
Prorise
这是我的博客,分享技术与生活的点点滴滴
Ruo-Yi基础篇(五):第五章. 架构解构:浅析若依的“五脏六腑”
Ruo-Yi基础篇(五):第五章. 架构解构:浅析若依的“五脏六腑”
Prorise第五章. 架构解构:浅析若依的“五脏六腑”
摘要: 在前四章中,我们已经熟练掌握了若依的快速搭建、核心价值(代码生成)、核心概念(权限/字典/组织架构)以及系统监控。至此,我们已经具备了高效 “使用”和“管理” 若依的能力。本章,我们将开启一段全新的旅程,引导您从“使用者”向“开发者”迈出至关重要的一步。我们将不再聚焦于后台的界面操作,而是拿起“放大镜”和“手术刀”,深入前后端项目的源码,彻底解构支撑这一切高效运转的内部构造与设计哲学。
5.1. 后端架构:多模块的职责与协同
5.1.1.浅析设计哲学
我们初次用 IDE 打开若依的后端项目时,普遍会产生一个困惑:为什么不把所有代码都放在一个项目里?ruoyi-admin、ruoyi-common、ruoyi-system 等如此多的模块,它们各自的作用是什么?
这个问题的答案,根植于现代软件工程的核心设计原则——“分层架构”。对于一个企业级的、功能复杂的应用而言,将所有代码堆砌在一起会迅速导致项目变得难以维护、难以理解、难以扩展。若依的多模块(Multi-Module)架构正是为了解决这一难题而设计的。
我们将这种设计哲学带来的核心优势归纳为以下四点:
高内聚、低耦合
“内聚”指模块内部的各个元素(类、方法)联系的紧密程度,“耦合”则指模块与模块之间的依赖程度。一个优秀的架构追求高内聚、低耦合。在若依中,ruoyi-system模块只包含用户、角色、菜单等核心系统功能的代码(高内聚),而它与ruoyi-quartz(定时任务)模块之间没有直接的依赖关系(低耦合)。这使得我们在修改系统管理功能时,完全不必担心会影响到定时任务的逻辑。职责分离
每个模块都有其清晰、单一的职责。ruoyi-framework只负责框架层面的配置与支撑(如安全、数据源),ruoyi-common只提供全局通用的工具与实体。这种清晰的边界划分,使得我们遇到问题时,能够快速定位到应该检查哪个模块,极大地提升了开发和排错效率。可复用性
模块化设计天然地促进了代码复用。例如,ruoyi-common模块作为一个通用的工具包,它不依赖任何具体的业务。我们可以轻易地将其打包,并应用到公司内部的任何其他 Java 项目中,而无需进行任何修改。按需裁剪
并非所有项目都需要若依的全部功能。例如,如果我们的项目不需要代码生成或定时任务,我们可以直接在主模块ruoyi-admin的pom.xml中移除对ruoyi-generator和ruoyi-quartz的依赖。这样,这两个模块的功能就不会被打包到最终的可执行文件中,使得我们的应用更加轻量。
5.1.2. 核心模块地图:职责与定位
为了让大家对若依的后端结构形成一个清晰的“模块地图”,我们用表格的形式,为每个核心模块定义其精确的“角色卡”。当您看到某个模块名时,大脑中应能立刻浮现出它的核心职责。

| 模块名 | 核心职责 | 举例说明 |
|---|---|---|
ruoyi-admin | 启动入口 & 业务暴露层 | 包含 RuoYiApplication 启动类;存放所有业务 Controller(如我们生成的 CourseController)。它是整个应用的“总开关”和“接待大厅”。 |
ruoyi-system | 核心业务逻辑层 | 存放系统内置核心功能(用户、角色、菜单、部门等)的 Service 和 Mapper 接口及其实现。它是若依自带功能的“业务处理中心”。 |
ruoyi-framework | 框架核心配置与支撑 | 包含了 Spring Security 的安全配置、MyBatis 配置、全局拦截器、多数据源配置、权限服务 (ss) 等。它是整个应用的“骨架”和“神经中枢”。 |
ruoyi-common | 通用工具与核心域 | 存放全局共享的工具类 (StringUtils)、全局常量、自定义注解 (@Log)、核心实体基类 (BaseController, AjaxResult) 等。它是所有模块的“公共工具箱”。 |
ruoyi-generator | 代码生成器模块 (可移除) | 包含了代码生成器的独立引擎和相关逻辑。它是一个辅助开发的“工具”,与核心业务无关。 |
ruoyi-quartz | 定时任务模块 (可移除) | 封装了 Quartz 调度框架,用于执行定时任务。这也是一个相对独立的功能模块。 |
5.1.3. 依赖关系解密:Maven 如何协同工作
我们已经理解了每个模块的独立职责,现在需要探究它们是如何通过 Maven 这一构建工具,被有机地组织在一起协同工作的。
首先,我们通过中这一章依赖关系图,直观地感受一下这种组织结构。

这张图清晰地展示了一个“思维导图”式的分层结构。ruoyi-admin 在最顶层,依赖所有其他模块;ruoyi-common 在最底层,被所有模块依赖。这一切都由 pom.xml 文件精确定义。
我们将这个过程分为两步来理解:版本管理 与 依赖声明。
第一步:父工程的“版本管理中心” -
<dependencyManagement>
在多模块项目中,最大的挑战之一是保证所有模块使用的第三方依赖版本是一致的。如果ruoyi-system使用了fastjson-2.0.50,而ruoyi-framework却使用了fastjson-2.0.58,就可能引发难以预料的兼容性问题。为了解决这个问题,若依在最顶层的父工程pom.xml中使用了<dependencyManagement>标签。它的作用就像一个“版本管理中心”,它只 声明 依赖的版本,但 不实际引入。文件路径:
[项目根目录]/pom.xml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46<!-- 依赖声明 -->
<dependencyManagement>
<dependencies>
<!-- SpringBoot的依赖配置-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>3.5.4</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- 阿里数据库连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-3-starter</artifactId>
<version>${druid.version}</version>
</dependency>
<!-- ... 其他第三方依赖的版本声明 ... -->
<!-- 核心模块-->
<dependency>
<groupId>com.ruoyi</groupId>
<artifactId>ruoyi-framework</artifactId>
<version>${ruoyi.version}</version>
</dependency>
<!-- 系统模块-->
<dependency>
<groupId>com.ruoyi</groupId>
<artifactId>ruoyi-system</artifactId>
<version>${ruoyi.version}</version>
</dependency>
<!-- 通用工具-->
<dependency>
<groupId>com.ruoyi</groupId>
<artifactId>ruoyi-common</artifactId>
<version>${ruoyi.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
在这里,所有依赖(包括若依自身的模块)的版本都被统一管理。子模块在引入这些依赖时,将无需再指定版本号,Maven 会自动从父工程的“版本仲裁中心”获取。
第二步:子模块的“依赖声明” -
<dependencies>
当父工程定义好版本后,子模块就可以按需、清晰地声明自己需要哪些模块和工具了。我们以ruoyi-admin为例,它是整个应用的“组装车间”。文件路径:
ruoyi-admin/pom.xml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40<dependencies>
<!-- spring-boot-devtools -->
<dependency>
<groupId> org.springframework.boot </groupId>
<artifactId> spring-boot-devtools </artifactId>
<optional> true </optional> <!-- 表示依赖不会传递 -->
</dependency>
<!-- spring-doc -->
<dependency>
<groupId> org.springdoc </groupId>
<artifactId> springdoc-openapi-starter-webmvc-ui </artifactId>
</dependency>
<!-- Mysql驱动包 -->
<dependency>
<groupId> com.mysql </groupId>
<artifactId> mysql-connector-j </artifactId>
</dependency>
<!-- 核心模块-->
<dependency>
<groupId> com.ruoyi </groupId>
<artifactId> ruoyi-framework </artifactId>
</dependency>
<!-- 定时任务-->
<dependency>
<groupId> com.ruoyi </groupId>
