要的内容)右边界。 - 注意:慎用贪婪模式,善用
?限制匹配范围。
- 口诀:
- 调试技巧:善用 Debug Sampler 查看变量池,或利用 RegExp Tester 实时验证正则逻辑。
下一步计划:现在我们的脚本已经能够成功登录并提取 Token 和 SessionID。但是,如果后端突然报错了(HTTP 500),或者返回了 {"code": 20001, "msg": "库存不足"},JMeter 默认还是会显示 “绿色盾牌”(因为 HTTP 状态码是 200)。这会导致我们误判测试结果。在下一章,我们将学习 断言 (Assertion),给 JMeter 装上 “火眼金睛”,让它能识别真正的业务成功。
第五章. 断言与逻辑控制:让脚本有 “脑子”
摘要:本章将解决 JMeter “盲目乐观” 的问题。默认情况下,只要服务器返回 HTTP 200,JMeter 就会判定测试通过,忽略了业务逻辑报错(如 “库存不足”)。我们将学习如何使用 断言 识别真正的业务失败,并利用 逻辑控制器 让脚本根据上一步的结果智能决定下一步的走向。
本章学习路径
我们将按照以下步骤打造智能脚本:
- 5.1 揭穿 “假成功” 现象
- 5.1.1 构造一个 “HTTP 200 但业务失败” 的接口
- 5.1.2 观察 JMeter 的误判
- 5.2 响应断言 (Response Assertion)
- 5.2.1 校验核心业务字段
- 5.2.2 设定自定义的失败消息
- 5.3 JSON 断言 (JSON Assertion)
- 5.3.1 精准校验结构化数据
- 5.3.2 验证数组长度与特定值
- 5.4 逻辑控制器 (If Controller)
- 5.4.1 场景:登录失败就不下单
- 5.4.2 JEXL3 表达式语法实战
5.1. 揭穿 “假成功” 现象
在上一章,我们完成了关联。但在实际开发中,接口返回 HTTP 200 并不代表业务成功。例如支付接口返回 {"code": 5001, "msg": "余额不足"},HTTP 状态码依然是 200。如果不加判断,JMeter 会认为这次请求是成功的,导致最终的压测报告显示 “100% 成功率”,这不仅误导,甚至可能掩盖严重的线上 Bug。
5.1.1. 改造靶场:模拟业务异常
我们需要修改 Spring Boot 代码,增加一个模拟库存扣减的接口,它会随机返回成功或失败。
文件路径:src/main/java/com/demo/jmeterdemo/controller/OrderController.java
请新建 OrderController 类:
1 | package com.demo.jmeterdemo.controller; |
重启项目,我们准备开始测试。
5.1.2. 观察 JMeter 的误判
在 JMeter 中新建线程组 " S02_断言测试 "。
添加 HTTP 请求,命名为 " API_下单 "。
配置如下参数:
- Path:
/api/order/create - Method:
POST
设置线程组 循环次数 为
10。运行并观察 察看结果树。
结果分析:你会发现 10 次请求全部都是 绿色盾牌。点开响应数据,你会发现其中夹杂着 {"code": 5001, "msg": "Out of Stock"}。
这就是 “假成功”。在真正的压测报告中,我们必须把这 30% 的库存不足标记为 “失败”,否则我们就不知道系统在什么并发量下会开始出现业务瓶颈。
5.2. 响应断言:最通用的门神
为了纠正 JMeter 的判断,我们需要添加 断言 (Assertion)。断言就是我们设定的 “通过标准”。
5.2.1. 添加响应断言
操作步骤:
- 右键点击 " API_下单 " -> 添加 -> 断言 -> 响应断言 (Response Assertion)。
- 配置以下参数:
| 参数项 | 配置值 | 解释 |
|---|---|---|
| 测试字段 (Apply to) | Main sample only | 只检查主请求。 |
| 测试字段 (Field to Test) | 响应文本 (Text Response) | 检查 Response Body 的内容。 |
| 模式匹配规则 | 包括 (Contains) | 只要包含指定字符串就算通过。 |
| 测试模式 (Patterns to Test) | "code": 200 | 点击【添加】按钮输入。这里我们强制要求返回结果必须包含这段 JSON 文本。 |
| 自定义失败消息 | 业务代码非 200 | 如果断言失败,结果树中会显示这句话,方便排查。 |
5.2.2. 验证效果
再次运行测试。
预期结果:在 察看结果树 中,你应该会看到大约 30% 的请求变成了 红色感叹号。点击红色的请求,展开 断言结果 (Assertion Failure Message),你会看到:Assertion error: false that ... contains "code": 200

这样,JMeter 的聚合报告中的 “Error %” 就能真实反映业务成功率了。
5.3. JSON 断言:结构化数据的专家
虽然 “响应断言” 简单好用,但通过字符串匹配 "code": 200 并不严谨。如果返回的 msg 里包含 code: 200 字符,可能会导致误判。
对于 JSON 接口,更推荐使用 JSON 断言。
5.3.1. 配置 JSON 断言
我们先禁用掉刚才的 “响应断言”(右键 -> 禁用),添加一个新的断言。
操作步骤:
- 右键点击 " API_下单 " -> 添加 -> 断言 -> JSON 断言 (JSON Assertion)。
- 配置参数:
| 参数项 | 配置值 | 解释 |
|---|---|---|
| Assert JSON Path exists | $.orderId | 我们要求返回结果中必须包含 orderId 字段。只有下单成功才有这个字段。 |
| Expected Value (可选) | (空) | 如果勾选了 Additionally assert value,可以校验字段的值。这里我们只校验 “是否存在”。 |
原理:当返回 {"code": 5001, "msg": "Out of Stock"} 时,JSON 中没有 orderId 字段,断言通过 JSON Path 找不到路径,判定为失败。
5.4. 逻辑控制器:让脚本学会 “止损”
默认情况下,JMeter 像一个只会按顺序执行命令的机器人:无论上一步是成功还是炸了,它都会坚定地执行下一步。但在真实的业务场景中,如果用户连 “登录” 都失败了,后续的 “下单”、“支付” 操作根本就不应该发生。继续执行这些无效请求,不仅浪费压测机的 CPU,还会让服务端产生大量无意义的 401 错误日志,干扰问题排查。
我们需要利用 If 控制器 (If Controller) 来实现逻辑判断:只有当条件满足时,才执行内部的组件。
5.4.1. 场景重构:依赖链路
为了演示这个功能,我们需要构建一个典型的依赖场景:
- 前置动作:用户尝试登录。
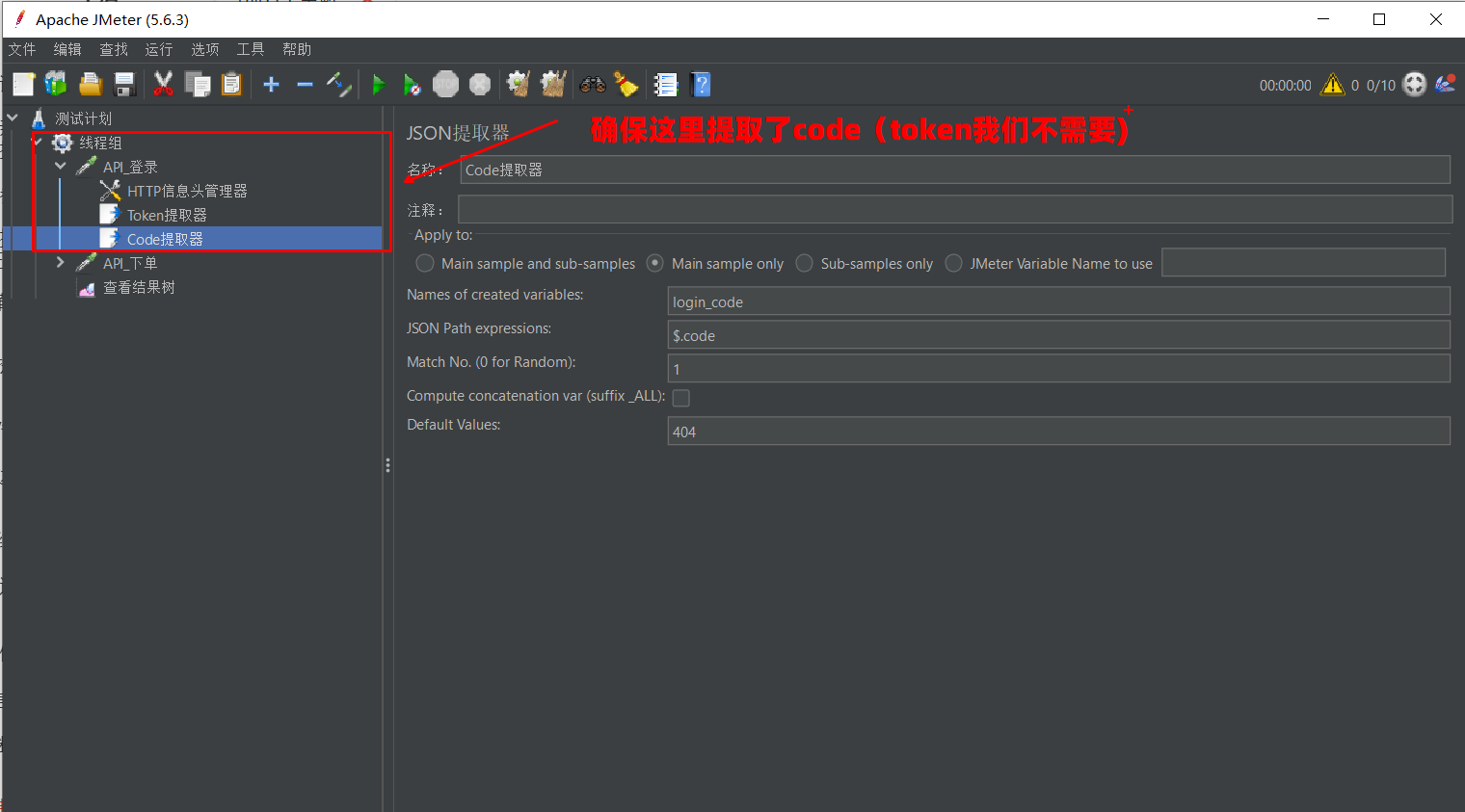
- 判断依据:提取登录接口返回的状态码
code。 - 分支逻辑:
- 如果
code == 200:执行 “API_下单”。 - 如果
code != 200:直接跳过,不做任何操作。
- 如果
准备工作:请确保你的 “API_登录” 请求下已经挂载了 JSON 提取器,并将状态码提取为变量 login_code。
5.4.2. 借助函数助手生成表达式
在配置 If 控制器之前,我们先解决最难的一步:如何写出正确的判断表达式?
