
Prorise
这是我的博客,分享技术与生活的点点滴滴
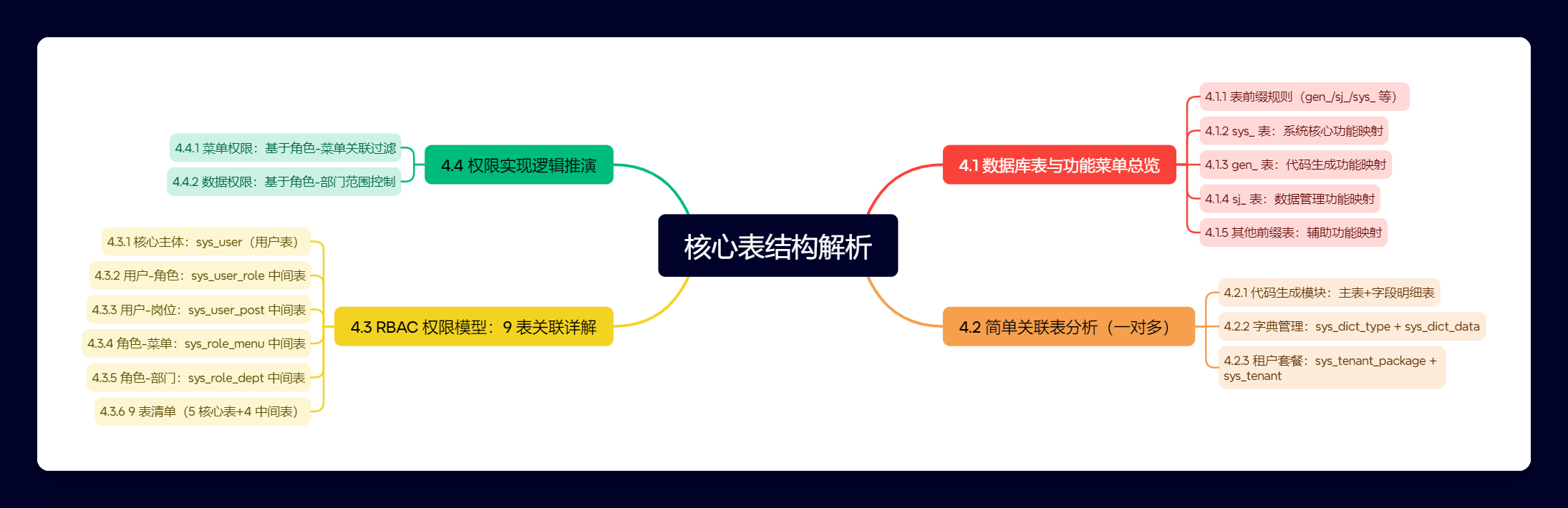
第四章. 核心数据库表结构解析
第四章. 核心数据库表结构解析
Prorise第四章. 核心数据库表结构解析)
摘要:本章我们将深入数据库层面,彻底解析“瘦身”后 RVP 5.x 框架的核心表结构。我们将从“表菜单”映射入手,识别每个表的功能,然后重点分析“租户”、“字典”等简单关联,最后将 重中-之重 放在 sys_user (用户) 表上,详细拆解其与角色、部门、岗位、菜单之间的 9 表关联(RBAC 模型),为你后续理解“权限控制”和“数据权限”打下最坚实的地基。
本章学习路径
我们将按照“从宏观到微观、从简单到复杂”的路径,一步步解构 RVP 的核心数据库:
4.1. 数据库表与功能菜单总览
在第三章中,我们成功完成了 ruoyi-workflow 模块的“架构瘦身”,得到了一个更轻量、启动更快的后端项目,数据库也变得更加整洁。然而,一个不熟悉数据库的开发者,就像一个不熟悉地基的建筑师。我们数据库中还剩下 gen_、sj_、sys_ 等几十张表。它们分别对应什么功能?