<artifactId> ruoyi-quartz </artifactId>
</dependency>
<!-- 代码生成-->
<dependency>
<groupId> com.ruoyi </groupId>
<artifactId> ruoyi-generator </artifactId>
</dependency>
</dependencies>我们注意到,
ruoyi-admin在引入ruoyi-framework、ruoyi-quartz等模块时,只提供了groupId和artifactId,完全没有<version>标签。这正是<dependencyManagement>发挥作用的结果。这种做法极大地简化了子模块的pom.xml,并从根本上保证了整个项目的版本一致性。
5.1.4. ruoyi-common 深度剖析:通用能力的基石
我们首先将目光投向整个项目架构的最底层——ruoyi-common 模块。如果说 ruoyi-admin 是应用的“大脑”,那么 ruoyi-common 就是为整个身体提供基础营养和工具的“循环系统”。它被所有其他模块依赖,其核心定位是:提供独立于任何具体业务的、全局通用的工具类、核心实体定义与常量。
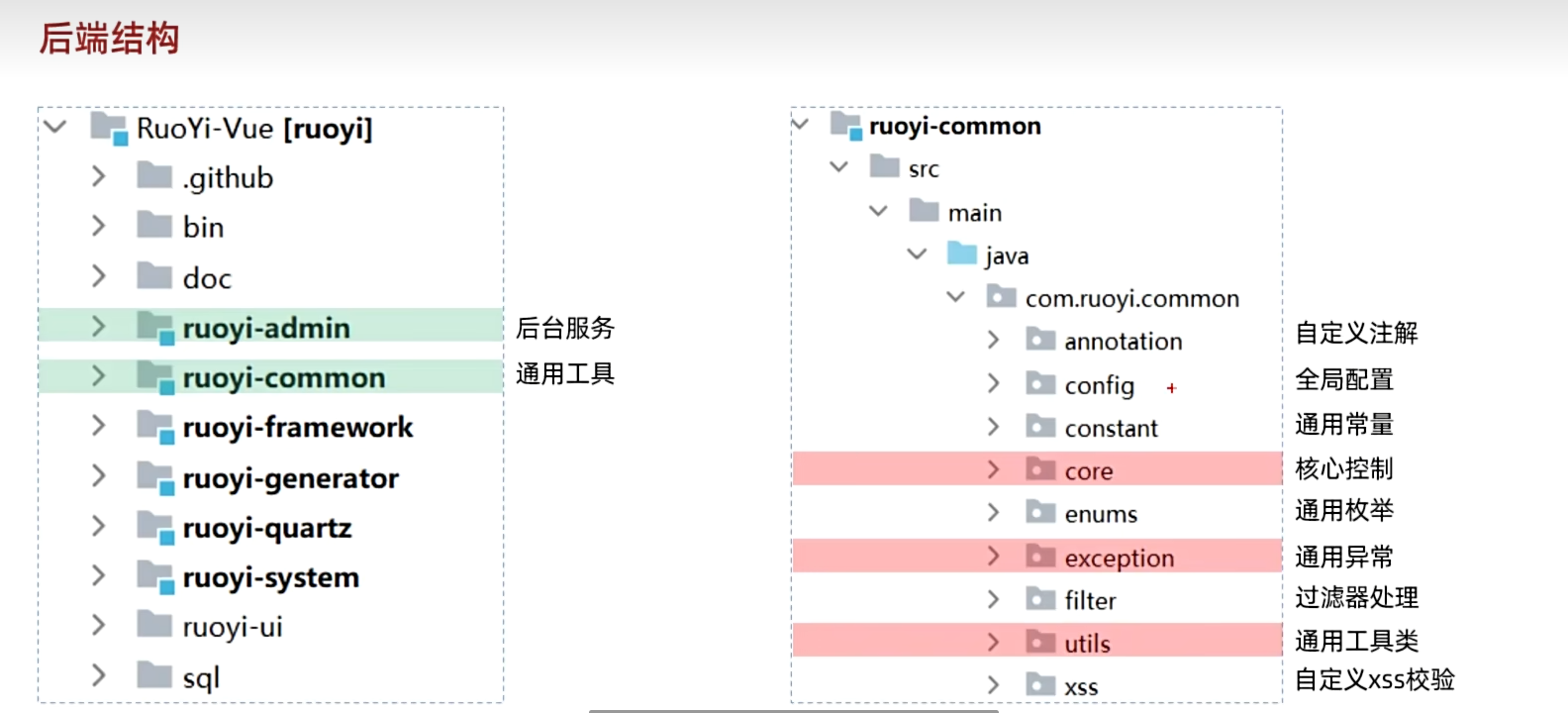
我们不必要深入分析这些提供好的工具类,而是深入其最核心的 core 包,通过“渐进式构建”的方式,来理解若依是如何通过它来解决开发中的普遍痛点的。
core包:核心抽象与封装
此包是ruoyi-common的心脏。我们首先聚焦于controller.BaseController,因为它是我们二次开发中接触最频繁、感受最直接的类。痛点场景: 设想一下,如果没有
BaseController,我们为“课程管理”编写一个分页查询方法,可能需要这样做:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// 一个没有继承 BaseController 的、重复繁琐的 Controller 示例
public class CourseController {
public Map<String, Object> list(HttpServletRequest request) {
// 1. 手动从 request 获取分页参数
int pageNum = Integer.parseInt(request.getParameter("pageNum"));
int pageSize = Integer.parseInt(request.getParameter("pageSize"));
// 2. 手动启动分页
PageHelper.startPage(pageNum, pageSize);
List<Course> list = courseService.selectCourseList();
PageInfo<Course> pageInfo = new PageInfo<>(list);
// 3. 手动封装成前端需要的格式
Map<String, Object> result = new HashMap<>();
result.put("code", 200);
result.put("msg", "查询成功");
result.put("rows", list);
result.put("total", pageInfo.getTotal());
return result;
}
}我们能看到大量的“样板代码”:手动解析参数、手动封装返回结果。每个需要分页的查询方法都这么写,无疑是一场灾难。若依的
BaseController正是为了根除这些痛点而设计的。现在,我们来逐步拆解它的核心能力。能力一:无感分页
startPage()
首先,BaseController承诺开发者无需再关心分页参数的获取。1
2
3
4
5
6
7
8
9// BaseController.java 的部分代码
/**
* 设置请求分页数据
*/
protected void startPage()
{
// 内部调用了 PageUtils 工具类,封装了从请求中获取参数的细节
PageUtils.startPage();
}- 逐行讲解: 这一行代码的背后,
PageUtils.startPage()会自动从HttpServletRequest中查找pageNum和pageSize等参数,并调用 MyBatis PageHelper 插件的PageHelper.startPage()方法。 - 核心原理: PageHelper 的核心是利用
ThreadLocal变量。当startPage()被调用时,分页参数会被存入当前线程的ThreadLocal中。随后,当这个线程执行 MyBatis 查询时,PageHelper 的拦截器会从ThreadLocal中取出分页参数,并自动地、动态地改写即将执行的 SQL 语句,为其加上LIMIT子句。这正是“无感分页”的魔力所在。
能力二:标准表格数据封装
getDataTable()
解决了分页,BaseController接着解决了响应封装的痛点。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// BaseController.java 的部分代码
/**
* 响应请求分页数据
*/
protected TableDataInfo getDataTable(List<?> list)
{
TableDataInfo rspData = new TableDataInfo();
rspData.setCode(HttpStatus.SUCCESS);
rspData.setMsg("查询成功");
rspData.setRows(list);
// 关键之处:从分页结果中获取总记录数
rspData.setTotal(new PageInfo(list).getTotal());
return rspData;
}- 逐行讲解: 这个方法接收一个
List(这正是 PageHelper 分页查询后返回的、只包含当前页数据的列表)。它创建了一个TableDataInfo对象,并设置了标准的状态码和消息。最关键的一行是rspData.setTotal(new PageInfo(list).getTotal()),PageHelper 在执行分页查询后,会将总记录数也存放在一个Page对象中,new PageInfo(list)正是用于从中提取出这个总记录数。
- 逐行讲解: 这一行代码的背后,
实战价值: 通过
startPage()+getDataTable()的组合,我们将之前那个繁琐的Controller方法,简化为了优雅的三行代码,这在 5.4 节 会有更详细的实战。能力三:统一操作结果响应
toAjax()
对于增、删、改操作,我们通常关心的是“操作是否成功”。BaseController为此提供了极致的便利。1
2
3
4
5
6
7
8
9
10
11// BaseController.java 的部分代码
/**
* 响应返回结果
*
* @param rows 影响行数
* @return 操作结果
*/
protected AjaxResult toAjax(int rows)
{
return rows > 0 ? AjaxResult.success() : AjaxResult.error();
}- 逐行讲解:
Service层的增删改方法通常返回一个int型的受影响行数。在Controller中,我们只需将这个int值传入toAjax()方法。这个方法通过一个简单的三元表达式,就将一个纯粹的技术性返回值(受影响行数),转换成了一个对前后端都有明确业务含义的AjaxResult对象(成功或失败)。这种封装,让我们的Controller代码不仅简洁,而且表意更加清晰。
- 逐行讲解:
通过对 BaseController 核心能力的“渐进式”剖析,我们已经深入理解了 ruoyi-common 的设计精髓。除了 BaseController,core.domain 包下的 AjaxResult(统一响应契约)、BaseEntity(通用字段基类),以及 exception(统一异常处理)、utils(静态工具库)和 annotation(AOP 注解)等包,共同构成了这个强大而可靠的项目基石。
5.1.5. ruoyi-framework 剖析:应用的骨架与安全中枢
如果说 ruoyi-common 是项目的“循环系统”,那么 ruoyi-framework 就是支撑整个应用的“底层骨架”与“安全系统”。它不包含任何具体业务逻辑,其核心职责是整合并配置 Spring Boot、Spring Security 等核心框架,为上层业务(如 ruoyi-system)提供一个稳定、安全、可依赖的运行环境。

我们将聚焦于其最重要的两个部分:config(框架配置)与 security(安全实现),来理解这个“骨架”是如何搭建起来的。
config包:框架级配置中心
此包是若依对所有第三方框架进行集中配置的地方。我们重点剖析其心脏——SecurityConfig.java。痛点场景: 在一个没有框架封装的 Spring Security 项目中,我们需要编写大量冗长的 XML 或 Java 配置来定义每一个 URL 的访问权限、指定登录页面、配置 session 策略、处理 CSRF 防护等等。这个过程极其繁琐且容易出错。
SecurityConfig.java的目的,就是将这些复杂的配置,用一种清晰、结构化的方式组织起来。我们来“渐进式”地解读
SecurityConfig.java的核心配置流程。第一步:开启方法级安全注解
1
2
3
4
5
6
7// SecurityConfig.java 的起始部分
public class SecurityConfig
{
// ...