手动编写 ${__jexl3(...)} 既容易错又难记。我们要利用 函数助手 自动生成代码。
操作步骤:
点击 JMeter 顶部菜单栏的 工具 (Tools) -> 函数助手对话框 (Function Helper Dialog)。
在左侧列表中找到并选中
__jexl3(这是 JMeter 高性能运算函数)。在右侧的 参数值 栏位中,输入你的逻辑表达式:
"${login_code}" == "200"点击底部的 生成 (Generate) 按钮。
复制 生成的字符串:
${__jexl3("${login_code}" == "200",)}。
语法细节:为什么变量 ${login_code} 外面要加双引号?这是为了防止空指针。如果提取失败,变量为空,表达式会变成 "" == "200"(合法);如果不加引号,会变成 == "200"(语法错误)。
5.4.3. 配置 If 控制器
拿到生成的代码后,配置控制器就非常简单了。
操作步骤:
- 右键点击 线程组 -> 添加 -> 逻辑控制器 -> 如果 (If) 控制器。
- 将 “API_下单” 请求 拖拽 到 “If 控制器” 的内部(使其成为子节点)。
- 在 If 控制器的面板中进行粘贴:
- Expression:粘贴刚才复制的代码
${__jexl3("${login_code}" == "200",)}。 - Interpret Condition as Variable Expression?:必须勾选。
- Expression:粘贴刚才复制的代码
始终勾选 “Interpret Condition as Variable Expression?”。这告诉 JMeter 直接使用高性能的 JEXL3 引擎处理变量,而不是启动笨重的 JavaScript 引擎。在高并发压测下,这一项配置能提升 10 倍以上的性能。
5.4.4. 验证 “止损” 效果
配置完成后,我们进行正反两面的测试,验证逻辑是否生效。
测试 A:正向用例(登录成功)
- 修改登录接口参数为正确的账号密码(
admin/123456)。 - 运行脚本。
- 观察:
login_code变为 200,你会在结果树中同时看到 “API_登录” 和 “API_下单”。
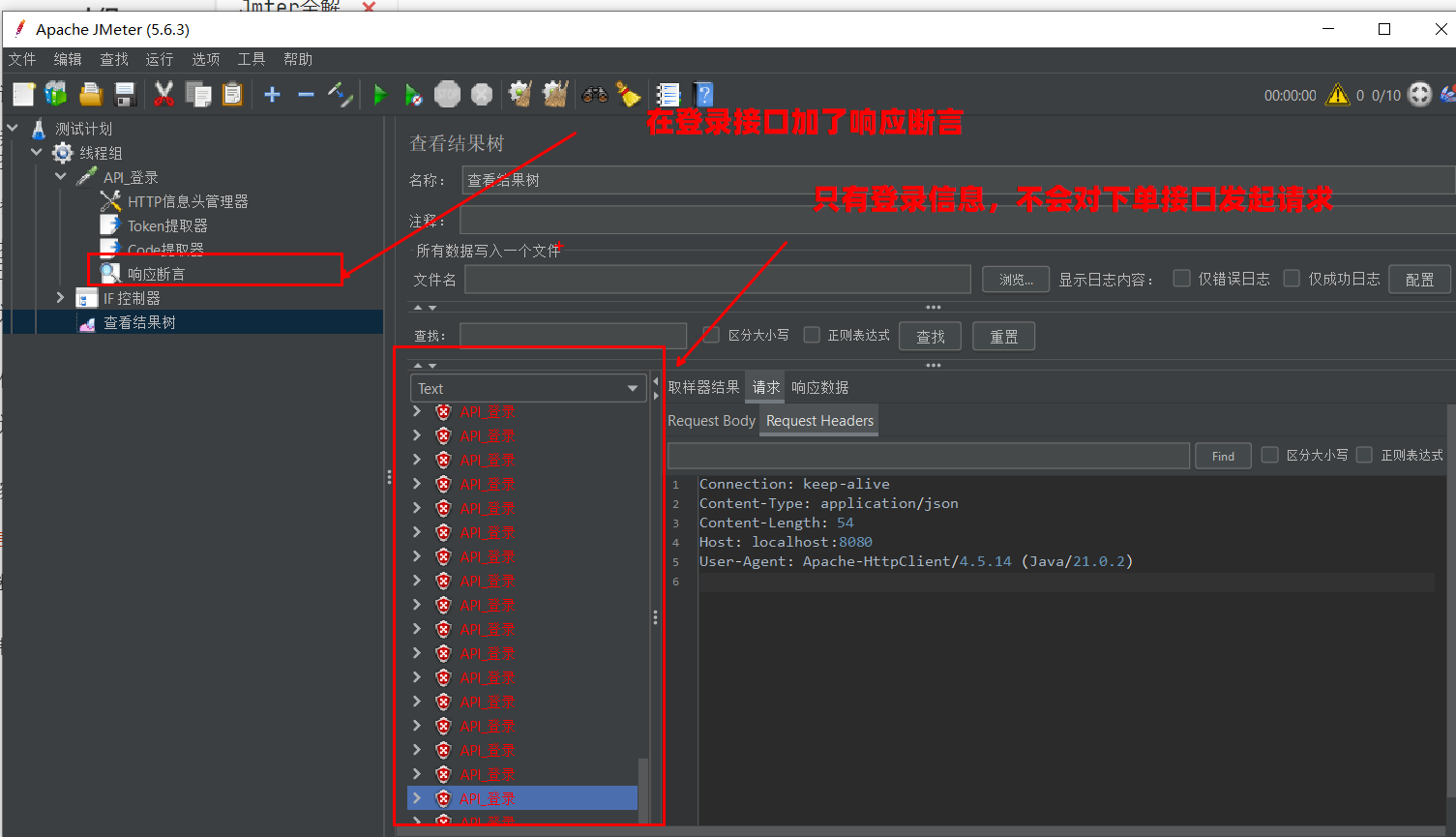
测试 B:反向用例(登录失败)
- 修改登录接口参数为错误的密码(如
admin/error)。 - 运行脚本。
- 观察:
- “API_登录” 执行,但业务码不是 200。
- 关键点:在结果树中,完全看不到 “API_下单” 的记录。
- 这说明 If 控制器成功拦截了请求,脚本实现了智能止损。
5.5. 本章小结
本章我们给脚本赋予了 “判断能力” 和 “决策能力”。
核心要点:
- HTTP 200 不等于成功:压测必须基于业务指标,使用 响应断言 或 JSON 断言 来修正成功率统计。
- 断言选择:简单的文本包含用响应断言;复杂的 JSON 字段校验用 JSON 断言。
- If 控制器:用于构建依赖链路,避免上游失败后下游继续无效执行,节省压测机资源。
下一步计划:目前我们的脚本已经非常健壮了,不仅能传参,还能自动判断对错。但是,它们还只能运行在标准 Java 代码无法解决的逻辑上。比如:“我想对密码进行 RSA 加密后再发送”,或者 “我想直接连数据库清理垃圾数据”。这些需求靠标准组件很难实现。在下一章,我们将解锁 JMeter 的核武器——JSR223 + Groovy 脚本编程。
第六章. 效率与规范:配置元件与作用域详解
摘要:在之前的实战中,我们发现每次创建 HTTP 请求都要手动填写 IP 和端口,且经常因为组件位置放错导致提取失败。本章我们将引入 HTTP 请求默认值 来消除配置冗余,并深入剖析 JMeter 的 作用域(Scope) 和 执行顺序,彻底揭开 “组件该放哪里” 的谜底。
本章学习路径
我们将掌握 JMeter 的高效设计模式:
- 6.1.全局配置战术:一处修改,处处生效
- 6.1.1 用户定义的变量:管理环境常量
- 6.1.2 HTTP 请求默认值:统一连接参数
- 6.1.3 HTTP 信息头管理器:统一通讯契约
- 6.2 深入理解:JMeter 的执行顺序
- 6.2.1 为什么调试取样器之前读不到变量?
- 6.2.2 八大组件的生命周期图谱
- 6.3 核心机制:作用域 (Scope)
- 6.3.1 树状结构:父节点、子节点与兄弟节点
- 6.3.2 HTTP 信息头管理器的合并策略
- 6.4 状态自动管理:HTTP Cookie 管理器
- 6.4.1 像浏览器一样自动处理 Session
- 6.4.2 什么时候不需要手动提取 Token?
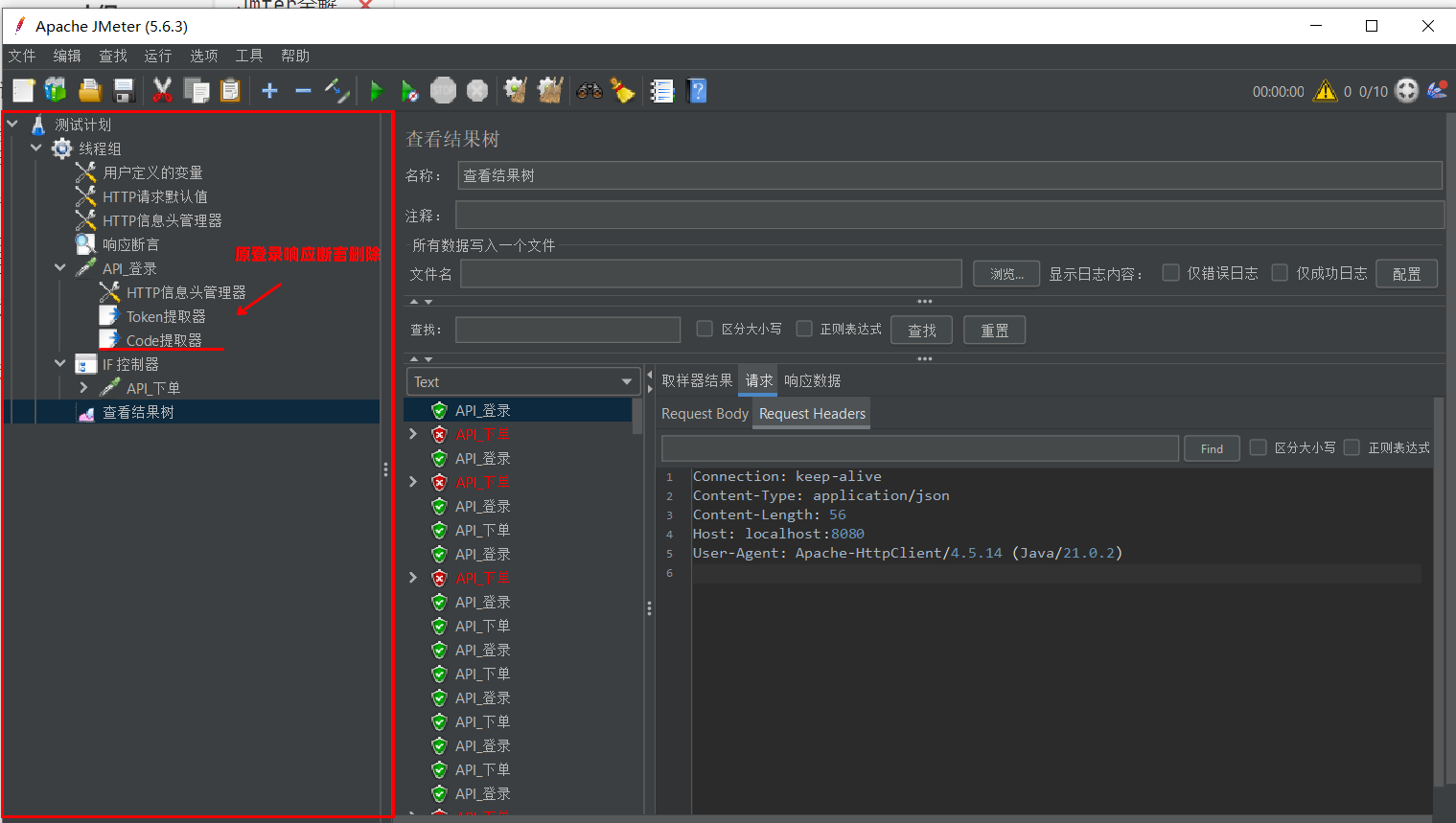
6.1. 全局配置战术:一处修改,处处生效
在之前的实战中,我们发现脚本存在大量的重复配置:每个请求都要填 IP,每个 POST 请求都要填 Header,每个接口都要加断言。这不仅繁琐,一旦后端接口规范调整(比如 Token 名字变了),你需要修改几十个地方。
本节我们将利用 配置元件 (Config Element) 搭建一套标准化的全局配置体系。
6.1.1. 用户定义的变量:管理环境常量
在第 3 章中,我们可能使用了“前置处理器”中的用户参数,但在全局配置场景下,更推荐使用 配置元件 中的 用户定义的变量 (User Defined Variables)。它在测试开始前就会初始化,且对整个线程组生效,性能更好。
操作步骤:
- 右键点击 线程组 -> 添加 -> 配置元件 -> 用户定义的变量。
- 将其拖拽到线程组的 最顶部。
- 添加以下常量:
| 名称 | 值 | 描述 |
|---|---|---|
target_host | localhost | 目标服务器 IP |
target_port | 8080 | 目标端口 |
default_encoding | UTF-8 | 统一编码格式 |
6.1.2. HTTP 请求默认值:统一连接参数
有了变量后,我们需要配置一个“基站”,让所有 HTTP 请求自动继承这些参数。
操作步骤:
- 右键点击 线程组 -> 添加 -> 配置元件 -> HTTP 请求默认值。
- 位置:放在“用户定义的变量”下方,所有 Sampler 上方。
- 配置参数:
- 协议:
http - 服务器名称或 IP:
${target_host} - 端口号:
${target_port} - 内容编码:
${default_encoding}
- 协议:
瘦身行动:现在,请打开你所有的 HTTP 请求(登录、下单等),把里面的 IP、端口、协议全部 清空。脚本瞬间清爽了!
6.1.3. HTTP 信息头管理器:统一通讯契约
前后端分离项目通常强制要求使用 JSON 交互。为了避免在每个 POST 请求里重复添加 Content-Type,我们做一次全局设定。
操作步骤:
- 右键点击 线程组 -> 添加 -> 配置元件 -> HTTP 信息头管理器。
- 位置:与“默认值”平级。
- 添加标头:
- 名称:
Content-Type - 值:
application/json
- 名称:
效果:该线程组下的所有请求都会自动带上这个头。如果某个特殊接口(如文件上传)需要不同的类型,只需在该接口下再加一个信息头管理器,子节点会覆盖父节点。
6.1.4. 全局响应断言:守住质量底线
你提到“不希望在每一个 API 接口下方添加验证”。的确,对于“HTTP 状态码必须为 200”这种通用标准,我们应该配置 全局断言。
操作步骤:
- 右键点击 线程组(注意是点击线程组,不是具体的请求) -> 添加 -> 断言 -> 响应断言。
- 配置参数:
- 测试字段:
响应代码 (Response Code) - 模式匹配规则:
相等 (Equals) - 测试模式:
200
- 测试字段:
原理说明:因为这个断言是直接挂在 线程组 下面的(是所有请求的“叔叔/伯伯”节点,但在作用域逻辑上属于父级作用域),它会对线程组内 每一个 运行的请求生效。
- 优点:一次配置,全员监控。只要有一个接口报 404 或 500,该请求就会被标记为失败。
- 例外:如果某个接口(如“测试错误密码”)预期就是返回 401,你可以使用 作用域 规则,在该请求下添加一个独立的断言来覆盖或补充逻辑。
在最后我们确保一下我们的 JMeter 执行顺序如下:
6.2. 深入理解:JMeter 的执行顺序
在第四章的调试过程中,很多初学者会遇到一个困惑:明明已经添加了提取器,为什么紧挨着的调试取样器读不到变量?
