
Prorise
这是我的博客,分享技术与生活的点点滴滴
Docker 核心思想与架构:全世界最好的Docker博文
Docker 核心思想与架构:全世界最好的Docker博文
Prorise序章: 准备工作:从 Linux 基础到 Docker 环境配置
摘要: 本章是整个知识体系的基石,旨在确保我们拥有共同的起点和一致的开发环境。我们将首先明确本指南的目标读者,并将您熟知的 Linux 概念与 Docker 技术进行映射。接着,我们将以详尽的、图文并茂的步骤,指导您在 Windows 上完成 WSL2 的前置配置、Docker Desktop 的安装、可选的汉化,并 重点解决安装过程中最常见的 WSL 更新失败问题。最后,我们将验证安装并配置国内镜像加速器,为后续的实战之旅扫清一切障碍。
0.1. 本篇指南的目标读者:DevOps 赋能的容器化实践者
在开始之前,我们希望明确,这份笔记是为特定类型的开发者精心设计的。如果您在以下描述中看到了自己的影子,那么恭喜您,这里就是您系统性掌握 Docker 的最佳起点。
我们假定您是:
- 一位将 WSL2 作为核心开发环境的实践者,日常工作离不开 Windows Terminal 和 VS Code Remote - WSL 插件。
- 一位对 Linux 命令行 怀有敬畏并运用自如的开发者,
grep,awk,curl,htop,systemctl等工具是您解决问题的得力助手。 - 一位具备初步 DevOps 思维 的工程师,深刻理解环境一致性的重要性,并渴望将这种一致性从开发、测试延伸到生产部署的每一个环节。
0.2. 知识衔接:你的 Linux 技能在 Docker 中的应用价值
您最大的优势在于,Docker 并非凭空产生的“魔法”,而是构建在 Linux 内核特性之上的产物。您已掌握的技能不仅不会过时,反而会成为您理解 Docker 底层原理的“金钥匙”。
| 你的 Linux 技能 | 在 Docker 世界的映射 | 核心关联与价值 |
|---|---|---|
进程管理与隔离 (ps, top, chroot) | Docker 容器 (Container) | Docker 使用 Linux 命名空间 (Namespaces) 为每个容器创建独立的进程树 (PID)、网络栈 (NET) 等。您对进程的理解能帮助您迅速领悟容器的隔离本质。 |
资源限制 (nice, ulimit, cgroups) | 容器资源配额 (--cpu, --memory) | Docker 直接利用 Linux 控制组 (Cgroups) 来限制和监控容器的 CPU、内存等资源使用。您的运维经验能让您更好地进行容器性能调优。 |
文件系统与挂载 (mount, fstab, ln) | 镜像分层与数据卷 (Volume) | Docker 的镜像利用了 联合文件系统 (UnionFS) 实现分层,而数据持久化则类似于 mount 操作。理解文件系统能帮您彻底搞懂数据如何管理。 |
网络配置 (ip addr, iptables) | Docker 网络 (Network) | Docker 通过创建虚拟网桥 (如 docker0) 和配置 iptables 规则来实现容器网络。您的网络知识是解开容器通信“黑盒”的关键。 |
| 脚本自动化 (Shell Scripting) | Dockerfile & CI/CD 流水线 | 编写 Dockerfile 本质上就是用声明式的方式编写一个构建脚本。您的脚本能力将直接转化为自动化构建和部署的能力。 |
0.3. 前置要求:安装 WSL 2 与 Linux 发行版
核心前置条件: 在 Windows 上使用 Docker Desktop 强依赖 WSL 2 作为其后端运行环境。因此,在安装 Docker Desktop 之前,您必须先成功安装 WSL 2 并配置至少一个 Linux 发行版(如 Ubuntu)。
如果您尚未完成此步骤,请务必参考以下这篇详尽的指南,它将指导您完成从零开始的全部流程,甚至包括如何将发行版安装到非系统盘。
请确保您已完成上述指南中的所有步骤,再继续阅读。
0.4. 安装并配置 Docker Desktop
0.4.1. 下载 Docker Desktop
- 访问 Docker 官方网站:https://www.docker.com/products/docker-desktop/
- 点击页面上的 “Download for Windows” 按钮,下载适用于 Windows 系统的 Docker Desktop 最新安装文件。
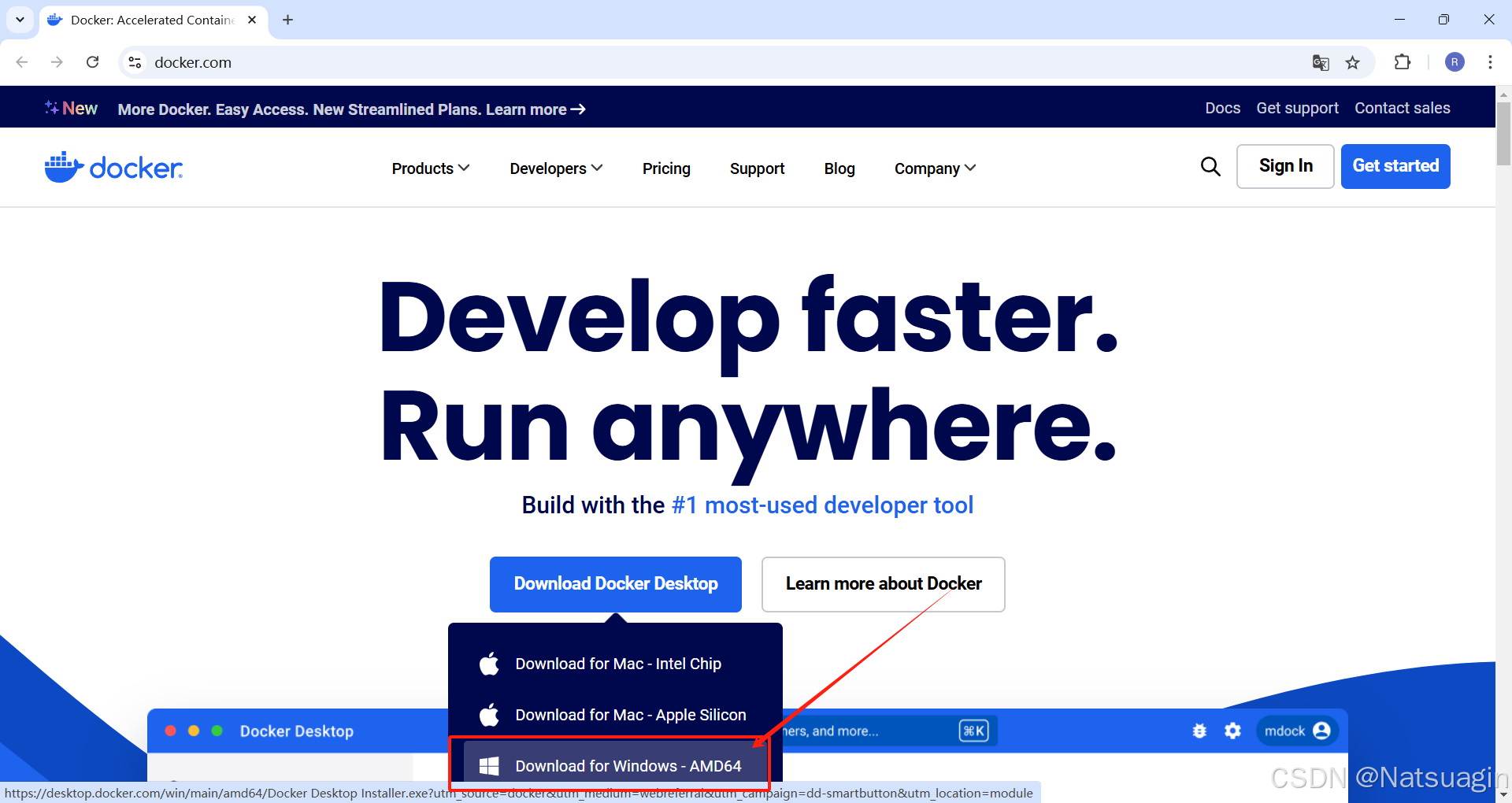
0.4.2. 执行安装程序
- 双击下载的
.exe安装文件,启动安装向导。 - 在配置界面,请确保勾选 “Use WSL 2 instead of Hyper-V (recommended)” 选项。这是我们选择的最佳实践方案。点击
Ok继续。
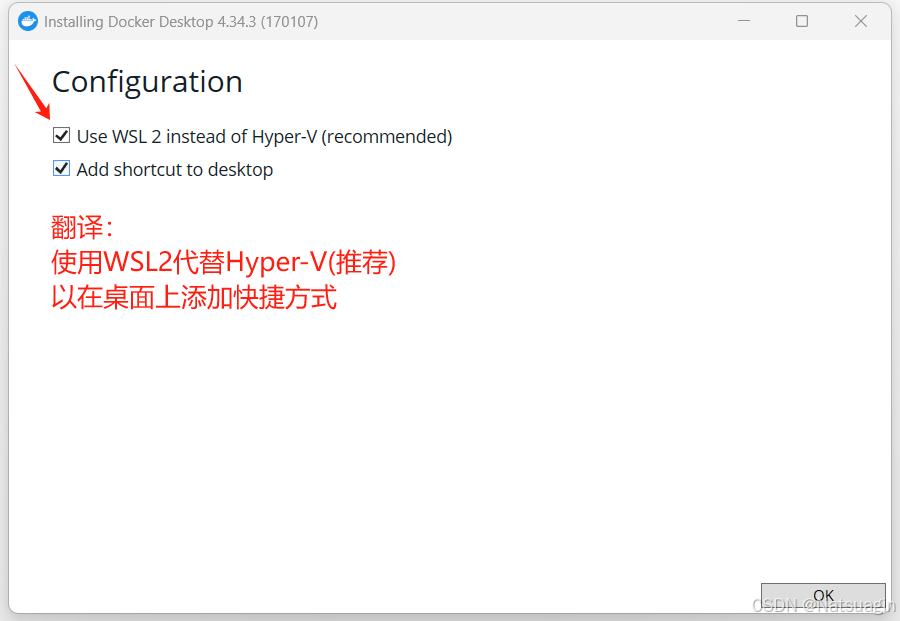 )
)
0.4.3. 完成首次启动配置
- 安装完成后,启动 Docker Desktop。
- 接受订阅协议: 首次打开时,会弹出 Docker 订阅服务协议,点击
Accept接受以继续。
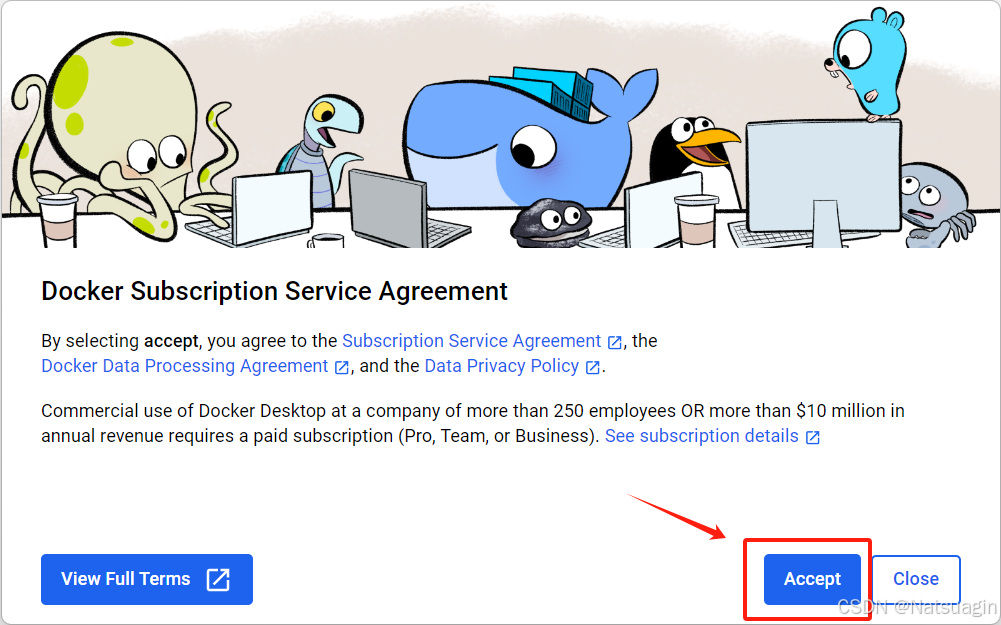
- 登录 (可选): 系统会提示您登录。您可以选择使用 Docker Hub、GitHub 或 Google 账户登录,如果暂时不需要,也可以点击
Continue without signing in跳过此步骤。
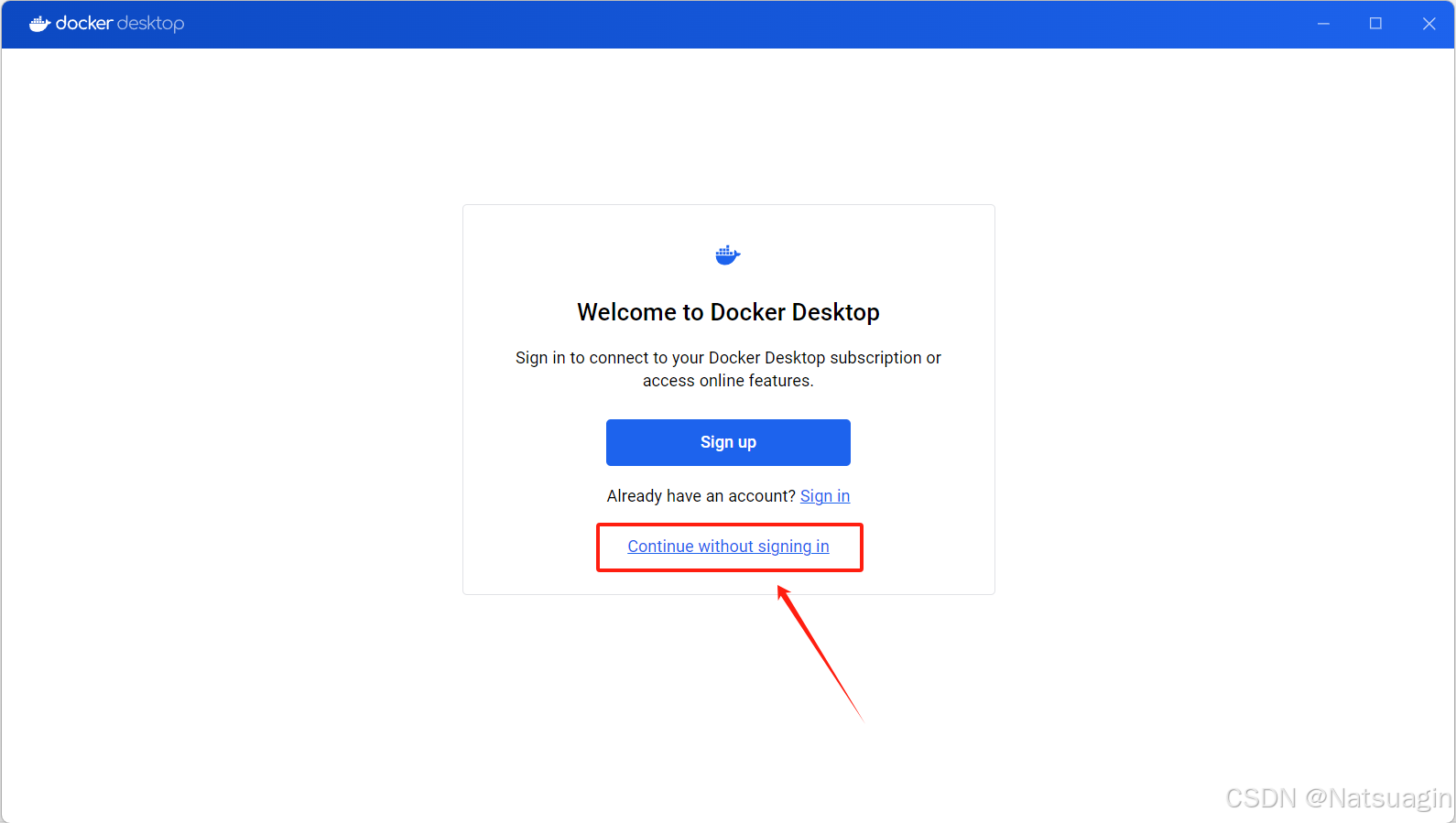
- 问卷调查 (可选): 接下来会有一个关于您角色的简短问卷,可以直接点击
Skip跳过。
 )
)
- 启动完成: 完成以上步骤后,您将看到 Docker Desktop 的主界面,左下角显示为绿色,表示引擎正在运行。
0.5. 汉化 Docker Desktop(可选)
对于希望使用中文界面的用户,可以按照以下步骤进行汉化。
0.5.1. 下载中文语言包
- 访问 GitHub 上的开源项目
DockerDesktop-CN,下载最新的语言包。
- 将下载的
app.asar文件(或包含该文件的压缩包)保存到本地。
0.5.2. 替换语言文件
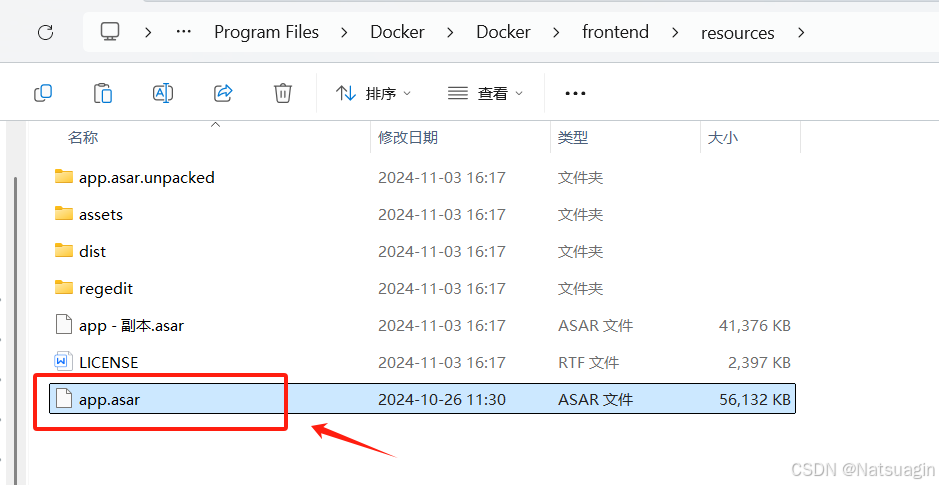
- 检查版本: 在替换前,请查看您 Docker Desktop 的版本号。可以在主界面右下角或设置中找到。
- 定位目录: 导航至 Docker 的资源文件目录,默认路径为:
C:\Program Files\Docker\Docker\resources - 备份与替换:
- 在该目录下找到原始的
app.asar文件,将其重命名为app.asar.bak以作备份。 - 将您从 GitHub 下载的、与您版本对应的中文
app.asar文件复制到此目录。
- 在该目录下找到原始的
0.5.3. 重启 Docker Desktop
- 彻底关闭 Docker Desktop(可以右键任务栏图标选择
Quit Docker Desktop)。 - 重新启动程序。此时,界面应该已经显示为中文。
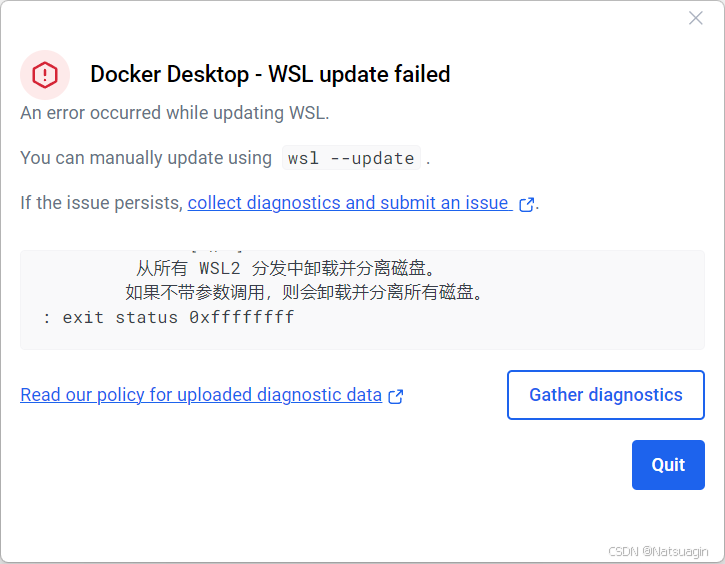
0.6. 关键问题排查:解决 WSL 更新失败
常见陷阱: 启动 Docker Desktop 时,可能会遇到 “WSL Kernel version too low” 或类似的错误提示,指出 WSL 更新失败。这通常是由于您的 Windows 系统版本过低,不满足当前 WSL 2 内核的要求所致。
 )
)
解决方案:升级 Windows 并手动更新 WSL
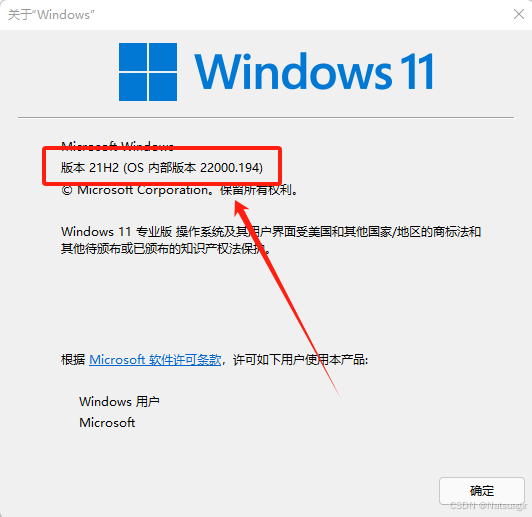
1. 检查 Windows 版本
- 按下 Win + R 组合键,输入
winver并回车。 - 查看您的 Windows 版本号。WSL2 的完整功能和稳定性需要 Windows 11 版本 22H2 或更高版本。如果您的版本较低(如 21H2),则必须升级。
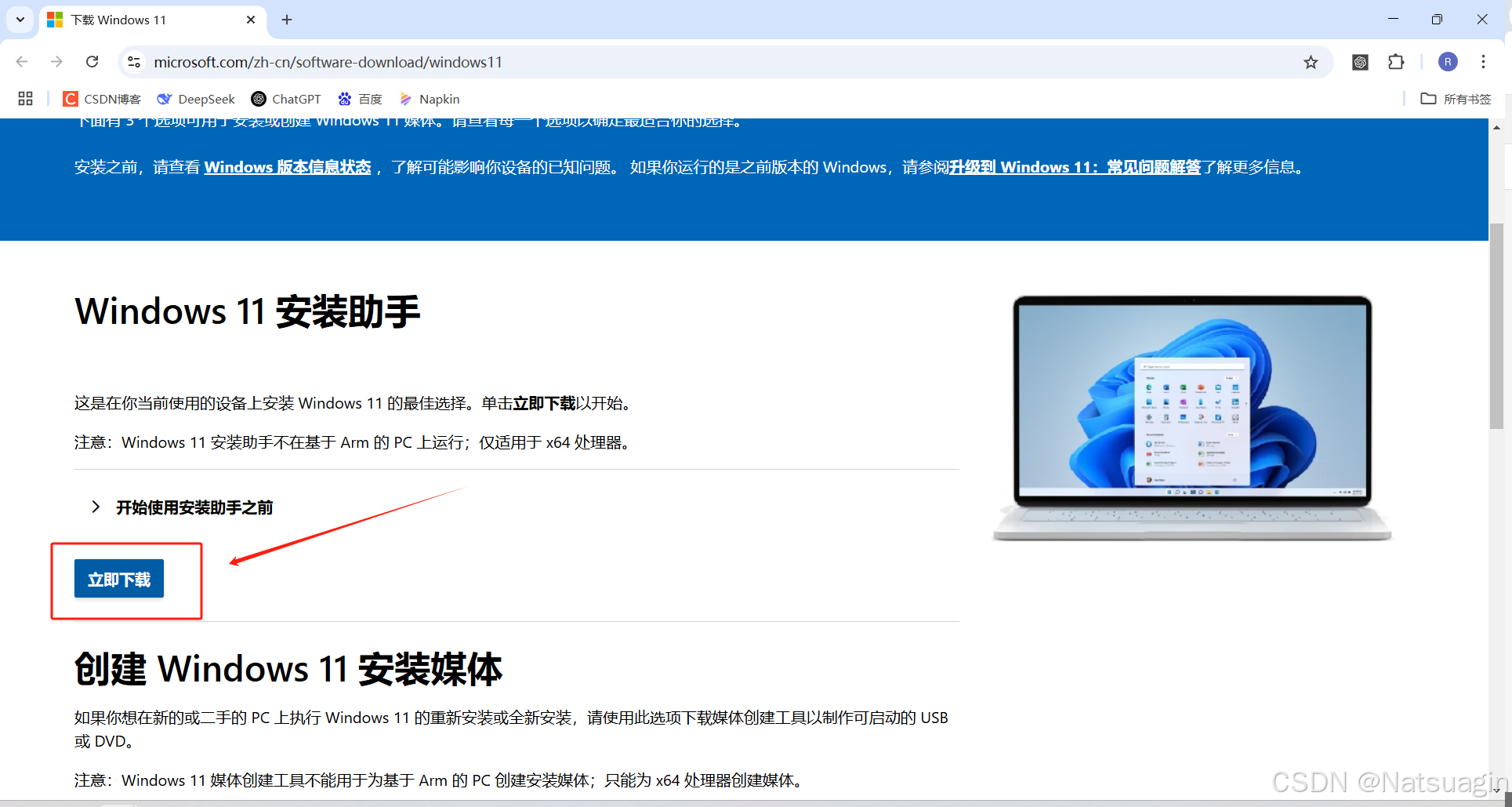
2. 手动升级 Windows
- 访问 Windows 11 安装助手官方页面。