}逐行讲解:
@EnableMethodSecurity(prePostEnabled = true)是整个若依权限体系的“总开关”。正是这个注解,激活了 Spring Security 对@PreAuthorize注解(我们在第三章使用过的)的解析能力。一旦开启,Spring AOP 就会为所有标记了@PreAuthorize的方法创建一个代理,在方法执行前,检查当前用户的权限是否满足注解中定义的表达式(如@ss.hasPermi('course:course:list'))。第二步:构建核心过滤器链
filterChain()
这是安全配置的核心,它像一个“安检流水线”,定义了所有 HTTP 请求需要经过哪些安全检查站。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26a
// SecurityConfig.java 的核心方法
protected SecurityFilterChain filterChain(HttpSecurity httpSecurity) throws Exception
{
return httpSecurity
// CSRF 禁用,因为我们是前后端分离,通过 token 认证,不依赖 session 和 cookie
.csrf(csrf -> csrf.disable())
// ... 其他基础配置 ...
// 基于 token,所以不需要 session,设置为无状态
.sessionManagement(session -> session.sessionCreationPolicy(SessionCreationPolicy.STATELESS))
// 配置 URL 的访问权限
.authorizeHttpRequests((requests) -> {
// 允许匿名访问的路径,通常由配置文件读取
permitAllUrl.getUrls().forEach(url -> requests.requestMatchers(url).permitAll());
// 硬编码的匿名访问路径,如登录、注册、获取验证码
requests.requestMatchers("/login", "/register", "/captchaImage").permitAll()
// 除上面外的所有请求,全部需要经过身份认证
.anyRequest().authenticated();
})
// ... 添加自定义过滤器 ...
.build();
}- 逐行讲解:
.csrf(csrf -> csrf.disable()): 在前后端分离的架构中,认证信息通过Authorization头中的 Token 传递,不依赖于浏览器的 Cookie-Session 机制,因此传统的 CSRF(跨站请求伪造)攻击方式不再适用,可以安全地禁用它。.sessionManagement(...STATELESS): 明确告诉 Spring Security,我们的应用是“无状态”的,服务端不会创建或维护任何HttpSession,每次请求都将独立认证。这是构建可伸缩、高性能服务的关键。.authorizeHttpRequests(...): 这是 URL 权限配置的核心。若依采用“白名单”策略:先通过permitAll()方法,明确定义哪些路径(如登录页、静态资源)无需认证即可访问;然后通过.anyRequest().authenticated(),规定 除此之外的所有其他请求 都必须经过身份认证。
- 逐行讲解:
security包:安全机制的具体实现SecurityConfig搭建了骨架,而security包则为这个骨架填充了“血肉”。我们重点关注filter.JwtAuthenticationTokenFilter,它是若依 Token 认证机制的“心脏”。痛点场景:
SecurityConfig只规定了“哪些请求需要认证”,但并没有说明“如何进行认证”。JwtAuthenticationTokenFilter的职责,就是在每个需要认证的请求到达时,执行具体的 Token 校验和用户身份构建工作。doFilterInternal()方法的执行流程:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26// JwtAuthenticationTokenFilter.java 的核心方法
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain chain)
throws ServletException, IOException
{
// 1. 从请求中获取 LoginUser 对象(TokenService 内部会解析请求头中的 Token)
LoginUser loginUser = tokenService.getLoginUser(request);
// 2. 判断用户是否存在,且当前上下文中没有认证信息
if (StringUtils.isNotNull(loginUser) && StringUtils.isNull(SecurityUtils.getAuthentication()))
{
// 3. 验证 Token 有效性(例如,检查是否过期)
tokenService.verifyToken(loginUser);
// 4. 构建一个代表当前用户的认证成功的令牌(AuthenticationToken)
UsernamePasswordAuthenticationToken authenticationToken = new UsernamePasswordAuthenticationToken(loginUser, null, loginUser.getAuthorities());
authenticationToken.setDetails(new WebAuthenticationDetailsSource().buildDetails(request));
// 5. 将这个令牌存入 SecurityContextHolder,完成认证
// 后续的 Spring Security 组件(如 AOP 注解)就可以从这里获取到当前用户信息了
SecurityContextHolder.getContext().setAuthentication(authenticationToken);
}
// 6. 放行请求,让它继续走向 Controller
chain.doFilter(request, response);
}- 核心原理: 这个过滤器继承自
OncePerRequestFilter,确保在一次请求中只执行一次。它的核心逻辑是:- 调用
TokenService从请求的Authorization头中解析出 JWT。 - 如果解析成功并获取到
LoginUser(代表用户已登录且 Token 有效),并且当前SecurityContextHolder中是空的(说明这是本次请求的第一次认证)。 - 它会创建一个
UsernamePasswordAuthenticationToken对象,这个对象是 Spring Security 内部用来表示“一个已认证用户”的标准凭证。 - 最后,它将这个凭证放入
SecurityContextHolder这个线程绑定的“全局容器”中。一旦SecurityContextHolder中有了认证信息,后续的所有安全检查(比如@PreAuthorize注解)就都可以从中获取到当前用户的身份和权限,从而做出正确的决策。
- 调用
- 核心原理: 这个过滤器继承自
通过对 ruoyi-framework 的剖析,我们理解了若依是如何利用 Spring Security 构建起一个强大的、基于 Token 的、无状态的安全体系的。这套体系既保证了应用的安全性,又为二次开发提供了清晰的扩展点。
5.1.6. ruoyi-system 剖析:内置核心业务的“示范样本”
在理解了底层的工具与框架模块后,我们现在聚焦于真正承载 业务逻辑 的 ruoyi-system 模块。我们必须明确其定位:它并 不是 一个框架或工具模块,而是若依 内置核心业务 的实现模块。它本身就是一个标准的、自包含的业务模块范例,是我们在进行二次开发时最好的“活教材”和“最佳实践参考”。
ruoyi-system 的代码组织结构
痛点场景: 当我们准备进行二次开发,想要添加一个新的业务模块(例如“订单管理”)时,最常问的问题是:“我的代码应该如何组织?domain、service、mapper 应该怎么写?”
