
Prorise
这是我的博客,分享技术与生活的点点滴滴
第七章:数据库核心概念与 Prisma 入门
第七章:数据库核心概念与 Prisma 入门
Prorise第七章:数据库核心概念与 Prisma 入门
摘要: 到目前为止,我们的 Express 应用已经拥有了清晰的结构和健壮的验证,但它依然有一个致命的缺陷——它没有记忆。服务器一旦重启,所有“创建”的用户、发布的消息都会烟消云散。本章,我们将为应用植入一颗“心脏”——数据库,实现数据的持久化。我们将深入探讨数据存储的两种主流范式:SQL 与 NoSQL,并理解为何需要 ORM (对象关系映射) 作为应用代码与数据库之间的桥梁。最后,我们将重点介绍并实战当今最热门的 Node.js ORM Prisma,学习如何通过其直观的 Schema 文件定义数据模型,并使用其强大的命令行工具将模型同步到真实的数据库中。
在本章,我们将为应用构建坚实的数据基石:
- 首先,我们将探讨 数据持久化的必要性,理解为什么简单的文件读写无法满足现代应用的需求。
- 接着,我们将细致对比 SQL 与 NoSQL 两大数据库阵营,理解它们的设计理念、核心差异及各自的适用场景。
- 然后,我们将深入解析 ORM 的核心价值,明白它如何解决了“对象”与“关系”之间的“阻抗不匹配”问题。
- 之后,我们将正式上手 Prisma,完成其初始化配置,并理解其三大核心组件。
- 最后,我们将聚焦于
schema.prisma,逐行详解其语法,定义复杂的数据模型和关系。 - 我们将使用 Prisma CLI 执行数据库迁移,将我们的数据模型真正应用到数据库中。
7.1. 数据持久化:为你的应用赋予记忆
痛点背景: 为什么我们不能简单地用 fs.writeFile 把用户数据存成一个 users.json 文件?对于一个玩具项目,这或许可行。但对于一个真实的、多用户同时访问的后端服务,这种方式会带来一系列无解的难题:
- 并发冲突: 想象一下,两个用户几乎同时注册。两个进程都读取了
users.json,各自在内存里添加了新用户,然后几乎同时写回文件。结果是什么?后写入的会覆盖先写入的,导致第一个用户的注册数据丢失。 - 查询效率低下: 如果要查询某个特定 email 的用户,你需要读取并解析整个 JSON 文件,然后在巨大的数组中进行遍历查找。当用户量达到百万级,这将是一场性能灾难。
- 数据关联复杂: 如何表示用户和他们发表的文章之间的关系?你可能需要在文章对象里存一个
userId,但如果要查询某个用户的所有文章,又需要遍历整个文章数组。维护这种关系的成本和复杂度会随着业务增长而急剧飙升。
解决方案: 数据库管理系统 (DBMS) 正是为解决以上所有问题而设计的专业软件。它提供了高效的数据检索、安全的并发控制(事务)、强大的数据关系管理以及数据备份恢复等一系列高级功能,是所有严肃应用的必备组件。
7.2. 两大阵营:SQL vs. NoSQL 的抉择
