
Prorise
这是我的博客,分享技术与生活的点点滴滴
Java(二):2.0 Java基础
Java(二):2.0 Java基础
Prorise2.0 Java基础
本章将深入Java语言的根基——构成程序万物的基础语法。我们将从“数据类型”这个核心筒开始,对Java世界中所有用于承载数据的基本单元和复杂结构,进行一次全面、详尽的探险。这趟旅程不仅涵盖它们的用法,更会深入其设计原理与实战中的避坑技巧,为后续所有高阶概念的学习打下最坚实的地基。
2.1 数据类型全解
2.1.1 引言:Java数据世界的两大基石
在开始学习具体的数据类型之前,我们必须先建立一个宏观的认知:Java中的所有数据类型归根结底分为两大阵营。理解它们的本质区别,是掌握Java内存管理和程序性能的关键。
基本数据类型
- 定义:这是Java语言内置的、最基础的8种数据类型。它们并非对象。
- 特点:变量本身直接存储数据的值。通常存储在栈(Stack)内存中(特指方法内的局部变量),这使得它们的存取速度非常快。
引用数据类型
- 定义:除了8种基本数据类型之外的所有类型,包括我们自定义的类(Class)、接口(Interface)、数组(Array)、枚举(Enum)以及后面要讲的
String和集合等,都属于引用类型。 - 特点:变量存储的是一个内存地址,这个地址指向了真正的数据(即对象实例)。变量的引用地址存储在栈上,而对象实例则存储在堆(Heap)内存中。
2.1.2 基本数据类型
这部分类型是构成程序运算的最小单位,它们不具备对象的方法,但性能极高。
整数家族 (byte, short, int, long)
核心用途
byte: 主要用于文件I/O操作,作为字节流进行数据传输,或在内存敏感的场景下节省空间。short: 使用场景较少,通常在一些底层或兼容性代码中可见。int: 最常用的整数类型,用于计数、索引、ID等绝大多数整数运算场景。long: 用于表示需要超出int范围的整数,如时间戳(毫秒数)、大型文件大小、大型计数等2。
类型介绍与面试题
类型 大小(位) 取值范围 默认值 byte8 -128 ~ 127 0short16 -32,768 ~ 32,767 0int32 -2³¹ ~ 2³¹-1 0long64 -2⁶³ ~ 2⁶³-1 0L- [面试题]
byte b = 127; b++;结果是什么?
答:结果是
-128。这是因为byte类型最大值为127(二进制01111111),加1后发生溢出,二进制变为10000000,这在计算机补码表示中恰好是-128。- [面试题]
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14package com.example;
//TIP To <b>Run</b> code, press <shortcut actionId="Run"/> or
// click the <icon src="AllIcons.Actions.Execute"/> icon in the gutter.
public class Main {
public static void main(String[] args) {
long timestamp = 1672531200000L;
byte b1 = 10;
byte b2 = 20;
// byte b3 = b1 + b2; // 这行会编译错误,因为b1+b2的结果已经是int类型
int result = b1 + b2; // 正确的做法
System.out.println("byte类型运算结果(已提升为int): " + result);
}
}
浮点数家族 (float, double)
核心用途:用于需要小数的计算,如科学计算、图形学等。
double(双精度)比float(单精度)更常用,因为它精度更高。类型介绍与避坑指南
float: 32位,数值后需加F或f后缀。double: 64位,是默认的小数类型。[面试必考][避坑指南] 为何金融计算禁用
float/double?答:因为
float和double采用二进制浮点数表示法,无法精确表示所有十进制小数(例如0.1)。这会导致舍入误差,在要求高精度的金融或商业计算中是致命的。最佳实践是使用java.math.BigDecimal类。
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15package com.example;
import java.math.BigDecimal;
public class Main {
public static void main(String[] args) {
double d1 = 0.2;
double d2 = 0.3;
System.out.println("0.1 + 0.2 = " + (d1 + d2)); // 输出通常不是精确的0.3
// 使用BigDecimal进行精确计算
var bd1 = new BigDecimal("0.1"); // 注意:使用字符串构造以保证精度
var bd2 = new BigDecimal("0.2");
System.out.println("BigDecimal 精确计算: " + bd1.add(bd2));
}
}
char (字符类型) 与 boolean (布尔类型)
- 核心用途
char: 表示单个字符,如字母、数字或符号。boolean: 用于逻辑判断,只有true和false两个值。
- 类型介绍与面试题
char在Java中占16位(2字节),采用Unicode编码,因此可以表示世界上绝大多数语言的字符。[面试题]
char类型能否存储一个中文汉字?答:可以。因为Java的
char类型使用Unicode编码,其范围覆盖了绝大多数汉字。
2.1.3 包装类
核心用途
包装类的存在是为了解决基本数据类型无法像对象一样被操作的问题。核心用途包括:
- 在集合框架中使用,如
List<Integer>,因为泛型参数必须是对象。 - 允许值为
null,用于表示缺失或未定义的状态。 - 包含了许多实用的静态方法,如类型转换、进制转换等。
Integer 深度剖析
类型介绍与面试题
- 自动装箱 (Autoboxing):
Integer i = 100;编译器自动转换为Integer i = Integer.valueOf(100);。 - 自动拆箱 (Unboxing):
int n = i;编译器自动转换为int n = i.intValue();。
1
2
3
4
5
6
7
8
9
10
11package com.example;
public class Main {
public static void main(String[] args) {
Integer i = 100; // 自动装箱
// 约等于这一行 -> Integer i = Integer.valueOf(100);
int n = i; // 自动拆箱
// 约等于这一行 -> int n = i.intValue();
System.out.println("n = " + n); // 输出 100
}
}[面试必考]
Integer缓存池为了提高性能,
Integer.valueOf()方法对 -128到127 之间的整数进行了缓存。当通过自动装箱或valueOf()创建这个范围内的Integer对象时,会直接返回缓存中的同一个对象。超出这个范围,则会new一个新的对象。因此,使用==比较时,若两个对象不是同一个实例,就会得到false,从而引发问题。建议使用.equals()方法进行值比较。1
2
3
4
5
6
7
8
9
10
11
12
13
14package com.example;
public class Main {
public static void main(String[] args) {
// Integer 缓存池演示
Integer a = 100;
Integer b = 100;
System.out.println("a == b (100): " + (a == b)); // true, 因为在缓存池内
Integer c = 200;
Integer d = 200;
System.out.println("c == d (200): " + (c == d)); // false, 超出缓存范围,创建了新对象
}
}- 自动装箱 (Autoboxing):
常用方法速查表