这通常是因为误解了 JMeter 的执行逻辑。JMeter 并不是简单地按照 “从上到下” 的视觉顺序执行,不同类型的组件有着严格的 优先级。
6.2.1. 八大组件生命周期
任何一个 JMeter 取样动作的执行,都严格遵循以下时间轴(优先级从高到低):
- 配置元件 (Config Elements):最先执行。用于初始化环境(如读取 CSV、设置默认值)。
- 前置处理器 (Pre-Processors):在请求发送 前 执行。用于参数加工(如密码加密、生成签名)。
- 定时器 (Timers):在请求发送 前 执行等待。用于模拟思考时间。
- 取样器 (Samplers):核心动作。真正向服务器发送请求。
- 后置处理器 (Post-Processors):在请求结束 后 执行。用于提取响应数据(如 JSON 提取器)。
- 断言 (Assertions):在提取完成后执行。用于验证结果。
- 监听器 (Listeners):最后执行。用于记录和展示结果。
6.2.2. 案例复盘
让我们用这个规则来解释第四章的 “调试取样器 (Debug Sampler)” 问题。
错误场景:
1 | 1. 调试取样器 (Debug Sampler) |
执行流程分析:
- JMeter 遇到 调试取样器(属于 Sampler)。由于它上面没有前置处理器,直接执行。此时," API_老旧接口 " 还没跑,提取器当然也没跑,所以变量不存在。
- JMeter 遇到 API_老旧接口(属于 Sampler),执行请求。
- 请求结束后,触发挂载的 正则表达式提取器(属于 Post-Processor),此时变量
legacy_sess才被创建。
修正场景:
1 | 1. API_老旧接口 (HTTP Request) |
修正后的流程:
- 先跑 " API_老旧接口 "。
- 跑完后触发提取器,生成变量。
- 再跑 调试取样器,此时它就能读取到内存中已存在的变量了。
6.3. 核心机制:作用域 (Scope)
除了 “时间顺序”,JMeter 还有 “空间范围”,也就是 作用域。这决定了组件对哪些请求生效。JMeter 的测试计划是一个 树状结构,遵循 “父子继承,兄弟隔离” 的规则。
6.3.1. 树状法则
我们以 HTTP 信息头管理器(用于设置 Content-Type)为例:
场景 A:全局生效(父节点作用域)
1 | Thread Group |
- 效果:该管理器是两个 API 的 兄弟节点(但在逻辑上属于线程组的子节点,作用于线程组内所有 Sampler)。因此,“登录” 和 “下单” 都会自动带上 JSON 头。
场景 B:局部生效(子节点作用域)
1 | Thread Group |
- 效果:该管理器是 " API_登录 " 的 子节点。它只对 " 登录 " 生效。" 下单 " 接口不会携带该请求头。
6.3.2. 合并策略 (Merge)
如果父节点配置了 Header,子节点也配置了 Header,会发生什么?
规则:
- 不同 Key:累加。
- 相同 Key:子节点覆盖父节点。
示例:
- 全局配置:
Authorization: None - 局部配置(在 " API_下单 " 下):
Authorization: Bearer xyz - 最终结果*:“API_下单” 发送时,
Authorization的值为Bearer xyz。
- 最终结果*:“API_下单” 发送时,
6.4. 状态自动管理:HTTP Cookie 管理器
在之前的章节中,我们通过 JSON 提取器手动获取 Token 并传递。这适用于现代的 JWT(无状态)架构。但对于传统的 Web 应用(如基于 JSP、Thymeleaf 的 Spring Boot 项目),服务器通常使用 JSESSIONID Cookie 来识别用户。
对于这种场景,JMeter 提供了一个 “作弊神器”,能让它像浏览器一样自动管理 Session。
6.4.1. 像浏览器一样工作
浏览器有一个特性:一旦服务器返回了 Set-Cookie 响应头,浏览器会自动保存,并在访问同一个域名的后续请求中自动带上 Cookie 头。
JMeter 默认是 无状态 的(不保存 Cookie)。要开启这个功能,只需添加一个组件。
操作步骤:
- 右键点击 线程组 -> 添加 -> 配置元件 -> HTTP Cookie 管理器。
- 配置:通常保持默认即可(它会自动遵循标准的 Cookie 策略)。
- 位置:建议放在 线程组顶部,使其对所有请求生效。
6.4.2. 效果验证
一旦添加了 HTTP Cookie 管理器,你就不再需要编写正则表达式去提取 JSESSIONID 了。
工作流程:
- API_登录 执行,响应头包含
Set-Cookie: JSESSIONID=A1B2...。 - Cookie 管理器 自动捕获并将其存储在当前线程的内存中。
- API_下单 执行时,Cookie 管理器自动检测到目标域名匹配,将
Cookie: JSESSIONID=A1B2...注入请求头。
如果你的应用是前后端分离且使用 Token (Header) 鉴权:使用 JSON 提取器 + 信息头管理器。
如果你的应用是传统 Web 且使用 Cookie/Session 鉴权:使用 HTTP Cookie 管理器。
6.5. 本章小结
本章我们从 “写脚本” 进化到了 “设计脚本”,解决了很多初学者 “懂发请求但不懂配置” 的痛点。
核心要点:
- DRY 原则:善用 HTTP 请求默认值,避免在几十个接口中重复修改 IP 和端口。
- 执行流水线:牢记 “配置 -> 前置 -> 动作 -> 后置 -> 断言” 的生命周期,这是排查 “变量取不到” 或 “断言失效” 的根本依据。
- 作用域法则:
- 想要全局生效,就放在线程组下一级。
- 想要局部生效,就挂在具体请求的下面。
- 子节点的配置会覆盖父节点(同名覆盖,异名累加)。
- Cookie 管理器:测试传统 Web 应用时,它是自动处理 Session 的神器,能节省大量提取代码。
下一步计划:现在的脚本结构已经非常规范了。但目前的压测行为更像是 “机器人”——以固定的频率、没有任何停顿地发送请求。而真实的用户在点击之前会有 “思考时间”,在抢购时会有 “瞬间并发”。在下一章,我们将引入 定时器 (Timers),让压测流量无限逼近真实世界。
第七章. 流量仿真:定时器与高阶控制器
摘要:在前面的章节中,我们的脚本像一个不知疲倦的机器人,以毫秒级的速度连续发送请求。但这与真实用户的行为背道而驰,且无法测试出“线程安全”等深层问题。本章我们将引入 定时器 来还原用户的“思考时间”,利用 同步定时器 制造绝对并发来检测 Spring Boot 的锁机制,并通过 高阶控制器 封装复杂的业务逻辑。
本章学习路径
我们将从“仿真”的角度出发,把脚本从“发包工具”升级为“用户模拟器”:
- 7.1 还原真实用户:定时器 (Timers)
- 7.1.1 并发数 $\neq$ 压力:思考时间的重要性
- 7.1.2 统一随机定时器:模拟自然波动
- 7.2 制造绝对洪峰:同步定时器
- 7.2.1 压力测试 vs 并发测试的区别
- 7.2.2 集合点实战:击穿数据库库存
- 7.2.3 避免死锁:Timeout 参数的最佳实践
- 7.3 业务视角封装:事务控制器
- 7.3.1 技术指标 vs 业务指标
- 7.3.2 “Generate parent sample” 深度解析
- 7.4 复杂逻辑编排:循环控制器
- 7.4.1 场景:轮询支付状态
- 7.4.2 线程循环 vs 控制器循环的区别
7.1. 还原真实用户:定时器 (Timers)
在上一章中,我们解决了配置冗余的问题。但在实际运行中,你可能会发现:明明设置了 100 个线程,为什么服务器的 CPU 瞬间就飙升到 100% 然后报错?而生产环境 1000 个在线用户却很平稳?
这是因为你忽略了 “思考时间” (Think Time)。
7.1.1. 核心概念:并发数与 TPS 的关系
在性能测试领域,有一个著名的公式:
$$TPS = \frac{并发用户数}{响应时间 + 思考时间}$$
- 机器人的行为:响应时间 100ms,思考时间 0ms。
$$TPS = 1 / 0.1 = 10$$ (单线程每秒发 10 个请求) - 真实用户的行为:响应时间 100ms,思考时间 3000ms(用户看完页面再点)。
$$TPS = 1 / 3.1 \approx 0.3$$ (单线程每 3 秒才发 1 个请求)
结论:如果不加定时器,100 个 JMeter 线程产生的压力,可能相当于 3000 个真实用户的压力。为了让测试结果具备参考价值,我们必须模拟这种“停顿”。
7.1.2. 实战:统一随机定时器 (Uniform Random Timer)