细致讲解: 选择数据库,是后端架构设计的第一个重要决策。这通常归结于在两种主流哲学之间做出选择:关系型 (SQL) 和非关系型 (NoSQL)。
核心思想
结构化、关系优先 —— 数据被组织在严格定义的“表”中,类似 Excel。
数据模型
- 表 (Table) →
Users、Posts - 行 (Row) → 一条记录(一个用户)
- 列 (Column) → 字段(
email、password),每列有严格数据类型 - 主键/外键 → 用
id唯一标识行;Posts.authorId指向Users.id建立关联
核心优势
- ACID 事务:强一致性,金融/电商必备
- 强大关联查询:
JOIN轻松多表关联 - 数据完整性:Schema 预定义,保证数据干净规范
适用场景
业务逻辑清晰、结构稳定、关系复杂:网上商城、银行系统、企业内部 ERP
核心思想
灵活性、文档优先 —— 数据被组织成独立的“文档”,像自由的 JSON 文件。
数据模型
- 集合 (Collection) → 类似 SQL 的表,如
users - 文档 (Document) → BSON/JSON 记录,可嵌套;同一集合字段可不同
- 字段 (Field) → 文档内的键值对
核心优势
- 灵活 Schema:无需预先定义表结构,随时增删字段,适合快速迭代
- 水平扩展:天生分布式,加服务器即可横向扩展性能
- 高性能读写:简单键值查询或大量非结构化数据写入更快
适用场景
大数据、内容管理、实时分析、物联网 (IoT):博客平台、社交网络、游戏数据
我们的选择: 对于“架构思维的觉醒者”而言,从结构化、关系明确的 PostgreSQL (SQL) 开始是更佳选择。它的严谨性有助于培养良好的数据建模习惯,并且能与 Prisma 这类提供强类型安全的 ORM 完美结合,构建出高度可预测和健壮的后端服务。
7.3. ORM:代码与数据库的优雅“翻译官”
细致讲解:
在我们的应用代码中,我们习惯于用“对象 (Object)”来思考和操作数据。但在关系型数据库中,数据是以“行和列”的形式存在的。这之间存在一个被称为 “阻抗不匹配” 的鸿沟。
没有 ORM 的世界 (手写 SQL):
1 | // 假设有一个 db 连接对象 |
ORM (Object-Relational Mapper) 的出现,就是为了填平这条鸿沟。它像一个智能的“翻译官”,允许我们继续使用面向对象的方式操作数据,由它在底层自动地、安全地生成和执行对应的 SQL 语句,并将结果转换回我们熟悉的对象。
拥有 ORM 的世界 (以 Prisma 为例):
1 | import { PrismaClient } from '@prisma/client'; |
使用 ORM,我们可以获得 类型安全、代码提示、更少的模板代码、更高的开发效率 以及 对 SQL 注入等常见攻击的内置防护。
7.4. Prisma 入门:下一代 ORM