方法签名 功能描述 parseInt(String s)将字符串解析为 int基本类型。valueOf(String s / int i)将字符串或 int转换为Integer对象。(推荐使用,会利用缓存)intValue()将 Integer对象转换为int基本类型。int compareTo(Integer anotherInteger)比较两个 Integer对象的大小。boolean equals(Object obj)比较两个 Integer对象的值是否相等。
1 | package com.example; |
2.1.4 字符串:String
核心用途
用于表示和操作一切文本信息,是Java中使用最频繁的类之一。
类型介绍与核心面试题
[面试必考]
String的不可变性:String对象一旦被创建,其内容就不能被修改。任何对String的修改操作(如拼接、替换)都会返回一个新的String对象。好处:线程安全;
利于缓存(字符串常量池);
3.作为
HashMap的键时,可保证hashCode不变。[面试] 字符串常量池(String Pool):位于堆内存中。当使用字面量(如
String s = "Java";)创建字符串时,JVM会先检查池中是否存在"Java",如果存在则直接返回其引用,否则创建新的并放入池中。
1 | package com.example; |
[面试题]
new String("abc")创建了几个对象?答:可能是一个,也可能是两个。如果常量池中已有"abc",则只在堆中创建一个新的
String对象。如果常量池中没有,则会在池中创建一个,同时在堆中也创建一个,共两个对象。
常用方法速查表
| 分类 | 方法签名 | 功能描述 |
|---|---|---|
| 获取/判断 | length(), isEmpty(), charAt(int index), contains(CharSequence s) | 获取长度、判空、获取字符、判断包含 |
| 查找 | indexOf(String str), lastIndexOf(String str) | 查找子串首次/末次出现的位置 |
| 比较 | equals(Object anObject), equalsIgnoreCase(String anotherString) | 内容比较(区分/不区分大小写) |
| 截取/分割 | substring(int beginIndex, int endIndex), split(String regex) | 截取子串,按正则表达式分割 |
| 替换 | replace(char oldChar, char newChar), replaceAll(String regex, String replacement) | 字符替换,正则替换 |
| 转换 | toLowerCase(), toUpperCase(), trim(), toCharArray(), getBytes() | 大小写转换、去首尾空格、转数组 |
代码示例详解
1 | String str = "Hello, World!"; |
关联类型:StringBuilder与StringBuffer
核心用途与场景
当我们需要频繁地修改或拼接字符串时,使用不可变的 String 会因创建大量临时对象而导致性能低下。StringBuilder 和 StringBuffer 正是为解决这一问题而生的可变字符串序列。
StringBuilder: 适用于单线程环境下的字符串拼接或修改。是绝大多数场景下的首选,因为它性能最高。StringBuffer: 适用于多线程环境下,需要保证共享字符串数据线程安全的场景。
类型介绍与原理
StringBuilder 和 StringBuffer 本质上都是一个可变的字符数组容器。与 String 每次操作都返回新对象不同,它们的大部分操作(如append)都是在内部的字符数组上直接进行的,只有在数组容量不足时才会进行扩容,从而避免了不必要的对象创建。
- 可变性 (Mutability):它们的内部
char[]数组不是final的,并且长度可以动态改变。 - 线程安全机制 (面试必考):
StringBuffer:它的所有公开方法(如append,insert)都被synchronized关键字修饰,这意味着在同一时刻,只有一个线程能访问这些方法,从而保证了线程安全。但加锁也带来了额外的性能开销。StringBuilder:它在Java 5中被引入,可以看作是StringBuffer的一个非线程安全版本,去掉了synchronized关键字,因此在单线程环境下性能更优。
常用方法速查表
(以下方法对 StringBuilder 和 StringBuffer 均适用)
| 方法签名 | 功能描述 |
|---|---|
append(...) | 在序列末尾追加内容。此方法被重载以接受所有基本类型、String等。 |
insert(int offset, ...) | 在指定索引位置插入内容。 |
delete(int start, int end) | 删除指定范围内的字符。 |
deleteCharAt(int index) | 删除指定位置的单个字符。 |
replace(int start, int end, String str) | 用指定字符串替换范围内的内容。 |
reverse() | 将序列反转。 |
length() | 返回当前序列的长度。 |
capacity() | 返回当前内部数组的容量。 |
toString() | 将当前的可变序列转换为一个不可变的String对象。 |
代码示例详解
场景一:循环中的高效拼接
这是
StringBuilder最核心、最经典的应用场景。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21package com.example;
public class Main {
public static void main(String[] args) {
// 低效的方法
String str = "";
for (int i = 0; i < 10; i++) {
str += i;
}
System.out.println("String '+' 拼接结果: " + str);
// 高效的方法:使用StringBuilder
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 10; i++) {
sb.append(i);
}
String result = sb.toString(); // 最后需要时再转换为String
System.out.println("StringBuilder 拼接结果: " + result);
}
}场景二:链式调用构建复杂字符串
append等方法返回对象本身,使得链式编程成为可能,代码更简洁。1
2
3
4
5
6
7
8
9
10
11
12
13package com.example;
public class Main {
public static void main(String[] args) {
StringBuilder queryBuilder = new StringBuilder();
queryBuilder.append("SELECT ")
.append("id, name, email ")
.append("FROM users ")
.append("WHERE age > ?");
String sqlQuery = queryBuilder.toString();
System.out.println("构建的SQL查询: " + sqlQuery);
}
}场景三:字符串反转
String本身没有提供反转方法,使用StringBuilder可以轻松实现。1
2
3
4
5
6
7
8
9
10package com.example;
public class Main {
public static void main(String[] args) {
String original = "level";
StringBuilder reverseBuilder = new StringBuilder(original);
String reversed = reverseBuilder.reverse().toString();
System.out.println("'" + original + "' 的反转是 '" + reversed + "'"); // 🤭
}
}
[面试题] 何时使用StringBuilder和StringBuffer?