- 在“Windows 11 安装助手”部分,点击
立即下载。
- 运行下载的工具,按照提示完成系统升级。这个过程耗时较长,请确保电脑电量充足并保持网络连接。
- 升级完成后,再次运行
winver命令,确认系统版本已达到22H2或更高。
3. 手动更新 WSL 内核
- 系统升级后,以 管理员身份 运行 PowerShell 或 Windows Terminal。
- 执行 WSL 更新命令:
1
wsl --update
- 更新完成后,检查 WSL 版本以确认成功:
1
wsl --version
4. 重新启动 Docker Desktop
- 完成以上所有步骤后,再次启动 Docker Desktop。此时,之前的 WSL 错误应该已经消失。
0.7. 最终验证与镜像加速配置
完成上述步骤后,您的 Docker 环境已基本就绪。现在,我们来进行最后的验证和优化。
1. 验证 Docker 环境
打开您的 WSL2 终端 (例如,在 Windows Terminal 中打开 Ubuntu 标签页),执行以下命令:
1 | # 检查 Docker 版本,确认客户端和服务端均已正常运行 |
1 | # 运行经典的 "hello-world" 镜像,验证 Docker 的完整工作流程 |
如果您能看到 “Hello from Docker!” 的问候语,那么恭喜您,Docker 环境已成功搭建!
2. 配置国内镜像加速器
关键优化: 由于网络原因,直接从 Docker Hub 官方仓库拉取镜像可能会非常缓慢甚至失败。配置国内镜像加速器是保证后续学习和开发效率的 必要步骤。
- 在任务栏右下角右键点击 Docker 图标,选择
Settings(设置)。 - 导航到
Docker Engine标签页。 - 在右侧的 JSON 配置文件中,添加
registry-mirrors字段。以下是一些常用的公共加速器地址(请选择一个或多个):
1 | { |
- 点击右下角的 “Apply & Restart” 按钮。Docker 将会重启并应用新的配置。
至此,您的开发环境已完全准备就绪。在下一章中,我们将正式深入 Docker 的内部,从其核心架构与概念开始,真正地“拆开”这个黑盒。
第一章: Docker 架构与核心概念解析
摘要: 在本章中,我们将彻底拆解 Docker 的“黑盒”。你将不再仅仅是命令的执行者,而是深入理解其内部工作原理的架构师。我们将从 Docker 引擎的客户端-服务端 (C/S) 架构入手,理清镜像、容器与仓库三大核心组件的交互关系。最重要的是,我们会将 Docker 的隔离机制与你熟知的 Linux 知识——命名空间 (Namespaces) 和控制组 (Cgroups) 进行深度关联,让你明白所谓的“容器魔法”其实源于坚实的 Linux 内核技术。最后,我们将聚焦于我们的 WSL2 环境,揭示 Docker 在其中资源管理的奥秘。
在本章中,我们将像剥洋葱一样,层层深入 Docker 的核心:
- 首先,我们将揭示 Docker 引擎的 C/S 架构,让你明白
docker命令是如何与后台守护进程通信的。 - 接着,我们将精准定义 Docker 世界的三大基本元素:镜像、容器和仓库。
- 然后,我们将深入底层,借助你的 Linux 知识,理解实现资源隔离的两大基石:命名空间 (Namespaces)。
- 紧接着,我们将探索实现资源限制的另一大基石:控制组 (Cgroups)。
- 最后,我们将把理论与实践结合,探讨 Docker 在 WSL2 中的资源管理 模式。
1.1. Docker 引擎:客户端-服务端 (C/S) 架构详解
在我们成功安装并运行 hello-world 之后,你可能认为 docker 是一个单一的可执行文件。然而,这只是冰山一角。Docker 实际上是一个标准的 客户端-服务端 (Client/Server) 应用。
本小节核心知识点:
- Docker 引擎 (Docker Engine): 这是 Docker 的核心,一个 C/S 架构的应用,主要由 Docker 守护进程 (Daemon)、REST API 和 Docker CLI 三部分组成。
- 守护进程 (Daemon): 名为
dockerd的后台进程,它负责处理所有核心工作,如创建和管理镜像、容器、网络和存储卷。守护进程 - Docker CLI: 命令行工具,也就是我们常用的
docker命令。它扮演客户端的角色,将我们的指令通过 REST API 发送给守护进程。 - REST API: 客户端与守护进程之间的桥梁,允许它们通过一个标准的接口进行通信。默认情况下,在 Linux 系统中,它们通过一个 UNIX 套接字 (socket)
/var/run/docker.sock进行通信。
痛点背景: 当我们在终端输入 docker run nginx 时,这个命令是如何让一个 Nginx 服务器运行起来的?如果 docker 只是一个简单的命令,它关闭后容器为什么还能继续运行?
解决方案: 理解 C/S 架构就能豁然开朗。
- 我们在 WSL2 终端中输入的
docker命令,启动了 Docker 客户端。 - 客户端将
run nginx这个请求,打包成一个标准的 API 请求,发送给在本机后台持续运行的 Docker 守护进程 `dockerd`。 - 守护进程接收到请求后,执行所有繁重的工作:检查本地是否存在
nginx镜像,如果不存在就从远程仓库拉取,然后基于该镜像创建一个新的容器,并启动它。 - 守护进程将执行结果返回给客户端,客户端在我们的终端上显示容器 ID 等信息,然后退出。
- 即使客户端退出了,守护进程和它所创建的容器依然在后台运行,这就是为什么关闭终端窗口,我们的 Nginx 服务不会中断的原因。
我们可以在 WSL2 中亲眼验证守护进程的存在:
1 | # 在 WSL2 终端中执行 |
1
2
# 输出会包含类似这样的一行,证明 dockerd 进程正在运行
root 1234 0.1 0.5 123456 7890 ? Ssl Sep17 1:23 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
1.2. 核心组件交互:镜像 (Image)、容器 (Container) 与仓库 (Registry)
理解了 C/S 通信模型后,我们再来明确通信内容中的三个核心“名词”:镜像、容器和仓库。对于有编程经验的你来说,一个恰当的类比能让你瞬间理解它们的关系。
本小节核心知识点:
- 镜像 (Image): 一个只读的模板,包含了运行应用所需的所有文件系统内容和配置。它采用分层存储结构,可以被看作是软件交付的“集装箱”本身。
- 容器 (Container): 镜像的一个可运行实例。容器与镜像的关系,就像是面向对象编程中 对象 (Object) 与 类 (Class) 的关系。镜像是静态的定义,容器是动态的运行实体。容器在镜像的只读层之上增加了一个可写层。
- 仓库 (Registry): 集中存储和分发镜像的服务。仓库与镜像的关系,就像是 代码仓库 (如 GitHub) 与 代码 (Code) 的关系。最著名的公共仓库是 Docker Hub。
核心关系链:
开发者在本地构建一个 Image -> 将 Image 推送到远程的 Registry -> 其他开发者或服务器从 Registry 拉取该 Image -> 在本地运行该 Image,创建出一个或多个 Container。
这个流程完美地解决了“在我电脑上明明是好的”这一经典难题,因为它确保了整个团队和所有环境(开发、测试、生产)都使用完全相同的只读模板(镜像)来创建运行环境(容器)。
1.3. 底层技术揭秘 (上):命名空间 (Namespaces) 如何实现资源隔离
承上启下: 我们已经知道容器是镜像的实例,并且容器之间是相互隔离的。那么,这种“隔离”的魔法究竟是如何实现的?这正是你的 Linux 知识大显身手的时刻。Docker 的隔离能力,主要依赖于 Linux 内核的两大特性,首先是 命名空间 (Namespaces)。
痛点背景:
- 为什么我在容器 A 中启动了一个 Web 服务监听 80 端口,还可以在容器 B 中再次启动一个服务监听 80 端口,而不会产生端口冲突?
- 为什么在容器内部执行
ps aux只能看到容器自己的进程,而看不到宿主机或其他容器的进程?