ruoyi-system 模块通过其清晰的目录结构,给出了这个问题的标准答案。
1 | . 📂 ruoyi-system |
这是一种经典且高效的三层架构实现:
domain层:业务实体的定义- 职责: 此目录下的 Java 类(如
SysUser.java,SysRole.java)是业务领域模型的实体映射。它们是纯粹的数据载体(POJO),负责定义业务对象的属性,与数据库表结构一一对应。
- 职责: 此目录下的 Java 类(如
mapper层:数据访问的接口与实现- 职责: 此层是与数据库打交道的 唯一 入口,实现了数据访问与上层业务逻辑的彻底隔离。
mapper/目录下的 Java 接口(如SysUserMapper.java)定义了所有数据库操作的方法签名。resources/mapper/system/目录下的 XML 文件(如SysUserMapper.xml)则通过 MyBatis 的 SQL 标签,编写了这些接口方法对应的具体 SQL 语句。
- 职责: 此层是与数据库打交道的 唯一 入口,实现了数据访问与上层业务逻辑的彻底隔离。
service层:业务逻辑的核心- 职责: 如果说
mapper层执行的是“原子操作”(单次数据库交互),那么service层就是负责编排这些原子操作,来完成一个完整、复杂的业务功能的“指挥官”。service/目录下的接口(如ISysUserService.java)定义了业务层需要对外提供的能力契约。service/impl/目录下的实现类(如SysUserServiceImpl.java)则是业务规则、事务管理、缓存处理、权限校验等复杂逻辑的真正所在地。
- 职责: 如果说
为了具体地理解 Service 层是如何“指挥”和“编排”的,我们深入到 SysUserServiceImpl.java 中,通过其 insertUser 方法,来观察一个“新增用户”功能的完整实现过程。
痛点场景: 一个看似简单的“新增用户”功能,背后其实隐藏着多个业务步骤和规则:不仅要插入用户基本信息,还要建立用户与岗位、用户与角色的关联关系,并且这一切操作必须保证 事务性——要么全部成功,要么全部失败。
SysUserServiceImpl.java 中的 insertUser 方法完美地展示了如何处理这种复杂场景。
第一步:事务管理与方法签名
1 | // SysUserServiceImpl.java 的部分代码 |
- 逐行讲解:
@Transactional注解是 Spring 提供的声明式事务管理。一旦标记在此方法上,Spring AOP 会为它创建一个代理。在方法开始执行前,代理会自动开启一个数据库事务;如果方法成功执行完毕,事务会自动提交;如果方法在执行过程中抛出任何运行时异常,事务会自动回滚。这确保了“新增用户”操作的原子性。
第二步:编排多个 Mapper 完成核心业务
1 | // insertUser 方法的核心逻辑 |
- 逐行讲解: 这里清晰地展示了
Service层的“编排”职责。它没有自己编写任何 SQL,而是像指挥官一样,依次调用三个不同的Mapper(或封装了Mapper调用的内部方法)来协同完成任务:userMapper.insertUser(user): 完成最基础的用户信息持久化。insertUserPost(user): 内部会调用userPostMapper,将用户 ID 和岗位 ID 批量插入到sys_user_post关联表中。insertUserRole(user): 内部会调用userRoleMapper,将用户 ID 和角色 ID 批量插入到sys_user_role关联表中。
这三个步骤被 @Transactional 注解紧密地包裹在一个事务中,共同构成了一个不可分割的业务单元。
通过对 ruoyi-system 模块的结构与核心代码的深度剖析,我们不仅理解了若依内置功能的实现方式,更重要的是,我们掌握了一套可以在自己二次开发中直接应用的、标准的、健壮的业务分层与代码组织范式。
5.1.7. ruoyi-admin 剖析:应用的入口与配置中心
我们终于来到了项目架构的最顶层——ruoyi-admin 模块。如果说其他模块是各司其职的“零部件”,那么 ruoyi-admin 就是将所有零部件最终组装起来的“总装车间”和“主控制台”。它扮演着两个至关重要的角色:应用启动入口 和 全局配置中心。
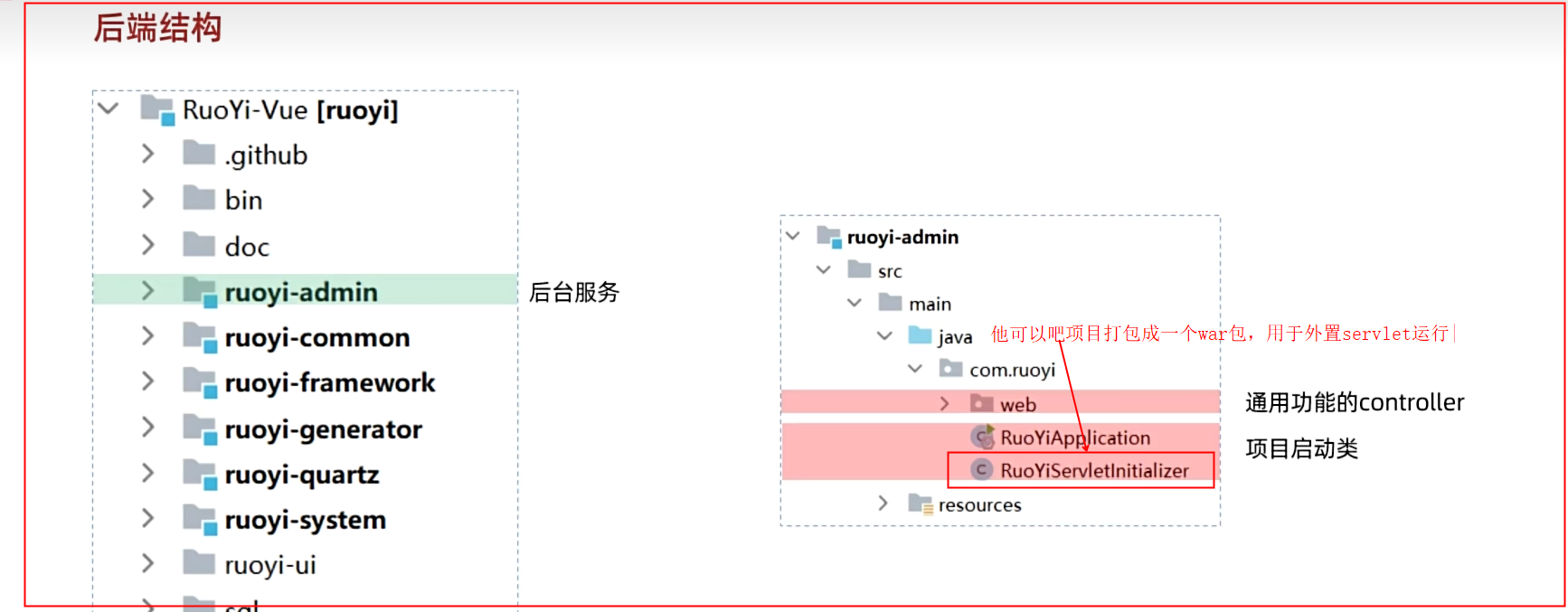
应用启动入口
这是ruoyi-admin最核心的职责。应用的“点火”操作,正是在这个模块中完成的。文件路径:
ruoyi-admin/src/main/java/com/ruoyi/RuoYiApplication.java1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20package com.ruoyi;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration;
/**
* 启动程序
*
* @author ruoyi
*/
public class RuoYiApplication
{
public static void main(String[] args)
{
SpringApplication.run(RuoYiApplication.class, args);
// ... 打印启动成功 banner ...