JMeter 提供了“固定定时器”,但在现实中,没有哪两个用户的思考时间是完全一秒不差的。为了模拟更自然的流量波动,我们推荐使用 统一随机定时器。
场景设计:用户登录成功后,浏览商品详情页,随机停留 1~3 秒,然后点击下单。
操作步骤:
- 展开 API_下单 请求。
- 右键点击 API_下单 -> 添加 -> 定时器 -> 统一随机定时器。
- 配置参数:
- Random Delay Maximum (随机延迟最大值):
2000 - Constant Delay Offset (固定延迟偏移):
1000
- Random Delay Maximum (随机延迟最大值):
原理解析:
$$总等待时间 = 固定偏移 + random(0, 随机最大值)$$
代入数值:$1000 + [0, 2000] = 1000ms \sim 3000ms$。这样的设置既保证了用户至少会看 1 秒(固定值),又模拟了手速的快慢差异(随机值)。
7.2. 制造绝对洪峰:同步定时器
在上一节,我们通过随机定时器让流量变得平滑。但在某些特殊场景——例如“秒杀”、“抢红包”——我们需要反其道而行之,制造瞬间的压力洪峰。
7.2.1. 压力测试 vs 并发测试
- 压力测试:考察系统在高负载下的稳定性(如 CPU 是否打满,GC 是否频繁)。
- 并发测试:考察系统对 共享资源 的抢占处理(如数据库锁、线程安全)。
普通的 JMeter 压测,线程是陆续启动的,很难在 微秒级 做到绝对同时请求。如果你的 Spring Boot 代码中有 stock = stock - 1 这种非原子操作,普通压测可能测不出 Bug,但上线就会超卖。
这时我们需要 同步定时器 (Synchronizing Timer),也就是 LoadRunner 中的 集合点 (Rendezvous Point)。
7.2.2. 实战:击穿库存
假设我们要测试 Spring Boot 的库存扣减逻辑。
操作步骤:
- 在 API_下单 的子节点下,添加 同步定时器。
- 配置参数:
- Number of Simulated Users to Group by:
50 - Timeout in milliseconds:
3000
- Number of Simulated Users to Group by:
执行逻辑:
- 线程启动后,运行到“下单”步骤时,会被定时器拦截并挂起。
- JMeter 会一直等待,直到积攒了 50 个被挂起的线程。
- 一旦达到 50 个,定时器瞬间释放,50 个请求在同一毫秒内涌向服务器。
- 这就构成了对数据库行锁的 绝对并发竞争。
7.2.3. 避免死锁:Timeout 的重要性
场景演示:假设你的线程组只设置了 30 个线程,但同步定时器要求集合 50 人。
- 结果:前 30 个线程到达集合点后开始等待第 31 人,但永远等不到。脚本会陷入 无限等待(死锁),进度条永远卡住。
最佳实践:永远不要把 Timeout 设置为 0(0 代表无限等待)。务必设置一个合理的超时时间(如 3000ms)。如果 3 秒内凑不齐 50 人,JMeter 会强制释放已到达的线程,继续执行后续步骤,避免脚本卡死。
7.3. 业务视角封装:事务控制器
在 JMeter 的默认报告中,我们看到的都是单个接口的耗时(登录 50ms,下单 80ms)。但产品经理通常会问:“用户完成一次购买流程需要多久?”。
简单的相加是不准确的,因为中间可能包含重定向、定时器等待等时间。我们需要 事务控制器 (Transaction Controller)。
7.3.1. 配置事务
操作步骤:
- 右键点击 线程组 -> 添加 -> 逻辑控制器 -> 事务控制器。
- 将 API_登录 和 API_下单(及其附属组件)全部拖拽到事务控制器内部。
- 关键配置:
- Generate parent sample (生成父样本):必须勾选。
- Include duration of timer (包含定时器耗时):根据需求勾选。
- 如果测的是 用户体验:勾选(用户觉得卡顿是包含了思考时间的)。
- 如果测的是 系统处理能力:不勾选(只统计服务器纯处理时间)。
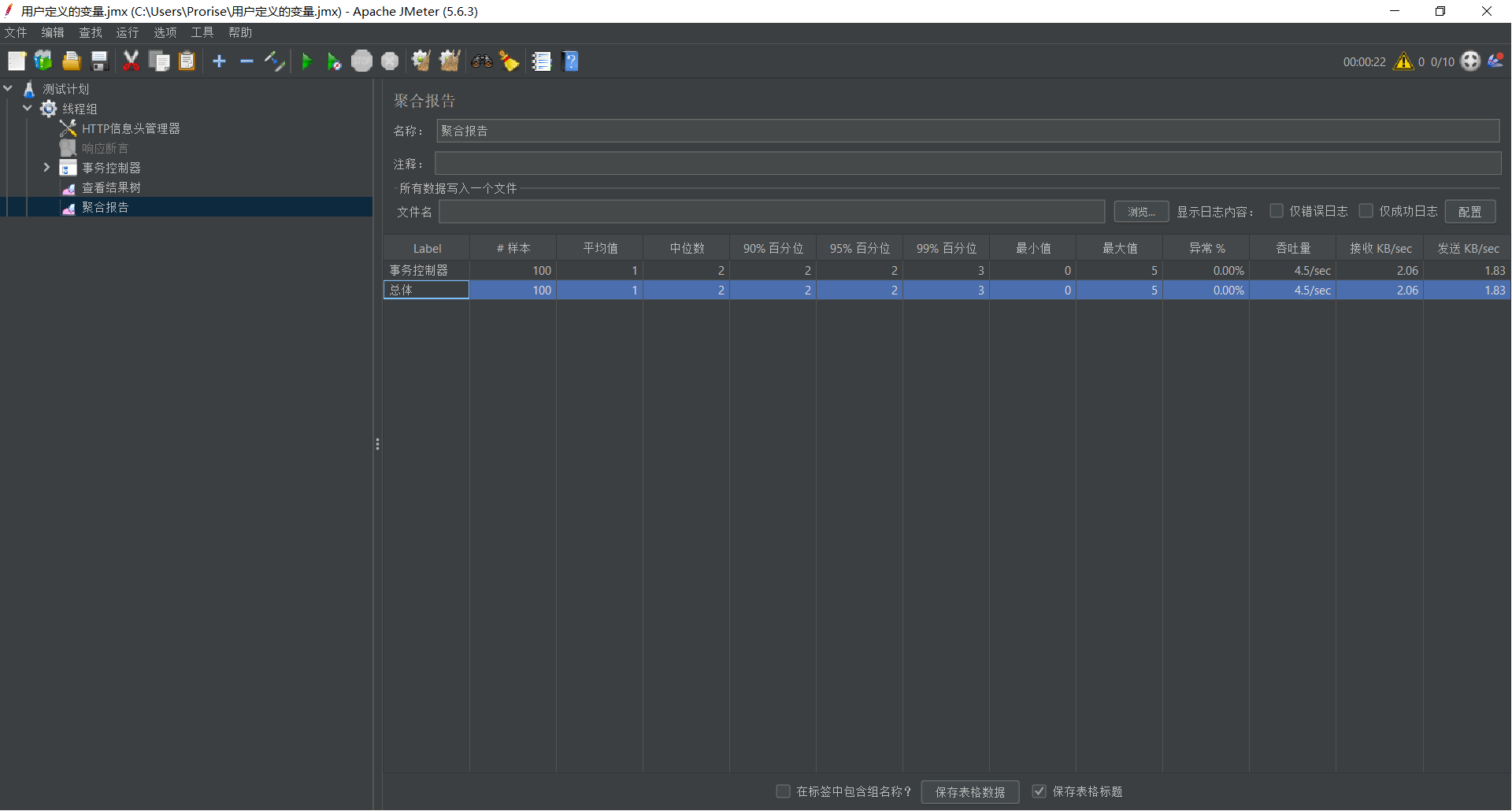
7.3.2. 数据解读
运行测试后,查看聚合报告。
- 未勾选 Generate parent sample:你会看到三个条目——“API_登录”、“API_下单”、“事务控制器”。数据比较杂乱。
- 勾选 Generate parent sample:你会看到一个合并后的条目 “事务控制器”,原来的子接口被隐藏了。此时的 TPS 和 RT 指标,反映的就是完整的“购买业务”的处理能力。
7.4. 复杂逻辑编排:循环控制器
并不是所有的业务都是“线性”的(登录 -> 下单 -> 结束)。在支付场景中,往往存在“轮询”机制:前端每隔 1 秒查询一次后端状态,直到支付成功或超时。
7.4.1. 实战:轮询支付状态
我们需要在脚本中模拟:“下单成功后,每隔 1 秒查询一次订单状态,共查询 5 次”。
操作步骤:
- 在 线程组 中添加 逻辑控制器 -> 循环控制器 (Loop Controller)。
- 配置参数:
- Loop Count (循环次数):
5。
- Loop Count (循环次数):
- 在循环控制器内部添加:
- HTTP 请求:
GET /api/order/status。 - 固定定时器:
1000ms。
- HTTP 请求:
7.4.2. 线程循环 vs 控制器循环
这是初学者最容易混淆的概念:
- 线程组的 Loop Count:决定了 整个剧本 演多少遍。
- 如果设为 10,意味着“登录 -> 下单 -> 轮询”这全套流程做 10 遍。
- 循环控制器的 Loop Count:决定了 剧本中某一个小节 重复多少遍。
- 如果设为 5,意味着在每一遍剧本中,“查询状态”这个动作要重复 5 次。
通过组合使用,我们可以构建出非常复杂的业务模型:1次登录 -> 5次浏览 -> 1次下单 -> 3次查询状态。
7.5. 本章小结
本章我们为脚本注入了“灵魂”,使其从简单的接口调用工具进化为复杂的用户行为模拟器。
核心要点:
- 思考时间:必须使用 定时器 模拟用户停顿,否则压测结果中的 TPS 会虚高,无法代表真实负载。
- 作用域:定时器挂在谁下面,就只影响谁。切忌在线程组层级随意添加定时器。
- 绝对并发:使用 同步定时器 模拟秒杀场景,这是检测 Spring Boot 线程安全问题的杀手锏,但切记设置 Timeout 防止死锁。
- 事务统计:使用 事务控制器 聚合多个接口,勾选 Generate parent sample 获取清晰的业务级性能报告。
速查配置:
- 统一随机定时器:Offset = 固定等待,Max = 随机波动。
- 同步定时器:Timeout 不要设为 0。
下一步计划:至此,我们已经彻底掌握了 JMeter 的 GUI 组件(配置、请求、断言、定时器、控制器)。但在面对一些极度复杂的场景(如:RSA 动态签名、自定义 Redis 操作、复杂的数据清洗)时,GUI 界面已经无法满足需求了。下一章,我们将解锁 JMeter 的终极能力——Groovy 脚本编程,真正实现“为所欲为”的测试。
第八章. JSR223 与 Groovy:JMeter 的核武器
摘要:在前面的章节中,我们通过鼠标点选 GUI 组件完成了大部分任务。但真实业务往往比这复杂得多:比如接口需要 “MD5 加密签名”、需要 “AES 解密响应”、或者需要把数据 “写入本地 Excel”。面对这些需求,GUI 界面束手无策。本章我们将解锁 JMeter 的 JSR223 组件配合 Groovy 语言,让你拥有直接编写代码操控压测逻辑的能力。
本章学习路径
我们将从面板认知开始,一步步掌握脚本编程:
- 8.1 认识 JSR223 组件
- 8.1.1 JSR223 是什么?为什么不是 BeanShell?
- 8.1.2 面板功能区详解(入口与配置)
- 8.2 Groovy 语言速成(面向 Java 开发者)
- 8.2.1 为什么它是 JMeter 的御用语言
- 8.2.2 核心语法差异:丢掉分号与类型
- 8.3 JMeter 的四大内置对象
- 8.3.1
log:你的调试眼睛 - 8.3.2
vars:变量的搬运工 - 8.3.3
props与ctx:跨线程与上下文(了解)
- 8.3.1
- 8.4 实战:手写 MD5 加密前置处理器
- 8.4.1 引入 Java 工具类
- 8.4.2 编写并调试加密脚本
- 8.5 实战:自定义数据写入后置处理器
- 8.5.1 文件流操作
- 8.5.2 将订单号落盘保存
8.1. 认识 JSR223 组件
在 “添加” 菜单中,你会发现很多带有 “脚本” 字样的组件,最著名的就是 BeanShell 和 JSR223。请记住一句话:在 2025 年,请彻底遗忘 BeanShell,只用 JSR223 + Groovy。