答:当需要进行大量或循环内的字符串拼接时,应使用它们来避免创建大量临时的String对象,从而提高性能。在选择时:
- 单线程环境:优先且总是使用
StringBuilder,因为它没有同步开销,性能更好。 - 多线程环境:如果一个字符串对象需要被多个线程共享和修改,必须使用
StringBuffer来保证线程安全。
2.1.5 数组 (Arrays) 与其工具类
核心用途与场景
数组是Java中最基础、最高效的数据结构之一,其核心用途是在内存中存储固定大小、同一类型的元素序列。
- 核心场景:
- 当元素数量固定,且对性能有较高要求时(如算法题、底层数据缓冲)。
- 作为更复杂数据结构(如
ArrayList,HashMap)的内部实现。 - 表示和操作矩阵或表格(使用多维数组)。
- 方法的参数或返回值,尤其是
main(String[] args)。
类型介绍与初始化
数组即对象:在Java中,数组是一个引用类型。数组变量存储在栈中,它指向堆内存中一块连续开辟的空间。这也解释了为什么数组的长度一旦创建就不可改变,因为其内存空间是连续且固定的。
length属性:数组拥有一个公共的final属性length来获取其长度,注意它是一个属性,而非方法(区别于List的size()方法)。初始化方式:
- 静态初始化:在创建时直接指定内容。
1
2int[] staticArray = {10, 20, 30};
String[] names = new String[]{"Java", "Python"}; - 动态初始化:指定数组长度,由系统分配默认值。
1
2
3int[] dynamicArray = new int[5]; // 所有元素默认为 0
boolean[] flags = new boolean[3]; // 所有元素默认为 false
String[] strings = new String[4]; // 所有元素默认为 null
- 静态初始化:在创建时直接指定内容。
[进阶] 多维数组
- Java中的多维数组本质上是“数组的数组”。例如,一个二维数组
int[][]实际上是一个int[]类型的数组,它的每个元素都是一个int[]数组。 - 因为是“数组的数组”,所以Java支持不规则数组(Ragged Array),即二维数组的每一行可以有不同的长度。
1
2
3
4
5
6
7
8
9
10
11package com.example;
public class Main {
public static void main(String[] args) {
int[][] arr = new int[3][];
arr[0] = new int[2]; // 第一行长度为 2
arr[1] = new int[3]; // 第二行长度为 3
arr[2] = new int[5]; // 第三行长度为 5
}
}- Java中的多维数组本质上是“数组的数组”。例如,一个二维数组
java.util.Arrays 核心工具方法详解
java.util.Arrays 是一个专门用于操作数组的工具类,提供了大量高效的静态方法。
| 分类 | 方法签名 | 功能描述与注意事项 |
|---|---|---|
| 排序 | sort(T[] a) / sort(T[] a, Comparator c) | 对数组进行升序排序。底层算法:为对象使用TimSort,为基本类型使用优化的快速排序。可提供自定义比较器(位于Java8新语法会详讲Comparator) |
| 查找 | binarySearch(T[] a, T key) | 必须在已排序数组上使用。如果找到,返回索引;否则返回 -(insertion point) - 1。 |
| 比较 | equals(T[] a, T[] a2) / deepEquals(Object[] a1, Object[] a2) | equals 比较一维数组内容。deepEquals 用于递归比较多维数组。 |
| 复制 | copyOf(T[] original, int len) / copyOfRange(T[] o, int f, int t) | copyOf 复制整个数组到新长度。copyOfRange 复制指定范围。是实现数组扩容/缩容的常用手段。 |
| 填充 | fill(T[] a, T val) | 用同一个值填充数组的所有元素,常用于初始化。 |
| 转换 | toString(T[] a) / deepToString(Object[] a) | toString 用于优雅地打印一维数组。deepToString 用于打印多维数组。 |
| 转换 | asList(T... a) | [高频避坑] 返回一个固定大小的List视图,不支持add/remove操作。对列表的修改会直接反映到原数组上,反之亦然。 |
| 转换 | stream(T[] array) | [Java 8+] 将数组转换为一个Stream,便于使用函数式编程进行链式操作,极大增强了数组的处理能力。 |
代码示例详解
排序
1 | package com.example; |
查找
1 | package com.example; |
比较
1 | package com.example; |
复制
1 | package com.example; |
填充
1 | package com.example; |
转换
1 | package com.example; |
流处理
这在后续的Java8语法中是至关重要的一个方法,开启一个流,并将每一个元素作为一个流来处理
1 | package com.example; |
[面试题] 数组 (Array) vs. 列表 (ArrayList)
| 对比维度 | 数组 (Array) | ArrayList |
|---|---|---|
| 大小 | 固定,创建时必须指定,不可改变。 | 动态,可根据需要自动扩容。 |
| 元素类型 | 可存储基本数据类型和对象引用。 | 只能存储对象引用(基本类型需自动装箱)。 |
| 性能 | 访问(get/set)极快 ,增删慢(需手动实现)。 | 访问快,增删(尤其在中间)相对较慢。 |
| 泛型支持 | 不支持泛型。 | 支持泛型,提供编译时类型安全检查。 |
| API与功能 | 功能有限,需依赖Arrays工具类。 | 功能强大,提供了丰富的增删改查方法。 |
| 核心选择依据 | 数量固定且追求极致性能时选数组。 | 数量不固定,需要灵活增删和丰富API时选ArrayList。 |
2.1.6 集合框架:List
核心用途
存储有序、可重复的元素集合,长度可动态改变。是日常开发中最常用的集合类型之一。
ArrayList 详解
- 核心用途:最常用的
List实现,适用于**高频的随机访问(查、改)**场景。 - 类型介绍与底层原理:底层基于动态数组实现。当添加元素导致容量不足时,会触发扩容机制,通常是创建一个1.5倍于原容量的新数组,并将旧数据复制过去。
- 常用方法速查表
方法签名 功能描述 boolean add(E e)在列表末尾添加元素。 void add(int index, E element)在指定索引处插入元素。 E get(int index)获取指定索引处的元素。 E set(int index, E element)替换指定索引处的元素。 E remove(int index)移除指定索引处的元素。 int size()返回列表中的元素数量。 - 代码示例详解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20package com.example;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) {