}
}Controller聚合器与业务暴露层
正如ruoyi-admin的目录结构所示,它内部的web/controller目录聚合了来自不同模块的Controller,是所有 HTTP 请求的统一入口。system包下的Controller(如SysUserController)负责暴露ruoyi-system模块的业务接口。monitor包下的Controller(如ServerController)负责暴露系统监控相关的接口。- 我们自己生成的
course包下的Controller,也自然地归属在这里。
ruoyi-admin 的配置中心体系
ruoyi-admin 的 src/main/resources 目录,是整个应用的 主配置中心,存放了所有与应用运行相关的配置文件。

application.yml:主配置文件
这是应用的核心配置文件,采用 YAML 格式,层级清晰。它定义了应用的基础行为。我们重点解读几个核心配置:在传统 Spring 项目中,我们需要编写大量 XML 来配置端口、上下文路径、Redis 连接等。
application.yml通过“约定优于配置”的思想,极大地简化了这些工作。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 开发环境配置
server:
# 服务器的HTTP端口,默认为8080
port: 8080
servlet:
# 应用的访问路径
context-path: /
# Spring配置
spring:
# redis 配置
redis:
# 地址
host: localhost
# 端口,默认为6379
port: 6379这种声明式的配置方式直观易懂。Spring Boot 在启动时会自动读取这些配置,并应用到相应的组件中。例如,
server.port: 8080会直接配置内嵌的 Tomcat 服务器监听8080端口。application-{profile}.yml:环境分离的艺术
我们注意到还有一个application-druid.yml文件。这是 Spring Boot Profiles(环境配置) 功能的体现。在
application.yml中有这样一行配置:1
2
3spring:
profiles:
active: druid- 核心原理: 这一行配置告诉 Spring Boot:“在加载主配置文件
application.yml之后,请继续加载名为application-druid.yml的配置文件”。application-druid.yml中的配置项会 覆盖 主配置文件中的同名项。 - 实战价值: 这种机制在多环境部署(如开发
dev、测试test、生产prod)时至关重要。我们可以创建application-dev.yml,application-prod.yml等文件,在其中定义不同环境下的数据库地址、Redis 地址等。部署时,只需通过启动参数(如-Dspring.profiles.active=prod)来切换环境,而无需修改任何代码或配置文件本身。
- 核心原理: 这一行配置告诉 Spring Boot:“在加载主配置文件
通过对 ruoyi-admin 模块的剖析,我们理解了它作为“总装车间”和“主控制台”的核心地位。它不仅是应用的启动入口,更是所有模块 Controller 的聚合点和所有配置文件的管理中心,将整个多模块项目有机地融为一体。
5.2. 前端架构:项目结构与核心文件导览
5.2.1. 工程化基石:.env 环境配置与 package.json 依赖蓝图
在深入若依前端的源码之前,我们必须先理解其工程化的两大基石:用于管理多环境配置的 .env 文件体系,以及定义项目依赖与脚本的 package.json。它们共同决定了项目的构建行为和运行环境。
.env 环境配置:构建不同环境的“配置文件”
痛点场景: 在软件开发中,开发、测试、生产环境的 API 地址、应用标题等配置通常是不同的。如果将这些配置硬编码在代码中,每次部署都需要手动修改,极其繁琐且容易出错。
若依采用了 Vite 支持的 .env 文件体系来优雅地解决此问题。在项目根目录下,我们可以看到三个核心的 .env 文件:
.env.development: 开发环境配置文件1
2
3
4
5
6
7
8# 页面标题
VITE_APP_TITLE = 若依管理系统
# 开发环境配置
VITE_APP_ENV = 'development'
# API 请求基础路径(用于代理)
VITE_APP_BASE_API = '/dev-api'.env.production: 生产环境配置文件1
2
3
4
5
6
7
8# 页面标题
VITE_APP_TITLE = 若依管理系统
# 生产环境配置
VITE_APP_ENV = 'production'
# API 请求基础路径
VITE_APP_BASE_API = '/prod-api'.env.staging: 预发布(测试)环境配置文件1
2
3
4
5
6
7
8# 页面标题
VITE_APP_TITLE = 若依管理系统
# 预发布环境配置
VITE_APP_ENV = 'staging'
# API 请求基础路径
VITE_APP_BASE_API = '/stage-api'
核心工作机制:
这个体系的核心在于 package.json 中的 scripts 命令与 Vite 的构建模式(mode)相结合。
1 | // package.json |
- 工作流剖析:
- 当我们执行
pnpm dev时,Vite 会自动加载.env.development文件。 - 当我们执行
pnpm build:prod时,--mode production参数会告诉 Vite 去加载.env.production文件。 - Vite 会将这些文件中以
VITE_开头的变量,注入到一个名为import.meta.env的全局环境变量对象中。 - 在项目的任何地方(如
request.js中),我们都可以通过import.meta.env.VITE_APP_BASE_API来获取当前环境对应的 API 基础路径。
- 当我们执行
通过这种方式,若依实现了配置与代码的完全分离,使得一次构建、多环境部署成为可能。
package.json:项目的“依赖蓝图”与“脚本中心”
package.json 文件是前端项目的“心脏”,它详细描述了项目的构成。我们将其核心内容归纳为两部分:依赖蓝图和脚本中心。
- 依赖蓝图 (
dependencies&devDependencies)
若依 Vue3 版精心选择了一系列高质量的第三方库来构建其功能。我们将核心依赖按其作用进行分类归纳:
| 分类 | 核心依赖 | 版本 | 作用说明 |
|---|---|---|---|
| Vue 全家桶 | vue | 3.5.16 | 核心框架 |
vue-router | 4.5.1 | 官方路由管理器 | |
pinia | 3.0.2 | 官方状态管理器(替代 Vuex) | |
| UI 组件库 | element-plus | 2.10.7 | 核心 UI 组件库 |
@element-plus/icons-vue | 2.3.1 | Element Plus 图标库 | |
| HTTP 通信 | axios | 1.9.0 | 强大的 HTTP 客户端,用于与后端交互 |
| 功能插件 | @vueup/vue-quill | 1.2.0 | 富文本编辑器 |
echarts | 5.6.0 | 数据可视化图表库 | |
sortablejs | 1.15.6 | 拖拽排序库 | |
vue-cropper | 1.1.1 | 图片裁剪组件 | |
| 开发工具 | vite | 6.3.5 | (Dev) 项目构建与开发服务器引擎 |
sass-embedded | 1.89.1 | (Dev) CSS 预处理器,用于编写 SCSS | |
unplugin-auto-import | 0.18.6 | (Dev) 自动导入 API 插件,简化编码 | |
vite-plugin-svg-icons | 2.0.1 | (Dev) SVG 图标自动化处理插件 |
脚本中心 (
scripts)scripts字段定义了项目的标准工作流命令。1
2
3
4
5
6"scripts": {
"dev": "vite",
"build:prod": "vite build --mode production",
"build:stage": "vite build --mode staging",
"preview": "vite preview"
},dev: 启动开发服务器,用于日常开发和调试。build:prod: 执行生产环境打包。此命令会读取.env.production,并对代码进行压缩、混淆、Tree-shaking 等优化,生成用于线上部署的静态文件。build:stage: 执行预发布环境打包,读取.env.staging。preview: 在本地预览打包后的生产环境产物,用于部署前的最后检查。
通过对 .env 文件体系和 package.json 的深度剖析,我们理解了若依前端项目是如何管理多环境配置,以及如何组织和构建其庞大的依赖体系的。这为我们后续深入源码打下了坚实的基础。
5.2.2. vite.config.js 深度剖析:项目的“构建总管”
在理解了 .env 和 package.json 如何定义项目的环境与依赖后,我们现在聚焦于驱动这一切运转的“引擎室”——vite.config.js。此文件是 Vite 的主配置文件,负责项目的开发服务器、打包构建、插件集成等所有核心行为。