Prisma 之所以被称为下一代 ORM,是因为它独特的架构。它主要包含三个部分:
- Prisma Client: 自动生成的、类型安全的数据库客户端。你在应用代码中
import和使用的就是它。 - Prisma Migrate: 数据库迁移工具。它根据你的数据模型声明,自动生成并应用 SQL 迁移脚本,让你的数据库结构变更可追踪、可版本化。
- Prisma Studio: 一个现代化的、可视化的数据库 GUI 工具,方便你直接浏览和编辑数据。
第一步:安装 Prisma CLI 和 Client
1 | npm install prisma --save-dev |
第二步:初始化 Prisma 项目
这个命令会在你的项目中创建一个 prisma 目录,并在其中生成一个 schema.prisma 文件。同时,它还会在项目根目录创建一个 .env 文件,用于存放数据库连接字符串。
1 | npx prisma init |
7.5. 定义数据模型:schema.prisma 详解
schema.prisma 是你项目的 唯一数据源。你在这里用一种简洁的声明式语言 (Prisma Schema Language, PSL) 定义你的数据模型,Prisma 会基于此文件生成所有内容。
让我们来定义一个包含 User (用户) 和 Post (文章) 的模型,并建立它们之间的一对多关系。
prisma/schema.prisma:
1 | // 默认内容:定义生成器,告诉 Prisma 我们要生成一个 JavaScript 的 Prisma Client |
7.6. Prisma CLI:从模型到数据库的桥梁
细致讲解:
我们已经在 schema.prisma 文件中精心绘制了数据模型的“蓝图”。现在,我们需要一个强大的工具来将这个蓝图变为现实——也就是在数据库中创建出真实的表结构。这个将模型定义同步到数据库的过程,在专业领域被称为数据库迁移 (Database Migration),而执行这个过程的工具就是 Prisma CLI。
在执行迁移之前,我们的应用需要一个真实可连接的数据库。虽然可以在本地安装 PostgreSQL,但一个更快捷、更现代的方式是使用免费的云数据库服务。这里,我们将以 Supabase 为例,手把手带你完成配置。
首先,你需要从 Supabase 获取一个免费的 PostgreSQL 数据库。这个过程非常简单:
- 访问使用 GitHub 账号登录并创建一个新项目。在创建过程中,系统会要求你设置一个数据库密码,请务必生成并立即复制保存这个密码,因为这是连接数据库的关键凭证。
- 项目创建成功后,进入项目仪表盘。在左侧菜单栏点击设置 (Settings) 图标(齿轮形状),然后选择 Database 选项。
- 在数据库设置顶栏,向上keyi看到Connect选项,找到 ORM卡片,如图所示