为了在后续章节中真正理解框架的原理(特别是权限控制),本节我们将严格按照教学文稿的指引,把这些剩余的表和后台管理界面的功能菜单进行一次“连连看”,彻底弄清每个表的功能。
为什么要建立映射?
在深入研究复杂的关系(如 RBAC)之前,我们必须先建立一个宏观的认识。知道哪个表支撑哪个功能,是我们后续阅读源码、进行二次开发的基础蓝图。
是什么?
“瘦身”后的数据库表,根据其功能和前缀,主要分为三大类:
gen_...:代码生成模块。sj_...:SnailJob 任务调度模块。sys_...:系统核心模块(权限、租户、日志等)。我们将逐一解析这些表。
4.1.1. 扩展模块表(gen_ 与 sj_)
这两类表属于 RVP 框架集成的扩展功能,它们与核心的 sys_ 表关联较少。
1. 代码生成(gen_...)
这两张表对应的是后台管理界面中的 “系统工具” -> “代码生成” 菜单。
gen_table:存储代码生成的“主表”信息,例如您要为哪个表生成代码、作者是谁、生成的模块名叫什么。gen_table_column:存储gen_table中每张表的“字段”信息,例如字段类型、是否为查询条件、使用什么 HTML 控件(如输入框、下拉框)等。
为了解决“代码生成”的需求,RVP 提供了 gen_table 表来存储元数据:
1 | -- 代码生成-业务表 (简化版) |
- 核心要点:
gen_table和gen_table_column是代码生成器的“蓝图”,我们对它们的操作(增删改查)就是配置代码生成策略的过程。
2. 任务调度(sj_...)
所有以 sj_ (SnailJob) 开头的表,对应的都是 “系统监控” -> “任务调度中心” 菜单。
sj_...:这些表(如sj_job_info,sj_job_batch,sj_namespace等)是 SnailJob 任务调度框架自身运行所需的核心表,用于存储任务信息、执行批次、命名空间等。
1 | -- 任务调度-任务信息表 (SnailJob 简化版) |
4.1.2. 系统核心表(sys_)
这批表是 RVP 框架的基石,支撑着 系统管理、租户管理 等核心功能,我们的学习重点将围绕它们展开。
sys_config:对应 “系统管理” -> “参数设置”。用于存储系统的全局配置项,如“主框架页-默认皮肤主题”。sys_dept:对应 “系统管理” -> “部门管理”。存储组织架构(如“xx 公司”、“xx 部门”)。sys_dict_type和sys_dict_data:对应 “系统管理” -> “字典管理”。type存储字典类型(如sys_user_sex- 用户性别),data存储具体的键值对(如0= 男,1= 女)。
1 | -- 字典类型表 (简化版) |
sys_logininfor:对应 “系统管理” -> “日志管理” -> “登录日志”。记录用户的登录和登出行为。sys_menu:对应 “系统管理” -> “菜单管理”。存储系统的所有菜单和按钮权限(如“系统管理”、“用户新增”)。sys_notice:对应 “系统管理” -> “通知公告”。sys_oper_log:对应 “系统管理” -> “日志管理” -> “操作日志”。记录用户对系统的所有操作(增删改查)。sys_oss和sys_oss_config:对应 “系统工具” -> “文件管理”。config存储 OSS(对象存储,如 Minio、阿里云)的配置,oss存储上传的文件记录。sys_post:对应 “系统管理” -> “岗位管理”。存储岗位信息(如“CEO”、“Java 工程师”)。sys_role:对应 “系统管理” -> “角色管理”。存储角色信息(如“管理员”、“普通用户”)。sys_social:对应 “系统管理” -> “三方登录”。存储绑定的第三方账号信息(如 Gitee、GitHub)。sys_tenant和sys_tenant_package:对应 “租户管理” 菜单。tenant存储租户(公司)信息,package存储租户可用的套餐(如“免费版”、“专业版”)。sys_user:对应 “系统管理” -> “用户管理”。存储系统的登录用户信息,是 RBAC 权限的核心。
1 | -- 用户信息表 (简化版) |
4.1.3. 核心关联表(中间表)