解决方案: 命名空间 (Namespaces) 是 Linux 内核提供的一种资源隔离方案。它能让一个进程(以及它的子进程)看起来像是拥有自己独立的全局资源。Docker 正是为每个容器创建了一系列专属的命名空间,从而实现了“欺骗”容器内进程的效果,让它以为自己独占了整个操作系统。
Docker 主要使用了以下几种命名空间:
| 命名空间 (Namespace) | 隔离的资源 | 解决的痛点 |
|---|---|---|
| PID Namespace | 进程 ID | 在容器内,进程可以拥有独立的 PID,例如 PID = 1 的初始进程,与宿主机的 PID 体系完全隔离。 |
| NET Namespace | 网络设备、端口、路由表 | 每个容器拥有独立的网络栈,包括自己的 IP 地址、端口空间和路由规则,解决了端口冲突问题。 |
| MNT Namespace | 文件系统挂载点 | 容器拥有独立的文件系统视图,看不到宿主机或其他容器的文件。 |
| IPC Namespace | 进程间通信 | 隔离了 System V IPC 和 POSIX message queues,防止不同容器间进程的意外通信。 |
| UTS Namespace | 主机名和域名 | 每个容器可以拥有独立的主机名 (hostname)。 |
| User Namespace | 用户和用户组 ID | 实现容器内的 root 用户映射为宿主机上的一个普通用户,提升安全性。 |
当你执行 docker run 时,Docker 在后台为你做的关键工作之一,就是创建好这些命名空间,然后将容器的初始进程放入其中。这就像是为容器内的进程戴上了一副“VR 眼镜”,让它看到的世界是经过内核精心“伪造”的。
1.4. 底层技术揭秘 (下):控制组 (Cgroups) 如何实现资源限制
承上启下: 命名空间为容器提供了隔离的“视野”,解决了“能看到什么”的问题。但这还不够,如果一个容器发生内存泄漏,它可能会耗尽宿主机的所有内存,导致整个系统崩溃。如何限制容器“能用多少”资源?这就是 Linux 内核的第二个法宝——控制组 (Cgroups) 的用武之地。
痛点背景:
- 如何确保一个容器最多只能使用 2 核 CPU 和 1GB 内存?
- 如何防止某个“坏邻居”容器抢占所有资源,影响到同一台宿主机上的其他重要服务?
解决方案: 控制组 (Cgroups) 是 Linux 内核的另一个核心特性,其主要作用是 限制、记录和隔离进程组所使用的物理资源,包括 CPU、内存、磁盘 I/O 等。
当 Docker 创建一个容器时,它不仅会为其创建命名空间,还会为其在 Cgroups 的层级体系中创建一个对应的控制组。所有容器内的进程都会在这个控制组的管辖之下。
我们可以通过 docker run 命令的参数来轻松地利用 Cgroups 的能力:
- 限制内存:
docker run --memory=1g ...这条命令告诉 Docker,创建一个容器,并配置其所属的 Cgroup,确保该容器使用的内存总量不会超过 1GB。 - 限制 CPU:
docker run --cpus=2 ...这条命令则限制容器最多可以使用两个 CPU 核心的计算能力。
总结: Namespaces 负责隔离,让容器“看不见”彼此和宿主机。Cgroups 负责限额,让容器“用不超”分配给它的资源。两者结合,构成了现代容器技术的基石。
🤔 思考一下
我们刚刚剖析了容器依赖的两大 Linux 内核技术。现在,请结合这些知识,思考一下:容器 (Container) 与我们熟知的传统虚拟机 (Virtual Machine) 之间,最本质的区别是什么?
1.5. WSL2 集成模式下的资源管理与性能监控
承上启下: 理解了 Namespaces 和 Cgroups 这两大通用 Linux 原理后,我们把目光拉回到具体的开发环境:Windows + WSL2。Docker Desktop 在 WSL2 上的运行方式非常巧妙,了解它有助于我们更好地管理资源。
痛点背景:
- 开发者普遍担心 Docker Desktop for Windows 会占用大量系统资源,拖慢电脑。
- 在 WSL2 模式下,我们如何精确地控制 Docker 能使用的最大内存和 CPU 数量?
解决方案: Docker Desktop 并没有直接在你的 Windows 系统上运行 dockerd。相反,它在 WSL2 内部启动了一个专用的、轻量级的 Linux 发行版(名为 docker-desktop),Docker 守护进程和所有容器都运行在这个专门的 WSL2 “虚拟机” 中。
这种方式的优势在于性能,因为它利用了 WSL2 提供的完整 Linux 内核,让 Docker 可以原生运行。但这也意味着,Docker 的资源消耗被计入了整个 WSL2 的资源池中。
要精确控制 Docker (以及所有 WSL2 发行版) 的资源上限,我们可以在 Windows 用户目录下创建一个名为 .wslconfig 的文件。
文件路径: C:\Users\<你的用户名>\.wslconfig
在这个文件中,我们可以这样配置:
1 | # .wslconfig |
重要提示: 修改 .wslconfig 文件后,必须在 PowerShell 或 CMD 中执行 wsl --shutdown 命令来彻底关闭所有 WSL2 实例,然后重新启动 Docker Desktop 或你的 WSL2 终端,配置才会生效。你可以通过 wsl -l -v 命令来查看所有正在运行的 WSL2 实例。
通过这种方式,我们就为 Docker 设置了一个清晰的资源“天花板”,再也不用担心它会失控并耗尽整个 Windows 系统的资源了。
1.6. 本章核心速查总结
本章我们深入了 Docker 的内部架构与核心概念,为你后续的实战打下了坚实的理论基础。
| 分类 | 关键项 | 核心描述 |
|---|---|---|
| 核心架构 | C/S 架构 | Docker Engine 由客户端 (CLI)、服务端 (Daemon) 和 REST API 组成。我们操作的是客户端,真正工作的是守护进程。 |
| 核心组件 | 镜像 (Image) | 静态的、只读的模板,应用打包的交付物。相当于面向对象中的“类”。 |
| 核心组件 | 容器 (Container) | 动态的、可运行的实例,由镜像创建。相当于面向对象中的“对象”。 |
| 核心组件 | 仓库 (Registry) | 集中存储和分发镜像 的服务,如 Docker Hub。相当于代码领域的“GitHub”。 |
| 底层技术 | 命名空间 (Namespaces) | 实现资源隔离。让容器感觉自己独占了操作系统(独立的进程树、网络、文件系统等)。 |
| 底层技术 | 控制组 (Cgroups) | 实现资源限制。控制容器能使用的 CPU、内存、I/O 等物理资源上限。 |
| 环境配置 | .wslconfig | 在 Windows 用户目录下,用于 配置 WSL2 全局资源限制(内存、CPU 等),从而间接控制 Docker 的资源上限。 |
总结要点:
Docker 并非魔法,它巧妙地运用了成熟的 Linux 内核技术(Namespaces 和 Cgroups)来提供轻量级的应用隔离与资源限制。理解其 C/S 架构和三大核心组件(镜像、容器、仓库)的交互关系,是掌握 Docker 的关键第一步。
1.7. 高频面试题与陷阱
你好,看你简历上写了熟悉 Docker。那你能用自己的话,深入地讲讲容器和传统虚拟机最本质的区别是什么吗?
当然可以。最本质的区别在于它们的隔离层级和因此带来的资源开销差异。
虚拟机是通过 Hypervisor 在硬件层之上虚拟出一整套硬件,再安装一个完整的客户机操作系统,所以它有独立的内核。这是硬件级别的隔离,非常彻底,但启动慢、资源消耗大。
而容器是直接运行在宿主机的内核之上的,它和宿主机共享同一个内核。容器的隔离是通过 Linux 内核的命名空间(Namespaces)和控制组(Cgroups)技术实现的,这是一种操作系统级别的隔离。
很好,那你能具体说说命名空间和控制组分别解决了什么问题吗?
命名空间解决了“资源可见性”的问题,比如 PID 命名空间让容器内的进程看不到宿主机的进程,网络命名空间让容器有自己独立的 IP 和端口。它就像是给容器进程造了一个“信息茧房”。
控制组则解决了“资源使用量”的问题,它可以限制一个容器最多能用多少 CPU、多少内存。它就像是给这个容器的资源使用量设置了一个“天花板”,防止它影响到其他容器或宿主机。
非常清晰。总结一下,就是虚拟机是模拟硬件,容器是隔离进程,对吗?
是的,这个总结非常精辟。虚拟机更“重”,像一个完整的房子;容器更“轻”,像是房子里的一个独立房间。
第二章: Docker 镜像 (Image) 深度解析与管理
摘要: 在上一章,我们建立了 Docker 的宏观认知,知道了镜像是容器的“蓝图”。本章,我们将聚焦于这个核心概念,从它旨在解决的软件交付根源问题出发,深入剖析其独特的 分层存储结构,理解 Docker 高效、可移植的本质。最终,这些深刻的理解将转化为一套扎实的、可动手实践的镜像管理技能,让你对本地的每一个镜像都了如指掌。
在本章中,我们将沿着一条精心设计的路径,逐步揭开镜像的神秘面纱:
- 首先,我们将回到软件部署的原点,探讨传统模式下的种种困境,从而理解 Docker 镜像所带来的革命性价值。
- 接着,我们将深入镜像的内部构造,揭示其高效、轻量的秘密——联合文件系统与分层存储机制。
- 然后,我们将全面掌握一套镜像管理的 基础操作技能,包括从远端获取、在本地查看和进行标记。
- 紧接着,我们将学习 高效的镜像维护策略,学会清理无用镜像,释放宝贵的磁盘空间。
- 最后,我们将探索一种重要的 离线交付方案,掌握在没有网络的环境中迁移和部署镜像的能力。
2.1. 标准化交付:镜像的价值与诞生背景
承上启下: 我们在第一章将镜像比作静态的“类”或“蓝图”。在深入其技术细节前,我们有必要先回到一切开始的地方,理解它为何被创造出来,以及它为软件开发世界带来了怎样的变革。
痛点背景: 想象一下在没有 Docker 的时代,将一个典型的 Web 应用(例如,一个 Node.js 后端 + PostgreSQL 数据库的项目)部署到一台新的服务器上,往往是一场充满不确定性的挑战:
- 环境不一致: 你的开发机是 macOS,运行着 Node.js v18.17.0;而生产服务器是 Ubuntu 20.04,其官方源的 Node.js 可能是 v12.x。这种细微的环境差异是导致应用异常的温床,催生了那句经典的开发者名言:“在我电脑上明明是好的!”
- 依赖地狱: 为了让应用跑起来,你需要在服务器上手动安装特定版本的 Node.js、PostgreSQL 客户端库,可能还需要 Redis、ImageMagick 等一系列系统级依赖。这个过程繁琐、容易出错,且难以自动化和复现。
- 交付物混杂: 你交付给运维的,可能是一个包含源代码的 zip 包,外加一份长长的
README.md文档,上面写满了复杂的安装步骤和配置指南。这种代码与环境分离的交付方式,极大地增加了沟通成本和出错风险。
解决方案: Docker 镜像的诞生,正是为了终结这种混乱。
一个 Docker 镜像,可以被理解为一个 包含了运行一个应用所需一切的、标准化的、自给自足的软件包。这个“包”里不仅有你的应用程序代码,还固化了其运行时环境,包括:
- 应用运行时: 例如特定版本的 Node.js、Python 或 JRE。
- 系统工具库: 例如
curl、git或其他基础命令。 - 操作系统文件: 应用运行所依赖的底层文件系统结构。
- 应用配置: 例如默认的配置文件、环境变量等。
通过将应用及其所有依赖“冷冻”在一个轻量级、可移植的镜像中,我们创造了一个 不可变 的交付单元。无论是在开发者的 Windows/WSL2、测试团队的 Linux 服务器,还是在云端的生产环境,这个镜像都能以完全相同的方式运行,从而从根本上消除了环境不一致的问题。
核心价值: Docker 镜像将软件的交付标准从“交付代码 + 文档”,升级到了“交付一个可立即运行的、包含完整环境的业务单元”。这才是容器化革命的基石。
2.2. 镜像的内部构造:联合文件系统与分层存储
承上启下: 现在我们理解了镜像作为“标准化软件包”的重大价值。但一个新的问题随之而来:如果每次修改一行代码,就要重新制作和传输一个包含完整操作系统的、体积可能高达数百 MB 的“软件包”,那效率岂不是极其低下?Docker 的设计者早已预见了这一点,其解决方案就是镜像的 分层存储 机制。
痛点背景:
- 一个
ubuntu基础镜像大约 70MB,一个node镜像大约 900MB。如果我基于node镜像只加入 1MB 的代码,最终的应用镜像难道是 901MB 吗? - 我在拉取镜像时,控制台显示的
Pull complete和Already exists是什么意思?
解决方案: 这种高效的背后,是 联合文件系统 在发挥作用。它是一种可以将多个目录(分支)在逻辑上合并成一个单一视图的文件系统。Docker 正是利用此技术,将镜像设计成由一系列 只读层 堆叠而成的结构。
- 层层叠加: 镜像的构建过程就像是搭积木。最底层通常是一个精简的操作系统(如
alpine),称为基础镜像。之后,每一个安装软件、复制文件或修改环境的动作,都会在其上叠加一个新的、只读的层。 - 共享与复用: 这种分层结构的最大优势在于 最大限度地资源共享。如果你本地有
node:18和node:19两个镜像,它们共同依赖的许多底层系统库(例如debian的基础层)在磁盘上只会存储一份。当你拉取新镜像时,Docker 会检查哪些层你本地已经拥有,并直接跳过下载,只拉取你没有的增量层,这也就是你看到Already exists的原因。
当我们基于此镜像启动一个容器时,Docker 会在这个只读的层堆栈之上,再添加一个纤薄的 可写“容器层”。你在容器内对文件系统的所有修改,都发生在这个可写层,而下方的所有镜像层都保持不变。
我们可以通过 docker history 命令来直观地看到一个镜像的“积木”是如何搭建起来的。
1 | # 为了确保示例一致,我们先拉取一个特定版本的 nginx 镜像 |
1
2
3
4
5
6
7
8
IMAGE CREATED CREATED BY SIZE COMMENT
176252F220A8 5 months ago /bin/sh -c #(nop) CMD ["nginx" "-g" " daemo… 0B
<missing> 5 months ago /bin/sh -c #(nop) STOPSIGNAL SIGQUIT 0B
<missing> 5 months ago /bin/sh -c #(nop) EXPOSE 80 0B
<missing> 5 months ago /bin/sh -c #(nop) ENTRYPOINT ["/docker-ent… 0B
<missing> 5 months ago /bin/sh -c #(nop) COPY file: ce423... in /do… 4.62kB
...
<missing> 5 months ago /bin/sh -c #(nop) ADD file: e6a6a... in / 72.8MB
CREATED BY 列显示了创建该层的命令。你可以看到,一个完整的 Nginx 镜像是由多条命令逐步构建起来的。关于如何通过编写文件来自动执行这些命令创建自己的镜像,我们将在后续的 Dockerfile 章节中深入学习。
2.3. 基础操作:获取、查看与标记镜像
承上启下: 有了对镜像分层结构的清晰认知,我们现在可以满怀信心地开始与这些“蓝图”进行交互了。下面是你在日常工作中会用到的最核心的镜像管理命令。
1. 获取镜像 (docker pull)
此命令用于从远程的镜像仓库(Registry),如官方的 Docker Hub,下载镜像到你的本地机器。
1 | # 语法: docker pull [REGISTRY_HOST/][USERNAME/] NAME [: TAG] |
在拉取过程中,你可以清晰地看到 Docker 正在逐层下载,并对已存在的层进行复用。
2. 查看本地镜像 (docker images 或 docker image ls)
此命令会列出你本地存储的所有镜像。
1 | docker images |
1
2
3
4
5
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx 1.25.2 176252f220a8 5 months ago 187MB
ubuntu latest 6b7dfa7e8fdb 5 months ago 77.8MB
alpine 3.18 146313f01743 6 months ago 7.34MB
hello-world latest fedb12345678 10 months ago 9.14kB
REPOSITORY: 镜像的名称,标识了这是什么软件。TAG: 镜像的标签,通常用于表示版本。一个IMAGE ID可以有多个标签。IMAGE ID: 镜像的唯一身份 ID,是其内容的 SHA256 哈希值摘要。SIZE: 镜像所有层解压后的大小总和。
3. 为镜像添加标记 (docker tag)
此命令并不会创建或复制一份新的镜像实体,它只是为某个已存在的 IMAGE ID 创建一个额外的引用或别名。这在推送镜像到私有仓库或进行版本管理时至关重要。
场景: 假设你基于 alpine:3.18 制作了自己的应用,现在想把它标记为 my-app:1.0。
1 | # 语法: docker tag SOURCE_IMAGE [: TAG] TARGET_IMAGE [: TAG] |
1
2
3
4
REPOSITORY TAG IMAGE ID CREATED SIZE
my-app 1.0 146313f01743 6 months ago 7.34MB
alpine 3.18 146313f01743 6 months ago 7.34MB
...