ArrayList<String> fruits = new ArrayList<>();
fruits.add("Apple");
fruits.add("Banana");
fruits.add(0, "Orange"); // 在索引0处插入
System.out.println("第一个水果: " + fruits.get(0)); // Orange
fruits.set(1, "Grape"); // 替换
System.out.println("所有水果: " + fruits); // [Orange, Grape, Banana]
}
}
LinkedList 详解
核心用途:适用于高频的头尾增删操作场景。它还实现了
Deque接口,可作为队列或栈使用。类型介绍与底层原理:底层基于双向链表实现。每个节点都存储着数据以及前后节点的引用。
常用方法速查表
方法签名 功能描述 接口来源 void addFirst(E e)在列表头部添加元素。 Dequevoid addLast(E e)在列表尾部添加元素。 DequeE poll()/E pollFirst()获取并移除列表头部元素。 Queue/DequeE pollLast()获取并移除列表尾部元素。 DequeE peek()/E peekFirst()查看列表头部元素(不移除)。 Queue/Deque代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18package com.example;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.LinkedList;
import java.util.List;
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) {
LinkedList<String> taskQueue = new LinkedList<>();
// 作为队列使用
taskQueue.offer("Task 1"); // 入队
taskQueue.offer("Task 2");
System.out.println("处理任务: " + taskQueue.poll()); // 出队
System.out.println("下一个任务: " + taskQueue.peek());
}
}
[面试题] ArrayList vs LinkedList 对比
| 特性 | ArrayList | LinkedList |
|---|---|---|
| 底层结构 | 动态数组 | 双向链表 |
| 随机访问(get) | 快 | 慢 |
| 增/删(add/remove) | 末尾快,中间慢(需移动元素) | 头尾极快,中间慢(需遍历定位) |
| 内存占用 | 较少,内存连续 | 较大,需额外空间存节点引用 |
| 适用场景 | 读多写少,随机访问多 | 写多读少,头尾操作多 |
2.1.7 集合框架:Set
Set接口继承自Collection接口,它代表一个不包含重复元素的集合。这是Set与List最本质的区别。Set的主要设计目标就是确保其中每个元素的唯一性,并提供快速的成员资格检查。
- 核心特性:
- 不重复 (No Duplicates):
Set中不允许出现重复的元素。尝试添加一个已经存在的元素将会失败,且不会抛出异常。 - 通常无序 (Generally Unordered):大部分
Set的实现(如HashSet)不保证元素的存储和迭代顺序。但也有例外,如LinkedHashSet会保持插入顺序,TreeSet会保持排序顺序。
- 不重复 (No Duplicates):
HashSet 详解
核心用途与场景
HashSet是Set接口最常用、性能最高的实现类,其核心价值在于高效的元素去重与查找,他是无序的,在去重一个列表中会将元素打乱,顺序不一定按照顺序
- 最佳场景:
- 对一个数据集(如
List)进行快速去重。 - 需要快速判断某个元素是否存在于一个庞大的集合中。
- 存储一组唯一的ID或标识符。
- 对一个数据集(如
类型介绍与去重原理
[面试] 去重流程:
HashSet保证元素唯一的两大基石是hashCode()和equals()方法。当调用add(element)方法时,其内部会执行map.put(element, PRESENT),参数PRESENT是一个常量,通常用于表示键已存在,但不需要存储额外的值。它常用于HashSet或HashMap的实现中,作为占位符值,以区分键是否被插入过。HashMap的put流程如下:首先,计算element的hashCode()值,通过哈希算法定位到内部数组的某个“桶”(bucket)索引。如果这个桶是空的,元素直接存入。如果桶中已经有其他元素(即发生哈希冲突),则会遍历这个桶中的所有元素,逐个用equals()方法与新元素进行比较。只要有一次equals()返回true,就认定元素已存在,添加失败;如果所有比较结果都为false,则将新元素添加到这个桶中(通常是链表或红黑树的末端)。
结论:若想让自定义的类(如
User)对象能在HashSet中被正确去重,必须同时、正确地重写hashCode()和equals()方法。
常用方法速查表
| 方法签名 | 功能描述 |
|---|---|
boolean add(E e) | 添加元素。如果元素已存在,则返回false,集合不变。 |
boolean remove(Object o) | 移除指定元素。如果成功移除,返回true。 |
boolean contains(Object o) | 判断是否包含指定元素。这是Set的核心优势之一。 |
int size() | 返回集合中的元素数量。 |
void clear() | 清空集合中的所有元素。 |
Iterator<E> iterator() | 获取用于遍历集合的迭代器。 |
代码示例详解
场景一:基本数据类型去重
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15package com.example;
import java.util.*;
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) {
// 使用HashSet为List去重
List<String> nameList = Arrays.asList("Alice", "Bob", "Alice", "Charlie");
Set<String> uniqueNames = new HashSet<>(nameList);
System.out.println("原始列表: " + nameList); // 输出: [Alice, Bob, Alice, Charlie]
System.out.println("去重后集合: " + uniqueNames); // 输出: [Alice, Bob, Charlie] (顺序不保证)
}
}场景二:自定义对象的正确去重
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40package com.example;
import java.util.*;
public class Main {
public static void main(String[] args) {
Set<User> users = new HashSet<>();