除了上述的“实体表”,数据库中还有几张表名类似 sys_a_b 的表,它们是连接各个实体的“桥梁”(中间表),用于实现“多对多”关系:
sys_role_dept:角色-部门关联表。sys_role_menu:角色-菜单关联表。sys_user_post:用户-岗位关联表。sys_user_role:用户-角色关联表。
这些表是 RVP 权限设计的精髓,我们将在 4.3 节中详细解剖它们。
4.1.4. 本节小结
我们完成了数据库表的“宏观”认知,将它们与具体的功能菜单进行了映射。
核心要点:
- 数据库表按前缀可分为三大类:
gen_(代码生成)、sj_(任务调度)和sys_(系统核心)。 sys_表是框架的基石,包含了用户、角色、菜单、部门、岗位等核心实体。sys_user_role这类中间表是实现 RBAC 权限(多对多)的关键。
瘦身后的核心表清单(速查):
| 表前缀 | 表名(示例) | 对应菜单(后台 UI) | 作用 |
|---|---|---|---|
gen_ | gen_table, gen_table_column | 系统工具 -> 代码生成 | 存储代码生成的配置信息 |
sj_ | sj_job_info, sj_job_batch… | 系统监控 -> 任务调度中心 | SnailJob 框架运行数据 |
sys_ | sys_user | 系统管理 -> 用户管理 | 核心用户表 |
sys_ | sys_role | 系统管理 -> 角色管理 | 核心角色表 |
sys_ | sys_menu | 系统管理 -> 菜单管理 | 核心菜单/权限表 |
sys_ | sys_dept | 系统管理 -> 部门管理 | 核心部门表 |
sys_ | sys_post | 系统管理 -> 岗位管理 | 核心岗位表 |
sys_ | sys_dict_type, sys_dict_data | 系统管理 -> 字典管理 | 存储字典键值对 |
sys_ | sys_tenant, sys_tenant_package | 租户管理 | 租户及套餐信息 |
sys_ | sys_logininfor, sys_oper_log | 系统管理 -> 日志管理 | 存储登录和操作日志 |
sys_ | sys_oss_config, sys_oss | 系统工具 -> 文件管理 | OSS 配置和文件记录 |
sys_ | sys_social | 系统管理 -> 三方登录 | 社交登录绑定关系 |
sys_ | sys_user_role (中间表) | (隐藏) | 连接用户和角色 |
sys_ | sys_role_menu (中间表) | (隐藏) | 连接角色和菜单 |
4.2. 独立与简单关联表分析
在 4.1 节中,我们对所有核心表的功能和前缀(gen_、sj_、sys_)有了宏观认识,就像拿到了一张布满“点”的地图。但要理解它们如何协同工作,光看“点”是不够的,我们必须开始分析连接这些“点”的“线”(即表关系)。本节我们将从最简单的关系入手:分析那些“独立”的表和经典的“一对多”关联表,为后续理解复杂的多对多 RBAC 模型打下坚实的基础。
4.2.1. 独立表:系统配置与日志
在 RVP 框架中,有几张表的设计相对“独立”,它们不依赖于复杂的业务逻辑,而是为系统提供基础支持。我们首先来看 sys_config(参数配置表)和 sys_oper_log(操作日志表)。
参数配置表 (sys_config)
我们首先要理解,为什么需要 sys_config 这张表?在项目开发中,我们经常遇到一些需要动态调整的变量,例如“新用户初始密码”、“文件上传大小限制”等。如果将这些值 硬编码(Hardcoding,即写死在代码里),每次修改都需要后端开发人员修改代码、重新打包并部署服务,效率极低且风险高。
为了解决这个问题,RVP 设计了 sys_config 表,它本质上是一个数据库化的键值对(Key-Value)存储。
1 | create table sys_config ( |
在这张表中,config_key 是程序用来获取配置的唯一键。例如,RVP 中重置密码的功能,就会在代码中读取 sys.user.initPassword 的值。config_type 字段用于标记是否为系统内置,'Y'(是)通常表示这是框架运行必需的配置,防止管理员在后台误删。