请注意,my-app:1.0 和 alpine:3.18 的 IMAGE ID 完全相同。它们指向的是磁盘上同一份分层数据。这是一种零成本的引用操作。
2.4. 高效管理:清理磁盘空间与镜像维护
承上启下: 随着你不断地拉取和构建镜像,本地磁盘空间会逐渐被占用。学会如何安全、高效地进行“大扫除”是每位 Docker 实践者的必备技能。
痛点背景:
- 随着时间推移,系统中会积累大量旧版本或在构建过程中产生的中间镜像。
- 有时会出现一些没有
REPOSITORY和TAG,显示为<none>的镜像,这些被称为“悬浮镜像”(dangling images),它们是清理的首要目标。
1. 删除镜像 (docker rmi 或 docker image rm)
1 | # 语法: docker rmi IMAGE_NAME: TAG 或者 docker rmi IMAGE_ID |
如果一个镜像正被某个容器(即使是已停止的容器)所使用,Docker 会阻止你删除它,以防数据丢失。你必须先删除所有使用该镜像的容器,才能删除镜像。关于容器的管理,我们将在下一章深入探讨。
2. 自动化清理 (docker image prune)
这是一个极其有用的命令,用于批量清理不再需要的镜像。
1 | # 该命令会安全地删除所有悬浮的(dangling)镜像 |
定期执行 docker image prune 是保持开发环境整洁的好习惯。
2.5. 离线交付:镜像的导入与导出
承上启下: 标准的镜像分发依赖于镜像仓库,但如果你需要将镜像部署到一台无法访问外网的“内网”或“离线”服务器呢?这时,手动的导入导出功能就派上了用场。docker save 命令可以将一个或多个本地镜像打包成一个单一的 .tar 归档文件。这个文件是镜像的完整快照,包含了所有的层和元数据。
适用场景: 备份镜像,或将其打包以便拷贝到离线环境中。
1 | # 将本地的 nginx: 1.25.2 镜像保存为 nginx-image.tar 文件 |
docker load 命令是 save 的逆向操作。它从指定的 .tar 文件中读取数据,并将镜像完整地加载到本地的镜像库中。
适用场景: 在离线服务器上,从 .tar 文件恢复镜像。
1 | # 假设我们已将 nginx-image.tar 文件拷贝到了目标服务器 |
2.6. 本章核心速查总结
本章我们深入了 Docker 镜像的“灵魂”——分层存储,并掌握了一套完整的命令行管理工具。
| 分类 | 关键命令 | 核心描述 |
|---|---|---|
| 核心原理 | 分层存储 | 镜像是只读层的堆叠,基于 UnionFS 技术,实现高效的资源复用和缓存。 |
| 基础操作 | docker pull <image>[:<tag>] | (推荐) 从远程仓库拉取镜像到本地。始终指定明确的 tag 是最佳实践。 |
| 基础操作 | docker images 或 docker image ls | 列出本地存储的所有镜像,显示其仓库、标签、ID、大小等信息。 |
| 基础操作 | docker history <image> | 查看指定镜像的分层历史,理解其构建过程。 |
| 基础操作 | docker tag <source> <target> | 为一个已存在的镜像 ID 创建一个新的别名(标签),零成本操作。 |
| 管理维护 | docker rmi <image> | 删除指定的镜像(标签)。当最后一个标签被删除时,镜像数据才会被清理。 |
| 管理维护 | docker image prune [-a] | (推荐) 自动化清理。默认清理悬浮镜像,-a 参数清理所有未被容器使用的镜像。 |
| 离线交付 | docker save -o <file.tar> <image> | 将指定镜像完整地打包成一个 .tar 文件,用于离线传输。 |
| 离线交付 | docker load -i <file.tar> | 从 .tar 文件中加载镜像到本地 Docker 库。 |
总结要点:
镜像是 Docker 工作流的起点。深刻理解其 分层、共享、只读 的本质,是后续学习 Dockerfile 优化、实现高效 CI/CD 的关键。熟练运用本章的管理命令,能确保你的开发环境始终保持整洁和高效。
2.7. 高频面试题与陷阱
你提到了 Docker 镜像的分层存储机制,除了我们都知道的可以节省磁盘空间,你认为它还带来了哪些核心优势?尤其是在现代的 DevOps 流程中。
好的。除了最直观的磁盘空间节省,分层存储还带来了两大核心优势,它们对 DevOps 流程至关重要。
第一个是 传输效率。在团队协作或 CI/CD 流水线中,当我们将镜像推送到远程仓库,或者从仓库拉取更新时,Docker 只会传输那些本地不存在的、有差异的层。这意味着应用的更新和部署非常快速,因为我们传递的是增量,而不是每次都传递完整的“软件包”。
第二个,也是我认为最重要的优势,是 构建缓存。在自动化构建(CI)的场景中,Docker 会利用分层机制进行缓存。如果我们的代码构建过程有 10 个步骤,而我们只修改了第 8 步对应的代码,那么 Docker 在重新构建时,前 7 个步骤对应的层会直接命中缓存,无需重复执行,构建会从第 8 步开始。这极大地缩短了 CI 的运行时间,加快了开发迭代和反馈的速度。
很好,你提到了构建缓存,这确实是它在 CI/CD 中提效的关键。那么,这种机制是否有什么需要注意的“陷阱”?
有的。一个常见的陷阱是没能合理安排构建指令的顺序。比如,将容易变动的 COPY 源代码指令放在了不容易变动的 RUN 安装依赖指令之前。这样做会导致每次代码一有改动,缓存就从源代码复制那一步开始失效,其后所有步骤(包括耗时的依赖安装)都无法使用缓存,从而失去了分层缓存的优势。因此,编写高效的 Dockerfile 需要将最稳定、最不容易变动的指令放在前面。
第三章: Docker 容器 (Container) 全生命周期管理
摘要: 静态的“蓝图”(镜像)已经准备就绪,现在是时候注入灵魂,让它们成为一个个鲜活的、提供服务的实体了。本章将彻底改变上一版“命令罗列”的失败模式,我们将围绕一个核心实战任务——“启动、改造、监控并清理一个 Nginx Web 服务器”——来展开。您将不再是被动的信息接收者,而是亲手的操作者。本章结束后,您将获得的不仅是一份命令清单,而是一套能在真实开发场景中自如地创建、进入、调试和管理容器的坚实技能。
在本章,我们的学习路径将与一个真实的运维任务完全同步:
- 启动服务: 我们将学习如何用一行命令启动一个后台运行的 Nginx 容器,并从外部访问它。
- 临时任务: 我们将学习如何启动一个临时的、交互式的容器来完成一次性的诊断任务,用后即焚。
- 在线热更新: 我们将攻克核心技能——在不停止服务的情况下,进入正在运行的 Nginx 容器,亲手修改其欢迎页面。
- 实时监控: 我们将学习如何像使用
tail -f一样,实时查看 Nginx 容器的访问日志。 - 固化成果与清理: 我们将把修改后的容器状态保存为一个新镜像,并最终学会如何清理本次操作留下的所有痕迹。
3.1. 启动与管理我们的 Nginx 服务器
承上启下: 理论已经足够,让我们直接开始动手。我们的第一个任务是:启动一个标准的 Nginx Web 服务器,让它在后台持续运行,并能通过我们的主机浏览器访问到。
第一步:启动服务 (docker run)
在您的 WSL2 终端中,执行以下命令:
1 | docker run --name my-webserver -p 8080:80 -d nginx:1.25.2 |
这条命令看起来很长,但它正是容器管理的精髓所在。让我们像拆解代码一样,逐一分析每个参数的意义:
docker run: 这是我们告诉 Docker “创建并启动一个容器”的核心指令。--name my-webserver: 我们为这个容器起一个好记的名字my-webserver。如果没有这个参数,Docker 会分配一个随机的名字(如sad_einstein)。使用自定义名称能极大地便利后续管理。-p 8080:80: 这是 端口映射。-p参数的格式是[主机端口]:[容器端口]。这行命令的意思是,将我们主机(在这里指 WSL2 环境)的8080端口,映射到容器内部的80端口。这是让外部世界能够访问到容器内服务的关键。-d: 即--detach,意味着 后台运行。执行完命令后,终端会立即返回容器的完整 ID,而容器会在后台默默地提供服务,不会占用你当前的终端会话。nginx:1.25.2: 这是我们用来创建容器的“蓝图”——镜像。
第二步:验证服务 (docker ps 与浏览器)
服务已经启动,我们如何确认它真的在工作?
1 | # 使用 docker ps 查看当前正在运行的容器 |
1
2
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4e622eeeded6 nginx:1.25.2 "/docker-entrypoint.…" 6 seconds ago Up 5 seconds 0.0.0.0:8080->80/tcp my-webserver
输出结果清晰地告诉我们:my-webserver 容器正在运行 (Up 5 seconds),并且端口 8080 已经成功映射到了容器的 80 端口。
现在,打开你 Windows 上的浏览器,访问 http://localhost:8080。
恭喜你! 你已经成功启动了你的第一个后台服务容器。这个小小的 Nginx 服务器,连同它的整个运行环境,都被完美地封装在那个容器之中。
第三步:停止与清理 (docker stop & docker rm)
完成实验后,我们需要清理环境。
1 | # 1. 停止服务。stop 命令会优雅地关闭容器 |
3.2. 两种工作模式:服务型与任务型
承上启下: 上一节我们启动了一个 服务型 容器 (-d),它会像守护进程一样长期运行。但在开发中,我们还经常需要运行 任务型 容器,它只为了执行一个临时任务,执行完就应该消失。
场景:我需要一个纯净的 Linux 环境来测试网络连通性
这种“用完即走”的需求,正是 前台交互式 容器的用武之地。
1 | # 运行一个 alpine 容器,并启动它的 sh 命令行程序 |
让我们再次拆解这组新的参数:
-it: 这是-i和-t的合并写法。-i确保容器的标准输入保持打开,-t则为容器分配一个伪终端。两者结合,就为我们提供了一个可以交互的 shell 环境。--rm: 这是一个极其有用的“自毁”开关。它告诉 Docker,当这个容器的主进程退出时,自动删除该容器。这避免了系统中残留大量无用的一次性容器。alpine:3.18: 我们选用了一个极度轻量(仅约 7MB)的 Linux 发行版镜像。sh: 这是我们希望在容器启动后执行的命令。sh是 Alpine 系统默认的 shell。
执行命令后,你会发现你的终端提示符发生了变化:/ #
这表明你已经 身处 Alpine 容器的内部 了。现在,你可以像操作一台真实的 Linux 机器一样执行命令:
1 | # 在容器内部执行 |
当你输入 exit 后,容器的 sh 进程结束,由于我们设置了 --rm,容器会被立刻、自动地删除。执行 docker ps -a 你将找不到它的任何痕迹。
核心模式总结:
docker run -d ...: 用于需要长期运行的 服务,如 Web 服务器、数据库。docker run -it --rm ...: 用于需要交互的 临时任务,如环境测试、运行工具、代码编译。
3.3. 在线热更新:进入运行中的 Nginx 容器
承上启下: 这是本章最核心、最实用的技能。我们的 my-webserver 正在后台运行,但我们不满足于默认的欢迎页面,我们想在 不停止服务 的情况下,进去修改它!
第一步:重新启动我们的服务器
如果刚才你已经清理了环境,请重新运行它:
1 | docker run --name my-webserver -p 8080:80 -d nginx:1.25.2 |
第二步:进入容器 (docker exec)
我们需要一个通往容器内部的 shell,但又要避免干扰正在运行的 Nginx 主进程。这正是 docker exec 的完美应用场景。
1 | # 在 my-webserver 容器内,额外启动一个 bash 进程,并与之交互 |
docker exec: 告诉 Docker 我们要在指定容器内 执行一个新命令。-it: 同样,我们需要一个交互式的终端。my-webserver: 目标容器的名称。bash: 我们希望在容器内启动的新进程。
命令执行后,你的提示符会变为 root@c123...:/#。你现在拥有了 my-webserver 容器内部的“上帝视角”,而 Nginx 服务依然在后台安然无恙地运行着。
第三步:定位并修改网页文件
根据 Nginx 的知识,我们知道默认网页文件位于 /usr/share/nginx/html。
1 | # ---- 以下命令均在容器内部执行 ---- |
第四步:见证奇迹
回到你 Windows 的浏览器,刷新 http://localhost:8080 页面。
你成功了!在完全不中断服务的情况下,你完成了对容器内部文件的在线修改。这就是 docker exec 的强大之处,它是在开发和运维中进行快速诊断和修复的利器。
3.4. 实时监控:查看 Nginx 访问日志
承上启下: 我们已经修改了页面,现在想看看谁访问了我们的新页面。我们需要实时地监控 Nginx 的访问日志。
1 | # 使用 docker logs 命令,并附带 -f 参数来持续跟踪 |
-f(--follow): 这个参数与你熟知的 Linux 命令tail -f作用完全相同,它会“盯住”容器的日志输出,并实时打印到你的终端上。
现在,回到浏览器,多次刷新 http://localhost:8080。每刷新一次,你都会看到终端里立即出现一条新的访问记录。
1
2
3
172.17.0.1 - - [19/Sep/2025:01:45:10 +0000] "GET / HTTP/1.1" 200 52 "-" "Mozilla/5.0 ..." "-"
172.17.0.1 - - [19/Sep/2025:01:45:11 +0000] "GET / HTTP/1.1" 200 52 "-" "Mozilla/5.0 ..." "-"
172.17.0.1 - - [19/Sep/2025:01:45:12 +0000] "GET / HTTP/1.1" 200 52 "-" "Mozilla/5.0 ..." "-"
按 Ctrl+C 可以停止跟踪。
3.5. 固化成果:将修改保存为新镜像
承上启下: 我们对容器的在线修改是临时的。如果容器被删除,这些修改就会丢失。如果我们希望将这个“被改造过”的状态保存下来,制作成一个新的、可重复使用的“蓝图”,该怎么办?