8.1.1. 核心概念:Interface vs Language
- JSR223:这是一个 Java 规范(Java Specification Request 223),它定义了一个标准接口,允许 Java 程序调用各种脚本语言(如 Python, Ruby, Groovy)。在 JMeter 中,它是一个 容器。
- Groovy:这才是我们要写的 语言。它完全兼容 Java 语法,但更简洁。
- 为什么要用它?
- BeanShell 是解释执行的,性能极差(并发一高就会卡死)。
- Groovy 支持 “编译缓存”,JMeter 会把它编译成原生的
.class字节码运行,性能几乎等同于原生 Java。
8.1.2. 面板功能区详解
让我们先找到并打开这个组件。
操作步骤:
- 右键点击 线程组 -> 添加 -> 取样器 (Sampler) -> JSR223 取样器。
- 你会看到如下界面,我们需要关注三个核心区域:
关键配置项说明:
- Language (语言):
- 必须选择
groovy。千万不要选java或beanshell,否则无法享受性能优化。
- 必须选择
- Cache compiled script if available (缓存编译脚本):
- 必须勾选。这是性能起飞的关键。勾选后,这段代码只会被编译一次,之后 100 万次循环都直接运行机器码。
- Script (脚本编辑区):
- 这里就是我们写代码的地方。虽然它像个记事本,没有代码提示,但它支持标准的 Java/Groovy 语法。
8.2. Groovy 语言速成
对于已经掌握 Spring Boot 的你来说,学习 Groovy 是 “零成本” 的。因为 任何合法的 Java 代码都是合法的 Groovy 代码。
你可以直接在脚本区写 System.out.println("Hello");,它是能跑的。但 Groovy 提供了一些 “语法糖”,让代码更简洁。
8.2.1. 核心语法差异表
| 特性 | Java 写法 | Groovy 写法 (推荐) | 优势 |
|---|---|---|---|
| 分号 | String name = "Jack"; | String name = "Jack" | 可以省略分号,代码更干净。 |
| 类型定义 | String id = "123"; | def id = "123" | 使用 def 自动推断类型,类似 JS 的 let。 |
| 字符串插值 | "ID is " + id | "ID is ${id}" | 使用双引号 + ${} 直接拼接变量。 |
| Get/Set | user.getName() | user.name | 自动调用 getter/setter 方法。 |
建议:作为初学者,为了避免出错,你完全可以 直接写标准的 Java 代码。等你熟练了,再尝试 Groovy 的简化写法。
8.3. JMeter 的四大内置对象
在 Script 编辑区写代码时,JMeter 已经默默地往这一小块空间里注入了几个 “上帝对象”。你不需要 new,直接就能用。
8.3.1. log:你的调试眼睛
在 GUI 界面写代码没有断点调试,我们只能靠打印日志来观察变量。
- 代码:
1
2log.info("这是普通信息");
log.error("这是报错信息"); - 查看位置:点击 JMeter 界面右上角的 黄色感叹号图标,底部会弹出一个控制台窗口,你的日志就显示在那里。
8.3.2. vars:变量的搬运工(最重要)
vars 是 JMeterVariables 类的实例。它连接了 GUI 组件 和 代码世界。
读取变量(从 GUI -> 代码):假设你在 “用户定义的变量” 中定义了
target_host。1
String ip = vars.get("target_host"); // 获取变量值
写入/修改变量(从 代码 -> GUI):假设你想把计算好的结果传给下一个 HTTP 请求。
1
vars.put("new_token", "xwq89-sdsd-223"); // 创建名为 new_token 的变量
8.4. 实战 A:前置处理器 - 攻克 MD5 签名校验
在真实的企业级开发中,为了防止请求被篡改,后端往往要求前端对核心参数进行加密签名。例如:注册接口要求密码必须传输 32 位 MD5 密文,如果传输明文直接报错。
JMeter 的 GUI 组件没有自带 MD5 加密功能,这时候就轮到 JSR223 前置处理器大显身手了。
8.4.1. 第一步:改造靶场(制造困难)
为了模拟这个场景,我们需要先在 Spring Boot 项目中增加一个“强制校验 MD5”的注册接口。
文件路径:src/main/java/com/demo/jmeterdemo/controller/AuthController.java
请在 AuthController 类中追加以下代码:
1 | /** |
操作提醒:
- 粘贴代码后,请重启 Spring Boot 项目。
- 确保控制台无报错,端口 8080 正常监听。
8.4.2. 第二步:遭遇失败(复现问题)
我们先尝试用常规方式去请求,看看会发生什么。
- 在 JMeter 线程组下新建一个 HTTP 请求,命名为 " API_注册 "。
- Method:
POST - Path:
/api/auth/register - Body Data:
1
2
3
4{
"username": "admin",
"password": "123456"
} - 运行测试,查看 察看结果树。
- 响应结果:
{"code":400, "msg":"Security Error: Password must be MD5 encrypted!"} - 分析:后端校验生效,传输明文 “123456” 被拒绝。我们需要在发送请求 之前,把 “123456” 变成 MD5 密文。
- 响应结果:
8.4.3. 第三步:脚本编程(JSR223 救场)
我们需要使用 前置处理器 (PreProcessor),它的执行时机是在 HTTP 请求发送 之前。
操作流程:
修改 Body:将明文密码替换为变量占位符。
1
2
3
4{
"username": "admin",
"password": "${md5_pwd}"
}(注:变量
${md5_pwd}目前还不存在,我们马上用代码生成它)添加组件:右键点击 " API_注册_成功 " -> 添加 -> 前置处理器 -> JSR223 预处理程序。
配置面板:
- 语言:选择
groovy(必须!)。 - 缓存:勾选
Cache compiled script if available。
- 语言:选择
编写 Groovy 脚本:
请在 Script 编辑区输入以下代码。这段代码利用了 JMeter 自带的 commons-codec 库,这是 Java 处理加密的标准姿势。
1 | // 1. 导入加密工具类 (JMeter 自带,无需下载 jar 包) |
8.4.4. 第四步:全链路验证(闭环检查)
脚本写好了,能不能跑通?我们需要检查三个地方。
操作步骤:
- 打开日志监视器:点击 JMeter 右上角的黄色感叹号图标(或菜单栏 选项 -> 日志查看器),清空旧日志。
- 运行脚本:点击启动按钮。
- 检查点 1:看日志
- 观察下方控制台,是否输出了
加密结果: e10adc3949ba59abbe56e057f20f883e? - 如果有,说明 Groovy 代码运行正常,加密逻辑成功。
- 观察下方控制台,是否输出了
- 检查点 2:看请求体 (Request Body)
- 在 察看结果树 中选中 " API_注册_成功 "。
- 点击 请求 (Request) 选项卡 -> Request Body。
- 观察
password字段:"password": "e10adc3949ba59abbe56e057f20f883e"。 - 说明
vars.put生效了,变量成功替换了占位符。
- 检查点 3:看响应 (Response)
- 点击 响应数据 (Response Data)。
- 看到
{"code":200, "msg":"Register Success"}。 - 说明后端校验通过。
通过这四步,我们完整实现了一个 “Java 加密 -> JMeter 变量 -> HTTP 请求” 的数据流转。
8.5. 实战 B:后置处理器 - 核心数据落盘保存
在压测过程中,我们经常需要把生产出来的数据(比如:注册成功的用户名、下单成功的订单号)保存下来,作为下一轮压测的输入数据,或者发给其他部门进行对账。
JMeter 的 “保存响应到文件” 组件功能很弱(只能存整个响应),要想灵活地只存一个 ID,必须使用 JSR223 后置处理器。