在我们的二次开发中,这张表非常有用。设想一下,我们需要增加一个“全局文件上传大小限制”。正确的做法是:
- 在
sys_config表中插入一条新纪录:config_key:sys.file.maxUploadSizeMbconfig_value:10config_name:全局上传大小限制(MB)
- 在 Java 代码中,注入 RVP 封装好的服务(如通过
RedisUtils获取缓存)来读取sys.file.maxUploadSizeMb的值进行判断。
如此一来,当运营人员需要将限制调整到 20MB 时,他们只需在【系统管理】->【参数设置】菜单中修改这个值,系统即可动态生效,无需我们后端开发人员介入。
操作日志表 (sys_oper_log)
看完了配置表,我们再来分析另一张同样重要的独立表:sys_oper_log(操作日志表)。这张表是系统的“黑匣子”,用于安全审计和问题排查。
当线上数据出现异常(例如,一个用户的关键信息被恶意篡改,或一个重要订单被误删),我们需要有据可查,必须能追溯到:谁 (Who) 在 什么时间 (When) 从 哪个 IP (Where) 做了 什么操作 (What),参数是什么 (How),以及 结果是成功还是失败 (Result)。
sys_oper_log 就是为了记录这一切而设计的。
1 | create table sys_oper_log ( |
这张表是通过 AOP(面向切面编程) 技术实现的。RVP 框架定义了一个 @Log 注解,当我们在 Controller 的方法上标记这个注解时,AOP 切面会自动拦截该方法的请求和响应,并将 oper_name(操作人)、oper_ip(IP 地址)、oper_param(请求参数)、json_result(返回结果)等信息异步存入这张表。
在二次开发中,我们不需要手动操作这张表。我们只需要在我们自己编写的、涉及重要操作(增、删、改)的 Controller 方法上,也加上 @Log 注解,就能自动享受到完整的操作审计功能。
4.2.2. 一对多:字典类型与字典数据
理解了独立表,我们开始进入表与表之间最常见的一种关系:一对多。字典管理(sys_dict_type 和 sys_dict_data)是这种设计的经典范例。
试想一个场景:系统中有很多地方需要用户选择“性别”,下拉框里是“男”、“女”、“未知”。我们不能在每个前端页面都写死这三个选项。如果哪天需要增加一个“保密”选项,岂不是要修改所有相关页面?
字典功能就是用来解决这个问题的。它将这些“可枚举”的数据变成了动态配置。
sys_dict_type(字典类型表):用于定义一个“类别”。sys_dict_data(字典数据表):用于存储这个“类别”下的所有可选“数据项”。
它们的关系是:一个“类型”对应多个“数据项”。
1. 字典类型表 (sys_dict_type)
1 | create table sys_dict_type ( |
这张表很简单,dict_name 是给人看的(如“用户性别”),dict_type 是给程序用的唯一标识(如 sys_user_sex)。
2. 字典数据表 (sys_dict_data)
这张表是关键,它通过 dict_type 字段与 sys_dict_type 表建立了关联。
1 | create table sys_dict_data ( |
关联分析:sys_dict_type 中的一条记录 (dict_type = 'sys_user_sex') 对应了 sys_dict_data 中的三条记录。
- 数据字典的运作原理:当我们需要在前端页面(如用户注册页)展示一个“性别”下拉框时:
- 前端向后端发起请求,调用“根据字典类型查询字典数据”的接口,参数为
sys_user_sex。 - 后端根据
dict_type = 'sys_user_sex'从sys_dict_data表中查出“男(0)”、“女(1)”、“未知(2)”三条数据。 - 前端动态渲染下拉框。
- 用户选择了“男”,前端提交给后端的
value是'0'。 - 后端在
sys_user表的sex字段中存储'0'。 - 当在列表页显示时,再根据