这时,docker commit 就派上用场了。
1 | # 语法: docker commit [OPTIONS] CONTAINER [REPOSITORY[: TAG]] |
执行后,docker images 列表里就会出现这个崭新的镜像。我们可以用它启动一个完全一样的、已包含修改后页面的新服务器:
1 | # 从新镜像启动一个新容器,注意主机端口要换一个,避免冲突 |
docker commit 是一个强大的快速快照工具,非常适合用于调试和实验。但在正规的生产流程中,我们 强烈推荐 使用 Dockerfile 来构建镜像。因为 Dockerfile 是一个记录了所有构建步骤的“代码”,它透明、可复现、易于版本控制,而 commit 产生的镜像是“黑盒”,不利于维护和团队协作。我们将在下一章深入 Dockerfile 的世界。
3.6. 离线文件归档:容器文件系统导出 (export)
承上启下: 我们已经学会了使用 docker commit 将容器的 完整状态(包括分层历史和配置)保存为一个新的 镜像。但有时,我们的需求可能更纯粹:我不需要一个新的 Docker 镜像,我只想要容器里 所有文件的一份简单、扁平的 .tar 归档。比如,用于数据备份、迁移到非 Docker 系统,或者提交给安全团队进行审计。
这正是 docker export 的用武之地。
export 与 commit 的核心区别:
commit: 产物是 镜像。保留了 Docker 的“血统”(分层、元数据),可以被docker run。export: 产物是 文件归档。丢弃了所有 Docker 的历史和配置,只是文件系统的快照,不能被docker run。
动手实践:导出我们的 Nginx 文件系统
让我们继续使用之前运行的 my-webserver 容器。
1 | # 语法: docker export -o [输出文件名] [容器名] |
命令执行后,你的当前目录下就会出现一个 my-webserver-fs.tar 文件。我们可以用 tar 命令来验证一下它的内容:
1 | # 使用 tar 命令查看归档文件的内容列表(只看前几行) |
1
2
3
4
5
.dockerenv
dev/
dev/console
dev/core
dev/fd/
如你所见,这就是一个标准的 Linux 根文件系统归档,你可以用任何标准的归档工具来处理它。
docker export 的配对命令是 docker import,它可以将一个文件系统归档导入为一个新的 Docker 镜像。这在从零开始制作自定义的基础镜像时非常有用。例如:cat my-webserver-fs.tar | docker import - my-base-image:1.0
最后一步:彻底清理
我们的实验全部完成,现在执行清理操作,释放所有资源。
1 | # 停止并删除所有容器 (如果它们还在运行) |
第四章: Dockerfile 生产级最佳实践
摘要: 在前几章中,我们学会了如何使用和管理别人构建好的镜像。从本章开始,我们将迎来一次质的飞跃:亲手创造属于我们自己的、生产就绪的镜像。我们将以 Dockerfile 这个强大的“建筑图纸”为核心工具,将一个从零开始创建的现代化 Vite + React 应用,通过一系列循序渐进的优化,最终封装成一个体积小巧、构建迅速、安全可靠的 Docker 镜像。这不再是理论学习,这是一场彻头彻尾的实战演练。
4.0 项目准备:从零开始创建 Vite 应用
在为应用编写 Dockerfile 之前,我们得先有一个应用。我们将完全模拟真实开发流程,在 WSL2 中初始化一个项目。
第一步:准备 Node.js 环境
虽然您的环境可能已安装 Node.js,但为了保证教程的统一性与最佳实践,我们推荐使用 nvm (Node Version Manager) 来管理 Node.js 版本。
打开您的 Windows Terminal (WSL2/Ubuntu) 环境,执行以下命令安装 nvm:
1 | # 从 nvm 的 GitHub 仓库下载并执行安装脚本 (版本号可能更新,此为示例) |
安装完成后,我们来安装 Node.js 的长期支持版 (LTS),并在 2025 年,我们选择 v20.x 系列:
1 | # 安装 Node.js v20 LTS 版本 |
1
2
v20.17.0
10.7.0
第二步:使用 Vite 创建 React + TypeScript 项目
现在,我们使用 Vite 的官方脚手架来快速生成项目结构。
1 | # 在你的主目录或工作目录下执行 |
Vite CLI 会以交互方式提问,请按以下方式选择:
- Project name:
my-react-app - Select a framework:
React - Select a variant:
TypeScript
第三步:安装依赖并验证项目
项目已创建,让我们进入目录,安装依赖,并验证它能否在本地正常运行。
1 | # 进入项目目录 |
1
2
3
4
5
VITE v5.3.1 ready in 381 ms
➜ Local: http://localhost:5173/
➜ Network: use --host to expose
➜ press h + enter to show help
现在,按住 Ctrl 并点击 http://localhost:5173/ 链接,它应该会在你的 Windows 浏览器中打开 Vite + React 的默认欢迎页面。
确认页面正常显示后,回到终端按 Ctrl+C 停止开发服务器。
准备就绪! 我们现在拥有了一个功能完备、结构清晰的现代 Web 应用。它的目录结构如下,这将是我们本章进行所有 Dockerfile 操作的基础。
1 | # my-react-app/ |
4.1. 构建的基石:设定构建上下文 (Build Context) 与 .dockerignore
承上启下: 我们的项目已经准备好,现在可以在项目根目录下(my-react-app/)开始编写 Dockerfile 了。但在写下第一行 FROM 指令之前,有一个至关重要的、却常常被新手忽略的步骤:告诉 Docker 引擎,哪些文件“不应该”被看到。
痛点背景: 当我们执行 docker build . 命令时,最后的 . 代表了 构建上下文 (Build Context)。Docker 客户端会把这个路径下 所有 的文件和目录(除了被忽略的)打包发送给 Docker 守护进程。如果不对其进行限制:
- 构建缓慢: 体积巨大的
node_modules目录(可能包含数万个小文件)和.git目录会被一同发送,极大地拖慢了构建的初始速度。 - 镜像臃肿: 如果这些文件被不小心
COPY进了镜像,会造成镜像体积无意义地膨胀。 - 安全风险: 可能会将包含密钥的
.env文件或本地日志等敏感信息打包进镜像中。
解决方案: 在项目根目录下创建一个名为 .dockerignore 的文件,它的语法和 .gitignore 完全一样,用于从构建上下文中排除文件和目录。
实战操作: 在 my-react-app 目录下,创建一个新文件 .dockerignore。
1 | # .dockerignore |
创建好 .dockerignore 文件,就像是为我们的构建过程设置了一个“门卫”。现在,当我们执行构建时,Docker 守护进程只会收到一个干净、轻量的项目包,为后续的高效构建打下了坚实的基础。
现在,同样在 my-react-app 目录下,创建我们本章的主角——Dockerfile 文件。我们将在接下来的小节中逐步填充和完善它的内容。
4.2. 初版构建:一个能工作,但有陷阱的 Dockerfile
承上启下: 我们的项目和 .dockerignore 文件都已就绪,现在可以正式开始编写 Dockerfile 了。在本节中,我们的目标是创建“v0.1”版本——一个能成功将 React 应用打包成可运行镜像的、简单直观的 Dockerfile。在这个过程中,我们将主动规避一个极其常见的容器网络陷阱,并最终揭示这个初版 Dockerfile 在构建效率上存在的致命缺陷,为后续的优化做足铺垫。
第一步:让我们的应用变得“容器友好”
在将任何 Web 服务容器化之前,一个专业的开发者会首先确保该服务能被容器环境正确地访问。这涉及到一个核心的网络概念:网络绑定地址。
- 出于安全考虑,许多开发服务器(包括 Vite)默认只监听
localhost(即127.0.0.1)。 - 在容器的独立网络世界里,
localhost指的是 容器自己,这意味着服务只接受来自容器 内部 的连接。 - 当我们从主机浏览器访问时,流量经过 Docker 的端口映射进入容器,这在容器看来是 外部 连接,因此会被默认的服务设置所拒绝。
为了让服务能被外部访问,我们必须让它监听 0.0.0.0,这个特殊的 IP 地址意为“监听本机上所有可用的网络接口”。
实战操作: 我们通过修改 package.json 来实现这一点,这比在 Dockerfile 中通过命令行参数修改更为稳健。
- 在 VS Code 中,打开
my-react-app/package.json文件。 - 找到
"scripts"部分下的"preview"命令。 - 为
vite preview添加--host标志,指示它监听所有网络接口。
1 | // package.json |
通过这个简单的修改,我们的应用现在已经为容器化做好了充分的准备。
第二步:编写 Dockerfile v0.1
现在,在 VS Code 中打开 Dockerfile 文件,并粘贴以下内容。这是一个逻辑清晰的初稿:
1 | # Dockerfile (版本 0.1 - 初始草稿) |
第三步:构建并运行容器
在 VS Code 的集成终端中,执行以下命令来构建镜像和启动容器:
1 | # 构建镜像,并标记为 my-react-app: 0.1 |
构建完成后,打开你的 Windows 浏览器并访问 http://localhost:8888。您应该能成功看到 Vite + React 的欢迎页面,它现在正由一个完全独立的 Docker 容器提供服务。
第四步:揭示性能陷阱
我们的容器虽然能工作,但现在我们将展示其作为“初稿”的致命缺陷。
在 VS Code 中,打开
src/App.tsx文件。做一点微小的修改,例如,将
<h1>Vite + React</h1>改为<h1>Vite + React in Docker!</h1>。回到终端,基于修改后的代码,重新构建一个
v0.2版本的镜像:1
docker build -t my-react-app:0.2 .
仔细观察构建过程的输出。您会发现,即使我们只改动了一行业务代码,与 npm 依赖毫无关系,Docker 依然 完整地、缓慢地重新执行了 RUN npm install 步骤。
陷阱所在: 我们的 COPY . . 指令位于 RUN npm install 之前。这意味着项目中的 任何文件 改动,都会导致 COPY 层的缓存失效。一旦某个层的缓存失效,其 后续所有层 的缓存都会随之失效,Docker 必须重新执行从 COPY 开始的所有步骤,包括耗时的依赖安装。
在进入下一节优化之前,让我们先清理掉刚刚创建的容器:
1 | docker stop webapp-v0.1 && docker rm webapp-v0.1 |
我们已经成功地构建并运行了第一个容器,并精准地定位了它的性能瓶颈。在下一节中,我们将学习如何利用 Docker 的缓存机制,彻底解决这个问题。
4.3. 效率革命:精通构建缓存与指令顺序的艺术
承上启下: 在上一节,我们成功构建并运行了 v0.1 版本的镜像,但也暴露了它在构建效率上的一个巨大缺陷:哪怕只修改一行代码,也要重新经历漫长的 npm install 过程。这在频繁提交代码的 CI/CD 流程中是不可接受的。本节,我们将通过重构 Dockerfile,学会利用 Docker 的核心特性——层缓存,将构建速度提升一个数量级。
痛点背后的原理:Docker 的层缓存机制
要解决问题,必先理解其根源。Docker 在构建镜像时,会严格按照 Dockerfile 中的指令顺序,一步步执行。每一条指令,都会生成一个镜像层。
Docker 会为每一个成功构建的层计算一个哈希值并将其缓存下来。在下一次构建时,Docker 会逐行检查指令:
- 如果指令和它操作的文件内容都没有任何变化,Docker 就会直接使用上一次缓存的层(你会看到
---> Using cache),跳过实际执行。 - 但是,一旦某一条指令因为自身或其依赖的文件发生变化而导致缓存失效,那么从这一层开始,其后所有步骤的缓存都将全部失效,必须被重新执行。
回顾我们的 v0.1 版本,COPY . . 指令位于 RUN npm install 之前。COPY . . 依赖于整个项目目录的内容。当我们修改 src/App.tsx 时,COPY . . 指令的输入发生了变化,它的缓存失效了。因此,它后面的 RUN npm install 和 RUN npm run build 指令也必须被强制重新执行。
解决方案:重排指令,将变化频率作为唯一标准
优化的核心思想非常简单:将最稳定、最不经常变化的部分放在 Dockerfile 的最前面。
在我们的项目中:
- 最稳定的是:项目依赖
package.json和package-lock.json。只有当我们添加或删除依赖时,它们才会改变。 - 最善变的是:我们的业务源代码,如
src/目录下的文件。
因此,一个高效的 Dockerfile 应该遵循以下逻辑:
- 先只复制
package*.json文件。 - 然后执行
npm install。这一步只依赖package*.json,只要依赖不变更,这一层就可以被永久缓存。 - 最后再复制我们经常修改的源代码。
实战操作:重构 Dockerfile 为 v0.2
让我们将理论付诸实践。修改 Dockerfile 文件,内容如下:
1 | # Dockerfile (版本 0.1 - 初始草稿) |
见证效率的飞跃
让我们用这个优化后的 Dockerfile 来验证效果。
第一步:构建 v0.2 版本
1 | # 构建优化后的版本,这次 npm install 依然会完整运行 |
第二步:再次修改源代码
在 VS Code 中,再次打开 src/App.tsx 文件,做另一次修改,例如,将 <h1>Vite + React in Docker!</h1> 改为 <h1>Cache Optimized!</h1>。
第三步:构建 v0.3 版本,见证奇迹
现在,请仔细观察终端的输出。你会看到一个决定性的变化:
1 | docker build -t my-react-app:0.3 . |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
...
Step 3/8 : COPY package*.json ./
---> Using cache
7a8b9c0d1e2f
Step 4/8 : RUN npm install
---> Using cache
3g4h5i6j7k8l
Step 5/8 : COPY . .
---> 9m8n7o6p5q4r
Step 6/8 : RUN npm run build
---> Running in fedcba987654
...
vite v5.3.1 building for production...
✓ 29 modules transformed.
dist/index.html 0.47 kB │ gzip: 0.32 kB
dist/assets/react-B_OKSO-q.svg 4.13 kB │ gzip: 2.16 kB
dist/assets/index-D8YwQTtC.css 1.21 kB │ gzip: 0.64 kB
dist/assets/index-BRJ4s-vr.js 143.20 kB │ gzip: 45.47 kB
✓ built in 1.45s
...
成功了! 正如输出所示,COPY package*.json ./ 和 RUN npm install 步骤都明确地显示了 ---> Using cache。构建过程直接跳过了耗时的依赖安装,从 COPY . . 这一步才开始重新执行,整个构建过程可能从几分钟缩短到了几秒钟。这就是指令顺序的艺术。
COPY vs ADD:一个明确的选择
在 Dockerfile 中,你可能还会看到一个与 COPY 功能相似的指令 ADD。
COPY: 功能纯粹,就是将文件或目录从构建上下文复制到镜像中。ADD: 功能更复杂,它除了能做COPY的所有事,还有两个额外的特性:- 如果源文件是一个可识别的压缩包(如
.tar,.gzip),ADD会自动将其解压到目标路径。 - 如果源是一个 URL,
ADD会尝试下载该文件。
- 如果源文件是一个可识别的压缩包(如
最佳实践: 除非你明确需要 ADD 的自动解压或 URL 下载功能,否则 始终优先使用 COPY。COPY 的行为更透明、更可预测。使用 COPY 能清晰地表明你的意图只是复制文件,这使得 Dockerfile 更易于理解和维护。
在结束本节前,让我们清理环境:
1 | # 我们并没有运行容器,所以只需要清理掉构建的镜像即可 |
4.4. 镜像瘦身(上):选择合适的基础镜像
承上启下: 在上一节,我们通过优化指令顺序,极大地提升了 构建速度。现在,我们要关注另一个核心指标:镜像体积。我们 v0.2 版本的镜像是基于 node:20 构建的,它功能完备,但体积也相当庞大。一个臃肿的镜像会占用更多的磁盘和仓库存储,更重要的是,它会显著拖慢 CI/CD 流程中的拉取(pull)和推送(push)速度。本节,我们将学习第一个,也是最立竿见影的瘦身技巧:选择一个更小的基础镜像。
痛点背景:默认基础镜像的“慷慨”
当我们使用 FROM node:20 时,我们实际上得到的是一个基于完整版 Debian 操作系统的镜像。它包含了 bash、curl、git 以及大量编译工具和系统库。这些工具在某些场景下很有用,但对于一个已经构建好的、只想安静态运行的 Node.js 应用来说,90% 的内容都是不必要的“脂肪”。
解决方案:探索更苗条的镜像变体
Docker Hub 上的官方镜像通常会提供多种“风味”的标签(Tag),以满足不同需求。对于 Node.js 镜像,最常见的两种瘦身变体是:
node:<version>-slim: 这是一个“修身版”。它同样基于 Debian,但移除了许多非核心的软件包。体积适中,兼容性好,是一个稳健的折中选择。node:<version>-alpine: 这是一个“极限版”。它基于 Alpine Linux,一个以安全和轻量著称的极简发行版。它的体积非常小,能极大地缩减最终镜像的尺寸。
实战操作:直观对比体积差异
让我们通过亲手构建来感受一下这种差异有多么巨大。
第一步:构建一个“全尺寸”的基准镜像
首先,请确保你的 Dockerfile 内容是我们在 4.3 节优化缓存后的版本。然后,修改第一行,明确指定使用完整的 node:20 镜像,并构建它。
1 | # Dockerfile |
现在,构建这个全尺寸的镜像:
1 | docker build -t my-react-app:full-debian . |
第二步:切换到 alpine 并构建“极限版”镜像
接下来,我们只做一行修改:将基础镜像换成 alpine 版本。
1 | # Dockerfile |
构建这个 Alpine 版本的镜像:
1 | docker build -t my-react-app:alpine . |
第三步:见证瘦身成果
所有构建都已完成。现在,让我们使用 docker images 命令来检阅我们的劳动成果:
1 | docker images |
1
2
3
REPOSITORY TAG IMAGE ID CREATED SIZE
my-react-app alpine a1b2c3d4e5f6 2 minutes ago 315MB
my-react-app full-debian f6e5d4c3b2a1 5 minutes ago 1.13GB
效果惊人! 结果一目了然。仅仅通过修改 Dockerfile 的第一行,我们的应用镜像体积就从 1.13GB 骤降到了 315MB,缩减了超过 70%。在真实的部署流程中,这意味着更快的分发速度和更低的存储成本。
Alpine 的权衡:glibc vs musl libc
天下没有免费的午餐。Alpine 之所以能做到如此小巧,一个重要原因是它使用了 musl libc 作为标准的 C 库,而不是像 Debian/Ubuntu 等大多数 Linux 发行版那样使用 glibc。
glibc: 功能全面,兼容性最好,但体积较大。musl libc: 设计轻量,注重标准和安全,但与一些依赖特定glibc特性的二进制包不兼容。
潜在的坑: 对于我们纯 JavaScript 的 React 应用来说,使用 Alpine 通常是安全的。但如果你的 Node.js 项目依赖了一些需要编译原生 C++ 插件的库(例如一些图像处理、加密或数据库驱动库),这些插件可能在 musl libc 环境下编译失败或运行出错。因此,当你选择 Alpine 作为基础镜像时,必须进行充分的测试,确保所有功能都能正常工作。如果遇到兼容性问题,node:<version>-slim 是一个极好的替代方案。
在结束本节前,让我们清理掉本次实验创建的镜像:
1 | docker rmi my-react-app:full-debian my-react-app:alpine |
我们已经成功地为镜像进行了第一次“大瘦身”。然而,当前的 Alpine 版本镜像中,依然包含了大量仅在“构建”阶段需要的开发依赖和工具。在下一节,我们将学习终极瘦身武器——多阶段构建,将这些“杂质”彻底从最终的生产镜像中剔除。
4.5. 镜像瘦身(下):终极武器之 多阶段构建 (Multi-stage Builds)
承上启下: 上一节,我们通过切换到 Alpine 基础镜像,将镜像体积从 1.13GB 成功压缩到了约 315MB,成效显著。但这还远未达到极限。仔细思考一下,我们当前的 my-react-app:alpine 镜像中,到底包含了些什么?
- 完整的 Node.js 运行时环境。
npm包管理器。package.json中定义的所有dependencies和devDependencies(例如vite,typescript,@types/react等)。- 我们全部的 TypeScript 源代码(
src目录)。 - 最终编译生成的、真正对用户有用的静态文件(
dist目录)。
一个残酷的现实是:在生产环境中,为了让用户能看到我们的网页,我们真正需要的,仅仅是第 5 项——那个 dist 目录,以及一个能提供静态文件服务的 Web 服务器。其他所有东西,都是构建过程中产生的“脚手架”和“工业垃圾”,它们不仅让镜像变得臃肿,还因为包含了大量非必要的软件(如编译工具、开发服务器)而增大了潜在的攻击面。
解决方案:多阶段构建
多阶段构建允许我们在一个 Dockerfile 中使用多个 FROM 指令。每一个 FROM 都开启一个全新的、独立的构建 阶段 (Stage)。这让我们可以实现一个完美的“阅后即焚”流程:
- “构建器”阶段: 我们先在一个包含完整 Node.js 环境的阶段中,安装所有依赖、编译代码、运行测试,生成最终的
dist目录。 - “最终”阶段: 我们另起一个新的阶段,选择一个极度轻量级的、不含 Node.js 的生产级 Web 服务器镜像(如 Nginx),然后只从“构建器”阶段 拷贝 出我们唯一需要的
dist目录。
构建结束后,那个包含了所有“垃圾”的“构建器”阶段会被 直接丢弃,我们得到的将是一个只包含最终产物和最小化运行环境的、极致精简的生产镜像。
实战操作:打造生产级 Dockerfile
第一步:为 Nginx 准备 SPA 配置文件
单页应用(SPA)依赖前端路由,这意味着对于像 /about 或 /users/1 这样的路径,Nginx 不能去文件系统里找对应的目录,而应该总是返回 index.html,让 React Router 来接管。我们需要创建一个简单的 Nginx 配置文件来告知它这个规则。
在你的 my-react-app 项目根目录下,创建一个名为 nginx.conf 的文件:
1 | # nginx.conf |
第二步:编写多阶段构建的 Dockerfile
现在,用以下内容彻底覆盖你的 Dockerfile:
1 | # Dockerfile (版本 1.0 - 生产就绪版) |
第三步:构建并见证终极瘦身
让我们构建这个代表着最终成果的生产镜像:
1 | docker build -t my-react-app:production-v1.0 . |
构建完成后,再次执行 docker images,并将我们一路走来的所有版本进行对比:
1 | REPOSITORY TAG IMAGE ID CREATED SIZE |
无与伦比的优化! 最终的生产镜像体积仅为 42.5MB!