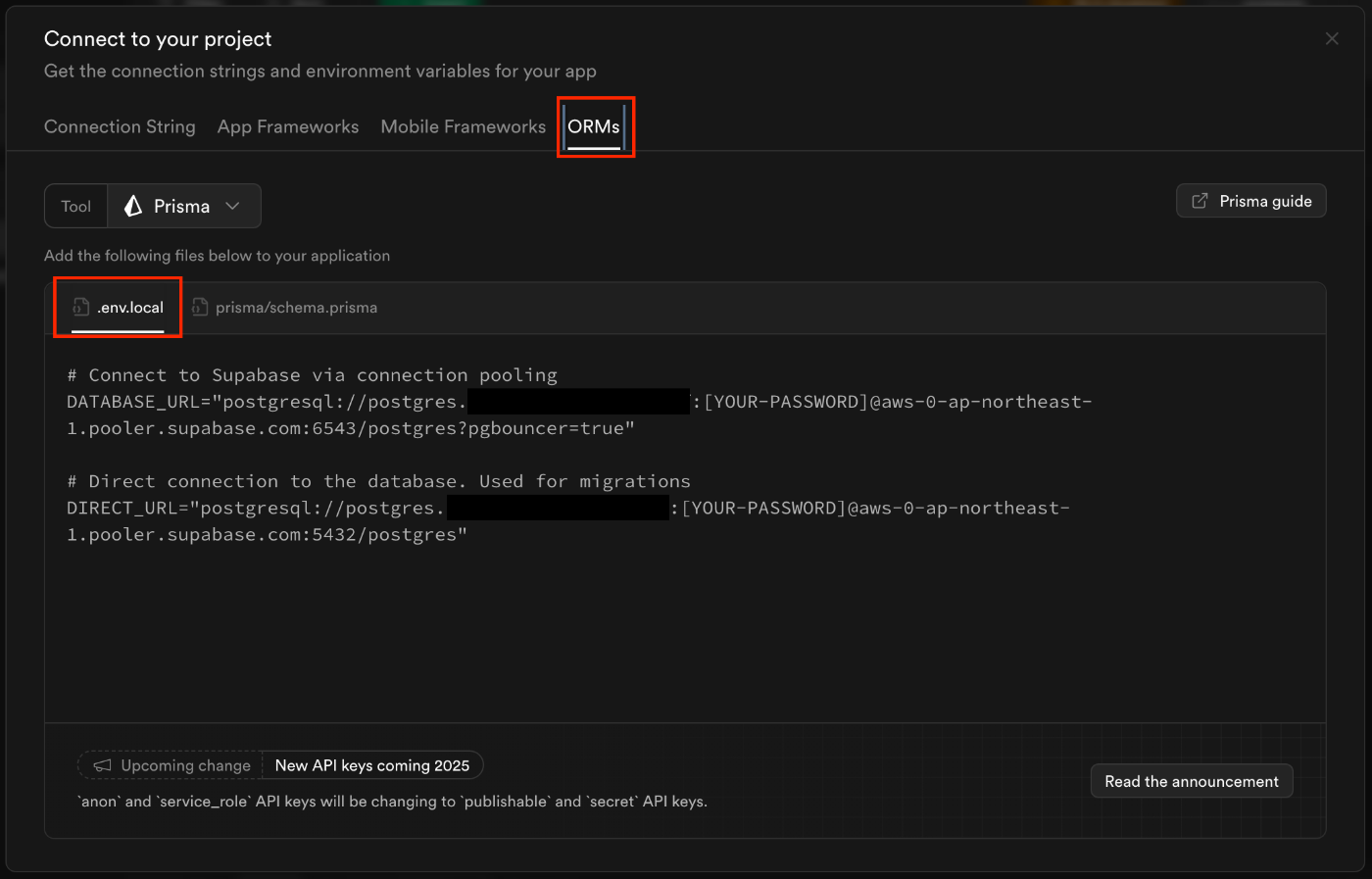
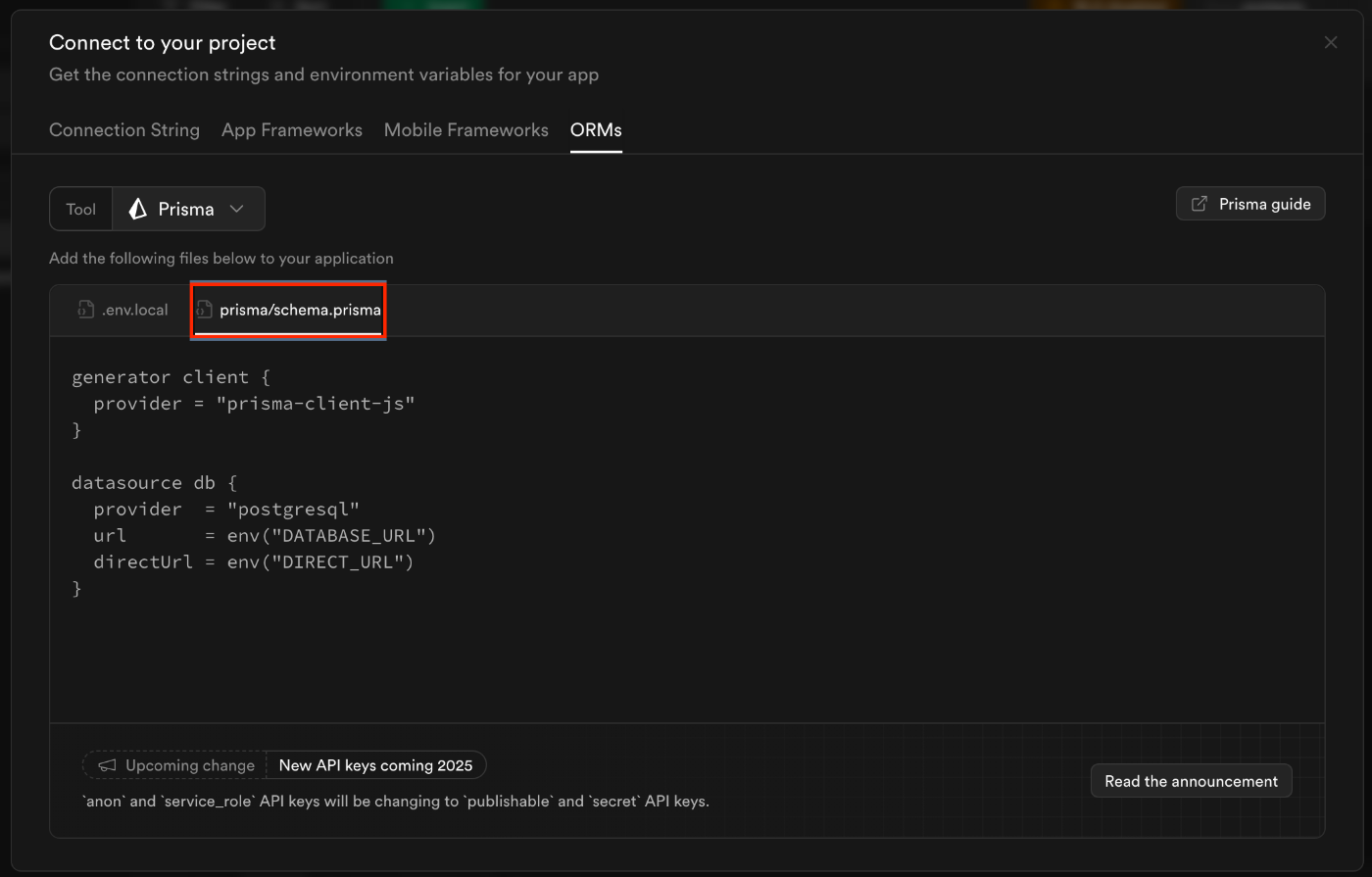
拿到连接字符串后,回到你的 Node.js 项目中,打开根目录下的 .env 文件(由 npx prisma init 创建)。将你复制的字符串粘贴到 DATABASE_URL 的引号内,并用你之前保存的数据库密码替换掉字符串中的 [YOUR-PASSWORD] 占位符。
配置完成后,你的 .env 文件看起来应该像这样:
1 | # .env |
安全警告:.env 文件包含你的数据库密钥,是项目的最高机密。绝对不能将它提交到 Git 仓库。请确保你的 .gitignore 文件中包含了 .env 这一行。
万事俱备。现在,我们可以执行第一次数据库迁移了。在你的终端里运行以下命令:
1 | # --name init 为这次迁移提供一个描述性的名称,例如 "init" 或 "initial-schema" |
这个命令是 Prisma 工作流的核心,它会为你自动完成一系列关键操作:
- 它会读取并解析你的
prisma/schema.prisma文件。 - 它会连接到你在
.env文件中配置的 Supabase 数据库。 - 它会为你生成一个包含
CREATE TABLE ...等 SQL 语句的迁移文件,并将其保存在prisma/migrations目录下,作为数据库结构变更的历史记录。 - 它会将这个 SQL 文件应用到你的云数据库中,创建出
User和Post两张表。 - 最后,它会自动运行
prisma generate。
最后来谈谈自动触发的 prisma generate。这个命令是 Prisma 类型安全魔法的源泉。它会再次读取你的 schema.prisma 文件,然后在 node_modules/@prisma/client 目录下生成一套完全根据你的 User 和 Post 模型定制的、包含所有 TypeScript 类型定义的客户端代码。
至此,一座连接你的应用代码和云端数据库的坚实桥梁已经成功搭建。你的 Supabase 数据库中已经拥有了正确的表结构,同时你的 Node.js 项目也拥有了一个完全类型安全、具备自动补全能力的数据库客户端,为下一章的数据操作做好了万全的准备。
7.7. 本章核心速查总结
| 分类 | 关键项 | 核心描述 |
|---|---|---|
| 数据库类型 | SQL (关系型) | 结构化,表、行、列,强一致性,适用于关系复杂的业务。 |
NoSQL (非关系型) | 灵活性,文档、集合,高可扩展性,适用于需求多变的业务。 | |
| 核心概念 | ORM (对象关系映射) | 在面向对象的代码和关系型数据库之间进行转换的“翻译官”。 |
| Prisma Schema | datasource | 定义数据库连接信息。 |