users.add(new User("U001", "Alice"));
users.add(new User("U002", "Bob"));
users.add(new User("U001", "Alice V2")); // id相同,被认为是重复对象,无法添加
System.out.println("用户集合大小: " + users.size()); // 输出: 2
System.out.println(users); // 输出两个User对象
}
}
class User {
String id;
String name;
// 构造方法
public User(String id, String name) {
this.id = id;
this.name = name;
}
public int hashCode() {
return java.util.Objects.hash(id); // 通常用唯一标识(如ID)来计算哈希
}
public boolean equals(Object obj) {
if (this == obj) return true;
if (obj == null || getClass() != obj.getClass()) return false;
User user = (User) obj;
return java.util.Objects.equals(id, user.id);
}
}
LinkedHashSet 详解
核心用途与场景
当你在需要Set的去重特性的同时,还希望保持元素的插入顺序时,LinkedHashSet是最佳选择。
- 最佳场景:
- 记录用户操作序列,并去除重复操作。
- 需要去重,但后续的展示或处理需要按照添加的先后顺序。
类型介绍与底层原理
LinkedHashSet继承自HashSet。它的实现方式与HashSet类似,但其内部使用的是一个LinkedHashMap实例。LinkedHashMap在HashMap的基础上,额外维护了一个贯穿所有元素的双向链表,正是这个链表保证了迭代的顺序与元素插入的顺序一致。
1 | package com.example; |
TreeSet 详解
核心用途与场景
当你需要一个时刻保持排序状态的、且元素唯一的集合时,TreeSet是唯一的选择。
- 最佳场景:
- 排行榜的实时更新与展示。
- 需要从一个集合中快速获取最大或最小元素。
- 存储需要按特定规则排序的唯一数据。
1 | package com.example; |
类型介绍与排序原理
[底层] 数据结构:
TreeSet的底层是基于**红黑树(Red-Black Tree)**实现的,这是一种自平衡的二叉搜索树。元素在被添加时,会根据其排序规则被放置在树的正确位置,从而保证了集合始终处于有序状态。实际上,TreeSet内部使用的是一个TreeMap。[面试必考] 排序规则:
TreeSet判断元素大小和唯一性的依据是元素的比较结果,而非hashCode()和equals()。它有两种排序方式:- 自然排序:存入
TreeSet的元素所属的类必须实现java.lang.Comparable接口,并重写compareTo(T o)方法。Java中许多核心类如Integer、String都已实现此接口。 - 定制排序:如果在创建
TreeSet时,通过构造函数传入一个java.util.Comparator的实现类,那么TreeSet将使用这个比较器来对元素进行排序。这种方式更灵活,也更常用。
- 自然排序:存入
常用方法速查表
除了Set接口的通用方法外,TreeSet还提供了一系列强大的导航方法。
| 方法签名 | 功能描述 |
|---|---|
E first() | 返回集合中的第一个(最小)元素。 |
E last() | 返回集合中的最后一个(最大)元素。 |
E lower(E e) | 返回小于给定元素e的最大元素。 |
E higher(E e) | 返回大于给定元素e的最小元素。 |
E floor(E e) | 返回小于等于给定元素e的最大元素。 |
E ceiling(E e) | 返回大于等于给定元素e的最小元素。 |
E pollFirst() | 移除并返回第一个(最小)元素。 |
E pollLast() | 移除并返回最后一个(最大)元素。 |
2.1.8 集合框架:Map(重点)
Map 接口核心特性
Map接口是Java集合框架的另一大分支,它专门用于存储**键值对(Key-Value)**数据。Map中的每一个元素都包含一个唯一的键(Key)和一个与之关联的值(Value)。
- 核心特性:
- 键的唯一性 (Unique Keys):
Map中不允许存在重复的键。如果尝试用一个已存在的键put新值,新值会覆盖旧值。键的唯一性判断依赖于其hashCode()和equals()方法。 - 值可重复:不同的键可以关联相同的值。
- 快速查找:
Map的核心价值在于能通过键来快速定位到值
- 键的唯一性 (Unique Keys):
HashMap 核心方法速查表
1. 核心操作
这是日常使用中最频繁的增、删、改、查操作。
| 方法签名 | 功能描述 | 注意事项 / 最佳实践 |
|---|---|---|
V put(K key, V value) | 将指定的键值对存入Map。如果键已存在,则覆盖旧值。 | 返回值:返回与key关联的旧值;如果key是新的,则返回null。 |
V get(Object key) | 根据键获取其对应的值。 | 如果key不存在,返回null。因此,get()返回null不一定代表key不存在,也可能key对应的值本身就是null。 |
V remove(Object key) | 根据键移除对应的键值对。 | 返回值:返回被移除的key所对应的value;如果key不存在,则返回null。 |
boolean containsKey(Object key) | 判断Map中是否包含指定的键。 |
2. 视图操作
HashMap提供了三种视图,用于以不同的角度审视Map中的数据。这些视图与Map本身是联动的。
| 方法签名 | 功能描述 | 注意事项 / 最佳实践 |
|---|---|---|
Set<K> keySet() | 返回Map中所有**键(Key)**组成的一个Set集合。 | 返回的是一个视图,不是副本。对这个Set进行移除操作会同步影响到原Map,但不支持添加操作。 |
Collection<V> values() | 返回Map中所有**值(Value)**组成的一个Collection。 | 同样是视图。可以包含重复元素。对这个集合的修改同样会影响原Map。 |
Set<Map.Entry<K, V>> entrySet() | 返回Map中所有**键值对节点(Map.Entry)**组成的Set集合。 | 最高效的遍历方式。Map.Entry对象提供了getKey()和getValue()方法。 |
3. 状态查询
| 方法签名 | 功能描述 | 注意事项 / 最佳实践 |
|---|---|---|
int size() | 返回Map中键值对的数量。 | 时间复杂度为O(1)。 |
boolean isEmpty() | 判断Map是否为空(即size()是否为0)。 | 比 size() == 0 更具可读性。 |
void clear() | 清空Map中所有的键值对。 | 调用后size()将变为0。 |
4. Java 8+ 增强方法
Java 8 引入了一系列函数式方法,极大地简化了代码。
| 方法签名 | 功能描述 | 注意事项 / 最佳实践 |