- 相比最初的
1.13GB,体积缩减了 96% 以上。 - 相比 Alpine 单阶段版本,体积也进一步缩减了 86%。
- 最重要的是,这个镜像的 攻击面被降到了最低。它不包含 Node.js,不包含 npm,不包含源代码,不包含任何编译工具,只包含一个身经百战的 Nginx 和我们编译好的静态文件。这才是真正的生产级交付物。
第四步:运行并验证生产镜像
1 | # 注意容器端口现在是 Nginx 默认的 80 |
访问 http://localhost:8080,你的 React 应用正由一个轻快、稳固的 Nginx 服务器提供服务。
在结束本章的核心实战前,让我们清理所有实验过程中的容器和镜像:
1 | docker stop webapp-prod && docker rm webapp-prod |
4.6. 安全加固:以 非 root 用户 运行你的应用
承上启下: 我们在 4.5 节中构建的 production-v1.0 镜像,在体积和结构上已经达到了生产级标准。现在,我们要关注一个同样重要、但更侧重于 安全 的方面。默认情况下,容器内的进程是以最高权限用户——root——来运行的。这是一个潜在的、必须被修复的安全隐患。
痛点背景:root 权限的风险
遵循“最小权限原则”是所有安全规范的基石。让应用以 root 用户身份在容器内运行,会带来不必要的风险:
- 增大了攻击面: 如果应用本身存在漏洞(例如,任意文件上传或远程代码执行),攻击者一旦利用漏洞获得了应用的控制权,他也就获得了容器内的
root权限。 - 增加了“容器逃逸”的风险: 虽然容器技术提供了有效的隔离,但历史上也出现过需要特定内核权限才能利用的 Linux 内核漏洞。如果攻击者在容器内是
root,他将拥有更多尝试利用这些漏洞、从容器“逃逸”到宿主机系统的能力。
解决方案:创建并切换到非特权用户
最佳实践是在 Dockerfile 中创建一个专用的、低权限的应用程序用户,并在容器启动前,使用 USER 指令切换到该用户。
实战验证:官方镜像的良好实践
幸运的是,我们为最终阶段选择的 nginx:stable-alpine 是一个维护精良的官方镜像,它已经为我们内置了安全实践。我们无需自己添加用户,但我们可以学会 如何去验证 这一点。
第一步:启动我们的生产容器
1 | # 如果你已清理环境,请先重新构建 v1.0 镜像 |
第二步:进入容器并检查进程
1 | # 进入正在运行的容器 |
1
2
3
4
5
6
7
PID USER TIME COMMAND
1 root 0:00 nginx: master process nginx -g daemon off;
33 nginx 0:00 nginx: worker process
34 nginx 0:00 nginx: worker process
...
40 root 0:00 sh
45 root 0:00 ps aux
结果分析:
请仔细观察 USER 列。你会发现一个关键的安全设计:
- PID 为 1 的 Master Process(主进程)是以
root用户启动的。这是必需的,因为在类 Unix 系统中,只有root用户才有权限绑定到 1024 以下的端口(例如 Nginx 默认的 80 端口)。 - 但真正处理用户请求、执行业务逻辑的 Worker Processes(工作进程),其用户是
nginx——这是一个由基础镜像预先创建好的、权限受限的非特权用户。
这意味着,即使 Nginx 的某个工作进程被漏洞攻陷,攻击者获得的也只是一个受限的 nginx 用户权限,而不是为所欲为的 root 权限。这个发现告诉我们一个宝贵的经验:尽可能选择并信任由官方维护的基础镜像。它们通常已经包含了大量的、经过社区检验的安全与最佳实践,让我们能站在巨人的肩膀上,避免重复造轮子和踩坑。
当我们需要自己创建用户时
当然,并非所有基础镜像都像 Nginx 一样配置完备。当你使用一个更通用的基础镜像(如 alpine 或 debian)来构建自定义应用时,你就必须自己负责创建和切换用户。
以下是在 Dockerfile 中创建和使用非 root 用户的标准模式,供你日后参考:
Dockerfile 安全模式:创建非 Root 用户 (Alpine)
1 | # 假设我们基于一个纯净的 Alpine 镜像 |
通过本节的学习,我们不仅验证了当前生产镜像的安全性,更掌握了在任何 Dockerfile 中实施“最小权限原则”的通用方法。
第五章: 从单体到多服务:容器网络与持久化存储
摘要: 在上一章,我们成功地将一个独立的前端应用打磨成了生产级的镜像。然而,现实世界的应用很少是孤立存在的。本章,我们将迈出从“单体”到“多服务”的关键一步。我们将通过实战,为一个前后端分离的应用,解决两个核心问题:身处隔离环境中的容器们,该如何相互发现并进行通信?服务产生的数据,又该如何安全地永久保存?本章的知识,是通往 docker-compose 服务编排的必经之路。
在本章中,我们将通过构建一个更完整的应用,来掌握服务间协作的命脉:
- 首先,我们将揭秘 容器间通信 的原理,通过创建一个专属的内部网络,让服务之间可以轻松对话。
- 接着,我们将为需要永久保存的数据,找到一个安全的“家”,学习 Docker 的第一种持久化方案:为 生产数据 而生的
Volumes。 - 然后,我们将学习第二种持久化方案:为 开发效率 而生的
Bind Mounts,用它来实现代码的热重载。 - 最后,我们将对这两种方案进行场景化总结,让您在未来的实践中能做出最恰当的选择。
5.1. 跨越鸿沟:揭秘容器间通信
首先我们需要解决一个根本问题:身处隔离环境中的容器们,该如何相互发现并进行通信?
第一步:准备我们的后端 API 服务
为了模拟真实场景,我们需要第二个服务。我们将快速创建一个极简的 Node.js/Express 后端 API。
- 在您的 WSL2 环境中,于
my-react-app项目旁边,创建一个新目录backend-api并进入。
1 | # 确保你位于 my-react-app 的上级目录 |
- 在
backend-api目录中,创建package.json文件来定义项目和依赖。
1 | { |
- 创建
index.js,这是我们的 API 服务器核心代码。
1 | // index.js |
- 最后,为此 API 创建一个简单的
Dockerfile。
1 | # Dockerfile |
- 构建后端 API 镜像。
1 | docker build -t my-api:1.0 . |
第二步:制造“通信失败”的场景
现在,我们拥有了 my-react-app:production-v1.0 (前端) 和 my-api:1.0 (后端) 两个镜像。让我们像往常一样,将它们分别启动:
1 | # 回到上级目录,以便同时看到两个项目 |
两个容器都在独立运行。现在,让我们进入前端容器,尝试从它内部去访问后端 API。
1 | # 进入前端容器的 shell |
1
curl: (6) Could not resolve host: backend-api
这就是痛点所在! 默认情况下,Docker 的容器是相互隔离的“孤岛”。尽管我们知道另一个容器的名字叫 backend-api,但在前端容器的世界里,这个名字是无法被解析的,它不知道这个名字指向哪个 IP 地址。
第三步:架设“桥梁”—— 自定义 Bridge 网络
要解决这个问题,我们不能依赖 Docker 默认的网络,而需要创建一个 自定义的 bridge 网络。这就像是为我们的应用服务们建立一个专属的、内部的局域网。凡是连接到同一个自定义网络中的容器,Docker 都会为其提供一个 内置的 DNS 服务,让它们可以通过 容器名 直接相互通信。
实战操作:
首先,清理掉我们刚才创建的“孤岛”容器。
1
docker stop frontend backend-api && docker rm frontend backend-api
创建一个新的网络。
1
docker network create my-app-network/
重新启动我们的两个容器,但这次,使用
--network标志,将它们都连接到我们新建的网络上。+1
2docker run -d --name backend-api --network my-app-network my-api:1.0
docker run -d --name frontend --network my-app-network -p 8080:80 my-react-app:production-v1.0最终验证:再次进入前端容器,执行完全相同的
curl命令。1
2docker exec -it frontend sh
/ # curl http://backend-api: 3000/api/data
1
{"message":"Hello from the Backend API!","timestamp":"2025-09-19T13:44:55.123Z"}
成功了! 通过自定义网络,我们优雅地解决了服务发现和服务通信的问题。frontend 容器现在可以通过一个稳定、可读的服务名 backend-api 来访问后端。
关于 --link: 在旧的教程或资料中,你可能会看到 --link 这个参数。请注意,这是 已被废弃的、过时的技术。自定义网络在功能、灵活性和安全性上都全面超越了 --link,请在所有新项目中忘记它的存在。
至此,我们已经掌握了多服务应用架构的第一个基石:网络通信。在下一节,我们将解决另一个同样重要的问题:数据持久化。
5.2. 数据永存之道(上):为数据而生的 Volumes
承上启下: 我们已经成功地让前端和后端容器通过网络连接起来。但目前为止,我们的后端 API 是一个 无状态 (stateless) 服务。现在,我们要给它增加一个“状态”:一个访问计数器。这个需求,将直接引出 Docker 中一个至关重要的话题:数据持久化。
第一步:改造我们的后端 API,使其“有状态”
我们需要修改 API 代码,让它在每次被请求时,将一个数字(保存在文件中)加一。
请确保您位于
backend-api项目目录中。用以下内容 完全覆盖
index.js文件:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43// index.js (v1.1 - with hit counter)
const express = require('express');
const fs = require('fs').promises;
const path = require('path');
const app = express();
const port = 3000;
const DATA_DIR = path.join(__dirname, 'data');
const HITS_FILE = path.join(DATA_DIR, 'hits.txt');
// 确保数据目录存在
async function ensureDataDir() {
try {
await fs.mkdir(DATA_DIR);
} catch (err) {
if (err.code !== 'EEXIST') throw err;
}
}
app.get('/api/data', async (req, res) => {
await ensureDataDir();
let hits = 0;
try {
const data = await fs.readFile(HITS_FILE, 'utf-8');
hits = parseInt(data, 10);
} catch (err) {
// 如果文件不存在,就当做是第一次访问
if (err.code !== 'ENOENT') throw err;
}
hits++;
await fs.writeFile(HITS_FILE, hits.toString());
res.json({
message: "Hello from the Backend API!",
hits: hits,
timestamp: new Date().toISOString()
});
});
app.listen(port, () => {
console.log(`API server listening on port ${port}`);
});代码已更新,现在,基于新的代码 重新构建 一个
v1.1版本的镜像。1
docker build -t my-api:1.1 .
第二步:亲身体验“数据丢失”的痛点
现在,我们将启动这个新版容器,并 明确地将它的端口暴露给主机,以便我们直接测试。
启动新版后端容器,并使用
-p标志进行端口映射。1
2# 我们将主机的 3001 端口映射到容器内部的 3000 端口
docker run -d --name backend-api --network my-app-network -p 3001:3000 my-api:1.1端口已映射,现在可以从 主机终端(您当前所在的 WSL2 终端)直接用
curl访问。请连续执行三次:1
2
3curl http://localhost:3001/api/data
curl http://localhost:3001/api/data
curl http://localhost:3001/api/data您会看到返回的
hits值依次为1,2,3。一切正常。现在,我们模拟一次常规的服务更新或重启:删除这个容器。
1
docker stop backend-api && docker rm backend-api
然后,我们从同一个
my-api:1.1镜像,启动一个“全新”的容器实例,使用完全相同的命令。1
docker run -d --name backend-api --network my-app-network -p 3001:3000 my-api:1.1
最后,再次访问 API 端点。
1
curl http://localhost:3001/api/data
1
{"message":"Hello from the Backend API!","hits":1,"timestamp":"2025-09-19T15:05:10.456Z"}
数据丢失了! 计数器从 1 重新开始。这是因为我们写入的 hits.txt 文件,保存在了容器的“可写层”上。当容器被删除时,它的可写层会随之一同被销毁。
第三步:使用 Volumes 实现数据永存
为了解决这个问题,我们需要一种能将数据存储在 容器之外 的、并由 Docker 负责管理和持久化的机制。这,就是 数据卷。数据卷的生命周期独立于任何容器,即使容器被删除,数据卷及其中的数据依然安然无恙。
实战操作:
首先,清理掉刚才的容器。
1
docker stop backend-api && docker rm backend-api
创建一个具名数据卷。给数据卷起一个有意义的名字是一个好习惯。
1
docker volume create my-api-data
重新启动后端容器,但这次,我们使用
-v标志来 挂载 我们刚创建的数据卷。1
2
3# -v 或 --volume 的格式是 [数据卷名]:[容器内绝对路径]
# 确保命令中包含所有必要的参数:--name, --network, -p, 和 -v
docker run -d --name backend-api --network my-app-network -p 3001:3000 -v my-api-data:/app/data my-api:1.1这行命令告诉 Docker:“请把名为
my-api-data的数据卷,‘连接’到容器内的/app/data目录上”。现在,我们 API 应用所有对/app/data目录的读写操作,实际上都会直接作用于my-api-data这个数据卷。最终验证:重复我们的实验
- 连续用
curl http://localhost:3001/api/data访问 API 数次,让计数器增长到比如5。 - 用
docker stop backend-api && docker rm backend-api再次删除容器。 - 用 完全相同 的
docker run ... -v my-api-data:/app/data ...命令启动一个 新 的容器实例。 - 再次访问 API。
1
curl http://localhost:3001/api/data
- 连续用
1
{"message":"Hello from the Backend API!","hits":6,"timestamp":"2025-09-19T15:07:20.789Z"}
成功了! 计数器从 6 开始,这意味着数据被完美地持久化了。my-api-data 数据卷就像一个独立于容器的“数据保险箱”,确保了数据的安全与永存。
5.3. 数据永存之道(下):为开发而生的 Bind Mounts
承上启下: 上一节,我们使用 Volumes 成功地解决了生产数据的持久化问题。但随之而来的是一个开发效率的痛点:我们每修改一行后端代码,都必须重新构建镜像、停止旧容器、启动新容器,整个过程繁琐且耗时。我们渴望的,是像本地开发一样,保存代码后立即看到效果的“热重载”体验。
痛点背景:容器化开发中的“慢反馈循环”
在容器内运行应用,享受了环境一致性的好处,但却牺牲了开发的即时反馈。我们当前 修改 -> 重建 -> 重启 的循环,严重拖慢了开发速度。