generator | 定义要生成的客户端类型(通常是 prisma-client-js)。 | |
model | 定义一个数据模型,对应数据库中的一张表。 | |
@id, @unique, @default | 字段属性,分别用于定义主键、唯一约束和默认值。 | |
@relation | (关键) 用于定义模型之间的关系。 | |
| Prisma CLI | npx prisma init | 初始化 Prisma,创建 prisma 目录和 .env 文件。 |
npx prisma migrate dev | (核心命令) 根据 schema.prisma 的变更,生成并应用数据库迁移。 | |
npx prisma generate | 手动触发 Prisma Client 的生成(migrate 会自动调用)。 |
7.8. 高频面试题与陷阱
你好,在使用 ORM 时,我们经常会听到一个经典的性能问题,叫做“N+1 查询问题”。你能解释一下什么是 N+1 问题吗?
当然。N+1 查询问题通常发生在查询一个列表数据,并且需要同时加载每个列表项的关联数据时。
举个例子,假设我们要查询 10 篇文章(Posts),并同时显示每篇文章的作者信息(User)。最朴素的实现方式可能会导致:第 1 次查询,用一条 SQL 语句 SELECT * FROM "Post" LIMIT 10; 获取了 10 篇文章。然后,代码会遍历这 10 篇文章,对每一篇文章,都单独执行一次 SQL 查询去获取其作者信息,例如 SELECT * FROM "User" WHERE id = ?;。
所以这里的“N+1”指的是什么?
“1” 指的是获取文章列表的那一次主查询。而“N”指的是为了获取这 N 篇文章各自的作者信息,而额外执行的 N 次独立的子查询。如果 N 是 10,那么总共就执行了 1+10 = 11 次 SQL 查询。如果 N 是 1000,就会执行 1001 次查询,这对数据库会造成巨大的、不必要的压力。
说得很清楚。那么,对于像 Prisma 这样的现代 ORM,通常会提供什么方案来解决或避免 N+1 问题?
现代 ORM 通常提供了一种叫做“预加载”或“急切加载” (Eager Loading) 的机制。在 Prisma 中,这体现在它的 include 选项上。当查询文章列表时,我可以这样写:prisma.post.findMany({ include: { author: true } })。Prisma 在底层会优化这个查询,通常会将其转换为两条高效的 SQL 语句:一条是 SELECT * FROM "Post" ...,另一条是 SELECT * FROM "User" WHERE id IN (..., ..., ...),用一个 IN 子句一次性加载所有需要的作者信息。这样,无论 N 是多大,都只需要执行 1+1 = 2 次查询,完美地解决了 N+1 问题。