如果说 package.json 定义了“用什么工具”,那么 vite.config.js 则详细规定了“如何使用这些工具”。它是 Vite 的主配置文件,负责开发服务器、项目打包、插件集成等所有行为。
文件路径: [项目根目录]/vite.config.js
1 | import { defineConfig, loadEnv } from 'vite' |
渐进式解读
plugins: Vite 的核心优势之一在于其插件化的生态系统。若依将所有 Vite 插件的配置都收敛到了 vite/plugins 目录中,并通过 createVitePlugins 函数统一引入。例如,vite/plugins/svg-icon.js 插件负责将 src/assets/icons/svg 目录下的所有 SVG 图标文件,自动处理成可在 Vue 组件中直接使用的图标组件。这种插件化机制使得 vite.config.js 保持了高度的整洁。
resolve.alias: 这是提升开发效率的关键配置。'@': path.resolve(__dirname, './src') 这一行定义了一个路径别名,意味着在项目的任何地方,我们都可以使用 @ 来代替冗长的相对路径(如 ../../..),直接指向 src 目录。这使得代码中的模块导入语句更加清晰和易于维护。
server.proxy: 这是解决开发环境跨域问题的核心。
首先,我们必须理解其解决的痛点:前端开发服务器运行在 80 端口,而后端 API 在 8080 端口,这构成了浏览器安全策略中的“跨域”,直接访问会被阻止。
若依的解决方案如下:
1 | '/dev-api': { |
这段配置的含义是:
拦截规则
Vite 开发服务器会监听所有由前端发起的请求。如果请求的 URL 以/dev-api开头,则触发此代理规则。目标服务器
Vite 会将这个被拦截的请求转发给target指定的地址,即http://localhost:8080。changeOrigin: true
在转发时,将请求头中的Host字段从当前的前端地址(如localhost:80)修改为目标服务器的地址。这是确保后端能正确处理请求的关键。rewrite
在将请求真正发送给后端之前,使用rewrite函数重写 URL,将/dev-api前缀去掉。例如,前端请求/dev-api/system/user/list,最终到达后端的将是/system/user/list。
通过对这两个核心文件的剖析,我们理解了若依前端项目是如何通过 package.json 管理依赖,并通过 vite.config.js 进行高效、灵活的工程化配置,为快速开发奠定了坚实的基础。
5.2.3. 项目目录结构与核心文件导览
在理解了若依前端的工程化基础设施后,我们现在需要从整体上把握项目的目录组织架构。一个清晰的目录结构,不仅能让开发者快速定位代码位置,更体现了项目的设计思想和分层理念。
痛点场景: 面对一个拥有数百个文件的前端项目,如果没有清晰的目录规范,开发者往往会陷入 “找不到代码在哪”、“不知道该把新功能写在哪” 的困境。若依通过精心设计的目录结构,将不同职责的代码严格分离,实现了高内聚、低耦合的架构目标。
5.2.3.1. 项目目录树:清晰的分层架构
若依 Vue3 版采用了标准的 Vue 3 + Vite 项目结构,在 src/ 目录下按功能模块进行了精细化分层。以下是核心目录结构的可视化展示:

5.2.3.2. 核心目录职责解析
若依的目录设计遵循了 按职责分层、按业务分模块 的原则。我们将各目录的核心职责归纳如下:
| 目录 | 职责定位 | 核心作用 | 典型文件示例 |
|---|---|---|---|
api/ | API 接口层 | 统一管理所有后端接口调用,按业务模块分类,与后端 Controller 层一一对应 | system/user.js 对应后端 UserController |
assets/ | 静态资源库 | 存放图片、图标、样式等静态资源,由 Vite 在构建时处理 | icons/svg/ 存放 89 个 SVG 图标 |
components/ | 全局组件库 | 存放项目级别的公共组件,可在任何页面中复用 | Pagination 分页组件被数十个列表页使用 |
directive/ | 自定义指令 | 封装 Vue 自定义指令,提供权限控制、DOM 操作等功能增强 | v-hasPermi 实现按钮级权限控制 |
layout/ | 布局框架 | 定义系统的整体布局结构(顶栏、侧边栏、内容区),所有业务页面都嵌套在此布局中 | Sidebar 侧边栏根据权限动态渲染菜单 |
plugins/ | 功能插件层 | 封装常用功能为插件,挂载到 Vue 实例,方便全局调用 | $modal.msg() 统一的消息提示 |
router/ | 路由配置 | 管理前端路由,包括静态路由与动态权限路由 | 区分 constantRoutes 和 dynamicRoutes |
store/ | 状态管理 | 基于 Pinia 的集中式状态管理,按模块拆分 | user.js 管理登录用户信息与 Token |
utils/ | 工具函数库 | 封装通用的工具函数,提供可复用的业务逻辑 | request.js 是 Axios 的二次封装,统一处理请求响应 |
views/ | 页面视图层 | 按业务模块组织的页面组件,是用户直接交互的界面 | system/user/index.vue 用户管理页面 |
设计亮点:
- API 层与视图层分离:
api/和views/严格分离,即使切换 UI 框架,API 层代码也无需修改。 - 组件分级管理:全局组件放
components/,页面专属组件放在对应的views/子目录下。 - 工具函数模块化:
utils/按功能拆分成多个文件,避免单一文件过于庞大。
5.2.3.3. 核心文件用途浅析
除了目录结构,若依还有几个 位于 src/ 根目录的核心文件,它们是整个应用的 “枢纽”,在系统启动和运行过程中扮演着关键角色。
main.js - 应用的 “启动引擎”
文件路径: src/main.js
这是整个 Vue 应用的入口文件,负责创建 Vue 实例并完成初始化工作。其核心职责包括:
创建 Vue 应用实例
1
const app = createApp(App)
注册全局插件与组件
1
2
3app.use(router) // 注册路由
app.use(store) // 注册 Pinia 状态管理
app.use(ElementPlus) // 注册 Element Plus UI 库挂载全局方法到 Vue 实例
1
2app.config.globalProperties.useDict = useDict // 字典工具
app.config.globalProperties.download = download // 下载工具注册全局组件(高频使用的组件)
1
2app.component('Pagination', Pagination) // 分页组件
app.component('DictTag', DictTag) // 字典标签加载权限控制
1
import './permission' // 导入权限控制逻辑,启动路由守卫
通过 main.js 的统一初始化,确保了整个应用在启动时就完成了所有必要的配置和注册工作。
permission.js - 权限控制的 “守门员”
文件路径: src/permission.js
此文件实现了全局的路由守卫(Route Guard),是若依权限体系的核心。它在 每次路由跳转前 都会执行检查,决定用户是否有权访问目标页面。
核心工作流程:
1 | router.beforeEach((to, from, next) => { |
解决的核心问题:
- 未登录用户访问受保护页面时,自动跳转登录页
- 已登录用户首次访问时,动态加载其有权限的路由
- 实现了基于角色和权限的精细化访问控制
router/index.js - 路由配置中心
文件路径: src/router/index.js
此文件是前端路由的定义中心,采用了 静态路由 + 动态路由 的混合模式。
两类路由:
constantRoutes(静态路由):无需权限即可访问的公共路由1
2
3
4
5export const constantRoutes = [
{ path: '/login', component: () => import('@/views/login') },
{ path: '/404', component: () => import('@/views/error/404') },
{ path: '/index', component: () => import('@/views/index') }
]dynamicRoutes(动态路由):需要根据用户权限动态加载的路由1
2
3
4
5
6
7
8export const dynamicRoutes = [
{
path: '/system/user-auth',
permissions: ['system:user:edit'], // 需要特定权限
component: Layout,
children: [...]
}
]
核心特性:
- 使用
createWebHistory()启用 HTML5 History 模式(无#号) - 路由配置中的
meta字段携带了页面标题、图标、权限等元数据 - 通过
hidden: true控制路由是否在侧边栏菜单中显示
utils/request.js - HTTP 通信的 “总管”
文件路径: src/utils/request.js
这是若依对 Axios 进行的二次封装,统一管理所有 HTTP 请求和响应的处理逻辑。