解决方案:绑定挂载
Bind Mounts 是另一种挂载机制。与 Volumes(由 Docker 管理的“数据保险箱”)不同,Bind Mounts 是将我们 宿主机(Host)上的一个文件或目录,直接“映射”进容器的指定路径。其核心机制是宿主机与容器之间建立了一个实时、双向的文件同步。你在 VS Code 中对宿主机文件的任何修改,都会立即、原封不动地 反映在容器内部。
第一步:为我们的 API 项目添加热重载能力
为了让 Node.js 应用能够监控文件变化并自动重启,我们需要一个工具,最常用的是 nodemon。
请确保您位于
backend-api项目目录中。为项目添加
nodemon作为开发依赖。
1 | pnpm install nodemon --save-dev |
- 修改
package.json,添加一个新的dev脚本来使用nodemon。
1 | // package.json |
第二步:使用 Bind Mount 启动开发容器
现在,我们将以一种全新的方式启动后端容器,不再使用镜像中固化的代码,而是直接挂载我们本地的源代码。
- 首先,清理掉上一节的容器(如果它还在运行)。
1 | docker stop backend-api && docker rm backend-api |
- 执行以下命令,启动一个“开发模式”的容器。
1 | # 我们仍然在 backend-api 目录下执行此命令 |
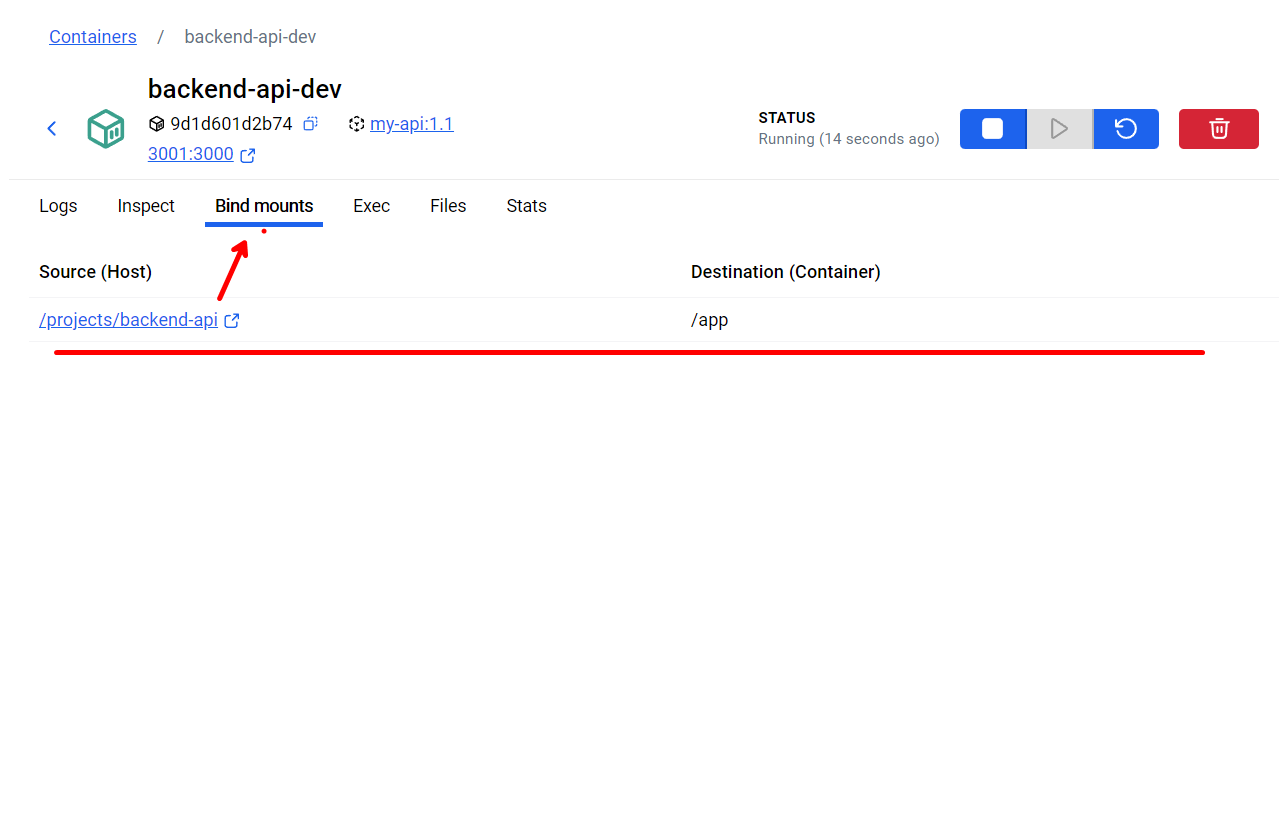
让我们来仔细解析这个强大的命令:
--name backend-api-dev: 我们为开发容器起一个新名字,以示区别。-v "$(pwd)":/app: 这正是 Bind Mount 的核心语法。-v标志的格式是[宿主机绝对路径]:[容器内绝对路径]。"$(pwd)"会自动替换为当前宿主机的绝对路径(即backend-api项目的完整路径),并将其完整地挂载到容器内的/app目录。my-api:1.1: 我们依然使用v1.1镜像,因为它为我们提供了已经安装好npm install的node_modules目录和 Node.js 运行环境。npm run dev: 我们在命令的最后覆盖了 Dockerfile 中默认的CMD,转而执行我们新增的dev脚本,启动nodemon。
第三步:见证热重载的“魔法”
- 首先,实时跟踪我们开发容器的日志。
1 | docker logs -f backend-api-dev |
在 VS Code 中,打开
backend-api/index.js文件。找到
res.json中的message字段,将其修改为:
1 | // index.js |
- 保存文件! 在你按下
Ctrl+S的瞬间,观察docker logs的终端。
1 | [nodemon] starting `node index.js` |
nodemon已经自动重启了服务。现在,再次用curl访问 API。
1 | curl http://localhost:3001/api/data |
1
{"message":"Hot-Reloading is AWESOME!","hits":1,"timestamp":"2025-09-19T15:03:12.123Z"}
成功了! 我们实现了完美的开发体验。你现在可以在 VS Code 中尽情编写代码,每一次保存,更改都会立即在运行的容器中生效,彻底告别了“修改 -> 重建 -> 重启”的漫长等待。
关于 WSL2 的性能
我们当前的这套工作流性能极高,因为您的项目文件(宿主机端)和 Docker 引擎都运行在 WSL2 的原生 Linux 文件系统中,文件事件通知和读写都接近原生性能。如果您将项目文件放在 Windows 文件系统(如 /mnt/c/Users/...)再进行绑定挂载,性能会急剧下降。
5.4. 场景化决策:Volumes vs. Bind Mounts
承上启下: 在前两节中,我们已经亲手实践了两种将数据存放在容器之外的方式:
- 我们使用
Volumes(数据卷) 来持久化我们 API 的“访问计数”,确保了即使容器被删除,数据依然安全。 - 我们使用
Bind Mounts(绑定挂载) 来映射本地的源代码,实现了“热重载”的高效开发体验。
本节将对这两种技术进行全面对比,让您在未来的任何场景下,都能毫不犹豫地做出最正确的选择。
Volumes:生产数据的保险箱
数据卷 (Volumes) 是由 `Docker 引擎` 来创建和管理的数据存储区域。它是 Docker 世界中持久化数据的 一等公民,也是官方 `首选` 的方式。把它想象成一个由 Docker 托管的、专供容器使用的“外置硬盘”。
核心特性:
- Docker 管理: 数据卷的创建、删除、查看等操作都通过 Docker CLI (
docker volume ...) 进行,其在宿主机上的具体存储位置由 Docker 统一管理,我们通常不应直接操作。 - 生命周期独立: 数据卷的生命周期与容器完全解耦。删除所有使用某个数据卷的容器,数据卷本身及其中的数据 不会 被删除。
- 高性能与平台无关: Docker 会保证数据卷在所有平台(Linux, Windows, macOS)上都以最高效的方式进行 I/O 操作。
- 更安全: 它将容器的数据需求与宿主机的特定文件系统布局隔离开来,避免了容器意外修改宿主机重要文件的风险。
最佳应用场景:
- 数据库数据: 例如 PostgreSQL、MySQL、MongoDB 等数据库的数据文件目录。
- 用户上传内容: 网站用户上传的图片、视频、文档等。
- 应用生成的状态: 需要在容器重启或更新后依然保持的状态数据,例如我们的“访问计数器”。
- 需要跨容器共享的数据: 多个容器可以同时挂载同一个数据卷,以共享配置或数据。
Bind Mounts:开发环境的任意门
绑定挂载 (Bind Mounts) 则是将 `宿主机` 上的一个已存在的文件或目录,直接“共享”或“映射”到容器内部。把它想象成一个在你本地电脑和容器之间建立的“实时同步的共享文件夹”。
核心特性:
- 宿主机管理: 挂载的源头是宿主机上的一个具体路径,文件的所有权和管理权都在宿主机这边。
- 实时同步: 宿主机上对文件的任何修改都会立刻反映在容器内,反之亦然。
- 路径依赖: 这种方式依赖于宿主机的文件系统结构,可移植性相对较差。
- 性能: 性能极高,特别是当源文件和 Docker 引擎都位于同一个原生文件系统时(例如我们的 WSL2 环境)。
最佳应用场景:
- 开发时的代码同步: 这是其最核心、最广泛的用途,用于实现代码热重载。
- 共享配置文件: 将宿主机上的配置文件(如
nginx.conf)直接挂载到容器中,方便在不重建镜像的情况下修改配置。 - 共享构建产物: 在 CI/CD 流程中,可能会将在宿主机上构建好的产物,挂载到容器中进行测试。
决策框架:一句话总结
当面临选择时,问自己一个简单的问题:
“这份数据是由我的应用在生产中产生的,需要被安全地‘托管’起来吗?”
- 如果是,请使用
Volumes。
- 如果是,请使用
“这份数据是我作为开发者在宿主机上编写的源代码或配置文件,需要实时同步到容器里进行调试吗?”
- 如果是,请使用
Bind Mounts。
- 如果是,请使用
在结束本章的核心内容前,如果您还在运行上一节的开发容器,请清理它:
1 | docker stop backend-api-dev && docker rm backend-api-dev |
5.5. 本章核心速查总结与面试题
承上启下: 在本章中,我们完成了从单体容器到多服务协作的关键一步。通过引入自定义网络,我们解决了服务间的通信问题;通过学习数据卷和绑定挂载,我们掌握了生产数据持久化和开发环境优化的核心技巧。这些知识是后续学习 docker-compose 进行复杂服务编排的绝对基石。
本节,我们将所有关键点浓缩成一张速查表和一道高频面试题,以便您日后快速回顾。
核心速查总结
| 分类 | 关键命令 / 标志 | 核心描述 |
|---|---|---|
| 网络 | docker network create <net_name> | (推荐) 创建一个自定义的 bridge 网络,为容器提供基于服务名的 DNS 解析能力。 |
| 网络 | docker network ls | 列出当前主机上所有的 Docker 网络。 |
| 网络 | docker run --network <net_name> | 将一个容器连接到指定的网络。 |
| 持久化 | docker volume create <vol_name> | 创建一个由 Docker 管理的具名数据卷 (Volume),用于持久化生产数据。 |
| 持久化 | docker volume ls | 列出当前主机上所有的 Docker 数据卷。 |
| 持久化 | docker run -v <vol_name>:<ctn_path> | (Volume 挂载) 将一个具名数据卷挂载到容器的指定路径。 |
| 持久化 | docker run -v <host_path>:<ctn_path> | (Bind Mount) 将一个宿主机的目录或文件挂载到容器的指定路径。 |
总结要点:
- 容器间的通信,首选 通过将它们连接到同一个 自定义 bridge 网络 来实现。
- 容器的数据持久化,根据场景选择:
- 生产环境 或由应用管理的数据,首选 使用
Volumes。 - 开发环境 需要同步源代码和配置文件,首选 使用
Bind Mounts。
- 生产环境 或由应用管理的数据,首选 使用
高频面试题与陷阱
你好,看你对 Docker 比较熟悉。那你能深入讲讲 Docker 中 Volumes 和 Bind Mounts 这两种数据持久化方式的 核心区别,以及它们各自 最适合的应用场景 吗?
当然可以。它们最核心的区别在于数据的 管理者 和 生命周期。
Volumes 是由 Docker 引擎 来管理的,它的生命周期完全独立于任何容器。您可以把它想象成一个专供容器使用的、可插拔的“数据盘”。它的主要应用场景是 生产环境的数据持久化,比如数据库文件、用户上传的内容、需要长期保存的应用状态等。它的优点是平台无关、性能由 Docker 优化,且更安全,因为它将应用数据和宿主机的文件系统隔离开了。
而 Bind Mounts 则是直接将 宿主机 上的一个具体文件或目录映射到容器里。数据的管理者是宿主机上的用户或进程。它的核心应用场景是 开发环境,我们可以通过它将本地的源代码目录直接映射到容器里,配合 nodemon 这样的工具,实现代码的 热重载,极大地提升开发效率。
很好,回答得很清晰。那你刚才提到的,在开发环境中使用 Bind Mounts 挂载源代码,有没有什么常见的“陷阱”需要注意?
有一个非常经典的陷阱,就是关于 node_modules 目录的处理。如果在宿主机(比如 macOS 或 Windows)上运行过 npm install,然后在 docker run 时,将整个项目目录(包含了宿主机生成的 node_modules)通过 Bind Mount 挂载到基于 Linux 的容器中,通常会导致应用崩溃。
这是因为宿主机上为特定操作系统编译的原生模块,与容器内 Alpine Linux 所需的模块不兼容。解决方案通常是在 Dockerfile 中正常执行 RUN npm install,然后在 docker run 时,使用一个匿名的 Volume 来“覆盖”掉被 Bind Mount 进来的 node_modules,从而让容器使用自己在镜像内部安装的、正确的依赖版本。
第六章: 终结繁琐:使用 Docker Compose 编排多容器应用
摘要: 在本章,我们将彻底告别那些繁琐、冗长且需要手动按顺序执行的 docker 命令。我们将学习使用 Docker Compose——现代容器化应用编排的基石——来让我们用一份独立的、声明式的 docker-compose.yml 配置文件,描述 并 管理 我们整个前后端分离的应用。本章结束后,您将能通过 docker compose up 和 docker compose down 两个简单的命令,实现整个应用环境的一键启动与销毁。
本章的起点:回顾第五章的“痛苦”
在深入 Docker Compose 之前,让我们清晰地回顾一下,在上一章为了让我们的前后端应用跑起来,我们手动执行了多少步骤:Z
docker network create my-app-network(手动创建网络)docker volume create my-api-data(手动创建数据卷)docker run -d --name backend-api --network ... -v ... my-api:1.1(手动启动后端,并挂载网络和数据卷)docker run -d --name frontend --network ... -p ... my-react-app:production-v1.0(手动启动前端,并挂载网络和端口)docker stop backend-api frontend && docker rm backend-api frontend(手动清理)
这个过程不仅繁琐,而且极易出错。任何一个参数的遗漏或错误,都可能导致应用无法正常工作。Docker Compose 的诞生,正是为了将我们从这种指令式的、过程化的操作中解放出来。
6.1. 初识 docker-compose.yml:将命令翻译为配置
承上启下: 我们将学习如何将上一章那些冗长的 docker run 命令,逐字逐句地“翻译”成 docker-compose.yml 文件中的配置项。这将是我们从“命令式”操作转向“声明式”管理的第一次实践。
第一步:创建 docker-compose.yml 文件
在您项目的根目录下(即包含 my-react-app 和 backend-api 两个子目录的地方),创建一个名为 docker-compose.yml 的新文件。这个 YAML 文件将是我们应用所有服务的“总纲”。
第二步:将后端服务“翻译”为 Compose 配置
我们的目标是翻译这条命令:docker run -d --name backend-api --network my-app-network -v my-api-data:/app/data my-api:1.1
我们在 docker-compose.yml 中这样描述它:
1 | # docker-compose.yml (v0.1 - 初始翻译) |
引入一个更佳实践:由 Compose 直接构建镜像
直接使用 image: my-api:1.1 意味着我们必须先手动 docker build 好这个镜像。但 Compose 提供了更强大的功能:它可以直接根据 Dockerfile 为我们构建镜像。
我们将 image 配置项替换为 build:
1 | # docker-compose.yml (v0.1 - 初始翻译) |
这比手动构建要方便得多。
第三步:将前端服务“翻译”为 Compose 配置
同样地,我们来翻译前端的启动命令:docker run -d --name frontend --network my-app-network -p 8080:80 my-react-app:production-v1.0
将其追加到 docker-compose.yml 文件中:
1 | # docker-compose.yml (v0.1 - 完整初稿) |
关于 version 字段
在旧版的 docker-compose.yml 文件中,你通常会在文件顶部看到一个 version: '3.8' 这样的字段。在新版的 Docker Compose 中,这个字段已经变为可选。Compose 会根据你使用的 YAML 关键字自动推断文件格式。为保持简洁,我们遵循现代规范,省略该字段。
第四步:第一次运行
我们已经有了一个初步的 docker-compose.yml 文件。现在,我们不再需要 docker run 了。在 docker-compose.yml 所在的根目录下,执行:
1 | docker compose up |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
[+] Building 2.5s (15/15) FINISHED
=> [backend-api internal] load build definition from Dockerfile
=> => transferring dockerfile: 142B
...
=> [frontend internal] load build definition from Dockerfile
=> => transferring dockerfile: 621B
...
[+] Running 2/2
✔ Container backend-api Started
✔ Container frontend Started
Attaching to backend-api, frontend
backend-api | API server listening on port 3000
frontend | /docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
...