|---|---|---|
V getOrDefault(Object key, V defaultValue) | 强烈推荐。获取值,若key不存在则返回一个指定的defaultValue。 | 优雅地解决了get()可能返回null的问题,避免了if (map.get(key) != null)的样板代码。 |
V putIfAbsent(K key, V value) | 仅当key不存在或其值为null时,才存入该键值对。 | 可用于实现缓存、单例初始化等原子性操作,避免覆盖已有值。 |
void forEach(BiConsumer<? super K, ? super V> action) | 使用Lambda表达式遍历Map的每个键值对。 | 是目前最简洁、最推荐的遍历方式之一。 |
V compute(K key, BiFunction<...> remappingFunction) | 对指定key的值进行计算和更新,功能强大且原子。 | 适用于需要先get、再计算、最后put的复杂更新场景。 |
V merge(K key, V value, BiFunction<...> remappingFunction) | 合并值。如果key不存在,存入value;如果存在,则用旧值和新value执行函数,并将结果存入。 | 非常适合实现计数统计等聚合操作,比getOrDefault更强大。 |
V replace(K key, V value) | 仅当key存在时,才用新value替换旧值。 |
**5. 批量操作 **
| 方法签名 | 功能描述 | 注意事项 / 最佳实践 |
|---|---|---|
void putAll(Map<? extends K, ? extends V> m) | 将另一个Map中所有的键值对都复制到当前Map中。 | 如果键冲突,会用新Map中的值覆盖当前Map中的值。 |
总结与建议:
在日常开发中,应熟练掌握核心操作和视图操作。同时,强烈建议多利用Java 8+提供的新方法(如 getOrDefault, putIfAbsent, merge, forEach 等),它们能让您的代码变得更简洁、更安全、更具表现力。
核心用途与场景
HashMap是Map接口最通用的实现,是日常开发中使用频率最高的集合之一。它适用于任何需要通过一个唯一标识来存取、管理一系列数据的场景。
- 典型场景:
- 实现内存缓存:快速存取热点数据,减轻数据库压力。
- 存储配置信息:加载应用的配置项,键为配置名,值为配置值。
- 数据索引:将
List中的数据按某个字段(如用户ID)转为Map,实现快速查找。 - 计数统计:统计文本中的词频,或集合中各元素的出现次数。
- 传递灵活参数:在方法间传递一组不固定的参数,类似一个动态对象。
场景一:实现内存缓存
目的:将耗时操作(如数据库查询、网络请求)的结果存储起来。当再次需要相同数据时,直接从内存中快速获取,避免重复执行耗时操作,从而提升系统性能。
1 | import java.util.HashMap; |
场景二:存储配置信息
目的:在程序启动时,将配置文件(如
.properties或YAML)中的键值对加载到Map中,便于在程序运行期间随时、快速地获取配置项。
1 | import java.util.HashMap; |
场景三:将列表数据转换为索引
目的:将一个对象列表(
List<T>)转换为以对象的某个唯一标识(如ID)为键的Map<ID, T>,从而将原先O(n)的遍历查找操作,优化为O(1)的直接访问操作。
1 | package com.example; |
场景四:计数统计
目的:统计一个集合或文本中,每个独立元素出现的次数。
HashMap是实现该功能的完美数据结构。
1 | import java.util.HashMap; |
TreeMap 简介
核心用途与场景
当你需要一个键(Key)时刻保持排序状态的Map时,TreeMap是你的不二之选。
- 最佳场景:
- 需要按键的自然顺序或自定义顺序遍历
Map。 - 需要对
Map的键进行范围查找,如“查找所有ID在100到200之间的用户”。
- 需要按键的自然顺序或自定义顺序遍历
类型介绍与排序原理
TreeMap底层基于红黑树实现。排序规则与TreeSet完全相同,依赖于键的Comparable接口(自然排序)或在构造时传入的Comparator(定制排序)。
代码示例详解
1 | package com.example; |
[面试题] HashMap vs Hashtable vs ConcurrentHashMap
这是其余的两个Map与最常用的HashMap作为对比
| 特性 | HashMap | Hashtable (已不推荐使用) | ConcurrentHashMap (推荐) |
|---|---|---|---|
| 线程安全 | 非线程安全 | 线程安全 (对整个表加synchronized锁) | 线程安全 (分段锁/CAS,性能远超Hashtable) |
| null支持 | 允许 key和value为null | 不允许 key和value为null (会抛NullPointerException) | 不允许 key和value为null |
| 性能 | 最高(单线程) | 最低(锁竞争激烈) | 高(并发环境) |
| 推荐用法 | 单线程环境下的首选。 | 不推荐使用,是过时的历史遗留类。 | 并发环境下的首选。 |
2.2 运算符详解
本节将直接深入运算符的核心与难点,剔除基础部分。我们将聚焦于位运算符的强大能力、逻辑与自增/自减运算的常见陷阱、优先级的避坑指南,以及Java新版本带来的语法糖,但在这之前,要深入理解位运算符,我们首先需要回归计算机的“母语”——二进制,并掌握不同进制间的转换,以及计算机内部表示数字(尤其是负数)的精妙方式:补码。
2.2.0 计算机基础:进制与编码
要深入理解位运算符,我们首先需要回归计算机的“母语”——二进制,并掌握不同进制间的转换,以及计算机内部表示数字(尤其是负数)的精妙方式:补码。
常见进制介绍
在日常生活中我们使用十进制,但在计算机科学中,我们必须熟悉以下几种进制:
- 二进制 (Binary):基数为2,由
0和1组成。是计算机物理层面的通用语言。在Java中以0b或0B开头,如0b1011。 - 八进制 (Octal):基数为8,由
0-7组成。在Java中以0开头,如055。 - 十进制 (Decimal):基数为10,由
0-9组成。我们最熟悉的进制。 - 十六进制 (Hexadecimal):基数为16,由
0-9和A-F(代表10-15) 组成。常用于表示内存地址、颜色值等。在Java中以0x或0X开头,如0x2D。
进制转换核心方法
十进制转二进制(除2取余法)
手算方法:将十进制数连续除以2,直到商为0,然后将每步得到的余数逆序排列。
手算示例:将十进制 45 转换为二进制。
1
2
3
4
5
645 ÷ 2 = 22 ... 余 1
22 ÷ 2 = 11 ... 余 0
11 ÷ 2 = 5 ... 余 1
5 ÷ 2 = 2 ... 余 1
2 ÷ 2 = 1 ... 余 0
1 ÷ 2 = 0 ... 余 1结果:从下往上倒序取余数,得到
101101。
二进制转十进制(按权展开法)
手算方法:权重法(8421 法则)
从右到左写出每位的权重:$2^0, 2^1, 2^2, \dots$
取出二进制中为 1 的权重,累加即可。
手算示例: 将 101101 转换为十进制:
1 | 32 16 8 4 2 1 (权重) |
2.2.3 [计算机基础] 原码、反码、补码
为何需要补码?