8.5.1. 第一步:确认数据源
我们要保存的是 下单接口 返回的 orderId。
- 确保你已经有了 " API_下单 " 接口(参考第 5 章)。
- 确保该接口下挂载了 JSON 提取器。
- 变量名称:
orderId - JSON 路径:
$.orderId
- 变量名称:
8.5.2. 第二步:编写落盘脚本
我们需要在提取出 orderId 之后,把它写入电脑的硬盘里。
操作步骤:
- 右键点击 " API_下单 " -> 添加 -> 后置处理器 -> JSR223 后置处理程序。
- 注意顺序:它必须放在 “JSON 提取器” 的 下方(因为要先提取,再写入)。
- 配置面板:语言选
groovy,勾选缓存。
编写 Groovy 脚本:
1 | // 1. 从 JMeter 变量池获取 OrderID |
8.5.3. 第三步:验证数据落盘
代码写得再漂亮,文件里有数据才是硬道理。
验证流程:
- 清理环境:如果
D:/jmeter_orders.csv已经存在,建议先手动删除它,确保我们看到的是新的。 - 运行脚本:设置线程组循环 5 次,点击启动。
- 观察 JMeter:
- 查看日志窗口,应该有 5 条
成功保存订单ID: xxxx的记录。 - 确保没有红色的
写入文件失败报错。
- 查看日志窗口,应该有 5 条
- 检查硬盘文件:
- 打开
D:/盘(或你设置的路径)。 - 找到
jmeter_orders.csv,用记事本打开。 - 预期结果:应该看到 5 行不同的数字 ID。
- 打开
1 | 1731988888123 |
如果能看到这个文件,恭喜你,你已经掌握了用 JMeter 处理复杂数据流的核心技能。
8.6. 本章小结
本章我们跨越了 GUI 的边界,进入了代码的领域。这是从中级测试工程师迈向高级的关键一步。
核心要点:
- 工具链:坚决使用 JSR223 + Groovy,配合 Cache 选项,性能是 BeanShell 的百倍。
- 调试法:脚本是看不见摸不着的,必须依赖
log.info()打印关键变量,通过日志控制台来 “透视” 运行过程。 - 数据流:
- GUI -> 代码:
vars.get("key") - 代码 -> GUI:
vars.put("key", "value")
- GUI -> 代码:
- 安全性:在进行文件读写等高危操作时,务必进行 判空校验 (null check) 和 异常捕获 (try-catch),防止因为一条脏数据导致整个测试中断。
第九章. 可视化监控体系:InfluxDB + Grafana
摘要:在之前的测试中,我们一直依赖 JMeter 自带的 GUI 监听器(如聚合报告)查看结果。这种方式有两个致命缺点:一是 GUI 消耗资源大,不适合高并发;二是无法实时查看 TPS 趋势图。本章我们将搭建 JMeter + InfluxDB + Grafana 黄金链路,抛弃丑陋的静态报告,打造好莱坞大片级别的实时监控大屏。
本章学习路径
我们将按照 “数据生产 -> 数据存储 -> 数据展示 -> 数据解读” 的闭环进行掌握:
- 9.1 监控架构演进
- 9.1.1 为什么要抛弃 GUI 报告?
- 9.1.2 JIG 架构解析 (JMeter + InfluxDB + Grafana)
- 9.2 部署监控基础设施
- 9.2.1 方案 A:Docker Compose 一键部署(推荐)
- 9.2.2 方案 B:Windows 原生安装
- 9.3 配置 JMeter 后端监听器
- 9.3.1 Backend Listener 核心配置
- 9.3.2 关键参数:
summaryOnly与percentiles
- 9.4 配置 Grafana 大屏
- 9.4.1 数据源配置
- 9.4.2 导入官方经典模板 (ID: 5496)
- 9.5 深度解读:像医生一样看大屏 (新增)
- 9.5.1 顶部导航与全局概览:掌握压测节奏
- 9.5.2 核心指标仪表盘:一秒判断生死
- 9.5.3 趋势图与错误分析:定位性能拐点
9.1. 监控架构演进
9.1.1. 痛点分析
在此前的章节中,我们依靠 “聚合报告” 看数据。但在真实压测中,它有三大罪状:
- 资源黑洞:GUI 监听器会将所有结果保存在内存中。如果压测持续 1 小时,积攒的百万条数据会直接把 JMeter 客户端撑爆(OOM)。
- 后知后觉:你只能在压测结束后看到平均值,无法看到压测过程中的 “抖动”(比如第 5 分钟突然发生了 TPS 暴跌)。
- 数据孤岛:无法与服务器的 CPU/内存监控图表放在一起对比。
9.1.2. JIG 架构解析
为了解决上述问题,业界通用的方案是 JIG:
- JMeter (生产者):负责施压。它不再把数据留在内存,而是通过 Backend Listener 异步地把精简后的统计数据 “推” 出去。
- InfluxDB (存储者):一个高性能的 时序数据库,专门用来存这种带时间戳的监控数据。
- Grafana (展示者):一个颜值极高的数据可视化平台,从 InfluxDB 读数据,画成炫酷的图表。
9.2. 部署监控基础设施
为了降低学习成本,我们推荐使用 Docker 快速搭建。如果你没有 Docker 环境,也可以选择原生安装,如果您不熟悉 docker,可转至
9.2.1. 方案 A:Docker Compose 一键部署
如果你是 Spring Boot 开发者,本地应该有 Docker Desktop。
操作步骤:
- 在任意目录创建一个
docker-compose.yml文件。 - 粘贴以下内容(使用 InfluxDB 1.8 版本,因为 JMeter 对 1.x 协议支持最原生,配置最简单):
1 | version: '3' |
- 在终端执行命令:
1
docker-compose up -d
- 验证:访问
http://localhost:3000能看到 Grafana 登录页(默认账号密码admin/admin),说明部署成功。
9.2.2. 方案 B:Windows 原生安装(备选)
如果不使用 Docker,你需要分别下载软件。
- InfluxDB:下载 v1.8.10 windows 二进制包 -> 解压 -> 运行
influxd.exe。 - Grafana:下载 Windows Installer -> 安装 -> 启动服务。
(注:为了教学流畅性,后续演示基于 Docker 环境,端口均为默认)
9.3. 配置 JMeter 后端监听器
基础设施搭建完毕,现在要配置 JMeter 往数据库里 “推” 数据。
9.3.1. 添加 Backend Listener
操作步骤:
- 打开你的 JMeter 脚本(建议使用包含 " API_登录 " 和 " API_下单 " 的脚本)。
- 右键点击 线程组 -> 添加 -> 监听器 -> 后端监听器 (Backend Listener)。
- 位置:放在线程组的最下方,或者测试计划的最外层(监听所有线程组)。
9.3.2. 核心参数配置
在后端监听器面板中,请依次完成以下核心参数的配置:
- Backend Listener implementation
1 | org.apache.jmeter.visualizers.backend.influxdb.InfluxdbBackendListenerClient |
选择 InfluxDB 协议客户端,这是连接的基础。
- influxdbUrl
1 | http://localhost:8086/write?db=jmeter |
数据写入地址。其中 db=jmeter 对应我们在 Docker 中预先创建的数据库名称。
- application
1 | SpringBoot_App_Test |
应用名称。该字段用于标识当前的压测项目,后续在 Grafana 中可以通过这个名字筛选出特定项目的监控数据。
- measurement
1 | jmeter |
InfluxDB 中的表名(Measurement),通常保持默认即可。
- summaryOnly
1 | false |
关键配置! 该选项默认为 false, 他使得 JMeter 记录每一个 Request 的详细数据,Grafana 才能依据这些数据绘制出精细的明细图表。
- percentiles
1 | 90;95;99 |
配置我们关心的百分位性能指标(如 TP90、TP95、TP99)。
验证配置:
点击启动 JMeter。虽然界面上看不到任何弹窗提示,但此时 JMeter 已经开始默默地通过 UDP/HTTP 协议向 localhost:8086 发送数据包了。
9.4. 配置 Grafana 大屏
最后一步,把数据画出来。
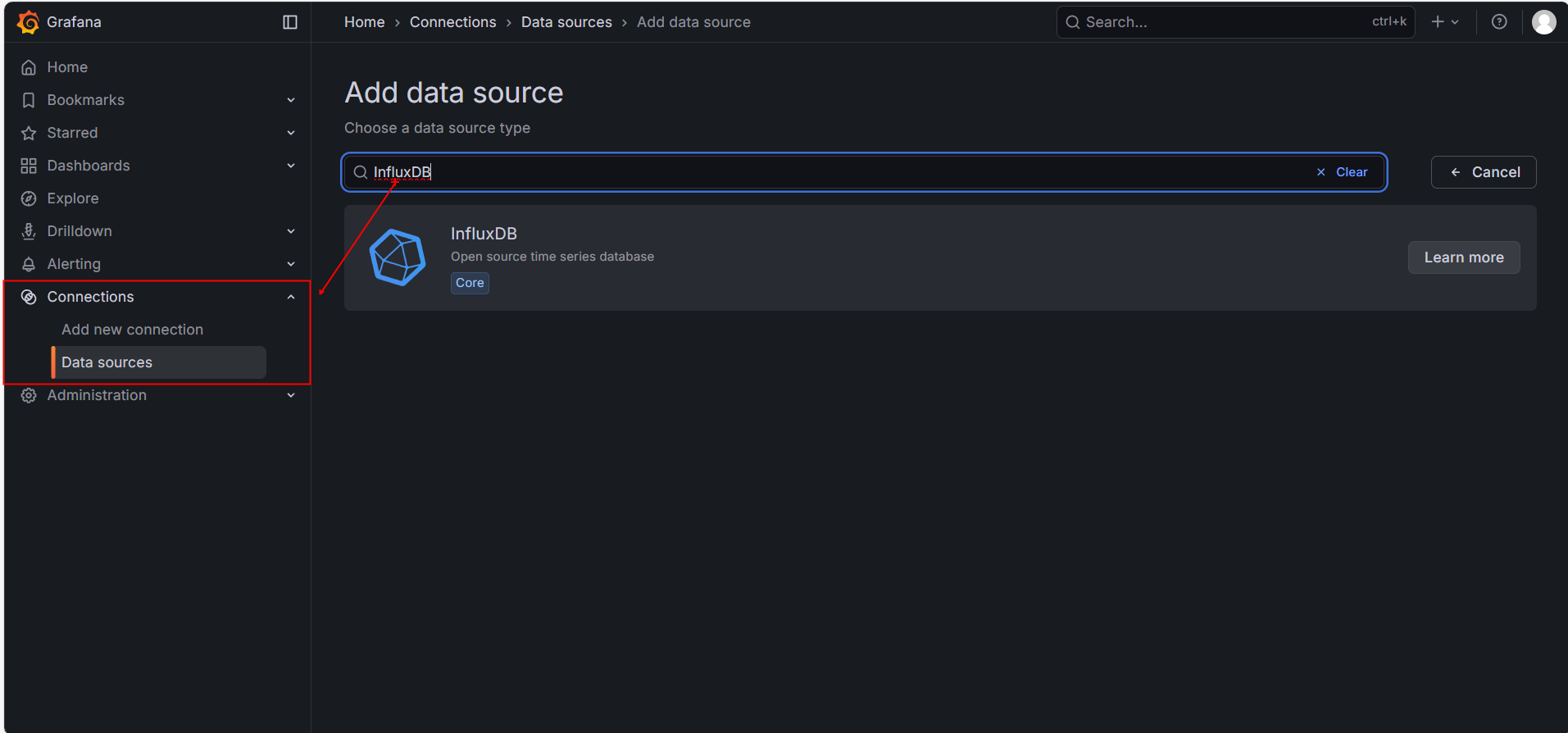
9.4.1. 配置数据源 (Data Source)