'0'反向查询sys_dict_data,得到dict_label为“男”,并在表格中显示“男”字。list_class字段则用来控制这个“男”字显示什么颜色。
- 前端向后端发起请求,调用“根据字典类型查询字典数据”的接口,参数为
4.2.3. 一对多:租户与租户套餐
RVP 框架的一大特色是支持多租户(SaaS 平台)。租户相关的表设计也使用了一对多,但关系与字典有所不同。
sys_tenant_package(租户套餐表):定义了 SaaS 服务的不同等级,例如“基础版”、“专业版”、“旗舰版”。sys_tenant(租户表):记录了所有入驻 SaaS 平台的“企业客户”。
它们的关系是:一个“套餐”可以被多个“租户”使用。
1. 租户套餐表 (sys_tenant_package)
这是“一”的一方。它定义了套餐包含哪些功能。
1 | create table sys_tenant_package ( |
核心字段是 menu_ids,它以逗号分隔的方式存储了该套餐能使用的所有菜单 ID(关联 sys_menu 表)。
2. 租户表 (sys_tenant)
这是“多”的一方。它记录了企业信息,并通过 package_id 关联到套餐表。
1 | create table sys_tenant ( |
关联分析:sys_tenant 表中的 package_id 字段,指向了 sys_tenant_package 表的 package_id。
- 二次开发场景:这个设计是 SaaS 系统的核心。当我们开发新功能时,比如开发了一个“高级报表”菜单。
- 我们在
sys_menu表中添加这个“高级报表”菜单(假设menu_id为 2001)。 - 运营人员在【租户管理】->【租户套餐】中,编辑“专业版”套餐,将
menu_id2001 添加到其menu_ids字段中。 - 此时,所有购买了“基础版”套餐的租户(他们的
package_id指向基础版)登录系统时,权限校验会发现他们的套餐不包含 2001 菜单,因此看不到“高级报表”。 - 而购买了“专业版”的租户,则可以正常看到并使用该功能。
- 这就实现了通过套餐配置动态控制不同企业客户功能可见性的目的。
- 我们在
4.2.4. 一对多:代码生成主表与字段表
最后我们来看 gen_ 前缀的这两张表。这是 RVP 的代码生成器功能所依赖的核心表。
gen_table(代码生成业务表):存储了要生成的“主表”信息。gen_table_column(代码生成业务表字段):存储了该主表下的“所有字段”信息。
它们的关系是:一个“表”对应多个“字段”。
1. 代码生成业务表 (gen_table)
1 | create table gen_table ( |
这张表存储了我们在【代码生成】界面上配置的各种信息,例如“包路径”、“模块名”、“作者”等。
2. 代码生成业务表字段 (gen_table_column)
1 | create table gen_table_column ( |
关联分析:gen_table_column 表中的 table_id 字段,指向了 gen_table 表的 table_id。
当我们点击“导入”按钮,从数据库中选择一张表(如 sys_user)时:
- RVP 会读取
sys_user的表信息,在gen_table中创建一条记录。 - 同时,RVP 会读取
sys_user的所有字段(如user_id,user_name,sex…),并在gen_table_column中创建多条记录,这些记录的table_id都指向第 1 步中创建的主表 ID。
当我们点击“编辑”时,会看到一个包含两部分的界面:
- 上半部分(基本信息、生成信息):修改的数据对应
gen_table。 - 下半部分(字段信息列表):修改的数据对应
gen_table_column。
这张 gen_table_column 表非常关键。它通过 html_type 告诉生成器这个字段在前端应该渲染成“文本框”还是“下拉框”;通过 dict_type 告诉生成器如果这是一个下拉框,应该去加载哪个字典(如 sys_user_sex);通过 is_query 告诉生成器这个字段是否作为查询条件。
理解了这张表的配置,我们就掌握了 RVP 代码生成器的精髓。
4.2.5. 本节小结
我们学习了独立表和“一对多”关联表的设计思想,这是理解 RVP 框架的基石。