计算机硬件层面,只有加法器。为了简化电路设计,希望将减法运算也统一为加法运算。例如 5 - 3 希望能变成 5 + (-3)。原码无法满足这个要求,而补码巧妙地解决了这个问题,并统一了+0和-0的表示。
正数与负数的编码表示
正数:原码、反码、补码都相同。
负数:
- **原码 **:最高位为符号位(1代表负),其余位是其绝对值的二进制。

例如我们之前计算的**
45的源码就为00101101,不足八位则不足,若是-45**则为10101101- 反码:在原码的基础上若为正数,则反码不变,若为负数,则符号位不变,其他全部取反(0变1)
例如
-45的反码就是01010010- **补码 :在反码的基础上,**末位加1。
例如
-45的补码就是01010011

计算机内存中,所有整数都以补码的形式存储。
补码的计算过程
- 示例:计算
-5在一个byte(8位)中的补码。- 先求
+5的原码:0000 0101 - 求
-5的原码(符号位变1):1000 0101 - 求
-5的反码(符号位不变,其余取反):1111 1010 - 求
-5的补码(反码加1):1111 1011所以,-5在内存中存储的就是1111 1011。
- 先求
2.2.1 [面试高频] 位运算符深度剖析
位运算符直接在整数的二进制位(bit)上进行操作,不关心其十进制值。它们之所以在面试和高性能场景中备受青睐,主要源于两大优势:极致的运行效率(因为更接近硬件操作)和高效的空间利用(例如用一个int存储32个开关状态),现代JVM的JIT(即时编译器)已经非常智能,可能会自动将 x * 2 这样的代码优化为 x << 1。但在一些对性能要求极为苛刻的场景,或者在阅读一些经典框架(如ArrayList、HashMap)的源码时,你会发现它们的身影
1 | // ArrayList.java 源码片段 |
核心对比:>> (算术右移) vs. >>> (逻辑右移)
这个区别是面试中的经典考点,它仅在处理负数时有所不同。
>>(带符号右移 / 算术右移):进行右移操作时,空出的高位会用原始数字的符号位来填充。如果原数是正数(符号位为0),则高位补0;如果原数是负数(符号位为1),则高位补1。这样做的目的是保持数字的正负性质不变。>>>(无符号右移 / 逻辑右移):进行右移操作时,无论原始数字是正数还是负数,空出的高位一律用0填充。这意味着,对一个负数进行无符号右移后,其结果会变成一个非常大的正数。
代码示例:对比 >> 和 >>>
1 | package com.example; |
第一步:确定-8的32位二进制补码表示
计算机不会直接处理 -8 这个符号,而是处理它的二进制补码。
求
+8的原码:在一个32位的int中,+8的二进制表示非常简单:00000000 00000000 00000000 00001000求
-8的反码:在+8原码的基础上,符号位(最高位)变为1,其余位按位取反(0变1,1变0)。11111111 11111111 11111111 11110111求
-8的补码:将反码加1,就得到了-8在内存中实际存储的形式。11111111 11111111 11111111 11111000
这就是我们操作的起始状态。
第二步:执行带符号右移 >> 2
操作 negativeNum >> 2 意味着将 -8 的补码向右移动两位。
原始补码:
11111111 11111111 11111111 11111000向右移动两位:
所有的32位都向右平移2个位置,最右边的两位00被丢弃。左边空出了两个位置。??111111 11111111 11111111 11111111 111110填充高位:
因为是>>(带符号右移),所以空出的高位会用原始的符号位来填充。-8的符号位是1,所以用1来填充。11111111 11111111 11111111 11111110
现在,我们就得到了右移操作后的二进制结果。
第三步:将结果转换回十进制
我们需要将这个新的补码 11111111 11111111 11111111 11111110 转换回我们能理解的十进制数,以验证它就是 -2。
- 观察符号位:最高位是
1,说明这是一个负数。 - 求其反码(补码减1):
11111111 11111111 11111111 11111101 - 求其原码(符号位不变,其余位取反):
10000000 00000000 00000000 00000010 - 读取数值:这个原码表示的数值就是
-2。
实战场景与代码详解
场景一:高效运算
判断奇偶数:
n & 1比n % 2效率更高。因为任何整数的二进制表示中,最低位是1则为奇数,是0则为偶数。1
2
3
4
5
6
7
8
9
10
11package com.example;
public class Main {
public static void main(String[] args) {
// num & 1 用于检查 num 的二进制最低位是否为 1,若不为1则返回0
int num1 = 100; // 偶数
if ((num1 & 1) == 0) {
System.out.println(num1 + " 是偶数。");
}
}
}代替乘除2的幂运算:
n << x相当于n * 2^x,n >> x相当于n / 2^x。1
2
3
4
5
6
7
8
9package com.example;
public class Main {
public static void main(String[] args) {
int num = 10;
// 10 * 8 (2^3)
int multiplied = num << 3;
System.out.println("10 * 8 = " + multiplied); // 输出: 80
}
}
2.2.2 [避坑指南] 逻辑与自增/自减运算符陷阱
短路逻辑 (&& 和 ||)
&& (与) 和 || (或) 具有短路特性,这是面试和日常编码中必须注意的细节。
&&(短路与):如果第一个操作数为false,则不会再执行第二个操作数,直接判定整个表达式为false。||(短路或):如果第一个操作数为true,则不会再执行第二个操作数,直接判定整个表达式为true。
& 和 | 也可以用作逻辑运算符,但它们不具备短路特性,会执行所有操作数。
i++ vs. ++i
++i(前自增):先自增,后取值。表达式返回的是i加1之后的值。i++(后自增):先取值,后自增。表达式返回的是i加1之前的原始值。
经典面试题:i = i++
1 | public class PostIncrementPuzzle { |
- 结果与原理解析:
输出结果是 0。
JVM底层执行步骤:- JVM将
i的当前值(0)加载到一个临时变量区,我们称之为temp。(temp = 0) i自身的值加1,此时i变量变为1。i++这个表达式返回的是加1前的原始值,即temp的值(0)。- 执行赋值操作
i = ...,将表达式的返回值(0)赋给i。最终,i的值被重新覆盖为了0。
- JVM将
2.2.3 运算符优先级与核心建议
完全记住运算符优先级表是困难且不切实际的。我们仅需关注几个易错点,并养成一个好习惯。
- 易错点1:位运算符的优先级低于关系运算符。如
(permissions & MASK) == MASK,括号必不可少。 - 易错点2:
&&的优先级高于||。如a || b && c等价于a || (b && c)。
核心开发建议:不要依赖隐式优先级
代码首先是写给人看的,其次才是给机器执行的。
在任何可能产生歧义的复杂表达式中,请毫不犹豫地使用圆括号 () 来明确指定运算顺序。这不仅能100%避免由优先级问题导致的、难以察V觉的BUG,更能极大地提升代码的可读性和可维护性。
2.3 [深度] 循环与异常处理进阶
本章将绕开基础的for/while循环和if判断的语法,直接深入探讨程序流程控制的“内功”——循环的底层机制、现代化的语法演进,以及构建健壮、可靠程序的基石:Java的异常处理框架。
2.3.1 [深度] for-each循环与Iterator迭代器原理
for-each循环(或称增强型for循环)是Java 5引入的语法糖,它极大地简化了对数组和集合的遍历。但要真正掌握它,必须理解其背后的Iterator机制。
for-each的底层真相
for-each循环并非一种新的循环结构,而是编译器为我们提供的便利。编译器在处理for-each循环时,会将其转换为不同的遍历方式:
- 对于数组:它会被转换为一个传统的、带索引的
for循环。 - 对于集合:它会被转换为使用
Iterator迭代器的while循环。这是理解所有相关问题的关键。
代码示例:for-each的编译后等价代码
1 | package com.example; |
[面试高频] Iterator 与 Fail-Fast 机制
Iterator接口: 提供了统一的遍历集合的方式,其核心方法为hasNext()(检查是否有下一个元素)、next()(获取下一个元素并后移指针)和remove()(从集合中删除next()方法最后返回的那个元素)。Fail-Fast(快速失败)机制: 这是ArrayList等非并发集合的一个重要特性。在集合内部,有一个名为modCount的变量,记录着集合结构被修改(如add、remove)的次数。当创建Iterator时,迭代器会记下当时的modCount值。在迭代过程中,每次调用iterator.next()时,都会检查迭代器的记录值与集合当前的modCount是否一致。如果不一致,说明在迭代期间,集合被外部(非迭代器自身)修改了,迭代器会立刻抛出ConcurrentModificationException,以避免在数据不一致的状态下继续操作,这就是“快速失败”。
代码示例:触发ConcurrentModificationException与正确删除
在任何情况下,都绝对不要在for-each循环中直接调用集合的remove()或add()方法。这是非常危险且不可靠的编码方式。唯一正确且安全的方式是使用Iterator的remove()方法。
1 | package com.example; |
2.3.2 [进阶] 带标签的 break 和 continue
这是一个不常用但非常有用的语法,它解决了如何从内层循环直接跳出外层循环的问题。
代码示例:在二维数组中查找并跳出所有循环
1 | package com.example; |
2.3.3 [核心] Java异常处理机制
面试题引入
“谈谈你对Java异常体系的理解。
Error和Exception有什么区别?Checked Exception和Unchecked Exception呢?”
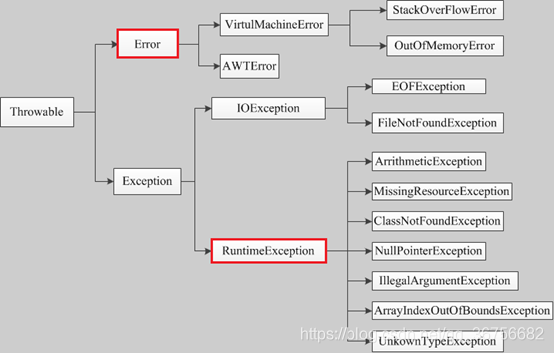
[底层] Throwable 家族:异常体系结构
Java中所有可抛出的东西都继承自Throwable类,它有两个重要的子类:Error和Exception。
Error:代表了JVM本身无法恢复的严重内部错误,如StackOverflowError(栈溢出)、OutOfMemoryError(内存耗尽)。应用程序不应该也无法捕获或处理这类错误。Exception:代表了应用程序层面可以处理的异常情况。它又分为两大类:Checked Exception(受检异常):继承自Exception但非RuntimeException的异常。编译器会强制开发者处理它们,必须使用try-catch捕获或在方法签名上用throws声明。它们通常代表了可预见的、可恢复的外部问题,如IOException、SQLException。Unchecked Exception(非受检异常):即RuntimeException及其所有子类。编译器不强制处理它们。它们通常是由程序自身的逻辑错误(BUG)引起的,如NullPointerException、IllegalArgumentException、ArrayIndexOutOfBoundsException。
[面试高频] try-catch-finally 的执行内幕
面试题 1:“
finally块一定会执行吗?”答:绝大多数情况下是的。
finally块的设立目的就是为了保证无论是否发生异常,某些清理代码(如关闭资源)都能得到执行。只有两种极端情况finally不会执行:- 在
try或catch块中调用了System.exit(); - JVM崩溃或线程被强制杀死。
- 在
面试题 2:“如果
catch块中有return语句,finally块会执行吗?”答:会执行。执行流程是:先执行
catch块中的代码,当遇到return时,会先将要返回的值保存起来,然后去执行finally块,finally块执行完毕后,方法再带着之前保存的值返回。
2.3.4 [Java 7+] try-with-resources 最佳实践
核心用途与场景
用于自动管理和关闭实现了java.lang.AutoCloseable或java.io.Closeable接口的资源,如文件流、数据库连接等,以防止资源泄漏。
代码示例:优雅地关闭资源
1 | package com.example; |
结论:在处理任何可关闭的资源时,永远优先使用 try-with-resources,这是现代Java开发的标准实践。