- 浏览器打开 http://localhost: 3000 ,登录 Grafana,用户名: admin,密码: admin
- 点击左侧齿轮图标 -> Data Sources -> Add data source。
- 选择 InfluxDB。
- 配置详情:
- URL:
http://influxdb:8086(如果你用 Docker) 或http://localhost:8086(如果你是原生安装)。 - Database:
jmeter。
- URL:
- 点击底部 Save & Test。如果显示绿色的 “Data source is working”,说明连接成功。
9.4.2. 导入炫酷模板
我们不需要自己一个一个画图,社区已经有大神做好了完美的模板。
- 点击 Grafana 左侧加号图标 -> Import。
- 在 Import via grafana.com 输入框中,填入 ID:5496。
- (注:模板 5496 是最经典的 JMeter Dashboard,由 Apache 官方推荐)
- 点击 Load。
- 在底部的 DB name 下拉框中,选择刚才创建的
InfluxDB数据源。 - 点击 Import。
9.4.3. 实战:见证奇迹的时刻
现在,屏幕上应该出现了一个空的大屏。让我们让它动起来。
- 回到 JMeter。
- 调整线程组:设置 50 个线程,循环 “永远”(或设置一个很大的循环次数),持续运行 5 分钟。
- 点击 启动。
- 回到 Grafana 浏览器页面,右上角选择刷新频率为
5s。
你将看到:
- Total Requests:请求数像里程表一样疯狂跳动。
- Active Users:显示当前在线的 50 个用户。
- Response Times (TR):平滑的曲线展示着 TP99 和 TP90 的波动。
- Throughput (TPS):绿色的线代表成功 TPS,红色的线代表失败 TPS。
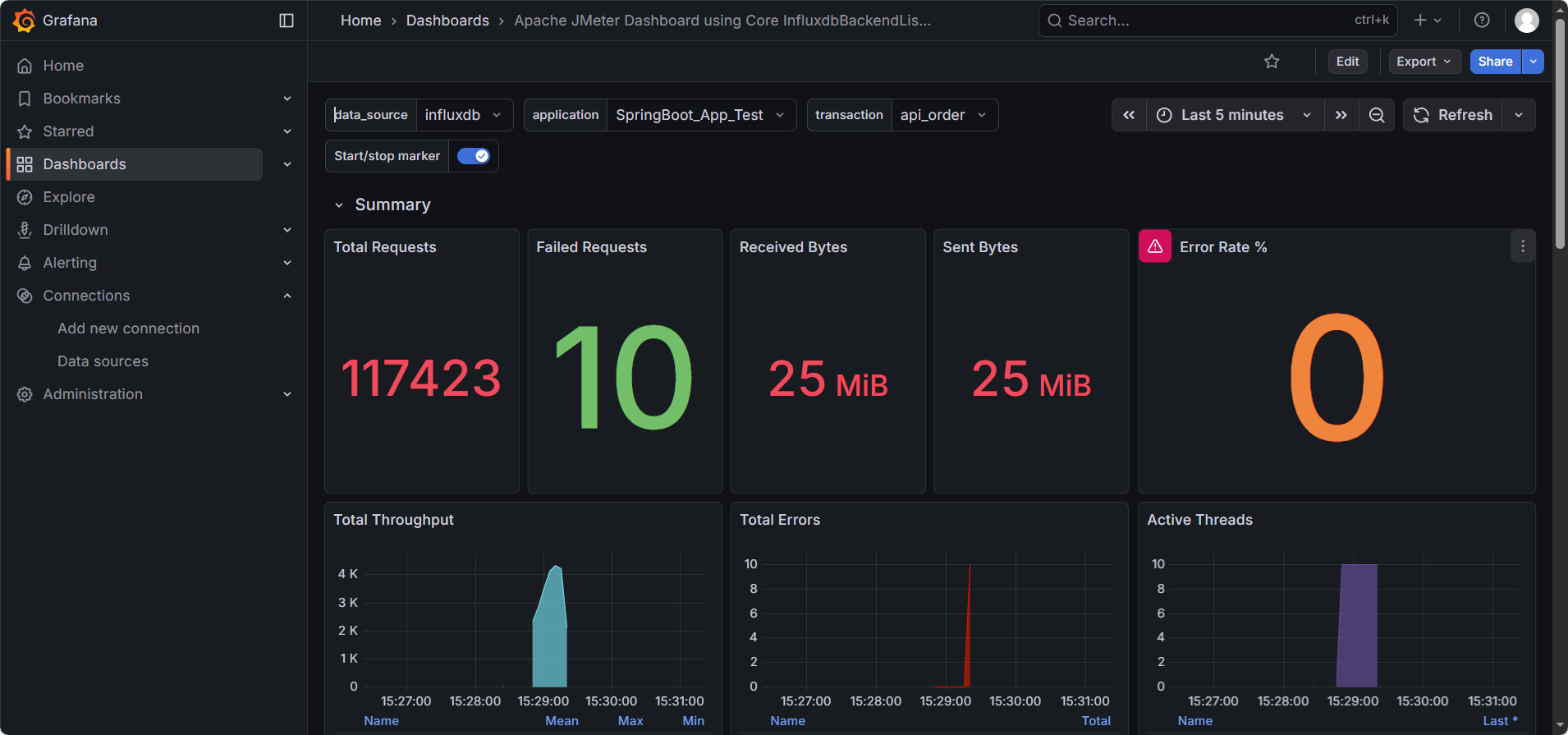
最佳实践:在这一刻,你可以把 “察看结果树” 和 “聚合报告” 都禁用了。在大规模压测中,我们只需要盯着 Grafana 的这个大屏,就能掌握一切。
9.5. 深度解读:像医生一样看大屏
大屏跑起来了,但如果看不懂数据的含义,它就只是一张漂亮的壁纸。为了精准定位性能瓶颈,我们需要学会正确地使用 Grafana 的分区功能。
我们将遵循 “顶层筛选 -> 局部诊断 -> 异常排查 -> 全局总结” 的逻辑,带你读懂每一个像素。
9.5.1. 驾驶舱:顶栏与折叠技巧
首先看屏幕最顶部的控制条,这是你的 “驾驶舱”。
1. 核心筛选器 (Filters)
- application: 对应 JMeter 后端监听器中配置的
application名。用于切换不同的压测项目。 - transaction (最关键):
- 默认是
all:显示所有接口的混合数据。 - 最佳实践:排查问题时,请务必切换到具体的接口(如
api_order)。因为 “登录” 的快可能会掩盖 “下单” 的慢,混合看数据容易产生误判。
- 默认是
- Time Range: 右上角的时间选择器。压测时建议选
Last 5 minutes,并开启Refresh 5s。
2. 分区折叠技巧
Grafana 的信息量很大,为了避免干扰,建议先利用行标题左侧的 小箭头 (>) 将所有分区折叠起来,只展开你需要关注的区域。
9.5.2. 局部诊断:Individual Transaction (独立分区)
这是我们最先要关注的地方。请在顶栏 transaction 选择 api_order,然后展开 Individual Transaction - api_order 分区。这里展示了单一接口的健康状况。
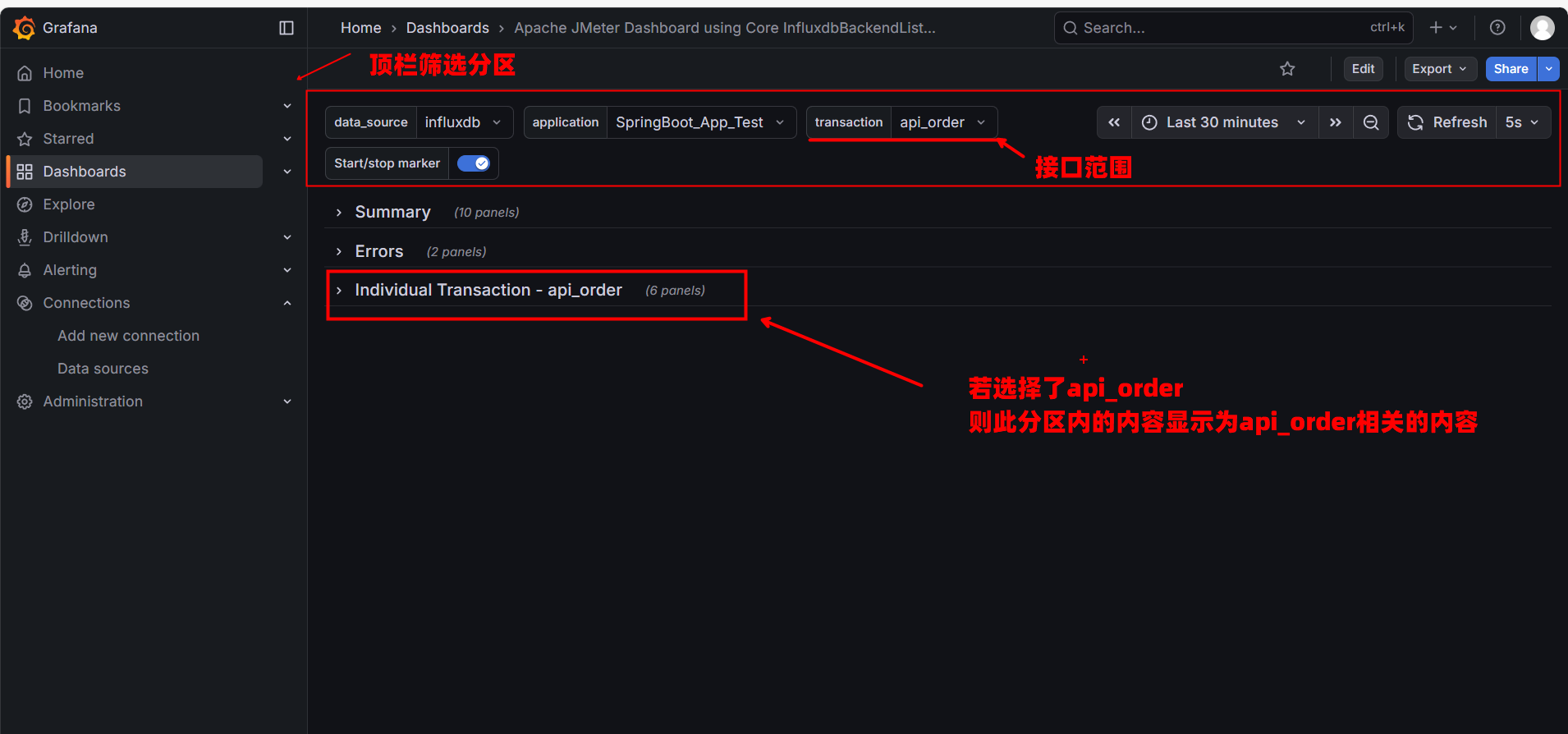
1. 核心仪表盘 (Dashboard)
- Total Requests: 该接口的请求总量。
- Failed Requests: 该接口的失败数量。
- Error Rate %: 红线指标。如果这里不是 0,说明该业务功能有 Bug 或服务器已崩溃。
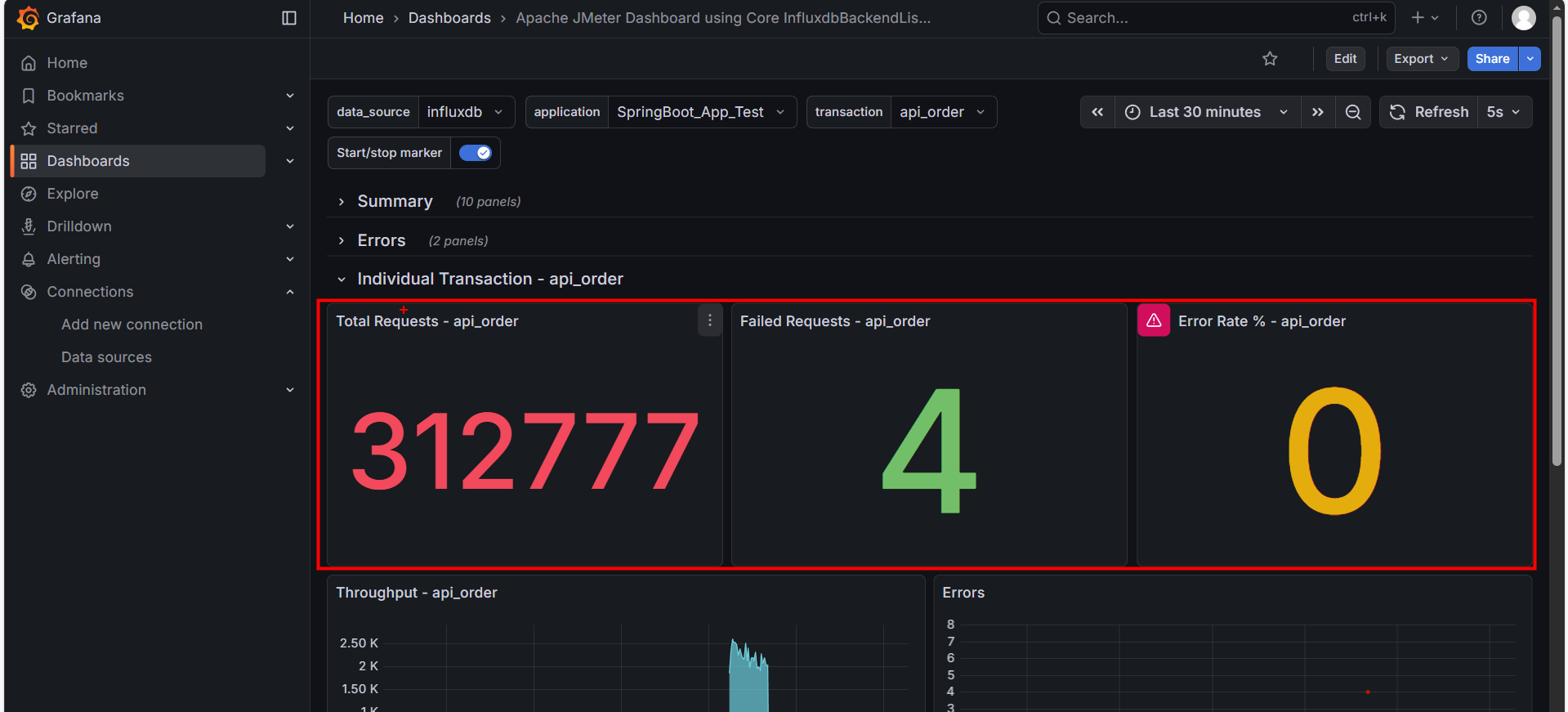
2. 吞吐量趋势 (Throughput)
- 蓝色面积图:表示每秒处理成功的请求数 (TPS)。
- 健康形态:应该随着线程数的增加而平滑上升,最后趋于稳定。
- 病态形态:如果图像出现剧烈的 “断崖式下跌”,说明系统发生了阻塞(如数据库锁死)。
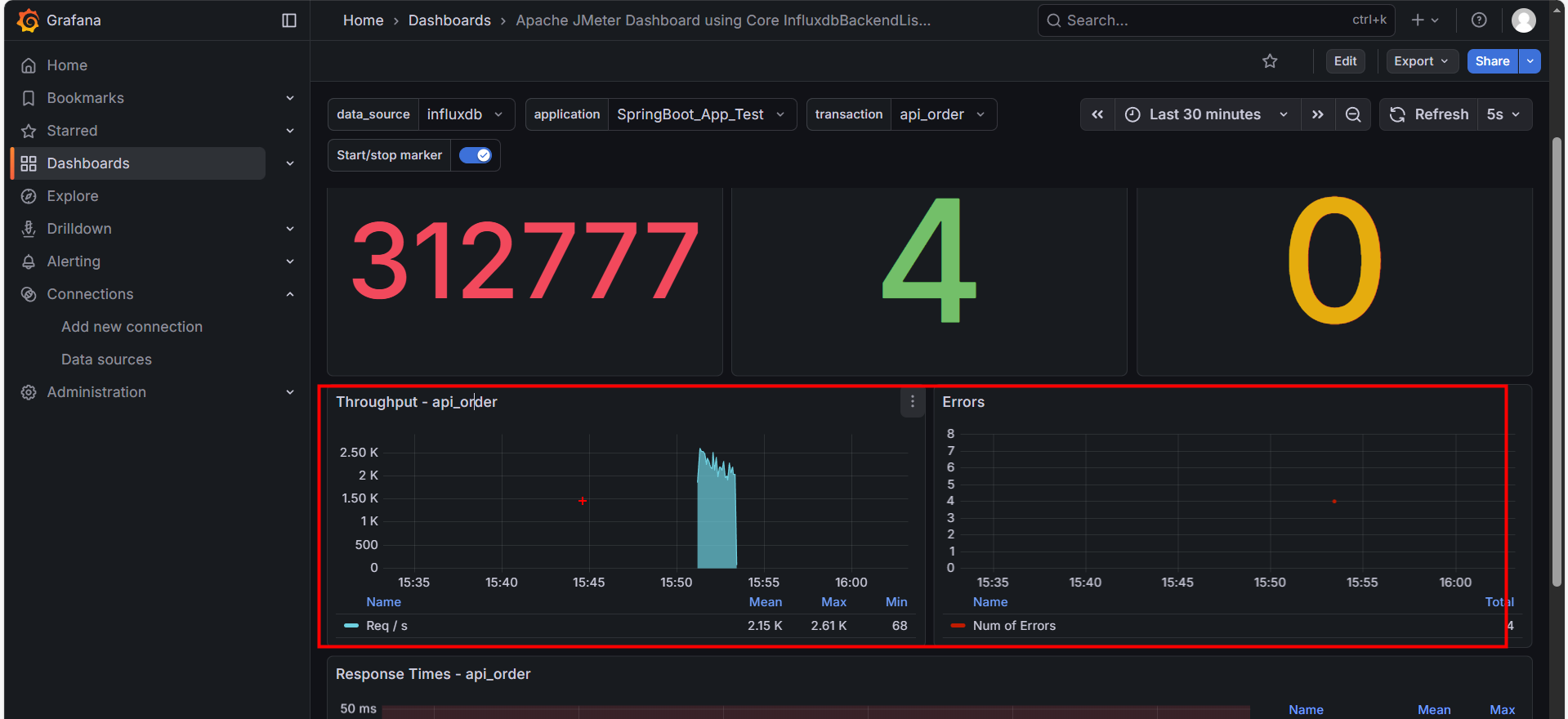
3. 响应时间 (Response Times)
这是判断性能拐点的核心图表。注意图中的几条线:
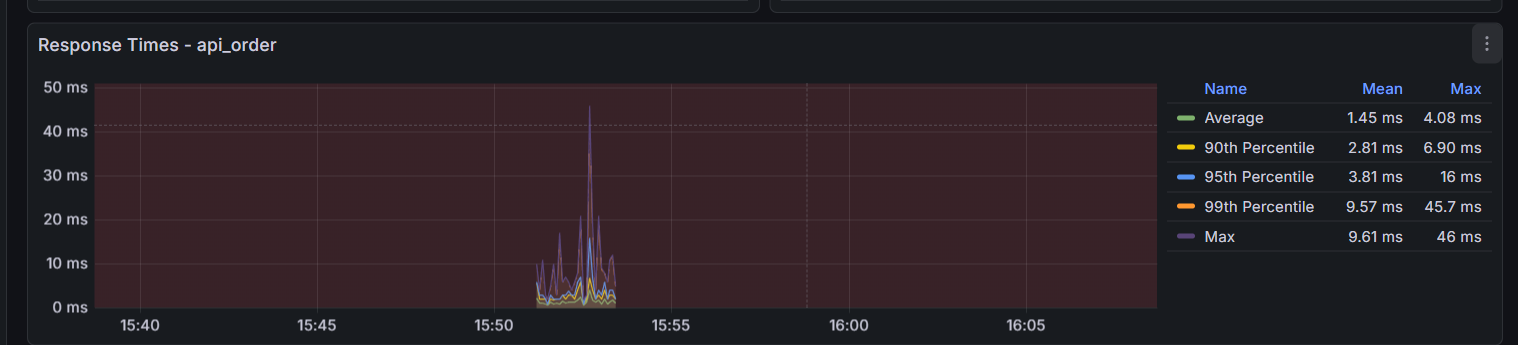
- Green (Mean): 平均响应时间。不要只看它,它具有欺骗性,假设马云和 9 个穷人在一起,平均资产是“人人都是亿万富翁”。在性能测试中,如果 99 个请求是 1ms,有 1 个请求卡死用了 10000ms(10 秒),平均时间 大约是 100ms。你看着 100ms 觉得“还行啊”,但那个卡死 10 秒的用户已经卸载你的 App 了。
黄线 (90th Percentile):第 90 名的成绩。
- 含义:意味着 90% 的用户,响应时间都 快于 这个数值。
蓝线 (95th Percentile):第 95 名的成绩。
- 含义:意味着 95% 的用户,体验都好于这个数值。这是业界最常用的 SLA (服务等级协议) 标准。如果老板问“我们系统慢不慢”,你就看这条线。
橙线 (99th Percentile):第 99 名的成绩。
- 含义:这条线代表了 系统的“短板”。如果这条线很高(例如飙升到 3 秒),说明偶尔会有用户遇到严重的卡顿。
Purple (Max): 最大响应时间。如果这条紫线偶尔飙升到几秒,说明存在 “长尾效应”(如 Full GC 停顿)
- 如果紫线紧贴着橙线(像图中医院):说明系统 极其稳定,没有奇怪的卡顿。
- 如果紫线偶尔 像针一样刺向天空(例如突然飙到 5000ms),而其他线很低:说明系统有 **“毛刺” **。
- 常见原因:Java 的垃圾回收 (Full GC) 卡顿、网络抖动、数据库死锁。
9.5.3. 异常分析:Errors (错误分区)
如果 Error Rate 变红了,我们需要立刻展开 Errors 分区来查明原因。
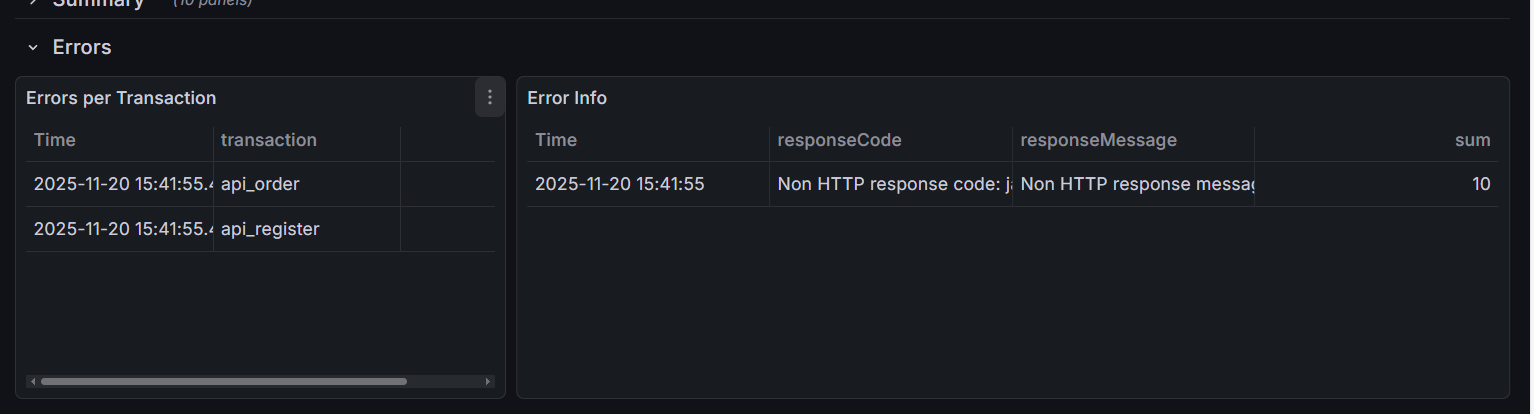
1. 错误分布表 (Errors per Transaction)
左侧表格告诉你 “谁错了”。是所有接口都挂了(可能是网关问题),还是只有 api_order 挂了(代码逻辑问题)。
2. 错误详情表 (Error Info)
右侧表格告诉你 “为什么错”。
- Response Code 500: 服务端内部错误(空指针、数据库连接失败)。
- Response Code 502/504: 网关超时。说明后端处理太慢,Nginx 等不及了。
特别注意:JMeter 强制停止导致的误报
如果你在压测过程中点击了 JMeter 的 “STOP” (强制停止) 按钮,Grafana 上可能会突然出现一批错误,报错信息通常为:
Non HTTP response code: java.net.SocketExceptionSocket closed
原因:JMeter 暴力断开了连接,导致 InfluxDB 记录了网络异常。
判断方法:如果这些错误仅出现在 压测结束的那一秒,请直接忽略它们,这属于 “人工误报”。
9.5.4. 全局总结:Summary (总结分区)
最后,我们展开最上方的 Summary 分区。这是给老板看 “最终成绩单” 的地方。
1. 宏观计数器
- Total Requests: 整个压测期间的总发包量。
- Error Rate %: 全局错误率。互联网应用通常要求小于 0.01%。
2. 网络流量 (Received/Sent Bytes)
- 作用:判断带宽瓶颈。
- 分析:如果你的 TPS 上不去,CPU 也很闲,但这里显示 Sent/Received 达到了几十 MB/s(接近千兆网卡极限),说明 带宽被打满了。这是很多新手容易忽略的硬件瓶颈。
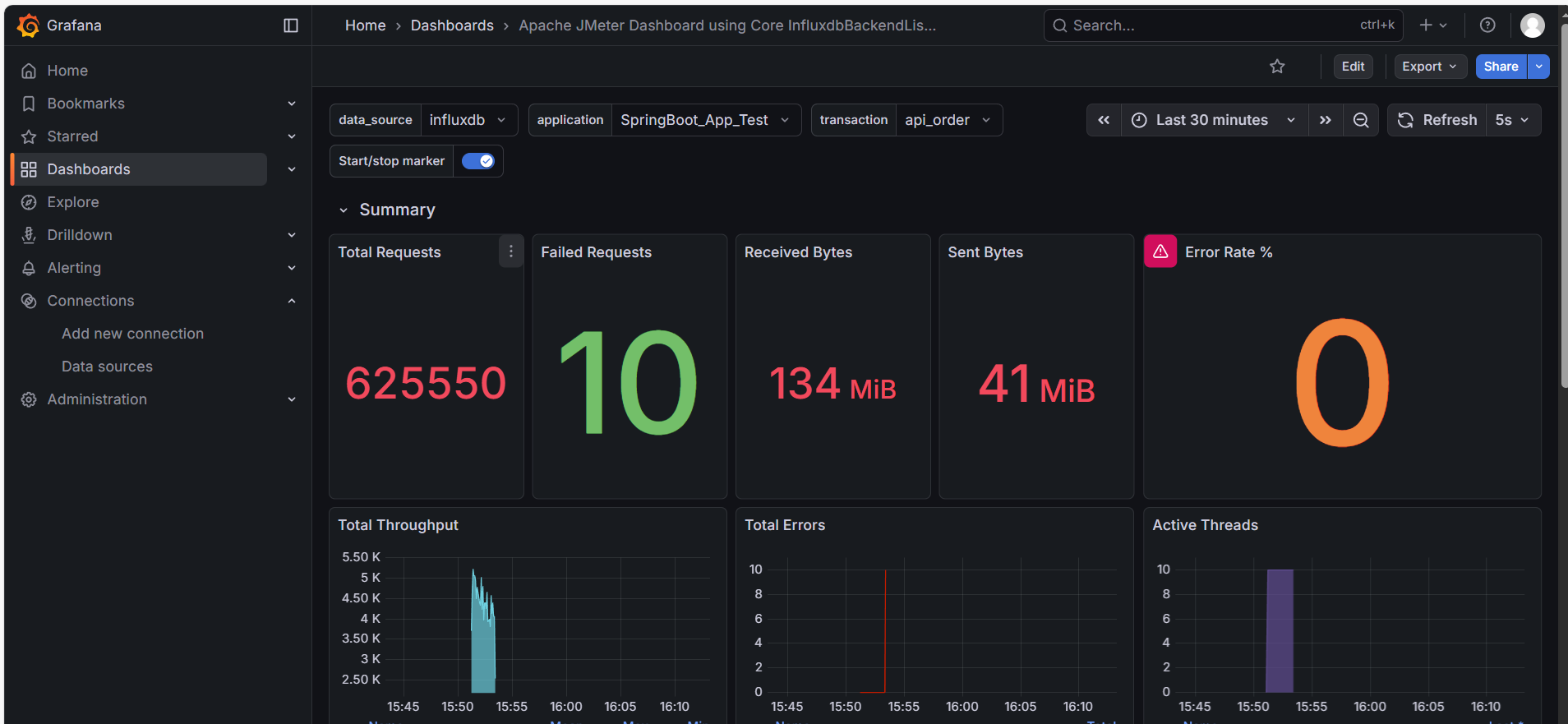
3. 活跃线程数 (Active Threads)
- 右下角的紫色柱状图。它展示了并发用户的爬升过程(Ramp-up)。
- 如果线程数突然 “腰斩”,说明 JMeter 客户端可能因为内存溢出(OOM)而崩溃了。
9.6 本章小结
本章我们搭建了专业的 JIG 监控链路,并学会了如何解读 Grafana 大屏。
核心要点:
- 架构优势:JMeter + InfluxDB + Grafana 彻底解决了 GUI 消耗资源大、无法回溯历史数据的问题。
- 看图逻辑:遵循 “筛选接口 -> 局部诊断 -> 查错 -> 全局总结” 的顺序,避免被海量数据淹没。
- 误报识别:压测结束时的
Socket closed错误通常是强制停止导致的,可忽略。 - 瓶颈判断:结合 TPS 曲线、P99 响应时间和网络带宽,综合定位是软件问题还是硬件限制。
第十章. 自动化压测:从命令行到代码化
摘要:在之前的九章中,我们依赖 GUI 界面完成了所有的学习与调试。但在真正的生产级实战中,GUI 是性能的杀手,XML 脚本是维护的噩梦。作为全系列的最终章,我们将跨越 “点点点” 的初级阶段,掌握 CLI 命令行压测 的标准姿势,并引入 JMeter-DSL,让作为 Spring Boot 开发者的你,用最熟悉的 Java 代码来定义压测逻辑,实现真正的工程化交付。
本章学习路径
- 10.1 摆脱 GUI 束缚:专家级 CLI 压测
- 10.1.1 “观测者效应”:为什么必须抛弃 GUI?
- 10.1.2 命令行解剖学:五大核心参数详解
- 10.1.3 成果验收:原生 HTML 报告解读
- 10.2 降维打击:JMeter as Code (DSL)
- 10.2.1 XML 的痛点与 DSL 的崛起
- 10.2.2 实战:用 Java 重写压测逻辑
- 10.2.3 运行与集成:像单元测试一样跑压测
10.1. 摆脱 GUI 束缚:专家级 CLI 压测
在之前的章节中,我们一直沉浸在 JMeter 舒适的图形界面(GUI)里。但在真正的企业级生产环境中,GUI 模式是绝对的禁区。本节我们将完成从 “玩具” 到 “工具” 的质变。
10.1.1. 为什么必须抛弃 GUI?(原理层)
在性能测试领域,存在一个著名的 “观测者效应”:当你观察系统时,你的观察行为本身会干扰系统。
对于 JMeter 而言,GUI 模式就是那个干扰源:
- 资源抢占:JMeter 的图形界面(Swing)需要消耗大量的 CPU 来绘制实时图表,同时消耗大量内存(Heap)来存储临时数据。
- 性能瓶颈:当并发数超过 500 时,往往服务器还没挂,JMeter 客户端先卡死了。
- 环境限制:Linux 服务器通常没有显示器,根本无法启动 GUI。
结论:GUI 只用于 编写和调试脚本;正式压测必须使用 CLI (Command Line Interface) 模式。
10.1.2. 命令行解剖学:五大核心参数
在终端中驱动 JMeter,你需要熟练组合以下五个参数。
标准命令模板:
1 | jmeter -n -t [脚本文件.jmx] -l [结果文件.jtl] -e -o [报告目录] |
参数详解:
-n(Non-GUI)- 含义:核心开关。明确告诉 JMeter 不要启动图形界面。
- 后果:如果不加此参数,在无界面的服务器上会直接报错退出。
-t(Test Plan)- 含义:指定 “作战蓝图”,即你在 GUI 中保存的
.jmx脚本文件路径。 - 注意:路径中严禁包含空格,否则可能识别失败。
- 含义:指定 “作战蓝图”,即你在 GUI 中保存的
-l(Log/Result File)- 含义:指定数据存储位置。JMeter 会将每一次请求的详细数据写入这个文件。
- 铁律:该文件必须不存在! 如果文件已存在,JMeter 默认会停止运行(防止覆盖历史数据)。
-e(Export to Dashboard)- 含义:压测结束后,自动触发 HTML 报告生成器。
-o(Output Folder)- 含义:指定 HTML 报告的产出目录。
- 铁律:该目录必须为空!
10.1.3. 成果验收:原生 HTML 报告解读
执行命令后,进入输出目录双击 index.html,你会看到 JMeter 原生的 Dashboard Report。这里有两个核心指标必须读懂:
1. APDEX (应用性能指数)
在 Dashboard 左上角的仪表盘,这是一个国际通用的用户满意度评分(0.0 ~ 1.0)。
- > 0.94 (Excellent):用户非常满意。
- < 0.50 (Unacceptable):用户无法忍受,系统不可用。
2. Statistics (统计摘要表)
在页面下方的表格中,关注以下列:
- Error %:错误率(底线指标)。
- 99th pct (P99):核心指标。例如 P99 = 2000ms,意味着 99% 的用户都在 2 秒内得到了响应,只有 1% 的长尾用户遭遇了慢请求。
10.2. 降维打击:JMeter as Code (DSL)
在上一节中,我们学会了用命令行执行 .jmx 脚本。但维护那个几千行的 XML 文件简直是噩梦。本节我们将引入 JMeter-Java-DSL,让作为 Spring Boot 开发者的你,用最熟悉的 Java 代码 来编写压测脚本。
10.2.1. XML 的痛点与 DSL 的崛起
JMeter 原生的 .jmx 本质上是 XML。虽然它对机器友好,但对人类极度不友好:
- 版本控制地狱:Git Diff 无法看懂 XML 的变动。
- 无法复用:很难把 “登录逻辑” 提取成一个通用方法。
解决方案:JMeter-Java-DSL
这是一个开源库,它封装了 JMeter 的底层 API,允许我们用 流式风格 (Fluent Style) 的 Java 代码来定义测试计划。压测脚本从此变成了项目代码的一部分。
10.2.2. 实战:用 Java 重写压测逻辑
我们需要创建一个 Maven 模块,并引入 jmeter-java-dsl 依赖。
代码实现:
我们将之前 “50 并发下单” 的逻辑翻译成 Java 代码:
1 | package com.demo.jmeterdemo; |
代码解析:
threadGroup:替代了 GUI 的线程组。httpSampler:替代了 HTTP 请求,支持链式调用.header()。.children():体现了 JMeter 的树状结构,将断言和定时器挂载在请求下方。
10.2.3. 运行与集成
如何运行?
这就和运行普通的单元测试一样简单。在 IDE 中点击 Run,或者在命令行执行 mvn test。
结果查看:运行结束后,查看项目目录下的 target/jmeter-reports 文件夹,你将看到生成的 index.html 报告和 report.jtl 数据文件。这意味着,你再也不用手动传递 .jmx 文件了,代码即脚本,所见即所得。
10.3. 本章小结与全系列回顾
随着代码的运行和报告的生成,我们的 JMeter 深度之旅也即将画上句号。
10.3.1. 本章核心要点
- CLI 是底线:正式压测请务必使用
jmeter -n -t ...,这是保证数据准确性的前提。 - DSL 是未来:对于 Java 开发者,使用 JMeter-DSL 能极大提升脚本的可维护性,并让压测无缝融入 Maven/Gradle 工程体系。
- 报告三要素:无论是 CLI 还是 DSL,最终交付的一定是标准的 HTML 报告,关注 Error % 和 P99 即可快速判断系统健康度。
10.3.2. 全系列课程总结
我们从第一章的 Spring Boot 环境搭建 开始,一路解锁了 JMeter 的核心技能树:
- 基础篇:掌握了线程组、取样器、断言的基本用法,打通了测试闭环。
- 进阶篇:攻克了参数化、关联、逻辑控制等复杂业务场景,学会了模拟真实用户行为。
- 高阶篇:利用 JSR223 + Groovy 突破了 GUI 的限制,利用 InfluxDB + Grafana 实现了实时监控。
- 终极篇:通过 CLI 和 DSL,将压测工程化、代码化。
虽然课程体系非常扎实,但如果要说“精通整个 JMeter”,不得不承认我们在以下三个方面仍存在盲区(这也是由我们的决定的,属于合理的教学取舍):
- 非 HTTP 协议:JMeter 其实支持 JDBC (直连数据库)、MQTT (物联网)、WebSocket、TCP 等协议。我们的课程 100% 聚焦于 HTTP/REST API。如果读者遇到 WebSocket 聊天室压测,他们需要通过查阅文档迁移知识。
- 分布式集群部署:虽然我们讲了 CLI,但真正的万级并发需要配置 Master-Slave 分布式集群(涉及 RMI 通信、防火墙配置等)。这部分运维属性较重,课程中并未涉及深层配置。
- 系统调优:我们教了“如何发现慢”,但没教“如何解决慢”。比如发现 Full GC 了该怎么调 JVM 参数,发现死锁了怎么改代码。这属于架构师领域,超出了 JMeter 工具本身的范畴。
最后的建议
工具只是手段,发现瓶颈 才是目的。JMeter 是一把锋利的剑,但能不能斩断性能问题的荆棘,取决于你对业务的理解和对系统的洞察。
愿你的系统永远 高可用,愿你的 P99 永远 低延迟。同学们,下课!