- 独立表:
sys_config(参数配置)和sys_oper_log(操作日志)是系统的基础支撑。sys_config用于实现“配置与代码分离”,便于动态调整系统参数。sys_oper_log基于 AOP 实现,用于安全审计和问题排查。
- 一对多关系:是企业级系统中最常见的数据模型。
- 字典 (Type/Data):
sys_dict_type(一) 对应sys_dict_data(多),用于管理系统中的枚举值(如下拉框选项)。 - 租户 (Package/Tenant):
sys_tenant_package(一) 对应sys_tenant(多),用于实现 SaaS 平台的套餐功能隔离。 - 代码生成 (Table/Column):
gen_table(一) 对应gen_table_column(多),用于存储代码生成器的元数据配置。
- 字典 (Type/Data):
4.3. RBAC 权限模型:9 表关联详解
在 4.2 节中,我们掌握了系统设计中常见的“一对多”关系,例如字典类型与字典数据、租户套餐与租户。但在实际的权限管理中,“一对多”是远远不够的。
设想一个场景:一个“财务经理”角色,他需要访问“报表中心”、“工资条管理”、“审批管理”三个菜单。同时,“张三”和“李四”都是“财务经理”。
- 一个用户(张三)可以有多个角色(例如他同时也是“数据分析师”)。
- 一个角色(财务经理)可以被多个用户(张三、李四)拥有。
- 一个角色(财务经理)可以访问多个菜单。
- 一个菜单(报表中心)可以被多个角色(财务经理、数据分析师)访问。
这些都是“多对多”关系。本节我们将聚焦于 RVP 框架的精髓——RBAC(Role-Based Access Control,基于角色的访问控制)模型。我们将彻底解析支撑这套模型运行的 5 张核心实体表及其 4 张关联表,共 9 张表,这是理解整个系统权限设计的地基。
4.3.1. 什么是 RBAC?
RBAC(Role-Based Access Control)是企业级应用权限设计的行业标准。
它的核心思想是 解耦“用户”与“权限”。
没有 RBAC 的糟糕设计:直接将“权限”(如访问
sys_menu表中的菜单)分配给“用户”(sys_user表)。- 痛点:假设我们有 1000 个用户和 100 个菜单项。当新员工“王五”入职时,我们需要手动从 100 个菜单中为他勾选 50 个他需要的权限。当下个月“工资条管理”菜单下线,换成“薪酬系统”时,我们必须找出所有拥有该权限的 800 个用户,逐一为他们移除旧权限、添加新权限。这是“运维灾难”。
采用 RBAC 的优雅设计:我们在“用户”和“权限”之间增加了一个抽象层,叫做“角色”(
sys_role表)。- 我们将“权限”(菜单)分配给“角色”。例如,创建“财务经理”角色,并为其分配“报表中心”、“工资条管理”等 50 个菜单权限。
- 我们将“角色”分配给“用户”。
在这种模型下,当新员工“王五”入职时,我们 只需要给他分配一个“财务经理”角色,他就立即自动获得了该角色所绑定的 50 个菜单权限。当下个月“薪酬系统”替换“工资条管理”时,我们 只需要修改“财务经理”这一个角色的权限,所有拥有该角色的 800 个用户(包括张三、李四、王五)的权限就同步更新了。
这就是 RBAC 的威力:它将对“人”的管理转变为对“角色”的管理,极大提升了系统的可维护性和扩展性。
4.3.2. 9 大核心表关系模型
RVP 的 RBAC 模型正是基于上述思想构建的,并在此基础上扩展了“部门”和“岗位”的概念,形成了 9 张表的核心体系。
这 9 张表可以分为两类:
1. 实体表(5 张):系统的“名词”,代表具体的实体。
sys_user(用户信息表)sys_role(角色信息表)sys_menu(菜单权限表)sys_dept(部门表)sys_post(岗位信息表)
2. 中间表/连接表(4 张):系统的“连线”,用于实现实体之间的“多对多”关系。
sys_user_role(用户和角色关联表)sys_role_menu(角色和菜单关联表)sys_user_post(用户与岗位关联表)sys_role_dept(角色和部门关联表)
这 9 张表协同工作,支撑了 RVP 的两大权限体系:
菜单权限(功能权限)