核心功能:
请求拦截器(Request Interceptor)
- 自动在请求头中添加
Authorization: Bearer [token],实现身份认证 - 防止重复提交(通过缓存机制判断短时间内的重复请求)
- 自动在请求头中添加
响应拦截器(Response Interceptor)
- 统一处理后端返回的状态码(如 401 未授权、500 服务器错误)
- 根据不同的错误码,自动弹出相应的提示信息
- Token 过期时自动弹窗提示用户重新登录
全局配置
1
2
3
4const service = axios.create({
baseURL: import.meta.env.VITE_APP_BASE_API, // 从环境变量读取 API 基础路径
timeout: 10000 // 请求超时时间
})
设计优势:所有页面的 API 调用都通过这个封装的 request 实例,确保了请求处理逻辑的一致性,避免了在每个 API 文件中重复编写认证、错误处理等代码。
store/index.js - 状态管理入口
文件路径: src/store/index.js
若依 Vue3 版使用了 Pinia(Vue 3 官方推荐的状态管理库)替代 Vuex。此文件仅包含 Pinia 实例的创建:
1 | const store = createPinia() |
真正的状态管理逻辑被拆分到了 store/modules/ 目录下的各个模块中:
user.js:管理用户登录状态、Token、角色权限等permission.js:管理动态路由和菜单settings.js:管理系统设置(如侧边栏主题、是否显示标签页等)tagsView.js:管理多标签页的打开/关闭状态
这种模块化的拆分方式,使得状态管理的职责更加清晰,易于维护。
App.vue - 根组件
文件路径: src/App.vue
这是 Vue 应用的根组件,结构极其简洁:
1 | <template> |
它的职责仅仅是渲染路由匹配到的组件。真正的布局结构(侧边栏、顶栏等)由 layout/index.vue 负责。
在 <script setup> 中,它完成了主题样式的初始化:
1 | onMounted(() => { |
settings.js - 系统全局配置
文件路径: src/settings.js
此文件定义了系统的默认配置项,如:
1 | export default { |
这些配置会被 store/modules/settings.js 读取并存入状态管理,用户在 “系统设置” 页面修改这些选项时,实际上是在更新 Store 中的状态。
5.3. 数据库设计:表结构与数据模型深度解析
在深入理解了若依的前端架构后,我们现在将目光转向系统的 “地基”——数据库表设计。一个优秀的表结构设计,不仅决定了系统的数据存储效率,更直接影响着业务逻辑的实现复杂度和系统的可扩展性。
痛点场景: 在企业级应用开发中,权限管理、日志记录、定时任务等功能几乎是标配需求。如果没有成熟的数据库表设计方案,开发者往往会陷入 “表结构设计不合理导致查询性能低下”、“权限控制逻辑复杂度爆炸”、“表关系混乱导致数据一致性问题” 等困境。
若依通过精心设计的 19 张核心业务表 + 11 张 Quartz 调度表,构建了一套完整、规范、可扩展的数据模型体系。我们将按功能模块对这些表进行分类剖析。
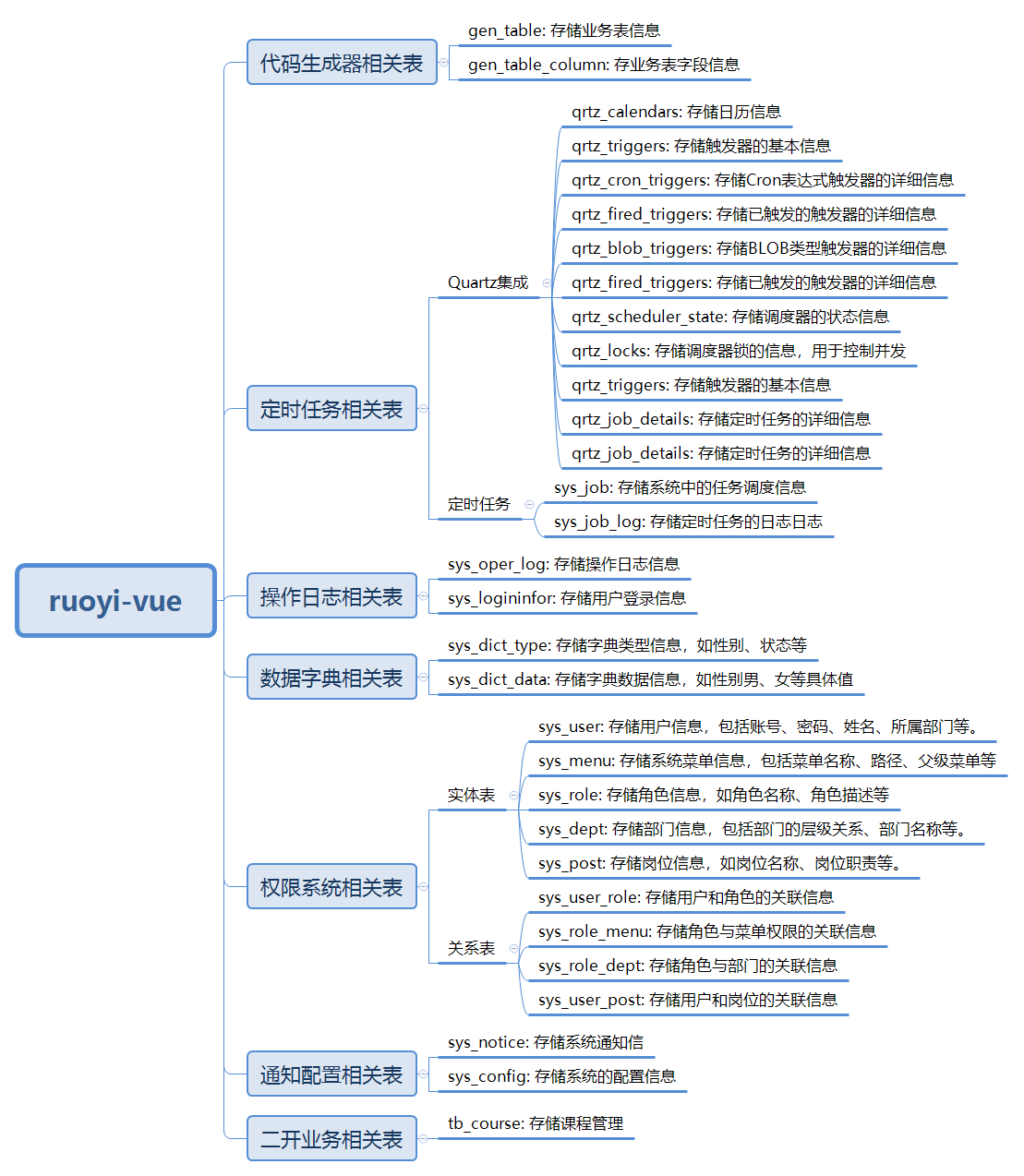
5.3.1. 核心权限管理表群:RBAC 模型的五表联动
若依采用了业界成熟的 RBAC(基于角色的访问控制) 模型,通过 5 张核心表实现了 “用户-角色-权限” 的灵活映射关系。
5.3.1.1. RBAC 模型概述
RBAC 核心思想:不直接给用户分配权限,而是先将用户归入不同的角色,再给角色分配权限。这种间接授权的方式,极大地降低了权限管理的复杂度。
若依的 RBAC 实现包含以下核心表:
| 表名 | 作用 | 表类型 | 核心字段 |
|---|---|---|---|
sys_user | 用户信息表 | 实体表 | user_id, user_name, password, dept_id, status |
sys_role | 角色信息表 | 实体表 | role_id, role_name, role_key, data_scope |
sys_menu | 菜单权限表 | 实体表 | menu_id, menu_name, perms, menu_type |
sys_user_role | 用户角色关联表 | 关联表 | user_id, role_id |
sys_role_menu | 角色菜单关联表 | 关联表 | role_id, menu_id |
表关系图示:
1 | sys_user (用户) |
5.3.1.2. 用户信息表 (sys_user)
表定义:
1 | create table sys_user ( |
核心字段解析:
| 字段 | 类型 | 作用 | 设计亮点 |
|---|---|---|---|
user_id | bigint(20) | 用户唯一标识 | 使用 bigint 支持海量用户,自增主键 |
dept_id | bigint(20) | 所属部门 ID | 关联 sys_dept 表,支持组织架构管理 |
password | varchar(100) | 加密后的密码 | 存储 BCrypt 加密后的密文,长度 100 足够 |
status | char(1) | 账号状态 | 0 正常 1 停用,支持账号禁用而不删除 |
del_flag | char(1) | 删除标志 | 逻辑删除标记,0 存在 2 删除,保留历史数据 |
pwd_update_date | datetime | 密码更新时间 | 用于实现密码过期策略,提升安全性 |
login_ip / login_date | varchar / datetime | 登录信息 | 记录最后登录位置,方便安全审计 |
设计亮点:
- 逻辑删除机制:使用
del_flag实现软删除,保留用户历史数据用于审计。 - 密码安全策略:
pwd_update_date字段支持密码过期提醒,强化安全性。 - 部门关联:通过
dept_id外键,将用户与组织架构绑定,支持数据权限控制。
5.3.1.3. 角色信息表 (sys_role)
表定义:
1 | create table sys_role ( |
核心字段解析:
| 字段 | 类型 | 作用 | 设计亮点 |
|---|---|---|---|
role_key | varchar(100) | 角色权限标识 | 如 admin、common,用于代码中的角色判断 |
data_scope | char(1) | 数据权限范围 | 核心字段,控制用户能看到的数据范围 |
menu_check_strictly | tinyint(1) | 菜单树关联显示 | 控制父子菜单的联动选择行为 |
数据权限范围详解(data_scope):
| 值 | 含义 | 应用场景 |
|---|---|---|
1 | 全部数据权限 | 超级管理员,可查看所有数据 |
2 | 自定义数据权限 | 通过 sys_role_dept 表指定可访问的部门 |
3 | 本部门数据权限 | 只能查看自己所在部门的数据 |
4 | 本部门及以下数据权限 | 可查看本部门及其所有子部门的数据 |
5 | 仅本人数据权限 | 只能查看自己创建的数据 |
设计亮点:data_scope 字段是若依权限体系的 核心创新点,它将数据权限控制从代码逻辑中抽离出来,通过配置即可实现灵活的数据隔离。例如,在查询用户列表时,SQL 会根据当前用户的角色 data_scope 自动拼接不同的 WHERE 条件。
5.3.1.4. 菜单权限表 (sys_menu)
表定义:
1 | create table sys_menu ( |
核心字段解析:
| 字段 | 类型 | 作用 | 设计亮点 |
|---|---|---|---|
parent_id | bigint(20) | 父菜单 ID | 实现树形结构,0 表示顶级菜单 |
menu_type | char(1) | 菜单类型 | M 目录、C 菜单、F 按钮,三级权限粒度 |
perms | varchar(100) | 权限标识 | 如 system:user:add,用于按钮级权限控制 |
path | varchar(200) | 路由地址 | 对应前端路由的 path,如 /system/user |
component | varchar(255) | 组件路径 | 前端组件的路径,如 system/user/index |
is_cache | int(1) | 是否缓存 | 控制页面是否使用 <keep-alive> 缓存 |
菜单类型(menu_type)详解:
| 类型 | 含义 | 示例 | 前端表现 |
|---|---|---|---|
M | 目录 | “系统管理” | 侧边栏的一级菜单,包含子菜单 |
C | 菜单 | “用户管理” | 可点击跳转的具体页面 |
F | 按钮 | “新增”、“删除” | 页面内的操作按钮,通过 v-hasPermi 指令控制显示 |
设计亮点:
- 三级权限粒度:目录、菜单、按钮三层控制,实现了从页面到按钮的全链路权限管理。
- 权限标识规范:
perms字段采用模块:功能:操作的命名规范(如system:user:add),语义清晰且易于维护。 - 前后端一体化:
path和component字段存储了前端路由信息,后端直接返回给前端用于动态路由生成。
5.3.1.5. 关联表:用户-角色-菜单的桥梁