您会看到:
- Docker Compose 首先并行 构建 了
backend-api和frontend两个服务的镜像。 - 然后,它 启动 了两个容器。
- 由于我们没有加
-d参数,所有服务的日志会混合输出到当前终端,这对于初次启动和调试非常有用。
现在,你可以访问 http://localhost:8080,前端页面应该可以正常显示。
第五步:识别缺失的环节并清理
虽然服务启动了,但我们的 v0.1 版本还存在明显的问题:
- 我们还没有定义
my-app-network,所以前后端容器之间依然无法通信。 - 我们还没有定义
my-api-data数据卷,所以后端的数据依然是易失的。
在终端中按下 Ctrl+C,Compose 会优雅地停止所有服务。然后,执行以下命令来彻底清理本次启动创建的所有资源(容器、默认网络等):
1 | docker compose down |
我们已经成功地将启动命令转化为了配置文件,并体验了 docker compose 的基本工作流程。在下一节,我们将把网络和数据卷的定义也加入进来,构建一个完整的多服务应用。
6.2. 协同工作:在 Compose 中定义 networks 与 volumes
承上启下: 在上一节,我们成功地将 docker run 命令的基本操作“翻译”成了 docker-compose.yml 中的 services 配置。然而,我们的应用目前还处于“残缺”状态:前后端服务之间无法通信,后端的数据也无法持久化。现在,我们将把在第五章手动创建的 network 和 volume 也纳入 Compose 的管理体系,构建一个功能完整的应用栈。
第一步:在 Compose 文件中声明“共享资源”
docker-compose.yml 不仅能定义 services,还能在顶层定义我们整个应用栈所需的共享资源,例如网络和数据卷。
请用以下内容 覆盖 你现有的 docker-compose.yml 文件。我们在 services 的 同级,新增了 networks 和 volumes 两个顶层关键字。
1 | # docker-compose.yml (v0.2 - 添加网络与数据卷) |
代码解读:
- 我们在文件底部使用
networks和volumes块,像声明变量一样,声明 了我们应用需要一个名为my-app-network的网络和一个名为my-api-data的数据卷。 - 在每个
service的定义内部,我们通过networks和volumes关键字来 引用 这些已声明的资源,将服务“接入”网络或“挂上”数据卷。
第二步:“一键启动”完整应用
我们的 docker-compose.yml 文件现在已经描述了一个功能完整的应用栈。让我们来启动它。这次,我们将使用 -d 参数,让它在后台运行。
1 | docker compose up -d |
1
2
3
4
5
[+] Running 4/4
✔ Network my-docker-guide_my-app-network Created
✔ Volume "my-docker-guide_my-api-data" Created
✔ Container backend-api Started
✔ Container frontend Started
这就是 Compose 的魔力! 只用一个命令,Docker Compose 就为我们自动完成了所有事情:
- 它检查到
my-app-network网络不存在,于是 自动创建 了它。 - 它检查到
my-api-data数据卷不存在,于是也 自动创建 了它。 - 它构建了两个服务的镜像(如果需要),并以正确的配置(连接了网络、挂载了数据卷)启动了两个容器。
你可能会注意到,Compose 创建的网络和数据卷名前面,被自动加上了项目目录名作为前缀(例如 my-docker-guide_my-app-network)。这是 Compose 用来隔离不同项目资源的方式,非常实用。
第三步:全面验证
验证网络通信: 我们可以使用
docker compose exec命令,在某个服务容器内执行命令。1
2# 在 frontend 容器内,执行 curl 命令访问 backend-api 服务
docker compose exec frontend sh -c "curl http://backend-api:3000/api/data"您应该能看到后端 API 成功返回了 JSON 数据,证明了服务间的 DNS 解析和通信完全正常。
验证数据持久化:
- 连续执行几次上面的
exec命令,让计数器增长。 - 现在,执行
docker compose down来 销毁 应用环境。该命令会停止并删除容器、网络,但 默认会保留具名数据卷,以防数据丢失。1
docker compose down
- 再次执行
docker compose up -d重建 应用环境。 - 最后,再次执行
exec命令访问 API。1
docker compose exec frontend sh -c "curl http://backend-api:3000/api/data"
您会发现
hits计数器在上次的基础上继续增加了!这证明了数据卷成功地在容器的“生死轮回”之间,为我们保全了数据。- 连续执行几次上面的
如果您希望在 down 的时候,连同数据卷也一起删除,可以使用 -v 标志:docker compose down -v。请谨慎操作此命令。
我们现在已经拥有了一个健壮的、可一键部署和销毁的多服务应用定义。在下一节,我们将为这个应用引入数据库,并学习如何管理服务之间的启动依赖关系。
6.3. 管理依赖与健康:depends_on 与 healthcheck
承上启下: 我们的应用正在变得越来越真实。一个典型 Web 应用除了前后端,还必然包含一个数据库。现在,我们将为系统添加一个 PostgreSQL 数据库服务。这个新角色的加入,会立刻引入一个在多服务架构中至关重要的新问题:服务启动依赖。后端 API 必须在数据库完全准备好之后才能启动,否则就会因为连接失败而崩溃。
第一步:在 docker-compose.yml 中添加数据库服务
我们首先在 docker-compose.yml 文件中定义我们的新成员:一个 postgres 数据库服务。
请用以下内容 覆盖 你现有的 docker-compose.yml 文件。注意新增的 db 服务和 db-data 数据卷:
1 | # docker-compose.yml (v0.3 - 添加数据库) |
第二步:改造后端 API 并重建镜像(关键修正)
现在,我们让 backend-api 在启动时去尝试连接数据库。这需要我们安装新的 npm 依赖,并 明确地重建镜像。
首先,为 backend-api 项目添加 pg 依赖库。
1 | cd backend-api |
然后,用以下仅用于测试数据库连接的代码,覆盖 backend-api/index.js。
1 | // backend-api/index.js (仅用于测试数据库连接) |
接着,执行最关键的一步:重建后端镜像。
因为我们修改了 package.json(通过 npm install pg),旧的镜像已经过时,它内部的 node_modules 缺少 pg 模块。我们必须基于新的代码和依赖,构建一个新的镜像。docker compose build 命令就是为此而生。
1 | docker compose build backend-api |
这个命令会告诉 Compose:“请只重新构建 backend-api 服务的镜像”。
第三步:制造“启动失败”的场景
镜像已正确更新,现在我们可以来观察服务间的启动竞争问题了。
1 | docker compose up |
仔细观察前台输出的日志。你会看到 backend-api 服务在疯狂地尝试重启,并不断打印出 Failed to connect... ECONNREFUSED 的错误。
1 | my-app-db | ... database system is ready to accept connections |
痛点所在: Docker Compose 默认以 并行 方式启动所有服务。backend-api 启动得太快了,此时 db 容器虽然可能已经创建,但其内部的 PostgreSQL 服务进程还 没有完全初始化好并准备接受连接,导致 API 连接失败并崩溃。
请按下 Ctrl+C 并执行 docker compose down 清理环境。
第四步:使用 depends_on 与 healthcheck 确保服务可用
为了解决这个问题,我们需要一个组合拳:使用 depends_on 控制启动的 顺序,并使用 healthcheck 确保我们等待的是一个 真正可用 的服务。
请将最终的、完整的 docker-compose.yml 修改如下:
1 | # docker-compose.yml (v0.4 - 健壮的依赖管理) |
关键改动:
- 我们在
db服务下添加了healthcheck块,使用 PostgreSQL 自带的pg_isready工具来检查数据库是否就绪。 - 我们将
backend-api的depends_on修改为更精确的格式,明确要求它等待db服务的状态变为healthy后再启动。
最终验证
现在,再次执行 docker compose up -d 启动整个应用。然后立刻执行 docker compose ps 查看服务状态,你会看到 db 服务的状态最初是 running (health: starting),几秒后会变为 running (healthy)。
此时,查看 backend-api 的日志 docker compose logs backend-api,你会看到一条干净利落的成功连接信息:
✅ Successfully connected to the database!
6.4. 解耦配置:环境变量与 .env 文件
承上启下: 在上一节,我们成功地为应用添加了数据库服务,并解决了启动依赖问题。但在 docker-compose.yml 文件中,我们留下了一个巨大的隐患:我们将数据库的用户名和密码 硬编码 在了配置文件里。将敏感凭证直接写入版本控制系统,是软件开发中的 头号禁忌。
解决方案:使用 .env 文件进行配置解耦
Docker Compose 提供了一套优雅的机制来解决这个问题。它允许我们在 docker-compose.yml 中使用变量占位符,然后在一个名为 .env 的独立文件中定义这些变量的实际值。Compose 在启动时会自动读取 .env 文件,并将值注入到配置中。
核心优势:
- 安全: 我们可以将
.env文件添加到.gitignore中,确保敏感信息永远不会被提交到代码仓库。 - 灵活: 团队中的每个成员都可以在本地维护自己的
.env文件,而无需修改共享的docker-compose.yml。 - 环境一致: 生产服务器上可以放置一个包含生产密码的
.env文件,实现不同环境的配置切换。
第一步:创建 .env 文件
在您项目的根目录下(与 docker-compose.yml 文件位于同一级),创建一个名为 .env 的新文件。
1 | # .env - 存储我们所有的敏感信息和环境特定配置 |
在真实项目中,请立刻将 .env 文件添加到你的 .gitignore 文件中!
第二步:改造 docker-compose.yml 以使用变量
现在,我们修改 docker-compose.yml,用 ${VARIABLE_NAME} 的语法来引用 .env 文件中定义的变量。同时,我们也要将这些凭证传递给 backend-api 服务,以便它能连接到数据库。
请用以下内容 覆盖 你现有的 docker-compose.yml 文件:
1 | # docker-compose.yml (v0.5 - 使用环境变量) |
第三步:改造 backend-api 以读取环境变量
我们的 backend-api 服务现在需要从环境变量(process.env)中读取数据库连接信息,而不是使用硬编码的值。
用以下内容 覆盖 backend-api/index.js 文件:
1 | // backend-api/index.js (读取环境变量) |
第四步:最终验证
所有改造都已完成。现在,我们来验证配置是否被成功加载。
首先,清理掉可能在运行的旧环境。
1 | docker compose down |
接着,使用 docker compose config 命令来预览 Compose 解析后的最终配置。 这是一个非常有用的调试工具。
1 | docker compose config |
在输出的 YAML 中,你应该能看到 db 和 backend-api 服务的 environment 部分,${...} 占位符已经被 .env 文件中的 实际值 所替换。
然后,一键启动整个应用。
1 | docker compose up -d |
最后,查看 backend-api 的日志。
1 | docker compose logs backend-api |
你应该能看到那条成功的连接信息:✅ Successfully connected to the database using credentials from .env file!
6.5. 环境隔离:使用 profiles 管理服务组合
承上启下: 我们的 docker-compose.yml 正在演变成一个完整的应用定义,包含了前端、后端和数据库。在真实的开发流程中,我们常常还需要一些 辅助服务,例如数据库管理工具、日志分析平台或测试工具。这些服务在开发和调试时非常有用,但在默认启动或生产部署时,我们并不希望运行它们。profiles 功能正是为了优雅地解决这个问题而设计的。
痛点背景:如何管理“可选”服务?
我们希望在 docker-compose.yml 中定义一个数据库管理工具(例如 Adminer),但我们不希望每次执行 docker compose up 时它都自动启动。我们只想在需要进行数据库调试时,才手动将它“激活”。
解决方案:为服务分配 profiles (配置文件)
profiles 关键字允许我们为一个或多个服务打上“标签”。被打上标签的服务,将不会被默认启动。只有当我们在命令行中明确激活该标签(profile)时,这些服务才会被创建和启动。
第一步:在 docker-compose.yml 中添加调试服务
我们来为应用栈添加一个 adminer 服务。Adminer 是一个轻量级的、通过 Web 界面管理多种数据库的工具。
请将 adminer 服务的定义,添加到您的 docker-compose.yml 文件中。
1 | # docker-compose.yml (v0.6 - 添加 Profile) |
第二步:验证默认启动行为
现在,我们来启动我们的应用栈。
1 | docker compose up -d |
启动完成后,我们来查看正在运行的服务。
1 | docker compose ps |
1
2
3
4
NAME IMAGE COMMAND SERVICE STATUS PORTS
backend-api my-docker-guide-backend-api "docker-entrypoint.s…" backend-api running
frontend my-docker-guide-frontend "/docker-entrypoint.…" frontend running 0.0.0.0:8080->80/tcp
my-app-db postgres:16-alpine "docker-entrypoint.s…" db running (healthy) 5432/tcp
请注意,adminer 服务 没有 被启动。因为我们为它分配了一个 profile,它已经变成了一个“可选”服务。
第三步:激活 debug Profile
现在,我们假设需要调试数据库。我们可以使用 --profile 标志来同时启动默认服务和 debug profile 中的所有服务。
首先,清理掉当前的环境。
1 | docker compose down |
然后,使用 --profile 标志启动。
1 | docker compose --profile debug up -d |
再次查看正在运行的服务。
1 | docker compose ps |
1
2
3
4
5
NAME IMAGE COMMAND SERVICE STATUS PORTS
adminer adminer "entrypoint.sh docke…" adminer running 0.0.0.0:8081->8080/tcp
backend-api my-docker-guide-backend-api "docker-entrypoint.s…" backend-api running
frontend my-docker-guide-frontend "/docker-entrypoint.…" frontend running 0.0.0.0:8080->80/tcp
my-app-db postgres:16-alpine "docker-entrypoint.s…" db running (healthy) 5432/tcp
这一次,adminer 服务成功启动了!
第四步:使用 Adminer 连接数据库
现在,打开你的 Windows 浏览器,访问 http://localhost:8081。你将看到 Adminer 的登录界面。
- System: 选择
PostgreSQL - Server: 输入
db(这是我们在 Compose 中为数据库服务定义的名字!) - Username: 输入我们在
.env文件中定义的prorise_user - Password: 输入我们在
.env文件中定义的s3cr3t_p@ssw0rd_zxcv - Database: 输入我们在
.env文件中定义的prorise_db
点击登录,你就可以通过图形化界面来查看和管理 my-app-db 容器中的数据库了。
在结束本节前,请清理环境:
1 | docker compose down |
6.6. 本章核心速查总结:Docker Compose 常用配置与命令
承上启下: 恭喜您!您已经成功地从执行零散的 docker 命令,迈入了使用 docker-compose.yml 进行声明式服务编排的全新阶段。我们通过一步步的迭代,将一个多服务应用从手动管理的混乱状态,转化为了一个优雅、健壮、可一键启停的应用栈。本节将把本章所有核心的 YAML 关键字和 CLI 命令浓缩起来,作为您日后工作中可随时查阅的“弹药库”。1
docker-compose.yml 核心关键字速查
| 分类 | 关键字 | 核心描述与用法 |
|---|---|---|
| 服务定义 | services | 顶层关键字,所有独立的应用服务都在其下定义。 |
| 镜像来源 | build: <path> | (推荐) 指定包含 Dockerfile 的路径,让 Compose 负责构建镜像。 |
| 镜像来源 | image: <name>:<tag> | 指定一个已经存在于本地或远程仓库的镜像。 |
| 容器配置 | container_name: <name> | 设置一个固定的、可读的容器名称,对应 docker run --name。 |
| 网络 | ports: ["<host>:<container>"] | 映射端口,对应 docker run -p。 |
| 网络 | networks: ["<net_name>"] | 将服务连接到在顶层 networks 块中定义的网络。 |
| 数据持久化 | volumes: ["<vol/path>:<ctn_path>"] | 挂载数据卷或绑定挂载,对应 docker run -v。 |
| 配置 | environment: ["KEY=VALUE"] | 设置环境变量,支持从 .env 文件进行 ${VAR} 格式的变量替换。 |
| 启动控制 | depends_on | 控制服务启动顺序。推荐与 healthcheck 结合使用。 |
| 启动控制 | healthcheck | 定义一个命令来检查容器内应用是否真正健康、可用。 |
| 环境管理 | profiles: ["<profile_name>"] | 将服务分配给一个非默认的配置文件组,实现服务的按需启动。 |
| 资源声明 | networks / volumes | 顶层关键字,用于声明整个应用栈所需的网络和数据卷资源。 |
docker compose 核心命令速查
| 命令 | 核心描述与常用参数 |
|---|---|
docker compose up | (核心) 根据 docker-compose.yml 创建并启动所有服务。默认在前台运行。 |
-d: 在后台(detached)模式下运行。 | |
--build: 强制重新构建所有服务的镜像,即使已存在。 | |
--profile <name>: 激活指定 profile 中的服务。 | |
docker compose down | (核心) 停止并 移除 所有相关的容器、网络。 |
-v: 同时移除在 volumes 块中定义的具名数据卷。 | |
docker compose ps | 列出当前 Compose 项目所管理的所有容器的状态。 |
docker compose logs [service_name] | 查看一个或所有服务的日志。 |
-f: 持续跟踪(follow)实时日志输出。 | |
docker compose exec <service> <cmd> | 在指定服务的一个正在运行的容器中,执行一个命令。 |
docker compose build [service_name] | 构建或重新构建一个或所有服务的镜像。 |
docker compose config | 验证并显示经过变量替换和解析后的最终配置,是调试的利器。 |
高频面试题与陷阱
在 docker-compose.yml 中,depends_on 和 healthcheck 是如何协同工作的?为什么说只用 depends_on 还不够可靠?
这是一个非常好的问题,它触及了多服务应用稳定启动的核心。
单独使用 depends_on,比如 depends_on: ['db'],它只保证了一件事:db 服务的 容器 会在 api 服务的 容器 启动之前被启动。但它完全不关心 db 容器 内部 的 PostgreSQL 进程是否已经完成了初始化、是否已经准备好接受外部连接。
这就会产生一个“竞态条件”:API 容器可能已经启动并开始尝试连接数据库,而此时数据库服务进程还在加载配置、检查文件,根本没“开门营业”,从而导致 API 连接失败并崩溃。
说得很好。那 healthcheck 是如何解决这个问题的?
healthcheck 解决了“知其然,并知其所以然”的问题。我们在数据库服务中定义一个 healthcheck,比如用 pg_isready 命令。Docker 会在容器启动后,定期执行这个命令。只有当 pg_isready 成功返回,Docker 才会将这个容器的状态标记为 healthy。
然后,我们将 API 服务的 depends_on 升级为 depends_on: { db: { condition: service_healthy } }。这样一来,Compose 的行为就变成了:“启动 db 容器,然后持续等待,直到 db 服务的 healthcheck 状态变为 healthy,然后,且仅当此时,才启动 api 服务”。这就完美地解决了竞态条件,确保了应用栈的启动是健壮和可预测的。