- 决定了“你能看到哪些菜单、能点击哪些按钮”。
- 实现路径:用户 -> 角色 -> 菜单 (
sys_user->sys_user_role->sys_role->sys_role_menu->sys_menu)
数据权限
- 决定了“在同一个菜单下,你能看到哪些人的数据”。(例如,A 部门经理只能看 A 部门的订单,B 部门经理只能看 B 部门的订单)
- 实现路径:用户 -> 角色 -> 部门 (
sys_user->sys_user_role->sys_role->sys_role_dept->sys_dept)
4.3.3. 用户表 (sys_user):一切的核心
sys_user 表是整个权限模型的起点,所有关系都围绕“人”展开。
1 | create table sys_user ( |
核心字段分析:
user_id:主键,所有中间表都将使用它来关联用户。tenant_id:租户编号。这是 SaaS 架构的基础,它确保了 A 公司的admin和 B 公司的admin是两个完全不同的用户,他们的数据被tenant_id严格隔离。我们后续分析的所有核心表(sys_role,sys_dept等)都有这个字段。dept_id:这是一个关键字段。它是一个 直接外键,指向sys_dept.dept_id。
重要理解:sys_user 表中的 dept_id 代表了该用户的“归属部门”或“主部门”。这是一个“一对多”关系(一个部门可以有多个用户)。这与后续的数据权限(如“仅看本部门数据”)密切相关。
4.3.4. 部门与岗位 (sys_dept 与 sys_post)
sys_dept(部门)和 sys_post(岗位)定义了企业的组织架构。
1. 部门表 (sys_dept)
sys_dept 不仅仅是一张简单的信息表,它是一个 树形结构。
1 | create table sys_dept ( |
核心字段分析(树形结构):
parent_id:指向父节点的dept_id。根节点(如“XXX 科技”)的parent_id为 0。ancestors:这是一个关键的性能优化字段。它用逗号分隔,存储了从根节点到当前节点的所有父级 ID 路径。- 为什么需要
ancestors? - 试想一个需求:“查询研发部门(id = 103)下的所有子部门”。如果只有
parent_id,我们需要编写一个复杂的递归 SQL 查询,性能很差。 - 有了
ancestors字段,查询变得极其简单高效:SELECT * FROM sys_dept WHERE ancestors LIKE '%,103,%'(查询所有祖级列表中包含 103 的部门)。 - RVP 框架在实现“本部门及以下数据权限”时,正是严重依赖了这个字段。
- 为什么需要
2. 岗位信息表 (sys_post)
sys_post 用于定义具体的“职位”,如“董事长”、“项目经理”、“普通员工”。
1 | create table sys_post ( |
在 RVP 5.x 的瘦身版 SQL 中,sys_post 表本身不直接关联 sys_dept。它是一个独立的岗位字典。
一个“用户”和一个“岗位”的关系是如何建立的呢?答案是通过我们前面提到的中间表 sys_user_post。
1 | create table sys_user_post ( |
这张表清晰地定义了 sys_user 和 sys_post 之间的“多对多”关系,允许一个用户(如某个部门经理)同时兼任另一个项目的“项目经理”岗位。
4.3.5. 本节小结
我们详细拆解了 RBAC 模型的 9 张核心表,重点理解了 5 张实体表(用户、角色、菜单、部门、岗位)和 4 张中间表(用户-角色、角色-菜单、用户-岗位、角色-部门)的职责。
- RBAC 核心:在“用户”和“权限”之间建立“角色”层,实现解耦,提升可维护性。
- 9 表模型:5 张实体表(名词) + 4 张中间表(连线)。
sys_user:权限模型的中心,dept_id是其“归属部门”的直接外键。sys_dept:通过parent_id和ancestors字段实现了高性能的树形结构,是“数据权限”的基石。- 多对多关系:通过
sys_user_role,sys_role_menu,sys_user_post等中间表实现。