sys_user_role - 用户角色关联表:
1 | create table sys_user_role ( |
sys_role_menu - 角色菜单关联表:
1 | create table sys_role_menu ( |
设计亮点:
- 多对多关系:通过中间表实现用户与角色、角色与菜单的多对多映射。
- 联合主键:
(user_id, role_id)作为主键,天然避免重复数据,无需额外的唯一索引。 - 查询性能:两字段联合主键会自动创建索引,极大提升关联查询性能。
权限判断流程:
1 | 1. 查询用户ID = 1 的所有角色 |
5.3.2. 组织架构表群:部门、岗位的树形管理
除了用户角色权限,若依还设计了完整的组织架构管理体系。
5.3.2.1. 部门表 (sys_dept)
表定义:
1 | create table sys_dept ( |
核心字段解析:
| 字段 | 作用 | 设计亮点 |
|---|---|---|
parent_id | 父部门 ID | 实现树形结构,0 表示顶级部门 |
ancestors | 祖级列表 | 核心优化字段,存储所有父级 ID,如 0,100,103 |
ancestors 字段的设计巧思:
痛点:传统的树形结构查询,若要获取某个部门的所有上级部门,需要递归查询,性能极差。
解决方案:ancestors 字段存储了从根节点到当前节点的完整路径。
示例数据:
1 | 部门ID | 部门名称 | parent_id | ancestors |
应用场景:
- 查询所有上级部门:直接解析
ancestors字符串即可,无需递归。 - 查询所有下级部门:
WHERE ancestors LIKE '%,103,%'即可找到所有子孙部门。
5.3.2.2. 岗位表 (sys_post)
表定义:
1 | create table sys_post ( |
用户与岗位关联表 (sys_user_post):
1 | create table sys_user_post ( |
设计思想:
- 部门与岗位分离:部门代表组织层级(如 “研发部”),岗位代表职责类型(如 “项目经理”)。
- 一个用户可以属于一个部门,但可以兼任多个岗位。
5.3.3. 系统功能表群:日志、字典、配置
5.3.3.1. 操作日志表 (sys_oper_log)
表定义:
1 | create table sys_oper_log ( |
设计亮点:
- 复合索引优化:在
business_type、status、oper_time上建立索引,支持多维度日志查询。 - 性能追踪:
cost_time字段记录接口响应时间,用于性能分析。 - 完整的请求链路:记录了方法名、URL、参数、返回值,方便问题追踪。
5.3.3.2. 字典表双表设计
sys_dict_type - 字典类型表:
1 | create table sys_dict_type ( |
sys_dict_data - 字典数据表:
1 | create table sys_dict_data ( |
双表设计的优势:
| 场景 | 单表设计问题 | 双表设计优势 |
|---|---|---|
| 类型管理 | 无法统一管理字典类型 | sys_dict_type 可以启用/禁用整个字典类型 |
| 数据扩展 | 新增字典项需要修改表结构 | sys_dict_data 灵活添加任意多个字典项 |
| 查询性能 | 需要扫描所有字典数据 | 通过 dict_type 外键快速定位 |
应用示例:
1 | -- 查询 "用户性别" 字典的所有选项 |
5.3.4. Quartz 定时任务表群:企业级调度框架
若依集成了 Quartz 框架实现定时任务调度,Quartz 通过 11 张表管理任务的完整生命周期。
5.3.4.1. Quartz 核心表概览
| 表名 | 作用 | 核心程度 |
|---|---|---|
QRTZ_JOB_DETAILS | 存储任务详细信息 | ⭐⭐⭐⭐⭐ |
QRTZ_TRIGGERS | 存储触发器信息 | ⭐⭐⭐⭐⭐ |
QRTZ_CRON_TRIGGERS | 存储 Cron 表达式触发器 | ⭐⭐⭐⭐ |
QRTZ_SIMPLE_TRIGGERS | 存储简单触发器 | ⭐⭐⭐ |
QRTZ_FIRED_TRIGGERS | 存储正在执行的触发器 | ⭐⭐⭐ |
QRTZ_SCHEDULER_STATE | 存储调度器状态 | ⭐⭐⭐ |
QRTZ_LOCKS | 存储悲观锁信息 | ⭐⭐ |
QRTZ_BLOB_TRIGGERS | 存储 Blob 类型触发器 | ⭐ |
QRTZ_CALENDARS | 存储日历信息 | ⭐ |
QRTZ_PAUSED_TRIGGER_GRPS | 存储暂停的触发器组 | ⭐ |
QRTZ_SIMPROP_TRIGGERS | 存储同步机制行锁 | ⭐ |
5.3.4.2. 任务详情表 (QRTZ_JOB_DETAILS)
表定义:
1 | create table QRTZ_JOB_DETAILS ( |
核心字段解析:
| 字段 | 作用 | 设计说明 |
|---|---|---|
job_class_name | 任务执行类 | 存储 Java 类的全限定名,如 com.ruoyi.quartz.task.RyTask |
is_nonconcurrent | 是否并发 | 1 不允许并发执行,避免同一任务重复运行 |
job_data | 任务参数 | 以 Blob 形式存储任务的上下文数据 |
5.3.4.3. 触发器表 (QRTZ_TRIGGERS)
表定义:
1 | create table QRTZ_TRIGGERS ( |
触发器状态(trigger_state):
| 状态 | 含义 |
|---|---|
WAITING | 等待触发 |
ACQUIRED | 已被调度器获取,准备执行 |
EXECUTING | 正在执行 |
PAUSED | 暂停 |
BLOCKED | 阻塞(上次执行未完成) |
ERROR | 错误状态 |
5.3.4.4. Cron 触发器表 (QRTZ_CRON_TRIGGERS)
表定义:
1 | create table QRTZ_CRON_TRIGGERS ( |
Cron 表达式示例:
| 表达式 | 含义 |
|---|---|
0/10 * * * * ? | 每 10 秒执行一次 |
0 0 2 * * ? | 每天凌晨 2 点执行 |
0 0 12 * * ? | 每天中午 12 点执行 |
0 0 10,14,16 * * ? | 每天 10 点、14 点、16 点执行 |
5.3.4.5. 调度器状态表 (QRTZ_SCHEDULER_STATE)
表定义:
1 | create table QRTZ_SCHEDULER_STATE ( |
集群支持:此表用于 Quartz 集群模式。多个应用实例共享同一数据库,通过此表实现:
- 心跳检测:每个实例定期更新
last_checkin_time - 故障转移:如果某实例超过
checkin_interval未更新,其他实例会接管其任务
5.3.5. 表设计亮点与最佳实践总结
通过对若依 30 张表的深度剖析,我们总结出以下数据库设计的最佳实践:
5.3.5.1. 设计模式亮点
| 设计模式 | 应用表 | 优势 |
|---|---|---|
| 逻辑删除 | sys_user, sys_role, sys_dept | 保留历史数据,支持数据恢复和审计 |
| 双表字典 | sys_dict_type + sys_dict_data | 类型与数据分离,易于管理和扩展 |
| 祖级路径 | sys_dept.ancestors | 优化树形结构查询,避免递归 |
| 联合主键 | sys_user_role, sys_role_menu | 天然防止重复,自动创建索引 |
| 多对多中间表 | 所有关联表 | 解耦实体关系,支持灵活的多对多映射 |
5.3.5.2. 性能优化策略
| 优化手段 | 应用表 | 效果 |
|---|---|---|
| 复合索引 | sys_oper_log | 支持多维度高效查询 |
| 外键约束 | QRTZ_TRIGGERS | 保证数据一致性 |
| 时间戳索引 | sys_oper_log.oper_time | 加速日志按时间范围查询 |
| Blob 存储 | QRTZ_JOB_DETAILS.job_data | 灵活存储复杂对象 |
5.3.5.3. 安全与审计
| 安全措施 | 应用表 | 作用 |
|---|---|---|
| 密码加密存储 | sys_user.password | 存储 BCrypt 密文,防止密码泄露 |
| 密码更新时间 | sys_user.pwd_update_date | 支持密码过期策略 |
| 操作日志完整记录 | sys_oper_log | 记录请求参数和返回值,方便审计 |
| 登录日志 | sys_logininfor | 记录登录 IP 和时间,防止异常登录 |
5.3.5.4. 扩展性设计
| 扩展能力 | 设计支撑 | 应用场景 |
|---|---|---|
| 数据权限灵活配置 | sys_role.data_scope + sys_role_dept | 支持 5 种数据权限范围 |
| 菜单动态扩展 | sys_menu 树形结构 | 无限层级的菜单体系 |
| 字典类型自由添加 | sys_dict_type + sys_dict_data | 无需修改代码即可新增字典 |
| 定时任务灵活调度 | Quartz 11 张表 | 支持 Cron、简单触发器等多种模式 |






